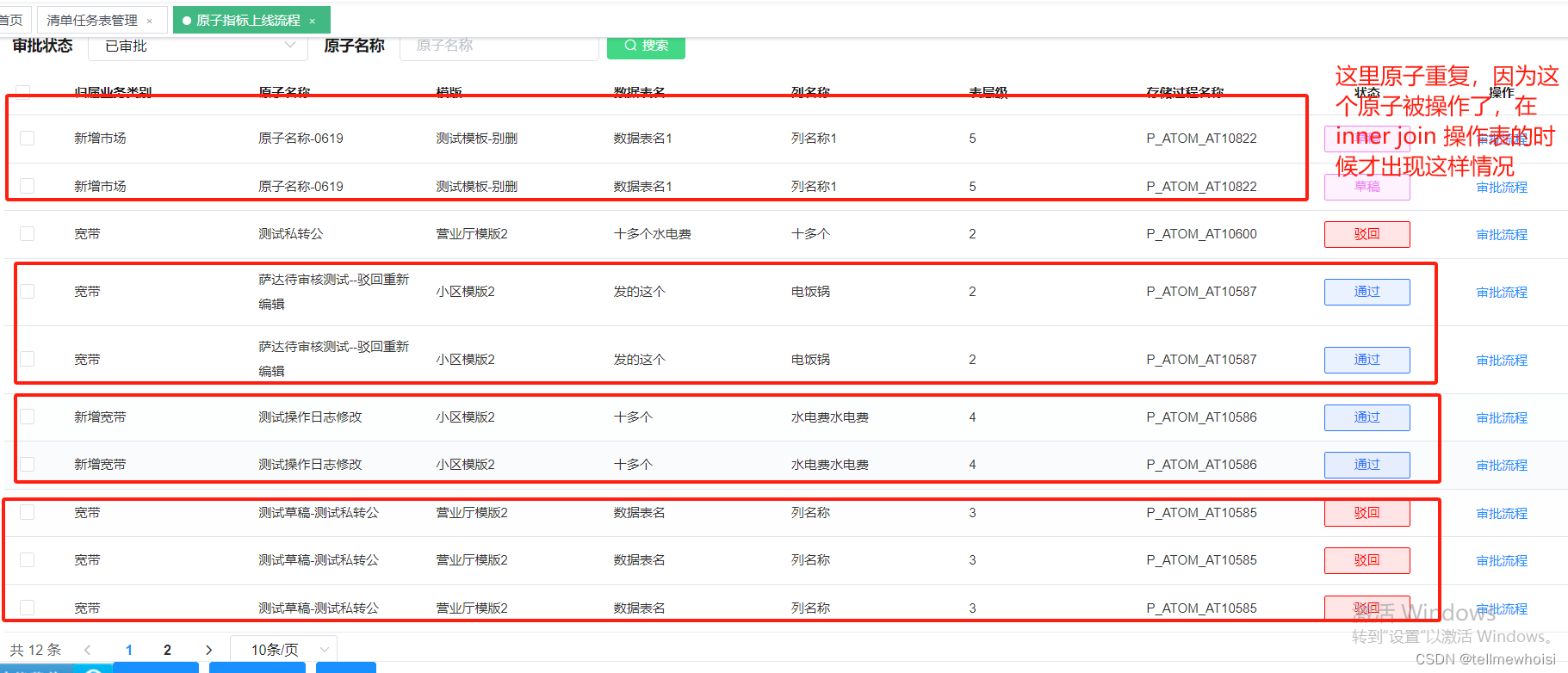
分页插件结合collection标签后分页数量不准确的问题
问题1:不使用collection 聚合分页正确
简单列子
T_ATOM_DICT表有
| id | name |
|---|---|
| 1 | 原子1 |
| 2 | 原子2 |
| 3 | 原子3 |
| 4 | 原子4 |
| 5 | 原子5 |
| 6 | 原子6 |
T_ATOM_DICT_AUDIT_ROUTE表审核记录表有
| id | audit |
|---|---|
| 1 | 拒绝 |
| 1 | 通过 |
| 4 | 拒绝 |
我要显示那些原子审核了,我把两个表inner join 就是那些原子审核过了
| id | name | audit |
|---|---|---|
| 1 | 原子1 | 拒绝 |
| 1 | 原子1 | 通过 |
| 4 | 原子4 | 拒绝 |
mapper
IPage<AtomDict> findAllByAuditRouteNoDuplicate(@Param("criteria") AtomDictQueryCriteria criteria, Page<Object> page);
xml基础的查询类型和返回类型
<!-- 分步要用-->
<resultMap id="BaseResultMap" type="com.njry.sjzl.busi.domain.AtomDict"><result column="ATOM_ID" property="atomId"/><result column="ATOM_ID" property="id"/><result column="CATEGORY_ID" property="categoryId"/><result column="CATEGORY_NAME" property="categoryName"/><result column="ATOM_NAME" property="atomName"/><result column="TYPE" property="type"/><result column="TYPE_NAME" property="typeName" /><result column="DATA_CYCLE" property="dataCycle"/><result column="DATA_CYCLE_NAME" property="dataCycleName"/><result column="LIB_TYPE" property="libType"/>
<!-- <result column="AUDIT_RESULT" property="auditResult"/>-->
<!-- <result column="AUDIT_REMARK" property="auditRemark"/>--><result column="LIB_TYPE_NAME" property="libTypeName"/><result column="DATA_GENE_MODE" property="dataGeneMode"/><result column="DATA_GENE_MODE_NAME" property="dataGeneModeName"/><result column="TEMPLATE_ID" property="templateId"/><result column="TEMPLATE_NAME" property="templateName"/><result column="DATABASE" property="database"/><result column="DATABASE_NAME" property="databaseName"/><result column="DATABASE_TABLE" property="databaseTable"/><result column="COLUMN_NAME" property="columnName"/><result column="TABLE_LEVEL" property="tableLevel"/><result column="PROC_NAME" property="procName"/><result column="IS_HZ" property="isHz"/><result column="STATUS" property="status"/><result column="ATOM_TABLE" property="atomTable"/><result column="MODE_FLAG" property="modeFlag"/><result column="CREATE_ID" property="createId"/><result column="CREATE_DATE" property="createDate"/><result column="REC_ID" property="recId"/><result column="REC_DATE" property="recDate"/><result column="SH_ID" property="shId"/><result column="SH_DATE" property="shDate"/><result column="SH_REMARK" property="shRemark"/><result column="DEL_ID" property="delId"/><result column="DEL_DATE" property="delDate"/><result