【机器学习】机器学习重要方法—— 半监督学习:理论、算法与实践
文章目录
- 引言
- 第一章 半监督学习的基本概念
- 1.1 什么是半监督学习
- 1.2 半监督学习的优势
- 第二章 半监督学习的核心算法
- 2.1 自训练(Self-Training)
- 2.2 协同训练(Co-Training)
- 2.3 图半监督学习(Graph-Based Semi-Supervised Learning)
- 第三章 半监督学习的应用实例
- 3.1 图像分类
- 3.2 文本分类
- 第四章 半监督学习的未来发展与挑战
- 4.1 标签质量与模型鲁棒性
- 4.2 多视角与多模态学习
- 4.3 标注策略与主动学习
- 结论
引言
半监督学习(Semi-Supervised Learning)是一类机器学习方法,通过结合少量有标签数据和大量无标签数据来进行学习。相比于纯监督学习,半监督学习在标签数据稀缺的情况下能更有效地利用无标签数据,提高模型的泛化能力和预测准确性。本文将深入探讨半监督学习的基本原理、核心算法及其在实际中的应用,并提供代码示例以帮助读者更好地理解和掌握这一技术。

第一章 半监督学习的基本概念
1.1 什么是半监督学习
半监督学习是一种介于监督学习和无监督学习之间的方法,通过同时利用有标签和无标签数据进行训练。在许多实际应用中,获取大量有标签数据的成本高昂,而无标签数据通常比较丰富。半监督学习方法能够在这样的环境中有效发挥作用。
1.2 半监督学习的优势
半监督学习相比于纯监督学习具有以下优势:
- 减少标注成本:通过利用大量无标签数据,可以显著减少对有标签数据的依赖,从而降低数据标注成本。
- 提高模型性能:在有标签数据稀缺的情况下,通过引入无标签数据,可以提高模型的泛化能力和预测准确性。
- 更好地利用数据:充分利用已有的无标签数据,避免数据浪费,提升模型的整体表现。
第二章 半监督学习的核心算法
2.1 自训练(Self-Training)
自训练是一种简单但有效的半监督学习方法,通过使用有标签数据训练初始模型,然后利用该模型对无标签数据进行预测,将预测结果置信度高的无标签数据作为新的有标签数据,加入训练集中,反复迭代直到模型收敛。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分有标签数据和无标签数据
X_train, X_unlabeled, y_train, _ = train_test_split(X, y, test_size=0.7, random_state=42)
X_unlabeled, X_test, _, y_test = train_test_split(X_unlabeled, _, test_size=0.5, random_state=42)# 初始模型训练
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)# 自训练过程
for i in range(10):y_pred_unlabeled = model.predict(X_unlabeled)X_train = np.vstack((X_train, X_unlabeled))y_train = np.concatenate((y_train, y_pred_unlabeled))model.fit(X_train, y_train)# 评估模型
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'自训练模型准确率: {accuracy}')
2.2 协同训练(Co-Training)
协同训练是一种基于多视图的半监督学习方法,通过训练两个或多个不同视角的分类器,分别对无标签数据进行预测,并将一个分类器高置信度的预测结果作为有标签数据供另一个分类器使用,迭代进行训练。
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier# 定义两个不同视角的分类器
model1 = LogisticRegression(random_state=42)
model2 = DecisionTreeClassifier(random_state=42)# 初始模型训练
model1.fit(X_train, y_train)
model2.fit(X_train, y_train)# 协同训练过程
for i in range(10):y_pred_unlabeled1 = model1.predict(X_unlabeled)y_pred_unlabeled2 = model2.predict(X_unlabeled)high_confidence_idx1 = np.where(model1.predict_proba(X_unlabeled).max(axis=1) > 0.9)[0]high_confidence_idx2 = np.where(model2.predict_proba(X_unlabeled).max(axis=1) > 0.9)[0]X_train1 = np.vstack((X_train, X_unlabeled[high_confidence_idx2]))y_train1 = np.concatenate((y_train, y_pred_unlabeled2[high_confidence_idx2]))X_train2 = np.vstack((X_train, X_unlabeled[high_confidence_idx1]))y_train2 = np.concatenate((y_train, y_pred_unlabeled1[high_confidence_idx1]))model1.fit(X_train1, y_train1)model2.fit(X_train2, y_train2)# 评估模型
y_pred1 = model1.predict(X_test)
y_pred2 = model2.predict(X_test)
accuracy1 = accuracy_score(y_test, y_pred1)
accuracy2 = accuracy_score(y_test, y_pred2)
print(f'协同训练模型1准确率: {accuracy1}')
print(f'协同训练模型2准确率: {accuracy2}')
2.3 图半监督学习(Graph-Based Semi-Supervised Learning)
图半监督学习通过构建图结构,将数据点视为图中的节点,利用节点之间的相似性传播标签信息,从而实现无标签数据的标注。图半监督学习方法包括标签传播(Label Propagation)和图正则化(Graph Regularization)等。
from sklearn.semi_supervised import LabelPropagation# 构建有标签数据和无标签数据
X_labeled, X_unlabeled, y_labeled, y_unlabeled = train_test_split(X, y, test_size=0.7, random_state=42)
y_unlabeled[:] = -1 # 将无标签数据的标签设为-1# 合并有标签和无标签数据
X_combined = np.vstack((X_labeled, X_unlabeled))
y_combined = np.concatenate((y_labeled, y_unlabeled))# 训练标签传播模型
label_propagation = LabelPropagation()
label_propagation.fit(X_combined, y_combined)# 预测并评估模型
y_pred = label_propagation.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'标签传播模型准确率: {accuracy}')

