MyBatis系列七: 一级缓存,二级缓存,EnCache缓存
缓存-提高检索效率的利器
- 官方文档
- 一级缓存
- 基本介绍
- 快速入门
- Debug一级缓存执行流程
- 一级缓存失效分析
- 二级缓存
- 基本介绍
- 快速入门
- Debug二级缓存执行流程
- 注意事项和使用细节
- mybatis的一级缓存和二级缓存执行顺序
- 小实验
- 细节说明
- EnCache缓存
- 基本介绍
- 配置和使用EhCache
- 细节说明
- MyBatis逆向工程

官方文档
官方文档: https://mybatis.org/mybatis-3/zh_CN/sqlmap-xml.html#cache
一级缓存
基本介绍
●基本说明
1.默认情况下, mybatis是启用一级缓存的/本地缓存/local Cache, 它是SqlSession级别的.
2.同一个SqlSession接口对象调用了相同的select语句, 会直接从缓存里面获取, 而不是再去查询数据库
●一级缓存原理图 [简单追一下源码, 后面再Debug]
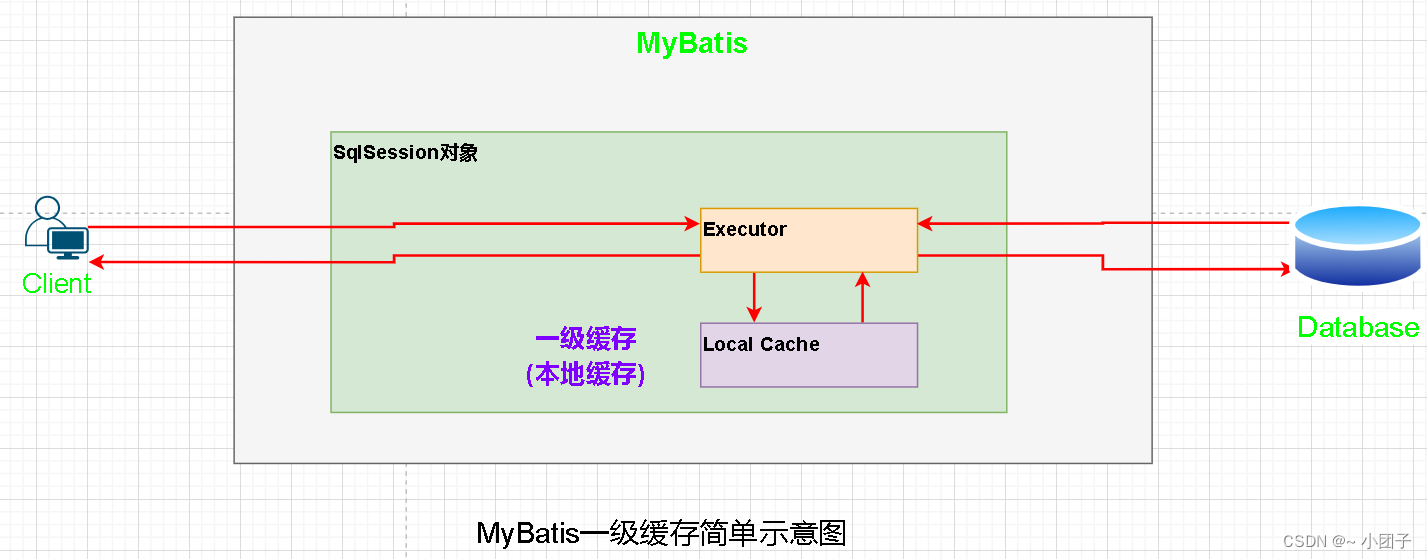
快速入门
需求: 当我们第1次查询 id=1的Monster后, 再次查询id=1的monster对象, 就会直接从一级缓存获取, 不会再次发出sql
●代码实现
1.创建新的 module: mybatis_cache, 必要的文件和配置直接从 mybatis_quickstart module 拷贝即可 [新建子模块参考]
2.需要拷贝的文件和配置如图
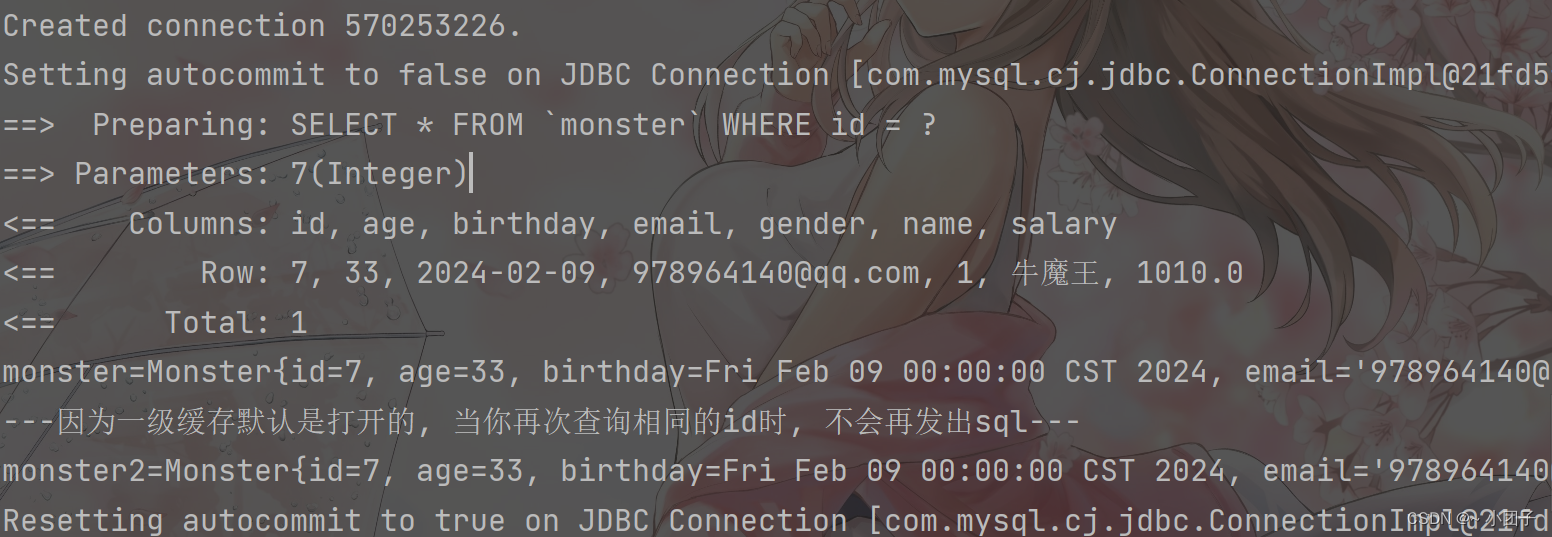
3.使用MonsterMapperTest.java, 运行 getMonsterById() 看看是否可以看到日志输出, 结构我们多次执行, 总是会发出SQL
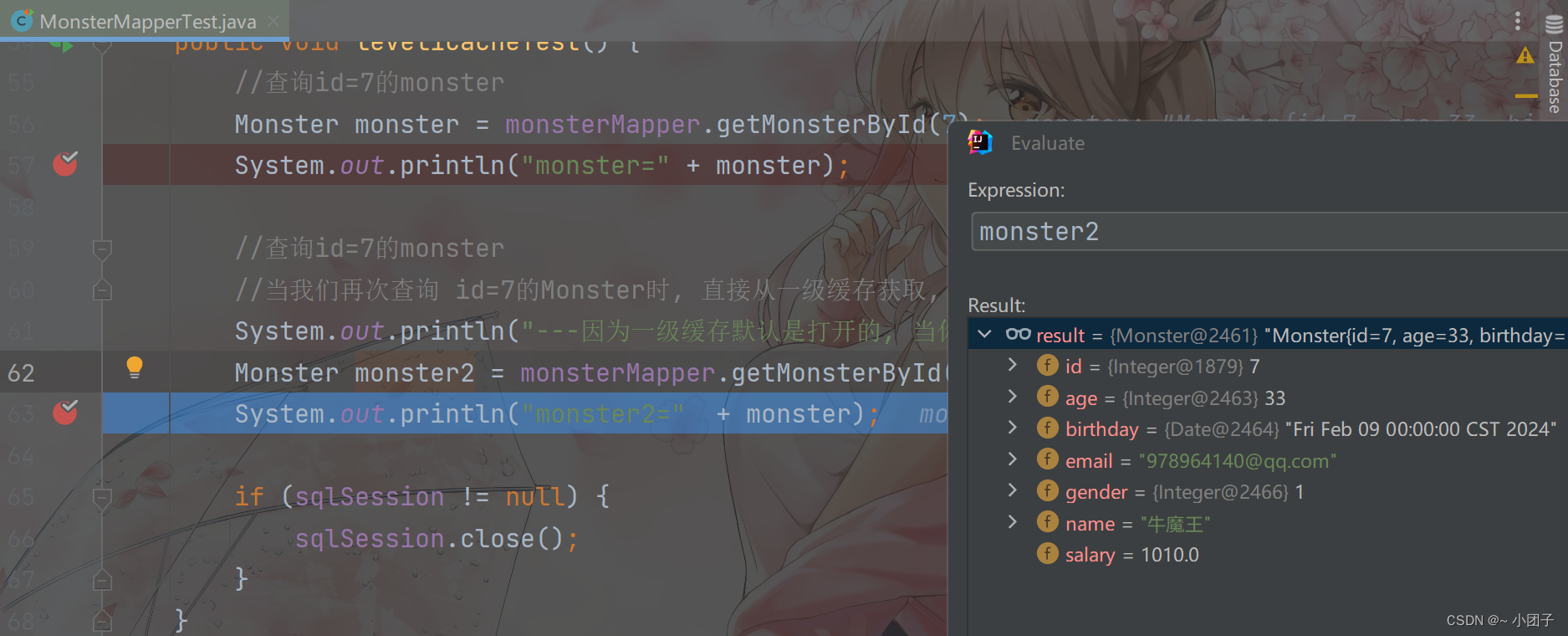
4.修改MonsterMapperTest.java, 增加测试方法, 测试一级缓存的基本使用 + Debug源码
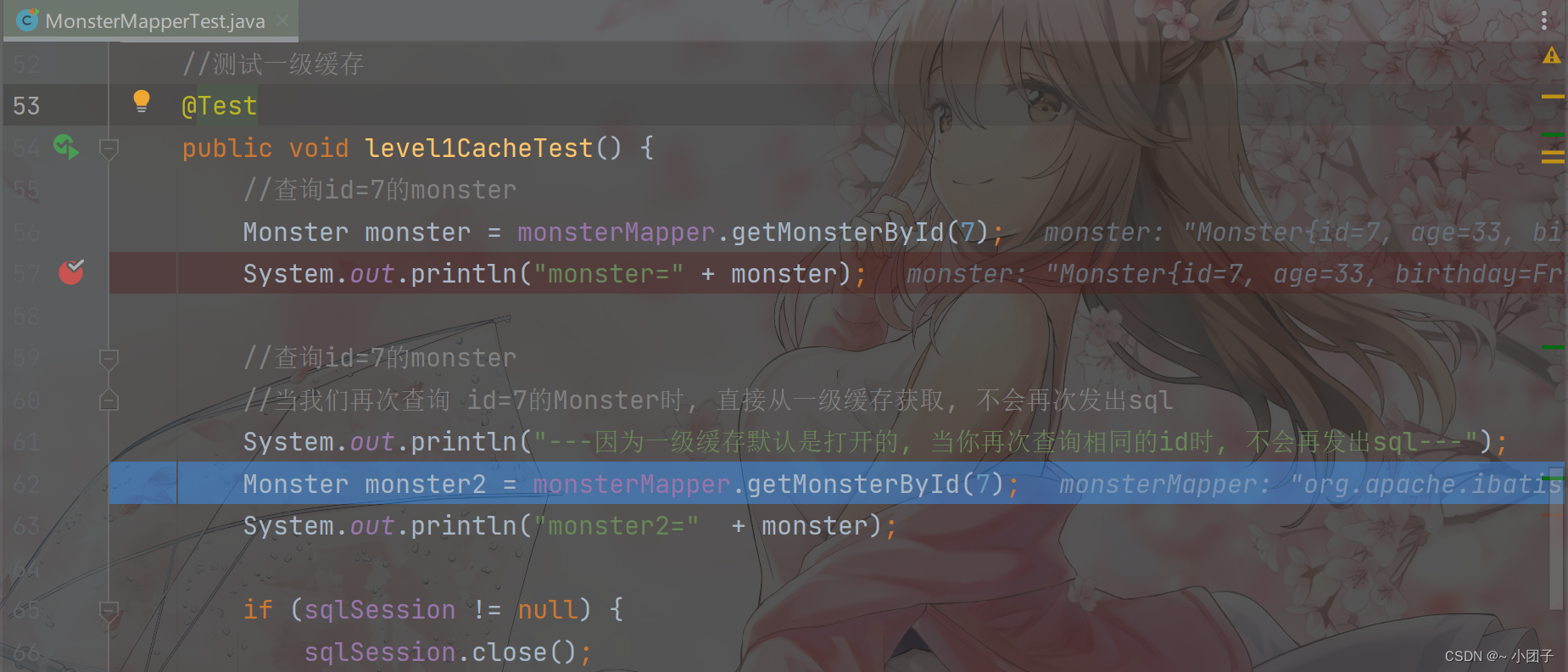
//测试一级缓存
@Test
public void level1CacheTest() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);System.out.println("monster=" + monster);//查询id=7的monster//当我们再次查询 id=7的Monster时, 直接从一级缓存获取, 不会再次发出sqlSystem.out.println("---因为一级缓存默认是打开的, 当你再次查询相同的id时, 不会再发出sql---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);if (sqlSession != null) {sqlSession.close();}
}
Debug一级缓存执行流程
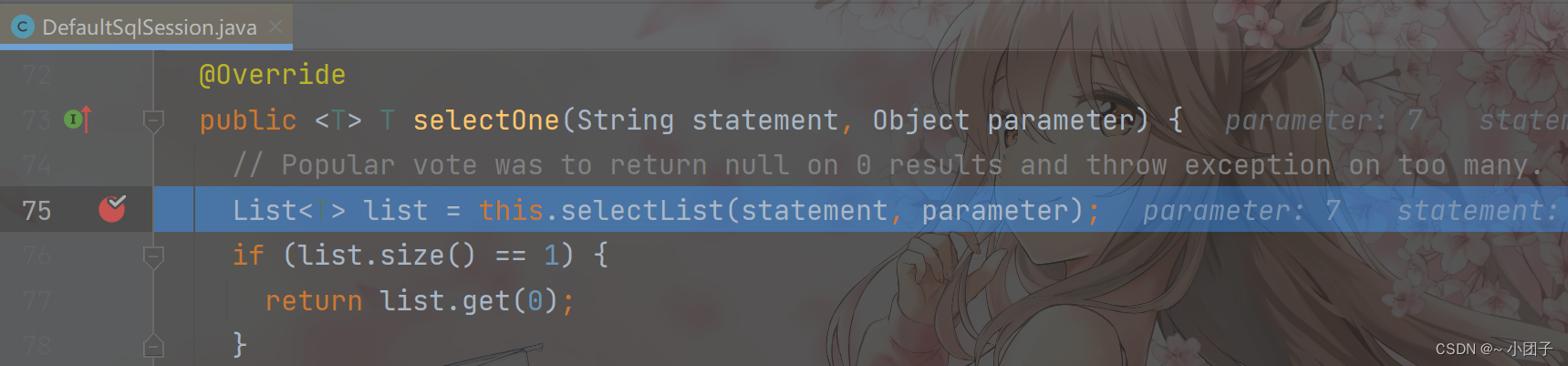
进入 Step Into

