海量数据处理利器 Roaring BitMap 原理介绍
作者:来自 vivo 互联网服务器团队- Zheng Rui
本文结合个人理解梳理了BitMap及Roaring BitMap的原理及使用,分别主要介绍了Roaring BitMap的存储方式及三种container类型及Java中Roaring BitMap相关API使用。
一、引言
在进行大数据开发时,我们可以使用布隆过滤器和Redis中的HyperLogLog来进行大数据的判重和数量统计,虽然这两种方法节省内存空间并且效率很高,但是也存在一些误差。如果需要100%准确的话,我们可以使用BitMap来存储数据。
BitMap 位图索引数据结构被广泛地应用于数据存储和数据搜索中,但是对于存储较为分散的数据时,BitMap会占用比较大的内存空间,因此我们更偏向于使用 Roaring BitMap稀疏位图索引进行存储。同时,Roaring BitMap广泛应用于数据库存储和大数据引擎中,例如Hive,Spark,Doris,Kylin等。
下文将分别介绍 BitMap 和 Roaring BitMap 的原理及其相关应用。
二、BitMap原理
BitMap的基本思想就是用bit位来标记某个元素对应的value,而key就是这个元素。
例如,在下图中,是一个字节代表的8位,下标为1,2,4,6的bit位的值为1,则该字节表示{1,2,4,6}这几个数。

在Java中,1个int占用4个字节,如果用int来存储这四个数字的话,那么将需要4 * 4 = 16字节。
BitMap可以用于快速排序,查找,及去重等操作。优点是占用内存少(相较于数组)和运算效率高,但是缺点也非常明显,无法存储重复的数据,并且在存储较为稀疏的数据时,浪费存储空间较多。
三、Roaring BitMap 原理
3.1 存储方式
为了解决BitMap存储较为稀疏数据时,浪费存储空间较多的问题,我们引入了稀疏位图索引Roaring BitMap。Roaring BitMap 有较高的计算性能及压缩效率。下面简单介绍一下Roaring BitMap的基本原理。
Roaring BitMap处理int型整数,将32位的int型整数分为高16位和低16位分别进行处理,高16位作为索引分片,而低16位用于存储实际数据。其中每个索引对应一个数据桶(bucket),那么一共可以包含2^16 = 65536个数据块。每个数据桶使用container容器来存储低16位的部分,每个数据桶最多存储2^16 = 65536个数据。

如上图所示,高16位作为索引查找具体的数据块,当前索引值为0,低16位作为value进行存储。
Roaring BitMap在进行数据存储时,会先根据高16位找到对应的索引key(二分查找),低16位作为key对应的value,先通过key检查对应的container容器,如果发现container不存在的话,就先创建一个key和对应的container,否则直接将低16位存储到对应的container中。
Roaring BitMap的精妙之处在于使用不同类型的container,接下来将对其进行介绍。
3.2 container类型
1.ArrayContainer
顾名思义,ArrayContainer直接采用数组来存储低16位数据,没有采用任何数据压缩算法,适合存储比较稀疏的数据,在Java中,使用short数组来存储,并且占用的内存空间大小和数据量成线性关系。由于short为2字节,因此n个数据为2n字节。ArrayContainer采用二分查找定位有序数组中的元素,因此时间复杂度为O(logN)。ArrayContainer的最大数据量为4096, 4096 * 2b = 8kb。
2.BitMapContainer
BitMapContainer采用BitMap的原理,就是一个没有经过压缩处理的普通BitMap,适合存储比较稠密的数据,在Java中使用Long数组存储低16位数据,每一个bit位表示一个数字。由于每个container需要存储2^16 = 65536个数据,如果通过BitMap进行存储的话,需要使用2^16个bit进行存储,即8kb的数据空间。
可以从下图中看出ArrayContainer和BitMapContainer的内存空间使用关系,当数据量小于4096时,使用ArrayContainer比较合适,当数据量大于等于4096时,使用BitMapContainer更佳。

