Elasticseach RestClient Api
Elasticsearch RestclientApi基础用法
查询
索引库
初始化
添加依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
创建链接
package com.hmall.item.es;import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;import static org.junit.jupiter.api.Assertions.*;/*** @ Author qwh* @ Date 2024/6/19 8:51*/class itemApplicationTest {private RestHighLevelClient client;//创建链接@BeforeEachvoid setup(){this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.70.145:9200")));}//测试链接@Testvoid testConnect(){System.out.println(client);}//关闭链接@AfterEachvoid destroy() throws IOException {this.client.close();}}
创建索引库
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
@Testvoid CreateIndex() throws IOException {//1CreateIndexRequest request = new CreateIndexRequest("items");//2request.source(MAPPING_TEMPLATE, XContentType.JSON);//3client.indices().create(request, RequestOptions.DEFAULT);}static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"stock\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"image\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sold\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"commentCount\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"isAD\":{\n" +" \"type\": \"boolean\"\n" +" },\n" +" \"updateTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";删除索引库
DELETE /索引库名
//删除索引库@Testvoid DeleteIndex() throws IOException {//创建请求对象DeleteIndexRequest items = new DeleteIndexRequest("items");//发送请求client.indices().delete(items,RequestOptions.DEFAULT);}
判断索引库是否存在
GET /索引库名
@Testvoid GetIndex() throws IOException {//发送请求GetIndexRequest items = new GetIndexRequest("items");boolean exists = client.indices().exists(items, RequestOptions.DEFAULT);System.out.println(exists ? "索引库已经存在" : "索引不存在");}
文档
新增文档
- 实体类
package com.hmall.item.domain.po;import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;import java.time.LocalDateTime;@Data
@ApiModel(description = "索引库实体")
public class ItemDoc{@ApiModelProperty("商品id")private String id;@ApiModelProperty("商品名称")private String name;@ApiModelProperty("价格(分)")private Integer price;@ApiModelProperty("商品图片")private String image;@ApiModelProperty("类目名称")private String category;@ApiModelProperty("品牌名称")private String brand;@ApiModelProperty("销量")private Integer sold;@ApiModelProperty("评论数")private Integer commentCount;@ApiModelProperty("是否是推广广告,true/false")private Boolean isAD;@ApiModelProperty("更新时间")private LocalDateTime updateTime;
}
- api语法
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
- java
- 1)创建Request对象,这里是IndexRequest,因为添加文档就是创建倒排索引的过程
- 2)准备请求参数,本例中就是Json文档
- 3)发送请求
package com.hmall.item.es;import cn.hutool.core.bean.BeanUtil;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hmall.common.utils.CollUtils;
import com.hmall.item.domain.po.Item;
import com.hmall.item.domain.po.ItemDoc;
import com.hmall.item.service.IItemService;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;/*** @ Author qwh* @ Date 2024/6/19 9:29*/
@Slf4j
@SpringBootTest(properties = "spring.profiles.active=local")
public class itemDocTest {private RestHighLevelClient client;@Autowiredprivate IItemService iItemService;@BeforeEachvoid setup(){client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.70.145:9200")));}@Test //添加文档void addDocument() throws IOException {//根据id查询item 添加到esItem item = iItemService.getById(100002644680L);//转换为文档类型ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);//将文档类型转换为jsonString doc = JSONUtil.toJsonStr(itemDoc);System.out.println(doc.toString());// 1.准备Request对象IndexRequest request = new IndexRequest("items").id(itemDoc.getId());// 2.准备Json文档request.source(doc, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);}@AfterEachvoid destroy() throws IOException {this.client.close();}
