问题解决:Problem exceeding maximum token in azure openai (with java)
问题背景:
I'm doing a chat that returns queries based on the question you ask it in reference to a specific database. For this I use azure openai and Java in Spring Boot.
我正在开发一个聊天功能,该功能根据您针对特定数据库的提问返回查询结果。为此,我使用了Azure OpenAI和Spring Boot中的Java。
My problem comes here:
How can I make the AI remember the previous questions without passing the context back to it (what I want to do is greatly reduce the consumption of tokens, since depending on what it asks, if the question contains a keyword, for example 'users', what I do is pass in the context the information in this table that is huge (name of the fields, type of data and description) so when you have several questions the use of tokens rises to more than 10,000))
我如何能让AI记住之前的问题,而不需要将上下文再次传递给它(我想做的是大大减少令牌的消耗,因为根据AI提出的问题,如果问题中包含一个关键字,例如“用户”,我会在上下文中传递这个巨大表格的信息(字段名、数据类型和描述),所以当你有多个问题时,令牌的使用量会上升到超过10,000个))
I can't show all the code since it's a project for my company.
由于这是我们公司的一个项目,我不能展示所有的代码。
What im currently doing is adding to the context the referenced table and the principal context(you are a based SQL chat...). And for the chat to remember, I have tried to save the history in java and pass the context history again(but this exceed the tokens pretty fast)
我目前所做的是向上下文中添加引用的表格和主要上下文(例如“您是一个基于SQL的聊天...”)。为了让聊天能够记住之前的对话,我试图在Java中保存历史记录并再次传递上下文历史(但这很快就会超过令牌限制)。
This is what I'm currently doing (no remembering from the AI):
这是我现在的做法(AI不会记住之前的对话)
chatMessages.add(new ChatMessage(ChatRole.SYSTEM, context));chatMessages.add(new ChatMessage(ChatRole.USER, question));ChatCompletions chatCompletions = client.getChatCompletions(deploymentOrModelId, new ChatCompletionsOptions(chatMessages));问题解决:
As far as I know, there is no way to make the LLM (Azure OpenAI in this case) remember your context cheaply, as you said, sending context (and a huge chunk of it) on each call gets pricy really fast. That been said, you could change the approach and try other techniques to mimic that the AI has memory like summarizing the previous questions and send that as content (instead of a long string with 20 questions/answers, you send a short summary of what the user has been asking for. it will keep your prompt short and kind of "aware" of the conversation.
据我所知,确实没有便宜的方法让大型语言模型(在这种情况下是Azure OpenAI)记住上下文,正如您所说,每次调用时发送上下文(特别是大量的上下文)会很快变得昂贵。话虽如此,您可以改变方法并尝试其他技术来模拟AI具有记忆的功能,比如总结之前的问题并将其作为内容发送(而不是发送包含20个问答的长字符串,您发送一个用户一直在询问的内容的简短摘要)。这将使您的提示保持简短,并使AI对对话保持“意识”。
There are also conversation buffers (keeping the chat history in memory and send it to de llm each time as you did) but it gets long pretty fast, for that you could configure a buffer window (limiting the memory of the conversation to the last 3 questions for example, that should help keep the token count manageable).
还有对话缓冲区(将聊天历史保存在内存中,并在每次调用时像您之前所做的那样发送给LLM),但对话历史很快就会变得很长。为此,您可以配置一个缓冲区窗口(例如,将对话的内存限制为最后3个问题),这有助于将令牌数量控制在可管理的范围内。
There are several ways to manage this but there is no "perfect memory" as far as I know, not one the is worth paying. If you could tell us a bit more on how good the bot memory needs to be or the specific use case, maybe we can be more precise. Good luck!
管理这种情况有几种方法,但据我所知,没有“完美的记忆”,至少没有一种值得为此付费的。如果您能告诉我们机器人需要多好的记忆能力,或者具体的使用场景,我们可能能给出更精确的建议。祝您好运!