因为BitMap直接使用位运算,所以BitMapContainer的时间复杂度为O(1)。
3.RunContainer
RunContainer采用Run-Length Encoding 行程长度编码进行压缩,适合存储大量连续数据。Java中使用short数组进行存储。连续bit位程度越高的话越节省存储空间,最佳场景下(65536个数据全为1)只需要存储4字节。最差场景为所有数据都不连续,所有存储数据位置为奇数或者偶数,这种场景需要存储128kb。由于采用二分查找算法定位元素,因此时间复杂度为O(logN)。
行程长度编码即的原理是对连续出现的数字进行压缩,只记录初始数字和后续连续数量。
例如:[1,2,3,4,5,8,9,10]使用编码后的数据为[1,4,8,2]。
Java 里可以使用runOptinize()方法来对比RunContainer和其他两个Container存储空间大小,如果使用RunContainer存储空间更佳则会进行转化。
根据上面三个Container类型我们可以得知如何进行选择:
-
Container默认使用ArrayContainer,当元素数量超过4096时,会由ArrayContainer转换BitMapContainer。
-
当元素数量小于等于4096时,BitMapContainer会逆向转换回ArrayContainer。
-
正常增删元素不会使Container直接变成RunContainer,而需要用户进行优化方法调用才会转换为最节省空间的Container。
3.3 Roaring BitMap 相关源码
介绍完Roaring BitMap的三种container类型以后,让我们了解一下,Roaring BitMap的相关源码。这里介绍一下Java中增加元素的源码实现。
public void add(final int x) {final short hb = Util.highbits(x);final int i = highLowContainer.getIndex(hb);if (i >= 0) {highLowContainer.setContainerAtIndex(i,highLowContainer.getContainerAtIndex(i).add(Util.lowbits(x)));} else {final ArrayContainer newac = new ArrayContainer();highLowContainer.insertNewKeyValueAt(-i - 1, hb, newac.add(Util.lowbits(x)));}}Roaring BitMap首先获取添加元素的高16位,然后再调用getIndex获取高16位对应的索引,如果索引大于0,表示已经创建该索引对应的container,故直接添加相应的元素低16位即可;否则的话,说明该索引对应的container还没有被创建,先创建对应的ArrayContainer,再进行元素添加。值得一提的是,在getIndex方法中,使用了二分查找来获取索引值,所以时间复杂度为O(logn)。
// 包含一个二分查找
protected int getIndex(short x) {// 在二分查找之前,我们先对常见情况优化。if ((size == 0) || (keys[size - 1] == x)) {return size - 1;}// 没有碰到常见情况,我们只能遍历这个列表。return this.binarySearch(0, size, x);
}对于元素添加,三种Container提供了不同的实现方式,下面将分别介绍。
1. ArrayContainer
if (cardinality == 0 || (cardinality > 0&& toIntUnsigned(x) > toIntUnsigned(content[cardinality - 1]))) {if (cardinality >= DEFAULT_MAX_SIZE) {return toBitMapContainer().add(x);}if (cardinality >= this.content.length) {increaseCapacity();}content[cardinality++] = x;} else {int loc = Util.unsignedBinarySearch(content, 0, cardinality, x);if (loc < 0) {// 当标签中元素数量等于默认最大值时,把ArrayContainer转换为BitMapContainerif (cardinality >= DEFAULT_MAX_SIZE) {return toBitMapContainer().add(x);}if (cardinality >= this.content.length) {increaseCapacity();}System.arraycopy(content, -loc - 1, content, -loc, cardinality + loc + 1);content[-loc - 1] = x;++cardinality;}}return this;
}ArrayContainer把添加元素分成两种场景,一种走二分查找,另外一种不走二分查找。
第一种场景:不走二分查找。
当基数为0或者值大于container中的最大值,可以直接添加,因为content数组是有序的,最后一个是最大值。
当基数大于等于默认最大值4096时,ArrayContainer将转换为BitMapContainer。如果基数大于content的数组长度的话,需要将content进行扩容。最后进行赋值即可。
第二种场景:走二分查找。
先通过二分查找找到对应的插入位置,如果返回loc大于等于0,说明存在,直接返回即可,如果小于0才进行后续插入。后续操作同上,当基数大于等于默认最大值4096时,ArrayContainer将转换为BitMapContainer。如果基数大于content的数组长度的话,需要将content进行扩容。最后通过拷贝数组将元素插入到content数组中。
2. BitMapContainer
public Container add(final short i) {final int x = Util.toIntUnsigned(i);final long previous = BitMap[x / 64];long newval = previous | (1L << x); BitMap[x / 64] = newval;if (USE_BRANCHLESS) {cardinality += (previous ^ newval) >>> x;} else if (previous != newval) {++cardinality;}return this;
}BitMap数组为BitMapContainer的存储容器存放数据的内容,数据类型为long,在这里我们只需要找到x在BitMap中的位置,并且把相应的bit位置1即可。x/64就是找到对应long的旧值,1L<<x 就是把对应的bit位置为1,再跟旧值进行或操作,就可以得到新值,再将这个新值存回到bitmap数组即可。<="" span="">
3. RunContainer
