Flink 定时加载数据源
一、简介
flink 自定义实时数据源使用流处理比较简单,比如 Kafka、MQ 等,如果使用 MySQL、redis 批处理也比较简单
如果需要定时加载数据作为 flink 数据源使用流处理,比如定时从 mysql 或者 redis 获取一批数据,传入 flink 做处理,如下简单实现
二、pom.xml 文件
注意 flink 好多包从 1.15.0 开始不需要指定 Scala 版本,内部自带
下面 pom 文件有 flink 两个版本 1.16.0 和 1.12.7(Scala:2.12)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.ye</groupId><artifactId>flink-study</artifactId><version>0.1</version><packaging>jar</packaging><name>Flink Quickstart Job</name><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.16.0</flink.version><!--<flink.version>1.12.7</flink.version>--><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target><log4j.version>2.17.1</log4j.version></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency>
<!--<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency>
--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!-- Add connector dependencies here. They must be in the default scope (compile). --><!-- Example:<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency>--><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.ye.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration></plugin></plugins></pluginManagement></build>
</project>三、自定义数据源
使用 Timer 定时任务(当然也可以使用线程池 Executors)自定义数据源,每过五秒随机生成一串字符串
public class TimerSinkRich extends RichSourceFunction<String> {private ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();private boolean flag = true;private Timer timer;private TimerTask timerTask;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);timerTask = new TimerTask() {@Overridepublic void run() {// 可以在这块获取 MySQL、redis 等连接并查询数据Random random = new Random();StringBuilder str = new StringBuilder();for (int i = 0; i < 10; i++) {char ranLowLetter = (char) ((random.nextInt(26) + 97));str.append(ranLowLetter);}queue.add(str.toString());}};timer = new Timer();// 延时和执行周期参数可以通过构造方法传递timer.schedule(timerTask,1000,5000);}@Overridepublic void run(SourceContext<String> ctx) throws Exception {while (flag){if(queue.size()>0){ctx.collect(queue.remove());}}}@Overridepublic void cancel() {if(null!=timer) timer.cancel();if(null!=timerTask) timerTask.cancel();// 撤销任务时,flink 默认 30 s(不同 flink 版本可能不同)尝试关闭数据源,关闭失败 TaskManager 不能释放 slot,最终导致失败if(queue.size()<=0) flag = false;}
}
四、flink 加载数据源并启动
public class TimerSinkStreamJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();executionEnvironment.setParallelism(1);DataStreamSource<String> streamSource = executionEnvironment.addSource(new TimerSinkRich());streamSource.print();executionEnvironment.execute("TimerSinkStreamJob 定时任务打印数据");}
}
本地测试成功
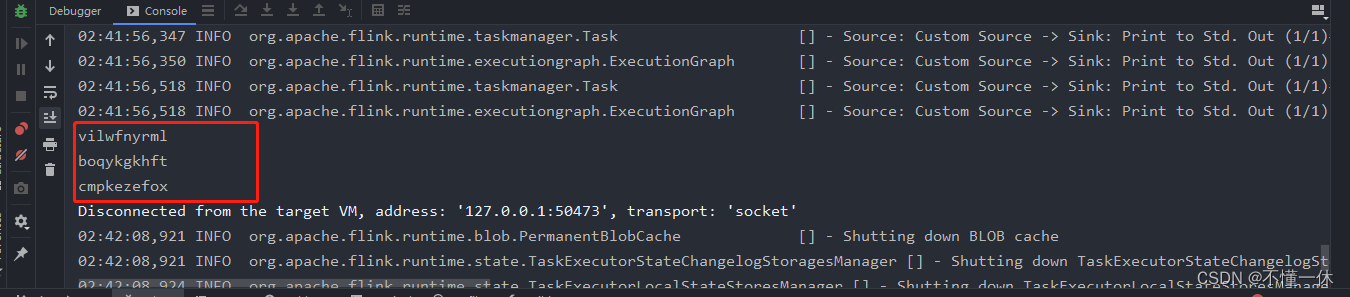
五、上传 flink 集群
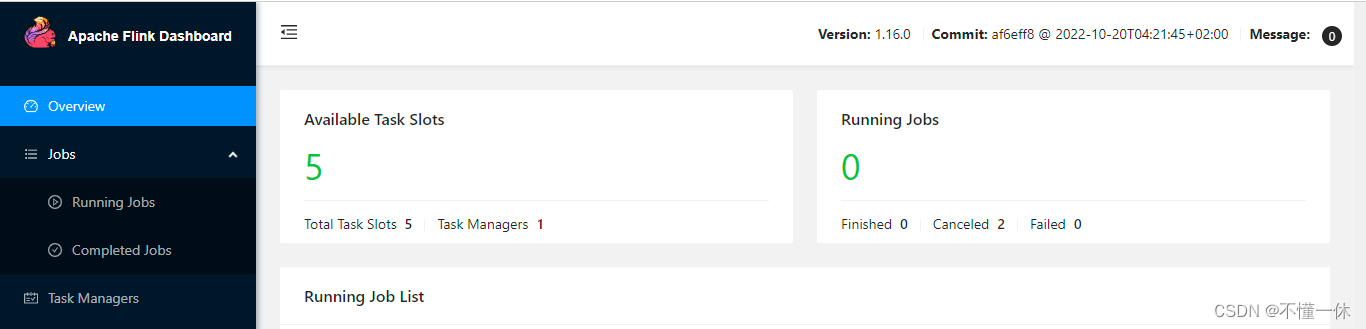
1、flink 1.16.0
启动成功
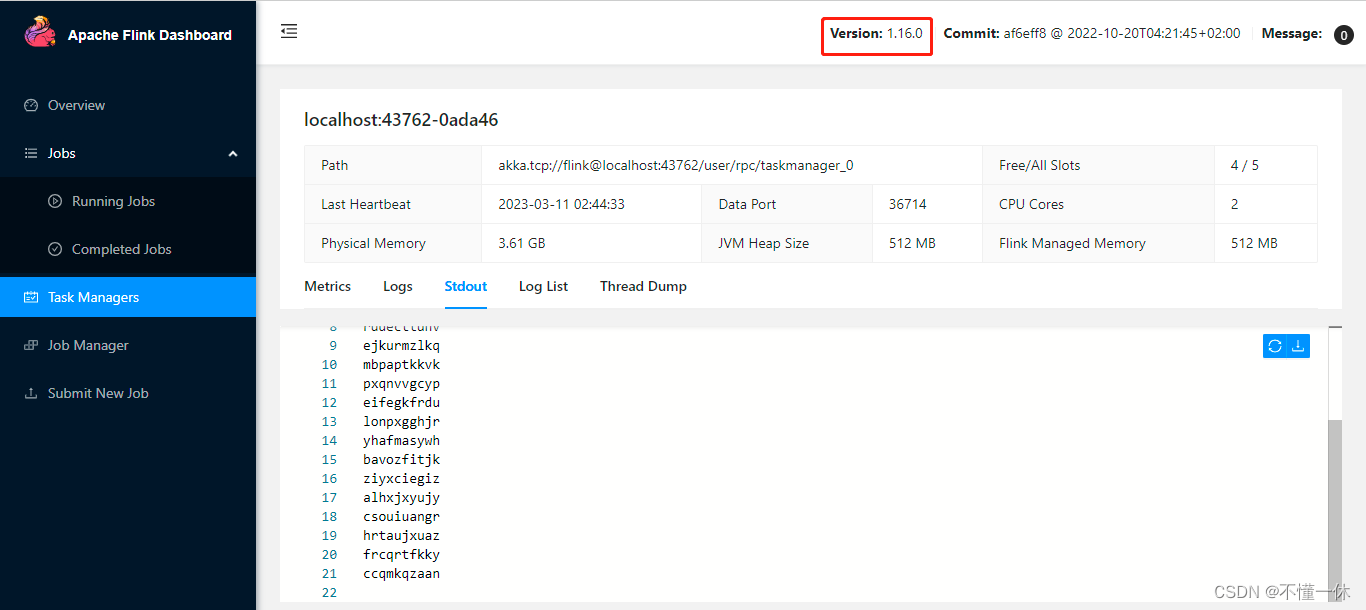
撤销任务成功
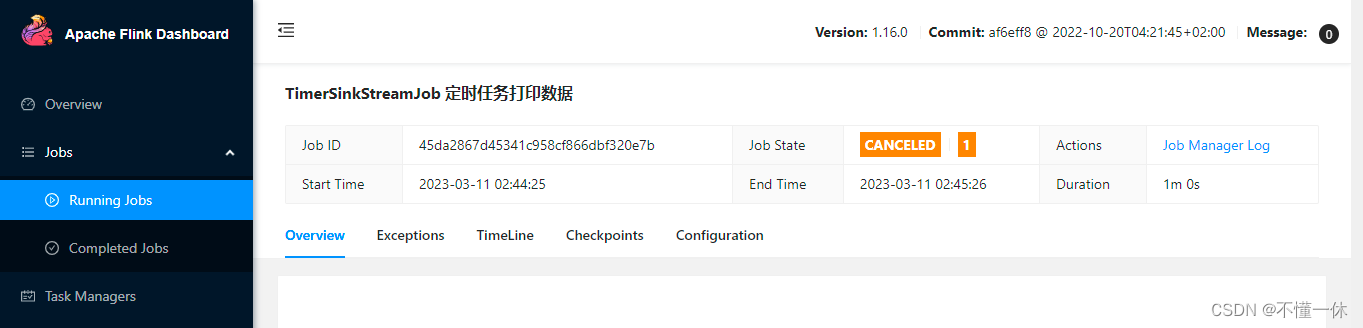
solt 也成功释放
2、flink 1.12.7
启动成功
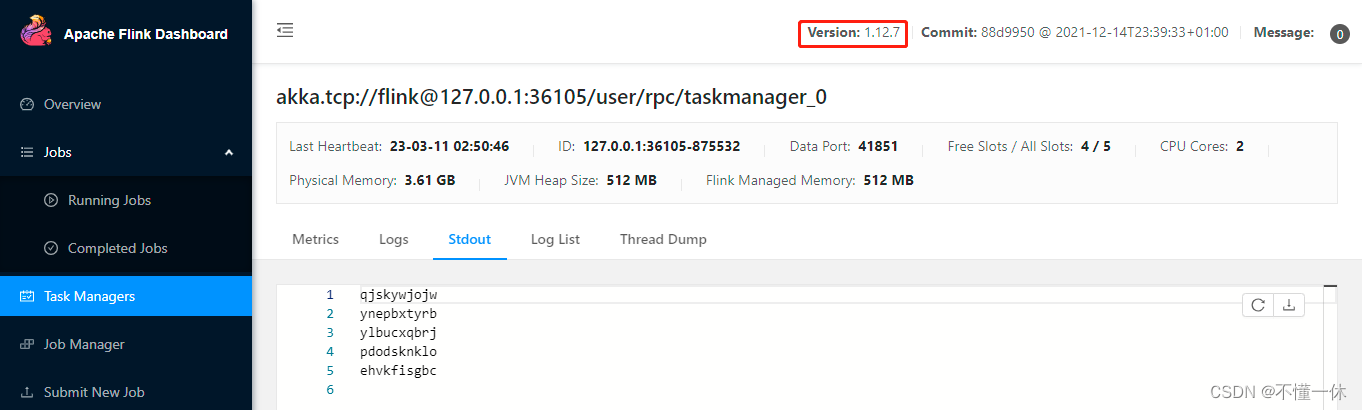
撤销任务当然也没问题,同样能正常释放 slot

