构建高效的大数据量延迟任务调度平台
目录
- 引言
- 系统需求分析
- 系统架构设计
- 总体架构
- 任务调度模块
- 任务存储模块
- 任务执行模块
- 任务调度算法
- 时间轮算法
- 优先级队列
- 分布式锁
- 数据存储方案
- 关系型数据库
- NoSQL数据库
- 混合存储方案
- 容错和高可用性
- 主从复制
- 数据备份与恢复
- 故障转移
- 性能优化
- 水平扩展
- 缓存机制
- 异步处理
- 监控与运维
- 监控指标
- 报警系统
- 日志管理
- 总结
引言
延迟任务调度是指在未来某个特定时间执行特定任务的能力。这种能力在各种应用场景中都非常有用,比如电商平台上的优惠券过期提醒、社交网络中的生日提醒以及大型数据处理系统中的定时数据清洗任务等。
在处理大规模数据量时,延迟任务调度平台需要具备高性能、可扩展性和高可用性。因此,我们需要一个精心设计的系统架构来满足这些需求。
系统需求分析
在设计大数据量延迟任务调度平台之前,我们首先需要明确系统的需求:
- 高并发支持:系统需要处理大量并发请求,包括任务的创建、查询和执行。
- 高可用性:系统需要在任何时候都能够正常运行,避免单点故障。
- 任务精确性:任务需要在指定时间精确执行。
- 可扩展性:系统需要能够平滑扩展,以支持不断增长的数据量。
- 数据一致性:在分布式环境中,系统需要保证数据的一致性。
系统架构设计
总体架构
一个典型的大数据量延迟任务调度平台可以分为以下几个模块:
- 任务调度模块:负责管理和调度任务,确保任务在指定时间执行。
- 任务存储模块:负责存储任务的详细信息,包括任务的创建时间、执行时间和状态等。
- 任务执行模块:负责实际执行任务,并将任务执行结果反馈给系统。
下图展示了系统的总体架构:

任务调度模块
任务调度模块是系统的核心,它负责定时扫描任务存储模块中的任务,并在合适的时间将任务推送给任务执行模块。为了提高效率,我们可以使用多种调度算法,如时间轮算法和优先级队列。
任务存储模块
任务存储模块需要能够高效地存储和检索任务信息。在处理大规模数据时,我们需要选择合适的数据库方案,如关系型数据库、NoSQL数据库,或者两者结合使用。
任务执行模块
任务执行模块负责实际执行任务。这一模块需要具备高并发处理能力,并且能够处理任务执行过程中可能出现的各种异常情况。
任务调度算法
时间轮算法
时间轮算法是一种高效的定时任务调度算法,适用于处理大量定时任务。时间轮的基本思想是将时间划分为多个时间片,每个时间片对应一个槽(slot),槽中存储需要在该时间片执行的任务。
时间轮结构
时间轮可以看作是一个循环数组,每个数组元素代表一个时间槽。时间槽中存储的是需要在相应时间点执行的任务列表。时间轮的大小取决于系统的精度要求。

时间轮的操作
- 任务添加:根据任务的延迟时间计算任务需要插入的时间槽,并将任务添加到该时间槽中。
- 时间推进:时间轮按时间推进,每次推进一个时间槽,当时间轮指针指向某个时间槽时,执行该时间槽中的所有任务。
- 任务执行:将时间槽中的任务取出并执行,如果任务需要再次延迟,则重新计算其插入的时间槽。
优先级队列
优先级队列是一种常见的数据结构,适用于需要按优先级顺序处理任务的场景。在延迟任务调度中,我们可以使用优先级队列将任务按执行时间排序,保证任务按时执行。
优先级队列实现
优先级队列可以使用最小堆(min-heap)来实现,其中堆顶元素是优先级最高(执行时间最早)的任务。任务的添加和删除操作的时间复杂度均为O(log N)。
优先级队列的操作
- 任务添加:将任务插入到优先级队列中,并保持堆的性质。
- 任务取出:取出堆顶的任务,并重新调整堆结构。
- 任务执行:按顺序执行取出的任务,如果任务需要再次延迟,则重新插入优先级队列。
分布式锁
在分布式系统中,为了避免多个实例同时处理同一个任务,我们需要使用分布式锁来保证任务的唯一性执行。常见的分布式锁实现方式包括基于数据库的分布式锁、基于Redis的分布式锁以及基于ZooKeeper的分布式锁。
基于Redis的分布式锁
Redis是一个高性能的键值数据库,可以用来实现分布式锁。以下是一个简单的基于Redis分布式锁的实现:
import redis
import time
import uuidclass RedisLock:def __init__(self, client, lock_key, timeout=10):self.client = clientself.lock_key = lock_keyself.timeout = timeoutself.lock_id = str(uuid.uuid4())def acquire(self):return self.client.set(self.lock_key, self.lock_id, nx=True, ex=self.timeout)def release(self):lock_value = self.client.get(self.lock_key)if lock_value and lock_value.decode() == self.lock_id:self.client.delete(self.lock_key)# 使用示例
client = redis.Redis(host='localhost', port=6379, db=0)
lock = RedisLock(client, 'my_lock_key')if lock.acquire():try:# 执行任务passfinally:lock.release()
数据存储方案
关系型数据库
关系型数据库(如MySQL、PostgreSQL)以其强大的事务处理能力和数据一致性保障,常用于存储结构化数据。在延迟任务调度平台中,关系型数据库可以用来存储任务的元数据和执行记录。
