如何让大语言模型在规格普通的硬件上运行 - 量化技术
近年来,大型语言模型(LLMs)的能力有了飞跃式的发展,使其在越来越多的应用场景中更加友好和适用。然而,随着LLMs的智能和复杂度的增加,其参数数量,即权重和激活值的数量也在增加,这意味着模型的学习和处理数据的能力在不断提升。例如,GPT-3.5拥有约1750亿个参数,而当前最先进的GPT-4则拥有超过1万亿个参数。
然而,模型越大,所需的内存也越多。这意味着只能在具有高规格硬件和足够数量的GPU的设备上运行这些模型——这限制了模型的部署选项,从而影响了基于LLM的解决方案的普及和应用。幸运的是,机器学习研究人员正在开发越来越多的解决方案来应对模型规模不断增长的挑战,其中最突出的解决方案之一就是量化技术。
在本篇中,我们将探讨量化的概念,包括其工作原理、重要性和优势,以及量化语言模型的不同技术。
1. 什么是量化以及为什么它很重要?
量化是一种模型压缩技术,它将大型语言模型(LLM)中的权重和激活值从高精度的数据表示转换为低精度的数据表示,也就是说,从可以容纳更多信息的数据类型转换为容纳较少信息的数据类型。一个典型的例子是将数据从32位浮点数(FP32)转换为8位或4位整数(INT8或INT4)。
理解量化的一个很好的类比是图像压缩。压缩图像涉及通过移除一些信息(即数据位)来减小其大小。虽然减小图像的大小通常会降低其质量(在可接受的范围内),但这也意味着在给定设备上可以保存更多的图像,同时传输或显示给用户所需的时间和带宽也会减少。同样,量化LLM增加了其可移植性和可部署方式的数量——尽管以可接受的细节或精度为代价。
量化在机器学习中是一个重要过程,因为减少模型每个权重所需的位数会显著减少其总体大小。因此,量化产生的LLM占用更少的内存、需要更少的存储空间、更节能,并且能够更快地进行推理。所有这些优点使得LLM可以在更广泛的设备上运行,包括单个GPU,而不是依赖昂贵的多GPU硬件,甚至在某些情况下可以在CPU上运行。
2. 量化是如何工作的?
从本质上讲,量化过程涉及将存储在高精度值中的权重映射到低精度数据类型。虽然在某些情况下这相对简单,例如将64位或32位浮点数映射到16位浮点数,因为它们共享表示方案,但在其他情况下则更加复杂。例如,将32位浮点值量化为4位整数就比较复杂,因为INT4只能表示16个不同的值,而FP32的范围非常广。
为了实现量化,我们需要找到将FP32权重值范围[最小值, 最大值]映射到INT4空间的最佳方式:一种实现此目的的方法称为仿射量化方案,其公式如下:
x_q = round(x/S + Z)
其中:
x_q – 对应于FP32值x的量化INT4值
S – FP32缩放因子,是一个正的float32值
Z – 零点:对应于FP32空间中的0的INT4值
round – 指将结果值四舍五入到最接近的整数
然而,要找到FP32值范围的==[最小值, 最大值]==,我们必须首先使用一个较小的校准数据集对模型进行校准。可以通过多种方式确定[最小值, 最大值],常见的解决方案是将其设置为观察到的最小和最大值。随后,所有超出此范围的值将被“截断”——即分别映射到最小值和最大值。
话虽如此,这种方法及类似方法的问题在于,离群值(即异常值)可能对缩放产生不成比例的影响:低精度数据类型的完整范围没有得到有效利用——这降低了量化模型的准确性。解决此问题的方法是块内量化,将权重按其值分为64或128的组。例如,每个块分别进行量化,以减轻离群值的影响并提高精度。
需要考虑的一点是,虽然LLM的权重和激活值将被量化以减少其大小,但在推理时会被反量化,因此在前向传播和后向传播期间可以使用高精度数据类型进行必要的计算。这意味着每个块的缩放因子也必须存储。因此,在量化过程中使用的块数越多,精度越高,但必须保存的缩放因子数量也越多。
3. 两种类型的大型语言模型量化:PTQ 和 QAT
虽然有多种量化技术,但总的来说,LLM 量化分为两类:
训练后量化(PTQ)
训练后量化指的是在大型语言模型已经训练完成后进行量化的技术。PTQ 比 QAT 更容易实现,因为它需要的训练数据更少且速度更快。然而,由于权重值精度的丧失,它也可能导致模型准确性的降低。
量化感知训练(QAT)
量化感知训练指的是在数据上进行微调时考虑量化的方法。与 PTQ 技术相比,QAT 在训练阶段集成了权重转换过程,即校准、范围估计、截断、舍入等。这通常会导致更优的模型性能,但计算需求更高。
4. 量化大型语言模型的优缺点
优点
模型更小:通过减少权重的大小,量化生成的模型更小。这使得它们可以在各种情况下部署,例如在硬件性能较低的设备上,并降低存储成本。
扩展性增强:量化模型的内存占用较小,这也使得它们的扩展性更强。由于量化模型对硬件的要求较低,组织可以更灵活地增加IT基础设施以适应它们的使用。
推理速度更快:权重使用的位宽较低,以及由此产生的较低内存带宽需求,使计算更加高效。
缺点
准确性降低:毫无疑问,量化的最大缺点是输出的准确性可能降低。将模型的权重转换为低精度可能会降低其性能——而且量化技术越“激进”,即转换数据类型的位宽越低,例如4位、3位等,准确性降低的风险就越大。
5. 不同的LLM量化技术
现在我们已经讨论了量化是什么以及它的好处,让我们来看看不同的量化方法及其工作原理。
QLoRA
Low-Rank Adaptation(LoRA)是一种参数高效微调 Parameter-Efficient Fine-Tuning(PEFT)技术,通过冻结基础LLM的权重并微调一小部分额外的权重(称为适配器 adapters),减少进一步训练基础LLM的内存需求。Quantized Low-Rank Adaptation(QLoRA)更进一步,将基础LLM中的原始权重量化为4位:减少LLM的内存需求,使其在单个GPU上运行成为可能。
QLoRA通过两个关键机制进行量化:4位NormalFloat(NF4)数据类型和双重量化。
NF4:一种用于机器学习的4位数据类型,将每个权重归一化为-1到1之间的值,与传统的4位浮点数相比,可以更准确地表示低精度权重值。然而,虽然NF4用于存储量化权重,QLoRA在前向和后向传播过程中使用另一种数据类型,即brainfloat16(BFloat16),这也是专为机器学习设计的。
双重量化(DQ):一种为了额外节省内存而对量化常量进行再次量化的过程。QLoRA将权重以64为一组进行量化,虽然这便于精确的4位量化,但还必须考虑每个组的缩放因子——这增加了所需的内存。DQ通过对每个组的缩放因子进行第二轮量化来解决这个问题。32位缩放因子被编译成256的块并量化为8位。因此,先前每个组的32位缩放因子为每个权重增加了0.5位,而DQ将其降至仅0.127位。尽管看似微不足道,但在例如65B LLM中,结合起来可以节省3 GB的内存。
PRILoRA
Pruned and Rank-Increasing Low-Rank Adaptation(PRILoRA)是一种最近由研究人员提出的微调技术,旨在通过引入两个额外的机制来提高LoRA的效率:ranks的线性分布和基于重要性的A权重剪枝。
回到low-rank分解的概念,LoRA通过结合两个矩阵来实现微调:W,包含整个模型的权重,和AB,表示通过训练额外权重(即适配器)对模型所做的所有更改。AB矩阵可以分解成两个更小的low-rank矩阵A和B,因此称为low-rank分解。然而,在LoRA中,low-rank r在所有LLM层中是相同的,而PRILoRA则线性增加每层的rank。例如,开发PRILoRA的研究人员从r = 4开始,并在最终层增加到r = 12——在所有层中产生了平均rank为8。
其次,PRILoRA在微调过程中每40步对A矩阵进行剪枝,消除最低的,即最不重要的权重。通过使用重要性矩阵来确定最低权重,该矩阵存储了每层的权重临时幅度和与输入相关的统计数据。以这种方式剪枝A矩阵减少了需要处理的权重数量,从而减少了微调LLM所需的时间和微调模型的内存需求。
