肾虚学习实验第T1周:实现mnist手写数字识别
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**目录
一、前言
作为一名研究牲,一定要了解pytorch和tensorflow。下面我来介绍一下。
TensorFlow和PyTorch是两个流行的开源机器学习库,它们都支持深度学习模型的开发和训练。尽管它们在很多方面有相似之处,但它们之间也存在一些关键的区别:1. **设计哲学**:- **TensorFlow**:最初由Google Brain团队开发,TensorFlow的设计更倾向于生产环境,强调模型的可扩展性和部署的灵活性。TensorFlow提供了一个静态计算图,这意味着在执行之前,整个计算图需要被定义和优化。- **PyTorch**:由Facebook的AI研究团队开发,PyTorch的设计更倾向于研究和快速原型开发,强调动态性和易用性。PyTorch使用动态计算图,允许在运行时修改图。2. **易用性**:- **TensorFlow**:对于初学者来说可能稍微复杂一些,因为它需要用户理解计算图的概念。- **PyTorch**:提供了一个更接近于NumPy的API,使得从NumPy过渡到深度学习更加自然。3. **灵活性**:- **TensorFlow**:由于其静态图的特性,可能在某些需要高度灵活性的场景下不如PyTorch灵活。- **PyTorch**:动态图使得在运行时修改模型变得更加容易,这对于研究和快速迭代非常有用。4. **性能**:- 两者在性能上都非常出色,但TensorFlow在某些情况下可能因为其优化的静态图而提供更好的性能。5. **社区和生态系统**:- **TensorFlow**:由于其较早的发布和Google的支持,拥有一个庞大的社区和丰富的库。- **PyTorch**:虽然起步较晚,但社区发展迅速,特别是在研究领域。6. **部署**:- **TensorFlow**:提供了TensorFlow Serving等工具,使得模型部署更加方便。- **PyTorch**:模型部署可能需要更多的工作,但PyTorch与ONNX(Open Neural Network Exchange)的集成正在改善这一状况。7. **多GPU支持**:- **TensorFlow**:从设计之初就考虑了多GPU支持。- **PyTorch**:虽然也支持多GPU,但在某些情况下可能需要更多的手动配置。8. **API一致性**:- **TensorFlow**:API在不同版本之间可能发生变化,这可能会影响向后兼容性。- **PyTorch**:API相对稳定,变化较少。选择哪个框架往往取决于个人偏好、项目需求和团队熟悉度。两者都是强大的工具,能够支持复杂的深度学习任务。二、我的环境

三、前期准备
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")2.导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()3.归一化
归一化与标准化![]() https://blog.csdn.net/qq_38251616/article/details/126048261
https://blog.csdn.net/qq_38251616/article/details/126048261

# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
"""4.可视化图片
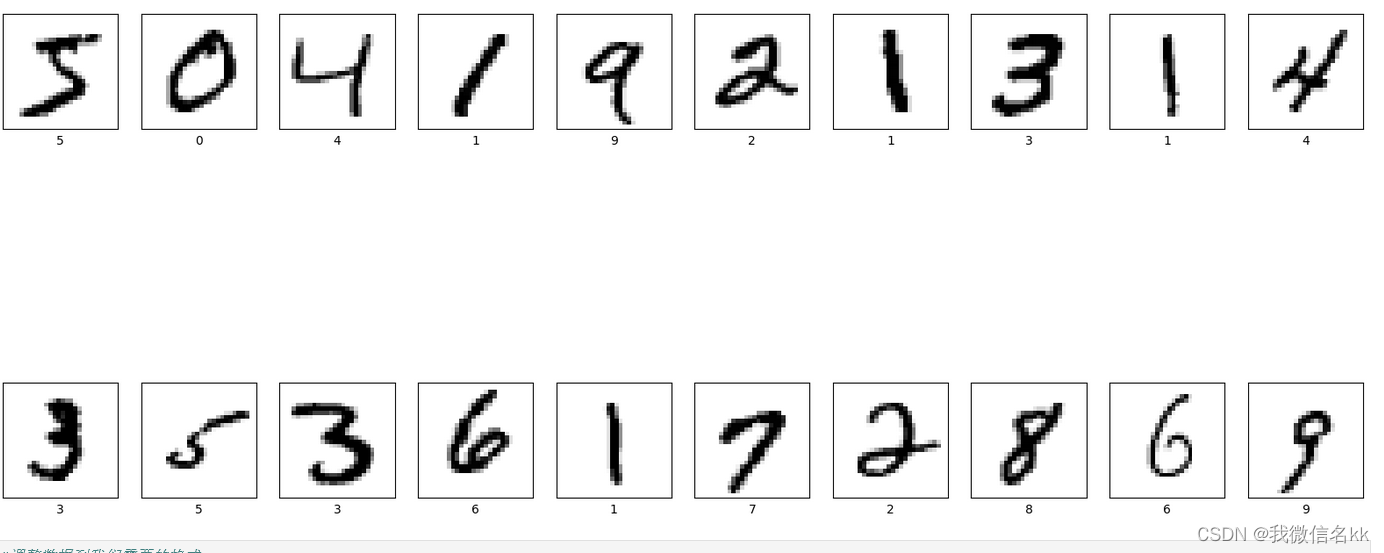
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):# 将整个figure分成5行10列,绘制第i+1个子图。plt.subplot(2,10,i+1)# 设置不显示x轴刻度plt.xticks([])# 设置不显示y轴刻度plt.yticks([])# 设置不显示子图网格线plt.grid(False)# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表plt.imshow(train_images[i], cmap=plt.cm.binary)# 设置x轴标签显示为图片对应的数字plt.xlabel(train_labels[i])
# 显示图片
plt.show()5.调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
"""