public Container add(short k) {int index = unsignedInterleavedBinarySearch(valueslength, 0, nbrruns, k);if (index >= 0) {return this;// already there}index = -index - 2;if (index >= 0) {int offset = toIntUnsigned(k) - toIntUnsigned(getValue(index));int le = toIntUnsigned(getLength(index));if (offset <= le) {return this;}if (offset == le + 1) {// we may need to fuseif (index + 1 < nbrruns) {if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {// indeed fusion is neededsetLength(index,(short) (getValue(index + 1) + getLength(index + 1) - getValue(index)));recoverRoomAtIndex(index + 1);return this;}}incrementLength(index);return this;}if (index + 1 < nbrruns) {// we may need to fuseif (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {// indeed fusion is neededsetValue(index + 1, k);setLength(index + 1, (short) (getLength(index + 1) + 1));return this;}}}if (index == -1) {// we may need to extend the first runif (0 < nbrruns) {if (getValue(0) == k + 1) {incrementLength(0);decrementValue(0);return this;}}}makeRoomAtIndex(index + 1);setValue(index + 1, k);setLength(index + 1, (short) 0);return this;
}RunContainer中的两个数据结构,nbrruns表示有多少段行程,数据类型为int,valueslength数组表示所有的行程,数据类型为short。
-
首先,使用二分查找+顺序查找在valueslength数组中查找元素k的插入位置index。如果查找到的index结果大于等于0那就说明k是某个行程起始值,已经存在,直接返回。
-
-index-2是为了指向前一个行程起始值的索引。
-
接下来是一些偏移量和索引值的判断,主要是为了确认k是否落在上一个行程里,或者外面,如果落在上一个行程里,则直接返回,否则需要新建一个行程或者就近与一个行程混合并且将行程长度加1。
3.4 BitMap 和 Roaring BitMap 存储情况对比
public static void count(Integer inputSize) { RoaringBitMap BitMap = new RoaringBitMap(); BitMap.add(0L, inputSize);//获取BitMap个数int cardinality = BitMap.getCardinality();//获取BitMap压缩大小int compressSizeIntBytes = BitMap.getSizeInBytes();//删除压缩(移除行程编码,将container退化为BitMapContainer 或 ArrayContainer) BitMap.removeRunCompression();//获取BitMap不压缩大小int uncompressSizeIntBytes = BitMap.getSizeInBytes();System.out.println("Roaring BitMap个数:" + cardinality);System.out.println("最好情况,BitMap压缩大小:" + compressSizeIntBytes / 1024 + "KB");System.out.println("最坏情况,BitMap不压缩大小:" + uncompressSizeIntBytes / 1024 / 1024 + "MB");BitSet bitSet = new BitSet();for (int i = 0; i < inputSize; i++) {bitSet.set(i);}//获取BitMap大小int size = bitSet.size();System.out.println("BitMap个数:" + bitSet.length());System.out.println("BitMap大小:" + size / 8 / 1024 / 1024 + "MB");}上述代码使用了Java内置的BitMap(BitSet) 和 Roaring BitMap进行存储大小对比,输出结果如下所示。
-
Roaring BitMap个数:1000000000
-
最好情况,BitMap压缩大小:149KB
-
最坏情况,BitMap不压缩大小:119MB
-
Roaring BitMap个数:1000000000
-
BitMap大小:128MB
可以发现,Roaring BitMap的压缩性能效果非常好,同等情况下,是BitMap占用内存的近一千分之一。在退化成BitMapContainer/arrayContainer之后也仍然比使用基本的BitMap存储效果好一些。
四、Roaring BitMap 使用
4.1 Java 中相关 API 使用
在Java中,Roaring BitMap提供了交并补差集等操作,如下代码所示,列举了Java中roaing BitMap的相关API使用方式。
//添加单个数字
public void add(final int x)//添加范围数字
public void add(final long rangeStart, final long rangeEnd)//移除数字
public void remove(final int x)//遍历RBM
public void forEach(IntConsumer ic)//检测是否包含
public boolean contains(final int x)//获取基数
public int getCardinality()//位与,取两个RBM的交集,当前RBM会被修改
public void and(final RoaringBitMap x2)//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitMap and(final RoaringBitMap x1, final RoaringBitMap x2)//位或,取两个RBM的并集,当前RBM会被修改
public void or(final RoaringBitMap x2)//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitMap or(final RoaringBitMap x1, final RoaringBitMap x2)//异或,取两个RBM的对称差,当前RBM会被修改
public void xor(final RoaringBitMap x2)//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitMap xor(final RoaringBitMap x1, final RoaringBitMap x2)//取原始值和x2的差集,当前RBM会被修改
public void andNot(final RoaringBitMap x2)//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitMap andNot(final RoaringBitMap x1, final RoaringBitMap x2)//序列化
public void serialize(DataOutput out) throws IOException
public void serialize(ByteBuffer buffer)//反序列化
public void deserialize(DataInput in) throws IOException
public void deserialize(ByteBuffer bbf) throws IOException对于序列化来说,Roaring BitMap官方定义了一套序列化规则,用来保证不同语言实现的兼容性。