表结构设计
CREATE TABLE tasks (id BIGINT AUTO_INCREMENT PRIMARY KEY,task_name VARCHAR(255) NOT NULL,execute_at TIMESTAMP NOT NULL,status VARCHAR(50) NOT NULL,payload TEXT,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);CREATE INDEX idx_execute_at ON tasks(execute_at);
NoSQL数据库
NoSQL数据库(如MongoDB、Cassandra)具有高扩展性和高可用性的特点,适用于存储海量数据。在延迟任务调度平台中,NoSQL数据库可以用来存储大量的任务数据,尤其是当任务的结构不固定时。
示例:MongoDB任务存储
db.tasks.createIndex({ "execute_at": 1 });db.tasks.insert({task_name: "example_task",execute_at: ISODate("2023-06-19T12:00:00Z"),status: "pending",payload: {...},created_at: new Date(),updated_at: new Date()
});
混合存储方案
在实际应用中,我们可以结合使用关系型数据库和NoSQL数据库,以发挥各自的优势。例如,我们可以使用关系型数据库存储关键的任务元数据,使用NoSQL数据库存储大量的任务日志和执行数据。
容错和高可用性
主从复制
主从复制是一种常见的数据冗余方案,通过将数据复制到多个节点,提高系统的可靠性和可用性。在延迟任务调度平台中,我们可以使用主从复制来保证任务数据的高可用性。
示例:MySQL主从复制配置
在主服务器上添加如下配置:
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog-do-db = tasks_db
在从服务器上添加如下配置:
[mysqld]
server-id = 2
replicate-do-db = tasks_db
在主服务器上创建复制用户:
CREATE USER 'replica_user'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'replica_user'@'%';
FLUSH PRIVILEGES;
在从服务器上启动复制:
CHANGE MASTER TO MASTER_HOST='主服务器IP', MASTER_USER='replica_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=0;
START SLAVE;
数据备份与恢复
定期数据备份是保证数据安全的重要手段。在延迟任务调度平台中,我们需要定期备份任务数据,以应对可能的数据丢失情况。
示例:使用mysqldump备份MySQL数据库
mysqldump -u username -p tasks_db > tasks_db_backup.sql
恢复数据库:
mysql -u username -p tasks_db < tasks_db_backup.sql
故障转移
故障转移是指当系统中的某个组件发生故障时,系统能够自动切换到备用组件,以保证系统的持续运行。在延迟任务调度平台中,我们可以使用故障转移机制来提高系统的高可用性。
示例:使用Keepalived实现MySQL故障转移
安装Keepalived:
sudo apt-get install keepalived
配置Keepalived:
vrrp_instance VI_1 {state MASTERinterface eth0virtual_router_id 51priority 100advert_int 1authentication {auth_type PASSauth_pass 1234}virtual_ipaddress {192.168.1.100}
}
启动Keepalived:
sudo service keepalived start
性能优化
水平扩展
水平扩展是指通过增加更多的服务器节点来提升系统的处理能力。在延迟任务调度平台中,我们可以通过水平扩展调度模块和存储模块来提高系统的并发处理能力。
示例:使用Kubernetes进行容器化部署
编写Kubernetes Deployment配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:name: scheduler-deployment
spec:replicas: 3selector:matchLabels:app: schedulertemplate:metadata:labels:app: schedulerspec:containers:- name: schedulerimage: scheduler-image:latestports:- containerPort: 8080
部署应用:
kubectl apply -f scheduler-deployment.yaml
缓存机制
缓存机制可以显著提高系统的性能,减少数据库的访问压力。在延迟任务调度平台中,我们可以使用缓存来存储频繁访问的任务数据。
示例:使用Redis缓存任务数据
import redis