进入 Step Into

进入 Step Into
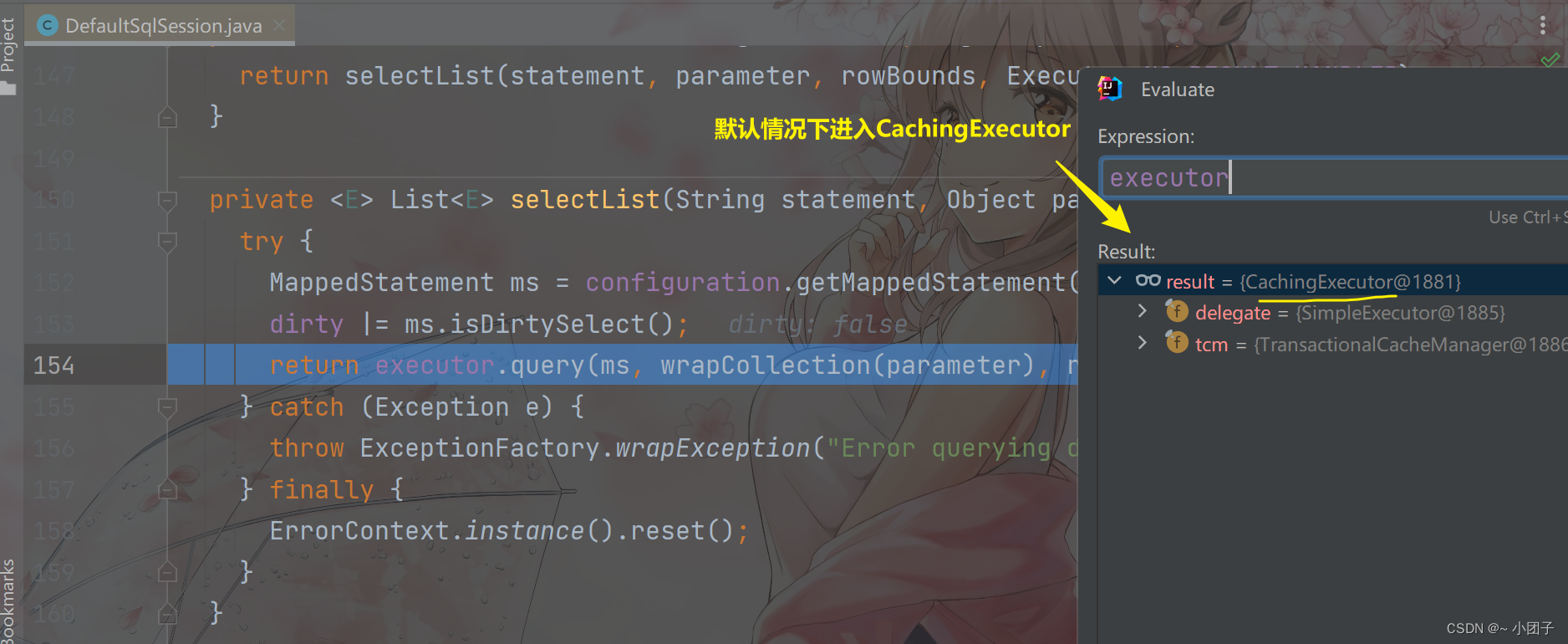
进入 Step Into
进入 Step Into
进入 Step Into
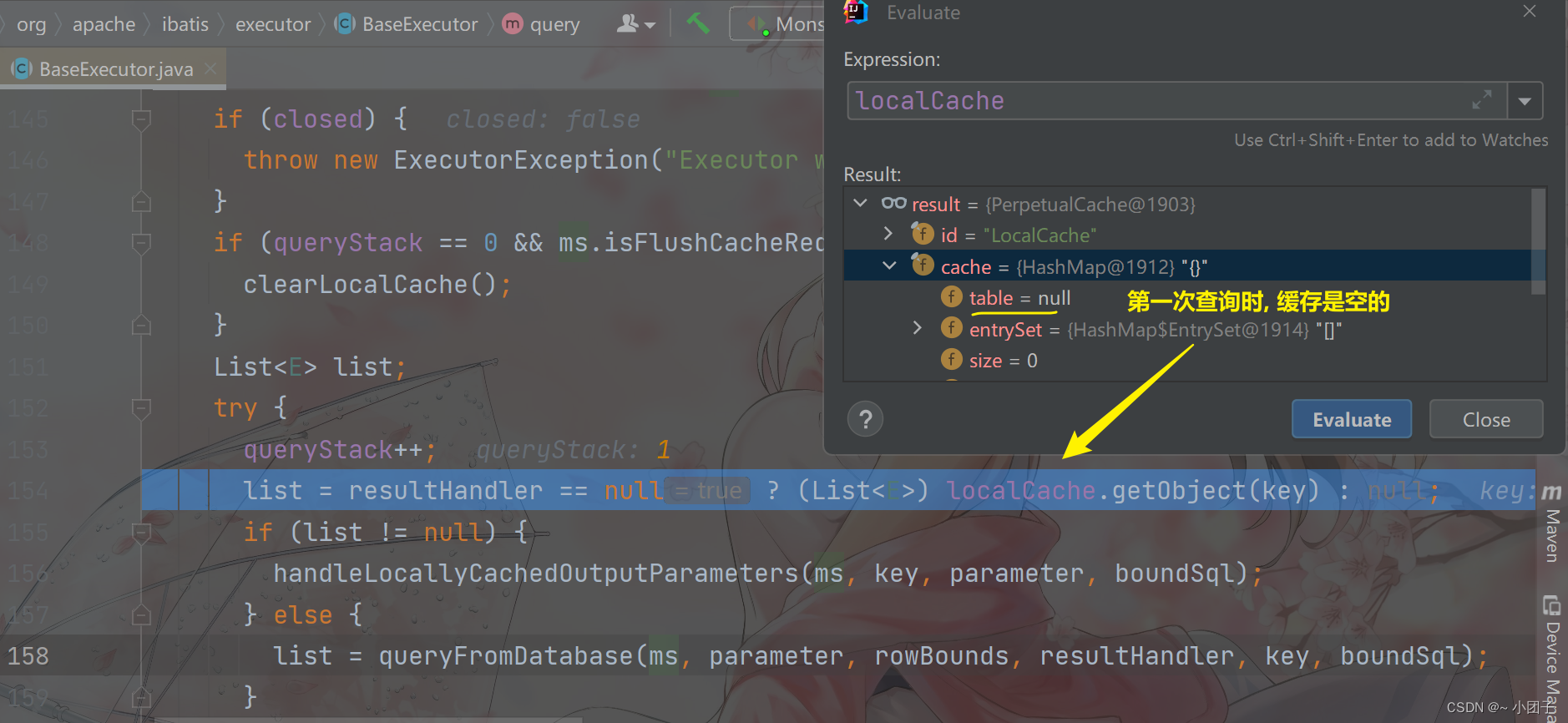
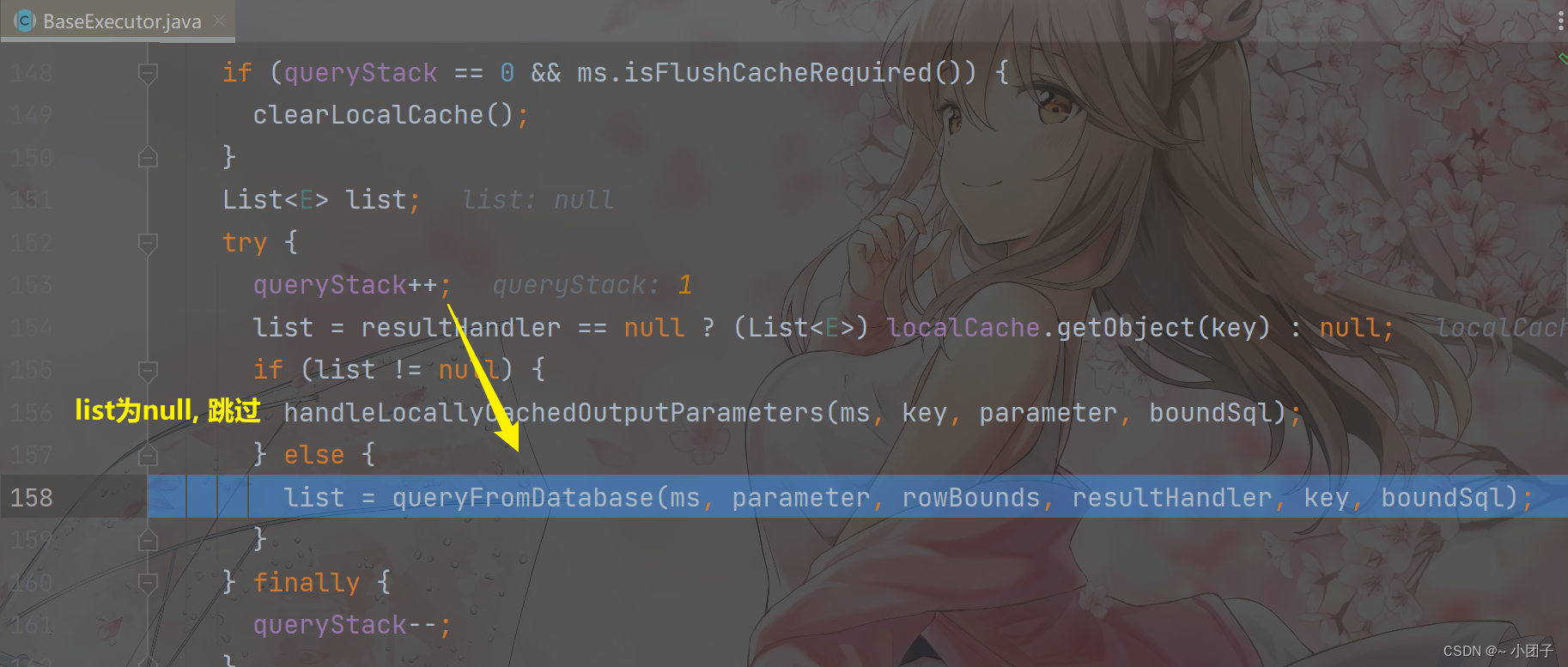
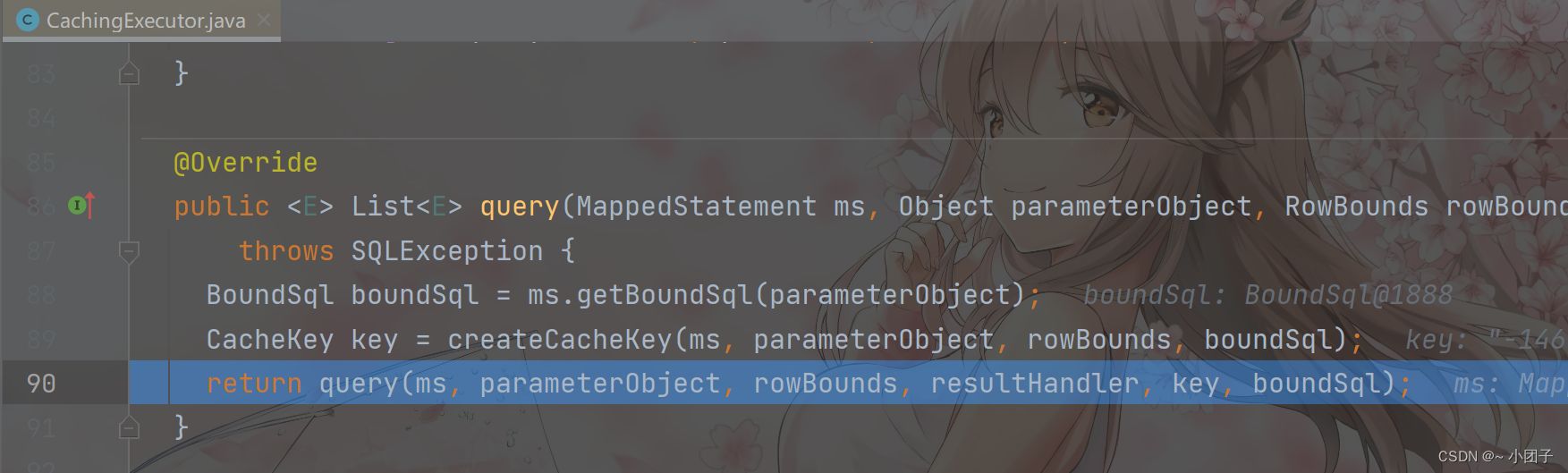
进入 Step Into
放行 Resume Program
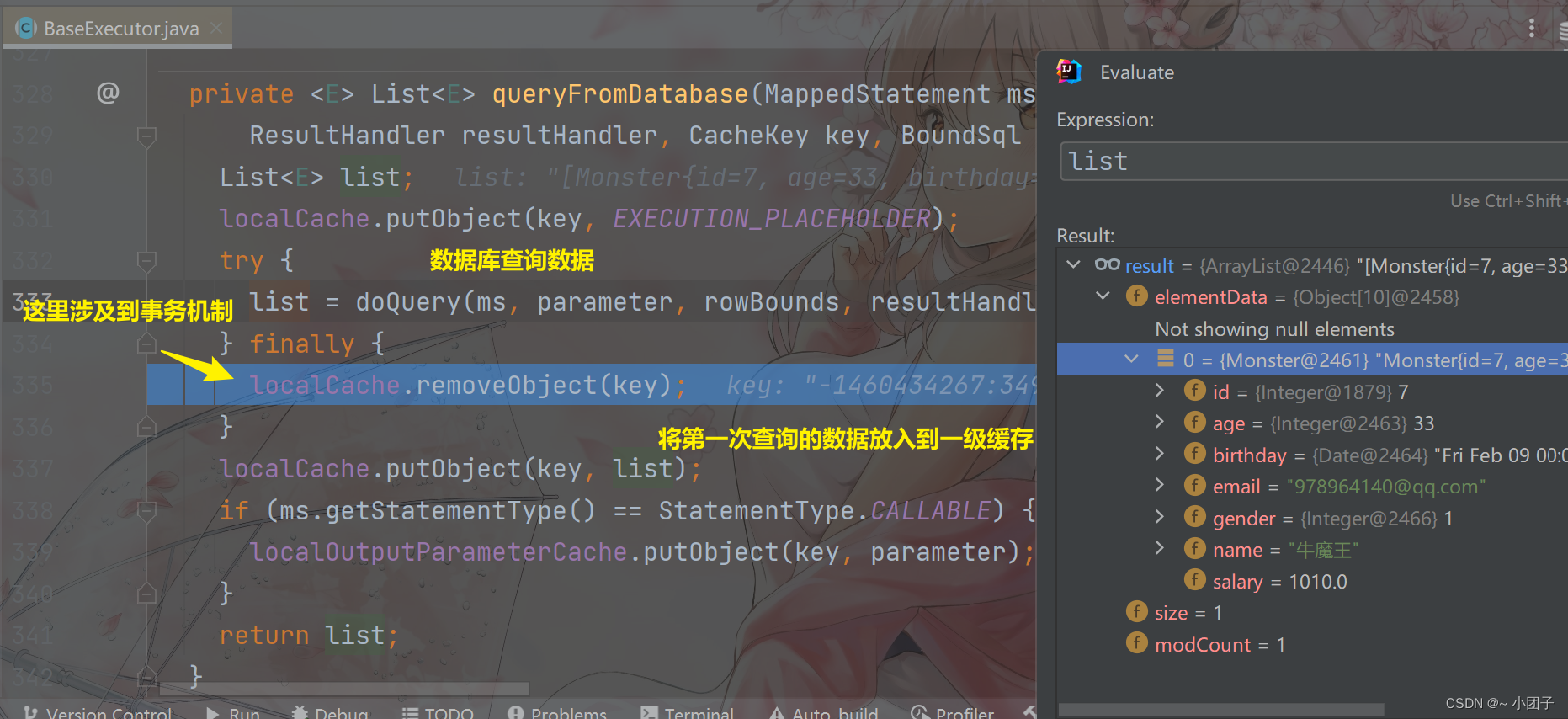
第二次Debug
放行 Resume Program
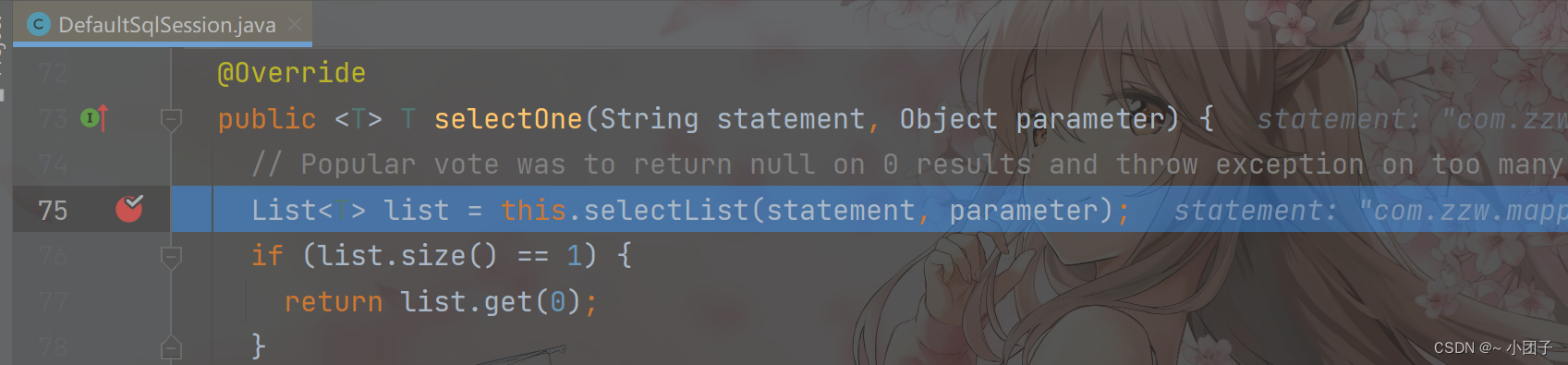
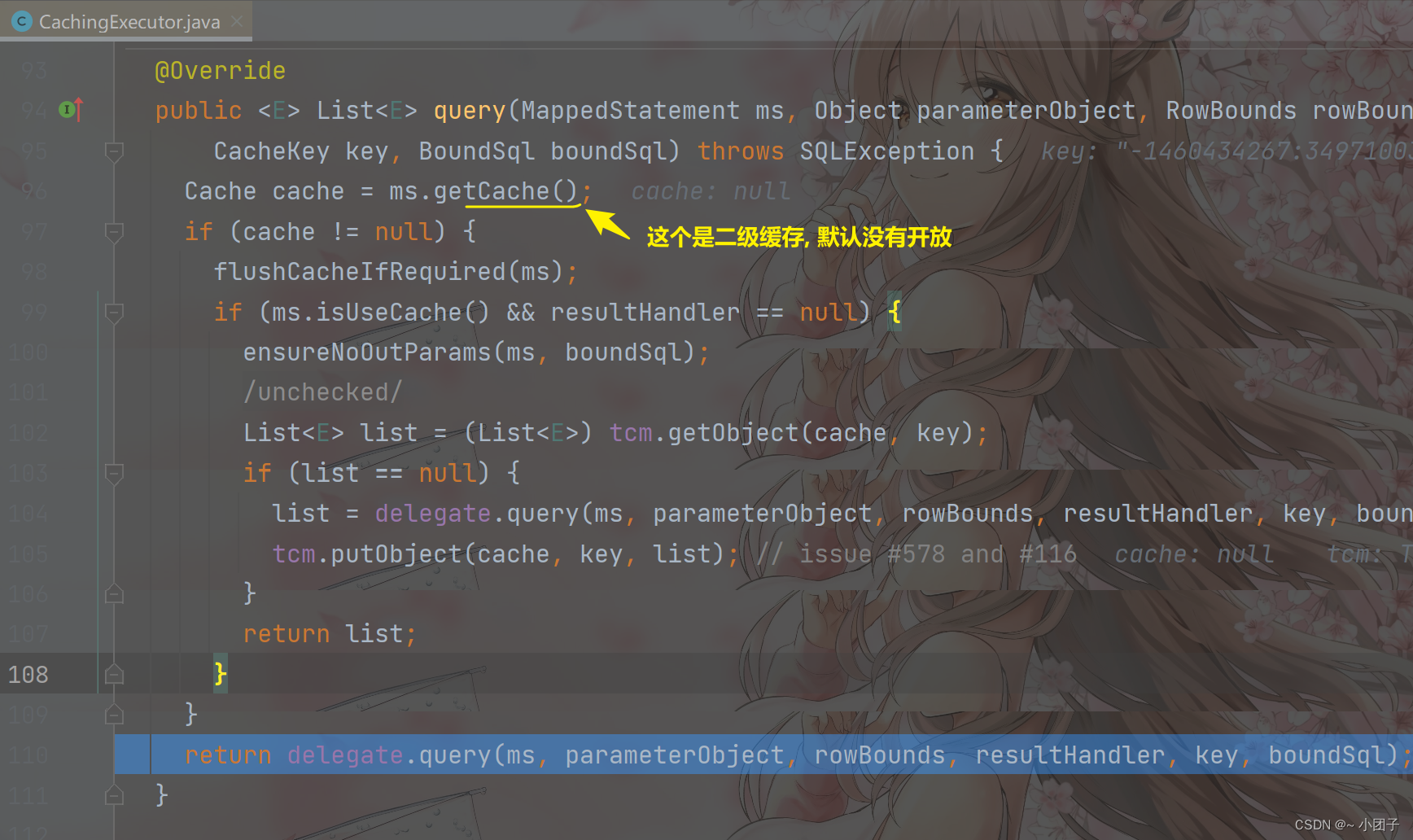
进入 Step Into
进入 Step Into
进入 Step Into
进入 Step Into
进入 Step Into
进入 Step Into
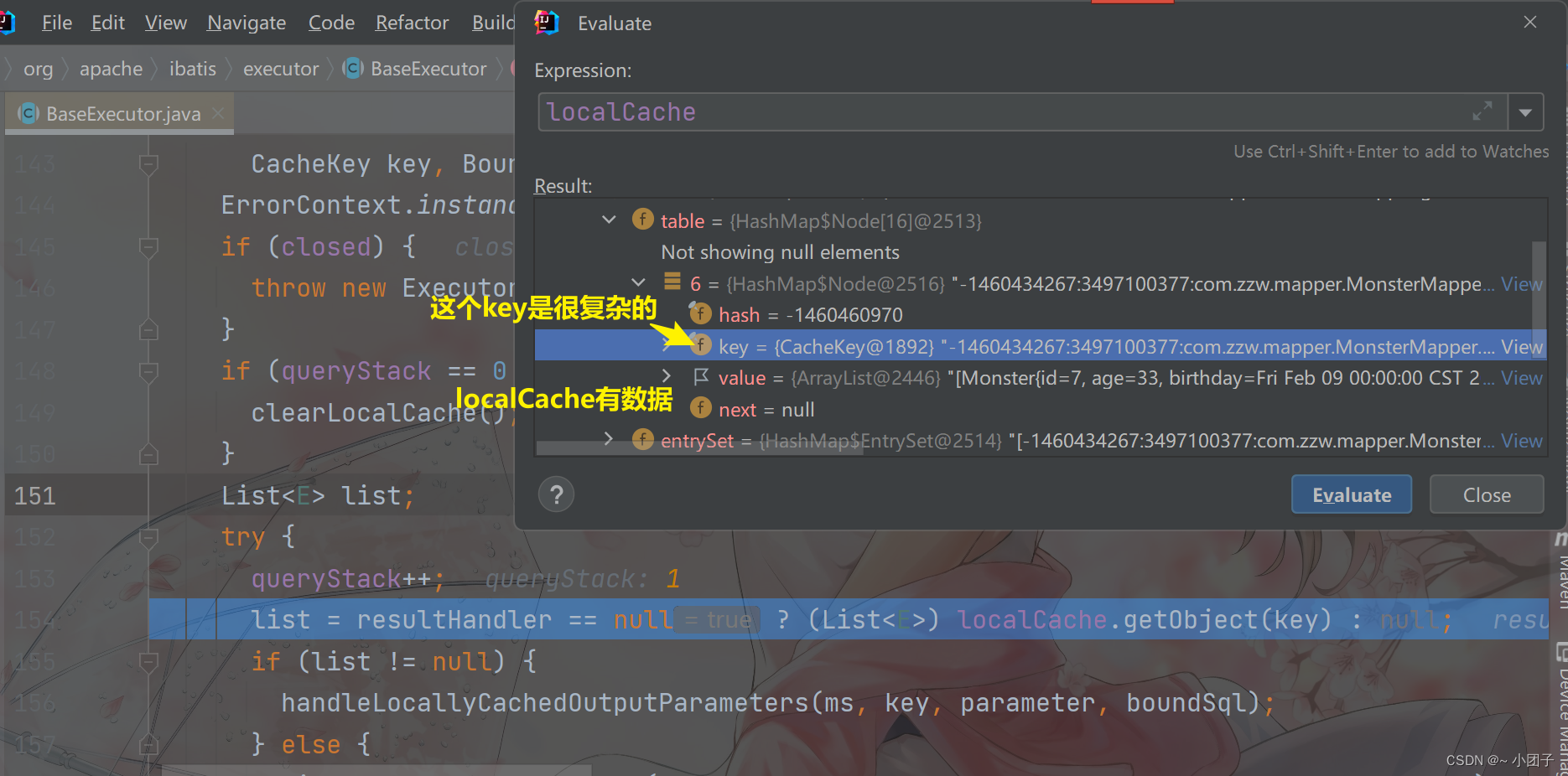
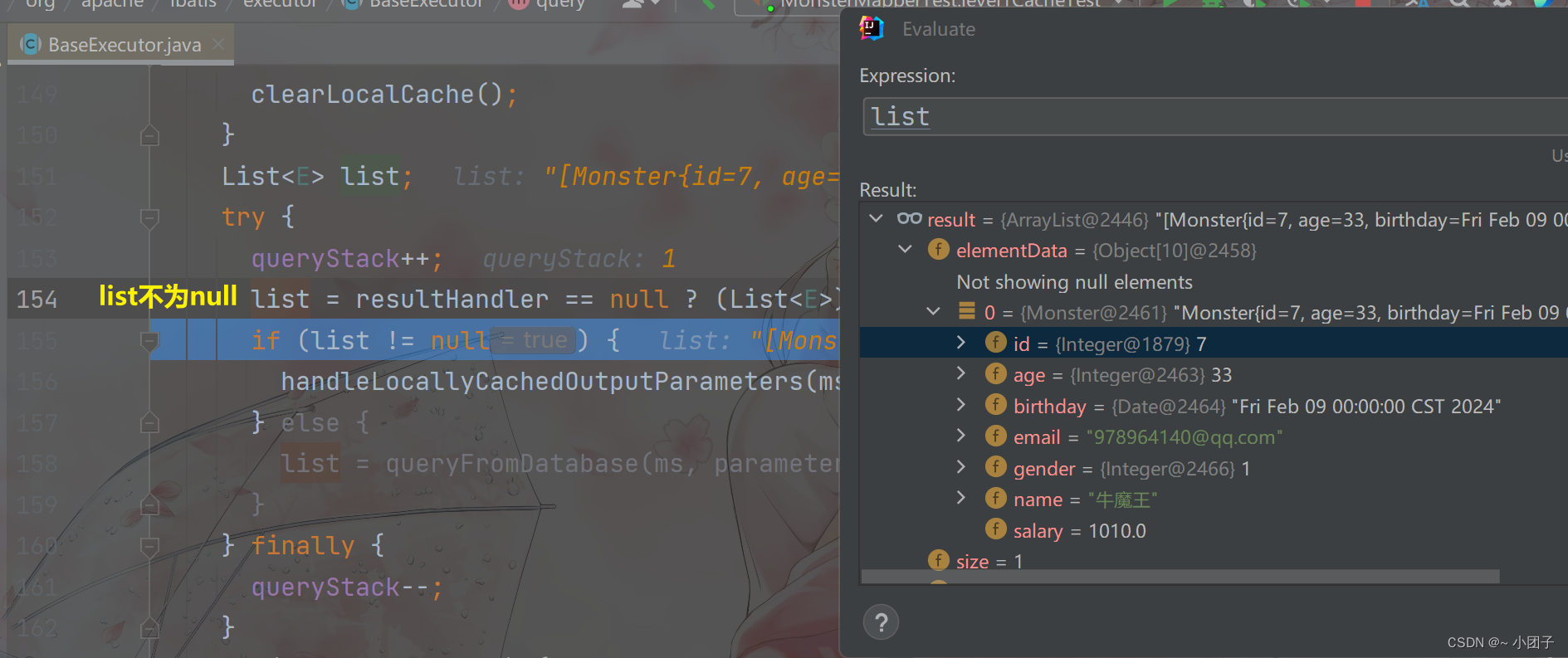
放行 Resume Program
●sqlSession的结构示意图
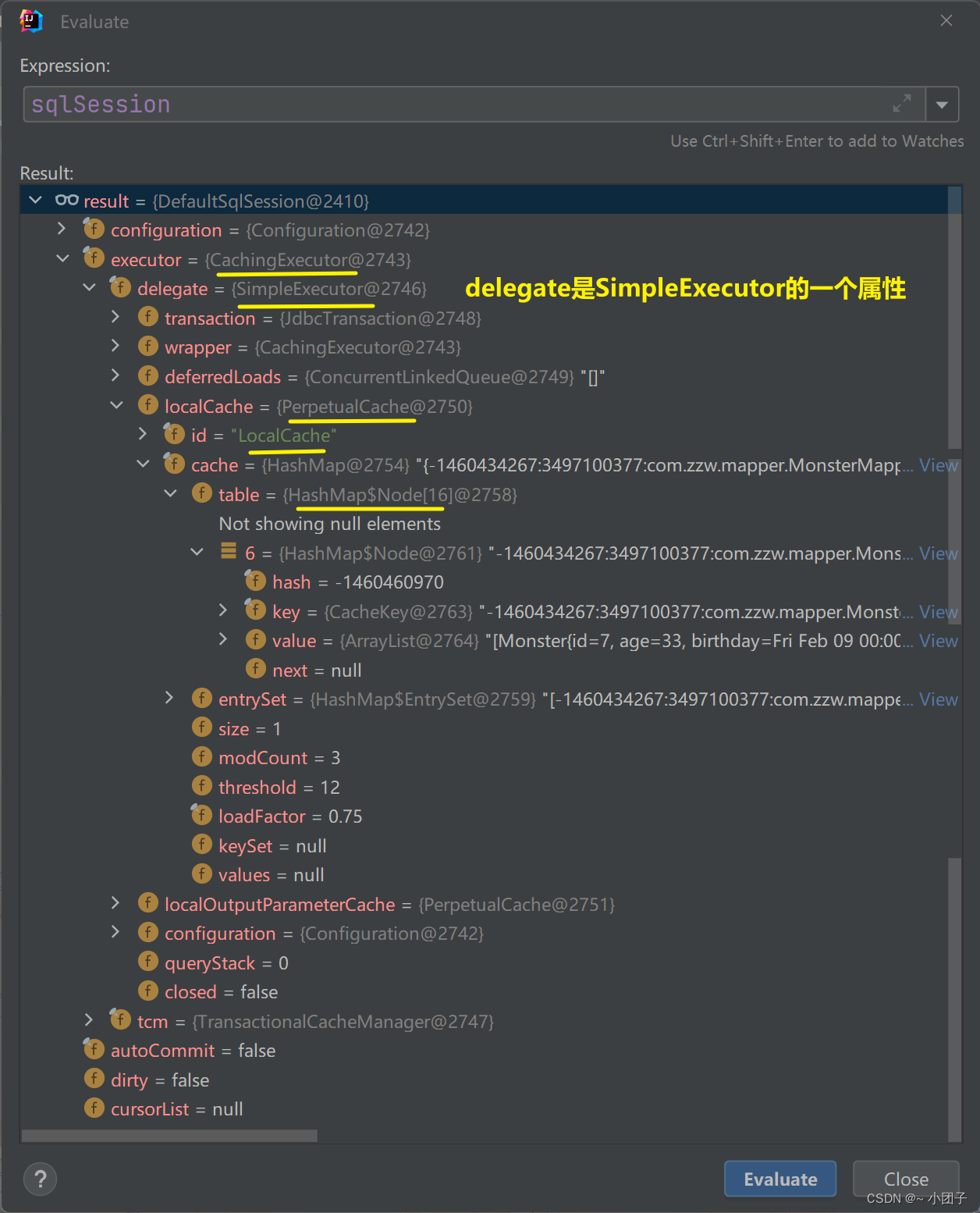
一级缓存失效分析
1.关闭sqlSession会话后, 再次查询, 会到数据库查询, 修改MonsterMapperTest.java, 测试一级缓存失效情况
//测试一级缓存,失效
//关闭sqlSession会话后, 一级缓存失效
@Test
public void level1CacheTest2() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);System.out.println("monster=" + monster);//关闭sqlSession, 一级缓存失效if (sqlSession != null) {sqlSession.close();}//因为关闭了sqlSession, 所以需要重新初始化sqlSession和 monsterMappersqlSession = MyBatisUtils.getSqlSession();monsterMapper = sqlSession.getMapper(MonsterMapper.class);//查询id=7的monster//当我们再次查询 id=7的Monster时, 直接从一级缓存获取, 不会再次发出sqlSystem.out.println("---如果你关闭了sqlSession, 当你再次查询相同的id时, 仍然会会发出sql---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);if (sqlSession != null) {sqlSession.close();}
}
2.当执行selSession.clearChche() 会使一级缓存失效, 修改MonsterMapperTest.java, 测试一级缓存失效情况
//测试一级缓存,失效
//如果执行sqlSession.clearCache(), 会导致一级缓存失效
@Test
public void level1CacheTest3() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);System.out.println("monster=" + monster);//执行clearCache/*** @Override* public void clearCache() {* executor.clearLocalCache();* }*/sqlSession.clearCache();//查询id=7的monsterSystem.out.println("---如果你执行了sqlSession.clearCache(), 当你再次查询相同的id时, 仍然会会发出sql---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);if (sqlSession != null) {sqlSession.close();}
}
3.当对同一个monster修改, 该对象在一级缓存会失效, 修改MonsterMapperTest.java, 测试一级缓存失效情况
//测试一级缓存,失效
//如果修改了同一个对象, 会导致一级缓存[对象数据]失效
@Test