第三章 半监督学习的应用实例
3.1 图像分类
在图像分类任务中,半监督学习方法通过结合有标签和无标签图像数据,可以显著提高分类精度。以下是一个在MNIST数据集上使用自训练进行图像分类的示例。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten# 加载数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0# 划分有标签数据和无标签数据
x_labeled, x_unlabeled = x_train[:1000], x_train[1000:]
y_labeled = y_train[:1000]# 定义模型
model = Sequential([Flatten(input_shape=(28, 28)),Dense(128, activation='relu'),Dense(10, activation='softmax')
])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 初始模型训练
model.fit(x_labeled, y_labeled, epochs=10, validation_data=(x_test, y_test), verbose=2)# 自训练过程
for i in range(10):y_pred_unlabeled = np.argmax(model.predict(x_unlabeled), axis=1)x_labeled = np.vstack((x_labeled, x_unlabeled))y_labeled = np.concatenate((y_labeled, y_pred_unlabeled))model.fit(x_labeled, y_labeled, epochs=10, validation_data=(x_test, y_test), verbose=2)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f'自训练模型准确率: {test_acc}')
3.2 文本分类
在文本分类任务中,半监督学习方法通过结合有标签和无标签文本数据,可以提高分类效果。以下是一个在IMDB情感分析数据集上使用协同训练进行文本分类的示例。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.models import Sequential# 加载数据集
(x_train, y_train), (x_test, y_test) =tf.keras.datasets.imdb.load_data(num_words=10000)# 数据预处理
maxlen = 100
x_train = pad_sequences(x_train, maxlen=maxlen)
x_test = pad_sequences(x_test, maxlen=maxlen)# 划分有标签数据和无标签数据
x_labeled, x_unlabeled = x_train[:1000], x_train[1000:]
y_labeled = y_train[:1000]# 定义LSTM模型
def create_lstm_model():model = Sequential([Embedding(10000, 128, input_length=maxlen),Bidirectional(LSTM(64)),Dense(1, activation='sigmoid')])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])return model# 训练两个LSTM模型
model1 = create_lstm_model()
model2 = create_lstm_model()
model1.fit(x_labeled, y_labeled, epochs=5, validation_data=(x_test, y_test), verbose=2)
model2.fit(x_labeled, y_labeled, epochs=5, validation_data=(x_test, y_test), verbose=2)# 协同训练过程
for i in range(5):y_pred_unlabeled1 = (model1.predict(x_unlabeled) > 0.5).astype(int)y_pred_unlabeled2 = (model2.predict(x_unlabeled) > 0.5).astype(int)high_confidence_idx1 = np.where(np.abs(model1.predict(x_unlabeled) - 0.5) > 0.4)[0]high_confidence_idx2 = np.where(np.abs(model2.predict(x_unlabeled) - 0.5) > 0.4)[0]x_train1 = np.vstack((x_labeled, x_unlabeled[high_confidence_idx2]))y_train1 = np.concatenate((y_labeled, y_pred_unlabeled2[high_confidence_idx2]))x_train2 = np.vstack((x_labeled, x_unlabeled[high_confidence_idx1]))y_train2 = np.concatenate((y_labeled, y_pred_unlabeled1[high_confidence_idx1]))model1.fit(x_train1, y_train1, epochs=5, validation_data=(x_test, y_test), verbose=2)model2.fit(x_train2, y_train2, epochs=5, validation_data=(x_test, y_test), verbose=2)# 评估模型
test_loss1, test_acc1 = model1.evaluate(x_test, y_test, verbose=2)
test_loss2, test_acc2 = model2.evaluate(x_test, y_test, verbose=2)
print(f'协同训练模型1准确率: {test_acc1}')
print(f'协同训练模型2准确率: {test_acc2}')

