【Kafka】SpringBoot整合Kafka详细介绍及代码示例
Kafka介绍
Apache Kafka是一个分布式流处理平台。它最初由LinkedIn开发,后来成为Apache软件基金会的一部分,并在开源社区中得到了广泛应用。Kafka的核心概念包括Producer、Consumer、Broker、Topic、Partition和Offset。
- Producer:生产者,负责将数据发送到Kafka集群。
- Consumer:消费者,从Kafka集群中读取数据。
- Broker:Kafka服务器实例,Kafka集群通常由多个Broker组成。
- Topic:主题,数据按主题进行分类。
- Partition:分区,每个主题可以有多个分区,用于实现并行处理和提高吞吐量。
- Offset:偏移量,每个消息在其分区中的唯一标识。
使用场景
Kafka适用于以下场景:
- 日志收集:集中收集系统日志和应用日志,通过Kafka传输到大数据处理系统。
- 消息队列:作为高吞吐量、低延迟的消息队列系统。
- 数据流处理:实时处理数据流,用于实时分析、监控和处理。
- 事件源架构:将所有的变更事件存储在Kafka中,实现事件溯源和回放。
- 流数据管道:构建数据管道,连接数据源和数据存储系统。
Spring Boot整合Kafka
项目结构
springboot-kafka
│
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com.example.kafka
│ │ │ ├── KafkaApplication.java
│ │ │ ├── config
│ │ │ │ └── KafkaConfig.java
│ │ │ ├── producer
│ │ │ │ └── KafkaProducer.java
│ │ │ ├── consumer
│ │ │ │ └── KafkaConsumer.java
│ │ │ └── controller
│ │ │ └── KafkaController.java
│ │ └── resources
│ │ ├── application.yml
│ │ └── logback-spring.xml (可选)
│ └── test
│ └── java
│ └── com.example.kafka
│ └── KafkaApplicationTests.java
└── pom.xml
1. 创建Spring Boot项目并添加依赖
pom.xml
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>
2. 配置Kafka
application.yml
spring:kafka:bootstrap-servers: localhost:9092consumer:group-id: my-groupauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
3. 创建Kafka配置类
KafkaConfig.java
package com.example.kafka.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class KafkaConfig {@Beanpublic NewTopic myTopic() {return new NewTopic("my-topic", 1, (short) 1);}
}
4. 创建Kafka生产者
KafkaProducer.java
package com.example.kafka.producer;import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;@Service
public class KafkaProducer {private final KafkaTemplate<String, String> kafkaTemplate;public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}
}
5. 创建Kafka消费者
KafkaConsumer.java
package com.example.kafka.consumer;import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
public class KafkaConsumer {@KafkaListener(topics = "my-topic", groupId = "my-group")public void listen(String message) {System.out.println("Received message: " + message);}
}
6. 创建控制器发送消息
KafkaController.java
package com.example.kafka.controller;import com.example.kafka.producer.KafkaProducer;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
public class KafkaController {private final KafkaProducer kafkaProducer;public KafkaController(KafkaProducer kafkaProducer) {this.kafkaProducer = kafkaProducer;}@GetMapping("/send")public String sendMessage(@RequestParam String message) {kafkaProducer.sendMessage("my-topic", message);return "Message sent";}
}
7. 创建Spring Boot主类
KafkaApplication.java
package com.example.kafka;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class KafkaApplication {public static void main(String[] args) {SpringApplication.run(KafkaApplication.class, args);}
}
8. 测试应用
通过访问以下URL来发送消息:
http://localhost:8080/send?message=HelloKafka9. 日志配置(可选)
为了更好地查看Kafka的日志,可以添加logback-spring.xml配置:
logback-spring.xml
<configuration><springProfile name="default"><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss} - %msg%n</pattern></encoder></appender><logger name="org.apache.kafka" level="INFO"/><root level="INFO"><appender-ref ref="STDOUT"/></root></springProfile>
</configuration>
10. 测试类(可选)
KafkaApplicationTests.java
package com.example.kafka;import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
class KafkaApplicationTests {@Testvoid contextLoads() {}
}
至此,你已经完成了Spring Boot整合Kafka的详细配置和代码示例。你可以根据实际需求进一步扩展和修改这个基础代码。
相关文章:

【Kafka】SpringBoot整合Kafka详细介绍及代码示例
Kafka介绍 Apache Kafka是一个分布式流处理平台。它最初由LinkedIn开发,后来成为Apache软件基金会的一部分,并在开源社区中得到了广泛应用。Kafka的核心概念包括Producer、Consumer、Broker、Topic、Partition和Offset。 Producer:生产者&a…...

