人工智能中的监督学习和无监督学习

欢迎来到 Papicatch的博客

目录
🍉引言
🍉监督学习
🍈基本思想
🍈具体过程
🍍数据收集
🍍数据预处理
🍍模型选择
🍍模型训练
🍍模型评估
🍍模型部署
🍉无监督学习
🍈基本思想
🍈具体过程
🍍数据收集
🍍数据预处理
🍍模型选择
🍍模型训练
🍍结果分析
🍉案例
🍈监督学习 - 房价预测(回归)
🍈监督学习 - 图像分类(分类)
🍈无监督学习 - 客户分群(聚类)
🍈无监督学习 - 降维和可视化
🍉对比监督学习和无监督学习的区别
🍈数据需求
🍈目标
🍈应用场景
🍈算法复杂度
🍈模型评估
🍉总结
🍉引言
人工智能(AI)中的机器学习(ML)可以根据学习方式分为几种主要类型,其中监督学习和无监督学习是两种最重要的方法。本文将介绍这两种学习方法的基本思想、具体过程,并提供四个复杂的代码实现案例来对比它们的区别。
🍉监督学习
🍈基本思想
监督学习是一种利用已知标签的数据进行训练的机器学习方法。其目标是学习一个函数,通过该函数可以将输入映射到相应的输出。监督学习可以分为两类:回归和分类。
- 回归:用于预测连续的数值,例如房价预测。
- 分类:用于预测离散的类别标签,例如图像分类。
🍈具体过程
🍍数据收集
收集带有标签的数据集,这些数据包含输入特征和对应的输出标签。
🍍数据预处理
清洗和整理数据,处理缺失值,进行特征选择和特征工程,确保数据质量。
🍍模型选择
选择适合问题的机器学习算法,例如线性回归、支持向量机、决策树、神经网络等。
🍍模型训练
使用训练数据集对模型进行训练,调整模型参数以最小化预测误差。
🍍模型评估
使用验证数据集评估模型性能,常用指标包括准确率、精确率、召回率、均方误差等。
🍍模型部署
将训练好的模型应用到实际数据中进行预测,并持续监控模型性能,进行必要的调整和改进。
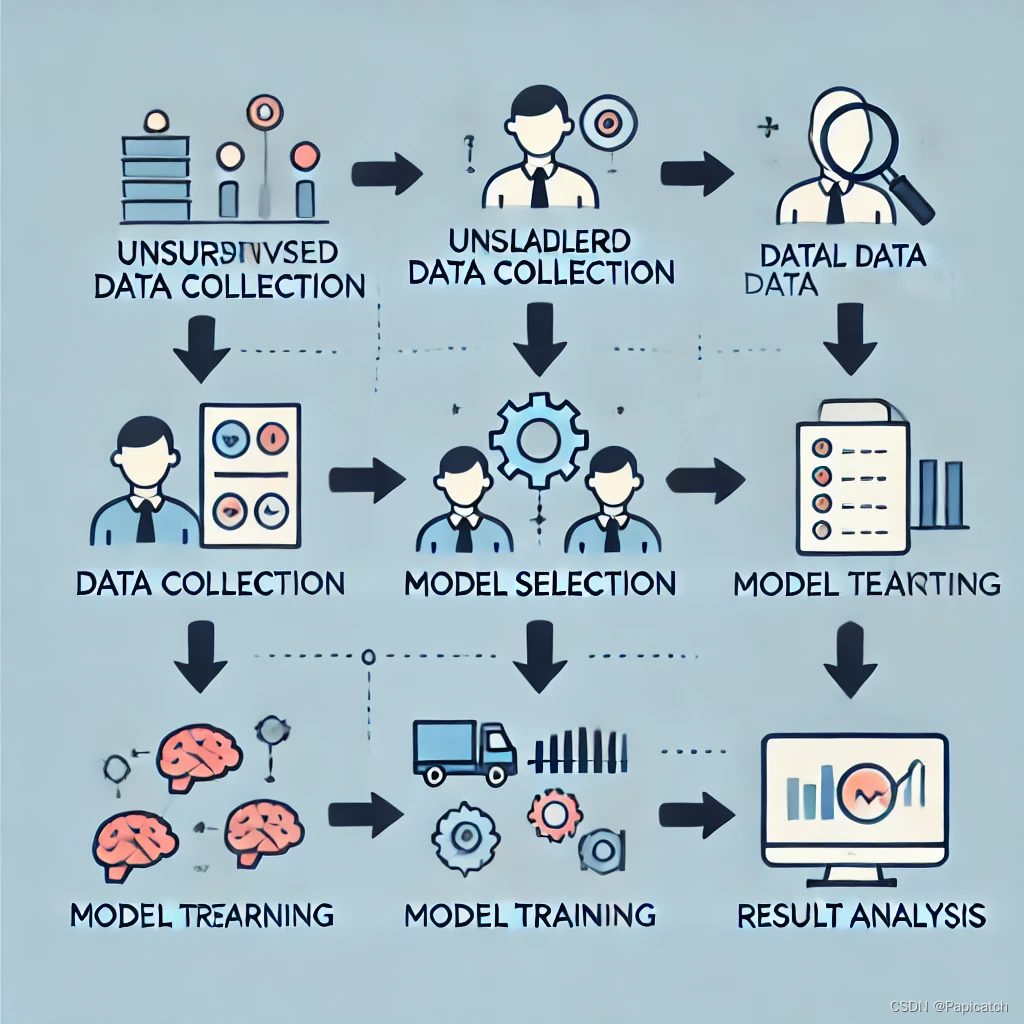
🍉无监督学习
🍈基本思想
无监督学习是一种不使用标签数据进行训练的机器学习方法。其目标是从数据中发现潜在的模式或结构。无监督学习常见的方法有聚类和降维。
- 聚类:将数据分成多个组,每组中的数据具有相似性,例如客户分群。
- 降维:减少数据的维度,同时保持数据的重要特征,例如主成分分析(PCA)。
🍈具体过程
🍍数据收集
收集未标注的数据集,这些数据只包含输入特征。
🍍数据预处理
同样需要进行数据清洗和整理,确保数据质量。
🍍模型选择
选择适合问题的无监督学习算法,例如K-means、层次聚类、主成分分析等。
🍍模型训练
使用数据集对模型进行训练,以发现数据的结构或模式。
🍍结果分析
对模型输出的结果进行分析和解释,评估模型在实际应用中的表现。
🍉案例
🍈监督学习 - 房价预测(回归)