}查询文档
- api
GET /{索引库名}/_doc/{id}
- java
- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
@Testvoid GetDocument() throws IOException {GetRequest request = new GetRequest("items").id("100002644680");//发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);//获取相应结果String json = response.getSourceAsString();ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class);System.out.println("itemDoc"+itemDoc);}
删除文档
- api
DELETE /{索引库}/_doc/{id}
- java
- 1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
- 2)
准备参数,无参,直接省略 - 3)发送请求。因为是删除,所以是client.delete()方法
@Testvoid deleteDocument() throws IOException {//准备request 参数 索引库名 文档idDeleteRequest request = new DeleteRequest("items", "100002644680");client.delete(request,RequestOptions.DEFAULT);}
修改文档
- 全量修改:本质是先根据id删除,再新增
- 局部修改:修改文档中的指定字段值
- api 局部修改
POST /{索引库名}/_update/{id}
{"doc": {"字段名": "字段值","字段名": "字段值"}
}
- java
- 1)准备Request对象。这次是修改,所以是UpdateRequest
- 2)准备参数。也就是JSON文档,里面包含要修改的字段
- 3)更新文档。这里调用client.update()方法
//修改文档@Testvoid updateDocument() throws IOException {//requestUpdateRequest request = new UpdateRequest("items", "100002644680");//修改内容request.doc("price",99999,"commentCount",1);//发送请求client.update(request,RequestOptions.DEFAULT);}
批量导入
- java
- 创建Request,但这次用的是BulkRequest
- 准备请求参数
- 发送请求,这次要用到client.bulk()方法
//批量导入
@Test
void loadItemDocs() throws IOException {
//分页查询
int curPage = 1;
int size = 1000;
while (true){Page<Item> page = iItemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<>(curPage, size));//f非空校验List<Item> items = page.getRecords();if (CollUtils.isEmpty(items)) {return;}log.info("加载第{}页数据共{}条",curPage,items.size());//创建requestBulkRequest request = new BulkRequest("items");//准备参数for (Item item : items) {ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);request.add(new IndexRequest().id(itemDoc.getId()).source(JSONUtil.toJsonStr(itemDoc),XContentType.JSON));}//发送请求client.bulk(request,RequestOptions.DEFAULT);curPage++;
}
}
文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。
- XXX是Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk时需要)
- 发送请求。
- 调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
模糊查询
叶子查询
- 基本语法
GET /{索引库名}/_search
{"query": {"查询类型": {// .. 查询条件}}
}
- GET /{索引库名}/_search:其中的_search是固定路径,不能修改
GET /items/_search
{"query": {"match_all": {}}
}
package com.hmall.item.es;import cn.hutool.json.JSONUtil;
import com.hmall.common.utils.CollUtils;
import com.hmall.item.domain.po.ItemDoc;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;
import java.util.List;
import java.util.Map;/*** @ Author qwh* @ Date 2024/6/19 16:16*/
public class JavaAPITest {private RestHighLevelClient client;@BeforeEachvoid setup(){this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.70.145:9200")));}@Testvoid SearchMatchAll() throws IOException {//创建requestSearchRequest request = new SearchRequest("items");//请求参数request.source().query(QueryBuilders.matchAllQuery());//解析相应SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化并打印ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);System.out.println(item);}}@AfterEachvoid destroy() throws IOException {this.client.close();}
}

