Python基础-引用参数、斐波那契数列、无极分类
1.引用参数的问题
(1)列表(list)
- 引用参数,传地址的参数,即list1会因list2修改而改变。
list1 = [1,2,3,4]
list2 = list1
print(list1)
list2[2] = 1
print(list2)
print(list1)
- 非引用参数,不传地址的参数,即list1不会因list2修改而改变。
list1 = [1,2,3,4]
list2 = list1[:] #原理:复制了(遍历list1)一份list1再赋值给list2
print(list1)
list2[2] = 1
print(list2)
print(list1)
(2)字典(Dictionary)
- 引用参数,传地址的参数,即dict1会因dict2修改而改变。
dict1 ={'name':'deng','age':18,'sex':1}
dict2 = dict1
print(dict1)
dict2['name'] = 'xiaodeng'
print(dict2)
print(dict1)
- 非引用参数,不传地址的参数,即dict1不会因dict2修改而改变。
dict1 ={'name':'deng','age':18,'sex':1}
dict2 = {k:dict1[k] for k in dict1} #原理:复制一份(遍历dict1)再拷贝给dict2
print(dict1)
dict2['name'] = 'xiaodeng'
print(dict2)
print(dict1)
(3)列表集合(set)
- 引用参数,传地址的参数,即set1会因set2修改而改变。
set1 = set([1,2,3,4])
set2= set1
print(set1)
set2.add(5)
print(set2)
print(set1)
- 非引用参数,不传地址的参数,即set1不会因set2修改而改变。
set1 = set([1,2,3,4]) #列表集合的引用参数()
s = list(set1) # s=[1,2,3,4] 强制将集合set类型转化为列表list(因为列表才能进行遍历复制)
set2 = set(s[:]) # set2=([1,2,3,4]) 再将列表list强制转化回集合set类型
print(set1)
set2.add(5)
print(set2)
print(set1)
2.斐波那契数列
这里我使用一个实例问题进行分享:
兔子种群数量问题:
假设一对兔子一个月能生出一对兔子,出生的一对兔子到能够生育新的兔子需要1个月的时间。那如果一
个年之后这最开始这对兔子可以产生的种群兔子数量是多少呢?

从上面可以得到一个规律除了1月跟2月以外其它月的兔子对数是前两个月之和:
比如:3月的兔子数量就是1月跟2月数量之和,其它也是一样的。
解决方案:
(1)使用迭代来完成上面的运算:
def getNumber(n = 12):n1 = 1 # n1代表n-2这个月兔子的数量n2 = 1 # n2代表n-1这个月兔子的数量n3 = 1 # n3代表n这个月兔子的数量# 使用循环完成计算while n > 2:# print(n)n3 = n1 + n2 # n月的兔子等于n-1月加上n-2月的兔子数量# 为了计算下个月兔子数量,我们需要重新设置n-1与n-2月份的兔子数量n1 = n2n2 = n3n -= 1print("兔子的数量为:%d"% n3) return n3
(2)使用递归来完成上面的运算:
def getNumber2(n = 1):if n==1 or n==2:return 1else:return getNumber2(n-1) + getNumber2(n-2)
3.无极分类
分类为父子级分类。并且子级分类是没有极限的。以数据格式来显示分类。这样的分类称为无极分类。
categorys = [{"id":2, "name":"国际新闻", "p_id":0},{"id":1, "name":"国内新闻", "p_id":0},{"id":3, "name":"娱乐新闻", "p_id":0},{"id":4, "name":"体育新闻", "p_id":0},{"id":5, "name":"广东新闻", "p_id":1},{"id":6, "name":"广西新闻", "p_id":1},{"id":7, "name":"北海新闻", "p_id":6},{"id":8, "name":"南宁新闻", "p_id":6},{"id":9, "name":"深圳新闻", "p_id":5},{"id":10, "name":"南山新闻", "p_id":9},{"id":11, "name":"龙岗新闻", "p_id":9},{"id":12, "name":"上水径新闻", "p_id":11},{"id":13, "name":"篮球新闻", "p_id":4},{"id":14, "name":"NBA新闻", "p_id":13},{"id":15, "name":"CBA新闻", "p_id":13},
]# for itme in categorys:
# print(itme)"""
由于无极分类数据本身的输出就是混乱的。
我们需要对该数据进行排序输出。
以以下的例子为准:
|- 国内新闻
|- |- 广东新闻
|- |- |- 深圳新闻
|- |- |- |- 南山新闻
|- |- |- |- 龙岗新闻
|- |- |- |- |- 上水径新闻
|- |- 广西新闻
|- |- |- 北海新闻
|- |- |- 南宁新闻"""# 定义通过PID获取同级所有分类的方法
def getTree( pid = 0, tree = [], level=1):level_str = '|- ' * level # 通过for循环进行遍历for cat in categorys:if cat["p_id"] == pid: # 判断获取的pid与cat中的p_id是否相同cat["level_str"] = level_str # 往cat添加新字段level_str并且赋值level_strcat["level"] = level # 往cat添加新字段level并且赋值leveltree.append(cat) # 将cat添加到tree中tree = getTree(cat["id"], tree, level+1) # 通过自调找当前分类的子级分类return treetree = getTree()
for cat in tree:print("%s %s"%(cat["level_str"], cat["name"]))
相关文章:
Python基础-引用参数、斐波那契数列、无极分类
1.引用参数的问题 (1)列表(list) 引用参数,传地址的参数,即list1会因list2修改而改变。 list1 [1,2,3,4] list2 list1 print(list1) list2[2] 1 print(list2) print(list1)非引用参数,不传…...

