GPU的工作原理
location: Beijing
1. why is GPU
CPU的存储单元和计算单元的互通过慢直接促进了GPU的发展
先介绍一个概念:FLOPS(Floating Point Operations Per Second,浮点运算每秒)是一个衡量其执行浮点运算的能力,可以作为计算机性能的指标。所以人们买计算机是往往关心一下计算机有多少FLOPS
然而,计算机性能可能是过剩的?下图是CPU与DRAM的关系

DRAM每秒把200GB的数据,也就是把25,000,000,000个FP64类型的浮点数传输给CPU;CPU每秒可以计算2,000,000,000,000个FP64类型的浮点数。可以看出,CPU可处理数据的能力是DRAM传输能力的80倍(这种比值有个专业术语:计算强度),除非我们的程序对每个数据都做80次运算,否则CPU的算力总是过剩的
所以从这里可以看出,大部分时间,计算机运行程序的速度并不取决于CPU的计算能力,而是DRAM与CPU传输数据的时间延迟(latency)
以一段测试程序daxpy函数为例:
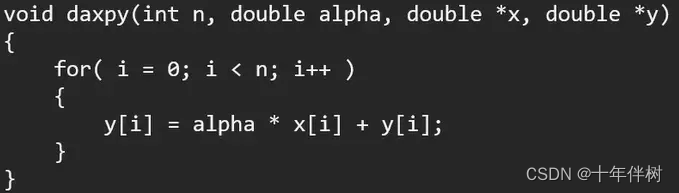
这里我们默认alpha存在CPU的缓存中,数组x和y存在DRAM中。当程序执行时,我们用甘特图看看程序的执行:

可以看出,在程序运行的过程中,CPU花了大量的时间在等待DRAM把数据传过来,这段等待时间大概是占整个程序执行时间的99%以上
至于为什么这么慢,我们可以理解为光速太慢,CPU尺寸太大,传输线太长……anyway,这里不在追究,不过值得一提的是,NVIDIA、Intel、AMD都无法解决这个物理问题
这个问题没办法解决了吗?或许我们可以另辟蹊径,既然这种latency无法避免,那我们就想办法“掩盖”这个latecy
如果总线在89ns内可以传输11659bytes数据,通过daxpy函数可以看到这个函数89ns内只要了16bytes的数据,所以为了让总线忙起来,我们只需要让daxpy函数一次要11659/16=729次数据就能让总线满负荷
比如下面一段程序一定程度上让总线忙一点
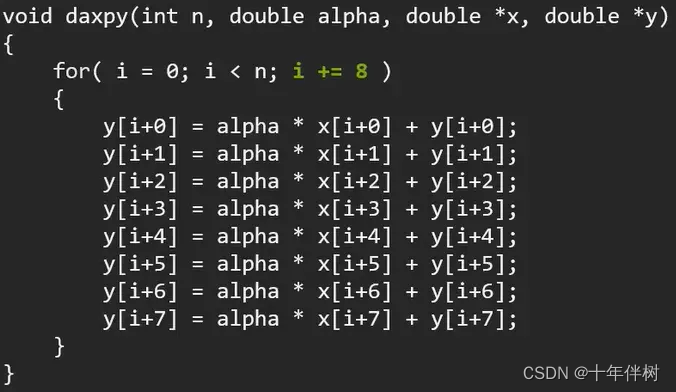
通过这种一次加载大量数据,让CPU和DRAM之间的传输线忙起来,这从一定程度上“减少”了后面加载的数据的延迟,使程序快速运行 ,理论上来讲,即使这是单线程的程序,我的循环中迭代729次也是没问题的
这里需要指出一个点:并行性指的是计算机同时处理多个任务的能力,在硬件限制下每个线程同时处理一个操作,但硬件可以处理很多线程;并发性指计算机有处理多个任务的能力,不讲究同时。
这样通过多线程的模式,也可以掩盖latency的的事实。

