CSDN 自动上传图片并优化Markdown的图片显示
文章目录
- 完整代码
- 一、上传资源
- 二、替换 MD 中的引用文件为在线链接
- 参考
完整代码
完整代码由两个文件组成,upload.py 和 main.py,放在同一目录下运行 main.py 就好!
# upload.py
import requests class UploadPic: def __init__(self, cookie): self.cookie = cookie # 解析 self.file_path = '' self.img_type = '' # 两个请求体 self.upload_data = {} self.csdn_data = {} self.output_url = '' def _get_file(self, file_path): with open(file_path, mode='rb') as f: binary_data = f.read() return binary_data def _upload_request(self): headers = { 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'content-type': 'application/json', 'cookie': self.cookie, 'origin': 'https://editor.csdn.net', 'priority': 'u=1, i', 'referer': 'https://editor.csdn.net/', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', } params = { 'type': 'blog', 'rtype': 'markdown', 'x-image-template': '', 'x-image-app': 'direct_blog', 'x-image-dir': 'direct', 'x-image-suffix': self.img_type, } url = 'https://imgservice.csdn.net/direct/v1.0/image/upload' response = requests.get(url, params=params, headers=headers) try: self.upload_data = response.json() except Exception as e: return e def _csdn_request(self): headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Origin': 'https://editor.csdn.net', 'Referer': 'https://editor.csdn.net/', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'cross-site', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } files = { 'key': (None, self.upload_data['data']['filePath']), 'policy': (None, self.upload_data['data']['policy']), 'OSSAccessKeyId': (None, self.upload_data['data']['accessId']), 'success_action_status': (None, '200'), 'signature': (None, self.upload_data['data']['signature']), 'callback': (None, self.upload_data['data']['callbackUrl']), 'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'), } url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/' response = requests.post(url, headers=headers, files=files) try: self.csdn_data = response.json() self.output_url = self.csdn_data['data']['imageUrl'] except Exception as e: return e def upload_image(self, file_path): self.file_path = file_path self.img_type = self.file_path.split('.')[-1] exception_1 = self._upload_request() assert exception_1 is None, exception_1 exception_2 = self._csdn_request() assert exception_2 is None, exception_2 return self.output_url if __name__ == '__main__': cookie = '' # 输入你的cookie upload = UploadPic(cookie) output_url = upload.upload_image('') #输入你需要上传的文件位置print(output_url)
# main.py
import os
import re
from pathlib import Path
from rich.progress import track
from upload import UploadPic class CSDNTransform: def __init__(self, upload:UploadPic, file_path, walk_path='C:/Users/Administrator/Documents/Obsidian Vault/'): self.upload = upload self.file_path = file_path self.walk_path = walk_path self.markdown_text = '' self.image_lst = [] self.posterior_image_lst = [] self.image_2_url_dic = {} def _get_markdown_text(self): with open(self.file_path, mode='r', encoding='utf-8') as f: markdown_text = f.read() self.markdown_text = markdown_text def _process_markdown_text(self): image_lst = re.findall(r'(!\[\[.*]])', self.markdown_text) posterior_image_lst = [item[3:-2] for item in image_lst] self.image_lst = image_lst self.posterior_image_lst = posterior_image_lst def _get_target_image_path(self, target_path): for root, floders, files in os.walk(self.walk_path): for file in files: if file == target_path: return str(Path(root) / file) def _get_the_url_of_image(self, image_path): image_url = self.upload.upload_image(image_path) return image_url def get_the_urls(self): self._get_markdown_text() self._process_markdown_text() not_exist_image_index = [] for ix, (origin_image, target_path) in track(enumerate(zip(self.image_lst, self.posterior_image_lst))): image_path = self._get_target_image_path(target_path) if image_path is not None: image_url = self._get_the_url_of_image(image_path) self.image_2_url_dic[origin_image] = image_url else: not_exist_image_index.append(ix) # 清楚掉需要删除的index num = 0 for ix in not_exist_image_index: del self.image_lst[ix-num] del self.posterior_image_lst[ix-num] num += 1 def _the_transform_data_from(self, image_url): data_form = f"""\n<div align=center><img src="{image_url}"></div>\n""" return data_form def _save_markdown_text(self, output_file='markdown_processed.txt'): with open(output_file, mode='w', encoding='utf-8') as f: f.write(self.markdown_text) def get_transform(self): self.get_the_urls() # Judge the length assert len(self.image_lst) == len(self.image_2_url_dic), f"上传成功{len(self.image_2_url_dic)}张图片,总共有{len(self.image_lst)}张图片" for origin_image, image_url in self.image_2_url_dic.items(): self.markdown_text = self.markdown_text.replace(origin_image, self._the_transform_data_from(image_url)) self._save_markdown_text()if __name__ == '__main__': cookie = '' # 输入你的cookiefile_path = '' # 输入你要转换的markdown文件地址upload = UploadPic(cookie) transform = CSDNTransform(upload, file_path) markdown_text = transform.get_transform()# 修改后的 Markdown 在当前目录的 markdown_processed.txt 文件中
一、上传资源
首先我们解析 CSDN 上传请求,这里随便上传一张图片,观察请求;

