快排(霍尔排序实现+前后指针实现)(递归+非递归)

前言
快排是很重要的排序,也是一种比较难以理解的排序,这里我们会用递归的方式和非递归的方式来解决,递归来解决是比较简单的,非递归来解决是有点难度的
快排也称之为霍尔排序,因为发明者是霍尔,本来是命名为霍尔排序的,但是霍尔这个人对于自己创造的排序很自信,所以命名为快排
当然也是如他所料,快排确实很快,但是还没有达到第一批次那个程度
快排gif
快排实现逻辑排序
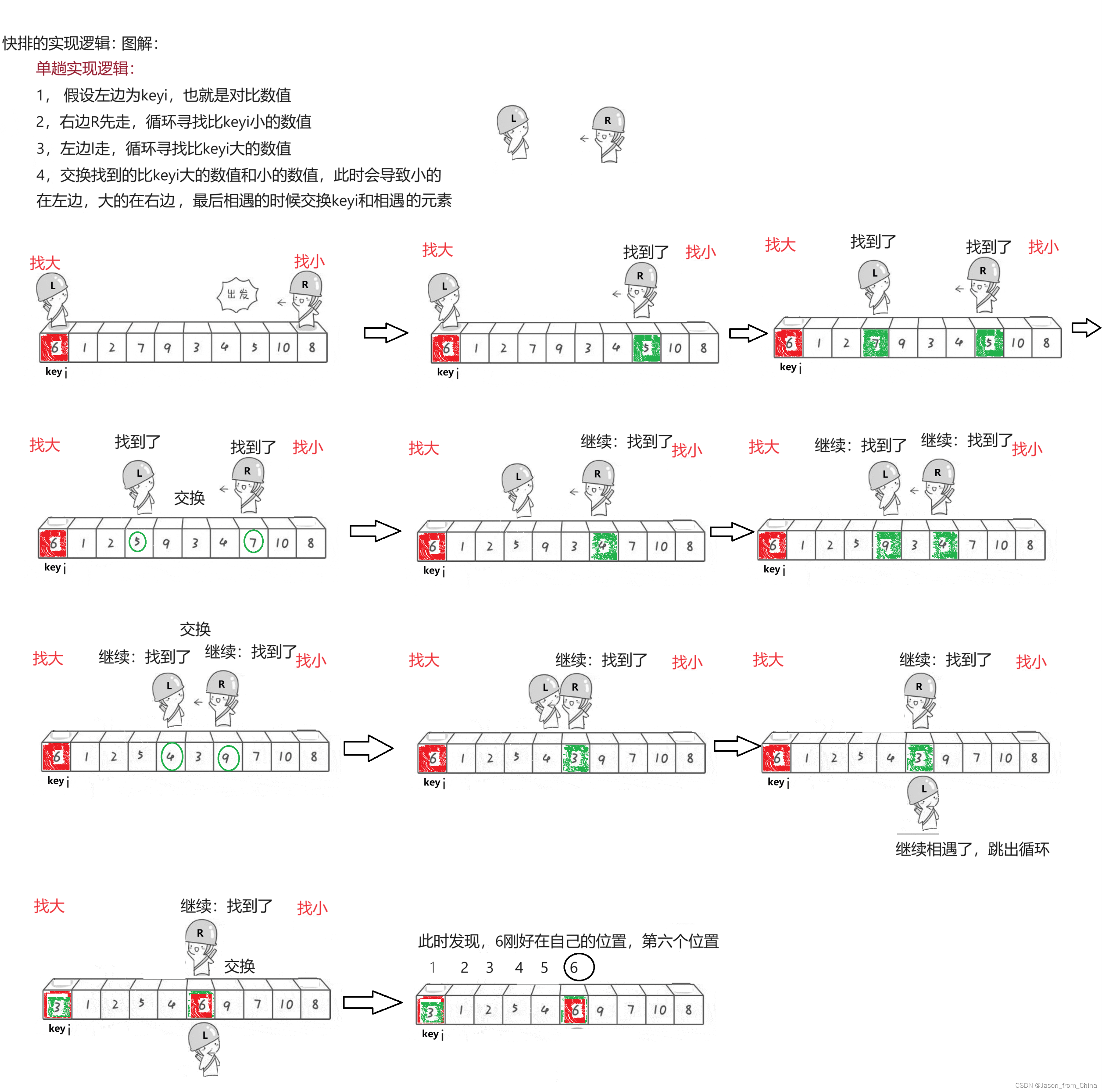
单趟实现逻辑:
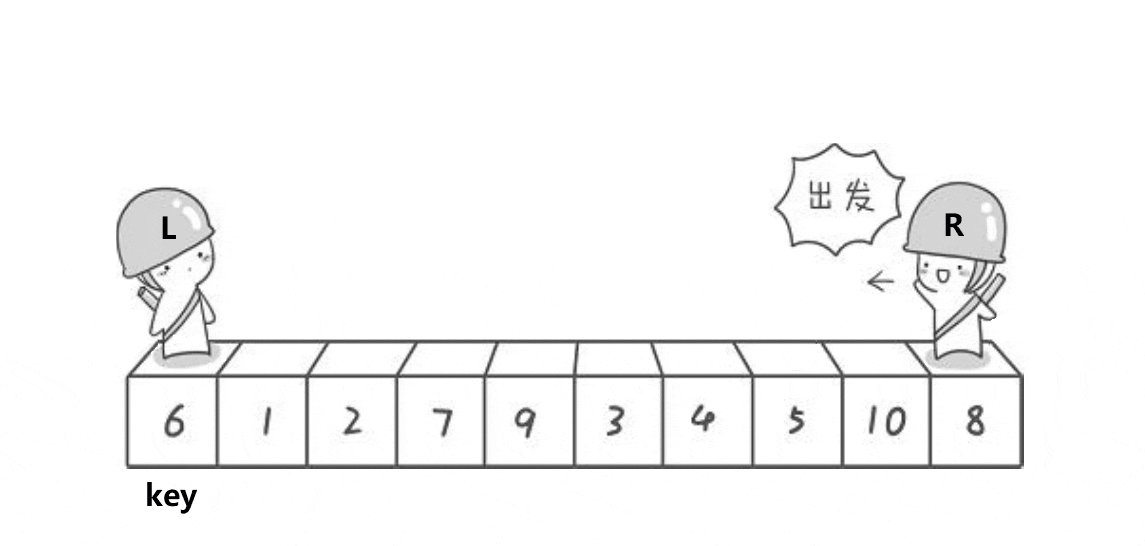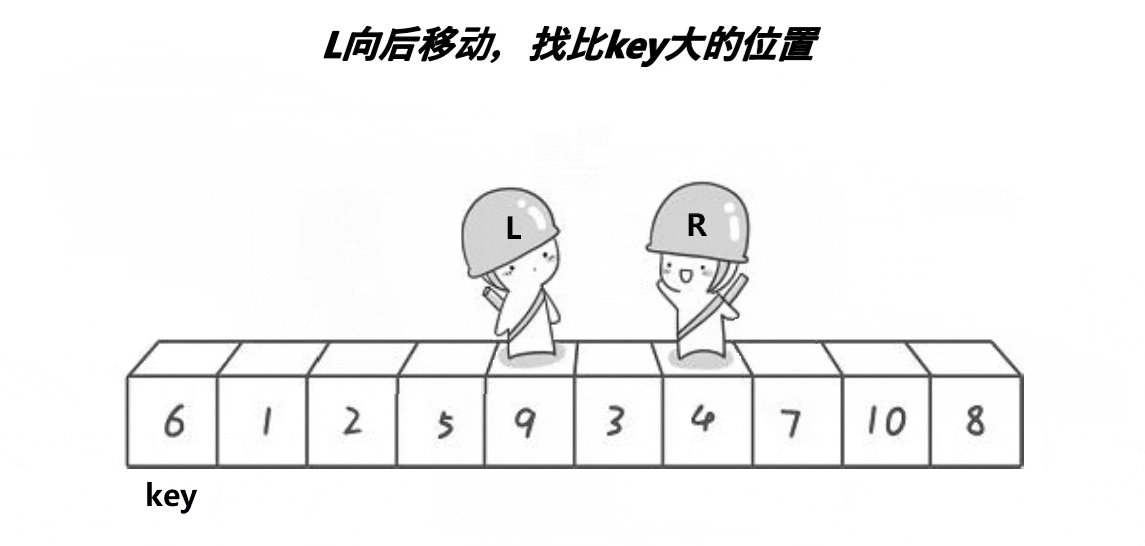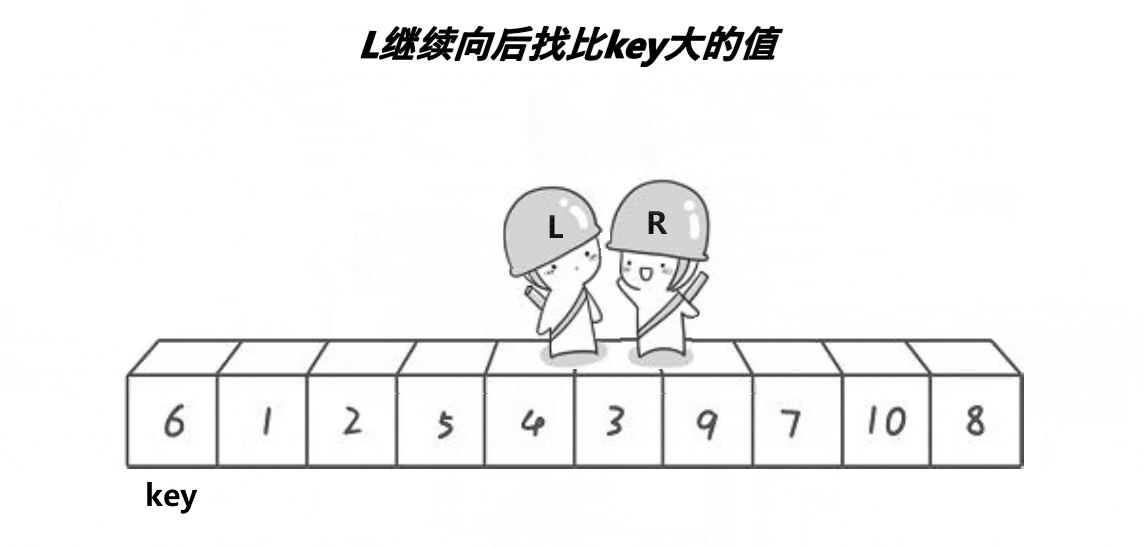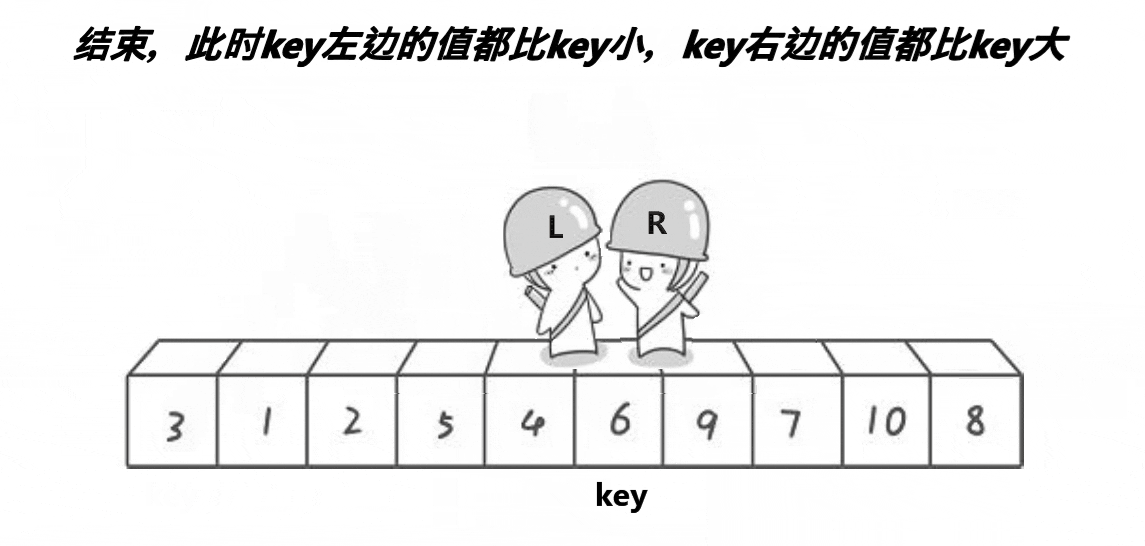
1.假设左边为keyi,也就是对比数值
2,右边R先走,循环寻找比keyi小的数值
3,左边l走,循环寻找比keyi大的数值
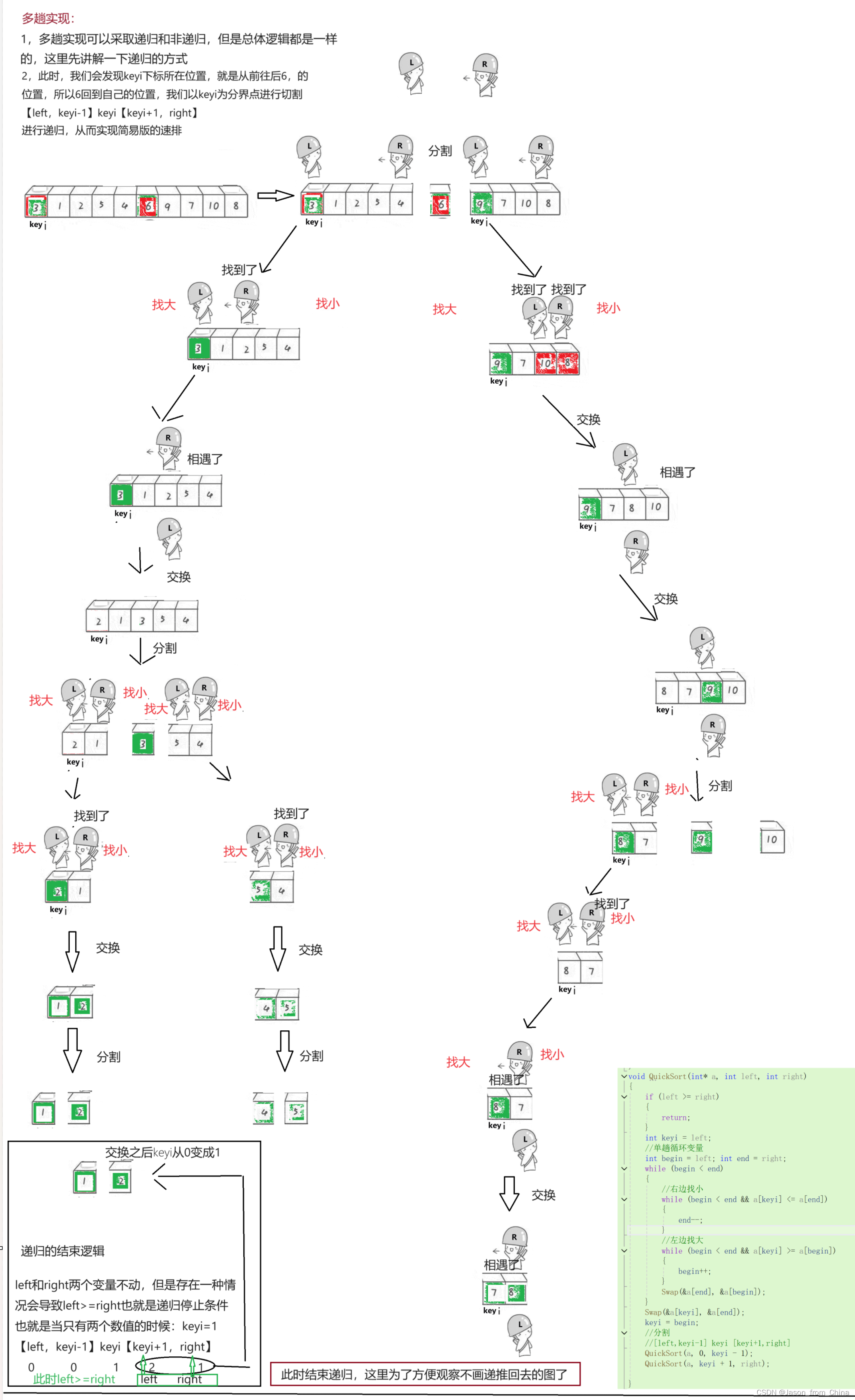
4,交换找到的比keyi大的数值和小的数值,此时会导致小的在左边,大的在右边,最后相遇的时候交换keyi和相遇的元素多趟实现:
1,多趟实现可以采取递归和非递归,但是总体逻辑都是一样的,这里先讲解一下递归的方式2,此时,我们会发现keyi下标所在位置,就是从前往后6,的位置,所以6回到自己的位置,我们以keyi为分界点进行切割【left,keyi-1】keyi【keyi+1,right】
进行递归,从而实现简易版的速排
完善逻辑:
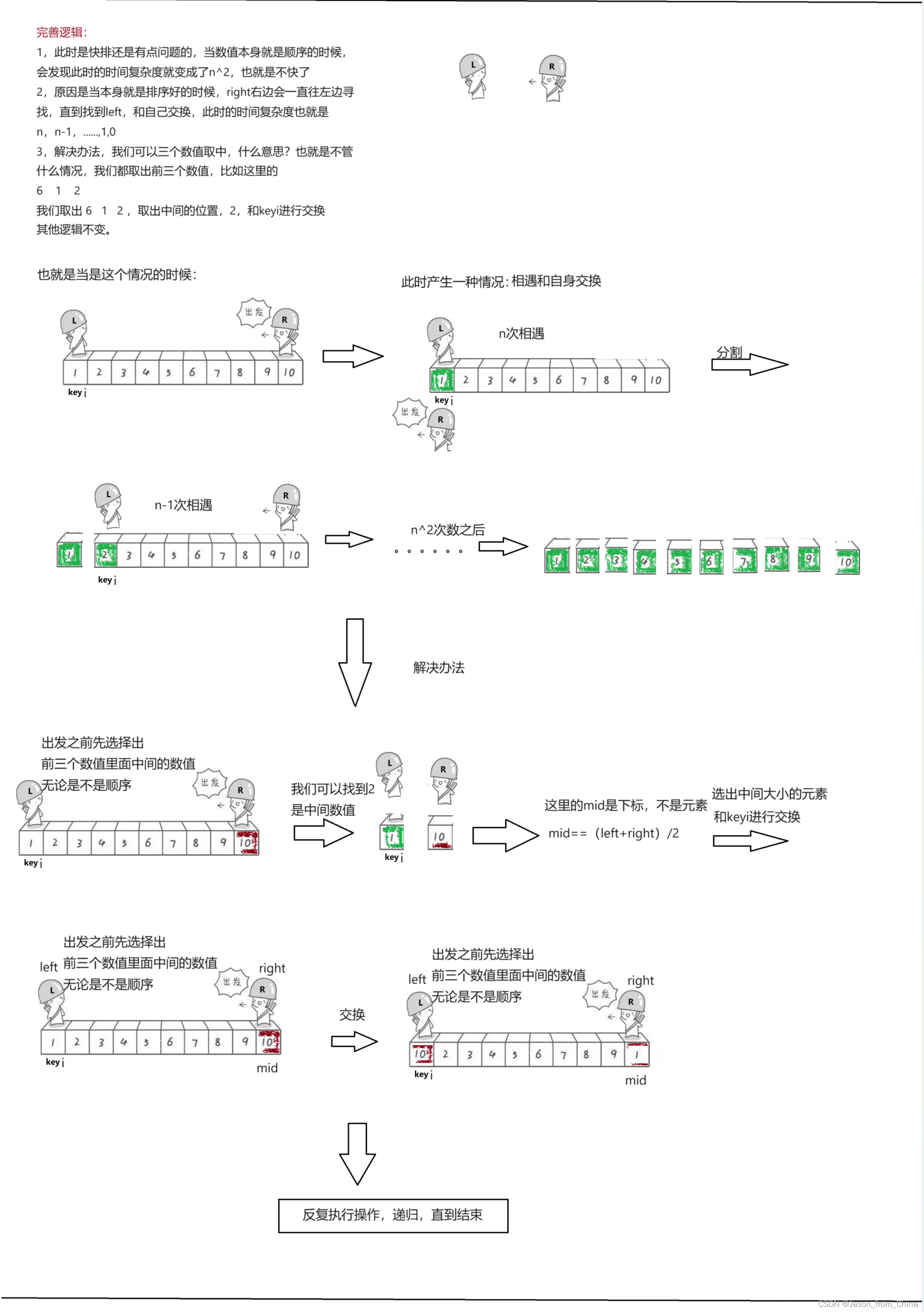
1,此时是快排还是有点问题的,当数值本身就是顺序的时候
会发现此时的时间复杂度就变成了n^2,也就是不快了
2,原因是当本身就是排序好的时候,right右边会一直往左边寻
找,直到找到left,和自己交换,此时的时间复杂度也就是
n,n-1..1.0
3,解决办法,我们可以三个数值取中,什么意思?也就是不管什么情况,我们都取出前三个数值,比如这里的
6 1 2
我们取出6 1 2,取出中间的位置,2,和keyi进行交换其他逻辑不变
完善逻辑:
1,此时我们发现逻辑没有问题,但是速度还是和堆排序有点差距,那么此时我们继续进行优化
2,因为这里是用递归来实现的,我们发现,递归的实现是逐级实现的,也就是
第-层->第n层:1->2->3->4->…->n-1->n
这样的递归方式来实现的,所以越到下面,递归的越多
我们可以把最后十层的递归用插入排序来实现一下,
3,为什么用插入排序?在排序里面有希尔排序,冒泡排序,选
择排序,堆排序
希尔排序->插入排序的进阶(书写复杂)
冒泡排序->时间复杂度高
选择排序->时间复杂度和冒泡一样,比较高
堆排序->处理大型数字问题,这里没必要
所以我们采取插入排序的方式进行解决
4,解决,我们只需要在递归的时候加一个判断,就可以,当数
值小于等于10 的时候,我们直接调用插入排序解决问题。
此时速排(霍尔排序),递归的方式也就结束了。图解:

快排单趟实现
快排多趟实现
简易版本的代码实现
//霍尔方法(递归实现) void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right); }解释:
函数定义:
QuickSort01函数接受一个整数数组的指针a以及两个整数left和right,分别表示要排序的数组部分的起始和结束索引。递归终止条件:如果
left大于或等于right,则当前子数组无需排序,递归结束。初始化:设置两个指针
begin和end分别指向子数组的起始和结束位置,keyi作为基准元素的索引,初始位置设为left。单趟排序:
- 使用两个内层循环,一个从右侧向左寻找比基准值小的元素,另一个从左侧向右寻找比基准值大的元素。
- 当找到合适的元素时,交换这两个元素的位置,然后继续寻找,直到
begin和end相遇。基准值定位:将基准值
a[keyi]与begin指向的元素交换,此时begin指向的位置是基准值的最终位置。递归排序:对基准值左边的子数组
[left, keyi - 1]和右边的子数组[keyi + 1, right]递归调用QuickSort01函数进行排序。效率:快速排序的平均时间复杂度为O(n log n),但在最坏情况下(如数组已经排序)时间复杂度会退化到O(n^2)。霍尔方法通过减少不必要的数据交换来提高排序效率。
辅助函数:
Swap函数用于交换两个元素的值,虽然在代码中未给出定义,但它是快速排序中交换元素的关键操作。快速排序算法的效率和性能在实际应用中通常优于其他O(n log n)算法,如归并排序,尤其是在数据量较大时。然而,其稳定性不如归并排序,且在最坏情况下性能较差。在实际应用中,快速排序通常与其他排序算法结合使用,以提高整体排序性能。
注意事项
注意事项1
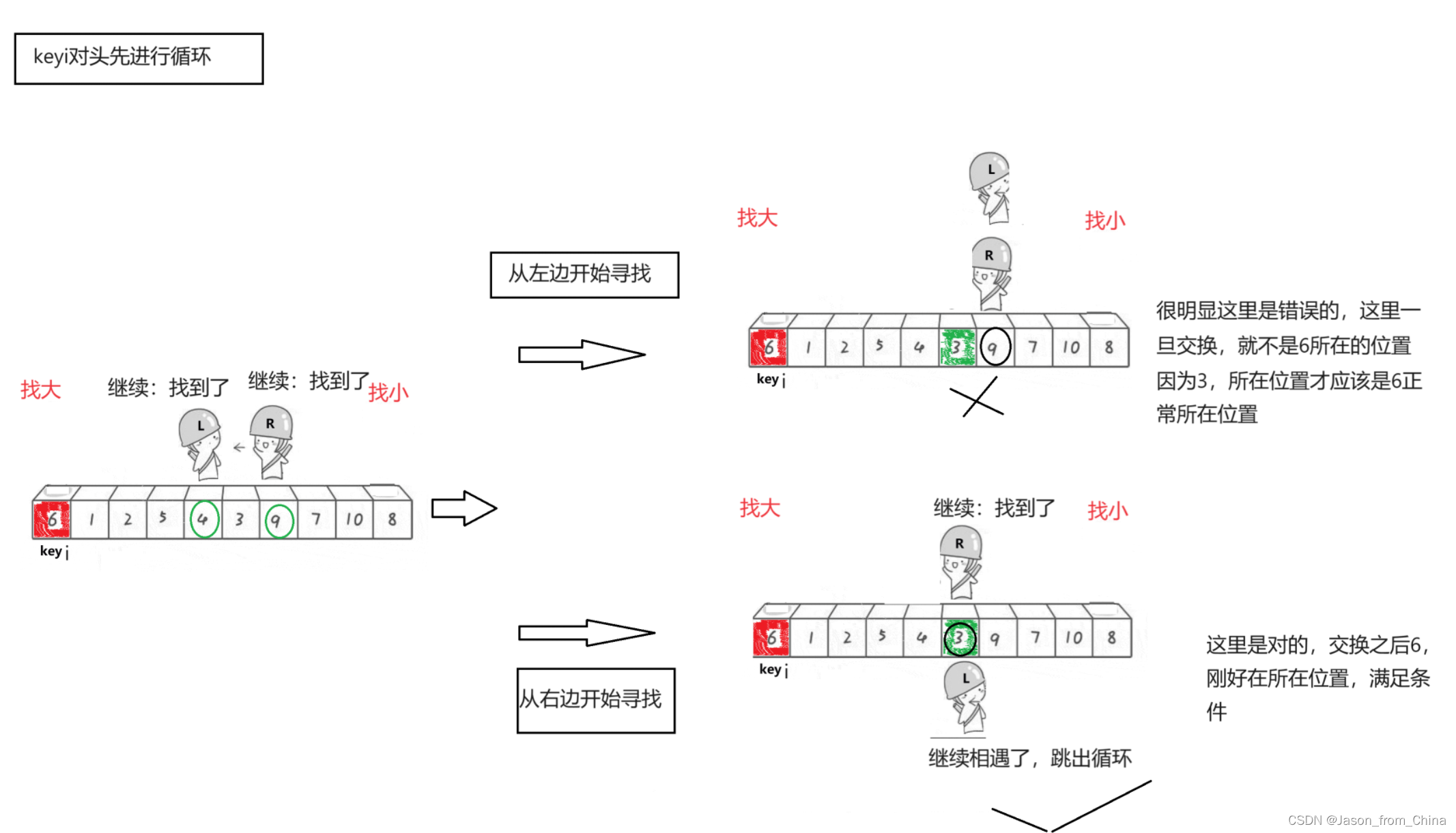
这里有一个关键点是很重要的,也就是我们是从右边先出发的,因为我们的keyi的位置在左边。
如果我们的keyi的下标在左边,并且左边先走的话,就会产生一种结果
如图
注意事项2
不是等于就交换,是等于会跳过往下找
当我们写的是不等于的时候