import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 数据加载
data = pd.read_csv('housing.csv')# 数据预处理
X = data.drop('price', axis=1)
y = data['price']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 模型选择与训练
model = LinearRegression()
model.fit(X_train, y_train)# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
在这个案例中,我们使用线性回归算法预测房价。通过将数据集分为训练集和测试集,我们训练模型并评估其性能。
🍈监督学习 - 图像分类(分类)
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
from sklearn.metrics import classification_report# 数据加载
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()# 数据预处理
train_images, test_images = train_images / 255.0, test_images / 255.0# 模型选择与训练
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10)
])model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))# 模型评估
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'Test accuracy: {test_acc}')
在这个案例中,我们使用卷积神经网络(CNN)进行图像分类任务。通过对CIFAR-10数据集进行训练和测试,我们评估模型的准确性。
🍈无监督学习 - 客户分群(聚类)
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 数据加载
data = pd.read_csv('customer_data.csv')# 数据预处理
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)# 模型选择与训练
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(data_scaled)# 聚类结果
labels = kmeans.labels_# 结果分析
plt.scatter(data_scaled[:, 0], data_scaled[:, 1], c=labels, cmap='viridis')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Customer Segmentation')
plt.show()
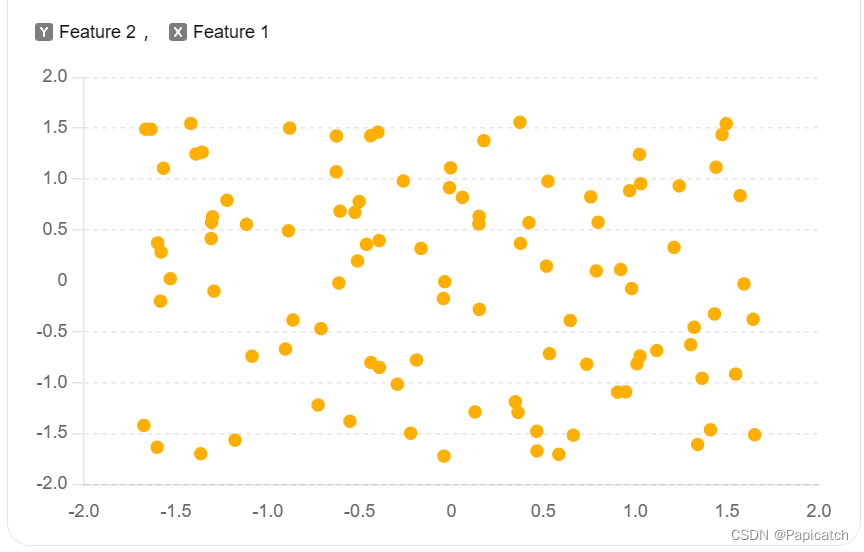
在这个案例中,我们使用K-means聚类算法对客户数据进行分群。通过数据标准化和K-means算法,我们可以发现数据中的自然分组。
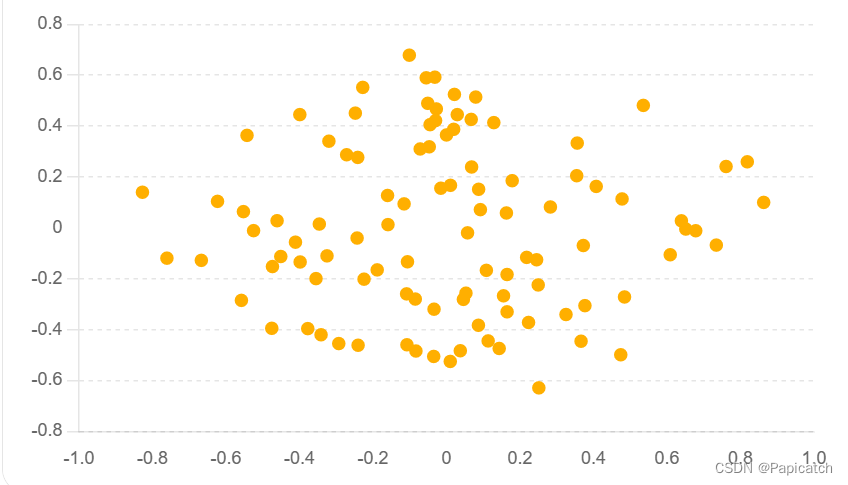
🍈无监督学习 - 降维和可视化