column="START_DATE" property="startDate"/><result column="END_DATE" property="endDate"/><result column="UNIT" property="unit"/><result column="DIMEN_FLAG" property="dimenFlag"/></resultMap><resultMap id="BaseResultMapBoss" type="com.njry.sjzl.busi.domain.AtomDict"><result column="ATOM_ID" property="atomId"/><result column="ATOM_ID" property="id"/><result column="CATEGORY_ID" property="categoryId"/><result column="CATEGORY_NAME" property="categoryName"/><result column="ATOM_NAME" property="atomName"/><result column="TYPE" property="type"/><result column="TYPE_NAME" property="typeName" /><result column="DATA_CYCLE" property="dataCycle"/><result column="DATA_CYCLE_NAME" property="dataCycleName"/><result column="LIB_TYPE" property="libType"/><result column="LIB_TYPE_NAME" property="libTypeName"/><result column="DATA_GENE_MODE" property="dataGeneMode"/><result column="DATA_GENE_MODE_NAME" property="dataGeneModeName"/><result column="TEMPLATE_ID" property="templateId"/><result column="TEMPLATE_NAME" property="templateName"/><result column="DATABASE" property="database"/><result column="DATABASE_NAME" property="databaseName"/><result column="DATABASE_TABLE" property="databaseTable"/><result column="COLUMN_NAME" property="columnName"/><result column="TABLE_LEVEL" property="tableLevel"/><result column="PROC_NAME" property="procName"/><result column="IS_HZ" property="isHz"/><result column="STATUS" property="status"/><result column="ATOM_TABLE" property="atomTable"/><result column="MODE_FLAG" property="modeFlag"/><result column="CREATE_ID" property="createId"/><result column="CREATE_DATE" property="createDate"/><result column="REC_ID" property="recId"/><result column="REC_DATE" property="recDate"/><result column="SH_ID" property="shId"/><result column="SH_DATE" property="shDate"/><result column="SH_REMARK" property="shRemark"/><result column="DEL_ID" property="delId"/><result column="DEL_DATE" property="delDate"/><result column="START_DATE" property="startDate"/><result column="END_DATE" property="endDate"/><result column="UNIT" property="unit"/><result column="DIMEN_FLAG" property="dimenFlag"/></resultMap>
<!-- <collection property="batchList" resultMap="BatchListResultMap"/>-->