快排完整代码实现-(三数值取中)
此时存在的最大问题就是如果排序本身就是顺序排序的情况下,这时间复杂度反而高了,所以我们对排序进行修改
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(递归实现) //三数取中 int GetMid(int* a, int left, int right) {//三数取中传参的是下标,我们取中也是根据下标进行计算的int mid = (left + right) / 2;if (a[left] < a[right]){if (a[mid] < a[left])//a[mid] < a[left] < a[right]{return left;}else if(a[mid] > a[right])// a[left] < a[right] < a[mid] {return right;}else{return mid;}}else//a[left] > a[right]{if (a[mid] > a[left])//a[mid] > a[left] > a[right]{return left;}else if (a[mid] < a[right])//a[left] > a[right] > a[mid] {return right;}else{return mid;}} } void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right); }总结:
函数目的:选择一个合适的基准值,以提高快速排序算法的效率。
传入参数:接受一个整数数组的指针
a,以及表示数组部分边界的整数left和right。计算中间索引:通过
(left + right) / 2计算中间元素的索引mid。三数取中逻辑:
- 如果数组的第一个元素
a[left]小于最后一个元素a[right]:
- 如果中间元素
a[mid]小于第一个元素,则选择第一个元素作为基准。- 如果中间元素大于最后一个元素,则选择最后一个元素作为基准。
- 否则,选择中间元素作为基准。
- 如果第一个元素大于或等于最后一个元素(即数组首尾元素已经排序或相等):
- 如果中间元素大于第一个元素,则选择第一个元素作为基准。
- 如果中间元素小于最后一个元素,则选择最后一个元素作为基准。
- 否则,选择中间元素作为基准。
返回值:函数返回基准值的索引。
优化目的:通过三数取中法选择基准,可以减少快速排序在特定情况下性能退化的问题,如数组已经排序或包含大量重复元素。
适用场景:适用于快速排序算法中,作为选择基准值的策略。
性能影响:选择一个好的基准值可以确保数组被均匀地划分,从而接近快速排序的最佳平均时间复杂度O(n log n)。
三数取中法是一种简单而有效的基准选择策略,它通过比较数组的首元素、尾元素和中间元素,来确定一个相对平衡的基准值,有助于提高快速排序的整体性能和稳定性。
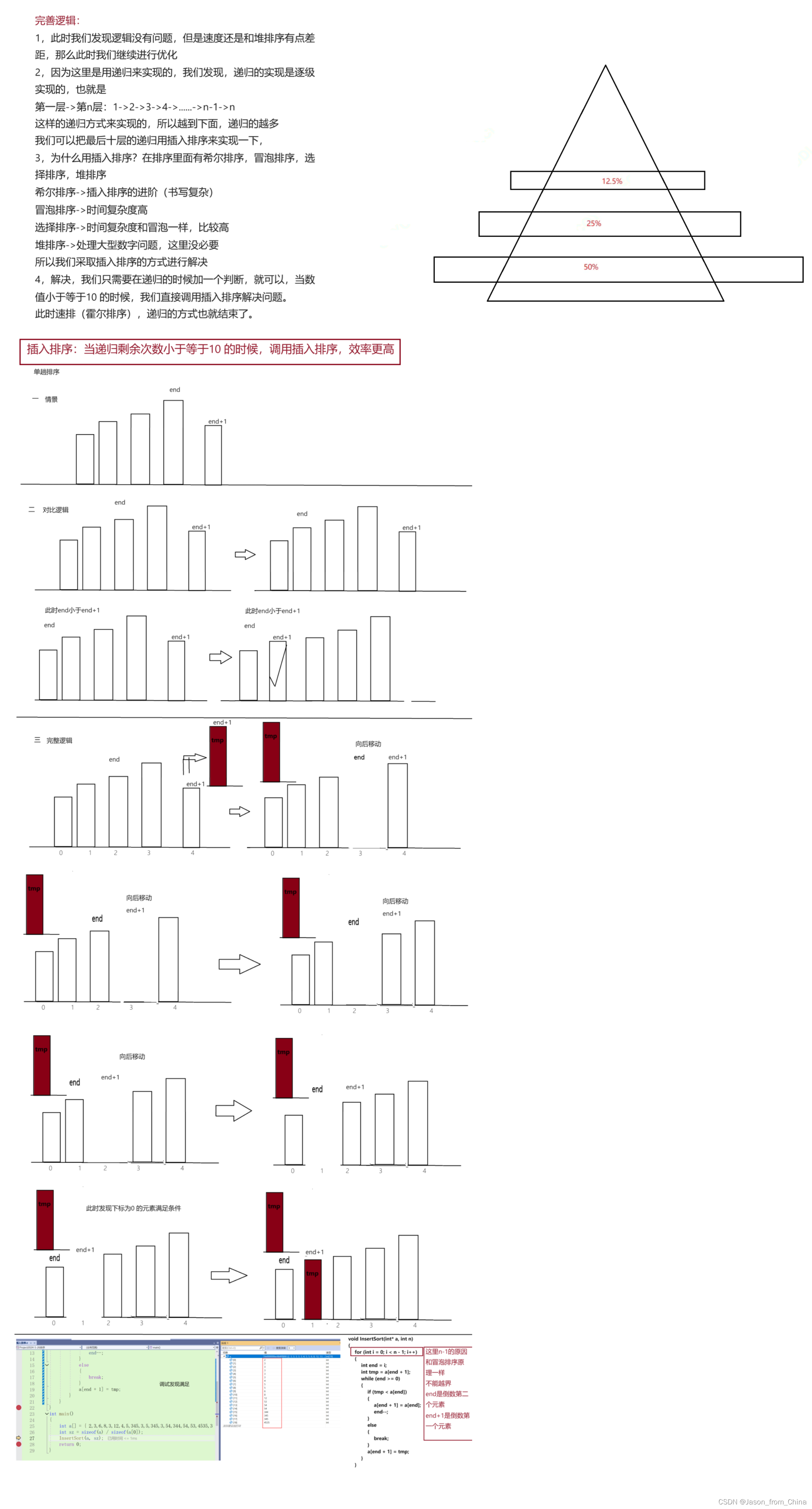
快排完整代码实现-(减少递归次数)
此时我们还面临的问题就是底层的递归次数过多的问题,递归会随着次数的增加呈现倍数增长,就像三角形一样
最后我们减少递归次数,把最底层从递归改为插入排序,逻辑完成
快排完整代码
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(递归实现) //三数取中 int GetMid(int* a, int left, int right) {//三数取中传参的是下标,我们取中也是根据下标进行计算的int mid = (left + right) / 2;if (a[left] < a[right]){if (a[mid] < a[left])//a[mid] < a[left] < a[right]{return left;}else if(a[mid] > a[right])// a[left] < a[right] < a[mid] {return right;}else{return mid;}}else//a[left] > a[right]{if (a[mid] > a[left])//a[mid] > a[left] > a[right]{return left;}else if (a[mid] < a[right])//a[left] > a[right] > a[mid] {return right;}else{return mid;}} } void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//当区间数值小于10个,此时我们直接采取插入排序进行排序if (right - left + 1 <= 10){//这里记得是左右区间,所以不能只传递a,而是传递a + leftInsertionSort(a + left, right - left + 1);}else{//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right);} }代码解释:
三数取中函数