import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt# 数据加载
data = pd.read_csv('high_dimensional_data.csv')# 数据预处理
data_cleaned = data.dropna() # 假设需要进行缺失值处理# 模型选择与训练
pca = PCA(n_components=2) # 将数据降到2维
principal_components = pca.fit_transform(data_cleaned)# 结果分析
plt.scatter(principal_components[:, 0], principal_components[:, 1], cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of High Dimensional Data')
plt.show()
🍉对比监督学习和无监督学习的区别
🍈数据需求
- 监督学习需要带标签的数据,而无监督学习不需要标签数据。这意味着监督学习的应用更依赖于数据标注,而无监督学习可以应用于更多场景。
🍈目标
- 监督学习的目标是预测已知输出,例如分类或回归问题。
- 无监督学习的目标是发现数据中的潜在结构,例如聚类或降维。
🍈应用场景
- 监督学习常用于需要明确预测的任务,例如图像分类、股票价格预测、欺诈检测等。
- 无监督学习常用于探索性数据分析和特征提取,例如客户分群、数据降维、异常检测等。
🍈算法复杂度
- 监督学习算法通常需要大量标注数据进行训练,数据标注成本高,但模型训练和评估的过程相对明确。
- 无监督学习算法需要更复杂的模型和算法来从未标注数据中提取信息,尽管数据获取成本低,但结果的解释和验证可能更具挑战性。
🍈模型评估
- 监督学习的模型评估可以使用诸如准确率、精确率、召回率、均方误差等明确指标。
- 无监督学习的模型评估通常依赖于领域专家的解释和对数据模式的直觉理解,缺乏标准化的评估指标。
🍉总结
本文详细介绍了人工智能(AI)中监督学习和无监督学习的基本思想、具体过程,并通过四个复杂的代码实现案例对比了它们的区别。在监督学习中,我们通过使用已标注的数据集进行模型训练,目标是预测已知输出,如回归问题中的房价预测和分类问题中的图像分类。无监督学习则不使用标签数据,目标是从数据中发现潜在的模式或结构,如聚类中的客户分群和降维中的主成分分析(PCA)。
通过对监督学习和无监督学习的详细讲解以及实际代码实现,我们了解到这两种方法在数据需求、目标、应用场景、算法复杂度和模型评估方面的不同。监督学习需要大量标注数据进行训练,而无监督学习不需要标签数据,更适用于探索性数据分析和特征提取。监督学习的目标是预测明确的输出,而无监督学习则致力于发现数据中的隐藏结构。
在实际应用中,根据问题的具体需求选择合适的学习方法至关重要。希望通过本文的介绍和案例展示,读者能够对监督学习和无监督学习有更深入的理解,并能在实际项目中灵活运用这两种方法解决问题。
希望能给大家提供一些帮助!!!