你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
全文检索
- 用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
- match:
- multi_match
- 语法match:
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}实例
查询名字里有荣耀的
GET /items/_search
{"query": {"match": {"name": "华为荣耀"}}
}
结果{"_index" : "items","_type" : "_doc","_id" : "21233662915","_score" : 18.592987,"_source" : {"id" : "21233662915","name" : "华为(HUAWEI) 华为 荣耀8 手机10 荣耀8X 智能手机 荣耀8X MAX 手机 荣耀8C 极光蓝 6GB+128GB","price" : 39900,"image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t28714/124/965064480/118844/84e42061/5c036e18N0f680a90.jpg!q70.jpg.webp","category" : "手机","brand" : "华为","sold" : 0,"commentCount" : 0,"isAD" : false,"updateTime" : 1556640000000}},
@Test //matchvoid matchQuery() throws IOException {//创建requestSearchRequest request = new SearchRequest("items");//请求参数request.source().query(QueryBuilders.matchQuery("name","华为"));//解析相应SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}
- multi_match
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}
例如
查询品牌和名称都又华为的
GET /items/_search
{"query": {"multi_match": {"query" : "华为","fields" : ["name","brand"]}}
}"_source" : {"id" : "28922228139","name" : "华为(HUAWEI)华为P20手机 极光色 全网通(6GB+64GB)(华为直供,送礼包)","price" : 5100,"image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t22243/131/709951731/332063/e5c95a29/5b15f92eN1f0677a5.jpg!q70.jpg.webp","category" : "手机","brand" : "华为","sold" : 0,"commentCount" : 0,"isAD" : false,"updateTime" : 1556640000000}}
@Test //multi_match
void multi_matchQuery() throws IOException {//创建requestSearchRequest request = new SearchRequest("items");//请求参数request.source().query(QueryBuilders.multiMatchQuery("name","华为","小米"));//解析相应SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);
}
精确查询
- Term-level query不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:ids term range 语法
- term
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}GET /items/_search
{"query": {"term": {"brand": {"value":"华为"}}}
}{"id" : "4093553","name" : "华为畅享7 Plus 3GB+32GB 普通版 香槟金 移动联通电信4G手机 双卡双待","price" : 26600,"image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t7804/212/1308671016/161589/6dd9c5fc/599c0da5N88410391.jpg!q70.jpg.webp","category" : "手机","brand" : "华为","sold" : 0,"commentCount" : 0,"isAD" : false,"updateTime" : 1556640000000}}
@Test //term
void termQuery() throws IOException {//创建requestSearchRequest request = new SearchRequest("items");//请求参数 // 500-9999request.source().query(QueryBuilders.termQuery("brand","华为"));//解析相应SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);
}
- range
range是范围查询,对于范围筛选的关键字有:
- gte:大于等于
- gt:大于
- lte:小于等于
- lt:小于GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}GET /items/_search
{"query": {"range": {"price": {"gte": 100,"lte": 2000}}}
}
{"id" : "1381868","name" : "ITO 拉杆箱20英寸旅行箱 商务时尚登机箱行李箱静音万向轮男女密码箱 CLASSIC 银色磨砂","price" : 900,"image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t4591/120/2388880972/76319/a3cda346/58ef603bN91f7daf4.jpg!q70.jpg.webp","category" : "拉杆箱","brand" : "ITO","sold" : 0,"commentCount" : 0,"isAD" : false,"updateTime" : 1556640000000}}
@Test //range
void rangeQuery() throws IOException {//创建requestSearchRequest request = new SearchRequest("items");//请求参数 // 500-9999request.source().query(QueryBuilders.rangeQuery("price").gte(500).lte(9999));//解析相应SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);
}
- bool查询
- bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
- 其中输入框的搜索条件肯定要参与相关性算分,可以采用match。但是价格范围过滤、品牌过滤、分类过滤等尽量采用filter,不要参与相关性算分
GET /items/_search