GetMid:
- 计算中间索引
mid。- 通过比较数组的首元素、尾元素和中间元素,选择一个合适的基准值。
- 如果首元素小于尾元素,选择中间元素和首尾元素中较小或较大的一个作为基准。
- 如果首元素大于尾元素,选择中间元素和首尾元素中较大或较小的一个作为基准。
快速排序函数
QuickSort01:
- 递归停止条件:如果当前区间的左右索引
left和right交叉或重合,则不需要排序。- 当区间大小小于或等于10时,使用插入排序,因为小数组上插入排序更高效。
- 使用
GetMid函数获取基准值的索引,并将基准值与首元素交换。- 霍尔方法的分区操作,通过两个指针
begin和end进行分区。- 递归地对基准值左边和右边的子区间进行快速排序。
辅助函数
Swap:
- 交换两个元素的值,虽然代码中未给出定义,但通常是一个简单的值交换操作。
总结:
- 算法优化: 通过三数取中法选择基准值,可以提高基准值的选中质量,从而提高快速排序的效率。
- 小数组优化: 当子数组的大小,小于或等于10时,使用插入排序代替快速排序,因为小数组上插入排序的性能通常更好。
- 递归与迭代: 快速排序是一个递归算法,但在小数组上切换到迭代的插入排序可以减少递归开销。
- 分区策略: 使用霍尔方法进行分区,这是一种高效的分区策略,可以减少不必要的数据交换。
- 适用场景: 这种改进的快速排序适用于大多数需要排序的场景,尤其是在大数据集上,它能够保持较好的性能。
- 时间复杂度: 平均情况下时间复杂度为 O(n log n),最坏情况下(已排序数组)时间复杂度为 O(n^2),但由于三数取中法和插入排序的结合,最坏情况出现的概率降低。
通过这种改进,快速排序算法在处理小数组时更加高效,同时在大数据集上也能保持较好的性能,使其成为一种更加健壮的排序算法。
快排的时间复杂度
快速排序算法的时间复杂度取决于分区过程中基准值的选择。
理想情况下
基准值会将数组均匀地分成两部分,每部分的元素数量大致相等。对于这种理想情况,快速排序的时间复杂度是 O(n log n),其中 n 是数组中的元素数量。
最坏情况下
如果基准值的选择非常不均匀,从而导致每次分区都极不平衡,快速排序的最坏时间复杂度会退化到 O(n^2)。这种情况通常发生在数组已经排序或所有元素相等的情况下。
在当前代码中
使用了三数取中法来选择基准值,这种方法可以在大多数情况下避免选择极端值作为基准,从而减少最坏情况发生的概率。但是,如果数组的元素分布非常不均匀,或者存在大量重复元素,仍然可能遇到性能退化的情况。
此外,代码中还引入了一个优化:当子数组的大小小于或等于10时,使用插入排序而不是快速排序。这是因为对于小数组,插入排序的性能通常比快速排序更好,而且插入排序是稳定的。这个优化可以提高算法在处理小数组时的效率。
总的来说,这个改进的快速排序算法的平均时间复杂度是 O(n log n),但在最坏情况下仍然是 O(n^2)。然而,由于三数取中法和插入排序的优化,最坏情况的发生概率被大大降低了。在实际应用中,这种改进的快速排序算法通常能够提供非常高效的排序性能。
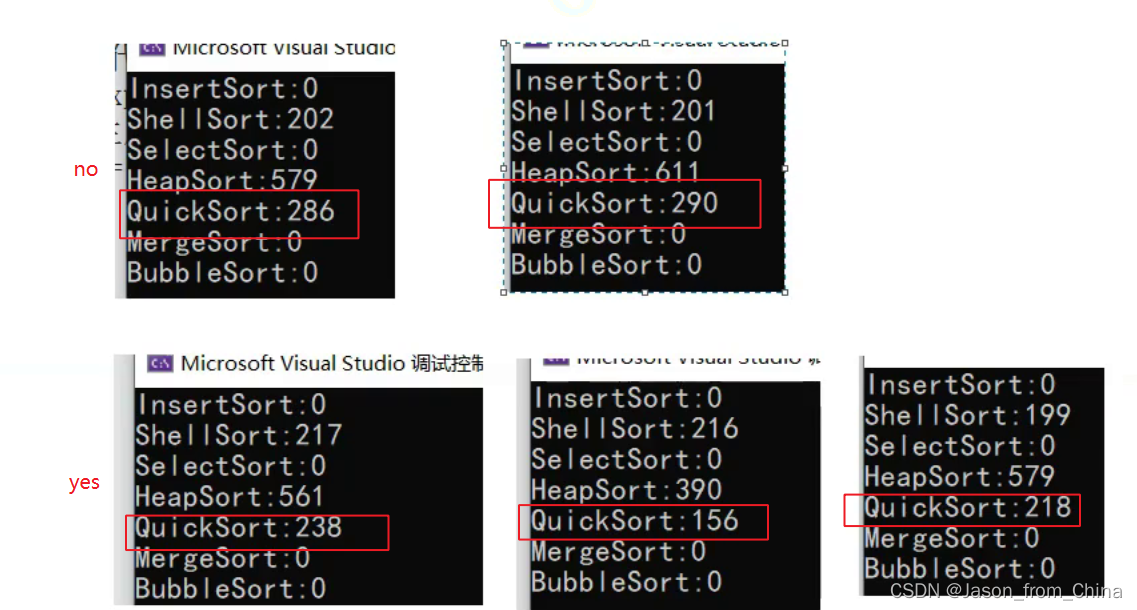
前后修改之后速度进行对比
优化,和不优化之间的区别
这里计算的是一千万个数值进行排序的毫秒数值,也就是不到一秒,还是很快的,尤其是修改之后,解决了大量的递归问题
注意事项
这里调用的插入排序是升序,写的快排也是升序,如果你需要测试降序,那么你需要把插入排序一起改成降序,不然会导致排序冲突
快排(前后指针-递归解决)
前言
快排解决办法有很多种,这里我再拿出来一种前后指针版本
虽然这个版本的时间复杂度和霍尔一样,逻辑也差不多,但是实际排序过程,确实会比霍尔慢一点
快排gif
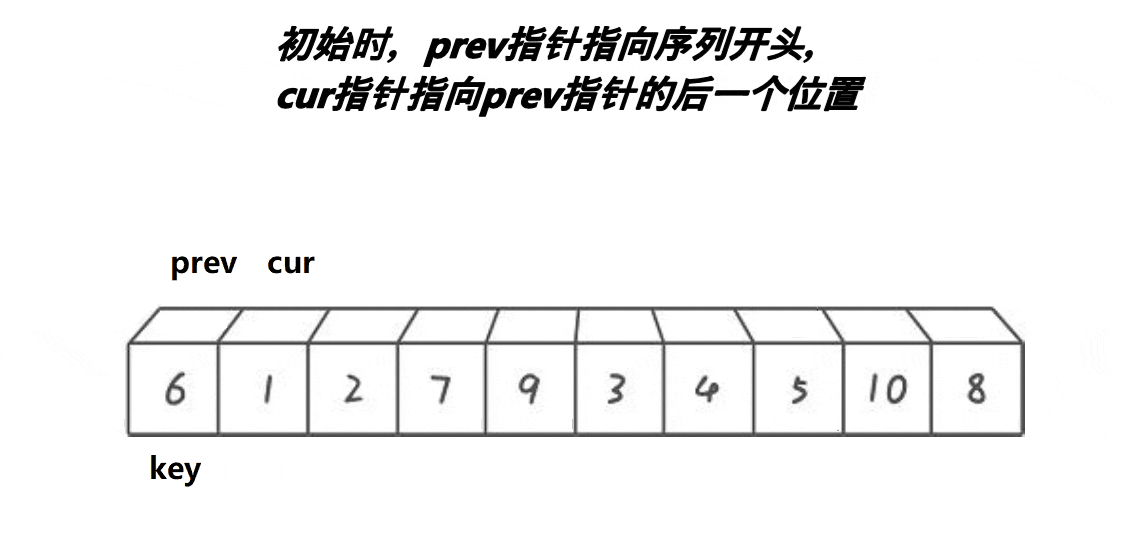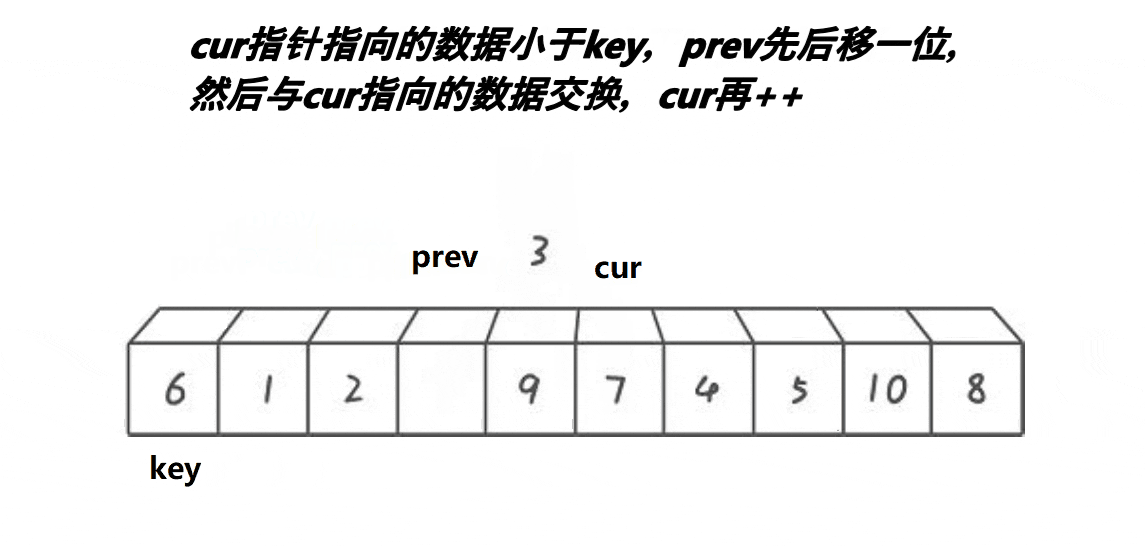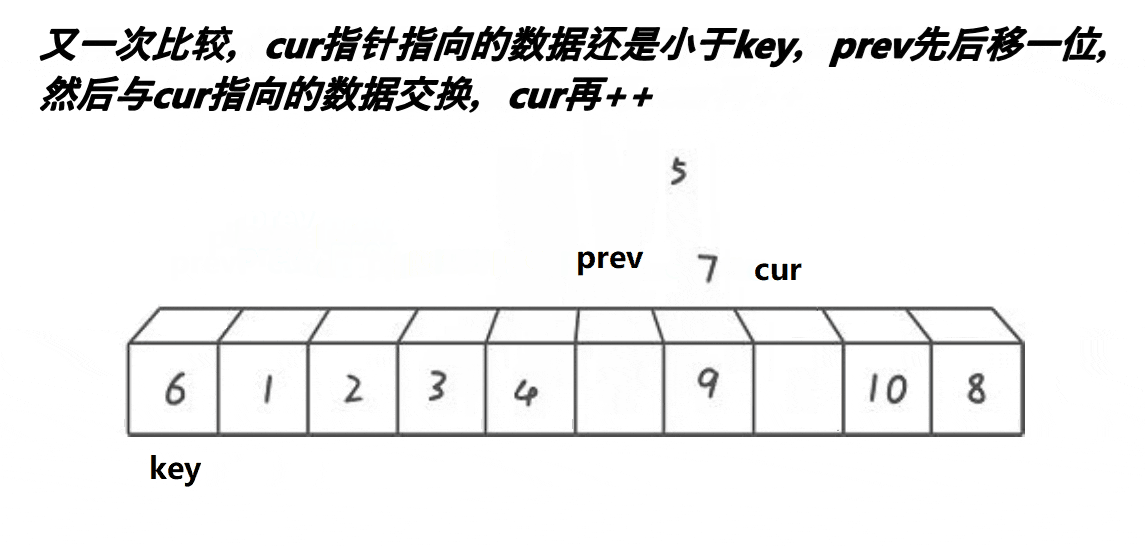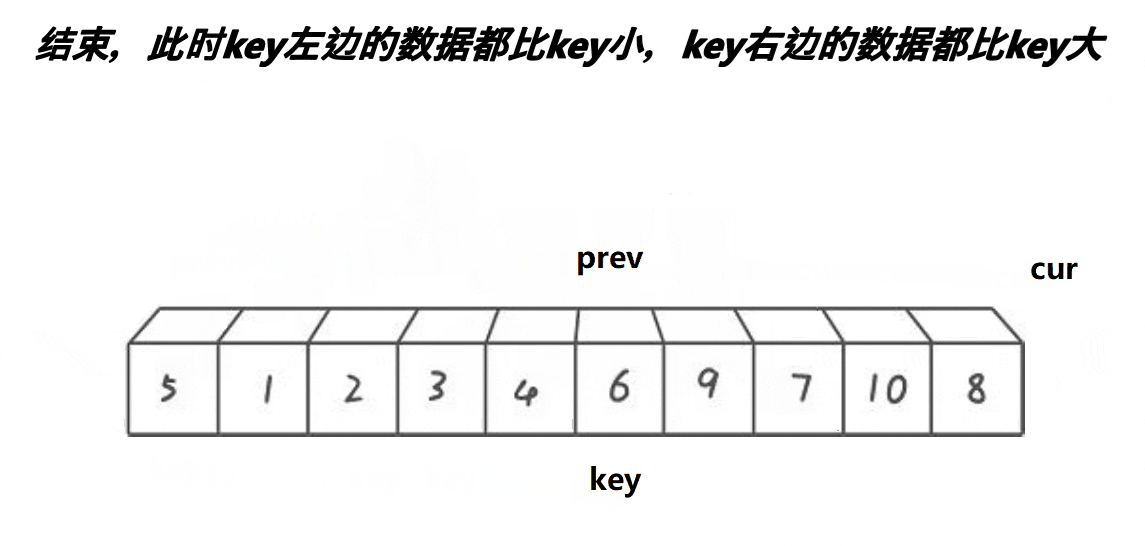
快排前后指针实现逻辑:
前后指针实现逻辑(升序):
单趟排序:
1,我们使用递归来进行实现,所以我们先实现单趟排序
2,定义两个下标,也就是所谓的指针,初始的时候,一个指向最左边第一个元素(prev),一个指向第二个元素(cur),最后定义一个对比keyi3,此时先判断我们的cur是不是小于keyi。cur小于keyi的话:prev++,交换,之后cur++4,但是我们如果和自己交换此时没有什么意义,所以这里我们需要做一个处理
5,继续往前走,如果遇见的是:比keyi下标大的元素此时,cur++,直到遇见的是比keyi下标小的元素,循环执行.prev++,交换,之后cur++6,最后cur走到最后一个元素,我们交换keyi的下标元素和prev的下标元素
多趟实现:
1,递归进行分割:【left,keyi-1】keyi【keyi+1,right】
2,停止条件就是当left>=right
原因:【left, keyi-1】keyi【keyi+1, right】