相关文章:
问题解决:Problem exceeding maximum token in azure openai (with java)
问题背景: Im doing a chat that returns queries based on the question you ask it in reference to a specific database. For this I use azure openai and Java in Spring Boot. 我正在开发一个聊天功能,该功能根据您针对特定数据库的提问返回查询…...
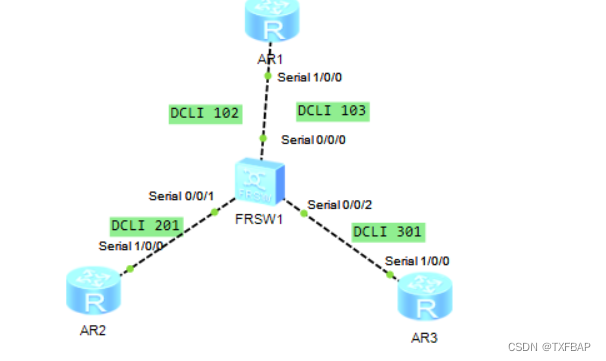
eNSP学习——OSPF在帧中继网络中的配置
目录 主要命令 原理概述 实验目的 实验场景 实验拓扑 实验编址 实验步骤 1、基本配置 2、在帧中继上搭建OSPF网络 主要命令 //检查帧中继的虚电路状态 display fr pvc-info//检查帧中继的映射表 display fr map-info//手工指定OSPF邻居,采用单播方式发送报文 [R1]os…...

PHP转Go系列 | 条件循环的使用姿势
大家好,我是码农先森。 条件 在 PHP 语言中条件控制语句,主要有 if、elseif、else 和 switch 语句 // if、elseif、else 语句 $word "a"; if ($word "a") {echo "a"; } elseif ($word "b") {echo "b&…...

八大经典排序算法
前言 本片博客主要讲解一下八大排序算法的思想和排序的代码 💓 个人主页:普通young man-CSDN博客 ⏩ 文章专栏:排序_普通young man的博客-CSDN博客 若有问题 评论区见📝 🎉欢迎大家点赞👍收藏⭐文章 目录 …...

【LeetCode热题 100】三数之和
leetcode原地址:https://leetcode.cn/problems/3sum/description 描述 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和…...

【深度学习驱动流体力学】完整配置安装 OpenFOAM 及其所需的ThirdParty与QT5工具
OpenFOAM 简介 OpenFOAM(Open Field Operation and Manipulation)是一个领先的开源计算流体动力学(CFD)软件包,由 OpenFOAM Foundation 开发和维护。作为一个高度模块化和可扩展的软件工具箱,OpenFOAM 支持模拟多种物理现象,包括流体流动、传热、混合、燃烧、声学等。由…...
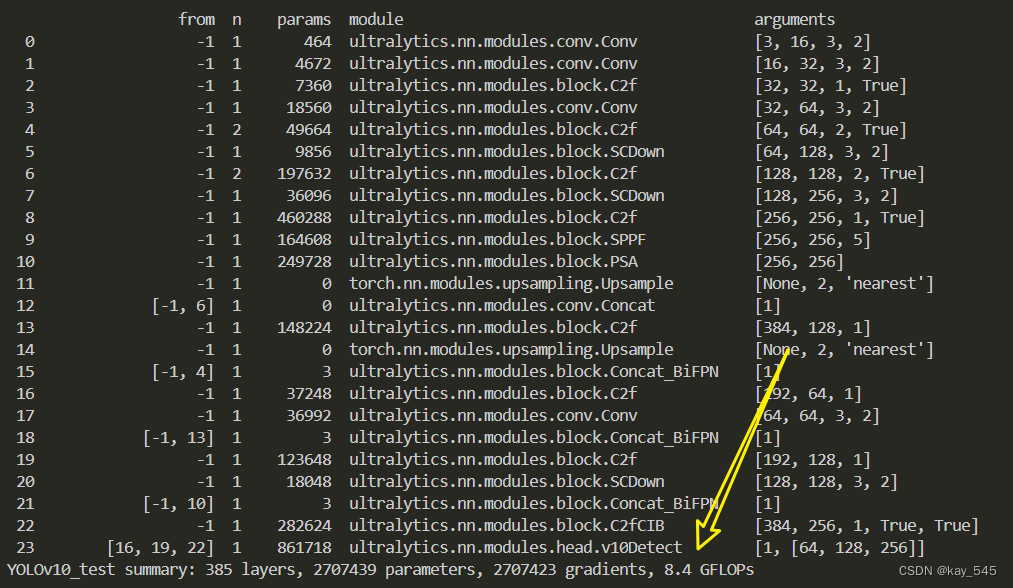
YOLOv10改进 | Neck | 添加双向特征金字塔BiFPN【含二次独家创新】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40篇内容,内含各种Head检测头、损失函数Loss、B…...