C++ 质数因子分解
描述 功能:输入一个正整数,按照从小到大的顺序输出它的所有质因子(重复的也要列举)(如180的质因子为2 2 3 3 5 ) 输入描述: 输入一个整数 输出描述: 按照从小到大的顺序输出它的所有质数的…...
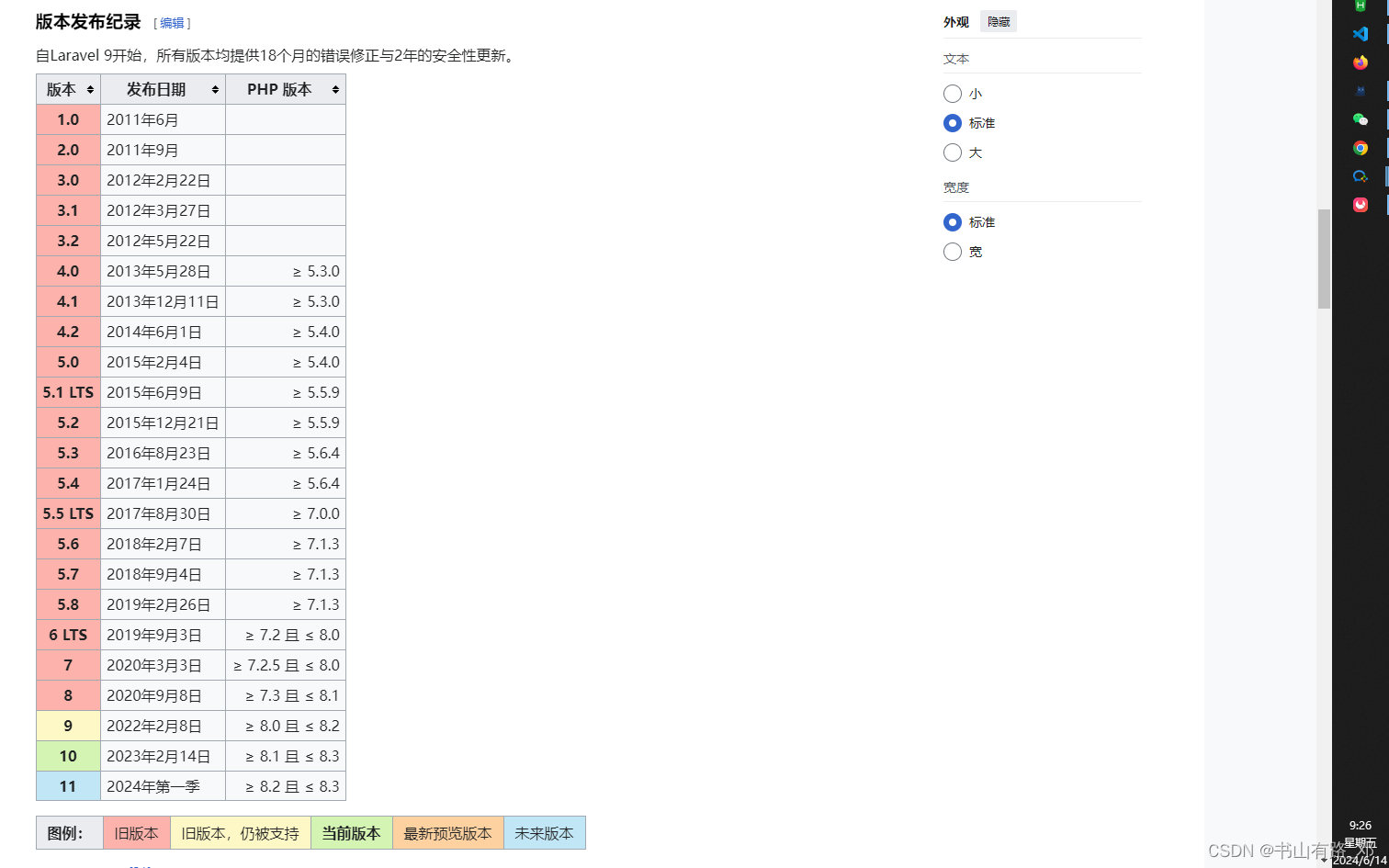
laravel版本≥ 8.1
laravel10 php ≥ 8.1 且 ≤ 8.3? 8.1 < php < 8.3PHP版本要求在 8.1 到 8.3 之间,包括这两个版本。具体来说:"≥ 8.1" 表示 PHP 的版本至少是 8.1,也就是说 8.1 及以上的版本都可以。 "≤ 8.3" 表示 P…...
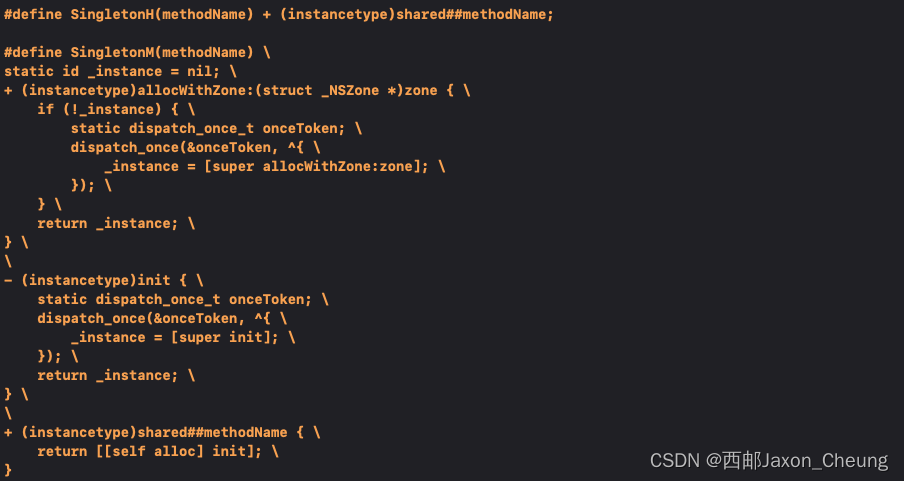
【iOS】MRC下的单例模式批量创建单例
单例模式的介绍和ARC下的单例请见这篇:【iOS】单例模式 目录 关闭ARC环境MRC下的单例ARC下的单例批量创建单例Demo 关闭ARC环境 首先关闭ARC环境,即打开MRC: 或是指定某特定目标文件为非ARC环境: 双击某个类文件,指定…...