请求由三部分组成,分别是:1. 获取存储位置和签名验证信息;2. 利用签名等验证信息上传文件;3. 获取文件信息并显示;
仔细观察两个请求,upload 请求是 GET ,csdn 请求是 POST,其结果很明显 csdn 请求是主体,仔细观察 csdn 的参数,可以所有参数都可以利用 upload 的返回结果得到;
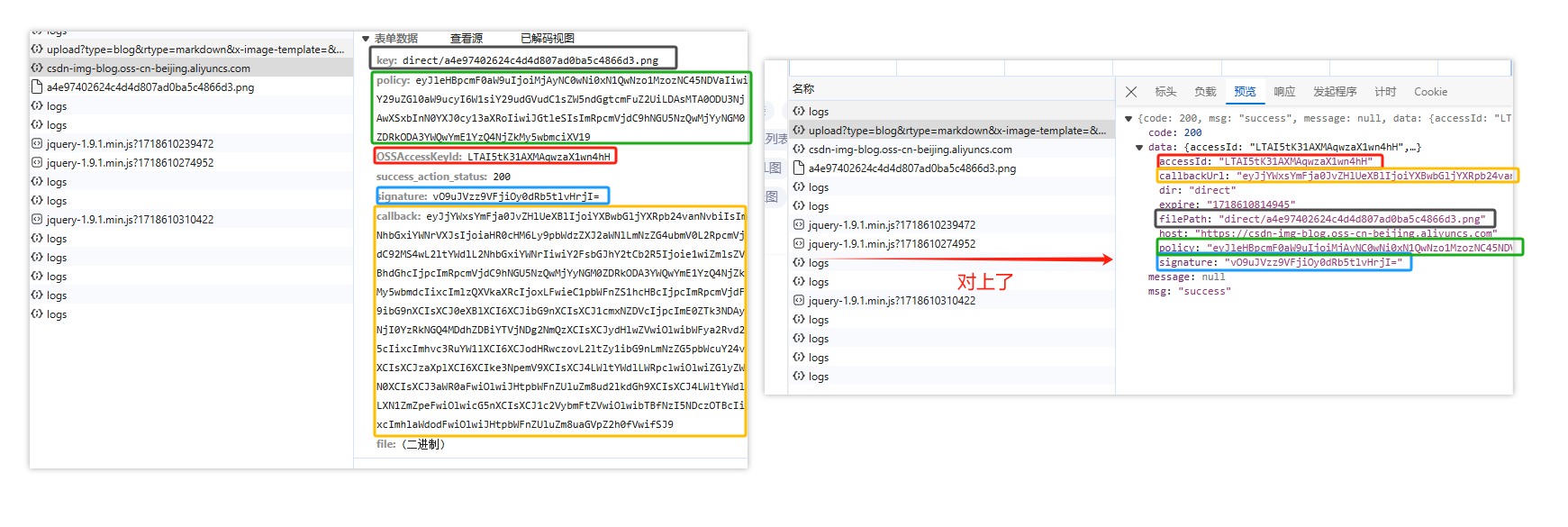
那么接下来我们开始构造 upload 请求
import requestsheaders = {'accept': '*/*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','content-type': 'application/json','cookie': '', # 输入自己的cookies'origin': 'https://editor.csdn.net','priority': 'u=1, i','referer': 'https://editor.csdn.net/','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-site','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
}params = {'type': 'blog','rtype': 'markdown','x-image-template': '','x-image-app': 'direct_blog','x-image-dir': 'direct','x-image-suffix': 'png',
}url = 'https://imgservice.csdn.net/direct/v1.0/image/upload'
response = requests.get(url, params=params, headers=headers)# 获得数据
upload_data = response.json()
得到 json 内容如下,通过比较该内容下 expire 和 time 库下的 time.time() * 1000,再根据英文名可以推断,expire 表示的是上传文件这一请求的失效时间,即 csdn 请求的最晚成功时间;
{'code': 200,'data': {'accessId': 'LTAI5tK31AXMAqwzaX1wn4hH','callbackUrl': 'eyJjYWxsYmFja0JvZHlUeXBlIjoiYXBwbGljYXRpb24vanNvbiIsImNhbGxiYWNrVXJsIjoiaHR0cHM6Ly9pbWdzZXJ2aWNlLmNzZG4ubmV0L2RpcmVjdC92MS4wL2ltYWdlL2NhbGxiYWNrIiwiY2FsbGJhY2tCb2R5Ijoie1wiZmlsZVBhdGhcIjpcImRpcmVjdC9jN2VlYWNjZjU2ZDM0MzM3OWQ2Yjk4ZmYwNGYyZWFjNS5wbmdcIixcImlzQXVkaXRcIjoxLFwieC1pbWFnZS1hcHBcIjpcImRpcmVjdF9ibG9nXCIsXCJ0eXBlXCI6XCJibG9nXCIsXCJ1cmxNZDVcIjpcImM3ZWVhY2NmNTZkMzQzMzc5ZDZiOThmZjA0ZjJlYWM1XCIsXCJydHlwZVwiOlwibWFya2Rvd25cIixcImhvc3RuYW1lXCI6XCJodHRwczovL2ltZy1ibG9nLmNzZG5pbWcuY24vXCIsXCJzaXplXCI6XCIke3NpemV9XCIsXCJ4LWltYWdlLWRpclwiOlwiZGlyZWN0XCIsXCJ3aWR0aFwiOlwiJHtpbWFnZUluZm8ud2lkdGh9XCIsXCJ4LWltYWdlLXN1ZmZpeFwiOlwicG5nXCIsXCJ1c2VybmFtZVwiOlwibTBfNzI5NDczOTBcIixcImhlaWdodFwiOlwiJHtpbWFnZUluZm8uaGVpZ2h0fVwifSJ9','dir': 'direct','expire': '1718611892700','filePath': 'direct/c7eeaccf56d343379d6b98ff04f2eac5.png','host': 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com','policy': 'eyJleHBpcmF0aW9uIjoiMjAyNC0wNi0xN1QwODoxMTozMi43MDBaIiwiY29uZGl0aW9ucyI6W1siY29udGVudC1sZW5ndGgtcmFuZ2UiLDAsMTA0ODU3NjAwXSxbInN0YXJ0cy13aXRoIiwiJGtleSIsImRpcmVjdC9jN2VlYWNjZjU2ZDM0MzM3OWQ2Yjk4ZmYwNGYyZWFjNS5wbmciXV19','signature': '2hRKp5YO3epBJe5+Qt7Ngi7P/y4='},'message': None,'msg': 'success'}
下面利用 upload 得到的请求来构造 csdn 请求;
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoderdef get_file(file_path):"""获取文件的二进制数据"""with open(file_path, mode='rb') as f:binary_data = f.read()return binary_dataheaders = {'Accept': 'application/json, text/javascript, */*; q=0.01','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Connection': 'keep-alive','Origin': 'https://editor.csdn.net','Referer': 'https://editor.csdn.net/','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'cross-site','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0','sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}success_action_status = '200'# upload 请求中获取到的数据
key = upload_data['data']['filePath']
policy = upload_data['data']['policy']
OSSAccessKeyId = upload_data['data']['accessId']
signature = upload_data['data']['signature']
