C++的入门
C++的关键字
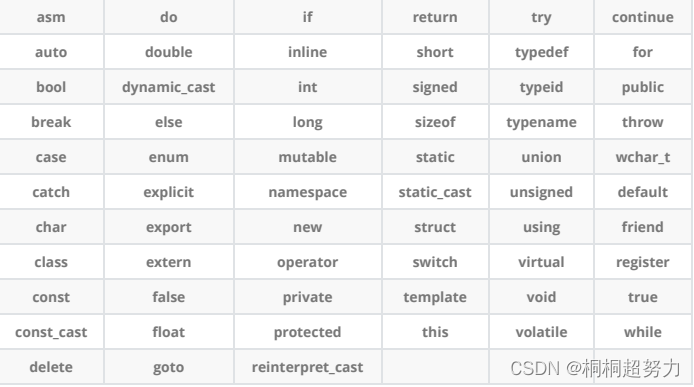
C++总计63个关键字,C语言32个关键字
命名空间
我们C++的就是建立在C语言之上,但是是高于C语言的,将C语言的不足都弥补上了,而命名空间就是为了弥补C语言的不足。
看一下这个例子。在C语言中会报错
#include<stdio.h>
#include<stdlib.h>int rand = 10;int main()
{printf("%d ", rand);return 0;
}

原因就是在我们
#include<stdlib.h>中,定义了rand,但是我们自己也定义了一个全局变量rand,这样就重定义了,C语言无法解决这个问题。
所以我们这是C++,为了解决这个问题,就引用了命名空间的概念。
我们在C语言中,我们们接触的域一共有两个,
一个是全局域,一个是局部域。他们的使用,和生命周期不一样。
而在这两个域中,我们可以声明同一个名字的变量,这是可以的。
但是我们想在局部作用域中,找命名相同的全局域的东西可以吗?
答案是可以的,这是就要用到我们的域作用符::,前面的空格就表示全局域。
看下面代码
#include<stdio.h>
#include<stdlib.h>int a = 10;void f1()
{int a = 0;printf("%d\n", a);printf("%d\n", ::a);
}int main()
{f1();return 0;
}
- 命名空间定义了什们?
- 命名空间域,只影响使用,不影响生命周期。
这时就需要一个关键字—namespace 命名空间怎么用? - 当我们的命名存在冲突的时候,将各自的内容用
namespace定义的域包括起来(这时我们自己定义这个域名),当我们要找的时候就用就域操作符::,找到我们的域名,就可以找到我们的命名冲突的东西。请看下列例子。
namespace List
{struct Node{struct QNode* next;struct QNode* prev;int val;};
}namespace Queue
{struct Node{struct QNode* next;int val;};}int main()
{//f1();struct Queue::Node node1;struct List::Node node2;return 0;
}
注意我们的命名空间,可以嵌套。
使用方法
1.指定命名空间访问。
每次使用的时候,我们都使用域作用符表明他的域
namespace Queue
{struct Node{struct QNode* next;int val;};struct QueueNode{struct Node* head;struct Node* tail;};void QueueInit(struct QueueNode* q){}void QueuePush(struct QueueNode* q,int x){}
}int main()
{struct Queue::QueueNode q;Queue::QueueInit(&q);Queue::QueuePush(&q,1);Queue::QueuePush(&q,2);
}
2.全局展开(一般情况,不建议全局展开)
我们用一次展开一次,太繁琐了,我们怎样可以简单一点呢?
就是用全局展开,
代码为using namespace + 域名
namespace Queue
{struct Node{struct QNode* next;int val;};struct QueueNode{struct Node* head;struct Node* tail;};void QueueInit(struct QueueNode* q){}void QueuePush(struct QueueNode* q,int x){}
}using namespace Queue;int main()
{struct QueueNode q;QueueInit(&q);QueuePush(&q,1);QueuePush(&q,2);
}所以我们写C++,代码的时候,
我们要加上一句using namespace std,将我们库文件的东西全局展开。
但是这种方法不太好,将我们好不容易建立的库,就有展开了,相当于没有命名空间了
所以我们以后进公司写项目,禁止这样写代码,但是我们在前期学习阶段,我们是可以这样的,因为这样很方便。
3.部分展开
就是将常用的展开。具体看下面的例子
#include<iostream>//常用的展开
using std::cout;
using std::endl;int main()
{cout << "1111" << endl;cout << "1111" << endl;cout << "1111" << endl;cout << "1111" << endl;int i = 0;std::cin >> i;
}cin和cout的理解
其实就是流,输入流,和输出流。
我们可以简单的认为,
cout相当于printf
cin相当于scanf
- 他们的优势
- 自动识别类型。
不用想我们的printf,scanf需要指定类型,%d,%f,但是我这个就不用,他自动识别类型。
#include<iostream>
using namespace std;int main()
{cout << "hello world" << endl;cout << "hello world" << '\n';int n;double* a = (double*)malloc(sizeof(double) * n);if (a == NULL){perror("malloc fail");exit(-1);}cin >> n;for (int i = 0; i < n; i++){cin >> a[i];}for (int i = 0; i < n; i++){cout << a[i] << endl;}
}