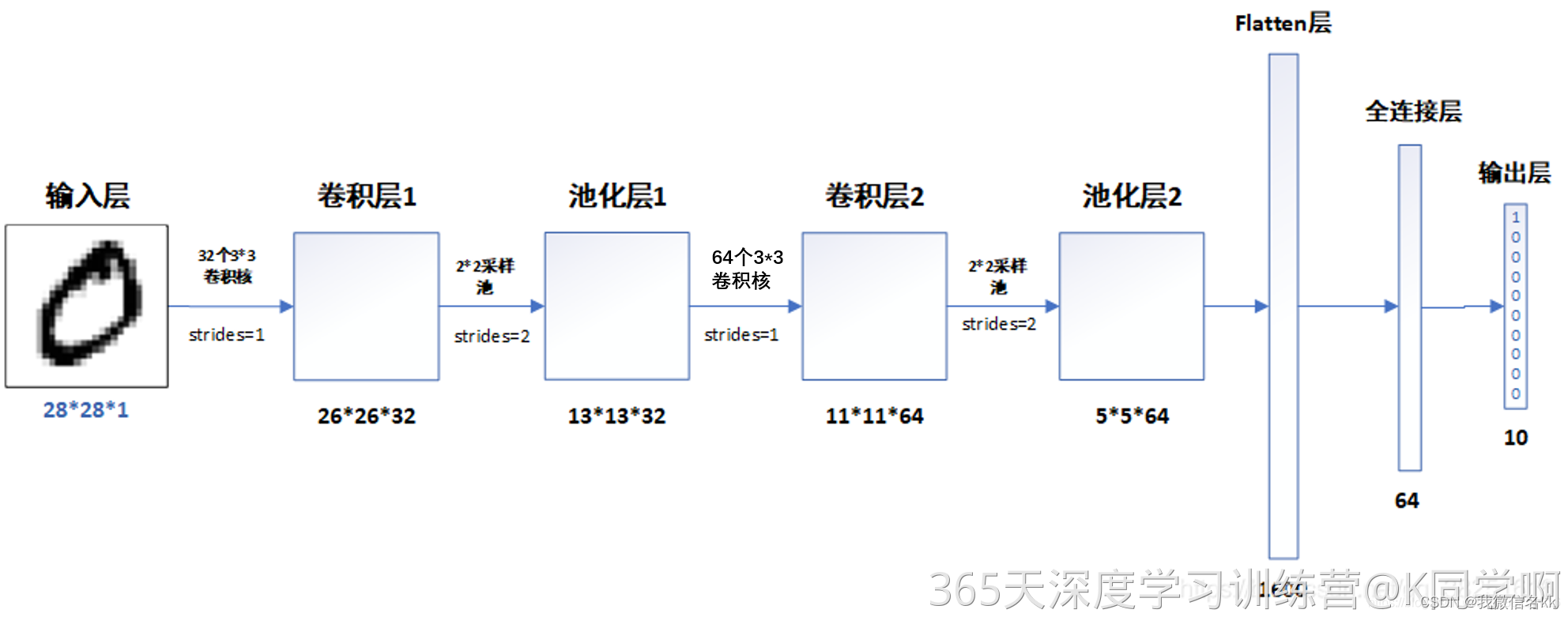
四、构建简单的cnn网络
网络结构图
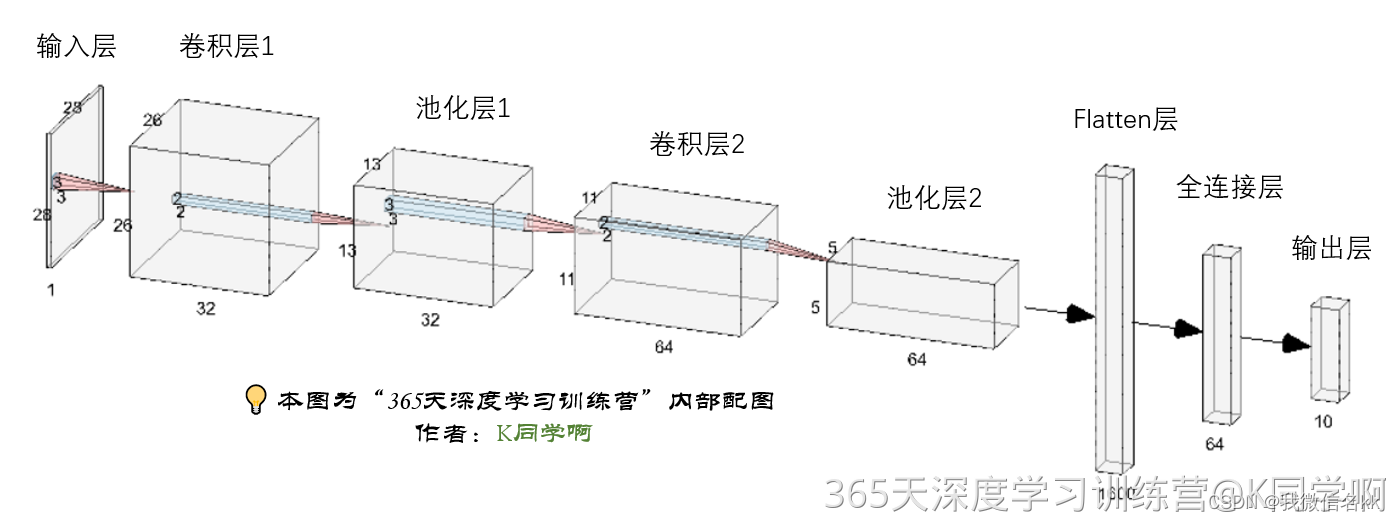
(1)第一步构建cnn网络模型
(2)第二步:加载并打印模型
(3)第三步: 输出结果编辑
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),#池化层1,2*2采样layers.MaxPooling2D((2, 2)), # 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数layers.Conv2D(64, (3, 3), activation='relu'), #池化层2,2*2采样layers.MaxPooling2D((2, 2)), layers.Flatten(), #Flatten层,连接卷积层与全连接层layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()
五.编译模型
"""
这里设置优化器、损失函数以及metrics
这三者具体介绍可参考我的博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(# 设置优化器为Adam优化器optimizer='adam',# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),# 设置性能指标列表,将在模型训练时监控列表中的指标metrics=['accuracy'])# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