【MySQL统计函数count详解】
MySQL统计函数count详解 1. count()概述2. count(1)和count(*)和count(列名)的区别3. count(*)的实现方式 1. count()概述 count() 是一个聚合函数,返回指定匹配条件的行数。开发中常用来统计表中数据,全部数据,不为null数据,或…...

大数据的发展,带动电子商务产业链,促进了社会的进步【电商数据采集API接口推动电商项目的源动力】
最近几年计算机技术在诸多领域得到了有效的应用,同时在多方面深刻影响着我国经济水平的发展。除此之外,人民群众的日常生活水平也受大数据技术的影响。 在这其中电子商务领域也在大数据技术的支持下,得到了明显的进步。虽然电子商务领域的发…...

Python类中变量定义详解
✨前言: Python中的类可以定义两种类型的变量:类变量和实例变量。 类变量(Class Variables): 类变量是在类级别上定义的变量,它们是对所有实例共享的。这意味着类变量只有一个副本,无论你创建了…...

c++ extern 关键字详解
extern关键字在C中用于声明变量或函数的外部链接。它通常用于以下几种场景: 声明全局变量:在一个文件中定义变量,在其他文件中使用extern声明该变量,以便在多个文件之间共享。C和C混合编程:在C代码中引用C语言编写的函…...
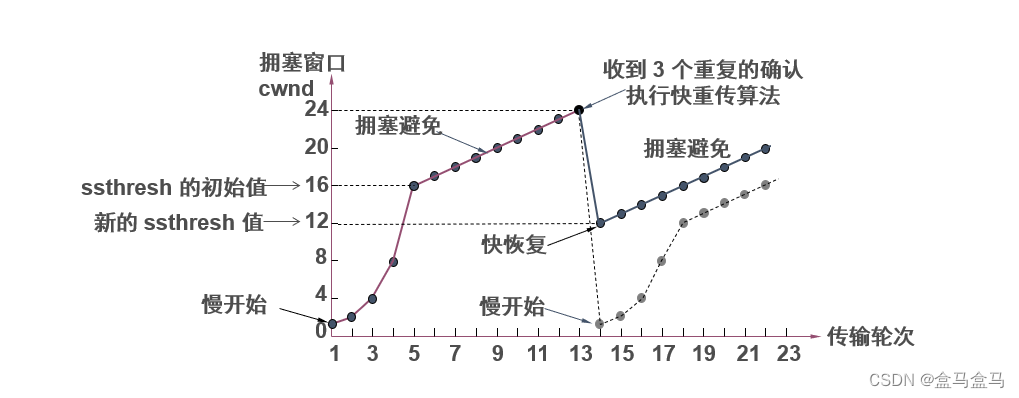
计算机网络:运输层 - TCP 流量控制 拥塞控制
计算机网络:运输层 - TCP 流量控制 & 拥塞控制 滑动窗口流量控制拥塞控制慢开始算法拥塞避免算法快重传算法快恢复算法 滑动窗口 如图所示: 在TCP首部中有一个窗口字段,该字段就基于滑动窗口来辅助流量控制和拥塞控制。所以我们先讲解滑…...