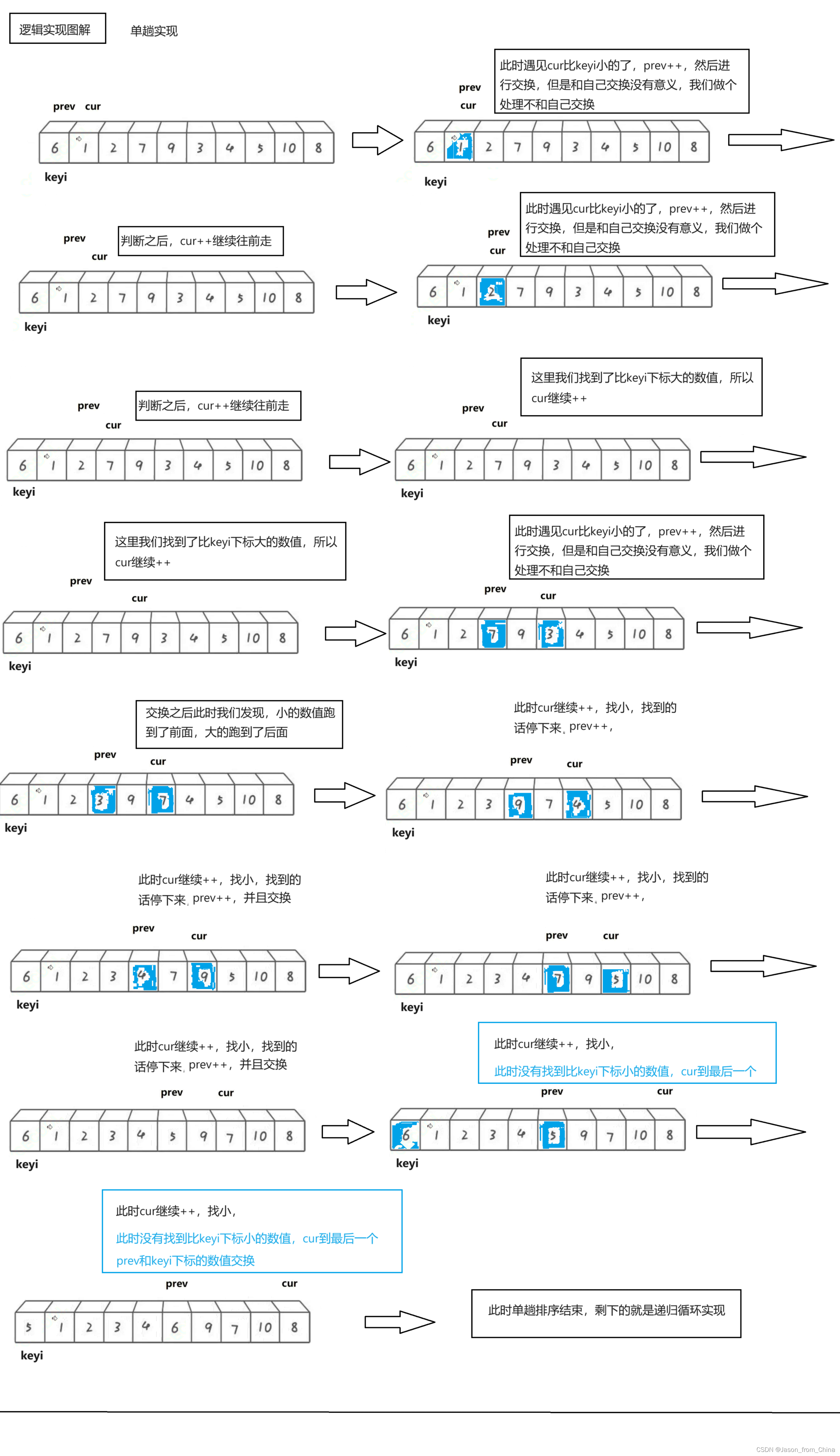
快排单趟实现
这里只是图解单趟实现逻辑,因为多趟实现的逻辑和霍尔的一样,也是递归,所以不进行多次书写
代码实现
这里的代码实现的核心逻辑不一样,大的框架是一样的,也就是三数取中,以及减少递归从而使用插入排序这样的逻辑是一样的,下面我们来看看这个新的组装怪
//快排(前后指针方法)(递归实现) void QuickSort02(int* a, int left, int right) {//递归停止条件if (left >= right)return;//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur]){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来prev++;Swap(&a[prev], &a[cur]);//同理快指针也进行++,往后移动cur++;}else{cur++;}}Swap(&a[prev], &a[keyi]);keyi = prev;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort02(a, left, keyi - 1);QuickSort02(a, keyi + 1, right); }总结:
算法基础:快速排序是一种分而治之的排序算法,它通过递归地将数组分为较小的子数组,然后对这些子数组进行排序。
分区策略:使用前后指针(
prev和cur)进行分区,而不是传统的左右指针。这种方法在某些情况下可以减少元素交换的次数。基准值选择:基准值(
keyi)是数组的第一个元素,即left索引对应的元素。指针移动规则:
prev作为慢指针,用于跟踪比基准值小的元素的边界。cur作为快指针,从left + 1开始遍历数组。元素交换:当快指针指向的元素大于基准值时,不进行交换,快指针继续移动;当快指针指向的元素小于或等于基准值时,与慢指针所指元素交换,然后慢指针和快指针都向前移动。
递归排序:在基准值确定之后,递归地对基准值左边和右边的子数组进行排序。
时间复杂度:平均情况下,快速排序的时间复杂度为O(n log n)。最坏情况下,如果每次分区都极不平衡,时间复杂度会退化到O(n^2)。
空间复杂度:由于递归性质,快速排序的空间复杂度为O(log n)。
算法优化:通过前后指针方法,可以在某些情况下提高快速排序的性能,特别是当基准值接近数组中间值时。
适用场景:快速排序适用于大多数需要排序的场景,特别是在大数据集上,它通常能够提供非常高效的排序性能。
优化
这里我们可以看到,cur无论是if还是else里面都需要++,所以我们直接放到外面
其次我们为了效率,不和自己交换,我们不和自己交换,进行一个判断条件