相关文章:
人工智能中的监督学习和无监督学习
欢迎来到 Papicatch的博客 目录 🍉引言 🍉监督学习 🍈基本思想 🍈具体过程 🍍数据收集 🍍数据预处理 🍍模型选择 🍍模型训练 🍍模型评估 🍍模型部署…...
)
深度学习500问——Chapter12:网络搭建及训练(1)
文章目录 12.1 TensorFlow 12.1.1 TensorFlow 是什么 12.1.2 TensorFlow的设计理念是什么 12.1.3 TensorFlow特点有哪些 12.1.4 TensorFlow的系统架构是怎样的 12.1.5 TensorFlow编程模型是怎样的 12.1.6 如何基于TensorFlow搭建VGG16 12.1 TensorFlow 12.1.1 TensorFlow 是什…...

HuggingFace CLI 命令全面指南
文章目录 安装与认证1.1 安装 HuggingFace Hub 库使用 pip 安装使用 conda 安装验证安装 1.2 认证与登录生成访问令牌使用访问令牌登录环境变量认证验证认证 下载文件2.1 下载单个文件安装 huggingface_hub 库认证与登录下载单个文件 2.2 下载特定版本的文件下载特定版本的文件…...
FreeRTOS源码分析
目录 1、FreeRTOS目录结构 2、核心文件 3、移植时涉及的文件 4、头文件相关 4.1 头文件目录 4.2 头文件 5、内存管理 6、入口函数 7、数据类型和编程规范 7.1 数据类型 7.2 变量名 7.3 函数名 7.4 宏的名 1、FreeRTOS目录结构 使用 STM32CubeMX 创建的 FreeRTOS 工…...