Python学习打卡:day10
day10 笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了 目录 day1073、文件的读取操作文件的操作步骤open()打开函数mode常用的三种基础访问模式读操作相关方法read()方法readlines()方法readline()方法for循…...
新书速览|Ubuntu Linux运维从零开始学
《Ubuntu Linux运维从零开始学》 本书内容 Ubuntu Linux是目前最流行的Linux操作系统之一。Ubuntu的目标在于为一般用户提供一个最新的、相当稳定的、主要由自由软件构建而成的操作系统。Ubuntu具有庞大的社区力量,用户可以方便地从社区获得帮助。《Ubuntu Linux运…...
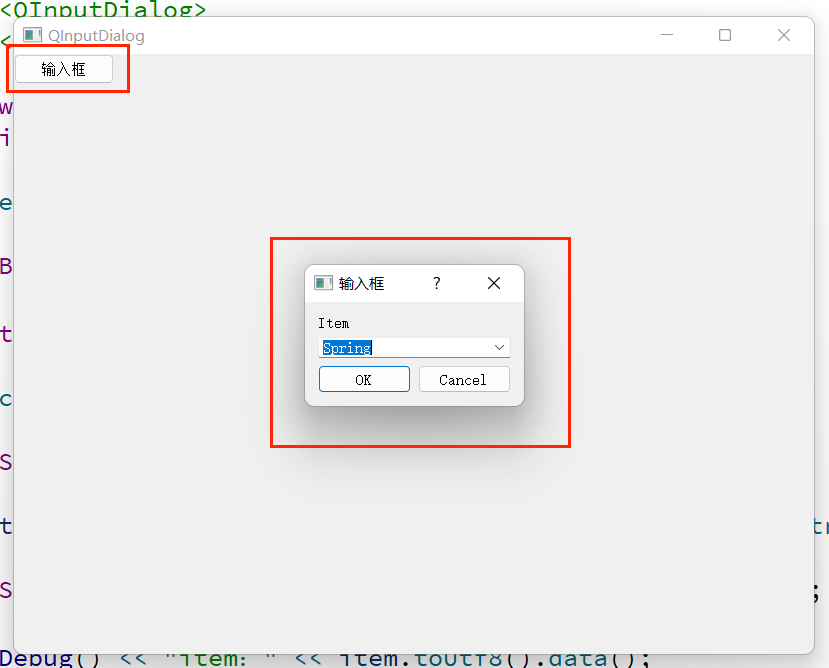
[Qt的学习日常]--窗口
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、窗口的分…...
Vue发送http请求
1.创建项目 创建一个新的 Vue 2 项目非常简单。在终端中,进入您希望创建项目的目录(我的目录是D:\vue),并运行以下命令: vue create vue_test 2.切换到项目目录,运行项目 运行成功后,你将会看到以下的编译成功的提示…...