缺省参数
也是为了弥补c语言的缺陷。
这是通过函数使用的,在c语言中,当我们的函数有参数的时候,我们在用这个函数的时候,我们必须传这个参数。
而缺省参数的作用,就是我们在函数传参的时候,可以不用传参数。在我们不传参数的时候,就会把我们的默认参数传上。
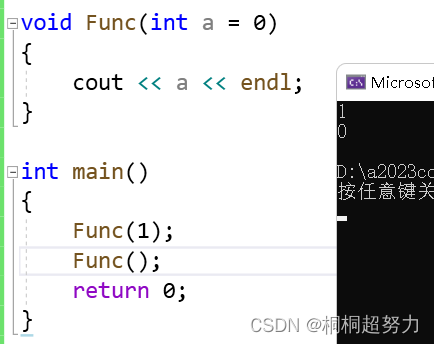
void Func(int a = 0)
{cout << a << endl;
}int main()
{Func(1);Func();return 0;
}
多个缺省参数
//全缺省
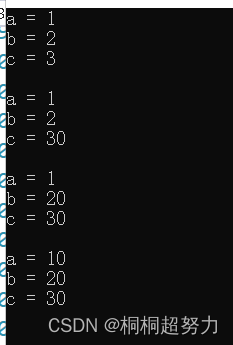
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;cout << endl;}int main()
{Func(1, 2, 3);Func(1, 2);Func(1);Func();return 0;
}
注意:不可以跳着传,使用缺省值,必须从右往左连续使用
下列用法不可以,这是规定没有为什们
Fun( ,2, );
Fun( , , 3);
半缺省
注意:必须从右往左连续缺省,不能跳跃缺省
//这样是可以的
void Func(int a, int b = 10, int c = 20) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; }
int main()
{Func(1, 2, 3);Func(1, 2);Func(1);return 0;
}
//这样是错误的,完全不可以
void Func(int a = 10, int b , int c = 20) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; }
- 注意
- 缺省参数不能在函数声明和定义中同时出现。
(推荐在声明的时候给我们的缺省参数)
如果生命与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该 用那个缺省值。
void Func(int a = 10); void Func(int a = 20) {}
函数重载
其实这也是为了解决c语言的缺陷,当一个函数同名的时候,我们就会重定义。
可能你会想,为什们要函数重载,函数本来就不能同名呀。
那你大错特错了,我们看完下面这个例子就知道了。
- 函数重载的定义
- 函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
函数返回值不同,不能构成函数重载。
是因为我们调用的时候可以不接受返回值,但是和没有返回值的函数无法区分,所以才不可以。
参数类型不同
// 1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}
int main()
{Add(1, 2);Add(1.1, 2.2);return 0;
}
参数个数不同
// 2、参数个数不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}
参数顺序不同
// 3、参数类型顺序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
编译器怎么分辨这些相同名字的函数呢
- 实际项目通常是由多个头文件和多个源文件构成,我们知道,【当前a.cpp中调用了b.cpp中定义的Add函数时】,编译后链接前,a.o的目标
文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢? - 所以链接阶段就是专门处理这种问题,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。
- 那么链接时,面对Add函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的 函数名修饰规则。
- 由于Windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们看g++演示了这个修饰后的名字。
- 通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度 +函数名+类型首字母】。
引用
- 什们是引用?(就是取别名)
- 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
比如:你有大名和小名,但那都是你,而引用就相当于这个。 引用怎么写? - 就是类型后面加一个&。
要区别赋值和引用。