{"query": {"bool": { //查询方式"must": [ //查询条件1 与 名称必须为 小米{"match": {"name": "手机"}}],"should": [ //查询条件2 或 品牌为 小米 或者 vivo{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}], //查询条件2 非 价格不是小于等于 2500的"must_not": [{"range": {"price": {"gte": 2500}}}], "filter": [ //对于用户输入的关键字的搜索,都有匹配度相关问题,需要参与算分;对于过滤性的条件,一般不参与算分{"range": {"price": {"lte": 1000}}}]}}
}
// 搜索手机,但品牌必须是华为,价格必须是900~1599
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"filter": [{"term": {"brand": { "value": "华为" }}},{"range": {"price": {"gte": 90000, "lt": 159900}}}]}}
}
@Test //复合查询
void compareQuery() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
- elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}
查询 所有按照价格排序
GET /items/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}]
}
- 分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的limit ?, ?
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [{"price": {"order": "desc"}}]
}
@Test //排序和分页
void pageQuery() throws IOException {int pageNo = 1, pageSize = 5;// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.搜索条件参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
- 深度分页
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第99页。那么分页查询的条件如下:
GET /items/_search
{"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}]
}
- 高亮
- 高亮词条都被加了标签 标签都添加了红色样式
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
GET /items/_search
{"query": {"match": {"name": "华为"}},"highlight": {"fields": {"name": {"pre_tags": "<em>","post_tags": "</em>"}}}
}{"id" : "28922228139","name" : "华为(HUAWEI)华为P20手机 极光色 全网通(6GB+64GB)(华为直供,送礼包)","price" : 5100,"image" : "https://m.360buyimg.com/mobilecms/s720x720_jfs/t22243/131/709951731/332063/e5c95a29/5b15f92eN1f0677a5.jpg!q70.jpg.webp","category" : "手机","brand" : "华为","sold" : 0,"commentCount" : 0,"isAD" : false,"updateTime" : 1556640000000},"highlight" : {"name" : ["<em>华</em><em>为</em>(HUAWEI)<em>华</em><em>为</em>P20手机 极光色 全网通(6GB+64GB)(<em>华</em><em>为</em>直供,送礼包)"]}},
@Test
void HighlightQuery() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse1(response);
}
private void handleResponse1(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);// 5.获取高亮结果Map<String, HighlightField> hfs = hit.getHighlightFields();if (CollUtils.isNotEmpty(hfs)) {// 5.1.有高亮结果,获取name的高亮结果HighlightField hf = hfs.get("name");if (hf != null) {// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值String hfName = hf.getFragments()[0].string();item.setName(hfName);}}System.out.println(item);}
}
地理坐标查询
- 用于搜索地理位置,搜索方式很多,例如:
- geo_bounding_box:按矩形搜索
- geo_distance:按点和半径搜索
- …略
聚合函数
@Test
void testAgg() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.准备请求参数BoolQueryBuilder bool = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机")).filter(QueryBuilders.rangeQuery("price").gte(300000));request.source().query(bool).size(0);// 3.聚合参数request.source().aggregation(AggregationBuilders.terms("brand_agg").field("brand").size(5));// 4.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析聚合结果Aggregations aggregations = response.getAggregations();// 5.1.获取品牌聚合Terms brandTerms = aggregations.get("brand_agg");// 5.2.获取聚合中的桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 5.3.遍历桶内数据for (Terms.Bucket bucket : buckets) {// 5.4.获取桶内keyString brand = bucket.getKeyAsString();System.out.print("brand = " + brand);long count = bucket.getDocCount();System.out.println("; count = " + count);}
}
相关文章:
Elasticseach RestClient Api
Elasticsearch RestclientApi基础用法 查询 索引库 初始化 添加依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency>创建链接 package com…...