从这里可以看出NVIDIA的优势,通过对一批数据进行221184种不同的操作(线程),来掩盖latency的不足,GPU就是为少量数据进行大量任务而设计的,与此相比,CPU期望通过一个线程解决所有问题。
因此,解决latency的问题变为:创造足够多的线程。
2. What is GPU
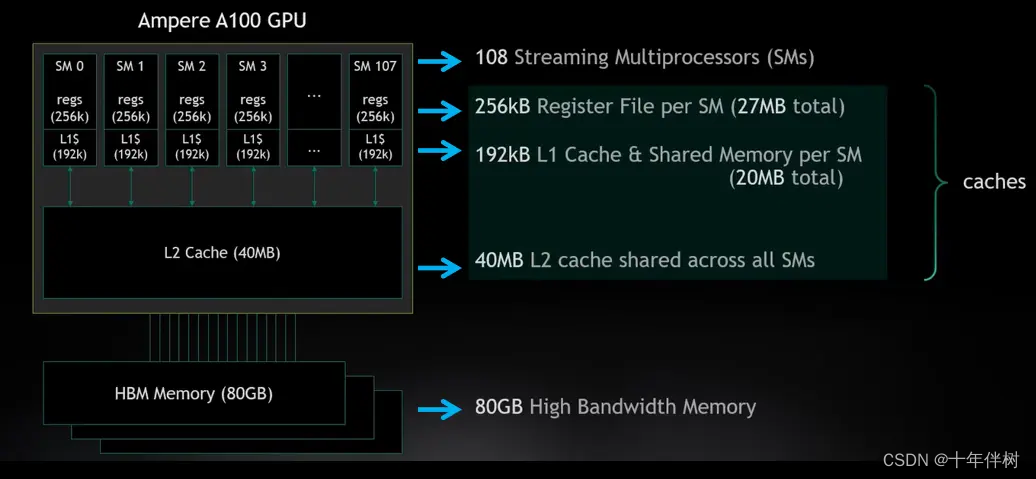
其中,我们希望离SM较近的寄存器能够尽可能的填满,因为每向较远的缓存访问数据,latency都会灾难性的上升。每一个SM都是一个基础处理单元,下图使SM的示意图
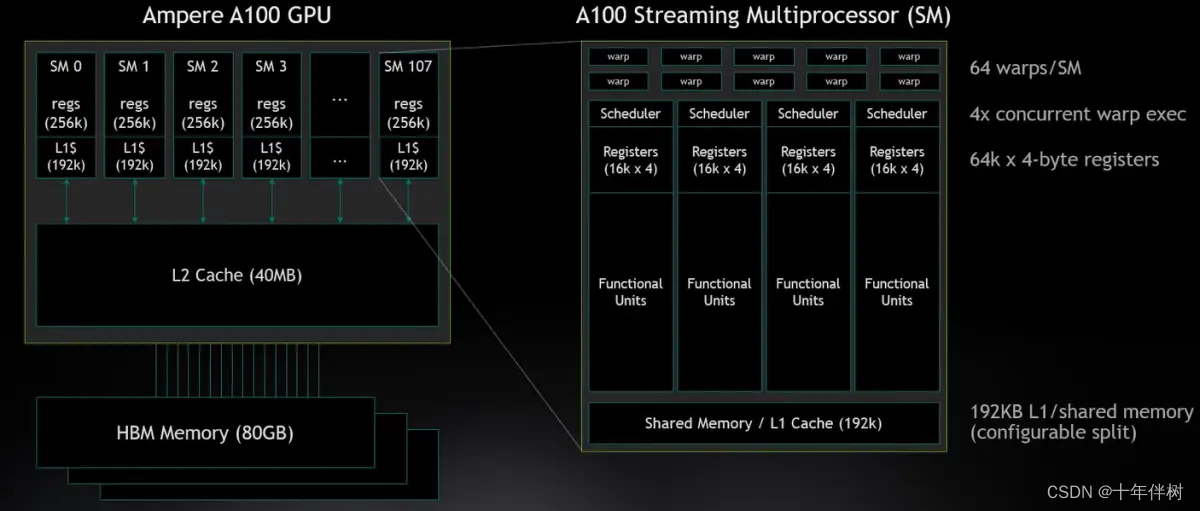
warp使GPU的基本调度单元,每个warp由32个线程组成,作用是将大量线程分组并同时执行,以实现并行计算和隐藏内存访问延迟,Warp中的32个线程将同时执行相同的指令,但操作不同的数据,但如果遇到条件分支语句(如if语句),不同线程可能会选择不同的执行路径。在这种情况下,Warp会以SIMD方式执行分支,即每个线程都会执行分支中的指令,但只有满足条件的线程会更新结果。
如果是单线程,那所有任务都要排队执行,而且最慢的任务可能卡着其他任务执行;但如果是多线程,所有任务都可以同时进入运算,这样就会更快,对延迟的处理更好。
但事实上,各线程之间很少能够独立的进行,因为很多算法或多或少需要一些邻居的数据,比如卷积操作,傅里叶变换。
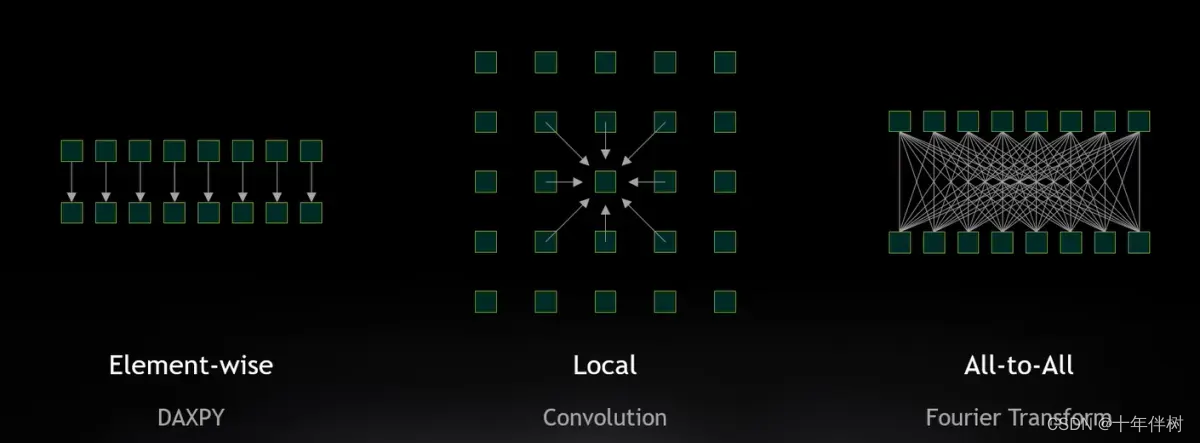
线程之间相互影响
3. How is GPU