callback = upload_data['data']['callbackUrl']# 上传的图片位置,
file = get_file('') # 输入需要上传文件的位置files = {'key': (None, key),'policy': (None, policy),'OSSAccessKeyId': (None, OSSAccessKeyId),'success_action_status': (None, '200'),'signature': (None, signature),'callback': (None, callback),'file': ('image.png', file, 'image/png'),
}url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/'
response = requests.post(url, headers=headers, files=files)print(response.text)
得到 Json 数据如下
{'code': 200,'data': {'hostname': 'https://img-blog.csdnimg.cn/','imageUrl': 'https://img-blog.csdnimg.cn/direct/97c5610606c140afb474800403140ea3.png','width': '1138','targetObjectKey': 'direct/97c5610606c140afb474800403140ea3.png','x-image-suffix': 'png','height': '239'},'msg': 'success'}
在其中 imageUrl 就表示上传的图片地址,同时,图片格式有许多种,面对不同的图片格式,在尝试观察后发现只需要修改 upload 请求中 parms 中的 x-image-suffix,csdn 请求中 files 中的 file;
整合得到完整上传类如下:
import requests class UploadPic: def __init__(self, cookie): self.cookie = cookie # 解析 self.file_path = '' self.img_type = '' # 两个请求体 self.upload_data = {} self.csdn_data = {} self.output_url = '' def _get_file(self, file_path): with open(file_path, mode='rb') as f: binary_data = f.read() return binary_data def _upload_request(self): headers = { 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'content-type': 'application/json', 'cookie': self.cookie, 'origin': 'https://editor.csdn.net', 'priority': 'u=1, i', 'referer': 'https://editor.csdn.net/', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', } params = { 'type': 'blog', 'rtype': 'markdown', 'x-image-template': '', 'x-image-app': 'direct_blog', 'x-image-dir': 'direct', 'x-image-suffix': self.img_type, } url = 'https://imgservice.csdn.net/direct/v1.0/image/upload' response = requests.get(url, params=params, headers=headers) try: self.upload_data = response.json() except Exception as e: return e def _csdn_request(self): headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Origin': 'https://editor.csdn.net', 'Referer': 'https://editor.csdn.net/', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'cross-site', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } files = { 'key': (None, self.upload_data['data']['filePath']), 'policy': (None, self.upload_data['data']['policy']), 'OSSAccessKeyId': (None, self.upload_data['data']['accessId']), 'success_action_status': (None, '200'), 'signature': (None, self.upload_data['data']['signature']), 'callback': (None, self.upload_data['data']['callbackUrl']), 'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'), } url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/' response = requests.post(url, headers=headers, files=files) try: self.csdn_data = response.json() self.output_url = self.csdn_data['data']['imageUrl'] except Exception as e: return e def upload_image(self, file_path): self.file_path = file_path self.img_type = self.file_path.split('.')[-1] exception_1 = self._upload_request() assert exception_1 is None, exception_1 exception_2 = self._csdn_request() assert exception_2 is None, exception_2 return self.output_url if __name__ == '__main__': cookie = '' # 输入你的cookie upload = UploadPic(cookie) output_url = upload.upload_image('') #输入你需要上传的文件位置print(output_url)