【网络安全学习】漏洞扫描:-04- ZAP漏洞扫描工具
**ZAP(Zed Attack Proxy)**是一款由OWASP组织开发的免费且开源的安全测试工具。 ZAP支持认证、AJAX爬取、自动化扫描、强制浏览和动态SSL证书等功能。 1️⃣ 安装zap工具 现在的kali版本不一定会预装zap,我们可以自行安装,安装也十分简单。 apt-get …...

fffdddd
library ieee; use ieee.std_logic_1164.all; use ieee.std_logic_arith.all; use ieee.std_logic_unsigned.all;entity GJL isport(clk, reset: in std_logic;btn_green, btn_red: in std_logic; -- 新增控制按键r1, r2, y1, y2, g1, g2: out std_logic;ledag: out std_logic_…...

SpringSecurity实战入门——授权
权限系统的作用 例如一个学校图书馆的管理系统,如果是普通学生登录就能看到借书还书相关的功能,不可能让他看到并且去使用添加书籍信息,删除书籍信息等功能。但是如果是一个图书馆管理员的账号登录了,应该就能看到并使用添加书籍信息,删除书籍信息等功能。 总结起来就是…...

Linux 网络请求工具:curl
文章目录 Linux 网络请求:curl1. 安装2. 常规用法3. 传输速率4. FTP5. 代理 Linux 网络请求:curl 1. 安装 若系统没有 curl 命令,可以直接通过 yum 或者 dnf 安装: yum -y install curl # 查看版本,确认安装结果 cu…...

leetcode 二分查找·系统掌握 寻找旋转排序数组中的最小值II
题目: 题解: 本题比普通的寻找旋转排序数组中的最小值多了一个数组中的元素可以重复这一点。 这会时原来的思路出现一个漏洞(大家感兴趣可以看看我做普通版寻找旋转排序数组最小值的思路),就是旋转后的数组中的第二个…...

Flink 容错
Apache Flink 的容错机制是确保数据流应用程序在出现故障时能够恢复一致状态的关键机制。这一机制主要通过创建分布式数据流和操作符状态的一致快照来实现,这些快照被称为检查点(Checkpoint)。以下是 Flink 容错机制的主要特点和关键点&#…...

OpenAI策略:指令层级系统让大模型免于恶意攻击
现代的大模型(LLMs)不再仅仅是简单的自动完成系统,它们有潜力赋能各种代理应用,如网页代理、电子邮件秘书、虚拟助手等。然而,这些应用广泛部署的一个主要风险是敌手可能诱使模型执行不安全或灾难性的行动,…...
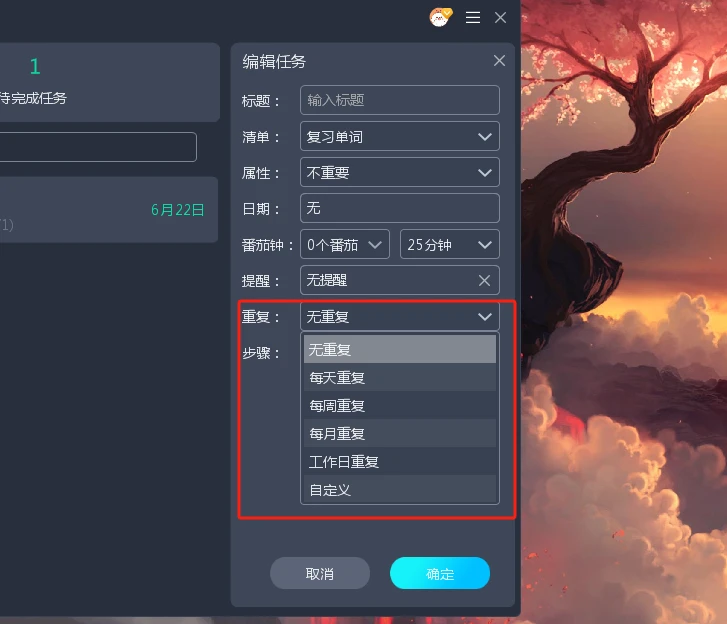
芝麻清单助力提升学习工作效率 专注时间完成有效的待办事项
芝麻清单助力提升学习&工作效率 专注时间完成有效的工作。今天我们给大家带来一个专注清单,一个更高效的学习和工作的方法! 我们都知道,专注做一个事情,会有效的提升效率,让事情更高效的完成。如果是学习的话&…...

Docker 容器操作命令
文章目录 前言1. 创建并运行容器2. 列出容器3. 停止容器4. 启动已停止的容器5. 重启容器6. 进入容器7. 删除容器8. 查看容器日志9. 导出和导入容器10. 管理网络11. 数据卷操作12. 设置容器自启动 前言 Docker 容器操作是 Docker 使用过程中非常重要的一部分。以下是一些常见的…...