PostgreSQL源码分析——pg_basebackup
涉及到的代码主要在src/backend/replication以及bin/pg_basebackup中。 我们知道pg_basebackup是一个进行基础备份的工具,除了使用这个工具,还可以用底层API的方式进行基础备份,主要过程如下: 连接到数据库执行select pg_start_…...
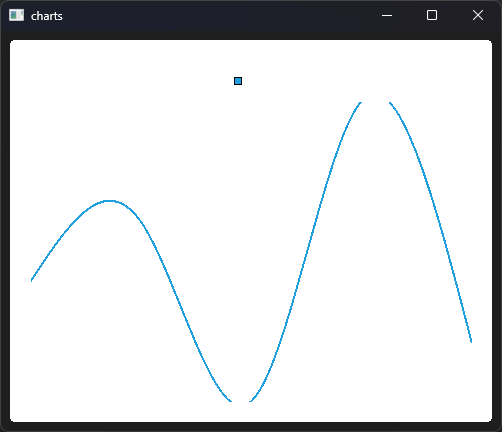
QT基础 - 常见图表绘制
目录 零. 前言 一. 添加模块 折线图 三. 树状图 四. 饼图 五. 堆叠柱状图 六. 百分比柱状图 七. 散点图和光滑曲线图 散点图 光滑曲线图 零. 前言 Qt Charts 是 Qt 框架的一个模块,用于创建各种类型的图表和数据可视化。它为开发者提供了一套功能强大的工…...