快慢指针代码优化(完整)
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //快排(前后指针方法)(递归实现) void QuickSort02(int* a, int left, int right) {//递归停止条件if (left >= right)return;if (right - left + 1 >= 10){InsertionSort(a + left, right - left + 1);}else{//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur] && prev++ != cur){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort02(a, left, keyi - 1);QuickSort02(a, keyi + 1, right);} }总结:
基本递归结构:算法使用递归调用来处理子数组,这是快速排序算法的核心结构。
小数组优化:当子数组的大小小于或等于10时,算法使用插入排序而不是快速排序,因为插入排序在小规模数据上更高效。
三数取中法:为了更均匀地分割数组,算法使用三数取中法选择基准值,这有助于减少最坏情况发生的概率。
前后指针方法:算法使用两个指针(
prev和cur),其中prev作为慢指针,cur作为快指针,通过这种方式进行一次遍历完成分区。分区操作:快指针从
left + 1开始遍历,如果当前元素小于基准值,则与慢指针所指的元素交换,然后慢指针向前移动。递归排序子数组:基准值确定后,算法递归地对基准值左边和右边的子数组进行排序。
时间复杂度:平均情况下,算法的时间复杂度为O(n log n),最坏情况下为O(n^2)。但由于采用了小数组优化和三数取中法,最坏情况的发生概率降低。
空间复杂度:算法的空间复杂度为O(log n),这主要由于递归调用导致的栈空间使用。
适用场景:这种改进的快速排序算法适用于大多数需要排序的场景,尤其是在大数据集上,它能够提供非常高效的排序性能,同时在小数据集上也表现出较好的效率。
算法稳定性:由于使用了插入排序对小规模子数组进行排序,算法在处理小规模数据时具有稳定性。
注意:在实际测试·里面,前后指针比霍尔排序慢一点
通过这种混合排序策略,算法在保持快速排序优点的同时,也提高了在特定情况下的排序效率,使其成为一种更加健壮的排序方法。
注意事项
这里调用的插入排序是升序,写的快排也是升序,如果你需要测试降序,那么你需要把插入排序一起改成降序,不然会导致排序冲突
快排(霍尔版本-非递归解决)
前言
快拍不仅需要学习递归,还需要学东西非递归,这样更有助于我们理解快拍
首先我们需要知道,非递归的学习需要使用栈,所以如果我们的栈的学习是不完善的,建议学习一下栈
非递归gif
这里其实单词循环是谁其实不重要,可以是前后指针,也可以是霍尔方式,这里我们拿出来霍尔的gif来观看
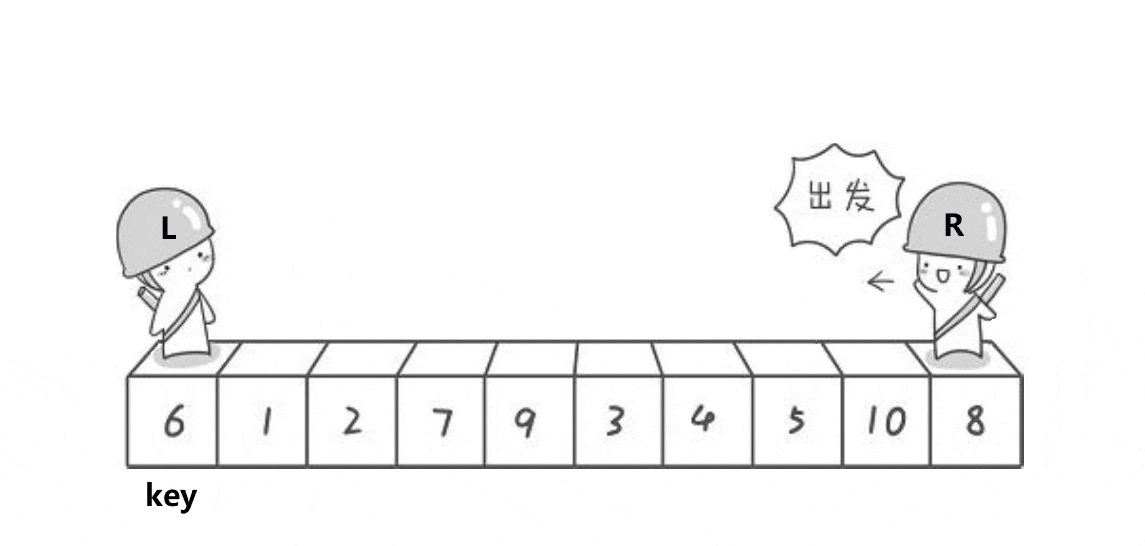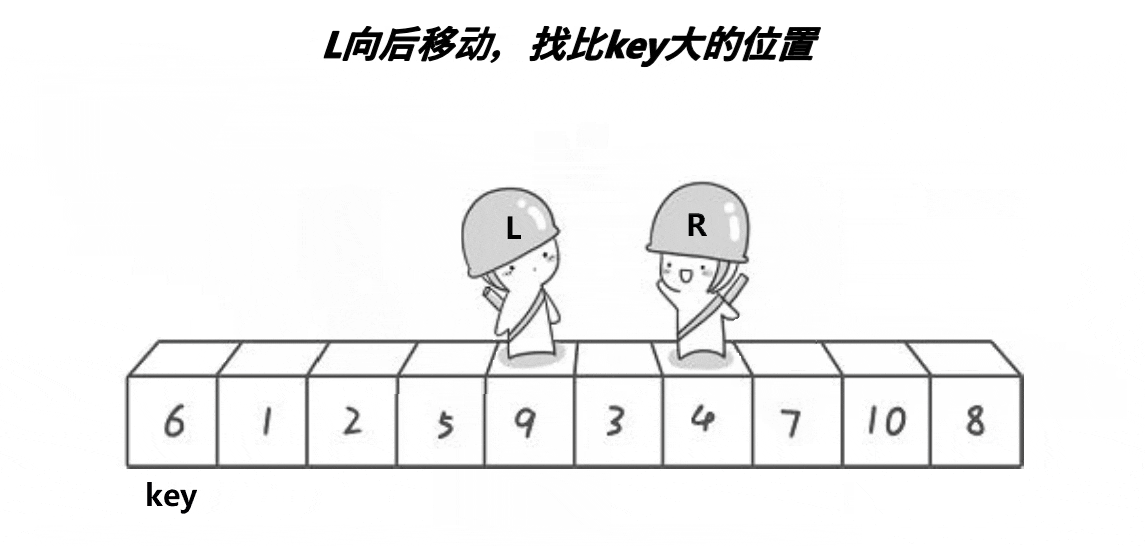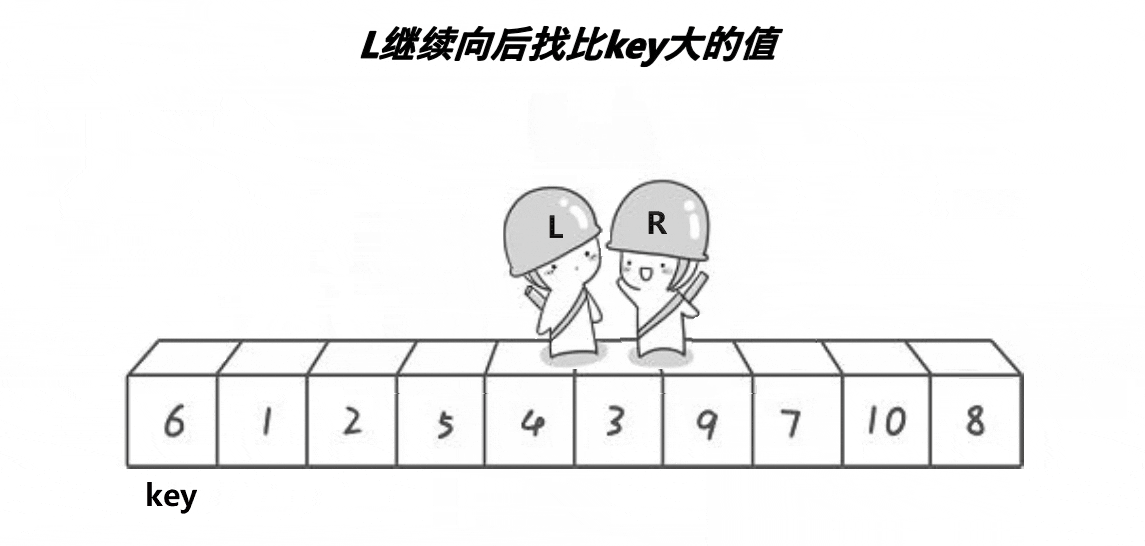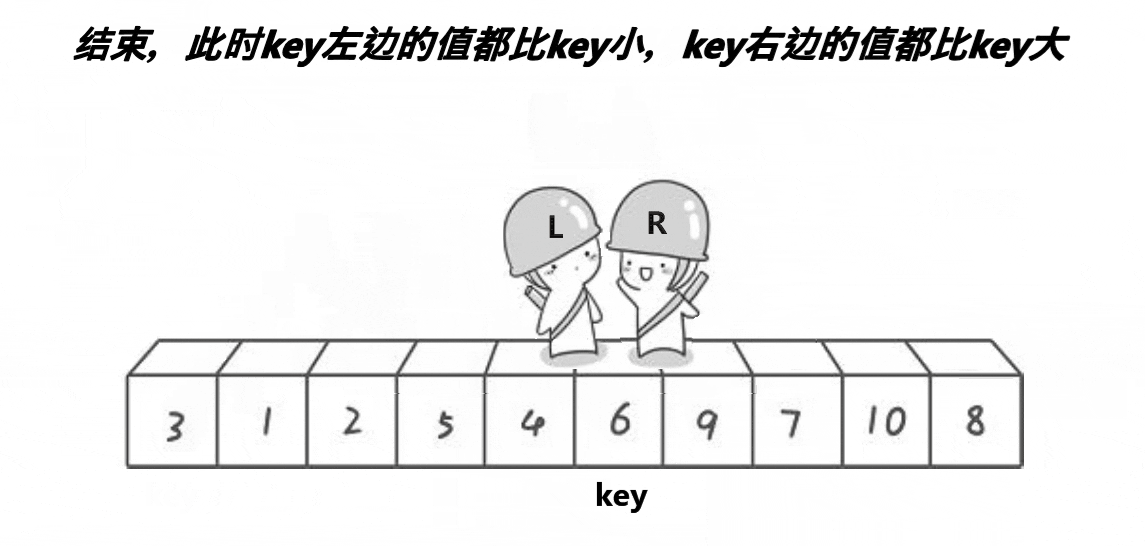
实现图解
非递归实现主要是依赖栈来进行实现,依赖栈的特点,先进后出,后进前出
1,首先我们需要写一个栈的库进行调用
2,入区间,调用单次排序的实现思路
3,入区间的时候,我们需要把握入栈和出栈的关键
代码实现(前后指针)
首先我们调用栈
头文件
#define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include<stdio.h> #include<assert.h> #include<stdlib.h> typedef int STDataType; typedef struct Stack {STDataType* _a; // 首元素的地址int _top; // 栈顶,初始化为0,也就是等同于size,初始化为-1,等同于下标int _capacity; // 容量 }Stack; // 初始化栈 void StackInit(Stack* ps); // 销毁栈 void StackDestroy(Stack* ps); // 入栈 void StackPush(Stack* ps, STDataType data); // 出栈 void StackPop(Stack* ps); // 获取栈顶元素 STDataType StackTop(Stack* ps); // 获取栈尾元素 STDataType Stackhop(Stack* ps); // 获取栈中有效元素个数 int StackSize(Stack* ps); // 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 int StackEmpty(Stack* ps);实现文件
#include"Stack.h" // 初始化栈 void StackInit(Stack* ps) {ps->_a = NULL;ps->_capacity = ps->_top = 0; } // 销毁栈 void StackDestroy(Stack* ps) {assert(ps && ps->_top);free(ps->_a);ps->_a = NULL;ps->_capacity = ps->_top = 0; }// 入栈 void StackPush(Stack* ps, STDataType data) {//判断需不需要扩容,相等的时候需要扩容if (ps->_capacity == ps->_top){//判断空间是不是0,因为为0的时候,再多的数值*2,也是0int newcapacity = ps->_capacity == 0 ? 4 : ps->_capacity * 2;STDataType* tmp = (STDataType*)realloc(ps->_a, sizeof(STDataType) * newcapacity);if (tmp == NULL){perror("StackPush:tmp:err:");return;}ps->_capacity = newcapacity;ps->_a = tmp;}ps->_a[ps->_top] = data;ps->_top++; }// 出栈 void StackPop(Stack* ps) {assert(ps);ps->_top--; } // 获取栈顶元素 STDataType StackTop(Stack* ps) {//这里必须大于0 因为我们这里等同size,也就是个数,等于0都不行assert(ps);return ps->_a[ps->_top - 1]; } // 获取栈尾元素 STDataType Stackhop(Stack* ps) {assert(ps && ps->_top > 0);return ps->_a[0]; } // 获取栈中有效元素个数 int StackSize(Stack* ps) {//获取有效元素的时候,里面可以没有元素assert(ps);return ps->_top; } // 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 int StackEmpty(Stack* ps) {//这里的判断是不是空,也就是里面是不是有数值,这里等于是一个判断,没有的话返回ture,有的话返回falseassert(ps);return ps->_top == 0; }其次调用前后指针来实现
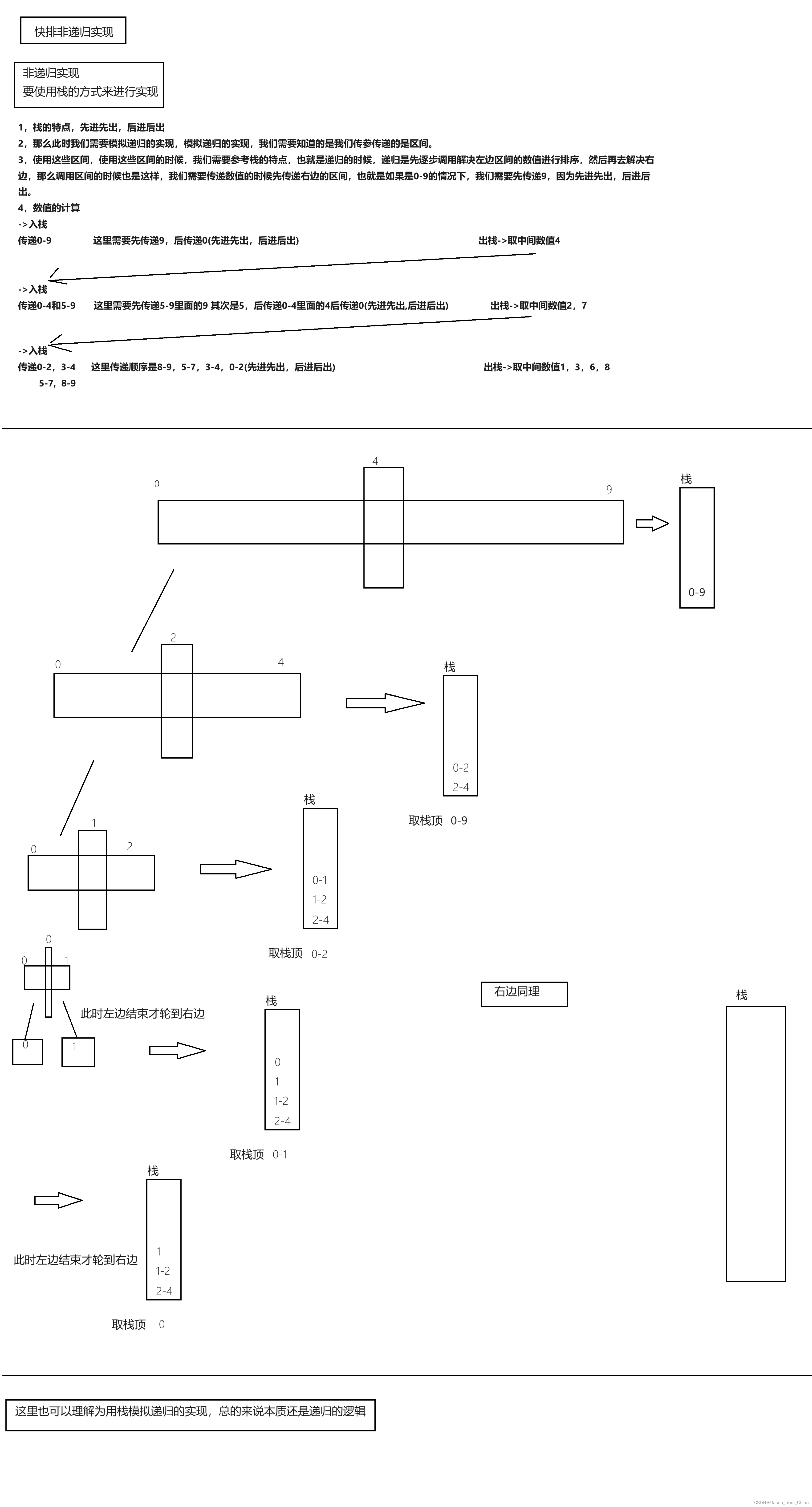