华为配置创建vlan及划接口,trunk干道,DHCP池塘配置
1、创建 vlan [SWA]vlan 10 [SWA-vlan10]quit [SWA]vlan batch2to3510 批量创建vlan2-3,5.10 2、 接口划入 vlan 单个接口修改接口模式为 access [SWA]interface GigabitEthernet 0/0/5 [SWA-GigabitEthernet0/0/5]port link-type access 批修改为 access [H…...

vue3 computed与watch,watchEffect比较
相同点 都是要根据一个或多个响应式数据进行监听 不同点 computed 如要return回来一个新的响应式值,且这个值不允许直接修改,想要修改的话可以设置set函数,在函数里面去修改所依赖的响应式数据,然后计算属性值会基于其响应式依…...

论文:R语言数据分析之机器学习论文
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者Xiao hong书:生信学习者知hu:生信学习者CDSN:生信学习者2 一、研究背景 全球范围内,乳腺癌是导致癌症发病率和死亡率的主要疾病之一。根据2018年…...

【C++】STL中优先级队列的使用与模拟实现
前言:在前面我们学习了栈和队列的使用与模拟实现,今天我们来进一步的学习优先级队列使用与模拟实现 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:高质量C学习 👈 💯代码仓库:卫…...
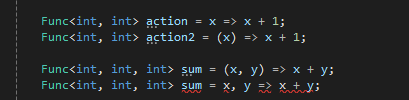
C#开发-集合使用和技巧(二)Lambda 表达式介绍和应用
C#开发-集合使用和技巧 Lambda 表达式介绍和应用 C#开发-集合使用和技巧介绍简单的示例:集合查询示例: 1. 基本语法从主体语句上区分:1. 主体为单一表达式2. 主体是代码块(多个表达式语句) 从参数上区分1. 带输入参数的…...
)
Qt底层原理:深入解析QWidget的绘制技术细节(2)
(本文续上一篇《Qt底层原理:深入解析QWidget的绘制技术细节(1)》) QWidget绘制体系为什么这么设计【重点】 在传统的C图形界面框架中,例如DUILib等,控件的绘制逻辑往往直接在控件的类的内部,例如PushButt…...
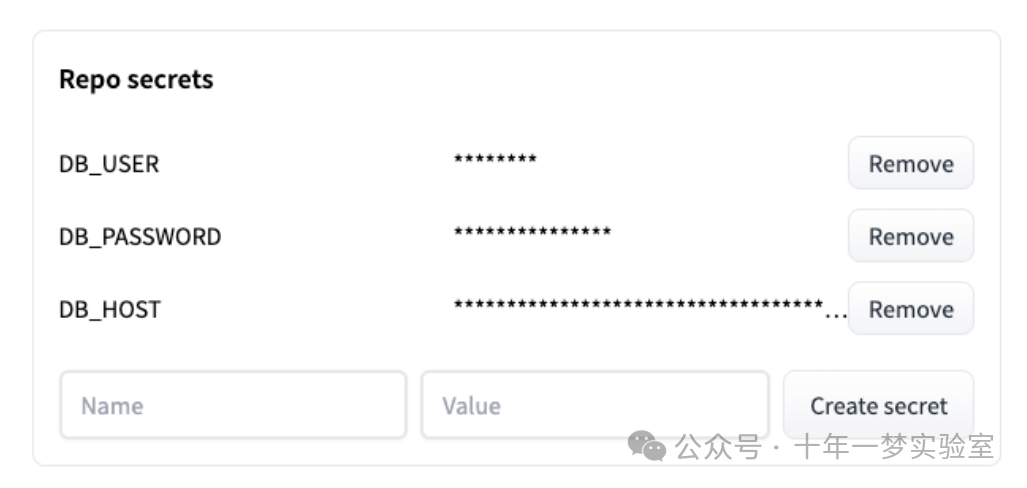
【Gradio】表格数据科学与图表-连接到数据库
简介 本指南解释了如何使用 Gradio 将您的应用程序连接到数据库。我们将连接到托管在 AWS 上的 PostgreSQL 数据库,但 gradio 对您连接到的数据库类型及其托管位置完全不可知。因此,只要您能够编写 Python 代码来连接到您的数据,您就可以使用…...