解释React中的“端口(Portals)”是什么,以及如何使用它来渲染子节点到DOM树以外的部分。
React中的“端口(Portals)”是一种将子节点渲染到DOM****树以外的部分的技术。在React应用中,通常情况下组件的渲染是遵循DOM的层次结构,即子组件会渲染在父组件的DOM节点内部。然而,有些情况下,开发者可能…...
java实现分类下拉树,点击时对应搜索---后端逻辑
一直想做分类下拉,然后选择后搜索的页面,正好做项目有了明确的需求,查找后发现el-tree的构件可满足需求,数据要求为:{ id:1, label:name, childer:[……] }形式的,于是乎,开搞! 一…...
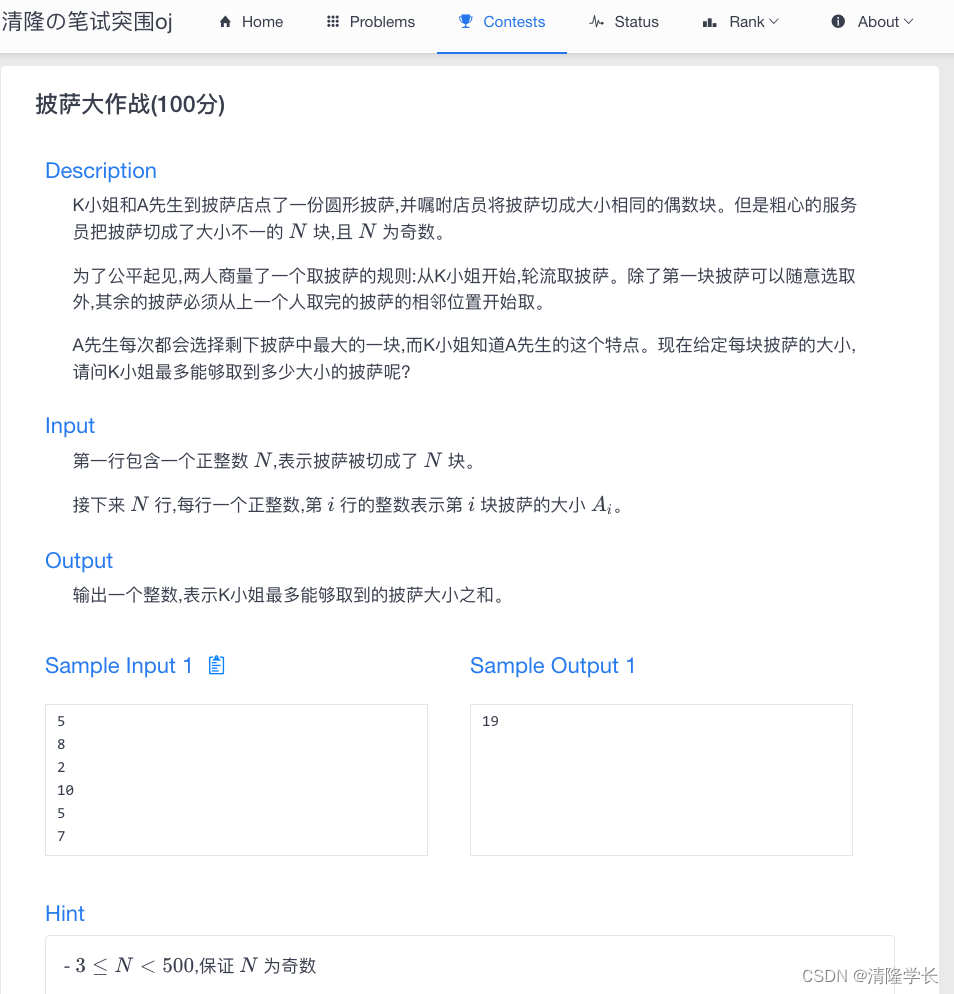
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 披萨大作战(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 …...

探索Facebook对世界各地文化的影响
随着数字化时代的到来,社交媒体已成为连接世界各地人们的重要平台之一。而在这个领域的巨头之一,Facebook不仅是人们沟通交流的场所,更是一座桥梁,将不同地域、文化的人们联系在一起。本文将探索Facebook对世界各地文化的影响&…...

导出requirements.txt
文章目录 requirements.txt导出环境中所有包导出当前项目的包可能遇到的问题 requirements.txt 在Python项目中,通常使用requirements.txt文件来列出所有需要的第三方库和模块。这个文件通常位于项目的根目录下,并且在安装Python项目时,可以…...
我主编的电子技术实验手册(09)——并联电路
本专栏是笔者主编教材(图0所示)的电子版,依托简易的元器件和仪表安排了30多个实验,主要面向经费不太充足的中高职院校。每个实验都安排了必不可少的【预习知识】,精心设计的【实验步骤】,全面丰富的【思考习…...

数据结构_二叉树
目录 一、树型结构 二、二叉树 2.1 概念 2.2 特殊的二叉树 2.3 二叉树的性质 2.4 二叉树的存储 2.5 遍历二叉树 2.6 操作二叉树 总结 一、树型结构 树是一种非线性的数据结构,它是由 n(n>0) 个有限结点组成一个具有层次关系的集合,一棵 n 个…...