六、训练模型
"""
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
关于model.fit()函数的具体介绍可参考我的博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
history = model.fit(# 输入训练集图片train_images, # 输入训练集标签train_labels, # 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。epochs=10, # 设置验证集validation_data=(test_images, test_labels))
七预测
通过下面的网络结构我们可以简单理解为,输入一张图片,将会得到一组数,这组代表这张图片上的数字为0~9中每一个数字的几率(并非概率),out数字越大可能性越大,仅此而已
在这一步中部分同学会因为 matplotlib 版本原因报 Invalid shape (28, 28, 1) for image data 的错误提示,可以将代码改为 plt.imshow(test_images[1].reshape(28,28)) 。
plt.imshow(test_images[1]) 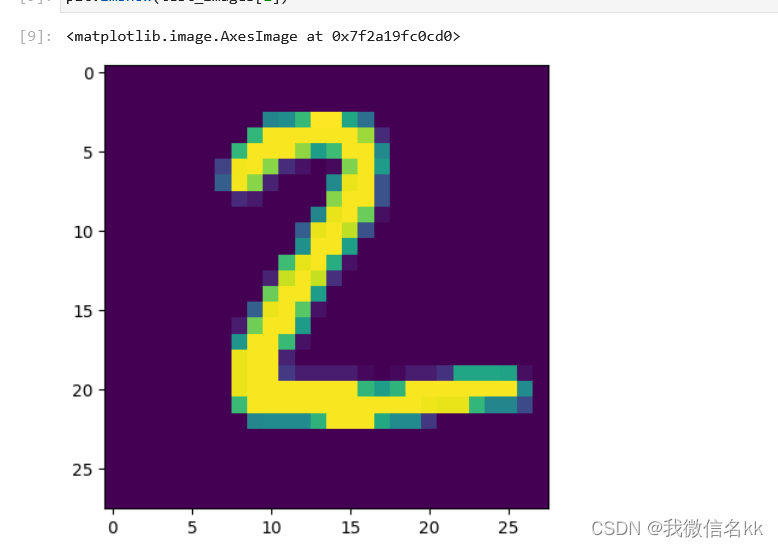
#输出测试集中第一张图片的预测结果
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果