比如我让AI去识别一只猫,首先先把照片切块,所有这些块相对独立的操作,GPU通过超量分配(oversubscribed)加载这些块,希望GPU的内存能够满载。然后每个块由若干线程同时操作,这些线程可以共享这个块的数据。
GPU的超量分配(Oversubscription)是指在GPU加速计算环境中,分配给应用程序或作业的资源超出了物理GPU硬件的实际容量,以覆盖latency。
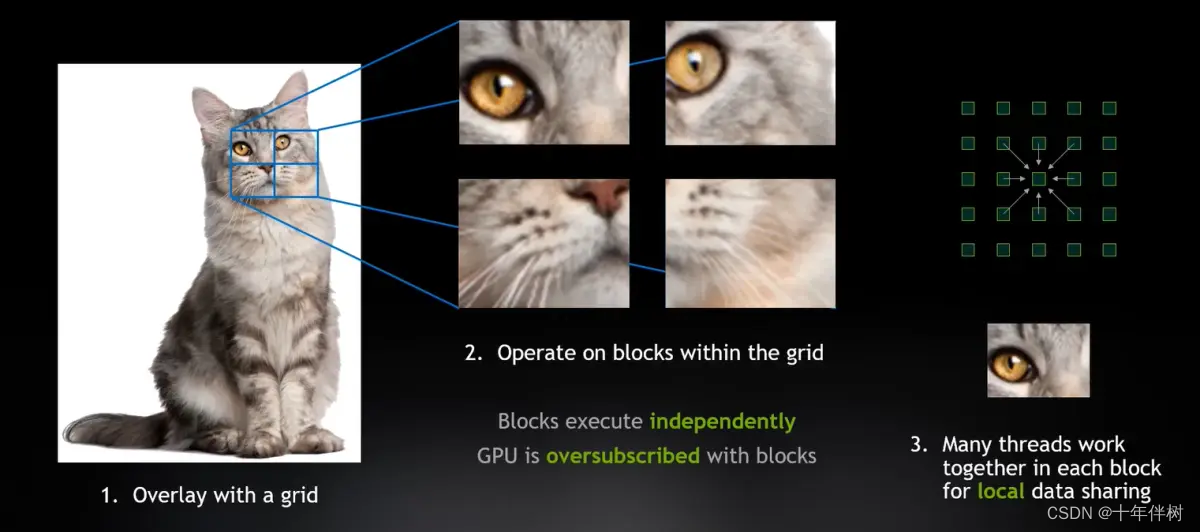
像这样,一个大的任务被分解成若干线程块,每个块相对独立,每个块都有同时进行的并行线程,这些并行的线程共享这个块的数据,当然特定块中的线程可以有所交叉。

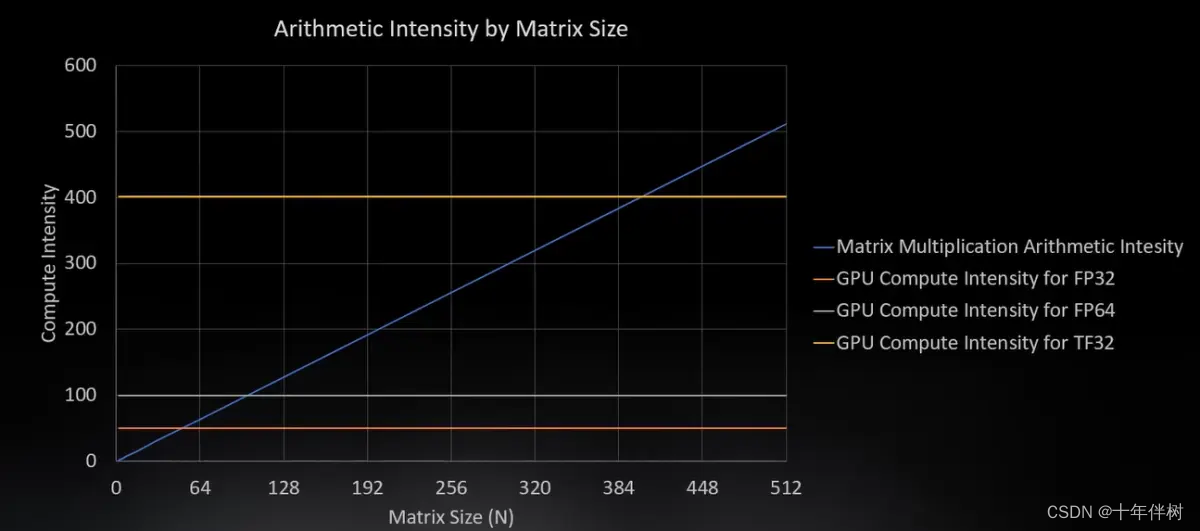
不同类型问题类型的计算强度如下图,intensity Scales=compute Scales/data Scales
可以理解为,对于Element-wise问题,每增加到N个线程,多加载到N个数据,多N组运算;对local问题,每增加N到个线程,多加载NN个数据,多NN数量级次的运算,在卷积中再多的数据也没办法与算术强度相抗衡;但是对于All-to-All问题,每增加到N个线程,多加载N个数据,多了N*N次运算,算术强度就会增加N。