计算机网络期末复习
今天考专四,环境都蛮好的,试卷也很新,老师人也不错,明年再来。 又到期末考试咯,大家复习没有?还没复习啊?还不复???? 目录 第一章 1-02 试简述…...

python写一个获取竞品信息报告
要编写一个获取竞品信息报告的Python程序,首先需要明确您想要获取的竞品信息以及数据来源。在这个示例中,我将展示如何从网页提取竞品信息,并编写一个简单的报告。 假设您想要获取以下竞品信息: 1. 产品名称 2. 产品价格 3. 产品特…...

一文彻底理解机器学习 ROC-AUC 指标
在机器学习和数据科学的江湖中,评估模型的好坏是非常关键的一环。而 ROC(Receiver Operating Characteristic)曲线和 AUC(Area Under Curve)正是评估分类模型性能的重要工具。 这个知识点在面试中也很频繁的出现。尽管…...

【二】【动态规划NEW】91. 解码方法,62. 不同路径,63. 不同路径 II
91. 解码方法 一条包含字母 A-Z 的消息通过以下映射进行了 编码 : ‘A’ -> “1” ‘B’ -> “2” … ‘Z’ -> “26” 要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法ÿ…...

Python闯LeetCode--第3题:无重复字符的最长子串
Problem: 3. 无重复字符的最长子串 文章目录 思路解题方法复杂度Code 思路 一上来马上想到两层for循环暴力枚举,但是又立马想到复杂度是 O ( n 2 ) O(n^2) O(n2),思考了一下能否有更优解,于是想到用头尾两个指针来指定滑动窗口(主…...