public void level1CacheTest4() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);System.out.println("monster=" + monster);//如果修改了同一个对象, 会导致一级缓存[对象数据]失效monster.setName("赵志伟^_^");monsterMapper.updateMonster(monster);//查询id=7的monsterSystem.out.println("---如果你修改了同一个对象, 当你再次查询相同的id时, 仍然会发出sql---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);if (sqlSession != null) {sqlSession.commit();//这里需要commitsqlSession.close();}
}
二级缓存
基本介绍
●基本介绍
1.二级缓存和一级缓存都是为了提高检索效率的技术
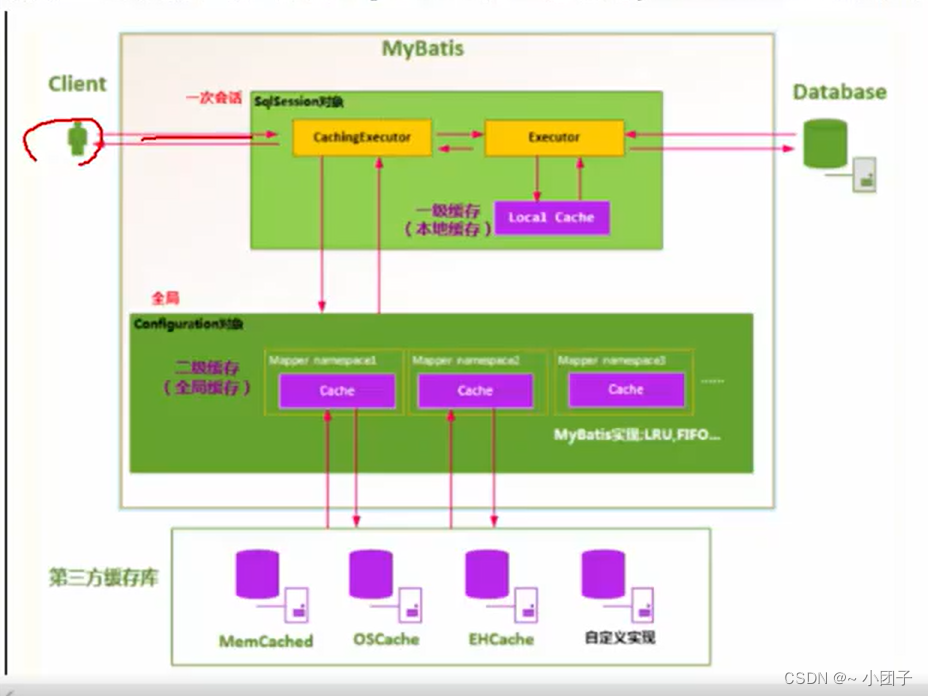
2.最大的区别就是作用域的范围不一样, 一级缓存的作用域是sqlSession会话级别, 在一次会话中有效. 而二级缓存作用域是全局范围, 针对不同的会话都有效.
●二级缓存原理图
快速入门
1.mybatis-config.xml配置中开启二级缓存
<!--配置MyBatis自带的日志输出-查看原生的sqlDOCTYPE规定 <settings/>节点/元素 必须在前面, 放在后面会报错
-->
<settings><setting name="logImpl" value="STDOUT_LOGGING"/><!--1.全局性地开启或关闭所有映射器配置文件中已配置的任何缓存2.默认就是: true--><setting name="cacheEnabled" value="true"/>
</settings>
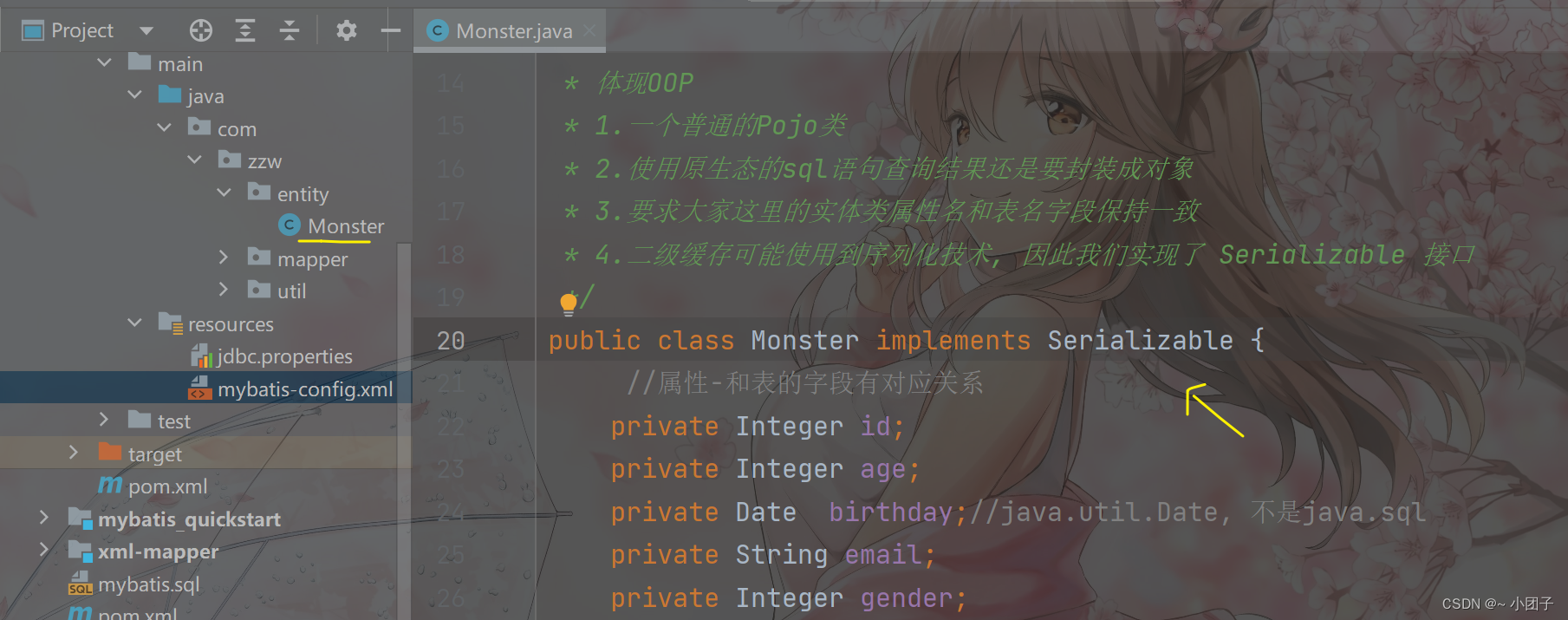
2.使用二级缓存时entity类实现序列化接口(serialize), 因为二级缓存可能使用到序列化技术
3.在对应的XxxMapper.xml 中设置二级缓存的策略
<!--
1.配置二级缓存
2.FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3.flushInterval 刷新间隔 是毫秒单位 60000, 表示 60s
4.size="512": 引用数目, 属性可以被设置为任意正整数, 默认1024
5.readOnly="true": (只读)属性可以被设置为 true 或 false: 如果我们只是用于读操作, 建议设置成 true, 这样可以提高效率. 如果有修改操作, 设置成 false, 默认就是false
-->
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
4.修改MonsterMapperTest.java, 完成测试
//测试二级缓存
@Test
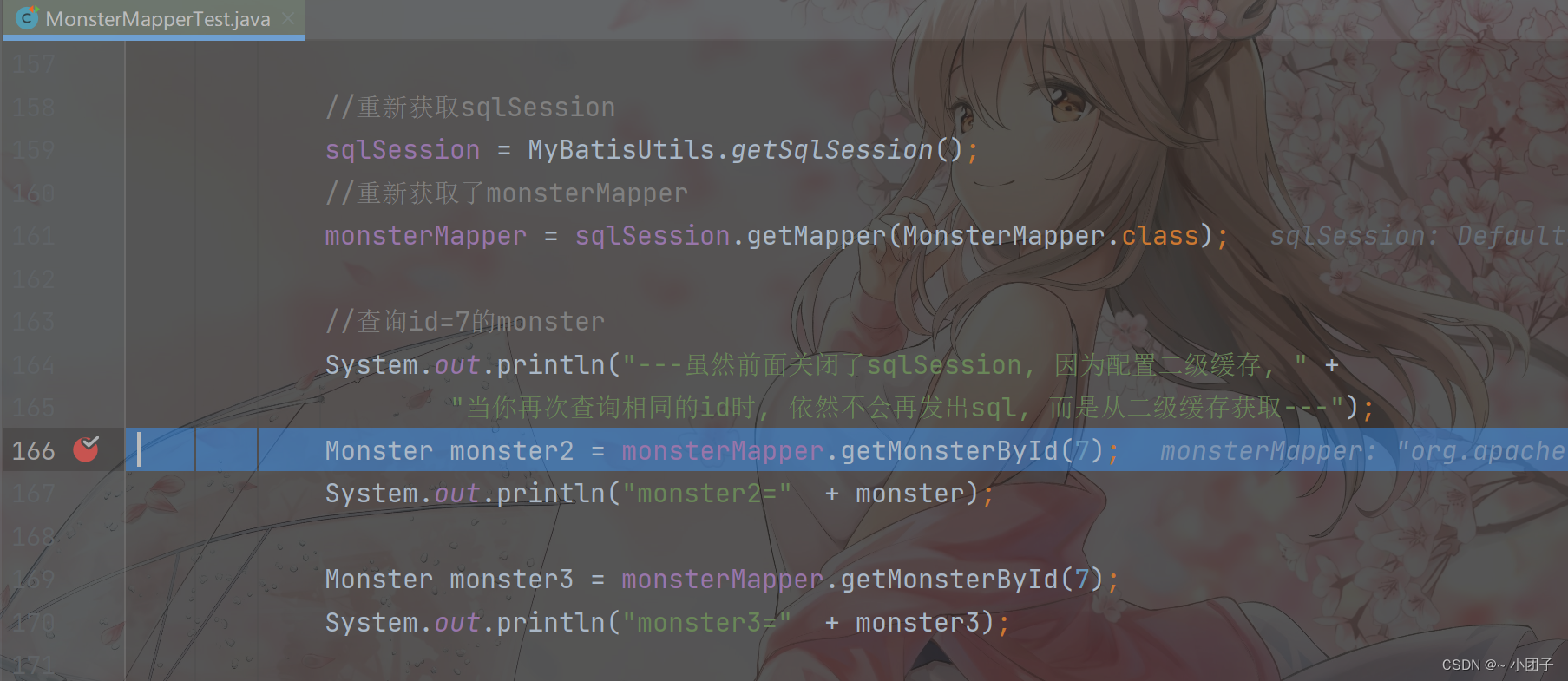
public void level2CacheTest() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);System.out.println("monster=" + monster);//这里我们关闭sqlSessionif (sqlSession != null) {sqlSession.close();}//重新获取sqlSessionsqlSession = MyBatisUtils.getSqlSession();//重新获取了monsterMappermonsterMapper = sqlSession.getMapper(MonsterMapper.class);//查询id=7的monsterSystem.out.println("---虽然前面关闭了sqlSession, 因为配置二级缓存, " +"当你再次查询相同的id时, 依然不会再发出sql, 而是从二级缓存获取---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);Monster monster3 = monsterMapper.getMonsterById(7);System.out.println("monster3=" + monster3);if (sqlSession != null) {sqlSession.close();}
}
Debug二级缓存执行流程
●观察Debug二级缓存执行流程[debug主线即可]