二、替换 MD 中的引用文件为在线链接
首先,肯定是整体替换而不是单个替换,因此我们的流程为:1. 上传所有文件,直到所有的文件都上传成功;2. 替换所有文件;
首先提取出 Markdown 中所有的图片信息,一般来说图片信息都在两个中括号之间 ![[ img_pic ]],使用 re 正则提取,代码如下;
import refile_path = 'C:/Users/Administrator/Documents/Obsidian Vault/UE开发/My FirstGame Tutorial.md'with open(file_path, mode='r', encoding='utf-8') as f:markdown_text = f.read()image_lst = re.findall(r'(!\[\[.*\]\])', markdown_text)
posterior_image_lst = [item[3:-2] for item in image_lst]
提取出所有的 img_pic 后,我们需要在根目录下寻找文件,一般来说在 Markdown 中文件名是不重复的;
import os
from pathlib import Pathdef get_target_image_path(target_path):walk_path = 'C:/Users/Administrator/Documents/Obsidian Vault/'for root, floders, files in os.walk(walk_path):for file in files:if file == target_path:return Path(root) / fileget_target_image_path(posterior_image_lst[0])
获取到了绝对位置后,我们可以将图片上传,在检查图片全部都上传完毕后,我们就可以替换 ![[ img_pic ]]
import os
import re
import requests
from pathlib import Path
from rich.progress import track class UploadPic: def __init__(self, cookie): self.cookie = cookie # 解析 self.file_path = '' self.img_type = '' # 两个请求体 self.upload_data = {} self.csdn_data = {} self.output_url = '' def _get_file(self, file_path): with open(file_path, mode='rb') as f: binary_data = f.read() return binary_data def _upload_request(self): headers = { 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'content-type': 'application/json', 'cookie': self.cookie, 'origin': 'https://editor.csdn.net', 'priority': 'u=1, i', 'referer': 'https://editor.csdn.net/', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', } params = { 'type': 'blog', 'rtype': 'markdown', 'x-image-template': '', 'x-image-app': 'direct_blog', 'x-image-dir': 'direct', 'x-image-suffix': self.img_type, } url = 'https://imgservice.csdn.net/direct/v1.0/image/upload' response = requests.get(url, params=params, headers=headers) try: self.upload_data = response.json() except Exception as e: return e def _csdn_request(self): headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Origin': 'https://editor.csdn.net', 'Referer': 'https://editor.csdn.net/', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'cross-site', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } files = { 'key': (None, self.upload_data['data']['filePath']), 'policy': (None, self.upload_data['data']['policy']), 'OSSAccessKeyId': (None, self.upload_data['data']['accessId']), 'success_action_status': (None, '200'), 'signature': (None, self.upload_data['data']['signature']), 'callback': (None, self.upload_data['data']['callbackUrl']), 'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'), } url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/' response = requests.post(url, headers=headers, files=files) try: self.csdn_data = response.json() self.output_url = self.csdn_data['data']['imageUrl'] except Exception as e: return e def upload_image(self, file_path): self.file_path = file_path self.img_type = self.file_path.split('.')