//快排(前后指针方法)(单趟) int one_QuickSort02(int* a, int left, int right) {//三数取中//int mid = GetMid(a, left, right);//Swap(&a[mid], &a[left]);//单趟实现//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur] && prev++ != cur){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[keyi], &a[prev]);return prev; //快排 非递归实现 void QuickSort003(int* a, int left, int right) {//非递归实现主要是用栈来模拟实现,在c++里面我们可以直接调用栈,但是在C语言里面我们只能写出来栈再进行调用//思路(霍尔方式)//1单趟的思路还是一样的,如果是升序的情况下,依旧是先从右边出发(找小),后从左边出发(找大)//2,循环递归过程我们改为利用进栈出栈来实现。首先我们需要明确这里传递的是区间,也就是利用栈实现的时候,我们传递的是数组和区间,利用区间进行计算。这里的关键在于传递区间的时候,我们需要详细知晓栈的特点,先进后出,后进后出,。所以在传递区间的时候,如果多趟循环,一分为二的时候,我们需要先传递右侧的区间,再传递左侧区间,因为我们需要先计算左侧。同理进去之后,我们需要继续入栈,需要先-入计算左侧的区间的右侧区间,后入左侧区间。这样就会先计算左侧区间。栈的特性,先进后出,后进先出// // 所以这里我们把霍尔排序单趟实现来单独拿出来,这样的话我们接受的返回值是中间值//[left,keyi-1] keyi [keyi+1,right]//这里需要用非递归来解决Stack ps;StackInit(&ps);StackPush(&ps, right);StackPush(&ps, left);while (!StackEmpty(&ps)){int begin = StackTop(&ps);StackPop(&ps);int end = StackTop(&ps);StackPop(&ps);//假设入栈区间此时来到-> 0-2int mini = one_QuickSort02(a, begin, end);//经过计算之后,此时中间值是,keyi=1//0 1 2 三个区间三个数值,此时进行入栈判断//[begin,keyi-1]keyi[keyi+1,end]//[ 0 , 0 ] 1 [ 2 , 2 ]//所以不继续入栈if (mini + 1 < end){//右边先入栈,后计算StackPush(&ps, end);StackPush(&ps, mini + 1);}if (mini - 1 > begin){//左边区间后入栈,先计算StackPush(&ps, mini - 1);StackPush(&ps, begin);}}StackDestroy(&ps); }解释:
one_QuickSort02函数这个函数是快速排序算法中的单趟排序实现。它使用前后指针法来实现,具体步骤如下:
- 初始化指针:
prev初始化为left,cur初始化为prev + 1,keyi也初始化为left。- 循环:当
cur小于等于right时,执行循环体内的操作。- 比较和交换:如果当前
cur指向的元素小于keyi指向的元素,并且prev指针不等于cur,说明找到了一个比基准值小的元素,需要交换。将a[prev]和a[cur]交换,并将prev指针向前移动一位。- 移动快指针:无论是否发生交换,
cur指针都向前移动一位。- 交换基准值:循环结束后,将
keyi指向的元素与prev指向的元素交换,此时prev指向的是比基准值小的元素的最后一个位置。- 返回值:函数返回
prev的值,这个值是下一次分区的起始位置。
QuickSort003函数这个函数是快速排序的非递归实现,使用栈来模拟递归过程。具体步骤如下:
- 初始化栈:创建并初始化一个栈
ps。- 入栈:将
left和right作为初始区间入栈。- 循环:只要栈不为空,就执行循环。
- 单趟排序:每次从栈中取出两个值作为区间的左右边界,调用
one_QuickSort02函数进行单趟排序,得到中间值mini。- 判断区间:根据
mini的位置,判断是否需要继续对左右区间进行排序。
- 如果
mini + 1 < end,则说明右侧还有元素需要排序,将end和mini + 1入栈。- 如果
mini - 1 > begin,则说明左侧还有元素需要排序,将begin和mini - 1入栈。- 出栈:每次循环结束,都会从栈中弹出两个值,直到栈为空。
- 销毁栈:循环结束后,销毁栈。
对于栈和队列不是很明白的,推荐看一下栈和队列篇章
数据结构-栈和队列(速通版本)-CSDN博客
https://blog.csdn.net/Jason_from_China/article/details/138715165
代码实现(霍尔排序)
这里其实不管是前后指针,还是霍尔排序,其实都是一样的,因为本质上都是让数值到应该到的位置,所以本质上是一样的,这里我再调用一个霍尔的方式是因为一方面和前后指针的调用形成对比,一方面有不同的注释
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(单趟实现) int one_QuickSort01(int* a, int left, int right) {//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);return begin; } //霍尔方法再次调用 void QuickSort03(int* a, int left, int right) {Stack ps;StackInit(&ps);StackPush(&ps, right);StackPush(&ps, left);while (!StackEmpty(&ps)){//取出左区间int begin = StackTop(&ps);StackPop(&ps);//取出右边区间int end = StackTop(&ps);StackPop(&ps);int mini = one_QuickSort01(a, begin, end);//计算区间//假设传递的区间是2-4 --->>> 传递过来的数值也就是下标是(1)4-2=2/2=1 --->>>此时mini=2,也就是此时我们返回的数值要么是第一个数值,要么的第二个数值的下标,不管是哪个,此时都会变成一个数值//此时我们继续入栈,入栈的是mini+1 也就是3-4,继续传递区间,此时传递回来的mini还是3,但是此时3+4==4了 所以不继续入栈,因为数值只有一个,不是区间了//右区间入栈,后出if (mini + 1 < end){//入右边,之后左边,这样取的时候栈顶先取左边,之后右边StackPush(&ps, end);StackPush(&ps, mini + 1);}//左区间入栈,先出if (mini - 1 > begin){StackPush(&ps, mini - 1);StackPush(&ps, begin);}}StackDestroy(&ps); }解释:
one_QuickSort01函数这个函数是霍尔快速排序算法的单趟实现,具体步骤如下:
- 三数取中:使用
GetMid函数找到数组a中间位置的元素,并将其与数组第一个元素交换(left索引位置的元素)。- 初始化指针:
begin初始化为left,end初始化为right,keyi初始化为begin。- 循环:使用
while循环,只要begin小于end,就继续执行循环。- 右边找小:从
end向begin扫描,找到第一个小于基准值a[keyi]的元素。如果找到,end指针向前移动,否则跳出循环。- 左边找大:从
begin向end扫描,找到第一个大于基准值a[keyi]的元素。如果找到,begin指针向后移动,否则跳出循环。- 交换元素:将找到的两个元素
a[begin]和a[end]交换位置。- 基准值交换:循环结束后,将
keyi指向的元素与begin指向的元素交换,此时begin指向的是基准值的正确位置。- 返回值:函数返回
begin的值,这个值是下一次分区的起始位置。
QuickSort03函数这个函数是快速排序的非递归实现,使用栈来模拟递归过程:
- 初始化栈:创建并初始化一个栈
ps。- 入栈:将初始区间的左右边界
left和right入栈。- 循环:只要栈不为空,就继续执行循环。
- 单趟排序:每次从栈中取出两个值作为区间的左右边界,调用
one_QuickSort01函数进行单趟排序,得到中间值mini。- 计算新区间:根据
mini的位置,计算新的左右区间。
- 如果
mini + 1 < end,则说明右侧还有元素需要排序,将end和mini + 1入栈。- 如果
mini - 1 > begin,则说明左侧还有元素需要排序,将begin和mini - 1入栈。- 栈的特性:由于栈是后进先出(LIFO)的数据结构,所以先入栈的是右侧区间,后入栈的是左侧区间,这样在出栈时,会先处理左侧区间,再处理右侧区间。
- 销毁栈:循环结束后,销毁栈。
这种非递归实现的快速排序算法利用了栈的特性来避免递归调用,从而减少了函数调用的开销,并且在处理大数据集时,可以避免递归深度过大导致的栈溢出问题。
相关文章:
快排(霍尔排序实现+前后指针实现)(递归+非递归)
前言 快排是很重要的排序,也是一种比较难以理解的排序,这里我们会用递归的方式和非递归的方式来解决,递归来解决是比较简单的,非递归来解决是有点难度的 快排也称之为霍尔排序,因为发明者是霍尔,本来是命名…...