八、知识点详解
本文使用的是最简单的CNN模型- -LeNet-5,如果是第一次接触深度学习的话,可以先试着把代码跑通,然后再尝试去理解其中的代码。
1. MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges(下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是28*28,数据集样本如下:

如果我们把每一张图片中的像素转换为向量,则得到长度为28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。

2. 神经网络程序说明
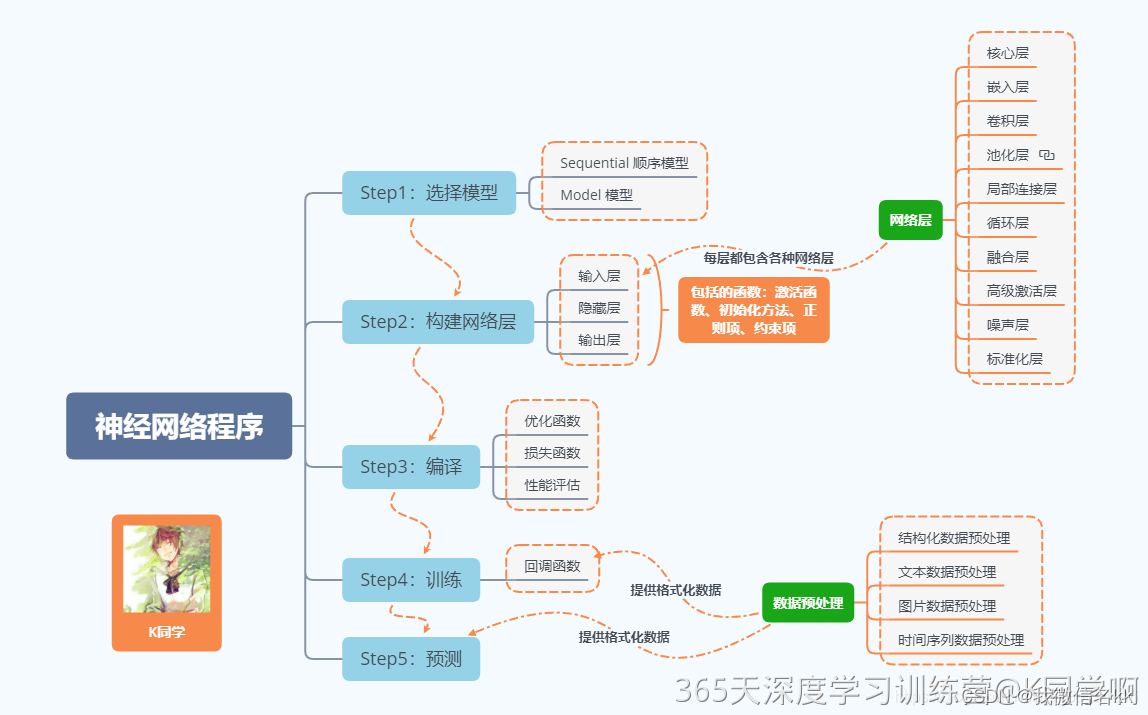
3.模型结构说明
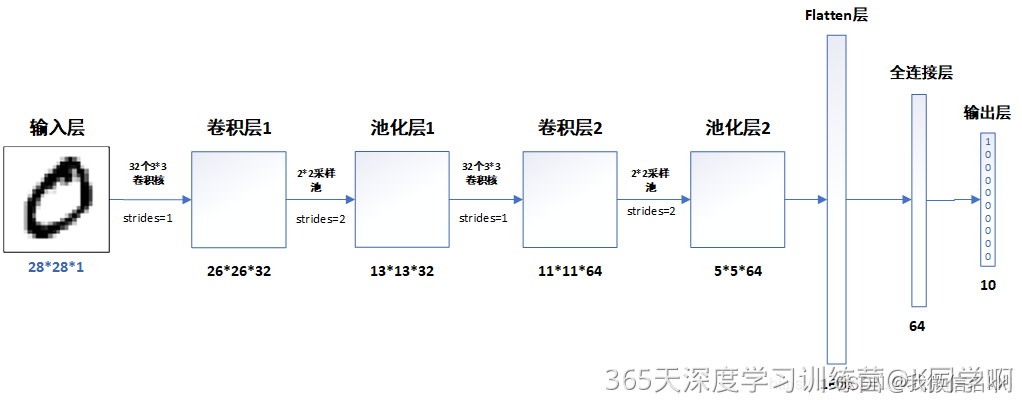
各层的作用
- 输入层:用于将数据输入到训练网络
- 卷积层:使用卷积核提取图片特征
- 池化层:进行下采样,用更高层的抽象表示图像特征
- Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡
- 全连接层:起到“特征提取器”的作用
- 输出层:输出结果
八、总结
本周的任务中,实现了手写数字识别的任务,第一点就是准备数据集,本次数据集是可以直接下载的不用导入,构建模型,使用的是最基础的- -LeNet-5,卷积层提取特征,池化层降采样,重复两遍之后来个flatten层拉伸一下,便于全连接层输入,全连接层得出分类结果。优化器损失函数直接放在# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准#方法里面了,最后直接训练即可。整体比较顺利。
相关文章:
肾虚学习实验第T1周:实现mnist手写数字识别
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客** >- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)** 目录 一、前言 作为一名研究牲࿰…...