那我们用一下
&,写一下我们的交换函数,就不用再传指针了。
//输出型参数
//形参的改变要影响实参。
void Swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}int main()
{int i = 10;int j = 20;Swap(i, j);printf("i=%d\n", i);printf("j=%d\n", j);return 0;
}
引用特征
- 引用必须在定义的时候初始化。
- 一个变量可以有多个引用
引用做返回值
我们先看一个场景,看完下面这个场景,我问一个问题,
- 在函数的返回值中我们是将函数中的
- 答案是否定的,我们
n是一个局部变量,他的生命周期就是在函数中,一但出了函数,那么它就会被销毁。
那么有的同学就会想:他是怎么传出来的呢?
其实编译器会将我们的n拷贝一个临时变量(临时变量具有常性),然后用这个临时变量将我们的n传给我们的ret。
n返回了吗?同时我们想优化一下他,我们也是不可以的,我们没有办法优化,但是我们看第二个例子
int count()
{int n = 0;n++;return n;
}
int main()
{int ret = count();return 0;
}
第二个例子不太一样,我们的
n存放在静态区,当函数被销毁的时候我们的n还在,但是这是有的同学会问,那么它传返回值是直接用n传吗?
答案并不是,编译器并不能分辨他们是哪一种,只会进行他的操作,跟上面一样还是产生一个n的临时拷贝,用的这个临时拷贝传个ret。
- 怎么优化?
- 我们想要优化一下这个,怎么优化?我们学习了引用,就是产生一个别名,我们可以通过改变别名来改变这个东西。
因为我们这里的n并不会被销毁,如果我们在返回的时候用引用。
这时我们还会像上面的操作一样产生一个临时变量,但是这个临时变量就不是我们的临时拷贝而是我们n的一个别名,我们如果想改变n,我们就可以通过改变返回值改变我们的n
int count()
{static int n = 0;n++;return n;
}
int main()
{int ret = count();return 0;
}
这就是引用返回。
int& count()
{static int n = 0;n++;return n;
}
int main()
{int ret = count();return 0;
}
什们场景下可以使用引用返回?
: 大家可能想到的是我们的静态变量,全局变量。结构体。
其实这些东西用一句话来说就是出了函数作用域,不被销毁的变量就可以。
引用返回的作用
通过上面的介绍我们知道了什们是引用返回,但是我们有这个有什么作用?我们什们情况下会用到这个。
那就看看下面这个例子。
#include<assert.h>
#define N 10typedef struct Array
{int a[N];int size;
}AY;//因为这个结构体在我们函数销毁完,我们还在所以可以用引用返回
int& PosAY(AY& ay, int i)
{assert(i < N);return ay.a[i];
}
int main()
{AY ay;//修改返回值for (int i = 0; i < N; i++){PosAY(ay, i) = i * 10;}//打印出来验证for (int i = 0; i < N; i++){cout << PosAY(ay, i) << " ";}return 0;
}
- 作用一
- 减少拷贝。
我们如果不用引用返回,那么我们在返回的时候我们要创建一个临时变量,将我们需要传的数据拷贝给临时变量。而我们的引用返回,直接将这个临时变量当作他的别名。 作用二 - 调用者可以修改返回对象
既然临时变量已经是我们要传的数据的别名,那么我们就可以修改返回对象来修改我们的数据。
下面我们在看一个例子
int& Add(int a, int b)
{int c = a + b;return c;
}
int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;cout << "Add(1, 2) is :" << ret << endl;return 0;
}
运行结果:
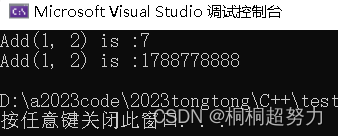
这是一个错误的程序,我们这个函数,在我们出去了这个函数,函数就会被销毁,而我们c是一个局部变量,也就说明c在出来函数也被销毁。
但是我们在传返回值的时候我们传的是引用返回,我们传的是别名,这时ret就是别名,但是已经销毁了,我们的别名就已经没有意义。
有的同学就问,那我们第一次是7呢,是因为在vs编译器下,函数销毁并没有清理空间,我们访问可以找到。但是第二次已经处理了,所以我们就是随机值了。
常引用
我们先看例子。
int main()
{int a = 1;int& b = a;const int c = 2;//错误//int& d = c;
}
我们的指针和引用,在进行赋值和初始化,权限可以缩小,但是权限不能放大。
就是我们上面对于c来说,c被const修饰,是一个不可修改的变量。
但是呢我们用d引用c,尽然可以让d修改,进而改变c,这显然是不合法的。这时我们就能理解为什们权限不能放大。但是权限可以平移。
解决方法,就是在引用的时候也变成被
const修饰的引用,让他变得不可修改。const int& d = c;
因为临时变量具有常性,大家看一下下面这个例子
int count()
{static int n = 0;n++;return n;
}
int main()
{int& ret = count();return 0;
}
上面这个代码大家千万不要以为这样可以,我们通过上面的讲解,并不是直接将我们的n返回,而是将我们的n拷贝给我们的临时变量。将其引用给ret涉及到权限的放大,这时万万不行的,所以我们的可以将ret也设置为常性。
const int& ret = count();这样就可以了。
我们再看一个代码。
int main()
{int i = 10;//错误//double& dd = i;const double& d = i;return 0;
}
为什们第一个不可以,但是第二个可以呢?
原因就是我们在进行类型转换的时候,我们会产生一个临时变量,(为什们会产生临时变量呢?我们再传的时候并不是将i直接传给d,并不能改变i,而是产生一个临时变量,将他改变,然后再赋值在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。给d。)又因为我们的临时变量具有常性,我们就必须用const修饰。
引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何 一个同类型实体
- 没有
NULL引用,但有NULL指针 - 在
sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节) - 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
内联函数
C++用const和枚举替换宏常量
C++用inline去替代宏函数
- 宏缺点
- 1.不能调试
2.没有类型安全的检查
3.有些常见很复杂,很容易函数,不容易掌握。 宏优点 -
- 增强代码的复用性。
- 提高性能。
内联函数既包括了宏的优点,也几乎去除了宏的缺点。
看一个例子感受内联函数的使用。
其实就是还是正常写我们的函数,再其前面加上inline,在编译阶段,会用函数体替换函数调用。
inline int Add(int x, int y)
{int z = x + y;return z;
}int main()
{int ret = Add(1, 2);cout << ret << endl;return 0;
}
内联函数的特型
1. inline是一种以空间换时间(空间指可执行程序)的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运 行效率。
2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建 议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
auto关键字
- 简化代码,自动识别类型。具体看下面代码
auto的作用int main()
{int a = 0;auto b = a;auto c = &a;//typeid能看他是什们类型cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;
}
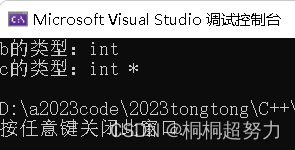
auto b = a;auto c = &a;//其实下面这个跟上面这个没有区别//就是将限定死d是指针auto* d = &a;auto& f = a;
auto在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译 器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{auto a = 1, b = 2;auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
auto不能推导的场景
- auto不能作为函数的参数