放行 Resume Program
进入 Step Into
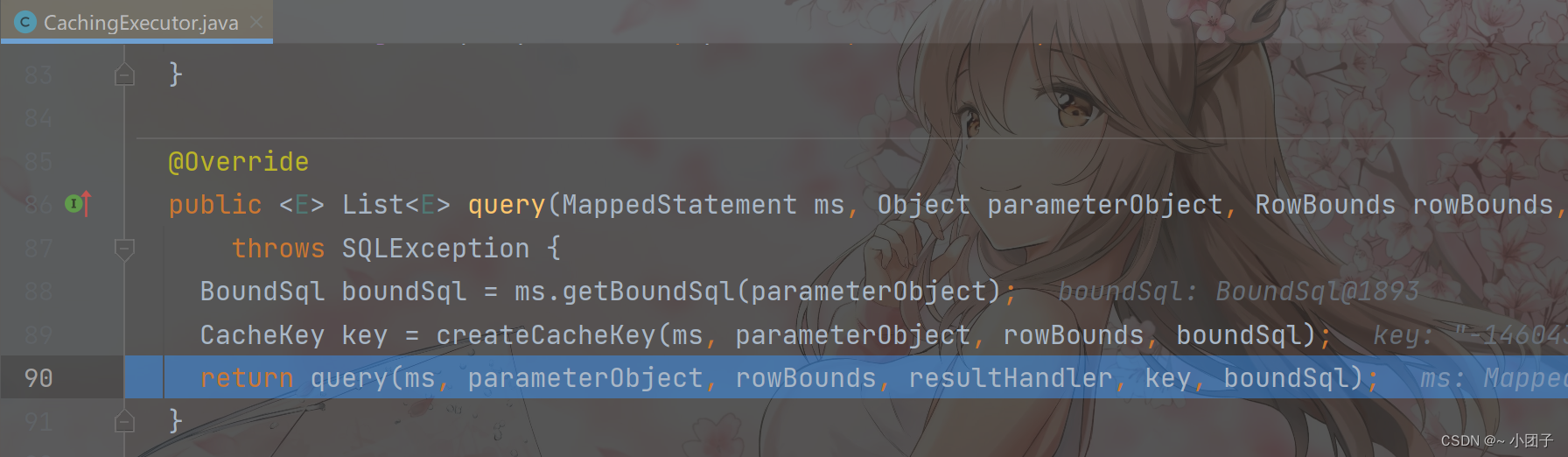
进入 Step Into
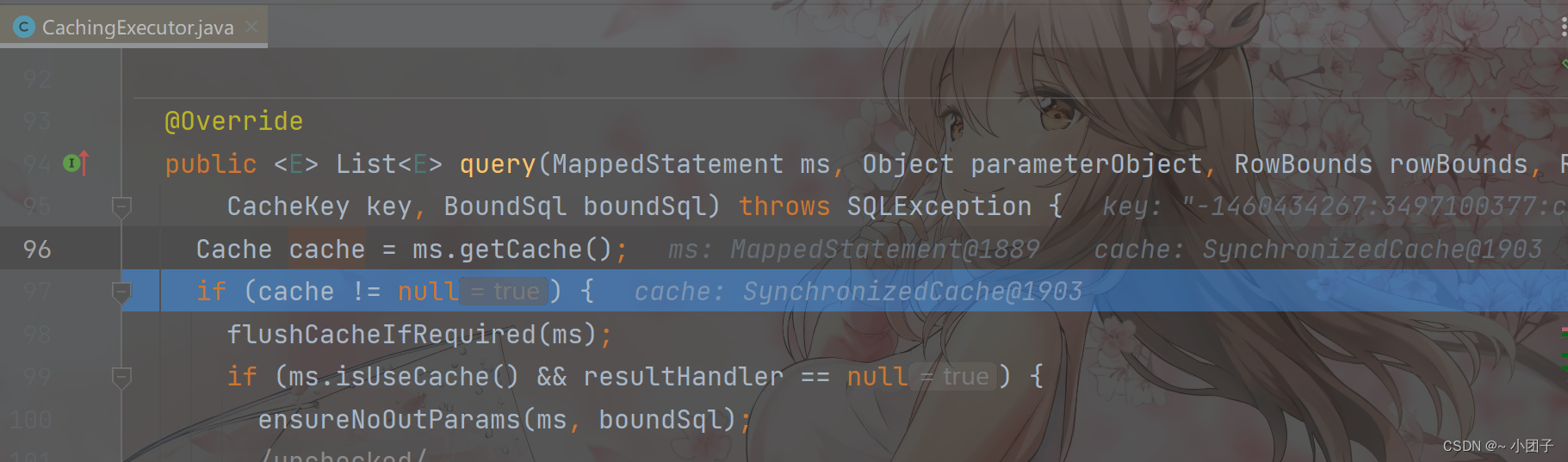
放行 Resume Program
放行 Resume Program
进入 Step Into
进入 Step Into
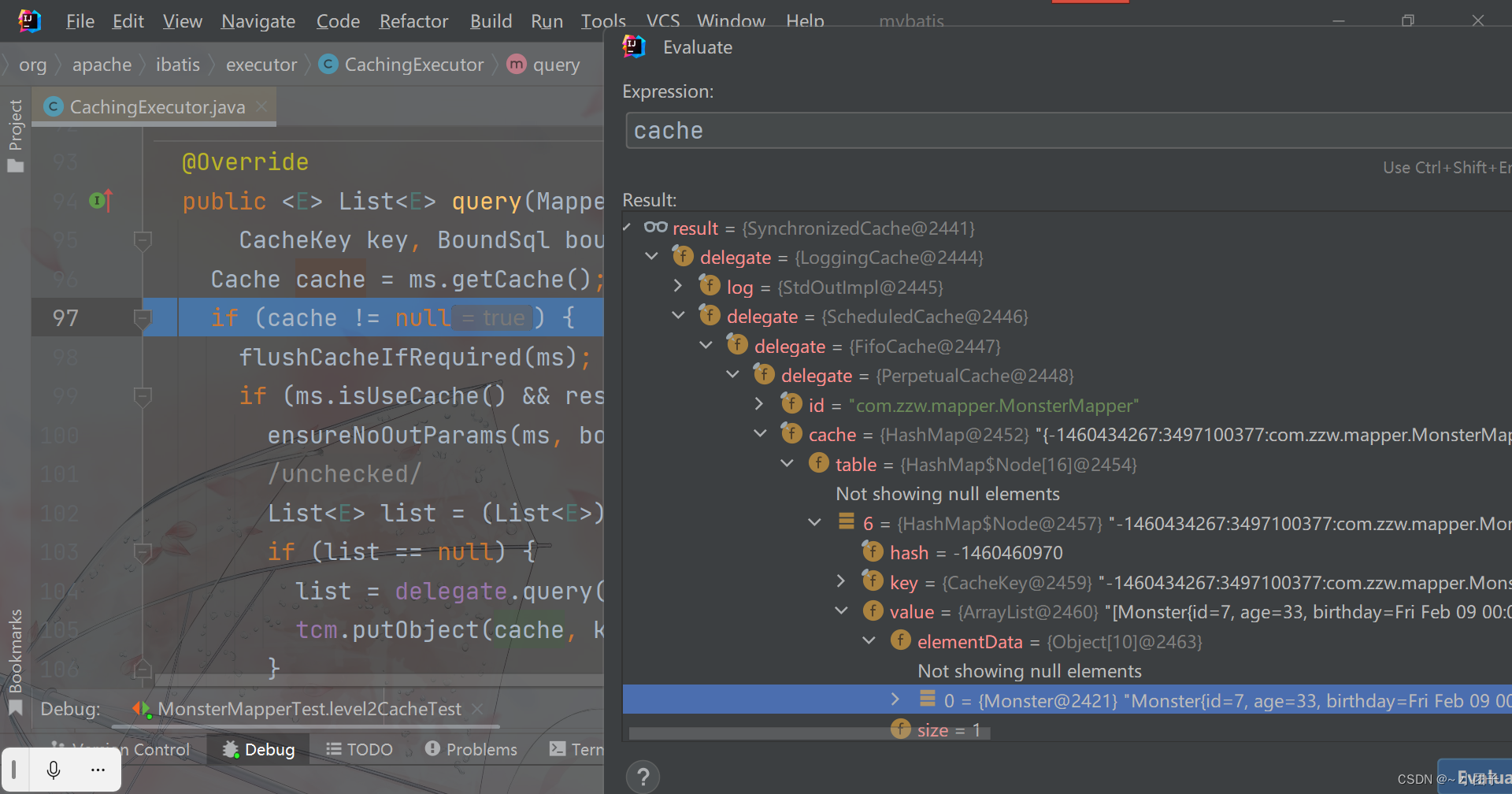
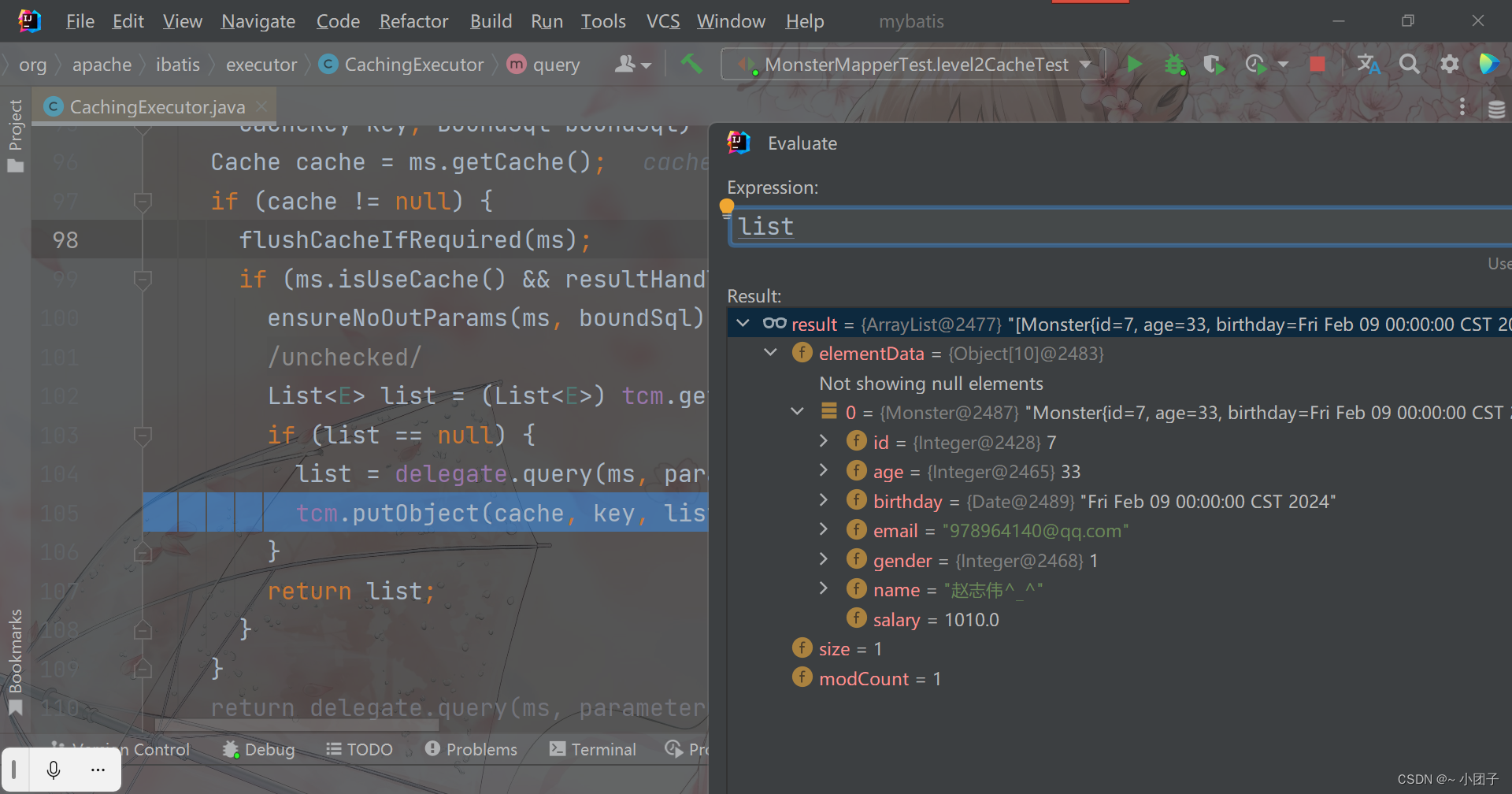
注意事项和使用细节
1.理解二级缓存策略的参数
<cache eviction=“FIFO” flushInterval=“60000” size=“512” readOnly=“true”/>
上面的配置含义如下:
创建了FIFO的策略, 每隔60秒刷新一次, 最多存放512个对象而且返回的对象被认为是只读的,
eviction: 缓存的回收策略
flushInterval: 时间间隔, 单位是毫秒
size: 引用数目, 内存大就多配置点, 要记住你缓存的对象数目要和你运行环境的可用内存资源数目对应. 默认值是1024
readOnly:true 只读
2.四大策略
√ LRU - 最近最少使用的: 移除最长时间不被使用的对象, 它是默认
√ FIFO - 先进先出: 按对象进入缓存的顺序来移除它们
√ SOFT - 软引用: 移除基于垃圾回收器状态和软引用规则的对象
√ WEAK - 弱引用: 更积极地移除基于垃圾回收器状态和弱引用规则的对象
3.如何禁用二级缓存
1)修改mybatis-config.xml
<settings><setting name="logImpl" value="STDOUT_LOGGING"/><!--1.全局性地开启或关闭所有映射器配置文件中已配置的任何缓存, 可以理解这是一个总开关2.默认就是: true--><setting name="cacheEnabled" value="false"/>
</settings>
2)修改映射器文件MonsterMapper.xml
<!--<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>-->
3)或者更加细粒度的, 直接在配置方法上指定
<!--配置/实现getMonsterById-->
<select id="getMonsterById" resultType="Monster" useCache="false">SELECT * FROM `monster` WHERE id = #{id}
</select>
设置useCache=false可以禁用当前select语句的二级缓存, 即每次查询都会发出sql去查询, 默认情况是true, 即该sql使用二级缓存.
注意: 一般我们不需要去修改, 使用默认的即可
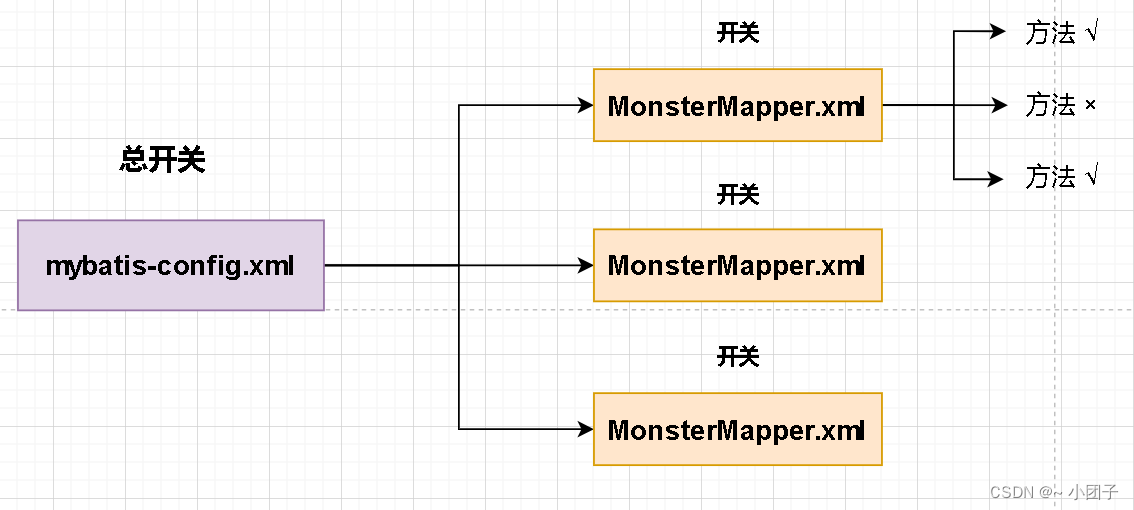
4.mybatis刷新二级缓存的设置
<update id="updateMonster" parameterType="Monster" flushCache="true">UPDATE `monster` SET `age` = #{age}, `birthday` = #{birthday}, `email` = #{email},`gender` = #{gender}, `name` = #{name}, `salary` = #{salary} WHERE id = #{id}
</update>
insert, update, delete操作数据后需要刷新缓存, 如果不执行刷新缓存会出现脏读
默认为true, 默认情况下为true即刷新缓存, 一般不用修改.
mybatis的一级缓存和二级缓存执行顺序
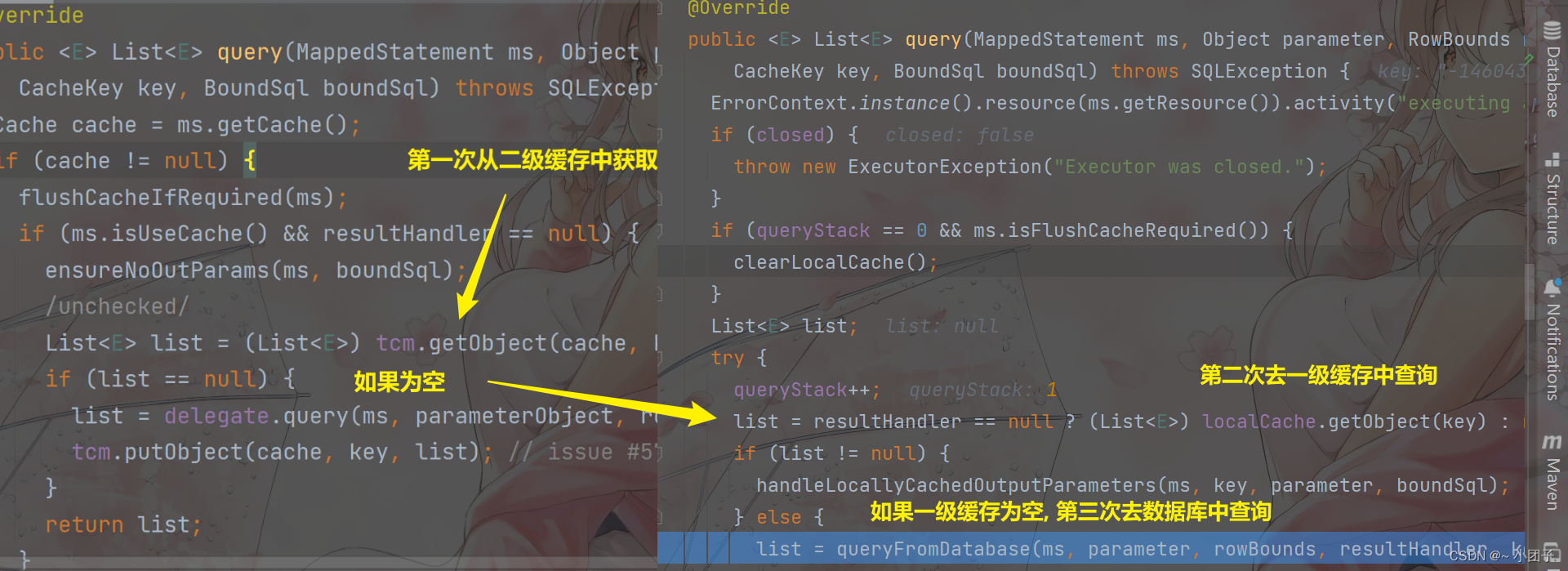
一句话: 缓存执行顺序是: 二级缓存 --> 一级缓存 --> 数据库
小实验
1.修改MonsterMapperTest.java
这里有debug, 自己debug看看, 很有意思的
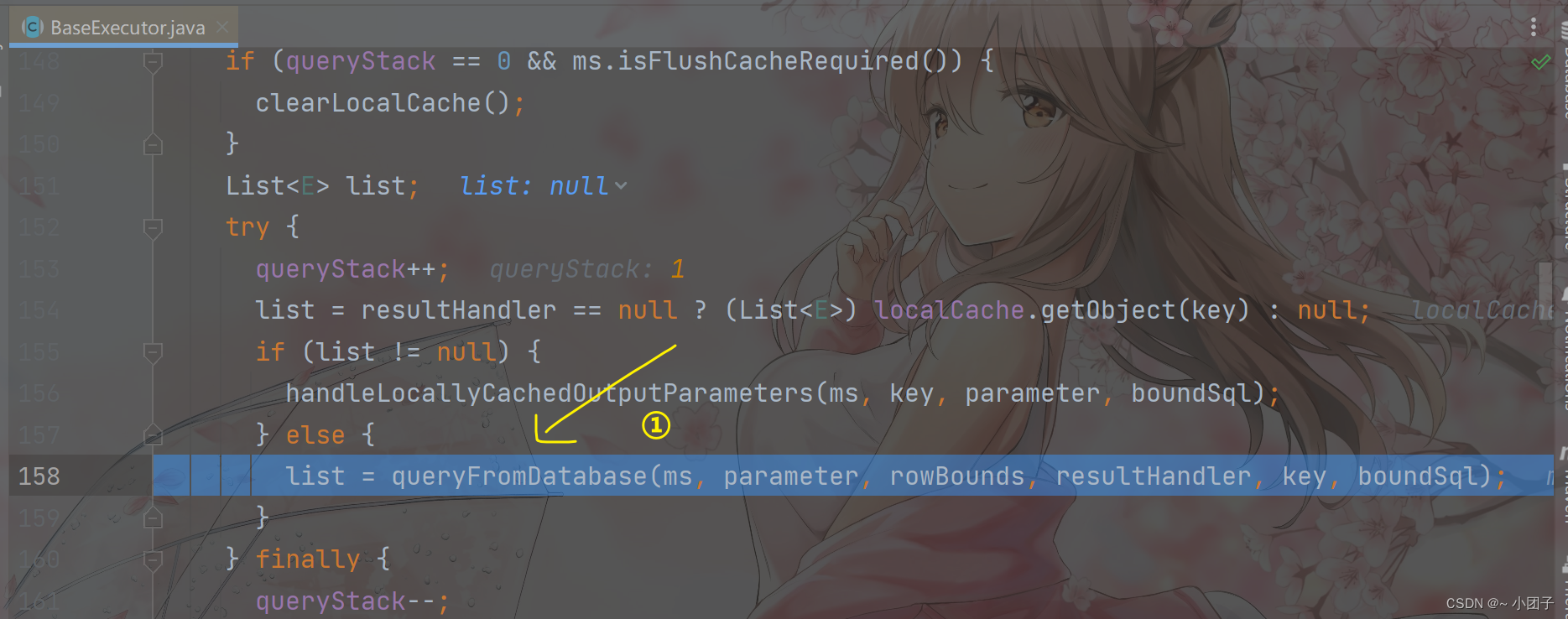
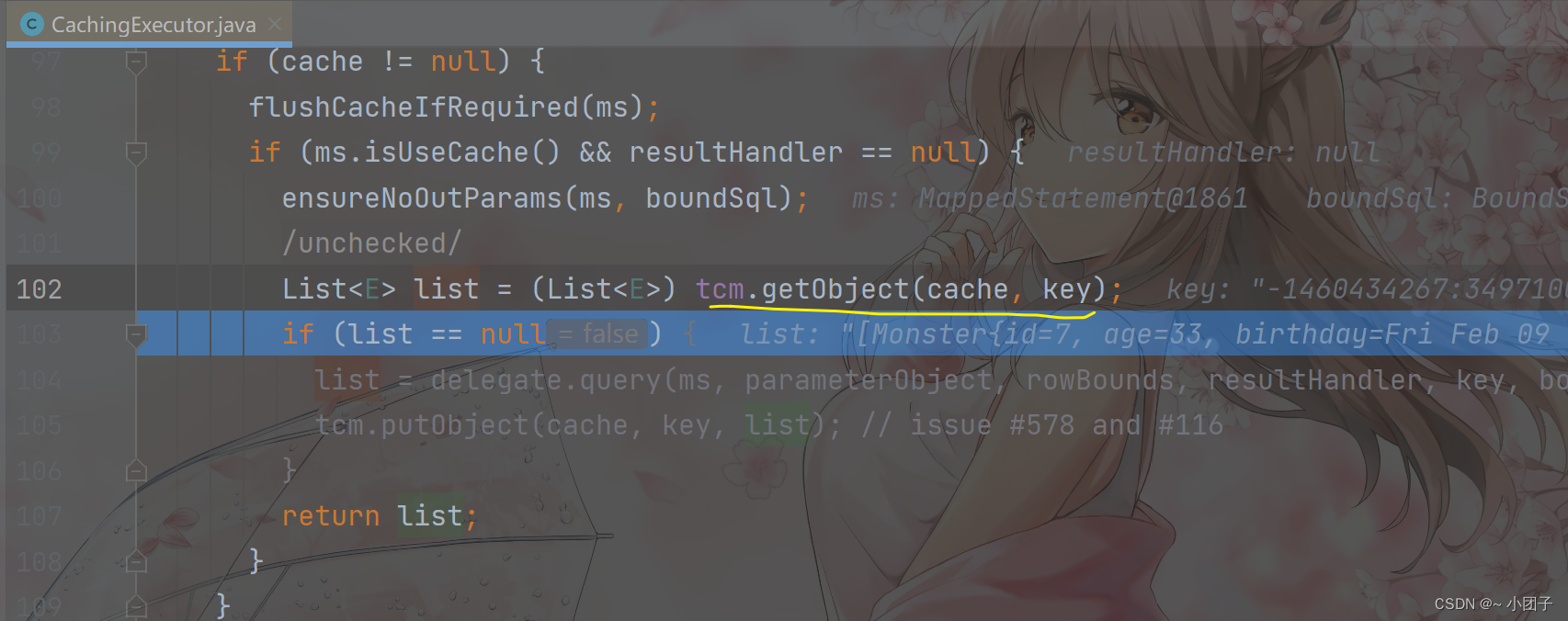
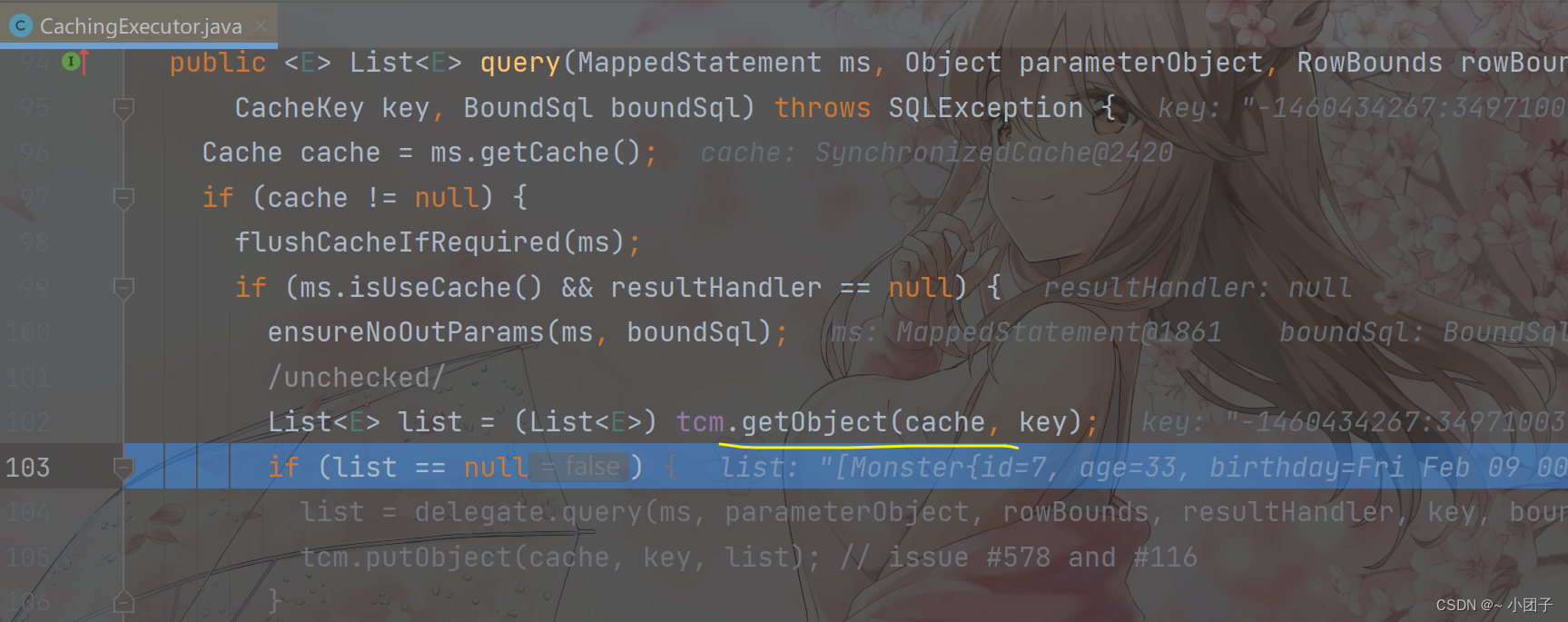
//演示:二级缓存->一级缓存->DB执行的顺序
@Test