尽管仍在研究中,PRILoRA在研究人员进行的基准测试中显示出了非常令人鼓舞的结果。这包括在8个评估数据集中有6个优于全量微调方法,同时在所有数据集中都取得了比LoRA更好的结果。
GPTQ
GPTQ(通用预训练Transformer量化 General Pre-Trained Transformer Quantization)是一种量化技术,旨在减少模型的大小,使其能够在单个GPU上运行。GPTQ通过一种逐层量化的方法工作:这种方法一次量化模型的一层,目的是发现最小化输出误差(即原始全精度层和量化层输出之间的均方误差(MSE))的量化权重。
首先,所有模型的权重被转换成一个矩阵,通过一种称为懒惰批更新 lazy batch updating的过程一次处理128列的批次。此过程包括批量量化权重,计算MSE,并将权重更新为减少MSE的值。在处理校准批次后,矩阵中的所有剩余权重根据初始批次的MSE进行更新——然后所有单独的层重新组合以生成量化模型。
GPTQ采用混合INT4/FP16量化方法,其中4位整数用于量化权重,激活值保持在更高精度的float16数据类型中。随后,在推理过程中,模型的权重实时反量化,以便计算在float16中进行。
GGML/GGUF
GGML
GGML(据说是以其创建者命名为Georgi Gerganov Machine Learning,或GPT-Generated Model Language)是一个基于C语言的机器学习库,旨在对Llama模型进行量化,使其能够在CPU上运行。更具体地说,该库允许你将量化后的模型保存为GGML二进制格式,从而可以在更广泛的硬件上执行。
GGML通过称为k-quant系统的过程来量化模型,该系统根据所选的量化方法使用不同位宽的值表示。首先,模型的权重被分成32个一组,每个组都有一个基于最大权重值(即最高梯度幅度)的缩放因子。
根据选择的量化方法,最重要的权重会被量化为高精度数据类型,而其余的权重则被分配为低精度类型。例如,q2_k量化方法将最大的权重转换为4位整数,其余权重转换为2位整数。或者,q5_0和q8_0量化方法分别将所有权重转换为5位和8位整数表示。你可以通过查看此代码库中的模型卡来查看GGML的全量化方法范围。
GGUF
GGUF(GPT-Generated Unified Format)是GGML的后继者,旨在解决其局限性——最显著的是使非Llama模型的量化成为可能。GGUF也是可扩展的:允许集成新功能,同时保持与旧LLM的兼容性。
然而,要运行GGML或GGUF模型,你需要使用一个名为llama.cpp的C/C++库——该库也是由GGML的创建者Georgi Gerganov开发的。llama.cpp能够读取以.GGML或.GGUF格式保存的模型,并使其能够在CPU设备上运行,而不是需要GPU。
AWQ
传统上,模型的权重量化时不考虑它们在推理过程中处理的数据。与之相反,激活感知权重量化 Activation-Aware Weight Quantization(AWQ)考虑了模型的激活,即输入数据中最显著的特征及其在推理过程中如何分布。通过根据输入的特定特性调整模型权重的精度,可以最大限度地减少量化引起的准确性损失。
AWQ的第一阶段是使用一个校准数据子集来收集模型的激活统计数据,即在推理过程中被激活的权重。这些被称为显著权重,通常占总权重的不到1%。为了提高准确性,显著权重在量化过程中会被跳过,保持为FP16数据类型。与此同时,其余的权重被量化为INT3或INT4,以减少LLM其余部分的内存需求。
6. 小结
量化是LLM领域的重要组成部分。通过压缩语言模型的大小,像QLoRA和GPTQ这样的量化技术有助于提高LLM的采用率。摆脱了全精度模型巨大内存需求的限制,组织、AI研究人员和个人都有更多的机会去尝试快速增长的各种LLM。
相关文章:

如何让大语言模型在规格普通的硬件上运行 - 量化技术
近年来,大型语言模型(LLMs)的能力有了飞跃式的发展,使其在越来越多的应用场景中更加友好和适用。然而,随着LLMs的智能和复杂度的增加,其参数数量,即权重和激活值的数量也在增加,这意…...

shell printf详解
默认的 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。 1. printf命令语法组成: printg format-string [arguments] 第一部分为格式化字符串,该字符串最好用引号括起来 第二部分为参数列表,例如字符串或变量值的列表,该列表需…...

【数据分析】用Python做事件抽取任务-快速上手方案
目录 方法一:使用OmniEvent库安装OmniEvent使用OmniEvent进行事件抽取OmniEvent优点缺点 方法二:使用大模型使用GPT网页版进行事件抽取事件类型列表 大模型优点缺点 总结 在自然语言处理(NLP)领域,事件抽取是一项关键任…...
B端系统门门清之:HRM,人力资源系统,公司发展的源动力。
人才是公司发展的源动力,针对公司复杂人力的管理就是HRM系统的核心功能,本文就带领大家详细认识一下HRM系统,分别从什么是HRM系统,作用、功能模块、颜值提升四个方面来阐述。欢迎大家点赞评论收藏转发。 一、什么是HRM系统 HRM系…...

tplink安防监控raw文件转码合成mp4的方法
Tplink(深圳普联)专业的网络设备生产商,属于安防监控市场的后来者。Tplink的安防产品恢复了很多,其嵌入式文件系统也一直迭代更新。今天要说的案例比较特殊,其不仅仅要求恢复,还要求能解析出音频并且要求画面和声音实现“同步”。…...
- 聚类)
每天一个数据分析题(三百八十三)- 聚类
关于忽略自相关可以带来什么问题描述错误的是? A. 均方误差可能严重低估误差项的方差 B. 可能导致高估检验统计量t值,致使本不显著的变量变得显著了 C. 参数估计值的最小方差无偏性不再成立 D. 参数估计值的最小方差无偏性仍成立 数据分析认证考试介…...
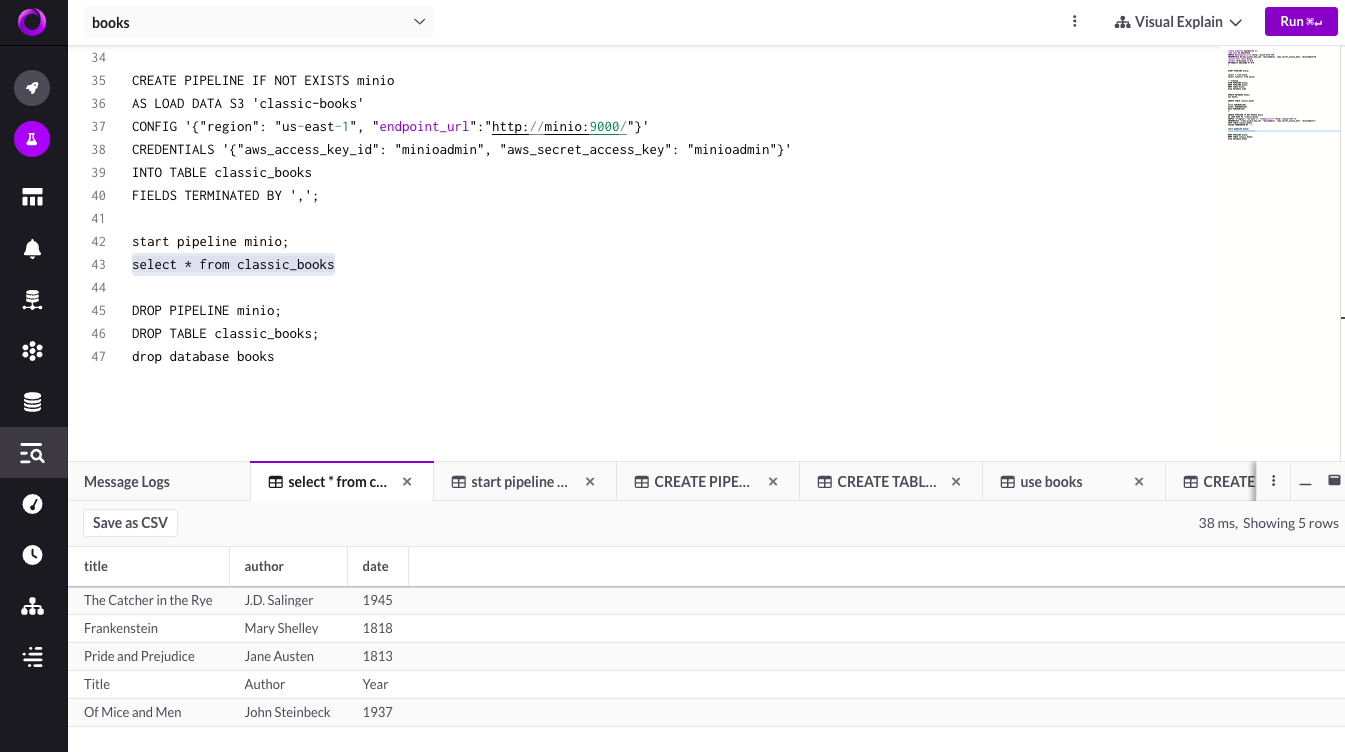
构建下一代数据解决方案:SingleStore、MinIO 和现代 Datalake 堆栈
SingleStore 是专为数据密集型工作负载而设计的云原生数据库。它是一个分布式关系 SQL 数据库管理系统,支持 ANSI SQL,并因其在数据引入、事务处理和查询处理方面的速度而受到认可。SingleStore 可以存储关系、JSON、图形和时间序列数据,以满…...