当然你也可以不要 open() 方法
public class DiySinkRich extends RichSourceFunction<String> {private TimerTask timerTask;private Timer timer;private boolean flag = true;private ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();@Overridepublic void run(SourceFunction.SourceContext<String> ctx) throws Exception {timerTask = new TimerTask() {@Overridepublic void run() {Random random = new Random();StringBuilder str = new StringBuilder();for (int i = 0; i < 10; i++) {char ranLowLetter = (char) ((random.nextInt(26) + 97));str.append(ranLowLetter);}queue.add(str.toString());}};timer = new Timer();timer.schedule(timerTask, 1000, 5000);while (flag) {if (queue.size() > 0) {ctx.collect(queue.remove());}}}@Overridepublic void cancel() {if (timer != null) timer.cancel();if (timerTask != null) timerTask.cancel();if (queue.size() == 0) flag = false;}
}
以上就是 flink 定时加载数据源的简单实例
相关文章:
Flink 定时加载数据源
一、简介 flink 自定义实时数据源使用流处理比较简单,比如 Kafka、MQ 等,如果使用 MySQL、redis 批处理也比较简单 如果需要定时加载数据作为 flink 数据源使用流处理,比如定时从 mysql 或者 redis 获取一批数据,传入 flink 做处…...

ChatGPT、人工智能、人类和一些酒桌闲聊
© 2023 Conmajia Initiated 10th March, 2023 昨天跟某化学家喝酒,期间提到了 ChatGPT。他的评价是:这鬼东西大量输出毫无意义、错漏百出甚至是虚假的信息,“in a confident accent”。例如某次 GPT 针对“描述某某记者”这一问题&#…...