public void cacheSeqTest() {System.out.println("查询第1次");//DB, 会发出sql, 分析cache hit radio 0.0Monster monster1 = monsterMapper.getMonsterById(7);System.out.println(monster1);//这里我们关闭sqlSession, 一级缓存数据消失//当我们关闭一级缓存的时候, 如果你配置了二级缓存, 那么一级缓存的数据, 会放入到二级缓存sqlSession.close();sqlSession = MyBatisUtils.getSqlSession();monsterMapper = sqlSession.getMapper(MonsterMapper.class);System.out.println("查询第2次");//从二级缓存获取id=7 monster信息, 就不会发出sql, cache hit radio 0.5Monster monster2 = monsterMapper.getMonsterById(7);System.out.println(monster2);System.out.println("查询第3次");//从二级缓存获取id=7 monster信息, 就不会发出sql, cache hit radio 0.666666Monster monster3 = monsterMapper.getMonsterById(7);System.out.println(monster3);if (sqlSession != null) {sqlSession.close();}
}
第一次, 去数据库中查询
第二次, 从二级缓存中获取
第三次, 从二级缓存中获取
细节说明
1.不会出现一级缓存和二级缓存中有同一个数据, 因为二级缓存是在一级缓存关闭之后才有的.
2.修改MonsterMapperTest.java, 不关闭一级缓存, 看看运行效果 这里有debug, 自己debug看看, 很有意思的
//分析缓存执行顺序
//二级缓存->一级缓存->DB
@Test
public void cacheSeqTest2() {System.out.println("查询第1次");//DB, 会发出sql, 分析cache hit radio 0.0Monster monster1 = monsterMapper.getMonsterById(7);System.out.println(monster1);//这里没有关闭sqlSessionSystem.out.println("查询第2次");//从一级缓存获取id=7, cache hit radio 0.0, 不会发出sqlMonster monster2 = monsterMapper.getMonsterById(7);System.out.println(monster2);System.out.println("查询第3次");//还是从一级缓存获取id=7, cache hit radio 0.0, 不会发出sqlMonster monster3 = monsterMapper.getMonsterById(7);System.out.println(monster3);if (sqlSession != null) {sqlSession.close();}
}
第一次, 去数据库中查询
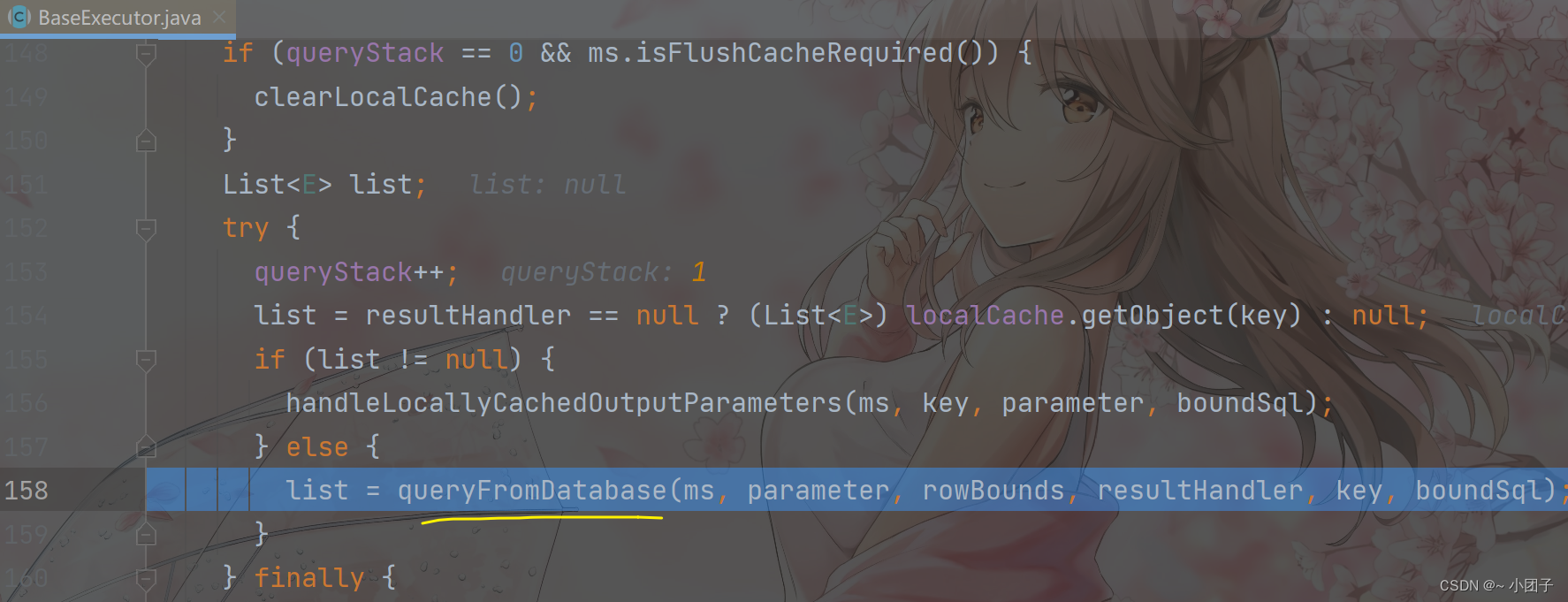
第二次, 去一级缓存中查询
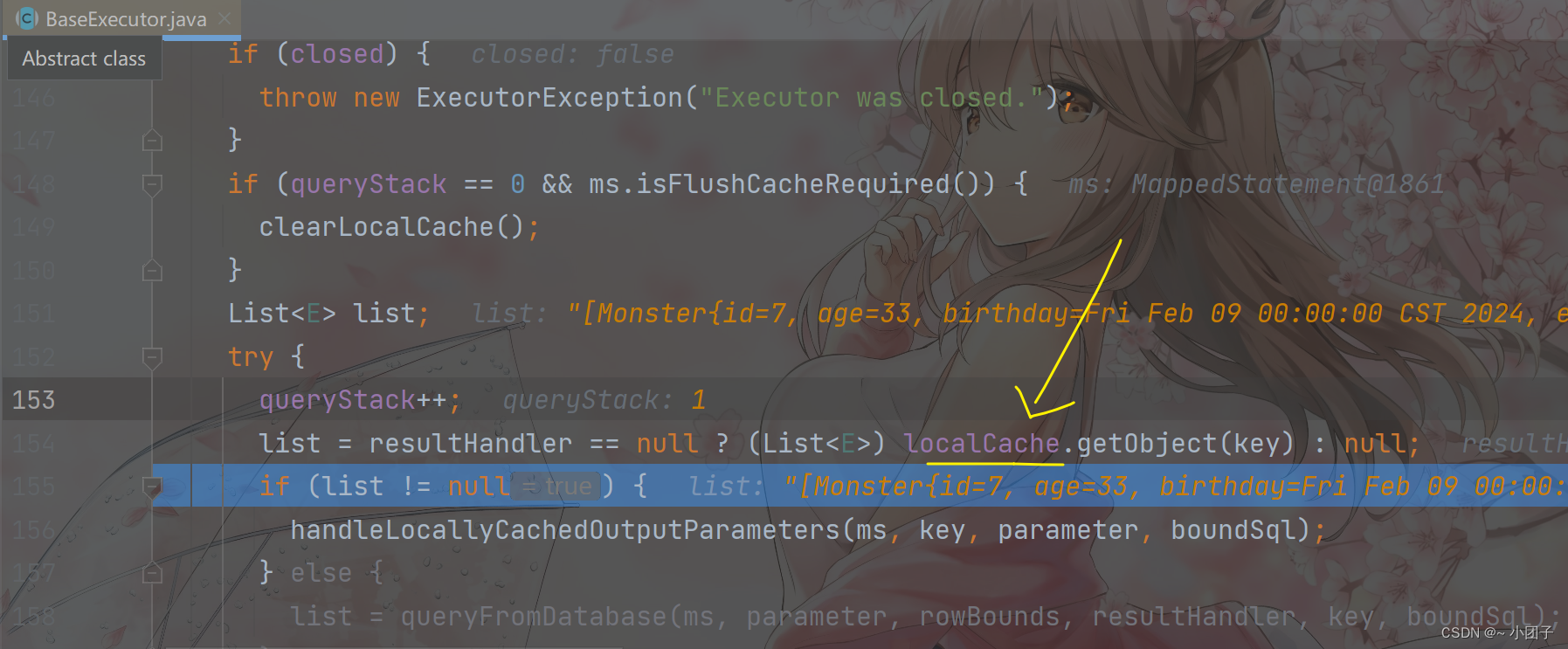
第三次, 从一级缓存中查询
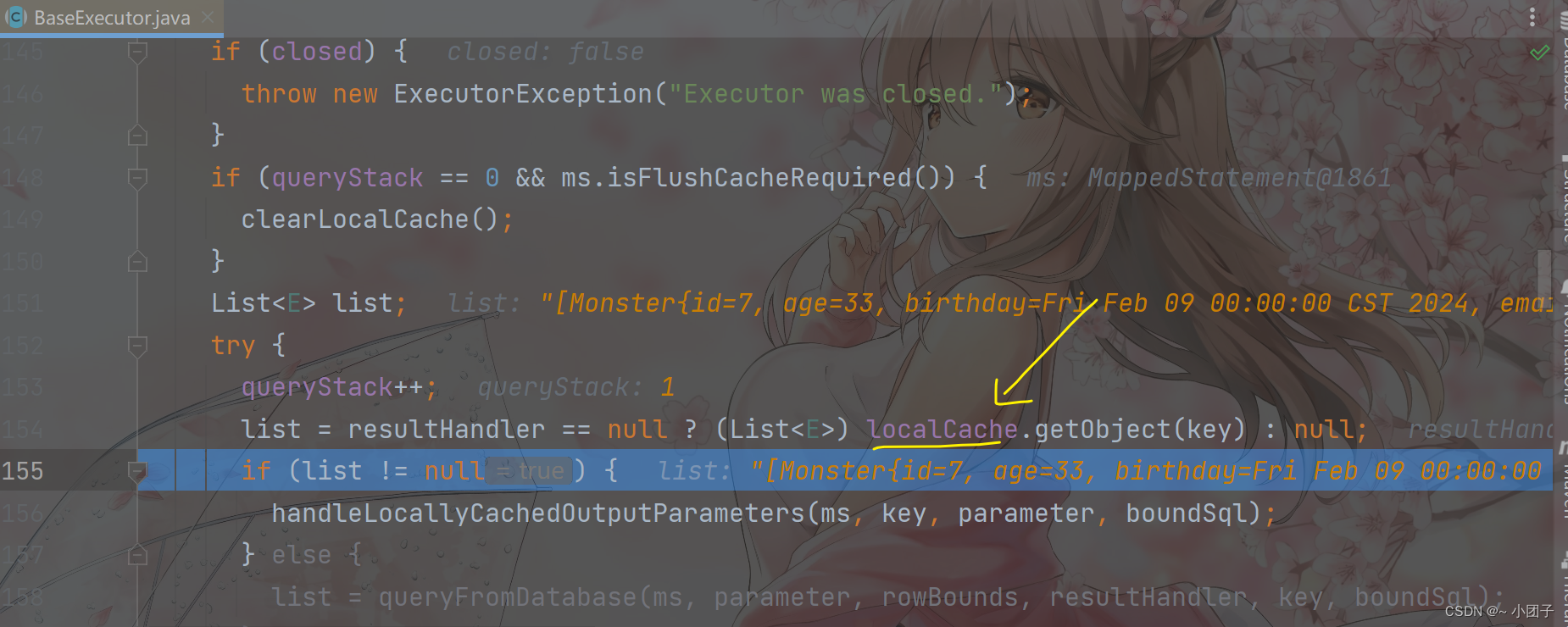
3.运行效果, 可以看到, 在一级缓存存在的情况下, 依然是先查询二级缓存, 但是因为二级缓存, 没有数据, 所以命中率都是 0.0. 可以debug
查询第1次
Cache Hit Ratio [com.zzw.mapper.MonsterMapper]: 0.0
Opening JDBC Connection
==>Loading class com.mysql.jdbc.Driver. This is deprecated. The new driver class is com.mysql.cj.jdbc.Driver. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Created connection 462773420.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@1b955cac]
==> Preparing: SELECT * FROM monster WHERE id = ?
==> Parameters: 7(Integer)
<== Columns: id, age, birthday, email, gender, name, salary