事实上,矩阵的乘法就是All-to-All问题,对于矩阵乘法,NN的矩阵相乘,有N行乘N列,再进行N次相加,所以compute Scales为O(NNN) ,访问内存的数量级是O(NN) ,因此算术强度是O(N) 。
下图的蓝线是矩阵计算的计算强度随矩阵规模增加的曲线,橘线是GPU的计算强度曲线,假设交点是50,计算机运算FP32的最佳位置也就是这个点。对于白线,100是双精度浮点数的最佳计算点。随着矩阵的增大,运算量变得更大,也就不太需要这么多的数据,所以内存也就变得更闲了。GPU中存在一些tensor cores,就是算力更强,这个点也就会上移一些。当内存用完,也就不需要增加算力了。
于是对应于GPU的内部结构,也就有了下图
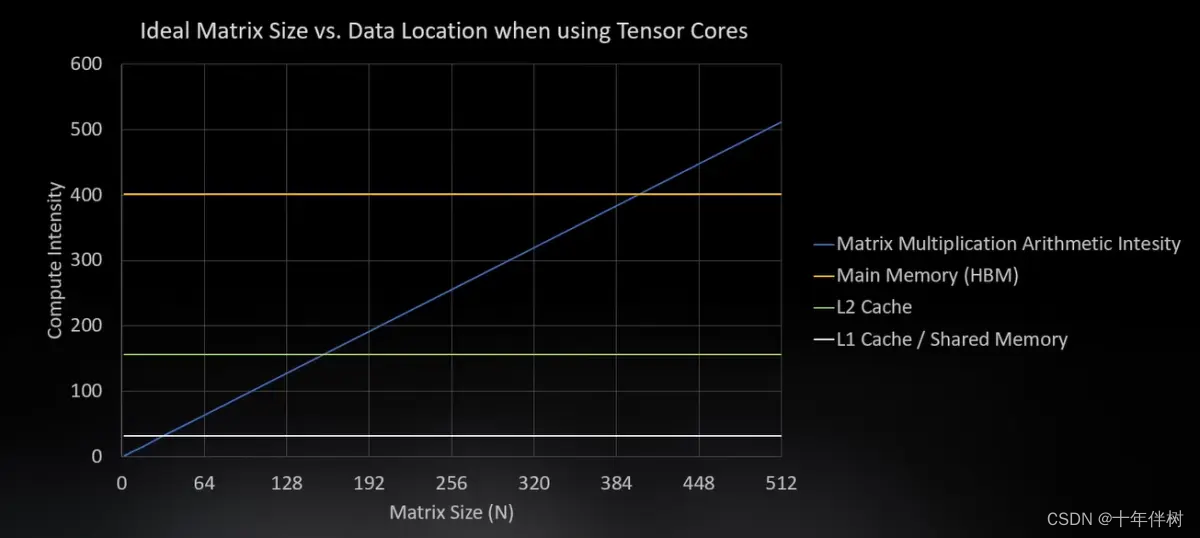
当数据存在L1,可以计算32*32,当数据存在L2可以计算大一些,当数据存在HBM,就会达到400。计算小矩阵更高效。
reference
[1] NVIDIA 2021 GPU工作原理
相关文章:
GPU的工作原理
location: Beijing 1. why is GPU CPU的存储单元和计算单元的互通过慢直接促进了GPU的发展 先介绍一个概念:FLOPS(Floating Point Operations Per Second,浮点运算每秒)是一个衡量其执行浮点运算的能力,可以作为计算…...
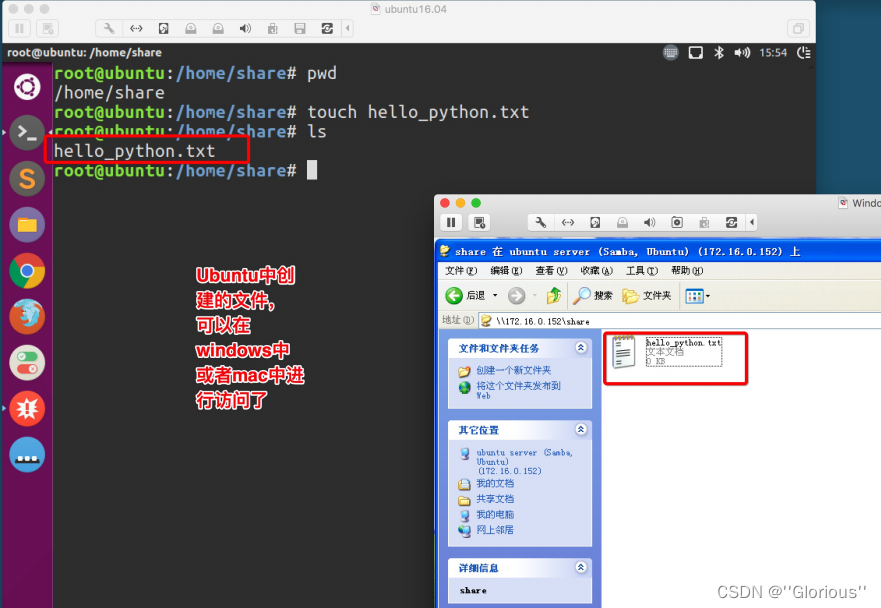
Linux常⽤服务器构建-samba
目录 1. 介绍 2. 安装 3. 配置 3.1 创建存放共享⽂件的路径 3.2 创建samba账户 4 重启samba 5. 访问共享⽂件 5.1 mac下访问⽅式 5.2 windows下访问⽅式 1. 介绍 Samba 是在 Linux 和 UNIX 系统上实现 SMB 协议的⼀个免费软件,能够完成在 windows 、 mac 操作系统…...