【经验分享】Ubuntu24.04安装微信
【经验分享】Ubuntu24.04安装微信(linux官方2024universal版) 文章如下,22.04和24.04微信兼容 【经验分享】Ubuntu22.04安装微信(linux官方2024universal版) 实测Ubuntu24.04LTS版本可以兼容。...
AXI学习笔记
文章目录 AXI口诀:AXI三种总线,三种接口,一个协议背景知识一、 AMBA:二、AXI2.1 通信协议与握手机制2.2 AXI协议特点2.3 三种AXI总线类型(AXI4、AXI4-lite、AXI4-stream)2.3.1 AXI通道(5通道&am…...
Spring boot 启动报:Do not use @ for indentation
一、使用maven插件动态切换配置时出现报错 二、配置文件及pom 2.1 配置文件结构 2.2 application.yml spring: # 根据环境读取配置文件(手动) # profiles: # active: dev# 根据环境读取配置文件(通过勾选maven插件)profiles…...

【数据结构】排序(下)
个人主页~ 排序(上) 栈和队列 排序 二、常见排序的实现8、快速排序的优化9、非递归快速排序(1)基本思想(2)代码实现(3)时间复杂度(4)空间复杂度 10、归并排序…...
基于Java+Swing贪吃蛇小游戏(含课程报告)
博主介绍: 大家好,本人精通Java、Python、C#、C、C编程语言,同时也熟练掌握微信小程序、Php和Android等技术,能够为大家提供全方位的技术支持和交流。 我有丰富的成品Java、Python、C#毕设项目经验,能够为学生提供各类…...

三角形法恢复空间点深度
三角形法恢复空间点深度 如下图,以图 I 1 I_1 I1为参考,图 I 2 I_2 I2的变换矩阵为 T T T。相机光心为 O 1 O_1 O1和 O 2 O_2 O2。在图 I 1 I_1 I1中有特征点 p 1 p_1 p1,对应图 I 2 I_2 I2中有特征点 p 2 p_2 p2。理论上直…...

Linux 阻塞和非阻塞 IO 实验学习
Linux 阻塞和非阻塞 IO 实验学习 IO 指的是 Input/Output,也就是输入/输出,是应用程序对驱动设备的输入/输出操作。当应用程序对设备驱动进行操作的时候,如果不能获取到设备资源,那么阻塞式 IO 就会将应用程序对应的线程挂起&…...

JuiceFS 社区版 v1.2 发布,新增企业级权限管理、平滑升级功能
JuiceFS 社区版 v1.2 今天正式发布,这是自 2021 年开源以来的第三个大版本。v1.2 也是一个长期支持版本(LTS)。我们将持续维护 v1.2 以及 v1.1 这两个版本,v1.0 将停止更新。 JuiceFS 是为云环境设计的分布式文件系统,…...

虚拟3D沉浸式展会编辑平台降低了线上办展的门槛
在数字化浪潮的引领下,VR虚拟网上展会正逐渐成为企业展示品牌实力、吸引潜在客户的首选平台。我们与广交会携手走过三年多的时光,凭借优质的服务和丰富的经验,赢得了客户的广泛赞誉。 面对传统展会活动繁多、企业运营繁忙的挑战,许…...