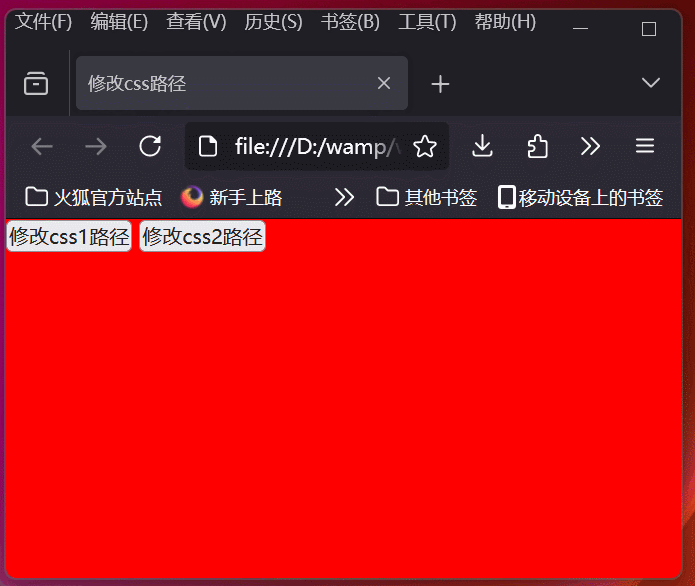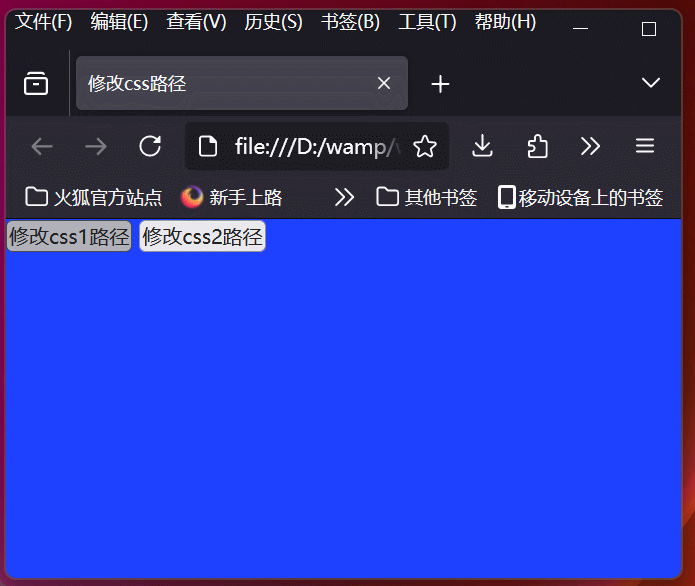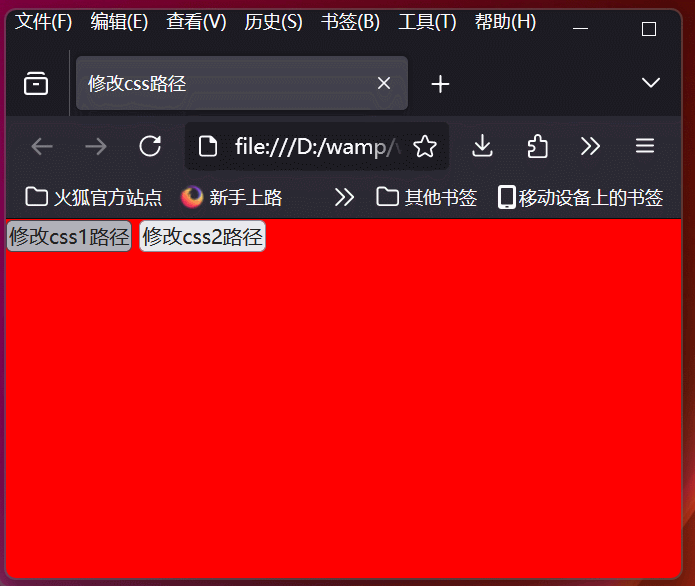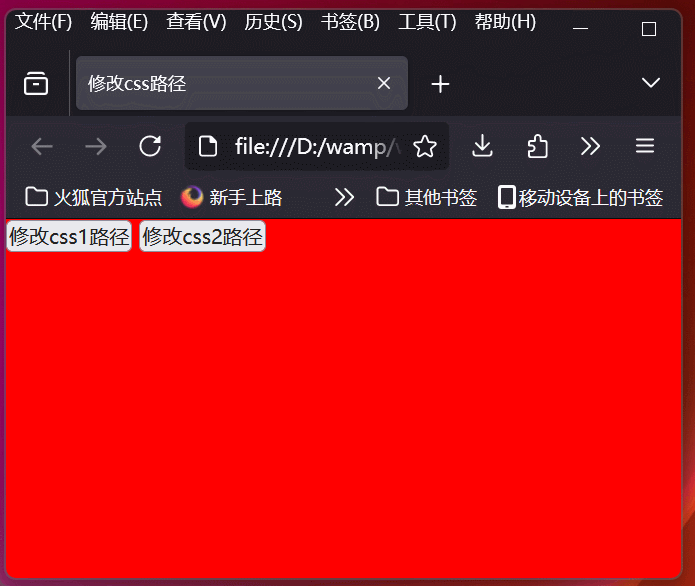
学习使用js和jquery修改css路径,实现html页面主题切换功能
学习使用js和jquery修改css路径,实现html页面主题切换功能 效果图html代码js切换css关键代码jquery切换css关键代码 效果图 html代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>修改css路径</title&g…...
请介绍一下Redis的数据淘汰策略)
(转)请介绍一下Redis的数据淘汰策略
1. **NoEviction(不淘汰)**:当内存不足时,直接返回错误,不淘汰任何数据。该策略适用于禁止数据淘汰的场景,但需要保证内存足够。 2. **AllKeysLFU(最少使用次数淘汰)**:…...