- auto不能直接用来声明数组

范围for–语法糖
先看例子
int main()
{int a[] = { 1,2,3,4,5,5 };//我们平常遍历一边数组,我们用的就是for循环for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){cout << a[i] << " ";}cout << endl;//那我们用语法糖//其实就是自己自动依次取数组中数据赋值给n对象,自动判定结束//for(int n : a)for (auto n : a){n *= 2;cout << n << " ";}cout << endl;
}
范围for只是自动依次取数组中数据赋值给n对象,自动判定结束
并不会改变数组的内容,他只是赋值。
如果想要改变数组的内容,我们就用引用,问题就可以很好的解决。
在这里插入代码片
指针空值nullptr
在C语言中,NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何 种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦
比如下面的代码,
结果是这样的
void f(int)
{cout<<"f(int)"<<endl;
}
void f(int*)
{cout<<"f(int*)"<<endl;
}
int main()
{f(0);f(NULL);f((int*)NULL); return 0;
}
所以C++使用一个关键字
nullptr来解决这个麻烦
- 注意
-
- 在使用
nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的.
- 在使用
-
- 在C++11中,
sizeof(nullptr)与sizeof((void*)0)所占的字节数相同。
- 在C++11中,
-
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用
nullptr。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用
相关文章:

C++的入门
C的关键字 C总计63个关键字,C语言32个关键字 命名空间 我们C的就是建立在C语言之上,但是是高于C语言的,将C语言的不足都弥补上了,而命名空间就是为了弥补C语言的不足。 看一下这个例子。在C语言中会报错 #include<stdio.h>…...

数据的存储
类型的意义:使用这个类型开辟内存空间的大小(大小决定了使用范围)如何看待内存空间视角类型的基本归类整型家族浮点数家族构造类型指针类型空类型整型存储解构:整型在计算机中占用四个字节,整型分为无符号整型和有符号整型在计算机…...