Python | Leetcode Python题解之第162题寻找峰值
题目: 题解: class Solution:def findPeakElement(self, nums: List[int]) -> int:n len(nums)# 辅助函数,输入下标 i,返回 nums[i] 的值# 方便处理 nums[-1] 以及 nums[n] 的边界情况def get(i: int) -> int:if i -1 or…...
定个小目标之刷LeetCode热题(26)
这道题属于一道简单题,可以使用辅助栈法,代码如下所示 class Solution {public boolean isValid(String s) {if (s.isEmpty())return false;// 创建字符栈Stack<Character> stack new Stack<Character>();// 遍历字符串数组for (char c : …...
网络爬虫设置代理服务器
目录 1.获取代理 IP 2.设置代理 IP 3. 检测代理 IP 的有效性 4. 处理异常 如果希望在网络爬虫程序中使用代理服务器,就需要为网络爬虫程序设置代理服务器。 设置代理服务器一般分为获取代理 IP 、设置代理 IP 两步。接下来,分…...

3、matlab单目相机标定原理、流程及实验
1、单目相机标定流程及步骤 单目相机标定是通过确定相机的内部和外部参数,以便准确地在图像空间和物体空间之间建立映射关系。下面是单目相机标定的流程及步骤: 搜集标定图像:使用不同角度、距离和姿态拍摄一组标定图像,并确保标…...

【gdb 如何生成并查看core dump】
生成core dump 使用ulimit命令来设置core dump文件的大小。 ulimit -c unlimitedcore dump位置 如果程序崩溃,系统会生成一个名为core的文件。可以通过以下命令查看core文件位置, cat /proc/sys/kernel/core_pattern查看core dump gdb /path/to/you…...

极简短视频查看、删除应用
本地短视频服务器 背景:我的NAS中存放了很多短视频,多到很多没看过,于是写了这个程序来随机查看并删除短视频 运行: 安装依赖后运行main.py 直接使用docker: docker pull realwang/short_video docker run -d -p 3000:…...

【秋招刷题打卡】Day01-自定义排序
Day01-自定排序 前言 给大家推荐一下咱们的 陪伴打卡小屋 知识星球啦,详细介绍 >笔试刷题陪伴小屋-打卡赢价值丰厚奖励 < ⏰小屋将在每日上午发放打卡题目,包括: 一道该算法的模版题 (主要以力扣,牛客,acwin…...

API低代码平台介绍6-数据库记录删除功能
数据库记录删除功能 在前续文章中我们介绍了如何插入和修改数据库记录,本篇文章会沿用之前的测试数据,介绍如何使用ADI平台定义一个删除目标数据库记录的接口,包括 单主键单表删除、复合主键单表删除、多表删除(整合前两者&#x…...