Java中可以使用serialize方法进行序列化,deserialize方法进行反序列化。
4.2 业务实际场景应用
Roaring BitMap可以用来构建大数据标签,针对类型特征来创建对应的标签。
在我们的业务场景中,有很多需要基于人群标签进行交并补集运算的场景,下面以一个场景为例,我们需要计算每天某个设备接口 在设备标签A上的查询成功率,因为设备标签A中的设备不是所有都活跃在网的,所以我们需要将设备标签A与每日日活人群标签取交集,得到的交集大小才能用作成功率计算的分母,另外拿查询成功的标签人群做分子来进行计算即可,查询时长耗时为1s。
假如没有使用标签保存集合之前,我们需要在hive表中查询出同时满足当天在网的活跃用户和设备A的用户数量,查询时长耗时在几分钟以上。两种方式相比之下,使用Roaring BitMap查询的效率更高。

五、总结
本文结合个人理解梳理了BitMap及Roaring BitMap的原理及使用,分别主要介绍了Roaring BitMap的存储方式及三种container类型及Java中Roaring BitMap相关API使用,如有不足和优化建议,也欢迎大家批评指正。
参考资料:
-
Chambi S , Lemire D , Kaser O , et al.
Better BitMap performance with Roaring
BitMaps[J]. Software—practice & Experience, 2016, 46(5):709-719.
-
https://RoaringBitMap.org/
-
GitHub - RoaringBitmap/RoaringFormatSpec: Specification of the compressed-bitmap Roaring format
相关文章:
海量数据处理利器 Roaring BitMap 原理介绍
作者:来自 vivo 互联网服务器团队- Zheng Rui 本文结合个人理解梳理了BitMap及Roaring BitMap的原理及使用,分别主要介绍了Roaring BitMap的存储方式及三种container类型及Java中Roaring BitMap相关API使用。 一、引言 在进行大数据开发时,…...

Javaweb登录校验
登录校验 JWT令牌的相关操作需要添加相关依赖 <dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version> </dependency>一、摘要 场景:当我们想要访问一个网站时&am…...

