Redis分片集群搭建
主从模式可以解决高可用、高并发读的问题。但依然有两个问题没有解决:
- 海量数据存储
- 高并发写
要解决这两个问题就需要用到分片集群了。分片的意思,就是把数据拆分存储到不同节点,这样整个集群的存储数据量就更大了。
Redis分片集群的结构如图
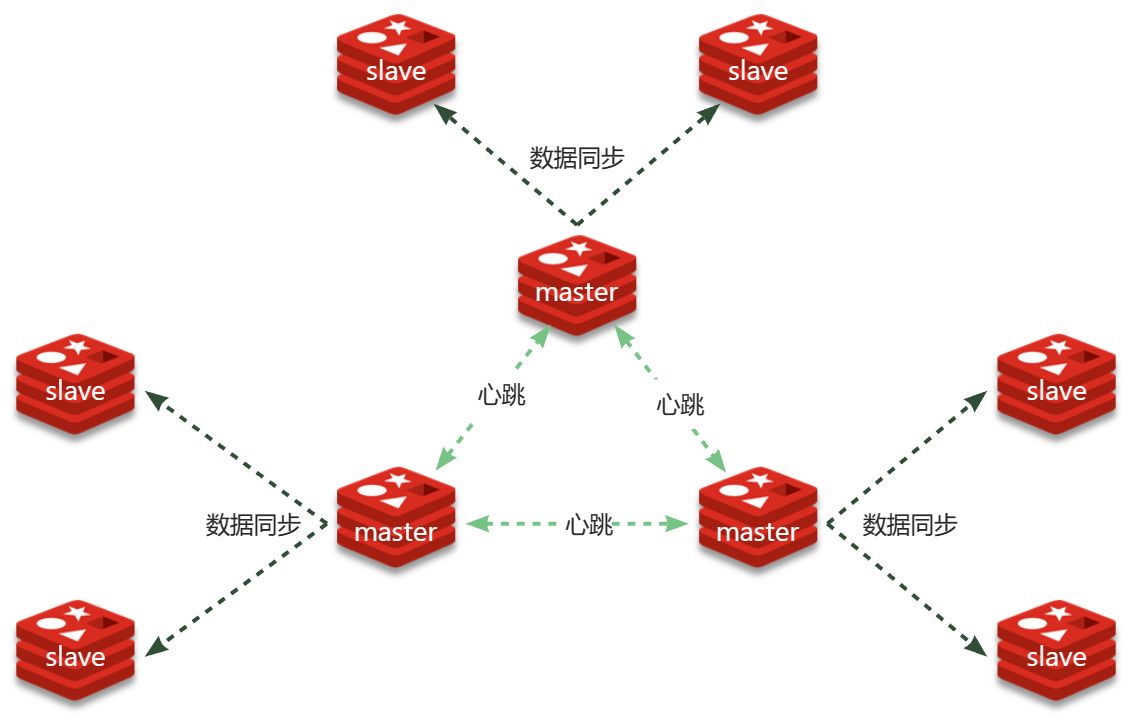
分片集群特征:
- 集群中有多个master,每个master保存不同分片数据 ,解决海量数据存储问题
- 每个master都可以有多个slave节点 ,确保高可用
- master之间通过ping监测彼此健康状态 ,类似哨兵作用
- 客户端请求可以访问集群任意节点,最终都会被转发到数据所在节点
- 搭建分片集群
- Redis分片集群最少也需要3个master节点,由于我们的机器性能有限,我们只给每个master配置1个slave,形成最小的分片集群:
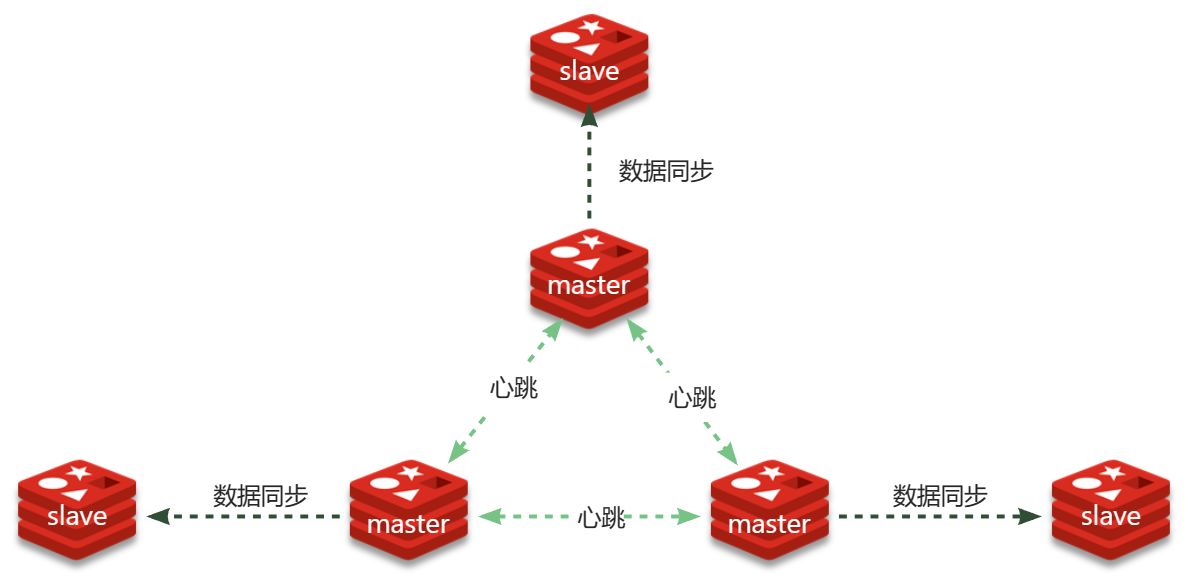
计划部署的节点信息如下:
| 容器名 | 角色 | IP | 映射端口 |
|---|---|---|---|
| r1 | master | 192.168.150.101 | 7001 |
| r2 | master | 192.168.150.101 | 7002 |
| r3 | master | 192.168.150.101 | 7003 |
| r4 | slave | 192.168.150.101 | 7004 |
| r5 | slave | 192.168.150.101 | 7005 |
| r6 | slave | 192.168.150.101 | 7006 |
集群配置
分片集群中的Redis节点必须开启集群模式,一般在配置文件中添加下面参数:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
其中有3个我们没见过的参数:
- cluster-enabled:是否开启集群模式
- cluster-config-file:集群模式的配置文件名称,无需手动创建,由集群自动维护
- cluster-node-timeout:集群中节点之间心跳超时时间
一般搭建部署集群肯定是给每个节点都配置上述参数,不过考虑到我们计划用docker-compose部署,因此可以直接在启动命令中指定参数,偷个懒。
在虚拟机的/root目录下新建一个redis-cluster目录,然后在其中新建一个docker-compose.yaml文件,内容如下:
version: "3.2"services:r1:image: rediscontainer_name: r1network_mode: "host"entrypoint: ["redis-server", "--port", "7001", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r2:image: rediscontainer_name: r2network_mode: "host"entrypoint: ["redis-server", "--port", "7002", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r3:image: rediscontainer_name: r3network_mode: "host"entrypoint: ["redis-server", "--port", "7003", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r4:image: rediscontainer_name: r4network_mode: "host"entrypoint: ["redis-server", "--port", "7004", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r5:image: rediscontainer_name: r5network_mode: "host"entrypoint: ["redis-server", "--port", "7005", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r6:image: rediscontainer_name: r6network_mode: "host"entrypoint: ["redis-server", "--port", "7006", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]注意:使用Docker部署Redis集群,network模式必须采用host3.1.2.启动集群
进入/root/redis-cluster目录,使用命令启动redis:docker-compose up -d启动成功,可以通过命令查看启动进程:ps -ef | grep redis
# 结果:
root 4822 4743 0 14:29 ? 00:00:02 redis-server *:7002 [cluster]
root 4827 4745 0 14:29 ? 00:00:01 redis-server *:7005 [cluster]
root 4897 4778 0 14:29 ? 00:00:01 redis-server *:7004 [cluster]
root 4903 4759 0 14:29 ? 00:00:01 redis-server *:7006 [cluster]
root 4905 4775 0 14:29 ? 00:00:02 redis-server *:7001 [cluster]
root 4912 4732 0 14:29 ? 00:00:01 redis-server *:7003 [cluster]注意:使用Docker部署Redis集群,network模式必须采用host
启动集群
进入/root/redis-cluster目录,使用命令启动redis:
docker-compose up -d
启动成功,可以通过命令查看启动进程:
ps -ef | grep redis
# 结果:
root 4822 4743 0 14:29 ? 00:00:02 redis-server *:7002 [cluster]
root 4827 4745 0 14:29 ? 00:00:01 redis-server *:7005 [cluster]
root 4897 4778 0 14:29 ? 00:00:01 redis-server *:7004 [cluster]
root 4903 4759 0 14:29 ? 00:00:01 redis-server *:7006 [cluster]
root 4905 4775 0 14:29 ? 00:00:02 redis-server *:7001 [cluster]
root 4912 4732 0 14:29 ? 00:00:01 redis-server *:7003 [cluster]
可以发现每个redis节点都以cluster模式运行。不过节点与节点之间并未建立连接。
接下来,我们使用命令创建集群:
# 进入任意节点容器
docker exec -it r1 bash
# 然后,执行命令
redis-cli --cluster create --cluster-replicas 1 \
192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 \
192.168.150.101:7004 192.168.150.101:7005 192.168.150.101:7006
命令说明:
- redis-cli --cluster:代表集群操作命令
- create:代表是创建集群
- –cluster-replicas 1 :指定集群中每个master的副本个数为1
- 此时节点总数 ÷ (replicas + 1) 得到的就是master的数量n。因此节点列表中的前n个节点就是master,其它节点都是slave节点,随机分配到不同master
输入命令后控制台会弹出下面的信息:
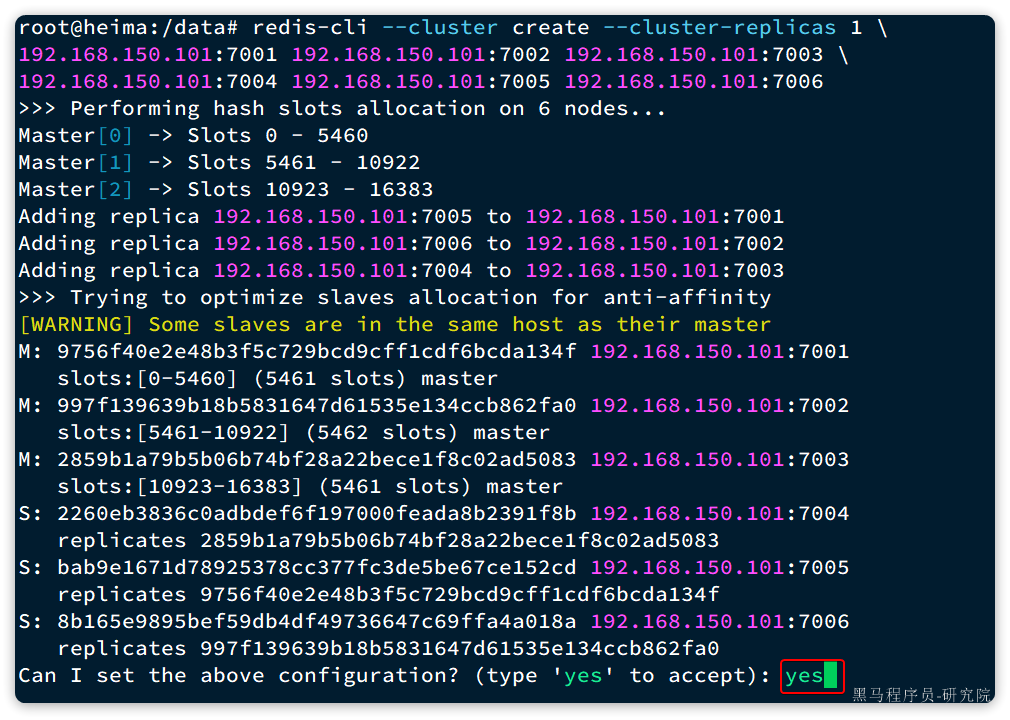
这里展示了集群中master与slave节点分配情况,并询问你是否同意。节点信息如下:
- 7001是master,节点id后6位是da134f
- 7002是master,节点id后6位是862fa0
- 7003是master,节点id后6位是ad5083
- 7004是slave,节点id后6位是391f8b,认ad5083(7003)为master
- 7005是slave,节点id后6位是e152cd,认da134f(7001)为master
- 7006是slave,节点id后6位是4a018a,认862fa0(7002)为master
输入yes然后回车。会发现集群开始创建,并输出下列信息:
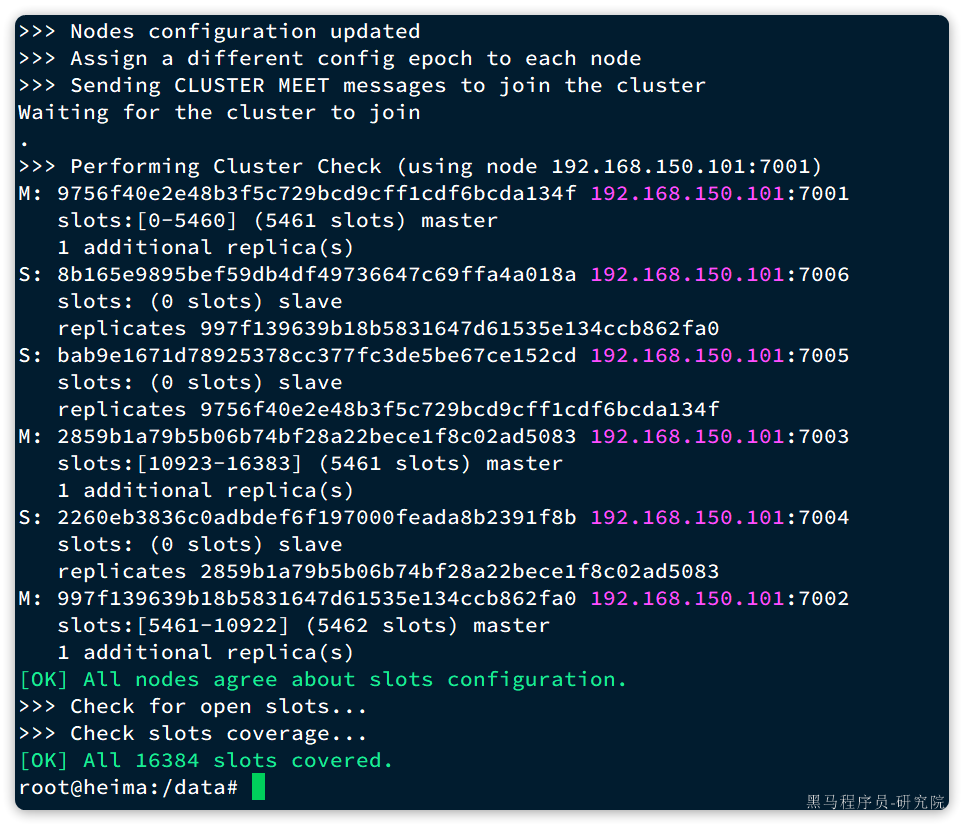
接着,我们可以通过命令查看集群状态:
redis-cli -p 7001 cluster nodes
结果:

- 散列插槽
- 数据要分片存储到不同的Redis节点,肯定需要有分片的依据,这样下次查询的时候才能知道去哪个节点查询。很多数据分片都会采用一致性hash算法。而Redis则是利用散列插槽(hash slot)的方式实现数据分片
- 在Redis集群中,共有16384个hash slots,集群中的每一个master节点都会分配一定数量的hash slots。具体的分配在集群创建时就已经指定了:
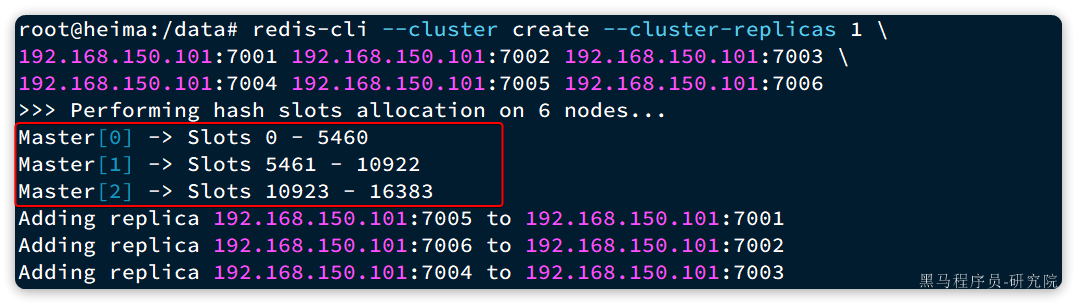
如图中所示:
- Master[0],本例中就是7001节点,分配到的插槽是0~5460
- Master[1],本例中就是7002节点,分配到的插槽是5461~10922
- Master[2],本例中就是7003节点,分配到的插槽是10923~16383
- 当我们读写数据时,Redis基于CRC16 算法对key做hash运算,得到的结果与16384取余,就计算出了这个key的slot值。然后到slot所在的Redis节点执行读写操作。
不过hash slot的计算也分两种情况:
- 当key中包含{}时,根据{}之间的字符串计算hash slot
- 当key中不包含{}时,则根据整个key字符串计算hash slot
- 例如:
- key是user,则根据user来计算hash slot
- key是user:{age},则根据age来计算hash slot
我们来测试一下,先于7001建立连接:
# 进入容器
docker exec -it r1 bash
# 进入redis-cli
redis-cli -p 7001
# 测试
set user jack
会发现报错了:
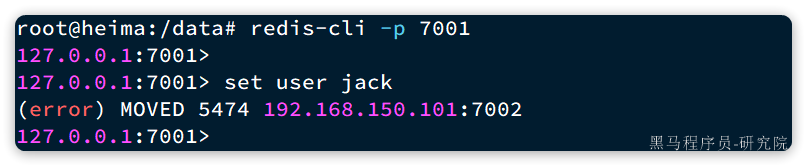
提示我们MOVED 5474,其实就是经过计算,得出user这个key的hash slot 是5474,而5474是在7002节点,不能在7001上写入!!
说好的任意节点都可以读写呢?
这是因为我们连接的方式有问题,连接集群时,要加-c参数:
# 通过7001连接集群
redis-cli -c -p 7001
# 存入数据
set user jack
结果如下:可以看到,客户端自动跳转到了5474这个slot所在的7002节点。
现在,我们添加一个新的key,这次加上{}:
# 试一下key中带{}
set user:{age} 21# 再试一下key中不带{}
set age 20
结果如下:
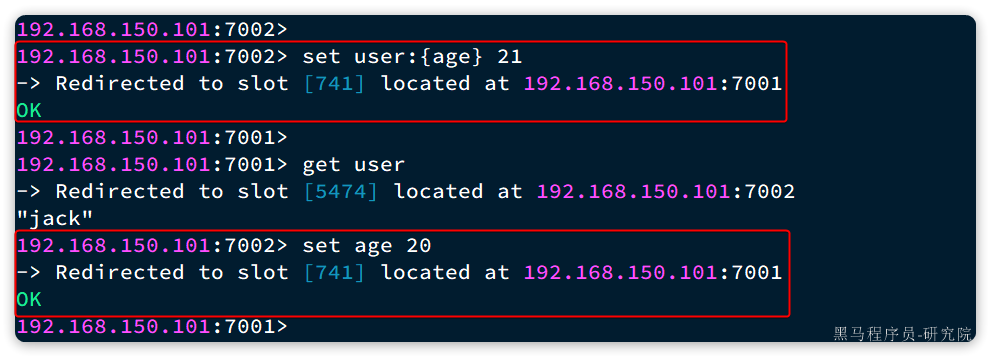
可以看到user:{age}和age计算出的slot都是741。
3.3.故障转移
分片集群的节点之间会互相通过ping的方式做心跳检测,超时未回应的节点会被标记为下线状态。当发现master下线时,会将这个master的某个slave提升为master。
我们先打开一个控制台窗口,利用命令监测集群状态:
watch docker exec -it r1 redis-cli -p 7001 cluster nodes
命令前面的watch可以每隔一段时间刷新执行结果,方便我们实时监控集群状态变化。
接着,我们故技重施,利用命令让某个master节点休眠。比如这里我们让7002节点休眠,打开一个新的ssh控制台,输入下面命令:
docker exec -it r2 redis-cli -p 7002 DEBUG sleep 30
可以观察到,集群发现7002宕机,标记为下线:
过了一段时间后,7002原本的小弟7006变成了master:

而7002被标记为slave,而且其master正好是7006,主从地位互换。
3.4.总结
Redis分片集群如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
- 如何将同一类数据固定的保存在同一个Redis实例?
- Redis计算key的插槽值时会判断key中是否包含{},如果有则基于{}内的字符计算插槽
- 数据的key中可以加入{类型},例如key都以{typeId}为前缀,这样同类型数据计算的插槽一定相同
3.5.Java客户端连接分片集群(选学)
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致,参考2.5节:
1)引入redis的starter依赖
2)配置分片集群地址
3)配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes:- 192.168.150.101:7001- 192.168.150.101:7002- 192.168.150.101:7003- 192.168.150.101:8001- 192.168.150.101:8002- 192.168.150.101:8003
相关文章:
Redis分片集群搭建
主从模式可以解决高可用、高并发读的问题。但依然有两个问题没有解决: 海量数据存储高并发写 要解决这两个问题就需要用到分片集群了。分片的意思,就是把数据拆分存储到不同节点,这样整个集群的存储数据量就更大了。 Redis分片集群的结构如…...

请解释Java中的策略模式,并举例说明其应用场景和实现方式。请解释Java中的模板方法模式,并讨论其在实际项目中的应用。
请解释Java中的策略模式,并举例说明其应用场景和实现方式。 策略模式(Strategy Pattern) 策略模式是一种行为设计模式,它使你能够定义一系列算法,并将每一个算法封装起来,使它们可以互相替换。策略模式使…...
Vim基础操作:常用命令、安装插件、在VS Code中使用Vim及解决Vim编辑键盘错乱
Vim模式 普通模式(Normal Mode): 这是 Vim 的默认模式,用于执行文本编辑命令,如复制、粘贴、删除等。在此模式下,你可以使用各种 Vim 命令来操作文本。插入模式(Insert Mode)&#…...