【Java】已解决java.lang.UnsupportedOperationException异常
文章目录 问题背景可能出错的原因错误代码示例正确代码示例注意事项 已解决java.lang.UnsupportedOperationException异常 在Java编程中,java.lang.UnsupportedOperationException是一个运行时异常,通常表示尝试执行一个不支持的操作。这种异常经常发生…...
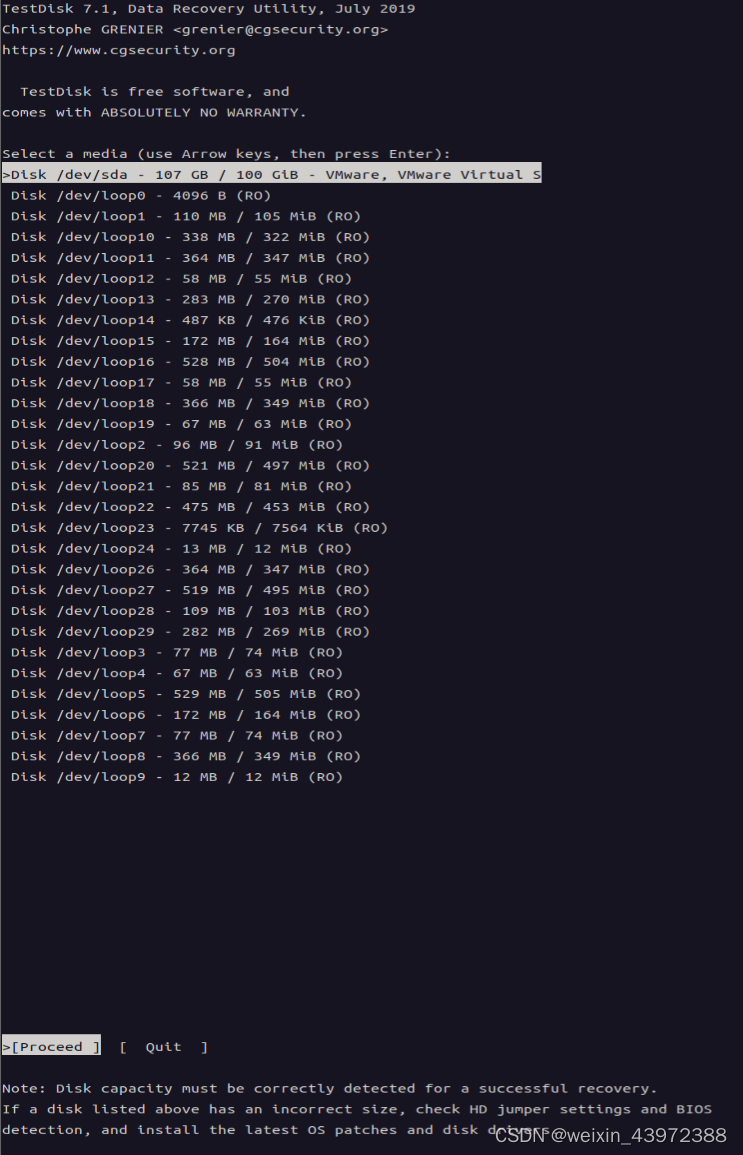
在ubuntu中恢复误删除的文件
1、安装 TestDisk 在 Ubuntu 上,可以使用以下命令安装 TestDisk: sudo apt-get install testdisk2、查询你删除的文件所在那个分区 #查询分区 df -h #我这里是/dev/sda2 #也可以使用下面命令查看具体哪个分区 lsblk3、查询该分区是什么系统类型 sudo …...
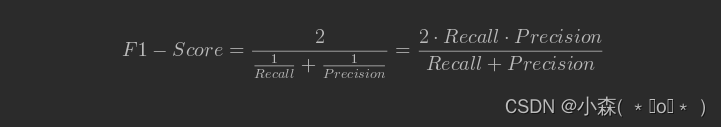
Sklearn中逻辑回归建模
分类模型的评估 回归模型的评估方法,主要有均方误差MSE,R方得分等指标,在分类模型中,我们主要应用的是准确率这个评估指标,除此之外,常用的二分类模型的模型评估指标还有召回率(Recallÿ…...

【ARM】MDK出现报错error: A\L3903U的解决方法
【更多软件使用问题请点击亿道电子官方网站】 1、 文档目标 解决MDK出现报错error: A\L3903U这样类型的报错 2、 问题场景 电脑或者软件因为意外情况导致崩溃,无法正常关闭,强制电脑重启之后,打开工程去编译出现下面的报错信息(…...