vxe-table 列表过滤踩坑_vxe-table筛选
但是这个过滤输入值必须是跟列表的值必须一致才能查到,没做到模糊查询的功能,根据关键字来过滤并没有实现。 下面提供一下具体实现方法:(关键字来过滤) filterNameMethod({ option, row }) {if (row.name.indexOf(op…...
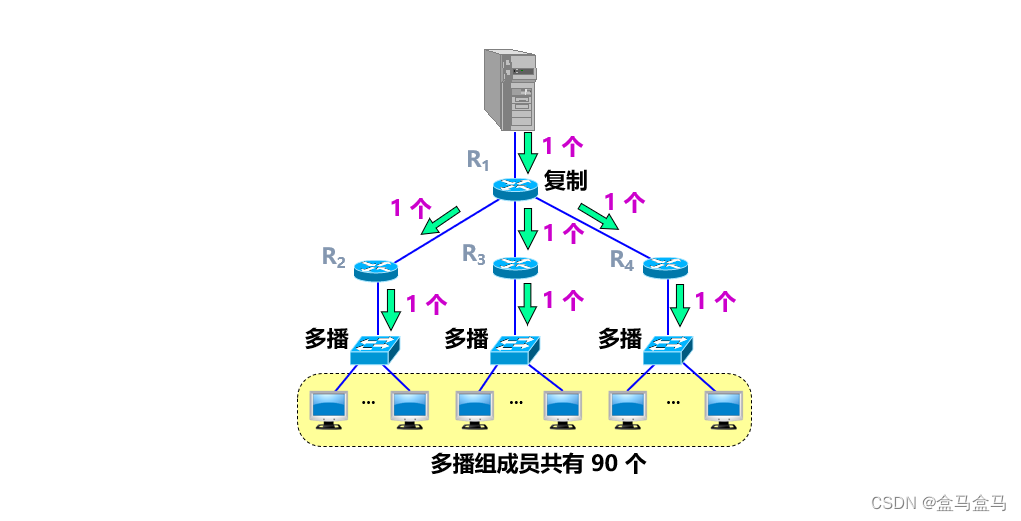
计算机网络:网络层 - IP数据报的转发
计算机网络:网络层 - IP数据报的转发 基于终点转发最长前缀匹配二叉线索树路由表特殊路由特定主机路由默认路由 IP多播 基于终点转发 路由器转发报文时,是通过报文中的目的地址字段来转发的,也即是说路由器只知道终点的IP地址,根…...

颠覆与创新:探寻Facebook未来的发展路径
Facebook,这个曾经引领社交网络革命的巨头,在如今竞争激烈的科技市场中,正面临着前所未有的挑战和机遇。如何在不断变化的数字世界中保持竞争力,成为业界领先者,这是摆在Facebook面前的重要课题。本文将探寻Facebook未…...

太湖远大毛利率下滑:研发费用率远低同行,募投项目合理性疑点重重
《港湾商业观察》黄懿 6月20日,浙江太湖远大新材料股份有限公司(以下简称“太湖远大”,873743.NQ)即将迎来过会。 2023年11月30日,太湖远大所提交的上市申请材料正式获北交所受理,保荐机构为招商证券&…...
)
赶紧收藏!2024 年最常见 20道设计模式面试题(八)
上一篇地址:赶紧收藏!2024 年最常见 20道设计模式面试题(七)-CSDN博客 十五、模板方法模式是如何在父类中定义算法框架的? 模板方法模式通过在父类(通常是一个抽象类)中定义算法的骨架&#x…...

JAVA学习-练习试用Java实现“比较版本号”
问题: 给定两个版本号 version1 和 version2 ,请比较它们。 版本号由一个或多个修订号组成,各修订号由一个 . 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,…...

云原生分级SLA
云原生分级SLA(Service Level Agreement,服务等级协议)规则是为了确保云服务提供商和客户之间对服务性能、可用性和其他关键指标有明确的理解和期望。这些规则通常基于业务需求和技术实现来制定,并根据服务的不同级别进行分级。以…...

java干货 线程间通信
文章目录 一、线程间通信1.1 为什么要处理线程间通信?1.2 什么是等待唤醒机制? 二、等待唤醒机制使用2.1 等待唤醒机制用到的方法2.1.1 wait2.1.2 notify 2.2 线程通信代码实践2.2.1 重要说明2.2.2 代码 一、线程间通信 1.1 为什么要处理线程间通信&…...

【人机交互 复习】第6章 交互式系统的设计
一、设计框架 1.在建立了一组需求之后,设计即将开始,建议采取自上面下的方式,首先把重点放在大的方面,生成低保真且不包含具体细节的方案,一般通过写剧本来确定交互设计模式与逻辑。 2.设计框架: 先站在一个…...