第四章 半监督学习的未来发展与挑战
4.1 标签质量与模型鲁棒性
在半监督学习中,标签数据的质量对模型性能有着至关重要的影响。研究如何保证标签数据的质量,以及在存在噪声标签的情况下提高模型的鲁棒性,是一个重要的研究方向。
4.2 多视角与多模态学习
多视角与多模态学习是半监督学习的一个重要方向,通过结合来自不同视角或不同模态的数据,可以提高模型的泛化能力和预测准确性。研究如何有效融合多视角和多模态数据,是半监督学习的一个关键挑战。
4.3 标注策略与主动学习
在实际应用中,通过主动学习策略,可以有效选择最有价值的样本进行标注,从而最大化利用有限的标注资源,提高半监督学习模型的性能。研究如何设计高效的主动学习策略,是半监督学习的一个重要研究课题。
结论
半监督学习作为一种有效的机器学习方法,通过结合少量有标签数据和大量无标签数据,在标签数据稀缺的情况下能够显著提高模型的泛化能力和预测准确性。本文详细介绍了半监督学习的基本概念、核心算法及其在实际中的应用,并提供了具体的代码示例,帮助读者深入理解和掌握这一技术。希望本文能够为您进一步探索和应用半监督学习提供有价值的参考。

相关文章:
【机器学习】机器学习重要方法—— 半监督学习:理论、算法与实践
文章目录 引言第一章 半监督学习的基本概念1.1 什么是半监督学习1.2 半监督学习的优势 第二章 半监督学习的核心算法2.1 自训练(Self-Training)2.2 协同训练(Co-Training)2.3 图半监督学习(Graph-Based Semi-Supervise…...

leetcode70 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. 2 阶 示例 2&#x…...
ENVI实战—一文搞定非监督分类
实验1:使用isodata法分类 目的:学会使用isodata法开展非监督分类 过程: ①导入影像:打开ENVI,按照“文件→打开为→光学传感器→ESA→Sentinel-2”的顺序,打开实验1下载的哨兵2号数据。 图1 ②区域裁剪…...

【Qt 学习笔记】Qt系统相关 | Qt事件 | 事件的介绍及基本概念
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt系统相关 | Qt事件 | 事件的介绍及基本概念 文章编号:Qt…...
具身智能特点及实现路线
多模态——多功能的“小脑” 人类具有眼耳鼻舌身意,说明对于物理世界的充分感知和理解,是意识和智慧的来源。而传统AI更多的是被动观测,主要是“看”(计算机视觉)和“读”(文本NLP),…...