[-1] exception_1 = self._upload_request() assert exception_1 is None, exception_1 exception_2 = self._csdn_request() assert exception_2 is None, exception_2 return self.output_url class CSDNTransform: def __init__(self, upload:UploadPic, file_path, walk_path='C:/Users/Administrator/Documents/Obsidian Vault/'): self.upload = upload self.file_path = file_path self.walk_path = walk_path self.markdown_text = '' self.image_lst = [] self.posterior_image_lst = [] self.image_2_url_dic = {} def _get_markdown_text(self): with open(self.file_path, mode='r', encoding='utf-8') as f: markdown_text = f.read() self.markdown_text = markdown_text def _process_markdown_text(self): image_lst = re.findall(r'(!\[\[.*]])', self.markdown_text) posterior_image_lst = [item[3:-2] for item in image_lst] self.image_lst = image_lst self.posterior_image_lst = posterior_image_lst def _get_target_image_path(self, target_path): for root, floders, files in os.walk(self.walk_path): for file in files: if file == target_path: return str(Path(root) / file) def _get_the_url_of_image(self, image_path): image_url = self.upload.upload_image(image_path) return image_url def get_the_urls(self): self._get_markdown_text() self._process_markdown_text() not_exist_image_index = [] for ix, (origin_image, target_path) in track(enumerate(zip(self.image_lst, self.posterior_image_lst))): image_path = self._get_target_image_path(target_path) if image_path is not None: image_url = self._get_the_url_of_image(image_path) self.image_2_url_dic[origin_image] = image_url else: not_exist_image_index.append(ix) # 清楚掉需要删除的index num = 0 for ix in not_exist_image_index: del self.image_lst[ix-num] del self.posterior_image_lst[ix-num] num += 1 def _the_transform_data_from(self, image_url): data_form = f"""\n<div align=center><img src="{image_url}"></div>\n""" return data_form def _save_markdown_text(self, output_file='markdown_processed.txt'): with open(output_file, mode='w', encoding='utf-8') as f: f.write(self.markdown_text) def get_transform(self): self.get_the_urls() # Judge the length assert len(self.image_lst) == len(self.image_2_url_dic), f"上传成功{len(self.image_2_url_dic)}张图片,总共有{len(self.image_lst)}张图片" for origin_image, image_url in self.image_2_url_dic.items(): self.markdown_text = self.markdown_text.replace(origin_image, self._the_transform_data_from(image_url)) self._save_markdown_text()if __name__ == '__main__': cookie = '' # 输入你的cookiefile_path = '' # 输入你要转换的markdown文件地址upload = UploadPic(cookie) transform = CSDNTransform(upload, file_path) markdown_text = transform.get_transform()# 修改后的 Markdown 在当前目录的 markdown_processed.txt 文件中
参考
requests库post请求参数data、json和files的使用_requests post data-CSDN博客
HTTP协议之multipart/form-data请求分析_http form-data请求-CSDN博客
相关文章:
CSDN 自动上传图片并优化Markdown的图片显示
文章目录 完整代码一、上传资源二、替换 MD 中的引用文件为在线链接参考 完整代码 完整代码由两个文件组成,upload.py 和 main.py,放在同一目录下运行 main.py 就好! # upload.py import requests class UploadPic: def __init__(self, c…...
常见日志库NLog、log4net、Serilog和Microsoft.Extensions.Logging介绍和区别
在C#中,日志库的选择主要取决于项目的具体需求,包括性能、易用性、可扩展性等因素。以下是关于NLog、log4net、Serilog和Microsoft.Extensions.Logging的基本介绍和使用示例。 包含如何配置输出日志到当前目录下的log.txt文件及控制台的示例,…...