计算机基础之:硬件系统的性能评估标准
服务器时钟的性能通常涉及多个方面,主要包括准确性、稳定性、以及对系统性能的影响。以下是一些关键指标和衡量方法: 准确性: 时间偏移:测量服务器时钟与一个可靠时间源(如GPS时间、原子钟或NTP服务器)之间…...
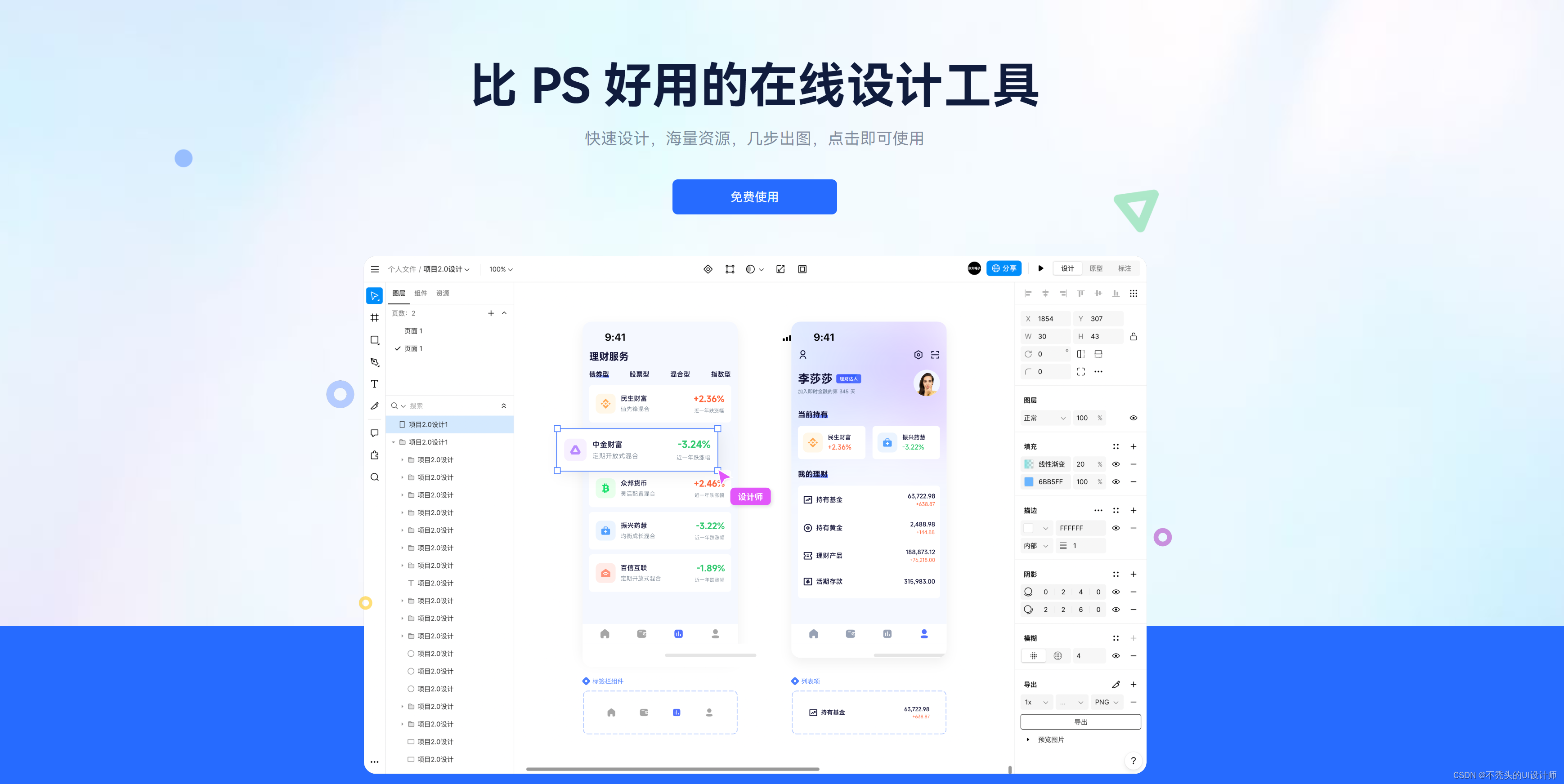
高互动UI设计揭秘:动画效果如何提升用户体验
动画,由于其酷的视觉冲击,往往会产生极好的用户体验。UI设计中的动态效果可以使用户界面看起来更酷,特别是界面的功能动画,是UX设计的重要组成部分,不容忽视。为什么UI设计的动态效果如此重要?接下来&#…...