HTML DOM 对象
HTML DOM 对象 1. 概述 HTML DOM(文档对象模型)是一个跨平台和语言独立的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。在HTML DOM中,文档被表示为节点树,其中每个节点代表文档中的一个部分,例如元素、文本或属性。HTML DOM对象是构成这个节点树的基…...

如何解决 BeautifulSoup 安装问题:从 BeautifulSoup 3 到 BeautifulSoup 4
在使用 Python 的过程中,解析 HTML 和 XML 数据是一项常见任务。BeautifulSoup 是一个非常流行的解析库。然而,最近在安装 BeautifulSoup 时,遇到了一些问题。本文将介绍如何解决这些问题,并成功安装 BeautifulSoup 4。 问题描述 …...

原型模式--深复制/浅复制
原型模式用于克隆复杂对象,由于new一个实例对象会消耗大部分时间,所以原型模式可以节约大量时间 1 public class Sheep implements Cloneable{2 private String name;3 private Date birth;4 public Sheep(String name, Date birth) {5 …...
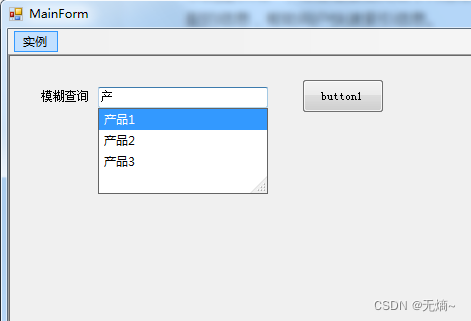
C# TextBox模糊查询及输入提示
在程序中,我们经常会遇到文本框中不知道输入什么内容,这时我们可以在文本框中显示提示词提示用户;或者需要查询某个内容却记不清完整信息,通常可以通过文本框列出与输入词相匹配的信息,帮助用户快速索引信息。 文本框…...
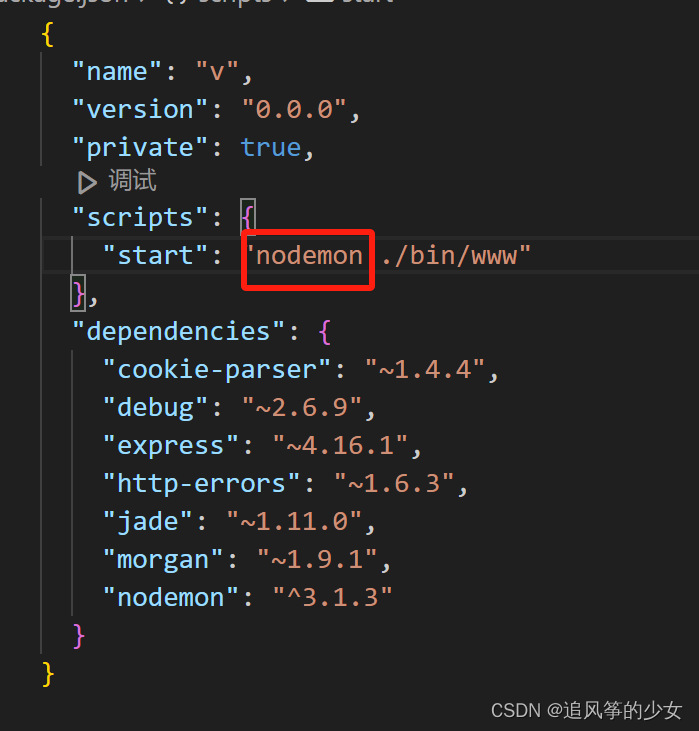
Node入门以及express创建项目