0018__字体的kerning是什么意思
泰山OFFICE技术讲座:字体的kerning是什么意思-CSDN博客 了解CSS属性font-kerning,font-smoothing,font-variant-CSDN博客...
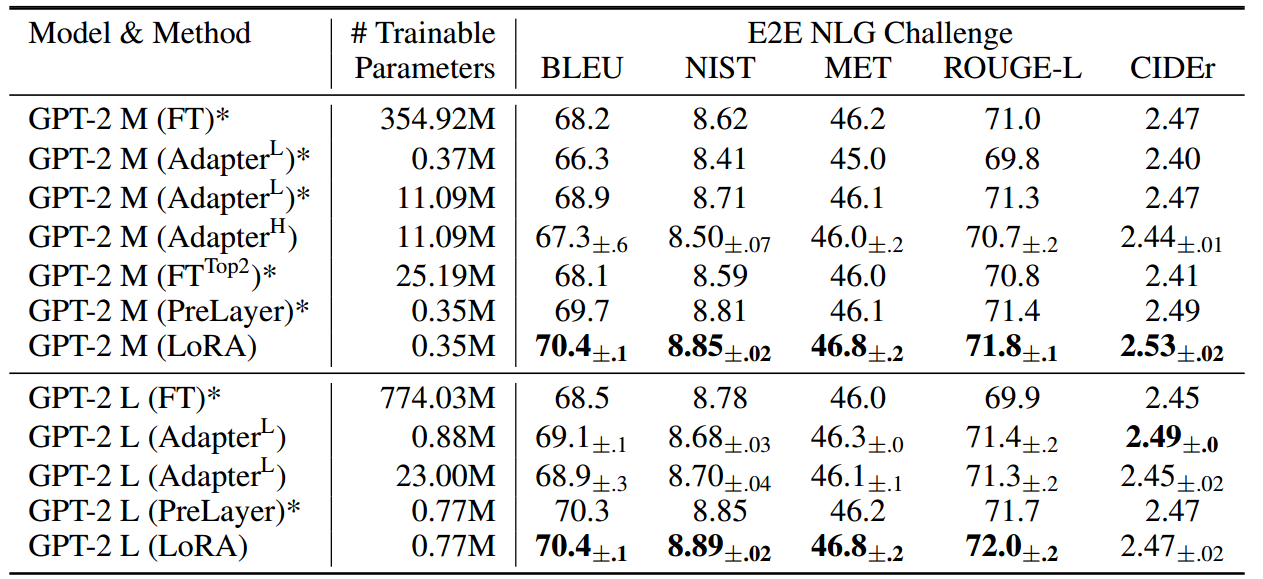
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
文章汇总 总体来看像是一种带权重的残差,但解决的如何高效问题的事情。 相比模型的全微调,作者提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。 模型架构 h W 0 x △…...

cmake、make、makefile、ninga的关系
CMake是一种跨平台的构建系统,它用来管理软件的编译过程。CMake可以生成本地平台特定的构建文件,例如Makefile或者Microsoft Visual Studio项目文件,以便开发人员更轻松地在不同的平台上构建他们的项目。它的主要功能是配置和生成构建脚本&am…...
StarRocks详解
什么是StarRocks? StarRocks是新一代极速全场景MPP数据库(高并发数据库)。 StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果。 1.可以在Spark和Flink里面处理数据,然后将处理完的数据写到StarRo…...