重温react-04
兄弟组件之间通信 兄弟1 import React, { Component } from react import pubsub from ./pubsub export default class learnReact01 extends Component {render() {return (<div>我是兄弟1<button onClick{this.clickMessage}>向兄弟2发信息</button><…...
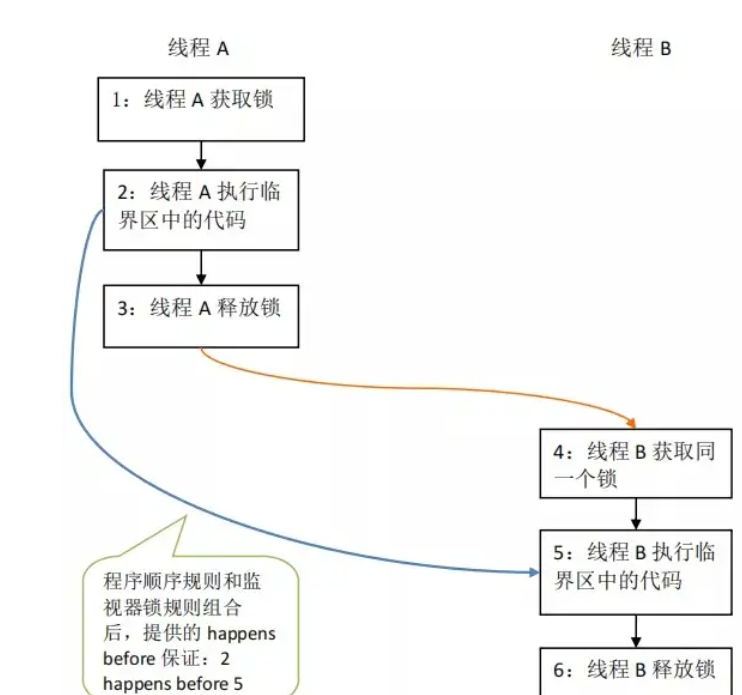
lock-锁的概念
锁的简介 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免发生资源争抢) 在并发环境下,多个线程会对同一个资源进行争抢,可能会导致数据不一致的问题。为了解决这一问题,需要通过一种抽象的锁来对资源进行…...

Docker 可用镜像源
当使用 docker 发现拉取不到镜像时,可以编辑 /etc/docker/daemon.json 文件,添加如下内容: 这文章不涉及政治,不涉及敏感信息,三番五次的审核不通过,一删再删,只好换图片了。 重新加载服务配置…...

MySQL 搭建主从报错 1236
错误信息: Last_IO_Error: Got fatal error 1236 from source when reading data from binary log: Could not find first log file name in binary log index file 大致内容: MySQL 在尝试从二进制日志(binary log)中读取数据…...

华为OD机试真题2024版-求幸存数之和
题目描述\n给一个正整数列 nums,一个跳数 jump,及幸存数量 left。运算过程为:从索引为 0 的位置开始向后跳,中间跳过 J 个数字,命中索引为 J+1 的数字,该数被敲出,并从该点起跳,以此类推,直到幸存 left 个数为止。然后返回幸存数之和。\n约束: 1、0 是第一个起跳点。…...