WebRTC开源库内部调用abort函数引发程序发生闪退问题的排查
目录 1、初始问题描述 2、使用Process Explorer工具查看到处理音视频业务的rtcmpdll.dll模块没有加载起来 3、使用Dependency Walker工具查看到rtcmpdll.dll依赖的库有问题 4、更新库之后Debug程序启动时就发生异常,程序闪退 5、VS调试时看不到有效的函数调用堆…...

Golang并发编程
Golang并发编程 文章目录Golang并发编程1. 协程2. channel2.1 channel的创建2.2 使用waitGroup实现同步3. 并发编程3.1 并发编程之runtime包3.2 mutex互斥锁3.3 channel遍历3.3.1 for if遍历3.3.2 for range3.4 select switch3.5 Timer3.5.1 time.NewTimer()3.5.2 Stop、reset…...
windows+Anaconda环境下安装BERT成功安装方法及问题汇总
前言 在WindowsAnaconda环境下安装BERT,遇到各种问题,几经磨难,最终成功。接下来,先介绍成功的安装方法,再附上遇到的问题汇总 成功的安装方法 1、创建虚拟环境 注意:必须加上python3.7.12以创建环境&a…...
git - 简易指南
git - 简易指南 创建新仓库 创建新文件夹,打开,然后执行 git init 以创建新的 git 仓库。 检出仓库 执行如下命令以创建一个本地仓库的克隆版本: git clone /path/to/repository 如果是远端服务器上的仓库,你的命令会是这个样…...

[论文笔记]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
引言 我们知道Transformer很好用,但它设定的最长长度是512。像一篇文章超过512个token是很容易的,那么我们在处理这种长文本的情况下也想利用Transformer的强大表达能力需要怎么做呢? 本文就带来一种处理长文本的Transformer变种——Transf…...
| 机考必刷)
华为OD机试题 - 找目标字符串(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:找目标字符串题目输入输出示例一输入输出说明Code解题思路版权说…...

C++面向对象编程之六:重载操作符(<<,>>,+,+=,==,!=,=)
重载操作符C允许我们重新定义操作符(例如:,-,*,/)等,使其对于我们自定义的类类型对象,也能像内置数据类型(例如:int,float,double&…...

JS_wangEditor富文本编辑器
官网:https://www.wangeditor.com/ 引入 CSS 定义样式 <link href"https://unpkg.com/wangeditor/editorlatest/dist/css/style.css" rel"stylesheet"> <style>#editor—wrapper {border: 1px solid #ccc;z-index: 100; /* 按需定…...

Django实践-06导出excel/pdf/echarts
文章目录Django实践-06导出excel/pdf/echartsDjango实践-06导出excel/pdf/echarts导出excel安装依赖库修改views.py添加excel导出函数修改urls.py添加excel/运行测试导出pdf安装依赖库修改views.py添加pdf导出函数修改urls.py添加pdf/生成前端统计图表修改views.py添加get_teac…...

java并发入门(一)共享模型—Synchronized、Wait/Notify、pack/unpack
一、共享模型—管程 1、共享存在的问题 1.1 共享变量案例 package com.yyds.juc.monitor;import lombok.extern.slf4j.Slf4j;Slf4j(topic "c.MTest1") public class MTest1 {static int counter 0;public static void main(String[] args) throws InterruptedEx…...

Ast2500增加用户自定义功能
备注:这里使用的AMI的开发环境MegaRAC进行AST2500软件开发,并非openlinux版本。1、添加上电后自动执行的任务在PDKAccess.c中列出了系统启动过程中的所有任务,若需要添加功能,在相应的任务中添加自定义线程。一般在两个任务里面添…...

用Python暴力求解德·梅齐里亚克的砝码问题
文章目录固定个数的砝码可称量重量砝码的组合方法40镑砝码的组合问 一个商人有一个40磅的砝码,由于跌落在地而碎成4块。后来,称得每块碎片的重量都是整磅数,而且可以用这4 块来称从1 至40 磅之间的任意整数磅的重物。问这4 块砝码片各重多少&…...