python实战:将视频内容上传到社交媒体平台
在Python中,上传视频到不同的平台可能需要使用不同的API和库。以下是一些常见的平台以及如何使用Python进行上传的示例: YouTube: 使用Google提供的YouTube Data API。 首先,你需要从Google Cloud控制台获取API密钥,并安装google-…...
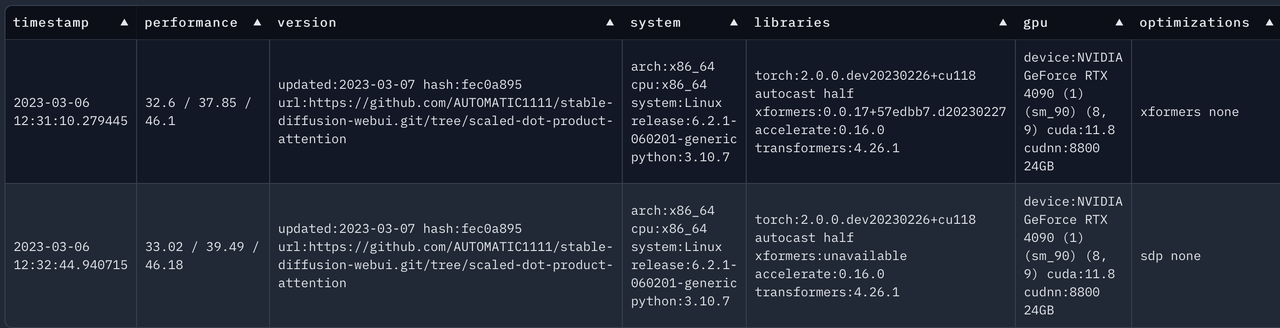
【深度学习】sdwebui A1111 加速方案对比,xformers vs Flash Attention 2
文章目录 资料支撑资料结论sdwebui A1111 速度对比测试sdxlxformers 用contorlnet sdxlsdpa(--opt-sdp-no-mem-attention) 用contorlnet sdxlsdpa(--opt-sdp-attention) 用contorlnet sdxl不用xformers或者sdpa ,用contorlnet sdxl不用xformers或者sdpa …...

5分钟了解单元测试
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是单元测试? 单元测试是指,对软件中的最小可测试单元在与程序其…...
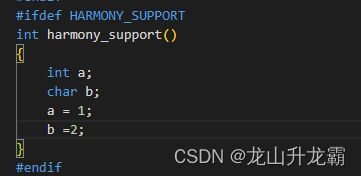
VSCode之C/C++插件之宏定义导致颜色变暗
这是因为该宏没有定义或者定义在makefile文件中导致无法被插件识别到,导致误判了 索性将该机制去了,显示也会好看些,如下将C_Cpp下的Dim Inactive Regions勾去了 显示效果会好很多。...

自然语言处理概述
目录 1.概述 2.背景 3.作用 4.优缺点 4.1.优点 4.2.缺点 5.应用场景 5.1.十个应用场景 5.2.文本分类 5.2.1.一般流程 5.2.2.示例 6.使用示例 7.总结 1.概述 自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,旨在实…...