Linux查看UTC时间
先了解一下几个时间概念。 GMT时间:Greenwich Mean Time,格林尼治平时,又称格林尼治平均时间或格林尼治标准时间。是指位于英国伦敦郊区的皇家格林尼治天文台的标准时间。 GMT时间存在较大误差,因此不再被作为标准时间使用。现在…...
SpringBoot修改启动图标(详细步骤)
目录 一、介绍 二、操作步骤 三、介绍Java学习(题外话) 四、关于基础知识 一、介绍 修改图标就是在资源加载目录(resources)下放一个banner.txt文件。这样运行加载的时候就会扫描到这个文件,然后启动的时候就会显…...

【每日一题Day143】面试题 17.05. 字母与数字 | 前缀和+哈希表
面试题 17.05. 字母与数字 给定一个放有字母和数字的数组,找到最长的子数组,且包含的字母和数字的个数相同。 返回该子数组,若存在多个最长子数组,返回左端点下标值最小的子数组。若不存在这样的数组,返回一个空数组。…...
Go 内置运算符 if for switch
算数运算符fmt.Println("103", 103) //103 13 fmt.Println("10-3", 10-3) //10-3 7 fmt.Println("10*3", 10*3) //10*3 30 //除法注意:如果运算的数都是整数,那么除后,去掉小数部分,保留整数部分 f…...
)
C语言指针数组实际应用(嵌入式)
C语言指针数组详细学习 指针是C语言中非常重要的概念之一,它可以让我们直接访问内存中的数据。指针数组则是由多个指针组成的数组,每个指针都可以指向内存中的某个位置。以下是一些指针数组的实际代码应用: 字符串数组 char* names[] {&q…...

常用的Java注解详解
Java是一种常用的编程语言,而注解是Java语言中非常重要的一部分。在这篇文章中,我们将介绍一些常用的Java注解,以及它们的作用和使用方法。 Override override注解是用于表示一个方法是被覆盖的。在Java中,如果子类要覆盖父类的方…...
| 机考必刷)
华为OD机试题 - 第 K 个最小码值的字母(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:第 K 个最小码值的字母题目输入输出示例一输入输出说明示例一输…...
vscode环境配置(支持跳转,阅读linux kernel)
目录 1.卸载clangd插件 2.安装C插件 3. 搜索框内输入 “intell”,将 C_Cpp:Intelli Sense Engine 开关设置为 Default。 4.ubuntu安装global工具 5.vscode安装插件 6.验证是否生效 7.建立索引 1.卸载clangd插件 在插件管理中卸载clangd插件 2.安…...

zigbee学习笔记:IO操作
1、IAR新建工程 (1)Projetc→Create New Projetc→OK→选择位置,确定 (2)新建一个c文件,保存在路径中 (3)点击工程,右键→add→加入c文件 (4)…...
| 机考必刷)
华为OD机试题 - 最少数量线段覆盖(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:最少数量线段覆盖题目输入输出示例一输入输出说明Code解题思路版…...
python趣味编程-2048游戏
在上一期我们用Python实现了一个盒子追逐者的游戏,这一期我们继续使用Python实现一个简单的2048游戏,让我们开始今天的旅程吧~ 在 Python 免费源代码中使用 Tkinter 的简单 2048 游戏 使用 Tkinter 的简单 2048 游戏是一个用Python编程语言编码的桌面游…...

求解完全背包问题
题目描述实现一个算法求解完全背包问题。完全背包问题的介绍如下:已知一个容量为 totalweight 的背包,有不同重量不同价值的物品,问怎样在背包容量限制下达到利益最大化。完全背包问题的每个物品可以无限选用背包问题求解方法的介绍如下&…...

我们为什么使用docker 优点 作用
1. 我们为什么使用Docker? 当我们在工作中,一款产品从开发设计到上线运行,其中需要开发人员和运维工程师,开发人员负责代码编写,开发产品,运维工程师需要测试环境,产品部署。这之间就会有分歧。 就好比我…...

Python每日一练(20230311)
目录 1. 合并两个有序数组 2. 二叉树的右视图 3. 拼接最大数 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 1. 合并两个有序数组 给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为…...

202109-3 CCF 脉冲神经网络 66分题解 + 解题思路 + 解题过程
解题思路 根据题意,脉冲源的阈值大于随机数时,会向其所有出点发送脉冲 神经元当v>30时,会向其所有出点发送脉冲,unordered_map <int, vector > ne; //存储神经元/脉冲源的所有出点集合vector 所有脉冲会有一定的延迟&am…...