<== Row: 7, 33, 2024-02-09, 978964140@qq.com, 1, 赵志伟_, 1010.0
<== Total: 1
Monster{id=7, age=33, birthday=Fri Feb 09 00:00:00 CST 2024, email=‘978964140@qq.com’, gender=1, name=‘赵志伟_’, salary=1010.0}
查询第2次
Cache Hit Ratio [com.zzw.mapper.MonsterMapper]: 0.0
Monster{id=7, age=33, birthday=Fri Feb 09 00:00:00 CST 2024, email=‘978964140@qq.com’, gender=1, name=‘赵志伟_’, salary=1010.0}
查询第3次
Cache Hit Ratio [com.zzw.mapper.MonsterMapper]: 0.0
Monster{id=7, age=33, birthday=Fri Feb 09 00:00:00 CST 2024, email=‘978964140@qq.com’, gender=1, name=‘赵志伟_’, salary=1010.0}
EnCache缓存
配置文档: https://www.cnblogs.com/zqyanywn/p/10861103.html
基本介绍
1.EhCache 是一个纯Java的缓存框架, 具有快速, 精干等特点.
2.MyBatis有自己默认的二级缓存(前面我们已经讲过了), 但是在实际项目中, 往往使用的是更加专业的第三方缓存产品, 作为MyBatis的二级缓存, EhCache就是非常优秀的缓存产品.
配置和使用EhCache
1.引入相关依赖, 修改mybatis_cache\pom.xml
<dependencies><!--引入ehcache核心库/jar--><dependency><groupId>net.sf.ehcache</groupId><artifactId>ehcache-core</artifactId><version>2.6.11</version></dependency><!--引入需要使用的slf4j--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.36</version></dependency><!--引入mybatis整合ehcache库/jar--><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.2.1</version></dependency>
</dependencies>
2.mybatis-config.xml 仍然打开二级缓存
<settings><!--1.全局性地开启或关闭所有映射器配置文件中已配置的任何缓存, 可以理解这是一个总开关2.默认就是: true--><setting name="cacheEnabled" value="true"/>
</settings>
3.加入src/main/resources/ehcache.xml配置文件
- 文档说明: https://www.taobye.com/f/view-11-23.html
<?xml version="1.0" encoding="UTF-8"?>
<ehcache><!--diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:user.home – 用户主目录user.dir – 用户当前工作目录java.io.tmpdir – 默认临时文件路径--><diskStore path="java.io.tmpdir/Tmp_EhCache"/><!--defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。--><!--name:缓存名称。maxElementsInMemory:缓存最大数目maxElementsOnDisk:硬盘最大缓存个数。eternal:对象是否永久有效,一但设置了,timeout将不起作用。overflowToDisk:是否保存到磁盘,当系统宕机时timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。clearOnFlush:内存数量最大时是否清除。memoryStoreEvictionPolicy:可选策略(清除策略)有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。FIFO,first in first out,这个是大家最熟的,先进先出。LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。--><defaultCacheeternal="false"maxElementsInMemory="10000"overflowToDisk="false"diskPersistent="false"timeToIdleSeconds="1800"timeToLiveSeconds="259200"memoryStoreEvictionPolicy="LRU"/></ehcache>