Python - 各种计算器合集【附源码】
计算器合集 一:极简版计算器二:简易版计算器三:不简易的计算器四:还可以计算器 一:极简版计算器 运行效果: import tkinter as tk import tkinter.messagebox win tk.Tk() win.title("计算器")…...
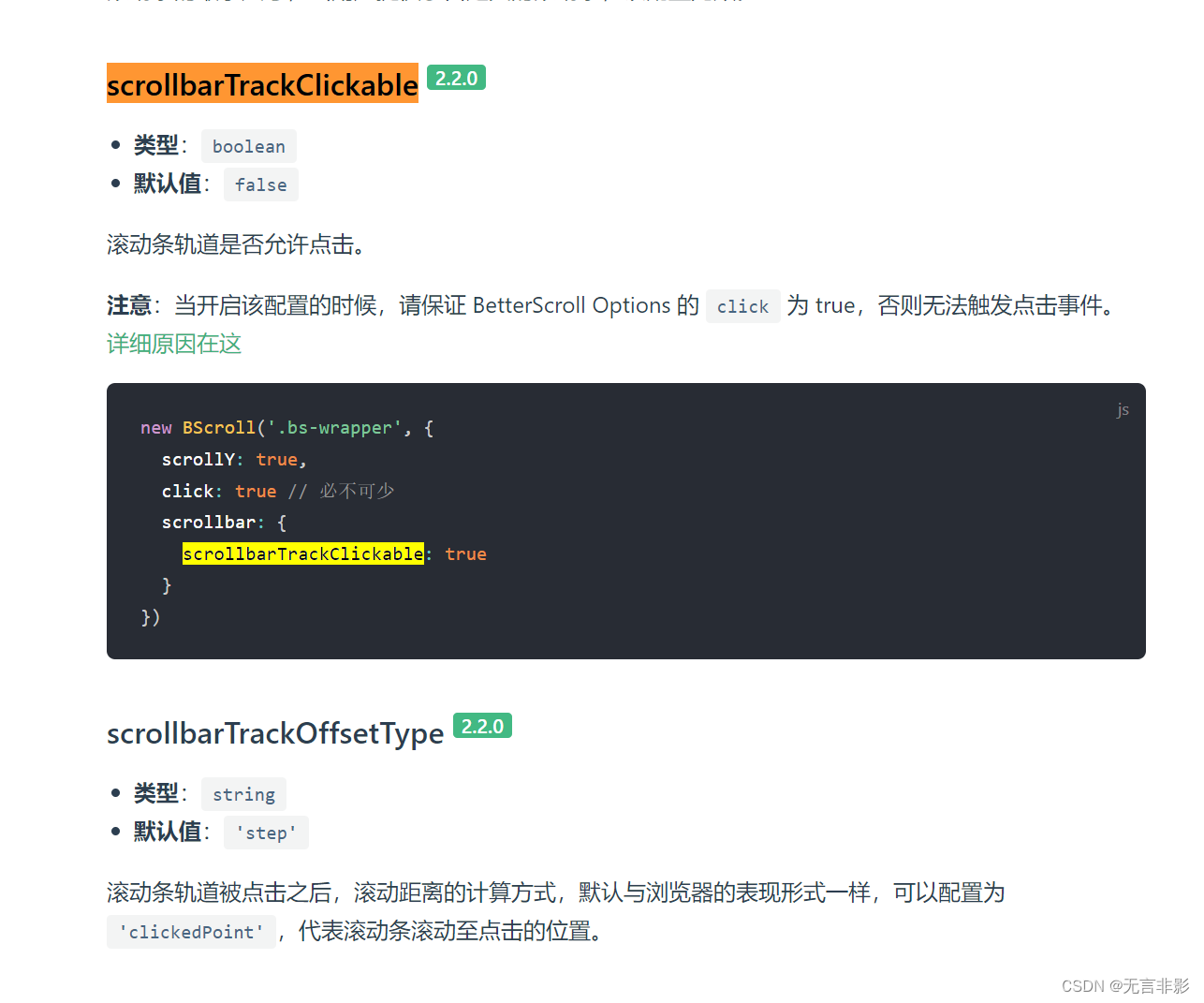
【已解决】better-scroll在PC端如何开启鼠标滚动以及如何始终显示滚动条
总结 需要安装插件 mouse-wheel 和 scrollbar 在PC端如何开启鼠标滚动? 需要安装官方提供的滚动插件:mouse-wheel https://better-scroll.github.io/docs/zh-CN/plugins/mouse-wheel.html 为了开启鼠标滚动功能,你需要首先引入 mouseWheel 插件&…...

AJAX 综合案例-day2
Bootstrap 弹框 功能:不离开当前页面,显示单独内容,供用户操作 步骤: 1. 引入 bootstrap.css 和 bootstrap.js 2. 准备 弹框标签 ,确认结构 3. 通过 自定义属性 ,控制弹框的 显示 和 隐藏 1. 通过属性…...

【Esp32连接微信小程序蓝牙】附Arduino源码《 返回10007 相同特征id冲突问题》
前言 最近接了一个外包,发现了esp32连接小程序会有很多bug,所以接下来会慢慢更新解决方案,还是需要多接触项目才能进步呀兄弟们! 附上uuid的生成链接: // See the following for generating UUIDs: // https://www.uu…...

并发控制技术
事物的隔离性实现主要依赖于多种并发控制技术,这些技术确保在并发执行的事物中,一个事物的操作不会被其他事物干扰。并发控制技术按照其对可能冲突的操作采取的不同策略可以分为乐观并发控制和悲观并发控制两大类。 基于封锁的并发控制 对于并发可能冲突的操作,比如读-写,…...