<!-- 审核表数据还得关联用户表显示用户名--><resultMap id="BatchListResultMap" type="com.njry.sjzl.busi.domain.AtomDictAuditRoute"><result column="ROUTE_ID" property="routeId"/><result column="ROUTE_ID" property="id"/><result column="ATOM_IDREPEAT" property="atomId"/><result column="AUDIT_RESULT" property="auditResult"/><result column="AUDIT_REMARK" property="auditRemark"/><result column="AUDIT_ID" property="auditId"/><result column="AUDIT_NAME" property="auditName"/><result column="AUDIT_DATE" property="auditDate"/></resultMap><sql id="BathList_Column_List">auditroute.ROUTE_ID as ROUTE_ID, auditroute.ATOM_ID as ATOM_IDREPEAT, tuser.NAME AS AUDIT_NAME,auditroute.AUDIT_RESULT as AUDIT_RESULT, auditroute.AUDIT_REMARK as AUDIT_REMARK,auditroute.AUDIT_ID as AUDIT_ID,auditroute.AUDIT_DATE as AUDIT_DATE</sql><sql id="Base_Column_List">tad.ATOM_ID, tad.CATEGORY_ID, tad.ATOM_NAME, tad.TYPE, tad.DATA_CYCLE, tad.LIB_TYPE, tad.DATA_GENE_MODE, tad.TEMPLATE_ID, tad.DATABASE_TABLE, tad."DATABASE",tad.COLUMN_NAME, tad.TABLE_LEVEL, tad.PROC_NAME, tad.IS_HZ, tad.STATUS, tad.ATOM_TABLE, tad.MODE_FLAG, tad.CREATE_ID,tad.CREATE_DATE, tad.REC_ID, tad.REC_DATE, tad.SH_ID, tad.SH_DATE, tad.SH_REMARK, tad.DEL_ID, tad.DEL_DATE, tad.START_DATE, tad.END_DATE, tad.UNIT, tad.DIMEN_FLAG</sql>
<!-- 数据字典回显名字--><sql id="Dict_Detail_Column_List">dtable.label AS DATABASE_NAME,dtable1.label AS DATA_GENE_MODE_NAME,dtable2.label AS LIB_TYPE_NAME,dtable3.label AS DATA_CYCLE_NAME,dtable4.label AS TYPE_NAME</sql>
真正xml如下:关联很多表回显,T_ATOM_TEMPLATE模板表,T_ATOM_BUSI_CATEGORY业务分类,五个字典表,和(原子审核表,原子审核表要关联用户表差审核用户名)
<select id="findAllByAuditRouteNoDuplicate" resultMap="BaseResultMapBoss">select tatempalte.TEMPLATE_NAME,tabc.CATEGORY_NAME AS CATEGORY_NAME,<include refid="Base_Column_List"/>,<include refid="Dict_Detail_Column_List"/>,<include refid="BathList_Column_List"/>from T_ATOM_DICT tadleft join T_ATOM_TEMPLATE tatempalte on tatempalte.TEMPLATE_ID = tad.TEMPLATE_IDleft join T_ATOM_BUSI_CATEGORY tabc on tad.CATEGORY_ID = tabc.category_idleft join (select dd.label,dd.value from t_dict d left join t_dict_detail dd on dd.dict_id = d.dict_idwhere d.name = 'asset_archive_name') dtableon tad.DATABASE = dtable.valueleft join (select dd1.label,dd1.value from t_dict d1 left join t_dict_detail dd1 on dd1.dict_id = d1.dict_idwhere d1.name = 't_atmo_dict_generation_mechanism') dtable1on tad.DATA_GENE_MODE = dtable1.valueleft join (select dd2.label,dd2.value from t_dict d2 left join t_dict_detail dd2 on dd2.dict_id = d2.dict_idwhere d2.name = 't_atmo_dict_atomic_library_type') dtable2on tad.LIB_TYPE = dtable2.valueleft join (select dd3.label,dd3.value from t_dict d3 left join t_dict_detail dd3 on dd3.dict_id = d3.dict_idwhere d3.name = 't_atmo_dict_data_cycle') dtable3on tad.DATA_CYCLE = dtable3.valueleft