艾多美用“艾”为生命加油,献血活动回顾
用艾为生命加油 6月10日~16日,艾多美中国开启献血周活动,已经陆续收到来自烟台总部、山东、广东、河南、四川、重庆、贵阳,乌鲁木齐,吉林,等地区的艾多美员工、会员、经销商发来的爱心助力,截止到目前&…...
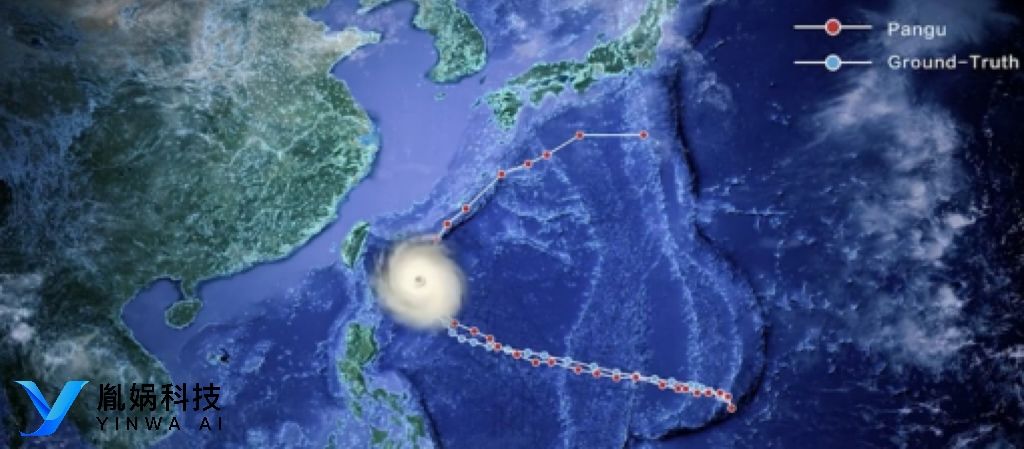
人工智能在气象预报领域的崛起:GraphCast引领新纪元
最近,谷歌推出的天气预测大模型GraphCast在全球范围内引起了广泛关注,其卓越的表现不仅刷新了人们对AI能力的认知,更预示着传统天气预报工作模式的深刻变革。 GraphCast是一款基于机器学习技术的天气预测工具,它通过深度学习和大数…...
http和https的区别在哪
HTTP(超文本传输协议)和HTTPS(超文本传输安全协议)之间存在几个关键区别主要涉及安全性、端口、成本、加密方式、搜索引擎优化(SEO)、身份验证等方面 1、安全性:HTTP(超文本传输协议…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...
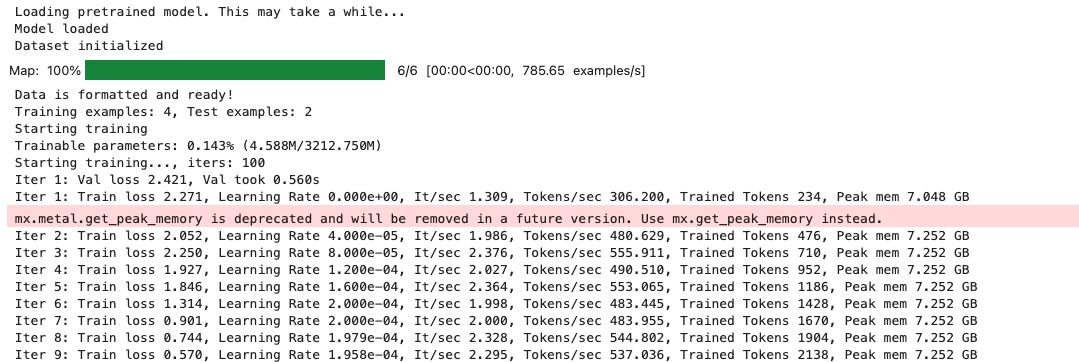
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...