前言 记录学习NodeJS 一、NodeJS是什么? Node.js 是一个开源和跨平台的 JavaScript 运行时环境 二、下载NodeJs 1.下载地址(一直点击next即可,记得修改安装地址) https://nodejs.p2hp.com/download/ 2.查看是否安装成功,打开命令行 nod…...
Cheat Engine CE v7.5 安装教程(专注于游戏的修改器)
前言 Cheat Engine是一款专注于游戏的修改器。它可以用来扫描游戏中的内存,并允许修改它们。它还附带了调试器、反汇编器、汇编器、变速器、作弊器生成、Direct3D操作工具、系统检查工具等。 一、下载地址 下载链接:http://dygod/source 点击搜索&…...
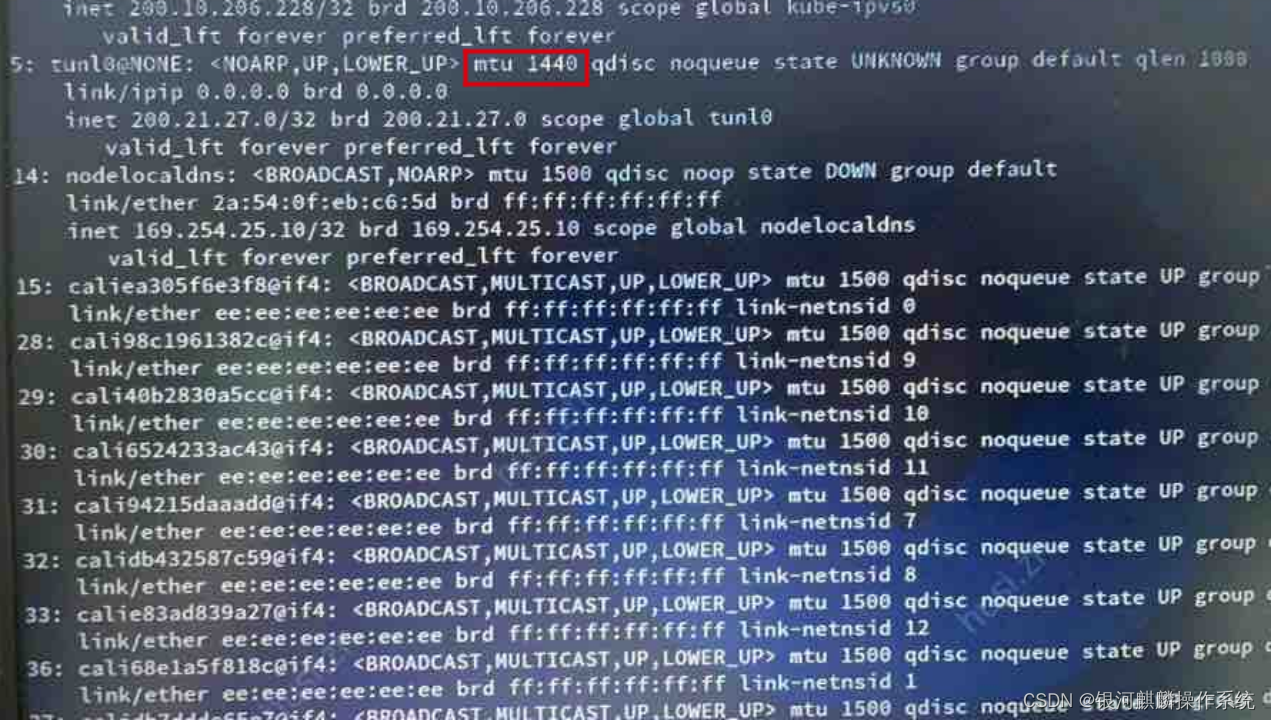
【实例分享】访问后端服务超时,银河麒麟服务器操作系统分析及处理建议
1.服务器环境以及配置 【机型】 处理器: Intel 32核 内存: 128G 整机类型/架构: x86_64虚拟机 【内核版本】 4.19.90-25.22.v2101.kylin.x86_64 【OS镜像版本】 kylin server V10 SP2 【第三方软件】 开阳k8s 2.问题现象描述 …...

Java中和的区别
在Java中,& 和 && 都是逻辑运算符,但它们之间存在一些重要的区别,特别是在它们如何评估其操作数以及它们的性能影响方面。 短路评估(Short-Circuit Evaluation): &&(逻辑…...
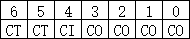
深入理解计算机系统 CSAPP 家庭作业6.34
第一步先求(S,E,B,m) 题目说共C32个字节,块大小B为16个字节,那就是分为两组:0,1.然后每组存4个int 每个4字节 CB*E*S .B16 ,直接映射的E就是1,所以S2 m为啥等于7? 通过写出两个数组所有的地址可以得出m7. 得出高速缓存的参数:(S,E,B,m)(2,1,16,7),注意图6-26每个参数的定义…...