【C语言】进程间通信之管道pipe
进程间通信之管道pipe 一、进程间通信管道pipe()管道的读写行为 最后 一、进程间通信 管道pipe() 管道pipe也称为匿名管道,只有在有血缘关系的进程间进行通信。管道的本质就是一块内核缓冲区。 进程间通过管道的一端写,通过管道的另一端读。管道的读端…...
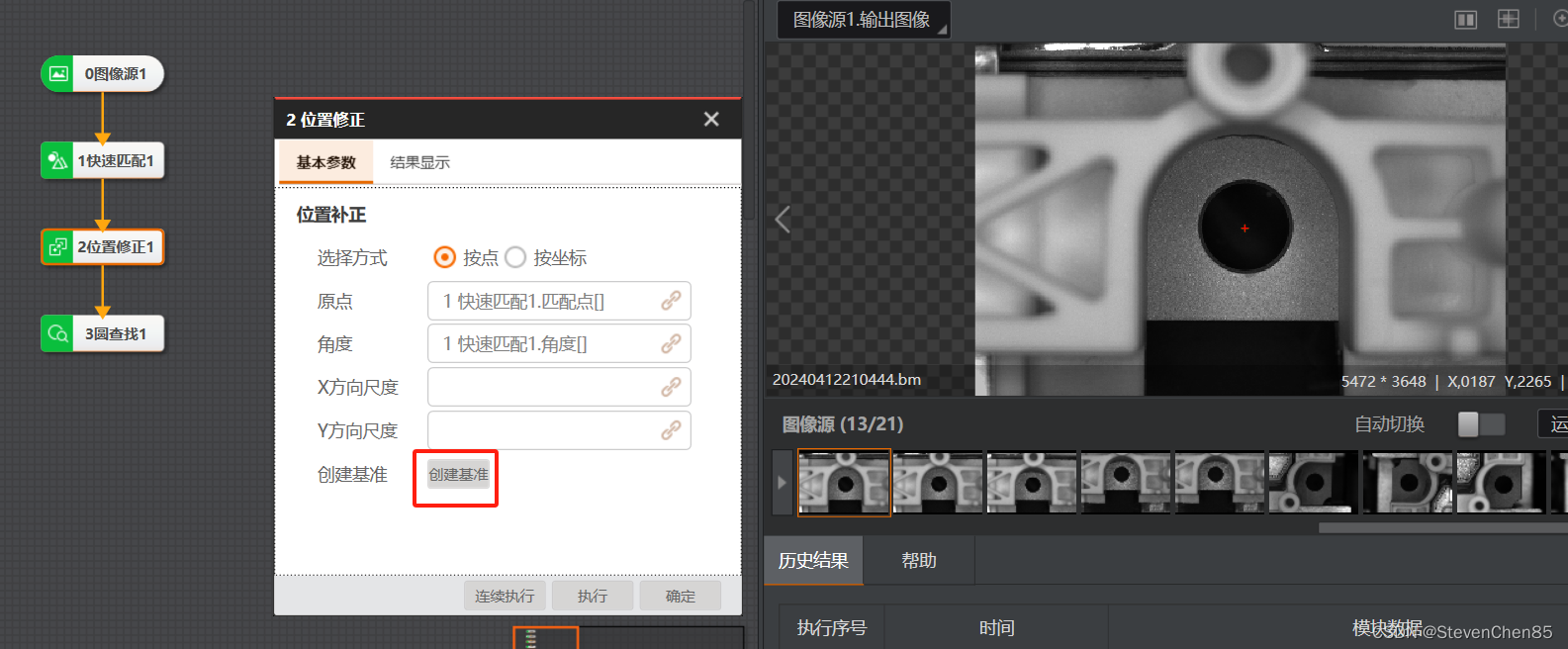
03.VisionMaster 机器视觉 位置修正 工具
VisionMaster 机器视觉 位置修正 工具 官方解释:位置修正是一个辅助定位、修正目标运动偏移、辅助精准定位的工具。可以根据模板匹配结果中的匹配点和匹配框角度建立位置偏移的基准,然后再根据特征匹配结果中的运行点和基准点的相对位置偏移实现ROI检测…...

Oracle 是否扼杀了开源 MySQL
Oracle 是否无意中扼杀了开源 MySQL Peter Zaitsev是一位俄罗斯软件工程师和企业家,曾在MySQL公司担任性能工程师。大约15年前,当甲骨文收购Sun公司并随后收购MySQL时,有很多关于甲骨文何时“杀死MySQL”的讨论。他曾为甲骨文进行辩护&#…...
机器学习归一化特征编码
特征缩放 因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度…...

抛光粉尘可爆性检测 打磨粉尘喷砂粉尘爆炸下限测试
抛光粉尘可爆性检测 抛光粉尘的可爆性检测是一种安全性能测试,用于确定加工过程中产生的粉尘在特定条件下是否会爆炸,从而对生产安全构成威胁。如果粉尘具有可爆性,那么在生产环境中就需要采取相应的防爆措施。粉尘爆炸的条件通常包括粉尘本身…...

python14 字典类型
字典类型 键值对方式,可变数据类型,所以有增删改功能 声明方式1 {} 大括号,示例 d {key1 : value1, key2 : value2, key3 : value3 ....} 声明方式2 使用内置函数 dict() 创建1)通过映射函数创建字典zip(list1,list2) 继承了序列的所有操作 …...

深入了解 .url文件中的 Prop3属性
在使用 Windows 操作系统时,我们经常会遇到以 .url 结尾的文件,它们通常被用来快速访问互联网上的特定网页。这些文件虽然看起来简单,但其中包含的 Prop3 属性却有其特殊的作用和意义。 1. Prop3 是什么? 在 .url 文件中&#x…...

vue3+vite:动态引入静态图片资源
目录 第一章 前言 第二章 vue2与vue3动态引入静态图片资源 2.1 vue2 webpack动态引入静态图片资源 2.1.1 了解 2.1.2 vue2项目动态引入静态图片资源 2.2 vue3 vite动态引入静态图片资源 2.2.1 了解 2.2.2 require vs import了解 2.2.3 vue3vite 项目动态引入静态图片…...