APP自动化测试-Appium常见操作之详讲
一、基本操作 1、点击操作 示例:element.click() 针对元素进行点击操作 2、初始化:输入中文的处理 说明:如果连接的是虚拟机(真机无需加这两个参数,加上可能会影响手工输入),在初始化配置中…...

写给大数据开发:谈谈数仓建模的反三范式
在数仓建设中,我们经常谈论反三范式。顾名思义,反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。简单来说,就是浪费存储空间,节省查询时间。用行话讲,这就是以空间换时间。听起来像是用大炮打蚊子&#…...

Stable diffusion 3 正式开源
6月12日晚,著名开源大模型平台Stability AI正式开源了,文生图片模型Stable Diffusion 3 Medium(以下简称“SD3-M”)权重。 SD3-M有20亿参数,平均生成图片时间在2—10秒左右推理效率非常高,同时对硬件的需求…...
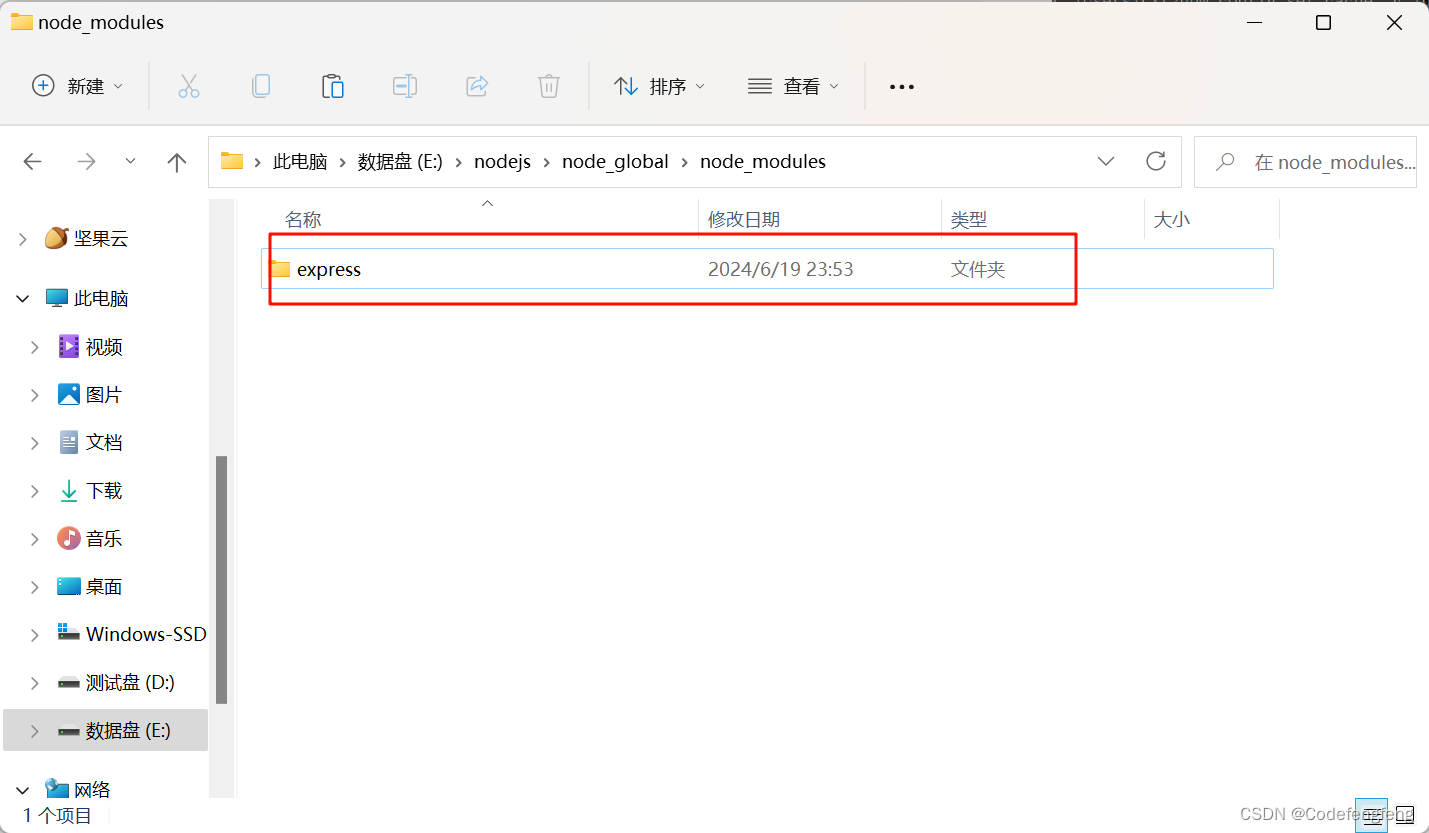
如何配置node.js环境
文章目录 step1. 下载node.js安装包step2. 创建node_global, node_cache文件夹step3.配置node环境变量step3. cmd窗口检查安装的node和npm版本号step4. 设置缓存路径\全局安装路径\下载镜像step5. 测试配置的nodejs环境 step1. 下载node.js安装包 下载地址:node.js…...