基于Windows API DialogBox的对话框
在C中,DialogBox函数是Windows API的一部分,它用于在Win32应用程序中创建并显示一个模态对话框。DialogBox函数是USER32.DLL中的一个导出函数,因此你需要在你的C Win32应用程序中链接到这个库。 #include "framework.h" #include …...

五十一、openlayers官网示例Layer Min/Max Resolution解析——设置图层最大分辨率,超过最大值换另一个图层显示
使用minResolution、maxResolution分辨率来设置图层显示最大分辨率。 <template><div class"box"><h1>Layer Min/Max Resolution</h1><div id"map" class"map"></div></div> </template><…...

24年计算机等级考试22个常见问题解答❗
24年9月计算机等级考试即将开始,整理了报名中容易遇到的22个问题,大家对照入座,避免遇到了不知道怎么办? 1、报名条件 2、报名入口 3、考生报名之后后悔了,不想考了,能否退费? 4、最多能够报多少…...

obsidian制作自己的主题一文入门
制作自己的主题 我最近发现一款插件,直接把obsidian的文章格式复制到公众号中。 我非常喜欢这个功能,这将减少公众号排版的时间,同时保持公众号文章格式的一致性。 但是这个插件提供的模板不能满足我的需求,所以,需要…...

游戏心理学Day20
扩展的8种玩家 完成主义者 此类玩家关心的是成就和进展,其主要目的是完成游戏的主要目标,其次是完成游戏的次要目标之后才是游戏中的其他内容,在多人游戏中完成主义者会致力于炫耀自己的状态和财富。如果游戏以胜负为目标,那么此…...

Serverless如何赋能餐饮行业数字化?乐凯撒思变之道
导语 | 在数字化浪潮席卷全球的今天,每一个行业都在经历着前所未有的变革。餐饮行业作为人们日常生活中不可或缺的一部分,更是面临着巨大的转型压力。如何完成数字化转型,打破传统经营模式的限制,成为摆在众多餐饮商家面前的一道难…...

css系列:音频播放效果-波纹律动
介绍 语音播放的律动效果,通俗来说就是一个带动画的特殊样式的进度条,播放的部分带有上下律动的动画,未播放的部分是普通的灰色竖状条。 实现中夹带了less变量、继承和循环遍历,可以顺带学习一下。 结果展示 大致效果如图所示…...

WPF学习(1)--类与类的继承
在面向对象编程中,继承是一种机制,允许一个类(称为子类或派生类)从另一个类(称为父类或基类)继承属性和方法。继承使我们能够创建一个通用类,然后根据需要扩展或修改它以创建更具体的类。以下是…...
)
Spring Boot框架的原理及应用详解(六)
本系列文章简介: 在当今的软件开发世界中,快速迭代、高效开发以及易于维护成为了开发者们不断追求的目标。Spring Boot作为Spring框架的一个子项目,自其诞生以来就凭借其“约定大于配置”的理念和自动配置的特性,迅速在Java开发社…...
)
密码学与信息安全面试题及参考答案(2万字长文)
目录 什么是密码学?它的主要目标是什么? 请解释明文、密文、加密和解密的概念。 密码系统的安全性通常基于哪三种假设? 什么是Kerckhoffs原则?它对现代密码学设计有何意义? 简述密码学中的“混淆”和“扩散”概念。 什么是AES(高级加密标准)?AES有几种常见的密钥…...
C++语法19 循环嵌套结构(for/while循环)
语法阶段已经更新到第18章了,前面的知识你都学会了吗?如果还没有学习前面的知识,请点击👉语法专栏进行学习哦! 目录 循环嵌套 训练:数字矩形 解析 参考代码 训练:星号三角形 解析 参考代码 …...

AtomicInteger原理和CAS与Synchronized(juc编程)
AtomicInteger原理 4.6.1 原理介绍 AtomicInteger的本质:自旋锁 CAS算法 CAS的全成是: Compare And Swap(比较再交换); 是现代CPU广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。CAS可以将read-modify-write转换为原子操作,这…...