【K8s】专题五(3):Kubernetes 配置之 ConfigMap 与 Secret 异同
以下内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发!欢迎扫码关注个人公众号! 目录 一、相同点 二、不同点 一、相同点 功能作用:ConfigMap 与 Secret 都用于存储…...
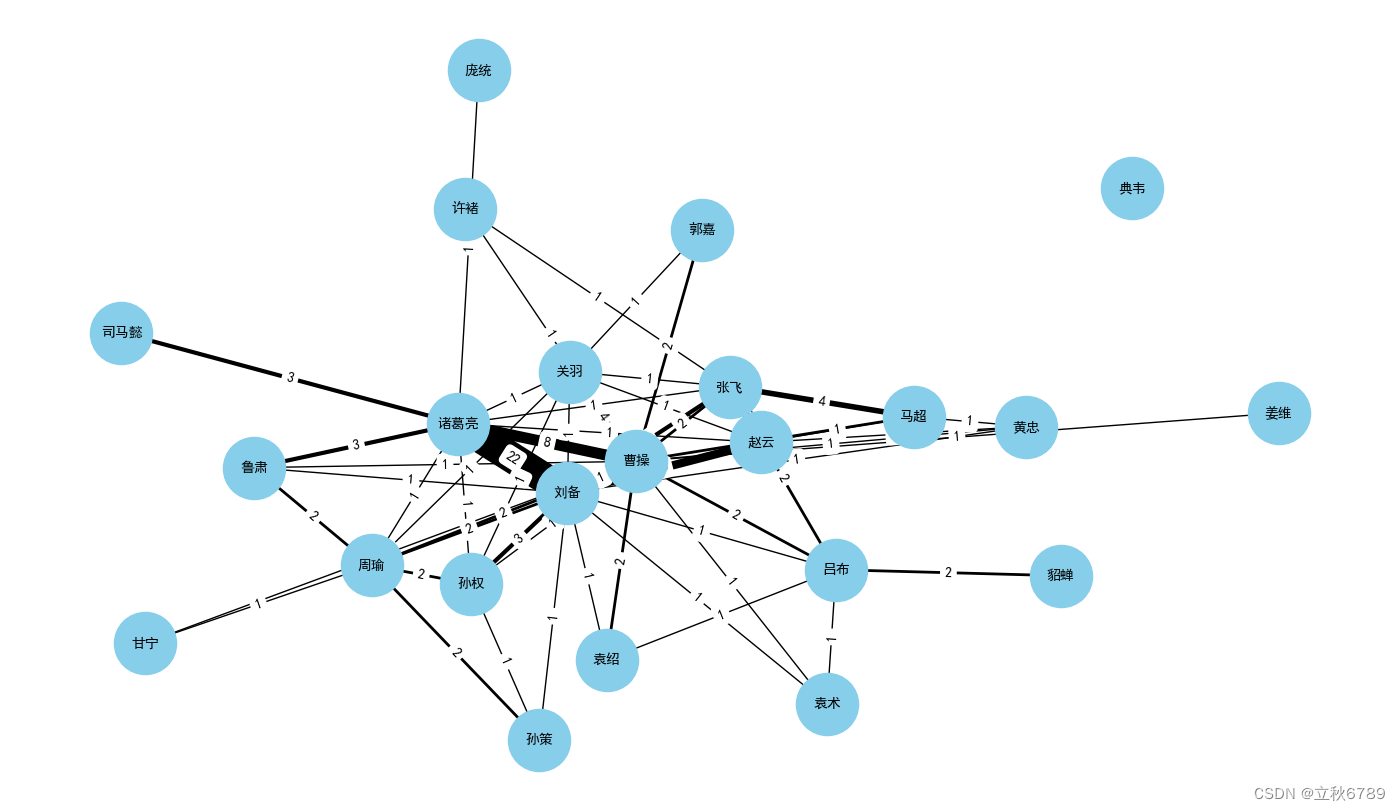
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...

Mali-400 MP OpenGL ES DDK核心问题与解决方案
## 1. Mali-400 MP OpenGL ES DDK核心问题解析作为ARM经典的移动GPU架构,Mali-400 MP在Symbian平台的OpenGL ES驱动开发套件(DDK)中存在三类典型问题。这些问题的根源往往涉及GPU硬件特性与图形API规范的微妙交互,开发者需要深入理解其底层机制才能有效规…...

阵列天线方向图综合算法与应用【附代码】
✨ 长期致力于方向图综合算法、交替投影迭代、交替方向乘子法、子阵方向图综合、相控阵系统、软件设计研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...

Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生
Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下的PL2303串口设备无法正…...

从零到一:OWASP ZAP实战渗透测试全流程解析
1. OWASP ZAP入门:渗透测试的瑞士军刀 第一次接触OWASP ZAP时,我完全被它复杂的界面吓到了。但用了三个月后,我发现这简直是Web安全测试的"瑞士军刀"——功能强大但需要正确打开方式。简单来说,ZAP就是个会自动帮你找网…...

Fawkes踩过的坑以及如何解决非常详细
首先我是用anaconda创建的一个虚拟环境 fawkes_env后续的所有操作都是在该环境中实现 不使用anaconda 可直接看第一步 坑:直接用 conda create -n fawkes python3.9 后,pip install -e . 可能因为 TensorFlow 版本过新导致不兼容(Keras 2.3…...
)
【紧急更新】Google官方刚推送的Veo 2 v2.3.1补丁深度解析:新增胶片扫描模拟、物理光晕建模与导演模式(Director Mode)
更多请点击: https://intelliparadigm.com 第一章:Google Veo 2 v2.3.1补丁核心特性概览 Google Veo 2 v2.3.1 补丁是面向视频生成模型推理优化与安全增强的关键更新,聚焦于低延迟部署、多模态对齐稳定性及合规性强化。该版本并非架构重构&a…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

3分钟快速上手:开源AIOps告警管理平台keep终极实战指南
3分钟快速上手:开源AIOps告警管理平台keep终极实战指南 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep 你是否曾经被海量的监控告警淹没,在Prometheus、Gr…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...