客户端输入网址后发生的全过程解析(协议交互、缓存、渲染)
目录 1. 输入 URL 并按下回车键2. DNS 解析3. TCP 连接4. 发送 HTTP 请求5. 服务器处理请求6. 发送 HTTP 响应7. 浏览器接收响应8. 渲染网页9. 执行脚本10. 处理其他资源11. TLS/SSL 加密(如果使用 HTTPS)握手过程 12. 协议协商和优化 总结 1. 输入 URL …...

未来科技:Web3如何重塑物联网生态系统
随着Web3技术的崛起,物联网(IoT)的发展正迎来一场深刻的变革。本文将深入探讨Web3如何重塑物联网生态系统,从技术原理到应用实例,全面解析其对未来科技发展的影响和潜力。 1. Web3技术简介与发展背景 Web3技术是建立在…...

C++之模板(二)
1、类模板 2、使用类模板 类模板在使用的时候要显示的调用是哪种类型,而不是像函数模板一样能够根据参数来推导出是哪种类型。 Stack.h #include <stdexcept>template <typename T> class Stack { public:explicit Stack(int maxSize);~Stack();void …...

相机的标定
文章目录 相机的标定标定步骤标定结果影响因素参数分析精度提升一、拍摄棋盘格二、提升标定精度 标定代码实现 相机的标定 双目相机的标定是确保它们能够准确聚焦和成像的关键步骤。以下是详细的标定步骤和可能的结果,同时考虑了不同光照条件和镜头光圈大小等因素对…...
C# 利用XejeN框架源码,编写一个在 Winform 界面上的语法高亮的编辑器,使用 Monaco 编辑器
析锦基于Monaco技术实现的Winform语法高亮编辑器 winform中,我们有时需要高亮显示基于某种语言的语法编辑器。 目前比较强大且UI现代化的,无疑是宇宙最强IDE的兄弟:VS Code。 类似 VS Code 的体验,可以考虑使用 Monaco Editor&a…...

03- jQuery事件处理和动画效果
1. jQuery的事件处理 1.1 绑定事件处理函数 on() 将一个或多个事件的处理方法绑定到被选择的元素上。on()方法适用于当前或未来的元素,如用脚本创建的新元素。 $(selector).on(event,childSelector,data,function) 参数描述event必需。规定要从被选元素添加的一…...
RabbitMQ 入门
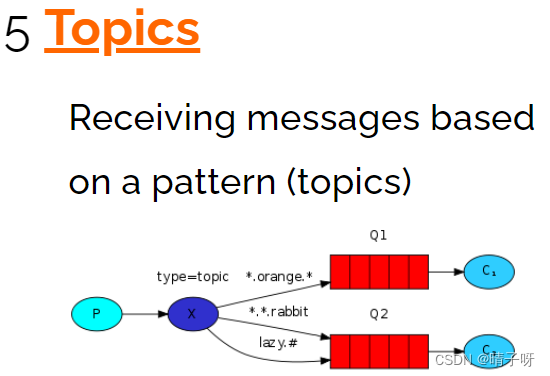
目录 一:什么是MQ 二:安装RabbitMQ 三:在Java中如何实现MQ的使用 RabbitMQ的五种消息模型 1.基本消息队列(BasicQueue) 2.工作消息队列(WorkQueue) 3. 发布订阅(Publish、S…...
物联网协议应用
目录 前言一、WIFI简介二、NTP协议2.1 NTP简介2.2 NTP实现 三、HTTP协议3.1 HTTP协议简介3.2 HTTP服务器 四、MQTT协议4.1 MQTT协议简介4.1.1 MQTT通信模型4.1.2 MQTT协议实现原理4.1.3 MQTT 控制报文 4.2 移植MQTT协议 前言 本文主要介绍一下物联网协议如NTP协议、HTTP协议和M…...

十分钟学会微调大语言模型
有同学给我留言说想知道怎么训练自己的大语言模型,让它更贴合自己的业务场景。完整的大语言模型训练成本比较高昂,不是我们业余玩家能搞的,如果我们只是想在某个业务场景或者垂直的方面加强大模型的能力,可以进行微调训练。 本文…...

结合简单工厂和工厂方法模式:实现灵活的对象创建
前言 在软件开发过程中,创建对象的方式直接影响代码的灵活性和可维护性。设计模式提供了一种解决复杂问题的方法,其中简单工厂模式和工厂方法模式是两种常用的创建型模式。在这篇文章中,我们将结合这两种模式,通过一个实际案例&a…...

网抑云特殊版,登录即永久
前言 今天分享一款特殊版本的音乐软件,相信大家在听网抑云的时候会有两大烦恼, 一是歌曲需要开通VIP才可以收听,不管怎么说也是国内厂商普遍操作 但是第二种烦恼你万万想不到的是,开通了会员后,惊奇的发现ÿ…...

Kotlin 实战小记:No-Arg 引用解决 No constructor found的问题
一、问题 新的项目试用一下kotlin, 调用数据库查询数据的时候报了这个问题:org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.executor.ExecutorException: No constructor found in com.neusoft.collect.entity.cm.CmRoom matc…...
——列表表格)
HTML(5)——列表表格
列表 无序列表 作用:布局排列整齐的不需要规定顺序的区域。 标签:ul嵌套il,ul是无序列表,li是列表条目 注:ul标签只能包裹li标签,li标签可以包含任何内容 有序列表 作用:布局排列整齐的需…...

FreeBSD通过CBSD管理低资源容器jail来安装Ubuntu子系统实践
简介 FreeBSD、CBSD、Jail和Ubuntu,四者的组合方案可以说是强强联合,极具性价比和竞争力!同时安装简单方便,整体方案非常先进。 CBSD是为FreeBSD jail子系统、bhyve、QEMU/NVMM和Xen编写的管理层。该项目定位为一个综合解决方案…...

SpringCloud总结(springcloud alibaba)
目录 版本说明(很重要) springcloud alibaba对应组件版本说明 简述 spring cloud albaba 几大模块 周会讨论 - spring cloud alibaba每周都会有周会讨论,社区活跃 spring cloud alibaba官网 注册配置中心 简单介绍 nacos 步骤 示例代码 依赖…...

轻轻松松上手的LangChain学习说明书
本文为笔者学习LangChain时对官方文档以及一系列资料进行一些总结~覆盖对Langchain的核心六大模块的理解与核心使用方法,全文篇幅较长,共计50000字,可先码住辅助用于学习Langchain。 一、Langchain是什么? 如今各类AI…...

全面对比与选择指南:Milvus、PGVector、Zilliz及其他向量数据库
本文全面探讨了Milvus、PGVector、Zilliz等向量数据库的特性、性能、应用场景及选型建议,通过详细的对比分析,帮助开发者和架构师根据具体需求选择最合适的向量数据库解决方案。 文章目录 向量数据库概述向量数据库的关键功能向量数据库的扩展和选择向量…...

svm 超参数
https://www.cnblogs.com/ChevisZhang/p/12932674.html https://wenku.baidu.com/view/b8a2c73cfd4733687e21af45b307e87100f6f861.html?wkts1718332423081&bdQuerysvm%E7%9A%84%E8%B6%85%E5%8F%82%E6%95%B0 用交叉验证找到最好的参数 C 和γ 。使用 RBF 核时,…...

001-基于Sklearn的机器学习入门:Sklearn库基本功能和标准数据集
本节将介绍Sklearn库基本功能,以及其自带的几个标准数据集的调用方法。本节是学习后面内容的基础,如果您已经对本节内容相当熟悉,可跳过本节内容。 1.1 Sklearn库基本功能 的 1.2 Sklearn库标准数据集 Sklearn自带许多标准数据集ÿ…...

终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件
终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli XNB文件是星露谷物语等XNA游戏引擎使用…...

亿图脑图高级技能:从思维建模到生产力提升的完整指南
1. 项目概述与核心价值最近在整理个人知识库和项目文档时,我一直在寻找一个能让我思维更清晰、协作更高效的“大脑外挂”。市面上思维导图工具不少,但要么功能臃肿、学习曲线陡峭,要么过于轻量、难以应对复杂的结构化思考。直到我深度体验并拆…...

macOS LaunchAgent 开机自启服务配置实战:以 OpenClaw 为例
title: “macOS LaunchAgent 开机自启服务配置实战:以 OpenClaw 为例” tags: macOSLaunchAgent开机自启launchdOpenClaw categories:macOS description: “从原理到实战,详解 macOS LaunchAgent 的配置方法,以 OpenClaw Gateway 和 CLIProx…...

书成紫微动,律定凤凰驯:从无心创作到天命显化的海棠山铁哥之路
书成紫微动,律定凤凰驯。 ——南北朝庾信一、千古谶语,千年未解诗句天道逻辑千年误读书成紫微动先著书立道,撼动文脉附会玄学,强行造神律定凤凰驯再定规立序,祥瑞归宁脑会剧情,虚妄狂欢 无人真正落地&#…...

AI智能体技能开发实战:从awesome-agent-skills到工程化应用
1. 项目概述:一个智能体技能的知识宝库最近在折腾AI智能体(Agent)开发,发现一个挺有意思的现象:大家都能用LangChain、AutoGen这些框架搭出个智能体的架子,但真想让这个“智能体”干点具体、有用、甚至有点…...

AI与Web3融合:Solana开发者工具箱core-ai架构解析与实践
1. 项目概述:当AI遇见Web3,一个开发者工具箱的诞生最近在Web3和AI的交叉领域里折腾,发现了一个挺有意思的项目——helius-tech-labs/core-ai。这名字听起来就很有野心,core(核心)和ai(人工智能&…...

CTF新手必看:用010 Editor修复PNG图片CRC错误,轻松拿下BUUCTF那道‘一叶障目’题
CTF新手实战:用010 Editor修复PNG图片CRC校验错误 拿到一张打不开的PNG图片,显示"CRC校验失败"?别急着放弃,这可能是CTF比赛中故意设置的陷阱。作为MISC方向的经典题型,修改PNG文件头参数是常见的出题套路。…...

国省考备考常见 10 大误区 上岸考生总结
作为上岸过来人,我太懂 “努力却没结果” 的无力。其实公考失败,大多不是不够努力,而是踩了本可以避开的坑。这 10 条避坑指南,覆盖备考方向、复习方法、心态调整,全是实战总结的干货,帮备考的你少走弯路。…...

如何让GPT-3开口说话?揭秘微调技巧,打造你的专属AI模型!
本文详细介绍了微调技术在AI模型中的应用,通过将通用模型如GPT-3进行微调,可以使其适应特定任务,如ChatGPT或GitHub Copilot。微调与普通提示词工程最大的区别在于,它能真正让模型学会数据,而非仅仅是“看到”数据。文…...

ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程
ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com/gh_mir…...