join (select dd4.label,dd4.value from t_dict d4 left join t_dict_detail dd4 on dd4.dict_id = d4.dict_idwhere d4.name = 't_atmo_dict_data_type') dtable4on tad.TYPE = dtable4.valueinner join (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATEfrom T_ATOM_DICT_AUDIT_ROUTE) auditroute on auditroute.ATOM_ID =tad.ATOM_IDleft join t_user tuser on tuser.oper_id = auditroute.AUDIT_ID<where><if test="criteria.atomId != null">and tad.ATOM_ID = #{criteria.atomId}</if><if test="criteria.atomName != null">and tad.ATOM_NAME like concat('%'||#{criteria.atomName},'%')</if></where>order by tad.CREATE_DATE desc, auditroute.AUDIT_DATE asc</select>
问题2:使用collection 聚合出现分页问题
xml基础的查询类型和返回类型 里面把注释的
方法返回类型 id = “BaseResultMapBoss” 里
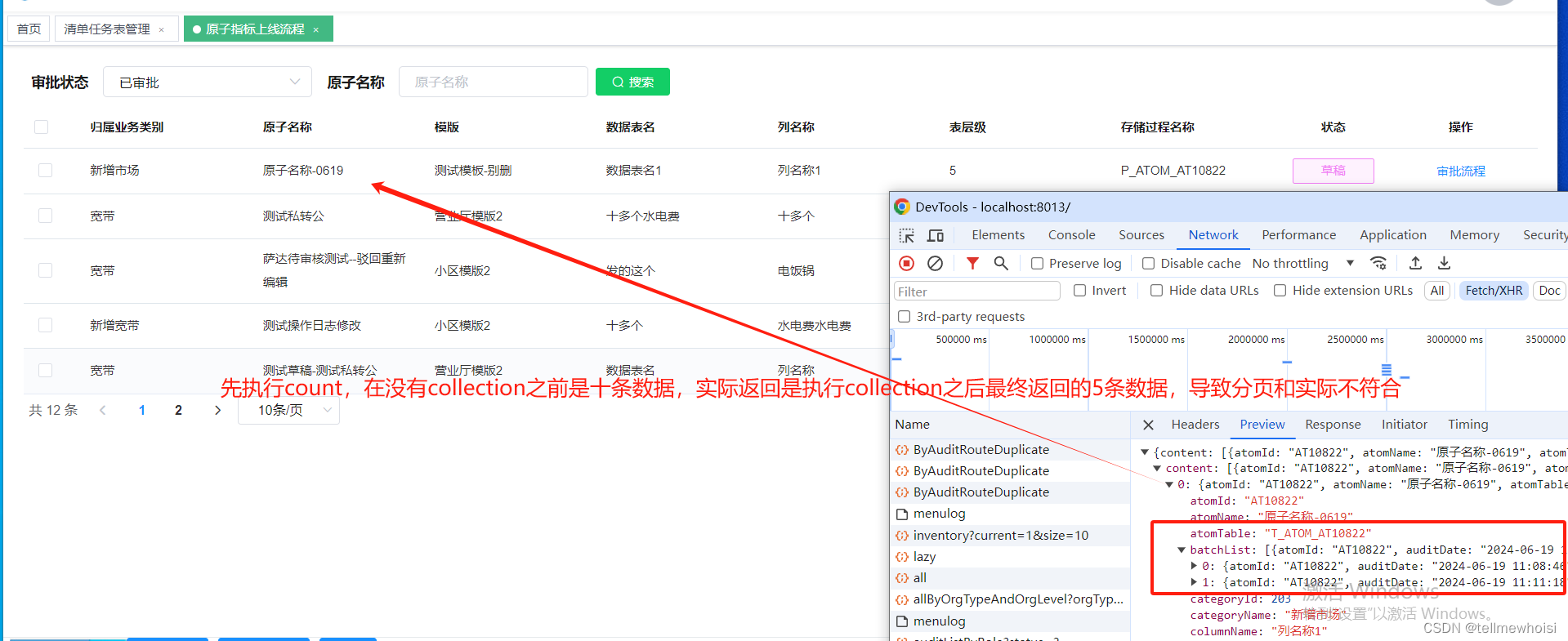
解决办法1(我最蠢的解决办法,把sql分解)
不知道怎么自定义分页解决这种(不会),
我只能把这一个sql语句分开
在impl层
@Overridepublic PageResult<AtomDict> queryAllByAuditRouteDuplicate(AtomDictQueryCriteria criteria, Page<Object> page){// 去重 inner join(原来一个sql就该搞定的)
// IPage<AtomDict> all = atomDictMapper.findAllByAuditRouteNoDuplicate(criteria, page);
// 去重 inner join(分步1)IPage<AtomDict> all = atomDictMapper.findAllByAuditRouteNoDuplicateSubstep(criteria, page);List<AtomDict> records = all.getRecords();// 根据每条数据类的busiSort递归向下查找归属业务分类(回显)
// 每条数据类还要找自己的审批过程(分步2)if(records.size() > 0 ){for (int i = 0; i < records.size(); i++) {AtomDict atomDict = records.get(i);if(atomDict != null){Set<String> taskSetResult = new LinkedHashSet<>();Long categoryId = atomDict.getCategoryId();
// 这里拿到第一步去重的审核原子再去查审核记录,放在返回前端的BatchList 里面List<AtomDictAuditRoute> atomDictAuditRoutes = atomDictMapper.selectBath(atomDict.getAtomId());atomDict.setBatchList(atomDictAuditRoutes);if(categoryId != null){List<String> subCategory = atomBusiCategoryMapper.findSubCategory(categoryId);String currentCategoryName = atomBusiCategoryMapper.findCategoryNameByCateforyId(categoryId);taskSetResult.addAll(subCategory);taskSetResult.add(currentCategoryName);String temp = "";for(String item : taskSetResult){temp += ","+item;}String result = temp.substring(1);atomDict.setCategoryName(result);}}}}return PageUtil.toPage(all);}
mapper
IPage<AtomDict> findAllByAuditRouteNoDuplicateSubstep(@Param("criteria") AtomDictQueryCriteria criteria, Page<Object> page);List<AtomDictAuditRoute> selectBath(@Param("atomId") String atomId);
xml