【PX4-AutoPilot教程-TIPS】离线安装Flight Review PX4日志分析工具
离线安装Flight Review PX4日志分析工具 安装方法 安装方法 使用Flight Review在线分析日志,有时会因为网络原因无法使用。 使用离线安装的方式使用Flight Review,可以在无需网络的情况下使用Flight Review网页。 安装环境依赖。 sudo apt-get insta…...

探究Spring Boot自动配置的底层原理
在当今的软件开发领域,Spring Boot已经成为了构建Java应用程序的首选框架之一。它以其简单易用的特性和强大的功能而闻名,其中最引人注目的特性之一就是自动配置(Auto-Configuration)。Spring Boot的自动配置能够极大地简化开发人…...
Fedora40的#!bash #!/bin/bash #!/bin/env bash #!/usr/bin/bash #!/usr/bin/env bash
bash脚本开头可写成 #!/bin/bash , #!/bin/env bash , #!/usr/bin/bash , #!/usr/bin/env bash #!/bin/bash , #!/usr/bin/bash#!/bin/env bash , #!/usr/bin/env bash Fedora40Workstation版的 /bin 是 /usr/bin 的软链接, /sbin 是 /usr/sbin 的软链接, rootfedora:~# ll …...

重生之 SpringBoot3 入门保姆级学习(19、场景整合 CentOS7 Docker 的安装)
重生之 SpringBoot3 入门保姆级学习(19、场景整合 CentOS7 Docker 的安装) 6、场景整合6.1 Docker 6、场景整合 6.1 Docker 官网 https://docs.docker.com/查看自己的 CentOS配置 cat /etc/os-releaseStep 1: 安装必要的一些系统工具 sudo yum insta…...
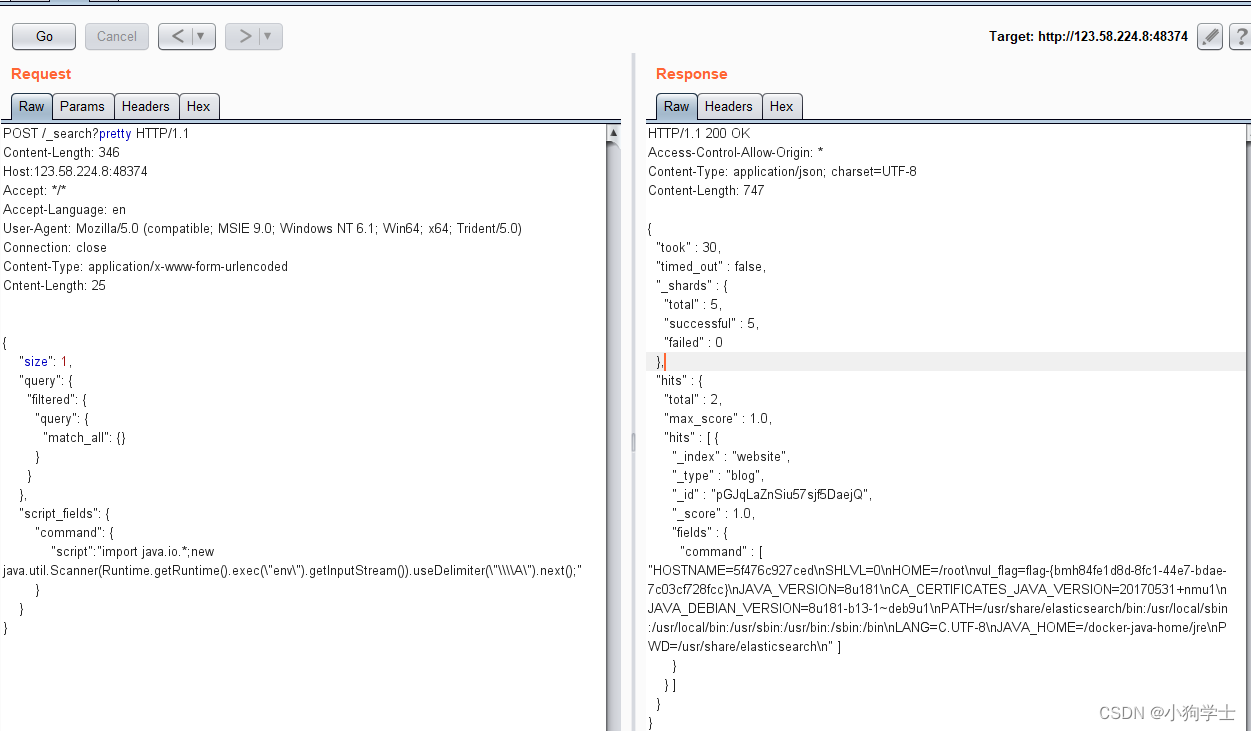
cve_2014_3120-Elasticsearch-rce-vulfocus靶场
1.背景 来源:ElasticSearch(CVE-2014-3120)命令执行漏洞复现_mvel 漏洞-CSDN博客 参考:https://www.cnblogs.com/huangxiaosan/p/14398307.html 老版本ElasticSearch支持传入动态脚本(MVEL)来执行一些复…...