[leetcode 141环形链表]双指针解决环形链表
Problem: 141. 环形链表 文章目录 思路Code 思路 首先想到如果链表为空直接返回false 其次想到用双指针,一个一回走一步,另一个一回走两步 如果是环形,总有一个时刻,两指针会指向同一个节点,而且该结点不能为空(空是快指针遍历完单链表了) Code /*** Definition for singly-li…...

【深度学习】Precision、Accuracy的区别,精确率与准确率:深度学习多分类问题中的性能评估详解
在深度学习的多分类问题中,Precision(精确率)和Accuracy(准确率)是两种常用的性能评估指标,它们各自有不同的定义和用途。 Precision(精确率)的中文发音是:pǔ rēi xī…...

原生TypeScript待办清单:纯前端架构、观察者模式与拖拽排序实践
1. 项目概述:一个由AI辅助构思的现代化待办清单最近在整理个人项目时,我重新审视了一个之前用TypeScript写的待办清单应用。这个项目的初衷很简单:我需要一个极简、快速、完全由我掌控的待办工具,它不需要登录,数据就存…...

Mali-400 MP OpenGL ES DDK核心问题与解决方案
## 1. Mali-400 MP OpenGL ES DDK核心问题解析作为ARM经典的移动GPU架构,Mali-400 MP在Symbian平台的OpenGL ES驱动开发套件(DDK)中存在三类典型问题。这些问题的根源往往涉及GPU硬件特性与图形API规范的微妙交互,开发者需要深入理解其底层机制才能有效规…...

ECA:编辑器无关的AI编程伴侣,统一配置多模型与编辑器
1. 项目概述:一个编辑器无关的AI编程伴侣如果你和我一样,每天大部分时间都泡在编辑器里,那你肯定也经历过这种场景:面对一段复杂的业务逻辑,或者一个陌生的API,你希望有个“懂行”的伙伴能立刻给你解释、重…...

BetterGI自动化工具:每天为原神玩家节省2小时
BetterGI自动化工具:每天为原神玩家节省2小时 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 | 自动烹饪 …...

Roast:颠覆AI助手模式,打造苏格拉底式思维拷问引擎
1. 项目概述:当AI开始“拷问”你如果你用过市面上那些主流的AI助手,不管是ChatGPT、Claude还是DeepSeek,你大概率有过这样的体验:你抛出一个想法,它总能给你一堆“哇,这个想法太棒了!”、“很有…...

模拟工程师必备:口袋参考指南的实战价值与核心应用
1. 为什么每个硬件工程师都需要一本“口袋参考书”?前几天整理书桌,翻出来一本2016年从TI官网下载打印的《模拟工程师口袋参考指南》,纸张已经有点发黄,边角也卷了。但就是这么一本薄薄的小册子,从毕业到现在ÿ…...
)
告别按钮!用Qt实现STM32小车的键盘与手柄控制方案(附串口通信源码)
超越按钮控制:Qt框架下STM32小车的键盘与手柄交互方案 在嵌入式开发领域,人机交互体验往往被忽视,而实际上它直接影响着用户的操作效率和舒适度。对于STM32遥控小车这类需要实时操控的项目,传统的按钮点击方式存在明显局限——操作…...

2026年项目管理工具测评:10款主流软件对比与企业选型建议
本文测评 ONES、Tower、Jira、Asana、monday、ClickUp、Notion、Trello、Microsoft Project、Smartsheet 十款项目管理工具,帮助选型人员从组织规模、项目复杂度、协作方式与治理需求出发,判断哪类项目管理工具更适合自身团队。一、10款项目管理工具速览…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

基于 JiuwenClaw AgentTeam 集群模式的年会策划实战:从源码部署到多智能体协作落地
目录 摘要 一、引言:JiuwenClaw AgentTeam 让复杂任务迎刃而解 1.1 为什么选择年会策划作为 AgentTeam 实战场景 1.2 本文实战目标 二、JiuwenClaw 概述 2.1 JiuwenClaw 的核心特性 2.2 JiuwenClaw 的系统架构 2.3 JiuwenClaw 的三种运行模式 2.3.1 规划模…...