<!-- 关联审核表确定原子已经审核,因为原子审核触发,在原子表没有字段判断是否审核字段修改,才导致要关联审核记录表判断(关键还得去重):和原来区别就是不collection并且去重--><select id="findAllByAuditRouteNoDuplicateSubstep" resultMap="BaseResultMap">select stupid.* from (select row_number() over(partition by tad.ATOM_ID order by tad.CREATE_DATE desc) rn,tatempalte.TEMPLATE_NAME,tabc.CATEGORY_NAME AS CATEGORY_NAME,<include refid="Base_Column_List"/>,<include refid="Dict_Detail_Column_List"/>from T_ATOM_DICT tadleft join T_ATOM_TEMPLATE tatempalte on tatempalte.TEMPLATE_ID = tad.TEMPLATE_IDleft join T_ATOM_BUSI_CATEGORY tabc on tad.CATEGORY_ID = tabc.category_idleft join (select dd.label,dd.value from t_dict d left join t_dict_detail dd on dd.dict_id = d.dict_idwhere d.name = 'asset_archive_name') dtableon tad.DATABASE = dtable.valueleft join (select dd1.label,dd1.value from t_dict d1 left join t_dict_detail dd1 on dd1.dict_id = d1.dict_idwhere d1.name = 't_atmo_dict_generation_mechanism') dtable1on tad.DATA_GENE_MODE = dtable1.valueleft join (select dd2.label,dd2.value from t_dict d2 left join t_dict_detail dd2 on dd2.dict_id = d2.dict_idwhere d2.name = 't_atmo_dict_atomic_library_type') dtable2on tad.LIB_TYPE = dtable2.valueleft join (select dd3.label,dd3.value from t_dict d3 left join t_dict_detail dd3 on dd3.dict_id = d3.dict_idwhere d3.name = 't_atmo_dict_data_cycle') dtable3on tad.DATA_CYCLE = dtable3.valueleft join (select dd4.label,dd4.value from t_dict d4 left join t_dict_detail dd4 on dd4.dict_id = d4.dict_idwhere d4.name = 't_atmo_dict_data_type') dtable4on tad.TYPE = dtable4.valueinner join (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATEfrom T_ATOM_DICT_AUDIT_ROUTE) auditroute on auditroute.ATOM_ID =tad.ATOM_IDleft join t_user tuser on tuser.oper_id = auditroute.AUDIT_ID<where><if test="criteria.atomId != null">and tad.ATOM_ID = #{criteria.atomId}</if><if test="criteria.atomName != null">and tad.ATOM_NAME like concat('%'||#{criteria.atomName},'%')</if></where>) stupidwhere stupid.rn = 1</select><select id="selectBath" resultMap="BatchListResultMap">select <include refid="BathList_Column_List"/>from (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATEfrom T_ATOM_DICT_AUDIT_ROUTE) auditrouteleft join t_user tuser on tuser.oper_id = auditroute.AUDIT_IDwhere auditroute.ATOM_ID = #{atomId}</select>
解决方法2(设计表时候应该加一个冗余字段)
我仔细想了一下,都是因为T_ATOM_DICT这个原子表缺少一个是否审核字段,(只要触发审核,就修改这个原子是否审核的状态)如果加这个字段就可以直接用collection收集这个原子的审批记录
解决方法3就是我不会的那种,求路过大神指教
相关文章:
分页插件结合collection标签后分页数量不准确的问题
问题1:不使用collection 聚合分页正确 简单列子 T_ATOM_DICT表有 idname1原子12原子23原子34原子45原子56原子6 T_ATOM_DICT_AUDIT_ROUTE表审核记录表有 idaudit1拒绝1通过4拒绝 我要显示那些原子审核了,我把两个表inner join 就是那些原子审核过了 idnameaudit1原子1拒绝…...