抖音a_bogus,mstoken全参数爬虫逆向补环境2024-06-15最新版
抖音a_bogus,mstoken全参数爬虫逆向补环境2024-06-15最新版 接口及参数 打开网页版抖音,右键视频进入详情页。F12打开控制台筛选detail,然后刷新网页,找到请求。可以发现我们本次的参数目标a_bogus。a_bogus有时长度为168有时为172…...

【机器学习】机器学习重要方法—— 半监督学习:理论、算法与实践
文章目录 引言第一章 半监督学习的基本概念1.1 什么是半监督学习1.2 半监督学习的优势 第二章 半监督学习的核心算法2.1 自训练(Self-Training)2.2 协同训练(Co-Training)2.3 图半监督学习(Graph-Based Semi-Supervise…...

leetcode70 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. 2 阶 示例 2&#x…...
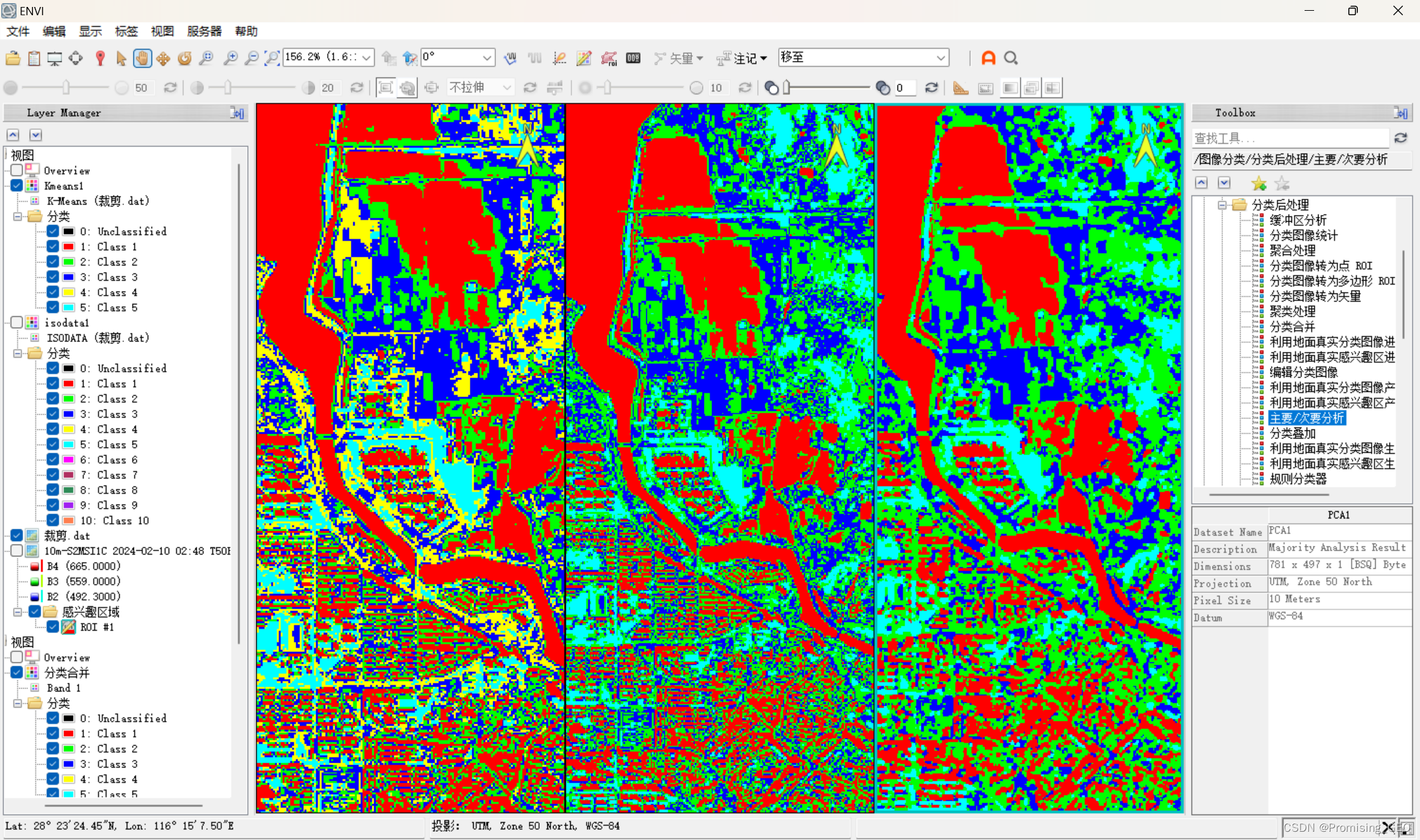
ENVI实战—一文搞定非监督分类
实验1:使用isodata法分类 目的:学会使用isodata法开展非监督分类 过程: ①导入影像:打开ENVI,按照“文件→打开为→光学传感器→ESA→Sentinel-2”的顺序,打开实验1下载的哨兵2号数据。 图1 ②区域裁剪…...