Java线程池七个参数详解
ThreadPoolExecutor 是JDK中的线程池实现,这个类实现了一个线程池需要的各个方法,它提供了任务提交、线程管理、监控等方法 下面是 ThreadPoolExecutor 类的构造方法源码,其他创建线程池的方法最终都会导向这个构造方法,共有7个参…...
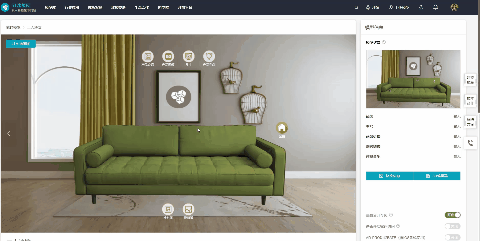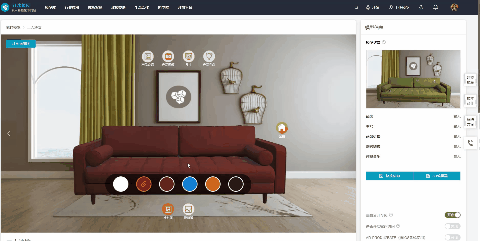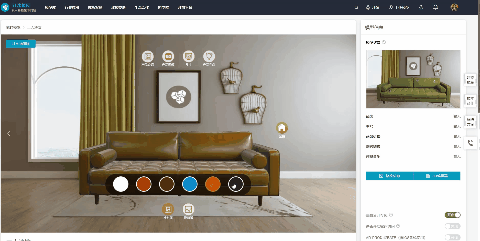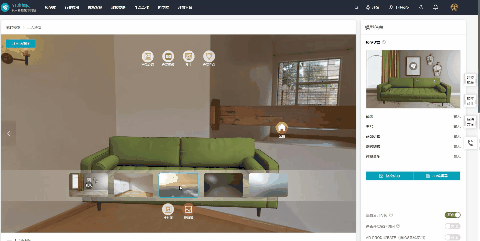
产品Web3D交互展示有什么优势?如何快速制作?
智能互联网时代,传统的图片、文字、视频等产品展示方式,因为缺少互动性,很难引起用户的兴趣,已经逐渐失去了宣传优势。 Web3D交互展示技术的出现,让众多品牌和企业找到了新的方向,线上产品展示不在枯燥无趣…...

Python | Leetcode Python题解之第171题Excel列表序号
题目: 题解: class Solution:def titleToNumber(self, columnTitle: str) -> int:number, multiple 0, 1for i in range(len(columnTitle) - 1, -1, -1):k ord(columnTitle[i]) - ord("A") 1number k * multiplemultiple * 26return n…...
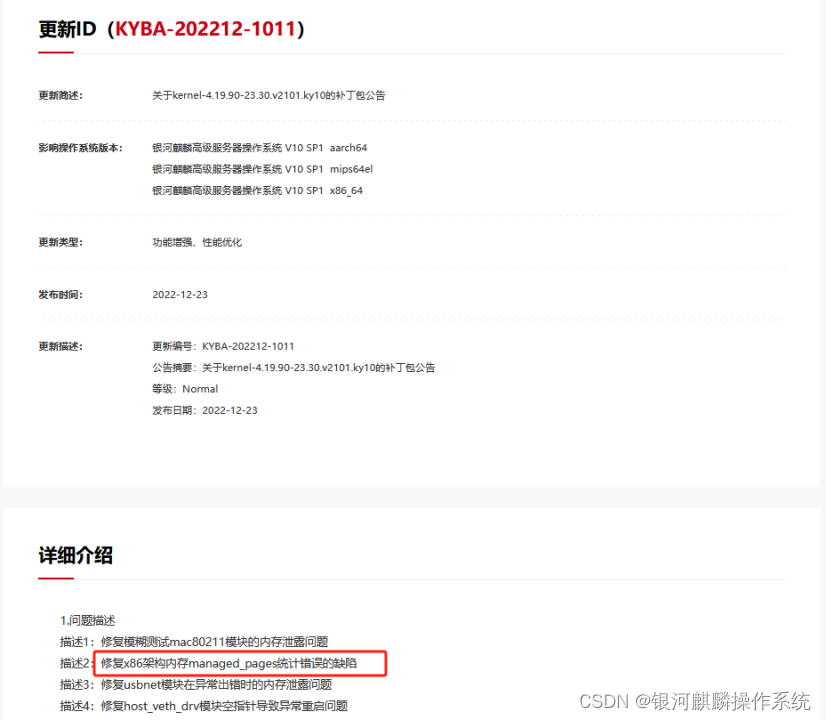
【银河麒麟】高可用触发服务器异常重启,处理机制详解
1.服务器环境以及配置 【机型】物理机 处理器: Intel 内存: 126G 【内核版本】 4.19.90-25.16.v2101.ky10.x86_64 【银河麒麟操作系统镜像版本】 Kylin-Server-10-SP2-Release-Shenzhen-Metro-x86-Build01-20220619 Kylin-HA-10-SP2-Release-S…...