git diff 命令
目录标题 [Q&A] git diff 作用常见用法比较工作目录与暂存区比较暂存区与最近一次提交比较工作目录与最近一次提交比较两个具体的提交之间差异 [Q&A] git diff 作用 git diff 用于展示不同版本之间文件内容的变化。 常见用法 比较工作目录与暂存区 显示工作目录中尚…...

Code Review常用术语
CR: Code Review. 请求代码审查。PR: pull request. 拉取请求,给其他项目提交代码。MR: merge request. 合并请求。LGTM: Looks Good To Me.对我来说,还不错。表示认可这次PR,同意merge合并代码到远程仓库。…...

HashMap 源码中的巧妙小技巧
根据容量计算大于容量的最小的哈希表的大小(table的length),这里的length需要满足length2^n,也就是我们需要根据容量算出最小的n的值 static final int tableSizeFor(int cap) {int n cap - 1;n | n >>> 1;n | n >>> 2;n | n >&g…...
极具吸引力的小程序 UI 风格
极具吸引力的小程序 UI 风格...
数据库 | 试卷五试卷六试卷七
1. 主码不相同!相同的话就不能唯一标识非主属性了 2.从关系规范化理论的角度讲,一个只满足 1NF 的关系可能存在的四方面问题 是: 数据冗余度大,插入异常,修改异常,删除异常 3.数据模型的三大要素是什么&…...
网页五子棋对战项目测试(selenium+Junit5)
目录 网页五子棋对战项目介绍 网页五子棋对战测试的思维导图 网页五子棋对战的UI自动化测试 测试一:测试注册界面 测试二:测试登陆界面 测试三:测试游戏大厅界面 测试四:测试游戏房间界面以及观战房间界面 测试五&#…...
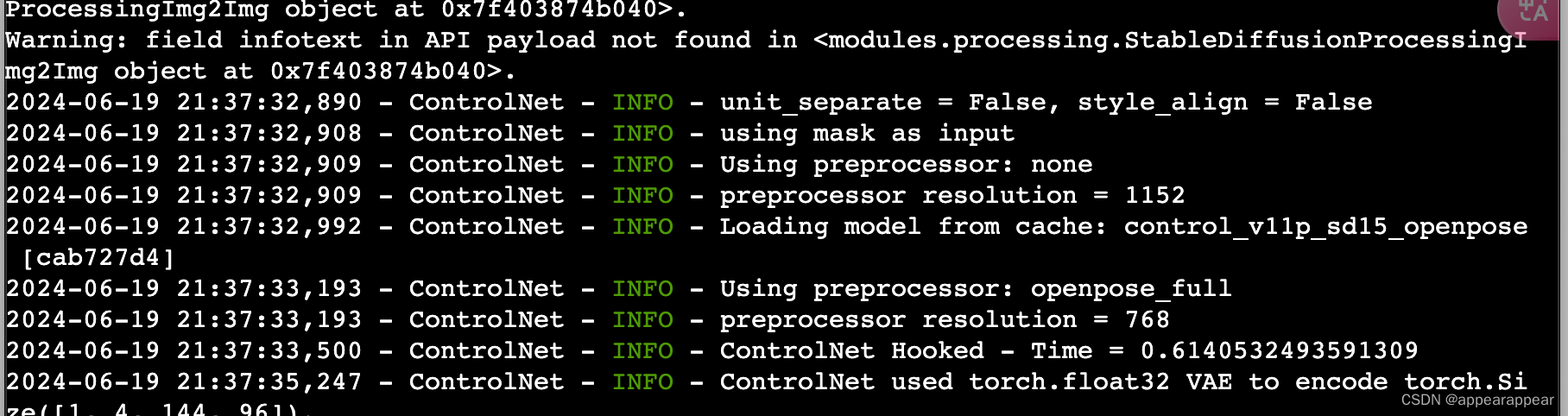
stable diffusion 局部重绘 reference-only api 接口调试
webUI api payload 插件生成的接口参数不准确,reference-only 的image不是对象,就是不同字符串字段,直接传,不是套image。 综上,那个插件参数不确定,应直接看插件的源码,看它接受什么参数 错误…...