1-函数极限与连续
1 2 平方项没有考虑到(其正负)...
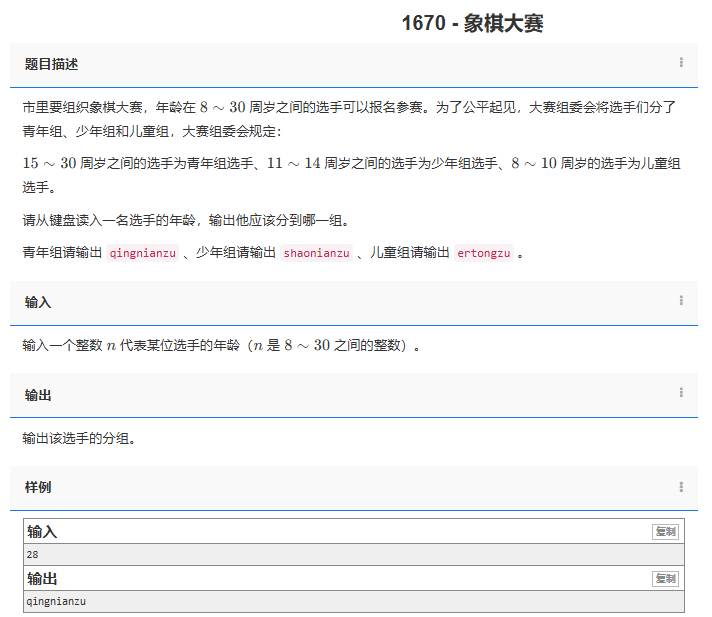
【C++题解】1670 - 象棋大赛
问题:1670 - 象棋大赛 类型:分支问题 题目描述: 市里要组织象棋大赛,年龄在 8∼30 周岁之间的选手可以报名参赛。为了公平起见,大赛组委会将选手们分了青年组、少年组和儿童组,大赛组委会规定:…...

Samba:用于高效无限上下文语言建模的简单混合状态空间模型
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling 📜 文献卡 Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling作者: Liliang Ren; Yang Liu; Yadong Lu; Yelong Shen; …...

通俗易懂的ChatGPT原理简介
一、引言 随着人工智能的发展,聊天机器人已经成为我们生活中的常见工具。而在众多聊天机器人中,ChatGPT 无疑是最受关注的一个。ChatGPT 是由 OpenAI 开发的一种基于生成式预训练模型(GPT)的大型语言模型。本文将通俗易懂地介绍 …...
你认为 AI 作图程序「MidJourney」有哪些比较好用的关键词?
玩了一段时间的MidJourney,打算把这个回答做成资源帖。也欢迎在评论区补充讨论。 MidJourney的极简指南 快速上手 装discord,或者直接打开网址 https://discord.gg/midjourney 注册用户。进入Midjourney的官方服务器后,在左侧栏找一个newb…...
excute()方法)
9.2JavaEE——JDBCTemplate的常用方法(一)excute()方法
execute()方法用于执行SQL语句,其语法格式如下: jdTemplate.execute("SQL 语句");下面以创建数据表的SQL语句为例,来演示excute()方法的使用,具体步骤如下。 1、创建数据库 在MySQL中,创建一个名为spring的…...

正向代理和反向代理的区别
正向代理和反向代理的主要区别在于代理服务器所服务的对象不同。 正向代理(Forward Proxy):正向代理的客户端是内部网络的用户。当内部网络的用户想要访问外部网络(例如互联网)时,可以通过正向代理服务器来…...
express入门03增删改查
目录 1 搭建服务器2 静态文件托管3 引入bootstrap4 引入jquery5 编写后端接口5.1 添加列表查询方法5.2 添加路由5.3 添加数据表格 总结 我们前两篇介绍了如何利用express搭建服务器,如何实现静态资源托管。那利用这两篇的知识点,我们就可以实现一个小功能…...
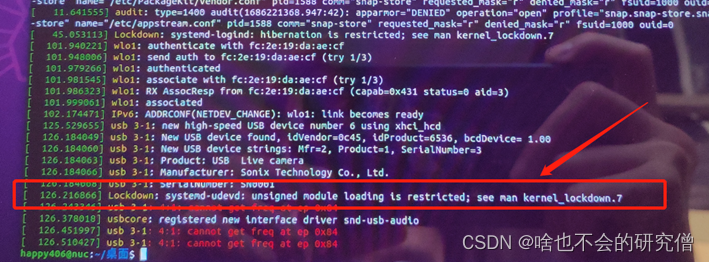
【usb设备端口异常】——使用ls /dev/video*查看设备号时出现报错:ls:无法访问‘/dev/video*‘: 没有那个文件或目录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、ls:无法访问/dev/video*: 没有那个文件或目录1. 问题描述2. 原因分析3. 解决方法 总结 前言 一、ls:无法访问’/dev/video*: 没有那个文件或目录 使用的这…...