为LibraVDB定制内存池:提升稀疏体素数据处理性能
1. 项目概述:一个为LibraVDB设计的开源内存管理库最近在搞一些基于体素的数据处理项目,特别是用到了LibraVDB这个开源的稀疏体素数据库。玩过VDB格式的朋友都知道,它的核心优势在于对稀疏体数据的极致压缩和高效访问,但这也带来了…...

线束工程化实践:从设计到测试的自动化工具链与开源资源
1. 项目概述:从“Awesome”清单到工程化实践在开源世界里,“Awesome”系列清单就像一个个精心整理的藏宝图,指引着开发者们快速找到某个领域内的优质资源。今天要聊的这个项目fastbeast2023-netizen/awesome-harness-engineering,…...

基于Claude的智能代码脚手架:提升AI编程协作效率的工程实践
1. 项目概述:一个为Claude设计的代码脚手架如果你和我一样,经常与Anthropic的Claude模型打交道,尤其是在代码生成、项目初始化这类场景,那你一定体会过那种“重复造轮子”的疲惫感。每次开启一个新项目,无论是简单的脚…...

New-API数据导出功能:轻松管理AI模型使用记录与账单数据
New-API数据导出功能:轻松管理AI模型使用记录与账单数据 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...

Vex:VS Code向量数据库管理扩展,提升AI开发效率
1. 项目概述:Vex,一个为开发者设计的向量数据库管理利器如果你正在用 VS Code 开发 AI 应用,并且和向量数据库(比如 Milvus 或 ChromaDB)打交道,那你大概率经历过这样的场景:为了插入几条测试向…...

非确定有限自动机—计算机等级考试—软件设计师考前备忘录—东方仙盟
1. 先明确:圆圈里的数字是什么?圆圈里的 0,1,2,3,4,5 是状态编号,不是输入符号,也不是要识别的字符串内容。比如 状态0 是起始状态,状态5 是终止(接受)状态。箭头边上的 0,1,ε 才是输入符号&am…...

自感痕迹论的思想史意义:一场发生学范式的四维跃迁
自感痕迹论的思想史意义:一场发生学范式的四维跃迁摘要在当代思想版图中,人文精神与科学技术正处于前所未有的割裂状态。一方面,现象学、后结构主义在解构了宏大叙事后,陷入相对主义与操作空转的泥淖;另一方面…...

告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南
告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南 在电池供电的物联网设备开发中,功耗优化往往成为决定产品成败的关键因素。想象一下,一个部署在偏远地区的环境监测节点,如果因为功耗问…...

90%的程序员都不知道,转大模型根本不用从头学深度学习
文章目录前言一、大模型时代,传统深度学习的学习路径已经彻底过时了1.1 以前做AI,确实得先学深度学习1.2 现在做AI,更像是开汽车1.3 90%的大模型岗位,根本不需要深度学习底层知识二、90%的大模型开发工作,到底在做什么…...
)
从配置字到实际运动:手把手教你用EtherCAT调试伺服电机的控制模式(以倍福TwinCAT3为例)
从配置字到实际运动:手把手教你用EtherCAT调试伺服电机的控制模式(以倍福TwinCAT3为例) 在工业自动化现场,伺服电机的精准控制往往决定着整条产线的运行效率。当面对一台全新的伺服驱动器时,如何快速完成从参数配置到实…...