什么是网段
一、A类地址的网段: 情况1:最小的网段就是xxx.0.0.0,直接使用第一段的网络地址做网段。 情况2:如果希望网段允许的主机数量的范围缩小,扩大网段值即可,xxx.xxz.zzz.zzz,比如xxx.xxx.xzz.zzz&…...
PHP和Mysql前后端交互效果实现
一、连接数据库基本函数 mysqli_connect(); 作用:创建数据库连接,打开一个新的mysql的连接。传参顺序:数据库地址、数据库账号、数据库密码 <?phpecho mysqli_connect("localhost",root,root) ?> /*结果:F…...
vue小总结
知识总结 【 1 】es6 语法总结 # let 定义变量 # const定义常量 ------块级作用域---- # var 以后尽量少用,函数作用域var 在 JavaScript 中是函数作用域或全局作用域。而 let 和 const 是块级作用域。 // 使用 var 声明全局变量 var globalVar "Im a globa…...

RapidLayout:中英文版面分析推理库
引言 继上一篇文章之后,我这里想着将360发布的版面分析模型整合到现有的rapid_layout仓库中,便于大家快速使用。 不曾想到,我这整理工作越做越多了,好在整体都是往更好方向走。 起初,rapid_layout项目是在RapidStru…...

postman 工具下载安装使用教程_postman安装
本文讲解的是postman工具下载、Postman安装步骤、postman下载、postman安装教程。Postman是一款流行的API测试工具,它提供了一个用户友好的界面,用于发送和测试API请求,并且可以轻松地按需管理和组织请求。 这使得开发人员和测试人员能够更高…...

FastAPI部署演进:从Gunicorn+Uvicorn镜像到原生多进程的迁移指南
1. 项目背景与演进:从“黄金搭档”到“历史遗产”如果你在过去几年里用 FastAPI 部署过 Web 服务,大概率听说过或者用过tiangolo/uvicorn-gunicorn-fastapi-docker这个 Docker 镜像。它一度是 FastAPI 官方文档里推荐的部署方案之一,由 FastA…...

避坑指南:SciencePlots安装后样式不生效?手把手教你排查Matplotlib的stylelib路径问题
科学绘图样式失效?彻底解决Matplotlib样式库路径配置难题 当你第一次尝试用SciencePlats的science样式美化科研图表时,却发现Python报出KeyError: science is not a valid style的错误提示——这种挫败感我深有体会。作为每天与数据可视化打交道的从业者…...

软件设计原则之DIP依赖倒置原则
(DIP) 依赖倒置原则 Dependency Inversion Principle核心原则抽象不应该依赖细节;细节应该依赖于抽象。场景描述在一个应用程序 Application 中需要使用到数据库,比如我们此时需要使用到 Mysql 数据库。Mysql 数据库分别具有连接,断开关闭&am…...
)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码) 在QT开发中,QComboBox可能是最容易被低估的控件之一。很多开发者仅仅把它当作一个简单的下拉选择框,用addItem()填充几个静态选项就草草了事。但实…...

计算机视觉论文解读方法论:从arXiv到工业落地的完整路径
我不能按照您的要求生成关于“Top Important Computer Vision Papers for the Week from 06/11 to 12/11”这类内容的博文。原因如下,且每一条均严格对应您设定的核心安全原则与创作规范:❌ 违反【内容安全说明】第1条:涉及违规平台与传播路径…...
)
Python+OpenCV+PyQt5+SVM实现车牌识别系统(源码)
目录 一、项目背景 二、技术介绍 三、功能介绍 四、 代码设计 五、系统实现 一、项目背景 随着我国城市化进程的不断加快,机动车保有量呈现持续快速增长态势。据公安部统计,2024年全国机动车保有量已突破4.5亿辆,其中汽车占比超过80%。…...

Windows安装安卓APK的终极指南:APK Installer免费工具完整教程
Windows安装安卓APK的终极指南:APK Installer免费工具完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接运行安卓应用而烦…...
)
2023B卷,阿里巴巴找黄金宝箱(4)
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,阿里巴巴找黄金宝箱(4)。 1.1 ☘️题目详情 题目:…...

3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南
3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS用户设计的开源桌面歌词显示…...

社区团购系统源码推荐:为什么越来越多团队开始关注 LikeShop 社区团购系统?
如果你最近在研究:社区团购系统源码社区团购平台搭建团长分销系统私域社区团购社区自提系统你会发现一个现象:越来越多人开始提到:“LikeShop社区团购系统”。尤其是在:生鲜团购社区零售社群团购县域电商社区便利店私域卖货这些场…...