深入FFmpeg解码器:从avcodec_send_packet看硬解与软解的实现差异
深入FFmpeg解码器:从avcodec_send_packet看硬解与软解的实现差异 在多媒体处理领域,FFmpeg无疑是开发者最常接触的开源框架之一。其强大的编解码能力支撑着从视频播放器到直播系统的各类应用,而解码器作为其中的核心组件,其性能直…...

SVG-Edit:开源矢量编辑在浏览器工具中的创新实践
SVG-Edit:开源矢量编辑在浏览器工具中的创新实践 【免费下载链接】svgedit Powerful SVG-Editor for your browser 项目地址: https://gitcode.com/gh_mirrors/sv/svgedit SVG-Edit是一款基于浏览器环境的开源矢量图形编辑工具,提供在线SVG编辑能…...

二次开发入门:修改nanobot镜像适配我的OpenClaw需求
二次开发入门:修改nanobot镜像适配我的OpenClaw需求 1. 为什么需要定制nanobot镜像 第一次接触OpenClaw时,我直接使用了官方提供的标准镜像。但在实际使用中,发现几个痛点:默认的chainlit界面过于简单,无法展示我需要…...

OpenClaw性能优化:降低GLM-4.7-Flash任务Token消耗的5个技巧
OpenClaw性能优化:降低GLM-4.7-Flash任务Token消耗的5个技巧 1. 为什么需要关注Token消耗 当我第一次在本地部署OpenClaw并接入GLM-4.7-Flash模型时,最让我震惊的不是它的自动化能力,而是执行简单任务后查看账单时的Token消耗数字。一个看似…...
)
ROS2 Humble下,如何用一份Xacro文件同时搞定MoveIt2配置与Gazebo仿真(附完整Launch文件)
ROS2 Humble统一建模实战:Xacro文件在MoveIt2与Gazebo中的协同设计 当机械臂的URDF文件需要同时满足MoveIt2的运动规划需求和Gazebo的物理仿真要求时,开发者往往陷入两难境地。传统方案需要维护两份模型文件——一份精简版用于MoveIt,另一份增…...

AI性能测试:TPS之外还要关注什么?
在AI驱动的时代,性能测试已成为软件测试从业者的核心技能。传统软件测试中,TPS(Transactions Per Second,每秒事务处理量)常被视为黄金指标,用于衡量系统的吞吐能力。然而,AI系统因其独特的计算…...

字节开源AI神器DeerFlow,4.1万星标刷屏,普通人免费就能用
文章目录这玩意儿不是ChatGPT那种"嘴炮型"选手35k星标怎么来的?字节这次把"龙虾"养明白了多智能体协作:不是一个人在战斗沙箱执行:让AI真的"动手"干活对比OpenAI:免费、本地、可控普通人怎么上手&a…...
)
好用还专业!高效论文写作全流程AI论文网站推荐(2026 最新)
论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,以下工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖免费/付费、通用/垂直场景。2026年AI论…...
)
手把手教你用NOAA气象数据做可视化分析(含常见字段解析与避坑指南)
手把手教你用NOAA气象数据做可视化分析(含常见字段解析与避坑指南) 气象数据可视化是理解气候模式、分析极端天气事件的重要工具。美国国家海洋和大气管理局(NOAA)提供的全球历史气候网络日数据(GHCN-Daily࿰…...

类型注解写错=线上Bug潜伏!:3个导致Pydantic崩溃、FastAPI 500、mypy静默失效的致命细节
第一章:类型注解写错线上Bug潜伏!:3个导致Pydantic崩溃、FastAPI 500、mypy静默失效的致命细节泛型未参数化:List 而非 List[str] 的隐式陷阱 Pydantic v2 强制要求泛型类型必须显式参数化。若仅写 List(而非 List[str…...