离散Hopfield神经网络的分类——高校科研能力评价
离散Hopfield网络离散Hopfield网络是一种经典的神经网络模型,它的基本原理是利用离散化的神经元和离散化的权值矩阵来实现模式识别和模式恢复的功能。它最初由美国物理学家John Hopfield在1982年提出,是一种单层的全连接神经网络,被广泛应用于…...
- Call逻辑分析和扩展机制)
Retrofit核心源码分析(三)- Call逻辑分析和扩展机制
在前面的两篇文章中,我们已经对 Retrofit 的注解解析、动态代理、网络请求和响应处理机制有了一定的了解。在这篇文章中,我们将深入分析 Retrofit 的 Call 逻辑,并介绍 Retrofit 的扩展机制。 一、Call 逻辑分析 Call 是 Retrofit 中最基本…...

源码分析spring如和对@Component注解进行BeanDefinition注册的
Spring ioc主要职责为依赖进行处理(依赖注入、依赖查找)、容器以及托管的(java bean、资源配置、事件)资源声明周期管理;在ioc容器启动对元信息进行读取(比如xml bean注解等)、事件管理、国际化等处理;首先…...
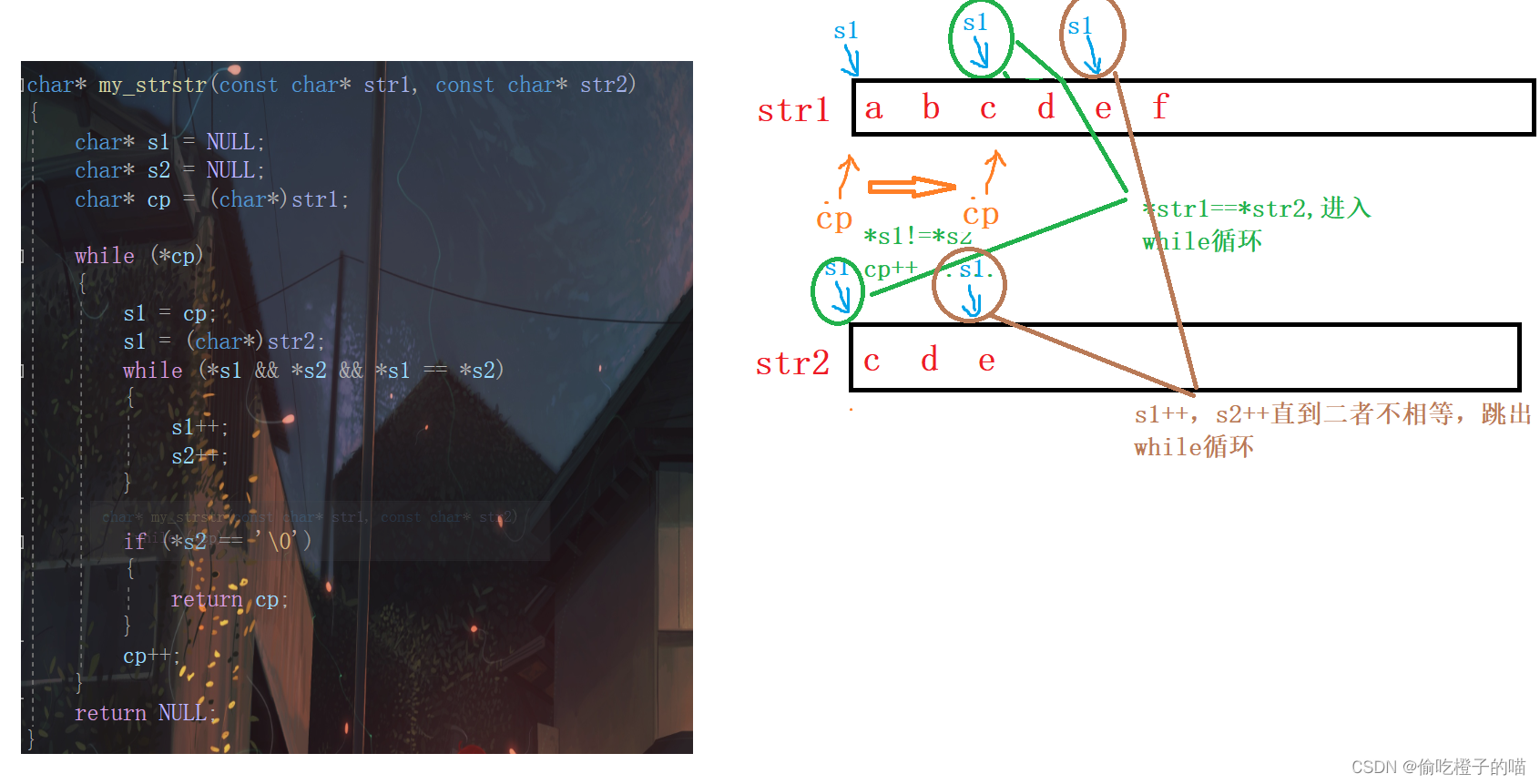
C语言--字符串函数1
目录前言strlenstrlen的模拟实现strcpystrcatstrcat的模拟实现strcmpstrcmp的模拟实现strncpystrncatstrncmpstrstrstrchr和strrchrstrstr的模拟实现前言 本章我们将重点介绍处理字符和字符串的库函数的使用和注意事项。 strlen 我们先来看一个我们最熟悉的求字符串长度的库…...
Webstorm使用、nginx启动、FinalShell使用
文章目录 主题设置FinalShellFinalShell nginx 启动历史命令Nginx页面发布配置Webstorm的一些常用快捷键代码生成字体大小修改Webstorm - gitCode 代码拉取webstorm 汉化webstorm导致CPU占用率高方法一 【忽略node_modules】方法二 【设置 - 代码编辑 - 快速预览文档 - 关闭】主…...