浪潮信息内存故障预警技术再升级 服务器稳定性再获提升
浪潮信息近日对其内存故障智能预警修复技术进行了全面升级,再次取得技术突破。此次升级后,公司服务器的宕机率实现了80%锐降,再次彰显了浪潮信息在服务器技术领域的卓越能力。 浪潮信息全新升级服务器内存故障智能预警修复技术MUPR (Memory …...
JWT整合Gateway实现鉴权(RSA与公私密钥工具类)
一.业务流程 1.使用RSA生成公钥和私钥。私钥保存在授权中心,公钥保存在网关(gateway)和各个信任微服务中。 2.用户请求登录。 3.授权中心进行校验,通过后使用私钥对JWT进行签名加密。并将JWT返回给用户 4.用户携带JWT访问 5.gateway直接通过公钥解密JWT进…...

vue实现全屏screenfull-封装组件
1. 安装依赖 npm install --save screenfull 2. 引用 import screenfull from "screenfull" 3.封装fullScreen/index: <template><div><el-tooltip v-if"!content" effect"dark" :content"fullscreenTips" placement&…...
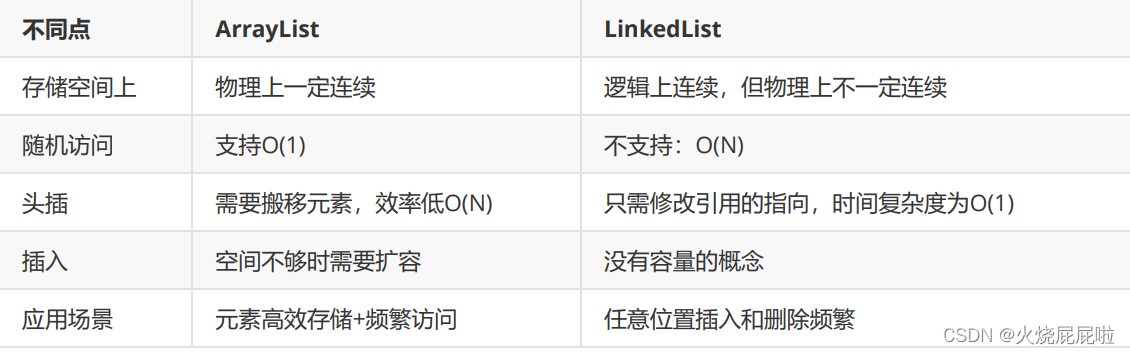
【LinkedList与链表】
目录 1,ArrayList的缺陷 2,链表 2.1 链表的概念及结构 2.2 链表的实现 2.2.1 无头单向非循环链表实现 3,LinkedList的模拟实现 3.1 无头双向链表实现 4,LinkedList的使用 4.1 什么是LinkedList 4.2 LinkedList的使用 5…...
为数据安全护航,袋鼠云在数据分类分级上的探索实践
在大数据时代,数据具有多源异构的特性,且价值各异,企业需依据数据的重要性、价值指数等予以区分,以利采取不同的数据保护举措,避免数据泄露。故而,数据分类分级管理属于数据安全保护中极为重要的环节之一。…...