【Qt 学习笔记】Qt系统相关 | Qt事件 | 事件的介绍及基本概念
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt系统相关 | Qt事件 | 事件的介绍及基本概念 文章编号:Qt…...

手机数据导出
在数字信息爆炸的时代,手机早已不仅是通讯工具,更是承载个人记忆、工作文件与生活轨迹的“数字器官”。然而,当意外发生——误删、系统崩溃、硬件损坏——手机数据导出便成为一项技术性极高、且充满情感救赎价值的系统工程。本文将围绕手机数…...

EmbedClaw:RAG应用中文本智能分块与向量化检索的工程实践
1. 项目概述:一个面向嵌入向量检索的“机械爪”最近在折腾RAG(检索增强生成)应用,发现向量数据库的检索效果,很大程度上取决于你“喂”进去的文本是怎么被切成一块一块的(也就是分块,Chunking&a…...

Faust.js实战:用Next.js构建高性能Headless WordPress前端
1. 项目概述:当WordPress遇见现代前端如果你和我一样,在过去几年里深度参与过企业级WordPress项目,那你一定对那个经典的“两难困境”记忆犹新:一方面,WordPress的后台管理体验和内容生态无可匹敌,是内容团…...

自治性、反应性、学习能力:AI Agent的关键特性
自治性、反应性、学习能力:AI Agent的关键特性——从蚂蚁觅食到通用智能体的进化之路 关键词 AI Agent, 自治性, 反应性, 强化学习, 记忆机制, 环境交互, 通用人工智能萌芽 摘要 想象一下:你有一个能自己帮你规划周末露营路线(自治性)、中途遇到暴雨自动切换到附近民宿…...

别再死记硬背了!用Python和C语言手把手带你理解CRC32查表法的实现原理
从数学到代码:用Python和C语言彻底搞懂CRC32查表法的实现 在数据传输和存储过程中,错误检测是确保数据完整性的关键环节。CRC32作为一种广泛应用的校验算法,从网络协议到压缩工具,再到文件系统,几乎无处不在。但很多开…...

工程师幽默竞赛:从技术梗到团队文化的创意表达
1. 项目概述:一场工程师的幽默竞赛如果你在电子工程行业待过一段时间,大概率在《EE Times》这样的行业媒体上,见过那种线条简洁、寓意深刻的单格漫画。漫画本身往往描绘一个充满电子元件、示波器或一脸困惑的工程师的实验室场景,但…...

先进制程重塑晶圆代工格局:从HPC需求到供应链博弈
1. 行业现状:先进制程如何重塑晶圆代工格局最近和几位在芯片设计公司负责流片的朋友聊天,大家讨论最激烈的,除了产能紧张,就是到底要不要、以及何时上更先进的工艺节点。一个普遍的共识是:7纳米和5纳米这类所谓“先进制…...

Qdrant 如何配置 API Key 认证
Qdrant 如何配置 API Key 认证 Qdrant 是当下最流行的向量数据库之一,广泛应用于 RAG(检索增强生成)、相似度搜索、AI 应用等场景。生产环境中,API Key 认证是保障数据安全的基本手段。本文详细介绍 Qdrant 的 API Key 配置方法&a…...

感统训练的真实效果能持续多久?会不会反弹?
直接给出结论:常见的感统训练维持周期短、反弹率高,多数孩子训练效果仅能保持3-6个月。一旦停止课程,大部分孩子会逐步退回原有状态。感统只能调整身体感官反应,无法从根源提升大脑自控力,治标不治本。感统训练适用人…...
— 硬件I2C驱动AT24C02 EEPROM从零到一)
小熊派gd32f303实战指南(9)— 硬件I2C驱动AT24C02 EEPROM从零到一
1. 硬件I2C与AT24C02基础认知 第一次接触硬件I2C时,我也被那些专业术语搞得一头雾水。简单来说,I2C就像两个人用摩斯密码交流——只需要两根线(SDA数据线和SCL时钟线),就能让主设备(GD32F303)和…...