用Rust和Pingora轻松构建超越Nginx的高效负载均衡器
目录 什么是Pingora?实现过程 初始化项目编写负载均衡器代码代码解析部署 总结 1. 什么是Pingora? Pingora 是一个高性能的 Rust 库,用于构建可负载均衡器的代理服务器,它的诞生是为了弥补 Nginx 存在的缺陷。 Pingora 提供了…...
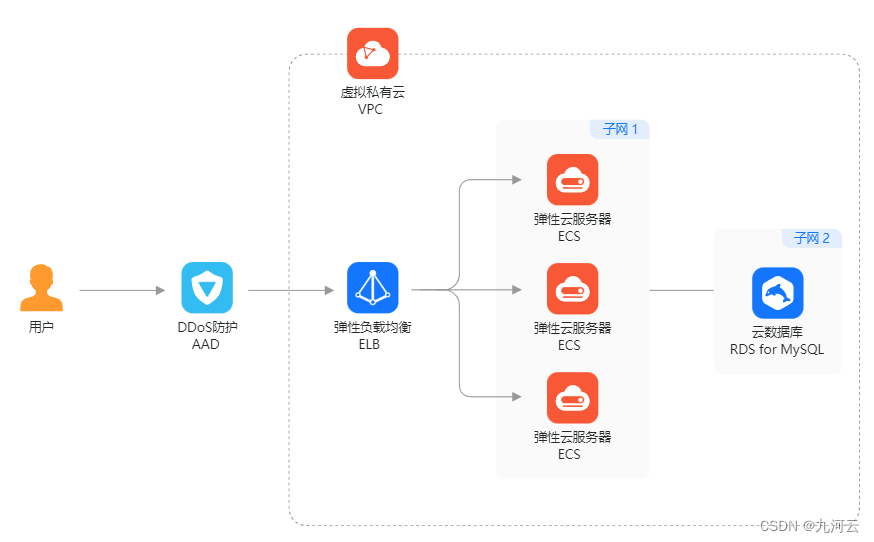
华为云与AWS负载均衡服务深度对比:性能、成本与可用性
随着云计算的迅速发展,企业对于云服务提供商的选择变得越来越关键。在选择云服务提供商时,负载均衡服务是企业关注的重点之一。我们九河云将深入比较两大知名云服务提供商华为云和AWS的负载均衡服务,从性能、成本和可用性等方面进行对比。 AW…...
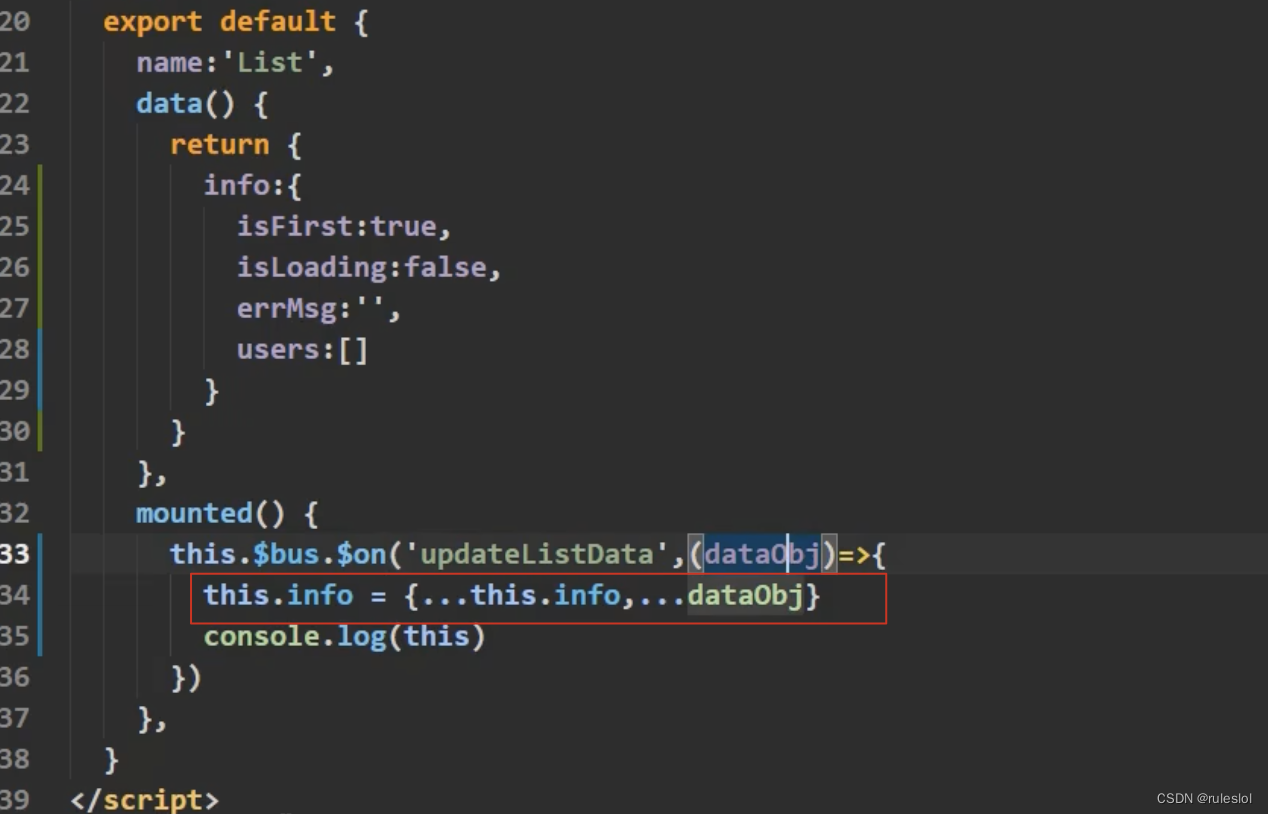
Vue65-组件之间的传值
1、收数据 2、传数据 3、批量的数据替换 若是info里面有四个数据,传过来的dataObj里面有三个数据,则info里面也只有三个数据了 解决方式: 该写法还有一个优势:传参的时候,顺序可以随意!...
Java零基础之多线程篇:线程生命周期
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...
技术差异,应用场景;虚拟机可以当作云服务器吗
虚拟机和云服务器是现在市面上常见的两种计算资源提供方式,很多人把这两者看成可以相互转换或者替代的物品,实则不然,这两种资源提供方式有许多相似之处,但是也有不少区别,一篇文章教你识别两者的技术差异,…...
Qt Quick 教程(一)
文章目录 1.Qt Quick2.QML3.Day01 案例main.qml退出按钮,基于上面代码添加 4.使用Qt Design StudioQt Design Studio简介Qt Design Studio工具使用版本信息 1.Qt Quick Qt Quick 是一种现代的用户界面技术,将声明性用户界面设计和命令性编程逻辑分开。 …...
)
react钩子函数用法(useCallback、useMemo)