探索Java异常处理的奥秘:源码解析与高级实践
1. 引言 在Java编程的广阔天地中,异常处理是确保程序健壮性、稳定性和可维护性的重要基石。对于Java工程师而言,深入理解Java异常处理的机制,并能够在实践中灵活运用,是迈向卓越的重要一步。 2. 基本概念 在Java中,异常(Exception)是程序执行期间出现的不正常或错误情况…...

深入了解python函数与函数内存使用
函数的定义 函数作为代码复用的基本单元,可以帮助我们组织代码、减少重复、提高可读性和可维护性。 在 Python 中,函数本质上是对象,可以赋值给变量、存储在数据结构中、作为参数传递和返回。 函数与内存 函数的加载和调用过程中ÿ…...

Java面试----MySQL面试题
1.索引有哪些优缺点? MySQL索引作为一种提升数据库查询效率的重要机制,具有以下主要优点和缺点: 优点: 提高查询速度: 索引能够显著加速数据的检索过程,类似于书籍的目录,让数据库引擎能够快速…...

python从入门到精通2:缩进
在Python中,缩进(Indentation)是一个非常重要的语法元素,它用于表示代码块的结构。与其他许多编程语言使用大括号 {} 来定义代码块不同,Python使用缩进来确定代码块的开始和结束。这种简洁的语法使得Python代码更加清晰…...
了解CDN:提升网络性能和安全性的利器
在当今的数字时代,网站性能和安全性是每一个网站管理员必须关注的核心问题。内容分发网络(CDN,Content Delivery Network)作为解决这一问题的重要工具,逐渐成为主流。本文将详细介绍CDN的定义、作用及其工作原理&#…...

ChatGPT的工作原理
ChatGPT的工作原理可以详细分为以下几个步骤,下面将结合相关信息进行清晰、详细的介绍: 数据收集: ChatGPT首先会从大量的文本数据中收集信息,这些数据可能包括网页、新闻、书籍等多样化的来源。它还会特别关注和分析网络上的热点…...

基于DPU的云原生裸金属服务快速部署及存储解决方案
1. 背景介绍 1.1. 业务背景 在云原生技术迅速发展的当下,容器技术因其轻量级、可移植性和快速部署的特性而成为应用部署的主流选择,但裸金属服务器依然有其独特的价值和应用场景,是云原生架构中不可或缺的一部分。 裸金属服务器是一种高级…...