Aurora简介
Amazon Aurora是一种兼容MySQL和PostgreSQL的商用级别关系数据库,它既有商用数据库的性能和可用性(比如Oracle数据库),又具有开源数据库的成本效益(比如MySQL数据库)。 Aurora的速度可以达到MySQL数据库的…...

【python实操】用python写软件弹窗
文章目录前言组件label 与 多行文本复选框组件Radiobutton单选组件Frame框架组件labelframe标签框架列表框Listboxscrollbar滚动条组件scale刻度条组件spinbox组件Toplevel子窗体组件PanedWindow组件Menu下拉菜单弹出菜单总结针对组件前言 python学习之路任重而道远࿰…...

Ubuntu 常用操作
版本22.04 1、开启 root # 输入新密码 sudo passwd rootUbuntu以root账号登录桌面 默认情况是不允许用root帐号直接登录图形界面的。 Ubuntu 默认使用 GNOME,GNOME 使用 GDM 显示管理器。 为了允许以 root 身份登录到 GNOME,你需要对位于 /etc/…...

1.8.1 掌握Scala类与对象 - Scala类
本次实战通过两组对比鲜明的案例,带你快速入门Scala面向对象编程的核心。首先,通过创建User类,我们掌握了Scala普通类的定义方式,了解了如何使用private修饰符封装成员变量,以及如何通过new关键字实例化对象并调用其公…...
)
JY901陀螺仪数据解析实战:从原始字节到工程可用的姿态角(附完整代码)
JY901陀螺仪数据解析实战:从原始字节到工程可用的姿态角(附完整代码) 在嵌入式开发中,姿态感知是实现自动平衡、导航定位等功能的基石。JY901作为一款高性价比的9轴运动传感器,其输出的原始数据需要经过精确解析才能转…...

基于MCP协议构建智能Telegram助手:连接AI与外部服务的实践指南
1. 项目概述:一个连接AI与Telegram的智能桥梁如果你正在寻找一种方法,让你在Telegram上使用的AI助手(比如ChatGPT、Claude等)能够“活”起来,不仅能聊天,还能帮你查天气、看新闻、管理待办事项,…...

)
别再让FTP匿名登录成后门!手把手教你加固vsftpd服务(附CentOS 7实战配置)
企业级vsftpd安全加固实战指南:从匿名登录风险到全方位防护 FTP服务作为企业文件传输的经典解决方案,至今仍在许多组织的IT架构中扮演重要角色。然而,默认配置下的vsftpd服务往往隐藏着致命的安全隐患——匿名登录功能如同一扇未上锁的后门&a…...

node.js、node、nvm、npm、npx的关系
1、node.js Node.js:一个基于Chrome V8引擎的JavaScript运行环境。Node.js是一个开源的、跨平台的JavaScript运行环境,用于在服务器端运行JavaScript代码。它使得开发人员可以使用JavaScript来编写服务器端应用程序,从而简化了开发过程&#…...

边缘AI落地实战:从软件平台到NPU硬件的协同开发路径
1. 边缘AI的现实挑战与破局思路在2025年的阿姆斯特丹,一场汇聚了半导体巨头与初创公司的会议,清晰地勾勒出当前技术领域最炙手可热的战场:边缘人工智能。这不再是实验室里的概念演示,而是工程师们每天都要面对的真实难题——如何让…...

《心核驱动:基于本质定义的AI性格自进化架构》
前言:拒绝表面调参,直击AI性格本质当前市面上的AI性格定制,大多停留在“表层调参”阶段——试图通过调整温度、Top-p等概率参数来模拟情感,结果往往顾此失彼,要么机械生硬,要么逻辑崩塌。真正的智能性格&am…...

在Google Cloud上构建OpenAI兼容API网关:无缝对接Vertex AI模型
1. 项目概述:在Google Cloud上搭建你自己的OpenAI兼容API网关 如果你正在寻找一种方法,能够让你手头那些原本为OpenAI ChatGPT设计的应用,无缝对接上Google Cloud Vertex AI的强大模型,比如Gemini Pro、PaLM 2或者Codeyÿ…...

开源AI投资情报工具MacroClaw:从数据抓取到智能分析的完整实践
1. 项目概述:一个实时投资情报的AI智能体如果你和我一样,每天需要花大量时间在财经新闻、大宗商品价格和地缘政治动态上,试图从海量信息中提炼出对投资决策有用的信号,那你一定明白这有多耗时耗力。传统的资讯平台要么信息滞后&am…...