吴恩达2022机器学习专项课程C2W3:2.26 机器学习发展历程
目录 开发机器学习系统的过程开发机器学习案例1.问题描述2.创建监督学习算法3.解决问题4.小结 误差分析1.概述2.误差分析解决之前的问题3.小结 增加数据1.简述2.增加数据案例一3.增加数据案例二4.添加数据的技巧5.空白创建数据6.小结 迁移学习1.简述2.为什么迁移学习有作用3.小…...

当OpenHarmony遇上OpenEuler
1、 安装openEuler 虚拟机、物理机器当然都可以安装。虚拟机又可以使用WSL、或者VMWare、VirtualBox虚拟机软件,如果需要安装最新版本,建议使用后者。当前WSL只支持OpenEuler 20.03。 1.1 WSL openEuler WSL的安装都是程序员的必备技能了,…...
Apple - Framework Programming Guide
本文翻译自:Framework Programming Guide(更新日期:2013-09-17 https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/BPFrameworks/Frameworks.html#//apple_ref/doc/uid/10000183i 文章目录 一、框架编程指南简介…...
R可视化:ggpubr包学习
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者 Xiao hong书:生信学习者 知hu:生信学习者 CDSN:生信学习者2 介绍 ggpubr是我经常会用到的R包,它傻瓜式的画图方式对很多初次接触R绘图的人来…...

优化Spring Boot项目启动时间:详解与实践
目录 引言了解Spring Boot框架启动机制常见启动瓶颈分析优化策略 禁用不必要的自动配置使用Profile进行开发和生产环境区分精简依赖延迟加载Bean并行初始化Bean缓存数据源连接优化Spring Data JPA使用Spring Boot DevTools 通过性能测试工具分析和优化实战示例:一个…...