4.在XxxMapper.xml中启用EhCache, 当然原来MyBatis自带的缓存配置就注销了
<!--
1.配置二级缓存: 是mybatis自带的二级缓存
2.FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3.flushInterval 刷新间隔 是毫秒单位 60000, 表示 60s
4.size="512": 引用数目, 属性可以被设置为任意正整数, 默认1024
5.readOnly="true": (只读)属性可以被设置为 true 或 false: 如果我们只是用于读操作, 建议设置成 true, 这样可以提高效率. 如果有修改操作, 设置成 false, 默认就是false
-->
<!--<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>-->
<!--配置/启用ehcache-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
5.修改MonsterMapperTest.java, 增加测试方法, 完成测试+简单 Debug
//测试ehcache缓存的使用
@Test
public void ehCacheTest() {//查询id=7的monsterMonster monster = monsterMapper.getMonsterById(7);//会发出sql,到db查询System.out.println("monster=" + monster);//这里我们关闭sqlSession, 一级缓存[数据]失效. 将数据放入到二级缓存(ehcache)if (sqlSession != null) {sqlSession.close();}//重新获取sqlSessionsqlSession = MyBatisUtils.getSqlSession();//重新获取了monsterMappermonsterMapper = sqlSession.getMapper(MonsterMapper.class);//查询id=7的monsterSystem.out.println("---虽然前面关闭了sqlSession, 因为配置二级缓存[ehcache], " +"当你再次查询相同的id时, 不会再发出sql, 而是从二级缓存[ehcache]获取数据---");Monster monster2 = monsterMapper.getMonsterById(7);System.out.println("monster2=" + monster);//再次查询id=7的monster, 仍然到二级缓存(ehcache), 获取数据, 不会发出sqlMonster monster3 = monsterMapper.getMonsterById(7);System.out.println("monster3=" + monster3);if (sqlSession != null) {sqlSession.close();}
}
细节说明
如何理解EhCache和MyBatis缓存的关系
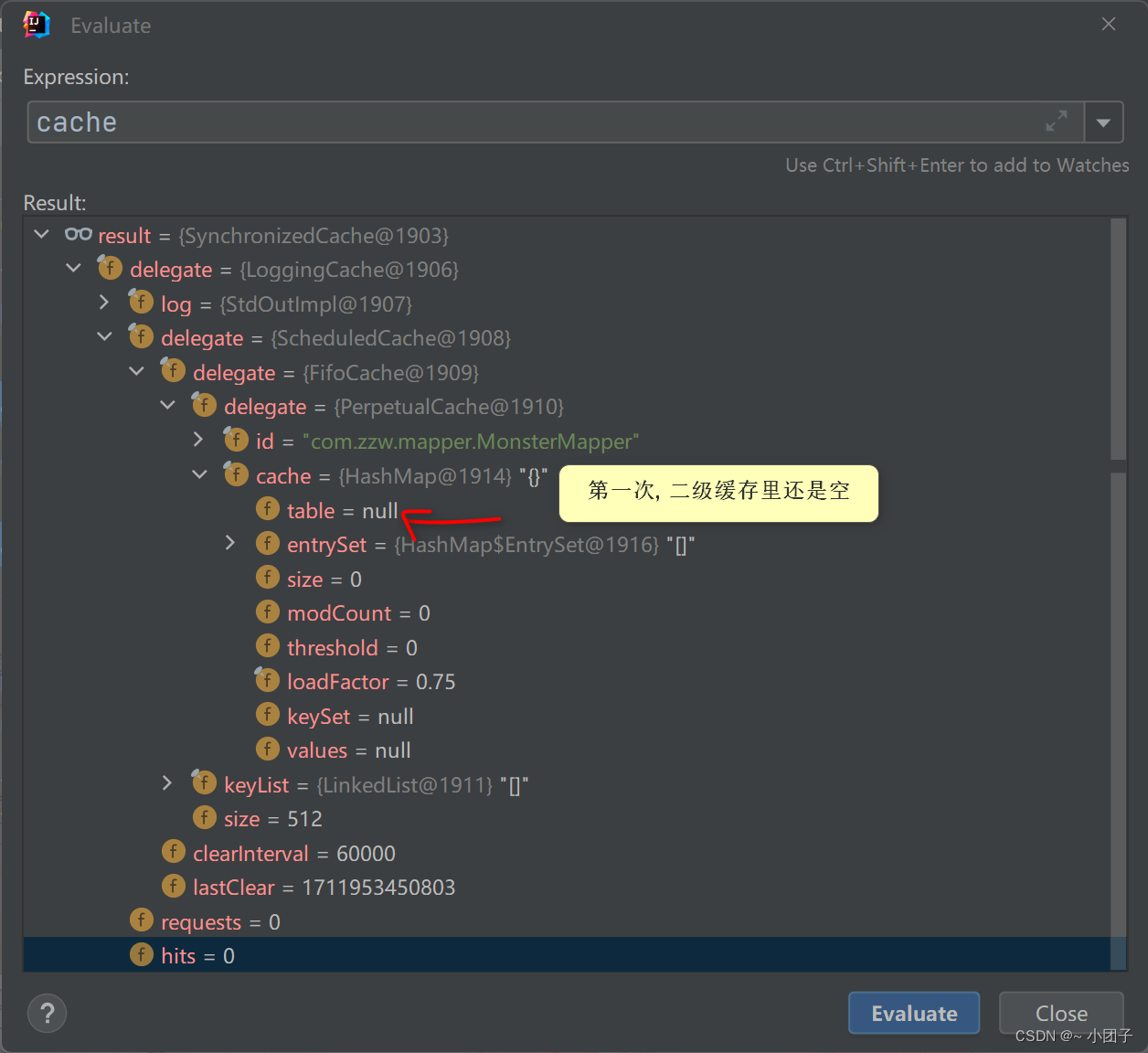
1.MyBatis提供了一个接口Cache[如右图, 找到org.apache.ibatis.cache, 关联源码包就可以看到Cache接口]
2.只要实现了该Cache接口, 就可以作为二级缓存产品和MyBatis 整合使用, Ehcache 就是实现了该接口
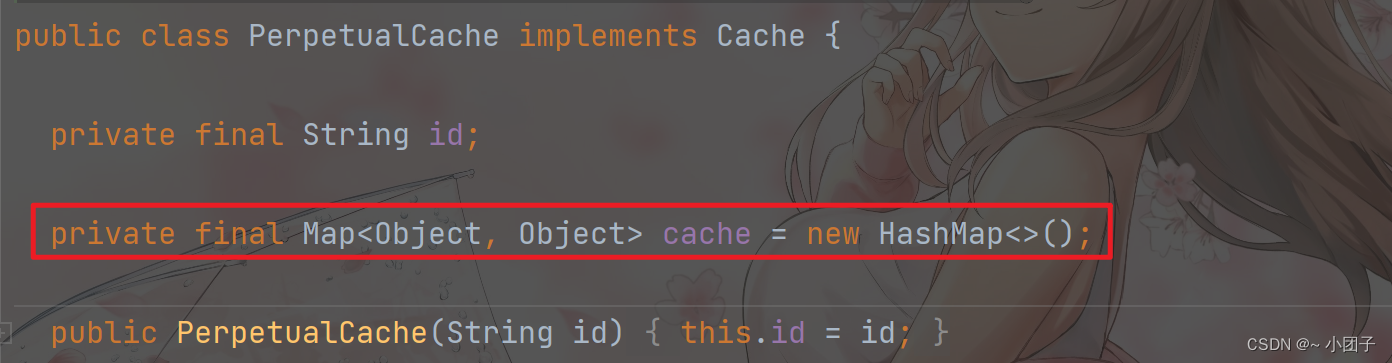
3.MyBatis默认情况(即一级缓存)是使用的PerpetualCache类实现Cache接口的, 是核心类
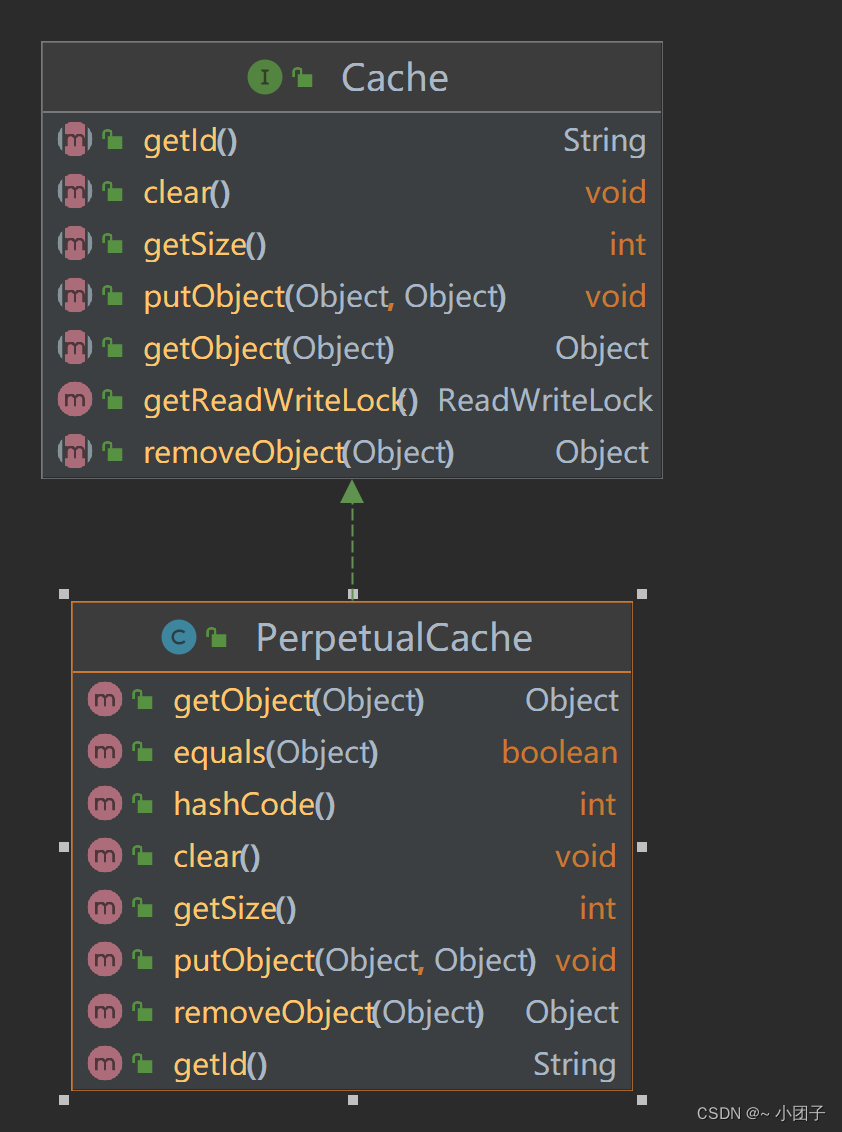
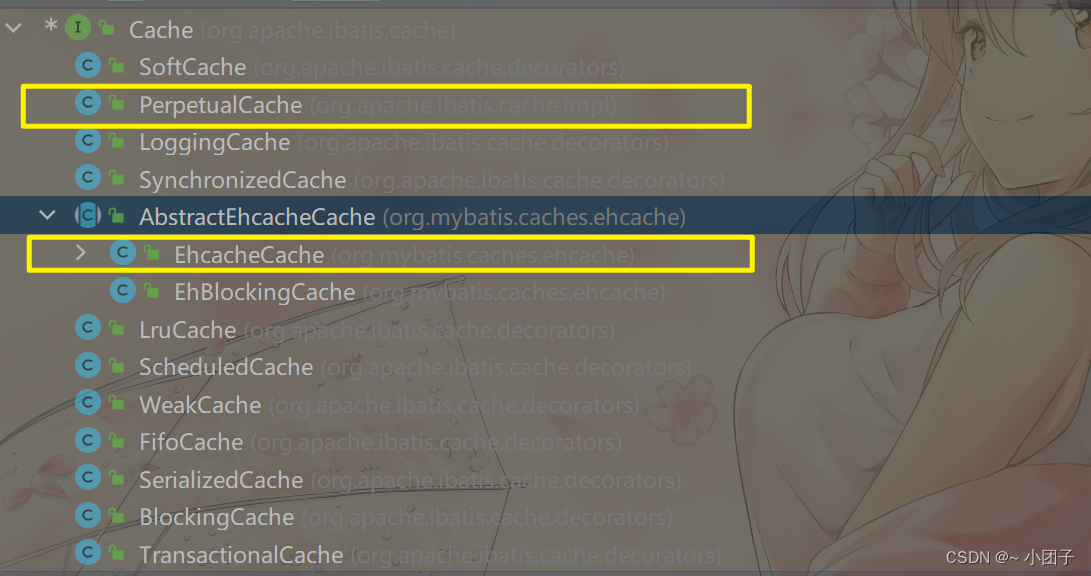
4.当我们使用了Ehcache后, 就是EhcacheCache类实现Cache接口的, 是核心类