论文学习_Large Language Models Based Fuzzing Techniques: A Survey
论文名称发表时间发表期刊期刊等级研究单位Large Language Models Based Fuzzing Techniques: A Survey 2024年arXiv-悉尼大学 0.摘要 研究背景在软件发挥举足轻重作用的现代社会,软件安全和漏洞分析对软件开发至关重要,模糊测试作为一种高效的软件测试方法,并广泛应用于各个…...
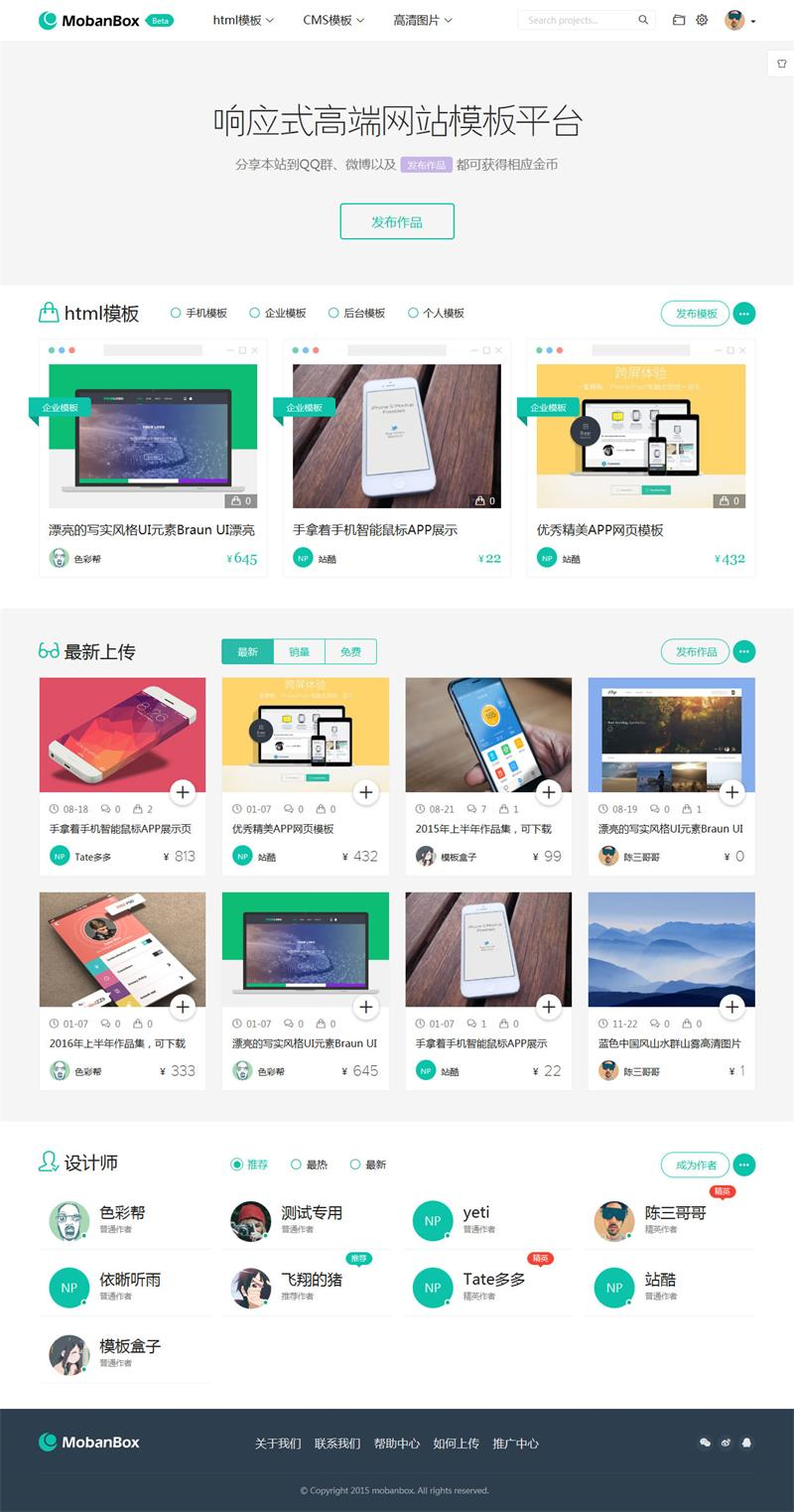
响应式德米拉数字内容交易系统素材下载站模板
★模板说明★ 该数字交易系统设计非常完美,两种响应式模式,可打开边栏模式和盒子模式;八种网站颜色,四种风格颜色可供用户自行选择,还可在网站选背景图片;完美的分成系统、充值功能、个人中心等等都以html…...

终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁
终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS激活锁绕过是许多iPhone用户在设备所有权验证遇到困难时的迫切需求。AppleRa1n…...
)
Python开发被内网卡脖子?5分钟用Docker搭个Pypiserver救急(含避坑指南)
Python内网开发救星:Docker化Pypiserver极速搭建指南 当你在客户现场调试代码时,突然发现内网环境无法连接PyPI官方源;当你在保密项目部署时,发现所有外网访问都被严格限制——这种"被卡脖子"的困境,相信不少…...

Synopsys工具filter命令:从数据筛选到高效IC设计的实战指南
1. 项目概述:从“大海捞针”到“精准定位”的思维转变在IC设计领域,Synopsys的工具链是我们日常工作中不可或缺的伙伴。无论是DC、ICC2、PT还是VCS,我们每天都要与海量的数据、复杂的网表和成千上万的命令打交道。很多时候,我们面…...

利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案 当你的 AIGC 应用从内部测试走向面向真实用户的生产环境时,服…...

Defender Control:Windows Defender 终极控制指南 - 如何永久禁用Windows安全防护
Defender Control:Windows Defender 终极控制指南 - 如何永久禁用Windows安全防护 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...

安全聚合技术:原理、实现与多场景应用
1. 安全聚合技术概述安全聚合(Secure Aggregation)是一种多方安全计算技术,它允许多个互不信任的参与方在不泄露各自私有数据的前提下,共同计算出一个聚合结果。这项技术的核心价值在于解决了数据隐私与数据共享之间的矛盾&#x…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

AI驱动工作流自动化:从原理到实践,构建智能效率引擎
1. 项目概述:当AI遇上工作流,一场效率革命正在发生最近在GitHub上看到一个名为“WorkflowAI/WorkflowAI”的项目,这个名字本身就充满了想象空间。作为一个长期与各种自动化工具和效率方法论打交道的人,我立刻意识到,这…...