泛微E9开发 查询页面添加按钮,完成特定功能
查询页面添加按钮,完成特定功能 1、关联知识(查询页面实现新增按钮)2、功能实现2.1. 点击按钮,输出选中的checkbox的值2.2. 点击按钮,打开一个自定义对话框 3、实现方法 1、关联知识(查询页面实现新增按钮&…...
初学51单片机之数字秒表
不同数据类型间的相互转换 在C语言中,不同数据类型之间是可以混合运算的。当表达式中的数据类型不一致时,首先转换为同一类型,然后再进行计算。C语言有两种方式实现类型转换。一是自动类型转换,另外一种是强制类型转换。 转换的主…...
SpringBoot整合justauth实现多种方式的第三方登陆
目录 0.准备工作 1.引入依赖 2.yml文件 3. Controller代码 4.效果 参考 0.准备工作 你需要获取三方登陆的client-id和client-secret 以github为例 申请地址:Sign in to GitHub GitHub 1.引入依赖 <?xml version"1.0" encoding"UTF-8&quo…...

【Java算法】滑动窗口
🔥个人主页: 中草药 🔥专栏:【算法工作坊】算法实战揭秘 👖一. 长度最小的子数组 题目链接:209.长度最小的子数组 算法原理 滑动窗口 滑动窗口算法常用于处理数组/字符串等序列问题,通过定义一…...

5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南
5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_…...
)
Midjourney Anthotype印相工作流全拆解(含v6.1专属--style raw+自定义光照映射公式)
更多请点击: https://intelliparadigm.com 第一章:Anthotype印相工艺的历史溯源与数字转译本质 Anthotype(植物感光印相)是一种诞生于1839年的前摄影术实践,由英国科学家Sir John Herschel首次系统记录。它利用植物汁…...

TTS-Backup:Tabletop Simulator数据备份与资源管理的技术解决方案
TTS-Backup:Tabletop Simulator数据备份与资源管理的技术解决方案 【免费下载链接】tts-backup Backup Tabletop Simulator saves and assets into comprehensive Zip files. 项目地址: https://gitcode.com/gh_mirrors/tt/tts-backup 在数字桌游时代&#x…...

口碑好的柜子定制服务商
在装修和商业展示领域,柜子定制的质量与风格直接影响着整体效果。今天,就来为大家揭开一家口碑超棒的柜子定制服务商——东莞市龙圣展柜装饰有限公司(以下简称龙圣展柜)的神秘面纱。一、丰富多样的产品服务,满足多元需…...

STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发?
STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发? 在嵌入式开发中,定时器中断是最基础也最常用的功能之一。然而,当开发者从标准库转向LL库(Low Layer Library)时,往往会遇到各种&quo…...

Windows触控板手势定制终极指南:3个技巧实现高效三指拖拽优化
Windows触控板手势定制终极指南:3个技巧实现高效三指拖拽优化 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFinger…...

免费LLM API集成实战:从选型到构建高可用AI服务
1. 项目概述:一个汇聚免费LLM API的宝藏仓库如果你正在开发一个需要AI对话、文本生成或代码补全功能的应用,但又被高昂的API调用费用或复杂的申请流程劝退,那么你很可能需要这个项目。Clovenhoofed-loadingarea139/awesome-free-llm-apis是一…...

AI代理协作平台Run402:基于看板与微支付的自动化任务管理
1. 项目概述:一个面向AI代理的协作与支付平台最近在开源社区里,我注意到一个挺有意思的项目,叫musfoner/run402。乍一看,它的描述非常简洁,甚至可以说有些“神秘”,只有“yonathan estudio”几个字。但结合…...

CANN/ops-nn自适应平均池化3D反向计算
aclnnAdaptiveAvgPool3dBackward 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 📄 查看源码 产品是否支持Ascend 950PR/Ascend 950DT√…...

Godot 4写实水体渲染:从PBR原理到波浪、菲涅尔与焦散实战
1. 项目概述:从像素到波光,在Godot中实现写实水体渲染如果你正在用Godot引擎开发一款开放世界游戏、模拟经营类作品,或者只是想为你的独立游戏场景增添一抹灵动的色彩,那么一个逼真的水体系统往往是提升沉浸感的关键。然而&#x…...