Spring 循环依赖详解
Spring 循环依赖详解 1. 引言 在Spring框架中,依赖注入(Dependency Injection, DI)是其核心功能之一,它通过配置来管理对象的创建和它们之间的依赖关系。然而,在复杂的应用程序中,开发人员有时会遇到循环…...

项目经理真的不能太“拧巴”
前期的项目经理经常是“拧巴”的,就是心里纠结、思路混乱、行动迟缓。对于每天需要面对各种挑战、协调各方资源、确保项目顺利进行的项目经理来说,这种“拧巴”不仅会让自己陷入内耗中,还会让项目出大问题。 项目计划总是改来改去࿰…...

企业如何选择合适的CRM工具?除Salesforce之外的10大主流选择
对比salesforce,其他10款优秀CRM:纷享销客CRM、Zoho CRM、腾讯企点、销售易、企业微信 (WeCom)、Odoo CR、OroCRM、金蝶、用友CRM、EspoCRM 虽然Salesforce以其全面的功能和强大的市场占有率在海外收获了许多客户,但Salesforce在国内市场的接…...
每年1-1.2万人毕业,男女比例约3:1,测绘工程的就业率如何
测绘工程,一个让人闻风丧胆的理科专业,虎扑评分4.2: 干过测绘的,苦不苦只有大家心里知道,带大家来感受一下,兄弟们的精神状态都十分美妙: 测绘专业到底是什么情况? PS.测绘分为本科…...
JimuReport 积木报表 v1.7.6 版本发布,免费的低代码报表
项目介绍 一款免费的数据可视化报表工具,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完…...

“灵活就业者“超两亿人 游戏开发者如何破局?
随着“灵活就业”者数量突破两亿,我相信“寒气”已经传递到每一位普通人!对于游戏行业的“灵活就业”者,应当如何破局? 首先应该恭喜大家,选择了一个相对“稳健”的行业,无论大环境如何,游戏/软…...

MySQL事务与存储引擎
一、事务的概念 是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行是一个不可分割的工作逻辑单元,在数据库…...

独立开发者如何利用Taotoken的透明计费规避项目超支风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的透明计费规避项目超支风险 对于独立开发者而言,项目预算的控制是决定项目能否持续、健康…...

摆脱论文困扰!盘点2026年普遍认可的的降AI率软件
轻松降低论文AI率在2026年已不再是天方夜谭。最新实测数据显示,2026年降AI率软件正以惊人的效率和精准度颠覆传统方法,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,帮你告别论文焦虑。…...

从‘六度空间’到HNSW:图解这个让推荐系统变快的底层算法
从“六度空间”到HNSW:让推荐系统快如闪电的底层逻辑 你是否想过,为什么社交平台上总能精准推荐你可能认识的人?电商网站能在毫秒间为你匹配心仪商品?这一切背后,都藏着一个将“六度分隔理论”数学化的算法——HNSW&am…...

【ElevenLabs老挝文语音实战指南】:2024年唯一经实测验证的8步本地化语音合成落地方案
更多请点击: https://kaifayun.com 第一章:ElevenLabs老挝文语音合成的技术背景与本地化价值 ElevenLabs 作为全球领先的AI语音生成平台,长期聚焦于高保真、情感化多语言语音合成技术。尽管其支持语言列表持续扩展,老挝文&#x…...

HS2汉化补丁终极解决方案:15分钟快速上手完整指南
HS2汉化补丁终极解决方案:15分钟快速上手完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日语界面而烦恼吗…...

洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能
洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能 【免费下载链接】New_lxmusic_source 六音音源修复版 项目地址: https://gitcode.com/gh_mirrors/ne/New_lxmusic_source 洛雪音乐是一款广受欢迎的开源音乐播放器,但近期许多用户遇到了六音音…...

第八篇:《软件测试的经济学:投入与回报》
在商业环境中,测试不是“免费”的——它需要人力、工具、时间。但缺陷也不是免费的——它可能导致损失、赔偿、用户流失。如何让管理者理解“投入测试是投资,而不是成本”?本文将从经济学角度分析测试的投资回报率(ROI)…...

企业内训系统集成AI问答时采用Taotoken的成本控制实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成AI问答时采用Taotoken的成本控制实践 应用场景类,设想一个企业开发内训知识库系统的场景,…...
)
2026年主流一键生成论文工具全攻略(含免费额度说明)
以下是当前学术圈口碑 TOP 的6 款 AI 写论文工具,覆盖从选题、开题到降重、答辩的论文全流程,剔除冗余工具,每款均附分步骤实操指南场景适配技巧,重点突出中文论文适配性,新手也能快速上手,效率翻倍。一、全…...

SubAgent 进阶:LLM 策略、工具借用与 Skill 嵌套
标签:Java SubAgent LLM策略 llmFactory allowedTools Skill嵌套 j-langchain 前置阅读:SubAgent 基础:拥有自主工具的子代理 适合人群:已掌握 SubAgent 基础用法,希望灵活控制模型选择、工具权限与多层嵌套的 Java 开…...