python tensorflow 各种神经元
感知机神经元(Perceptron Neuron): 最基本的人工神经元模型,用于线性分类任务。 import numpy as npclass Perceptron:def __init__(self, input_size, learning_rate0.01, epochs1000):self.weights np.zeros(input_size 1) #…...

Gone框架介绍27 - 再讲 Goner 和 依赖注入
gone是可以高效开发Web服务的Golang依赖注入框架 github地址:https://github.com/gone-io/gone 文档地址:https://goner.fun/zh/ 文章目录 Goner 和 依赖注入Goner的定义依赖标记Goners 注册Priest函数 Goner 和 依赖注入 Gone 作为一个依赖注入框架&am…...
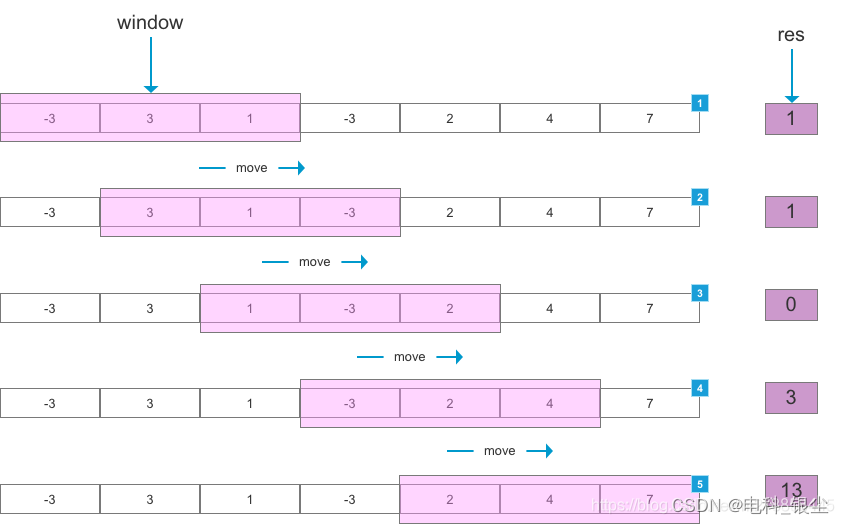
【Python/Pytorch 】-- 滑动窗口算法
文章目录 文章目录 00 写在前面01 基于Python版本的滑动窗口代码02 算法效果 00 写在前面 写这个算法原因是:训练了一个时序网络,该网络模型的时序维度为32,而测试数据的时序维度为90。因此需要采用滑动窗口的方法,生成一系列32…...