Android如何简单快速实现RecycleView的拖动重排序功能
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 要实现这个拖动重排序功能,主要是用到了RecycleView的ItemTouchHelper类 首先是定义一个接口 interface ItemTouchHelperAdapter …...
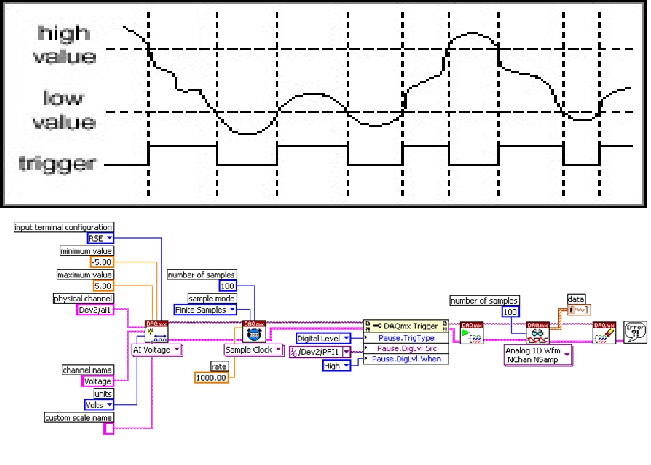
LabVIEW利用旋转编码器脉冲触发数据采集
利用旋转编码器发出的脉冲控制数据采集,可以采用硬件触发方式,以确保每个脉冲都能触发一次数据采集。本文提供了详细的解决方案,包括硬件连接、LabVIEW编程和触发设置,确保数据采集的准确性和实时性。 一、硬件连接 1. 旋转编码…...
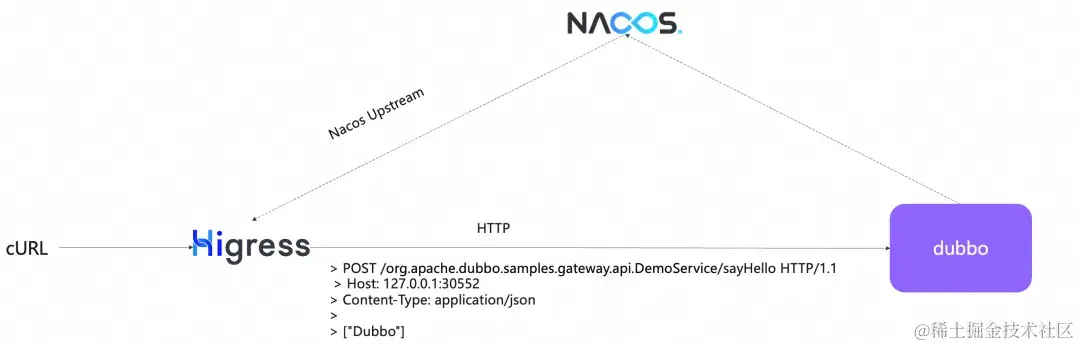
Dubbo3 服务原生支持 http 访问,兼具高性能与易用性
作者:刘军 作为一款 rpc 框架,Dubbo 的优势是后端服务的高性能的通信、面向接口的易用性,而它带来的弊端则是 rpc 接口的测试与前端流量接入成本较高,我们需要专门的工具或协议转换才能实现后端服务调用。这个现状在 Dubbo3 中得…...
我在高职教STM32——GPIO入门之蜂鸣器
大家好,我是老耿,高职青椒一枚,一直从事单片机、嵌入式、物联网等课程的教学。对于高职的学生层次,同行应该都懂的,老师在课堂上教学几乎是没什么成就感的。正因如此,才有了借助 CSDN 平台寻求认同感和成就…...
STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建
STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建 文章目录 STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建功能与作用典型工作流程 1. 硬件原理图介绍2. STM32 CubeMX工程搭建2.1 创建工程2.2 系统配置2.3 USART串口配…...

如果搜索一定超时,如何用dp来以空间换时间
E - Alphabet Tiles (atcoder.jp) 题目大意:1到k长度的字符串时,在A-Z给定数量下,搭配出多少种不同的字符串 思路 排列组合,会死人的 暴搜:可以解决,但是时间太长 dp:考虑前 i 个字母&…...

MySQL常见的命令
MySQL常见的命令 查看数据库(注意添加分号) show databases;进入到某个库 use 库; 例如:进入test use test;显示表格 show tables;直接展示某个库里面的表 show tables from 库; 例如:展示mysql中的表格 show tabl…...

11 类型泛化
11 类型泛化 1、函数模版1.1 前言1.2 函数模版1.3 隐式推断类型实参1.4 函数模板重载1.5 函数模板类型形参的默认类型(C11标准) 2、类模版2.1 类模板的成员函数延迟实例化2.2 类模板的静态成员2.3 类模板的递归实例化2.4 类模板类型形参缺省值 3、类模板…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

InsForge:基于Python的Instagram内容自动化创作与发布工具全解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫InsForge。这名字听起来有点“工业锻造”的味道,实际上,它是一个专注于Instagram内容创作与自动化的工具集。简单来说,它试图帮你解决在Instagram上创作、发布、管理内容…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...

终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率
终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中…...

Instagram视频下载终极指南:三分钟掌握免费下载技巧
Instagram视频下载终极指南:三分钟掌握免费下载技巧 【免费下载链接】instagram-video-downloader Simple website made with Next.js for downloading instagram videos with an API that can be used to integrate it in other applications. 项目地址: https:…...

AI代码管理器:统一多模型编程助手,提升开发效率与代码质量
1. 项目概述:一个面向开发者的多模型代码管理技能最近在折腾AI编程助手,发现一个挺有意思的现象:很多开发者手头可能同时用着Claude、CodeGemini这类工具,但每次切换都得重新配置环境、调整提示词,甚至要处理不同模型输…...

技能即代码:用自动化工具构建个人技能维护系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“skill-guardian”,作者是0xtresser。乍一看这个名字,可能有点摸不着头脑,但点进去研究了一下,发现这其实是一个关于“技能守护”或者说“技能管理”的…...