5.我们看一下源码, 发现缓存的本质就是 Map<Object, Object
MyBatis逆向工程
接下来我们学习, 整合SSM
💐💐💐💐💐💐💐💐给个赞, 点个关注吧, 各位大佬!💐💐💐💐💐💐💐💐
💐💐💐💐💐💐💐💐祝各位2024年大吉大运💐💐💐💐💐💐💐💐💐💐

相关文章:
MyBatis系列七: 一级缓存,二级缓存,EnCache缓存
缓存-提高检索效率的利器 官方文档 一级缓存基本介绍快速入门Debug一级缓存执行流程一级缓存失效分析 二级缓存基本介绍快速入门Debug二级缓存执行流程注意事项和使用细节 mybatis的一级缓存和二级缓存执行顺序小实验细节说明 EnCache缓存基本介绍配置和使用EhCache细节说明 My…...

C++迈向精通:函数指针对象与函数对象
C:指针对象 C语言中的函数指针 在C语言中,我们见过如下的函数指针: int add(int a, int b) {return a b; }int main() {int a, b;int (*p)(int, int) add;scanf("%d%d", &a, &b);p(a, b);return 0; } 为了适应C中面向…...

类和对象知识点
面向对象概念回顾 万物皆对象 用程序来抽象(形容)对象 用面向对象的思想来编程 什么是类 基本概念 具有相同特征,具有相同行为,一类事物的抽象。 类是对象的模板,可以通过类创建出对象,类的关键词—…...

【FAS】《Survey on face anti-spoofing in face recognition》
文章目录 原文基于手工设计特征表达的人脸活体检测方法基于深度学习的人脸活体检测方法基于融合策略的人脸活体检测方法人脸检测活体数据库点评 原文 邓雄,王洪春,赵立军等.人脸识别活体检测研究方法综述[J].计算机应用研究,2020,37(09):2579-2585.DOI:10.19734/j.issn.1001-3…...

【Unity】RPG2D龙城纷争(一)搭建项目、导入框架、前期开发准备
更新日期:2024年6月12日。 项目源码:后续章节发布 免责声明:【RPG2D龙城纷争】使用的图片、音频等所有素材均有可能来自互联网,本专栏所有文章仅做学习和教程目的,不会将任何素材用于任何商业用途。 索引 【系列简介】…...

多目标跟踪中检测器和跟踪器如何协同工作的
多目标跟踪中检测器和跟踪器如何协同工作的 flyfish 主要是两者 接口间的交互 假设 原始图像尺寸:1920(宽)x 1080(高) 模型输入尺寸:640(宽)x 640(高) 检…...

kali系统几个开机启动项的区别
1、Live system (amd64) 简单的模式 ,启动系统,直接进入 Kali,在系统中的所有的操作和设置都会在下次重启时失效。 Kali 中保存/编辑的所有东西都会重启丢失。 2、Live system (amd64 fail-safe mode) 这种模式与 Live (amd64) 类似…...

【自撰写】【国际象棋入门】第5课 常见开局战术组合(一)
第5课 常见开局战术组合(一) 本次课中,我们简要介绍几种常见的开局战术组合。开局当中,理想的情况是,己方的两只(或以上)轻子相互配合,或者与己方的兵配合,在完成布局的…...

高考志愿填报选专业,女孩就业率最好的专业有哪些?
高考志愿填报选专业, 大家都会关心:将来怎么就业? 按照目前的环境来说,女孩的就业是不乐观的,在职场上,绝大部分岗位都是男性优先的,至少短期内可能还无法改变,这样就要求我们在大学…...

yolov5模型训练早停模型变大
目录 1. 背景2. 原因分析2.1 train代码分析2.2 strip_optimizer函数分析 3. 验证 1. 背景 最近使用tph-yolov5训练yolov5l-tph-plus模型时,发现模型收敛的差不多了,就果断的停止了训练,结果发现last.pt和best.pt竟然488M,而正常训…...

next是什么???
大家都知道最近出了一个很火的框架,Next.js框架。很多大公司(例如:Tencent腾讯,docker,Uber)的项目都在使用这个Next.js框架。那Next.js到底是一个什么框架呢?Next.js有什么优点呢?今…...

K8s的资源对象
资源对象是 K8s 提供的一些管理和运行应用容器的各种对象和组件。 Pod 资源是 K8s 中的基本部署单元,K8s通过Pod来运行业务应用的容器镜像 Job 和 CronJob 资源用于执行任务和定时任务,DaemonSet 资源提供类似每个节点上守护进程, Deployment…...
OpenStack快速入门
任务一 熟悉OpenStack图形界面操作 1.1 Horizon项目 •各OpenStack服务的图形界面都是由Horizon提供的。 •Horizon提供基于Web的模块化用户界面。 •Horizon为云管理员提供一个整体的视图。 •Horizon为终端用户提供一个自主服务的门户。 •Horizon由云管理员进行管理…...
STM32CubeIDE对STM32F072进行ADC配置及使用
目录 1. 配置2. 时钟3. ADC配置4. 代码补充 1. 配置 引脚配置:PB0 2. 时钟 都是48MHz 3. ADC配置 ADC配置: 开启中断: 4. 代码补充 轮训ADC采样: HAL_ADC_PollForConversion(&hadc,10);ADC采样: HAL_ADC_Start (&a…...

Leetcode Hot 100 刷题记录 - Day 1
问题描述: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 示…...

k8s学习--Kruise Rollouts 基本使用
文章目录 Kruise Rollouts简介什么是 Kruise Rollouts?核心功能 应用环境一、OpenKruise部署1.安装helm客户端工具2. 通过 helm 安装 二、Kruise Rollouts 安装2. kubectl plugin安装 三、Kruise Rollouts 基本使用(多批次发布)1. 使用Deployment部署应用2.准备Roll…...

PHP框架详解 - CakePHP框架
CakePHP 是一个开源的 PHP Web 应用框架,它遵循 MVC(模型-视图-控制器)设计模式。CakePHP 提供了快速开发的功能,如代码自动生成、数据库交互的 CRUD 操作支持、灵活的路由、模板引擎、表单处理以及其它许多有用的特性22。 CakeP…...

el-cascader 支持多层级,多选(可自定义限制数量),保留最后一级
多功能的 el-cascader 序言:最近遇到一个需求关于级联的,有点东西,这里是要获取某个产品类型下的产品,会存在产品类型和产品在同一级的情况,但是产品类型不能勾选; 情况1(二级菜单是产品&…...
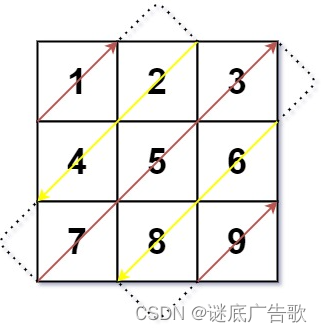
leetcode498 对角线遍历
题目 给你一个大小为 m x n 的矩阵 mat ,请以对角线遍历的顺序,用一个数组返回这个矩阵中的所有元素。 示例 输入:mat [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,4,7,5,3,6,8,9] 解析 本题目主要考察的就是模拟法,首…...

北京活动会议通常会邀约哪些媒体参会报道?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 北京作为我国的首都和文化中心,各类活动会议资源丰富,吸引了众多媒体的关注。以下是一些通常会被邀约参会报道的重要媒体类型: 国家级新闻机构&#x…...

性价比高的AI应用厂家
核心结论: 当前市面上AI应用厂商众多,但真正能做到“高性价比”的,必须同时满足三个条件:功能覆盖企业核心痛点(管理、销售、运营)、落地效果可量化(降本增效有数据支撑)、成本可控&…...

3步完成HTML网页到Figma设计稿的终极转换指南
3步完成HTML网页到Figma设计稿的终极转换指南 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html HTML转Figma工具是一个革命性的开源Chrome扩展程序,它能够将任何网页瞬间…...

Taotoken CLI工具安装与一键配置全模型环境指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具安装与一键配置全模型环境指南 对于需要接入多个大模型服务的开发团队而言,统一管理API密钥、模型配置…...

环境配置与基础教程:高效数据加载黑科技:替代默认 DataLoader,使用 NVIDIA DALI 加速 CPU 到 GPU 数据搬运
一、开篇:你的GPU真的在偷懒吗? 如果你是一位深度学习工程师,这个场景一定不陌生:你花重金租了一台搭载H100或A100的服务器,batch size拉满,模型架构精心调优,但打开nvidia-smi一看——GPU利用率只有20%-30%,大部分时间都在空转。CPU使用率却已经飙到100%,风扇呼呼作…...

Mermaid CLI深度解析:文本驱动图表生成在DevOps与文档自动化中的实践指南
Mermaid CLI深度解析:文本驱动图表生成在DevOps与文档自动化中的实践指南 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli Mermaid CLI作为Mermaid图表库的命令行接口&am…...

RT-Thread中断管理实战:从Cortex-M硬件机制到线程通信
1. 项目概述:从内核到中断,RT-Thread的实战拼图搞嵌入式开发,尤其是用RTOS,中断处理是绕不开的一道坎。之前我们聊RT-Thread的线程、IPC、内存管理,都是在“太平盛世”下进行的,线程们按部就班地运行、等待…...

RPG Maker终极视差地图插件:零代码打造专业级多层场景
RPG Maker终极视差地图插件:零代码打造专业级多层场景 【免费下载链接】RPGMakerMV RPGツクールMV、MZで動作するプラグインです。 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerMV 你是否曾为RPG Maker中单调的2D地图而苦恼?是否梦想创…...

AI圈大事!网友:太离谱了~
最近技术圈友发生了件大事:今年 2 月刚刚开源的 Hermes Agent,GitHub star 数已超过 106k。有些同学可能还不太了解,我们先来说说 Hermes 是什么。它不是简单的聊天机器人,是能自己做事、会学习、越用越聪明的数字员工。为啥能火成…...

如何高效恢复丢失数据:开源数据恢复工具TestDisk PhotoRec完整实战指南
如何高效恢复丢失数据:开源数据恢复工具TestDisk & PhotoRec完整实战指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk TestDisk和PhotoRec是两款功能强大的开源数据恢复工具,专…...

AISuperDomain:构建AI API智能网关,解决网络延迟与高可用难题
1. 项目概述与核心价值最近在折腾一些自动化脚本和本地化AI应用时,我遇到了一个挺普遍但又有点烦人的问题:如何让我的程序能稳定、高效地访问那些部署在境外的AI服务API,比如OpenAI、Claude或者一些开源的模型托管平台。直接调用?…...