useMemo import { useMemo } from react; function MyComponent({ a, b }) { const memoizedValue useMemo(() > { // 进行一些昂贵的计算 return a b; }, [a, b]); // 当 a 或 b 发生变化时,memoizedValue 将被重新计算 return <div>{memoizedVa…...
linux配置Vnc Server给Windows连接
1. linux 安装必要vnc server和桌面组件 sudo apt -y install tightvncserversudo apt install xfce4 xfce4-goodies2. linux 配置vncserver密码 #bash vncserver参考: https://cn.linux-console.net/?p21846#google_vignette 3. 将启动桌面命令写入.vnc/xstartup # .vnc/x…...

Android中的KeyEvent详解
介绍 在Android中,KeyEvent 是用来表示按键事件的类,可根据对应的事件来处理按键输入,具体包含了关于按键事件的信息,例如按键的代码、动作(按下或释放)以及事件的时间戳,KeyEvent 对象通常在用…...

移植案例与原理 - HDF驱动框架-驱动配置(2)
1.2.7 节点复制 节点复制可以实现在节点定义时从另一个节点先复制内容,用于定义内容相似的节点。语法如下,表示在定义"node"节点时将另一个节点"source_node"的属性复制过来。 node : source_node示例如下,编译后bar节点…...

年终奖发放没几天,提离职领导指责我不厚道,我该怎么办?
“年终奖都发了,你还跳槽?太不厚道了吧!” “拿完年终奖就走人,这不是典型的‘骑驴找马’吗?” 每到岁末年初,关于“拿到年终奖后是否应该立即辞职”的话题总会引发热议。支持者认为,这是个人…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...