Clickhouse集群create drop database可删除集群数据库或只删除本地数据库
集群环境下,在任意一个节点创建数据库,如果加上了ON CLUSTER clustername,则在集群环境的所有节点上都创建了该数据库,并在集群环境的所有节点上都创建了该数据库对应的目录,且数据库的metadata_path对应的目录路径在所…...

LFM2.5-1.2B-Thinking-GGUF效果展示:32K上下文下跨PDF章节引用准确性验证
LFM2.5-1.2B-Thinking-GGUF效果展示:32K上下文下跨PDF章节引用准确性验证 1. 模型能力概览 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用GGUF格式存储,配合llama.cpp运行时ÿ…...

专科ENSP毕设实战:基于eNSP的校园网高可用架构设计与配置避坑指南
最近在帮几个专科的学弟学妹看他们的eNSP毕业设计,发现大家普遍卡在几个地方:拓扑画得挺漂亮,但一配置就各种不通;协议背得滚瓜烂熟,但实际命令敲下去就报错;最后答辩演示时,一拔线整个网络就瘫…...

从原理到实践:Matlab相机标定参数详解与坐标变换全流程
1. 相机标定基础概念与Matlab工具箱实战 刚接触相机标定的朋友可能觉得那些参数看着就头疼,其实拆解开来并不复杂。我最早做机器人视觉项目时,也是被各种矩阵绕得晕头转向,直到自己动手标定了十几台工业相机才摸清门道。相机标定的本质就是建…...

CentOS 8下openLDAP服务器搭建避坑指南:从第三方仓库到phpLDAPadmin配置
CentOS 8企业级openLDAP部署实战:从仓库选择到安全加固全解析 在当今企业IT架构中,目录服务作为身份认证和资源管理的核心组件,其重要性不言而喻。而openLDAP作为开源目录服务的标杆解决方案,凭借其轻量高效、跨平台兼容的特性&am…...

LFM2.5-1.2B-Thinking-GGUF入门指南:Thinking模型输出后处理机制解析
LFM2.5-1.2B-Thinking-GGUF入门指南:Thinking模型输出后处理机制解析 1. 模型概述 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用GGUF格式存储,配合llama.cpp运行时,能够在…...

Qwen3.5-4B-Claude-GGUF效果展示:同一问题在不同Temperature下的推理差异
Qwen3.5-4B-Claude-GGUF效果展示:同一问题在不同Temperature下的推理差异 1. 模型介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。这个…...

GLM-OCR公式识别效果展示:LaTeX格式精准渲染,学术党必备工具
GLM-OCR公式识别效果展示:LaTeX格式精准渲染,学术党必备工具 作为一名经常需要处理学术文献的研究人员,我深知公式识别的痛点。那些复杂的数学表达式,要么手动输入到LaTeX里费时费力,要么用传统OCR工具识别后变成一堆…...

AWS Lambda性能调优终极指南:如何通过内存配置平衡成本与执行速度
AWS Lambda性能调优终极指南:如何通过内存配置平衡成本与执行速度 【免费下载链接】aws-lambda-power-tuning AWS Lambda Power Tuning is an open-source tool that can help you visualize and fine-tune the memory/power configuration of Lambda functions. It…...

OpenClaw压力测试:Qwen3-VL:30B在飞书中的并发处理能力
OpenClaw压力测试:Qwen3-VL:30B在飞书中的并发处理能力 1. 为什么需要测试个人场景下的并发能力? 上周我在飞书群里部署了一个基于OpenClawQwen3-VL:30B的智能助手,原本只是想让同事帮忙测试基础功能。没想到午休时间突然有十几个人同时机器…...

【大模型学习】常见AI工作流框架组合
常见AI工作流框架组合**一、框架组合全景图****二、各组合深度分析****1. LangChain LangGraph(大模型工程师首选)****技术架构****实现复杂度****优缺点****推荐场景****2. LlamaIndex Flowise(低代码RAG快速落地)****技术架构…...