源码分析Spring @Configuration注解如何巧夺天空,偷梁换柱。
前言 回想起五年前的一次面试,面试官问Configuration注解和Component注解有什么区别?记得当时的回答是: 相同点:Configuration注解继承于Component注解,都可以用来通过ClassPathBeanDefinitionScanner装载Spring bean…...
)
数字孪生软件篇教程(从零入门到工业落地)
前言 在数字孪生行业中,硬件决定真假,软件决定颜值与逻辑。很多新手误区:把数字孪生当成3D建模、做炫酷大屏。 真正工业级软件架构:三维建模 + 后端服务 + 数据中台 + 可视化引擎 + 仿真逻辑。 本篇为配套硬件篇专属软件教程,保持一模一样排版结构、通俗易懂、零基础入…...

3步搞定安卓应用Windows安装:告别臃肿模拟器的终极解决方案
3步搞定安卓应用Windows安装:告别臃肿模拟器的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了那些占用大量系统资源、启动缓慢的…...

PortProxyGUI:Windows端口转发图形化管理工具终极指南
PortProxyGUI:Windows端口转发图形化管理工具终极指南 【免费下载链接】PortProxyGUI A manager of netsh interface portproxy which is to evaluate TCP/IP port redirect on windows. 项目地址: https://gitcode.com/gh_mirrors/po/PortProxyGUI 在Window…...

LDBlockShow终极指南:5步掌握高质量连锁不平衡热图绘制
LDBlockShow终极指南:5步掌握高质量连锁不平衡热图绘制 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirrors/ld/…...

如何免费使用GanttProject:开源项目管理软件的完整入门指南
如何免费使用GanttProject:开源项目管理软件的完整入门指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 你是否正在寻找一款功能强大且完全免费的项目管理工具?…...

ClawDrive:为AI智能体设计的语义文件管理与跨模态检索系统
1. 项目概述:ClawDrive,为AI智能体打造的“语义硬盘” 如果你和我一样,每天被海量的文档、图片、音频和视频文件淹没,传统的文件夹分类和文件名搜索早已力不从心。更头疼的是,当你尝试让AI助手(比如Claude…...

如何用wxlivespy实现微信视频号直播数据实时抓取与分析
如何用wxlivespy实现微信视频号直播数据实时抓取与分析 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy wxlivespy是一款专业级的微信视频号直播间弹幕信息抓取工具,能够实时捕获弹幕、…...

mmdetection环境搭建避坑指南:从CUDA版本、pip源到Gitee镜像的全流程优化
MMDetection环境搭建全流程优化:从版本匹配到镜像加速的实战指南 在计算机视觉领域,OpenMMLab系列工具包已经成为许多研究者和开发者的首选。作为其中的核心检测库,MMDetection凭借其模块化设计和丰富的预训练模型,极大地简化了目…...

Get-cookies.txt-LOCALLY:浏览器Cookie本地导出终极指南
Get-cookies.txt-LOCALLY:浏览器Cookie本地导出终极指南 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在数字时代,浏览器…...

GPT-5.5推理效率优化背后的5个核心技术突破
概要GPT-5.5是OpenAI于2026年4月23日发布的旗舰模型,代号"Spud"。最近在库拉(c.877ai.cn)AI工具聚合平台上做了集中测试,GPT-5.5的推理效率提升不是单一优化的结果,而是五个核心技术方向同时突破。从数据看&…...