import jsonclass TaskCache:def __init__(self, client):self.client = clientdef get_task(self, task_id):task_data = self.client.get(task_id)if task_data:return json.loads(task_data)return Nonedef set_task(self, task_id, task_data, expire_time=3600):self.client.set(task_id, json.dumps(task_data), ex=expire_time)# 使用示例
client = redis.Redis(host='localhost', port=6379, db=0)
cache = TaskCache(client)# 设置任务缓存
cache.set_task('task_123', {'task_name': 'example_task', 'execute_at': '2023-06-19T12:00:00Z'})# 获取任务缓存
task_data = cache.get_task('task_123')
异步处理
异步处理可以有效提高系统的响应速度,减少任务的执行延迟。在延迟任务调度平台中,我们可以使用异步处理来执行耗时任务。
示例:使用Celery实现异步任务执行
安装Celery和Redis:
pip install celery[redis]
配置Celery:
from celery import Celeryapp = Celery('tasks', broker='redis://localhost:6379/0')@app.task
def execute_task(task_data):# 执行任务pass
发送异步任务:
from tasks import execute_tasktask_data = {'task_name': 'example_task', 'execute_at': '2023-06-19T12:00:00Z'}
execute_task.delay(task_data)
监控与运维
监控指标
监控是保证系统稳定运行的重要手段。在延迟任务调度平台中,我们需要监控以下指标:
- 任务处理量:每秒处理的任务数量。
- 任务延迟:任务实际执行时间与预定执行时间的差异。
- 系统资源使用情况:CPU、内存、磁盘和网络的使用情况。
- 错误率:任务执行失败的比例。
报警系统
报警系统可以及时发现并处理系统中的异常情况。在延迟任务调度平台中,我们可以设置多种报警规则,如任务执行超时、任务队列积压等。
示例:使用Prometheus和Alertmanager配置报警
配置Prometheus监控任务执行情况:
global:scrape_interval: 15sscrape_configs:- job_name: 'scheduler'static_configs:- targets: ['localhost:9090']
配置Alertmanager报警规则:
global:resolve_timeout: 5mroute:group_by: ['alertname']group_wait: 30sgroup_interval: 5mrepeat_interval: 3hreceiver: 'email'receivers:- name: 'email'email_configs:- to: 'admin@example.com'from: 'alertmanager@example.com'smarthost: 'smtp.example.com:587'auth_username: 'alertmanager'auth_password: 'password'inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'instance']
日志管理
日志是分析和调试系统问题的重要工具。在延迟任务调度平台中,我们需要记录详细的任务日志,包括任务的创建、调度和执行情况。
示例:使用ELK(Elasticsearch, Logstash, Kibana)进行日志管理
安装和配置Elasticsearch:
cluster.name: "scheduler-logs"
network.host: localhost
安装和配置Logstash:
input {file {path => "/var/log/scheduler/*.log"start_position => "beginning"}
}output {elasticsearch {hosts => ["localhost:9200"]index => "scheduler-logs-%{+YYYY.MM.dd}"}
}
安装和配置Kibana:
server.host: "localhost"
elasticsearch.hosts: ["http://localhost:9200"]
总结
构建一个高效的大数据量延迟任务调度平台是一个复杂而富有挑战性的任务。本文从系统需求分析入手,详细探讨了系统架构设计、任务调度算法、数据存储方案、容错和高可用性、性能优化以及监控与运维等方面的内容。通过合理的架构设计和技术选型,我们可以构建一个高性能、可扩展且高可用的延迟任务调度平台,为各类应用场景提供可靠的支持。希望本文能为广大技术人员在设计和实现延迟任务调度系统时提供有价值的参考。
相关文章:
构建高效的大数据量延迟任务调度平台
目录 引言系统需求分析系统架构设计 总体架构任务调度模块任务存储模块任务执行模块 任务调度算法 时间轮算法优先级队列分布式锁 数据存储方案 关系型数据库NoSQL数据库混合存储方案 容错和高可用性 主从复制数据备份与恢复故障转移 性能优化 水平扩展缓存机制异步处理 监控与…...
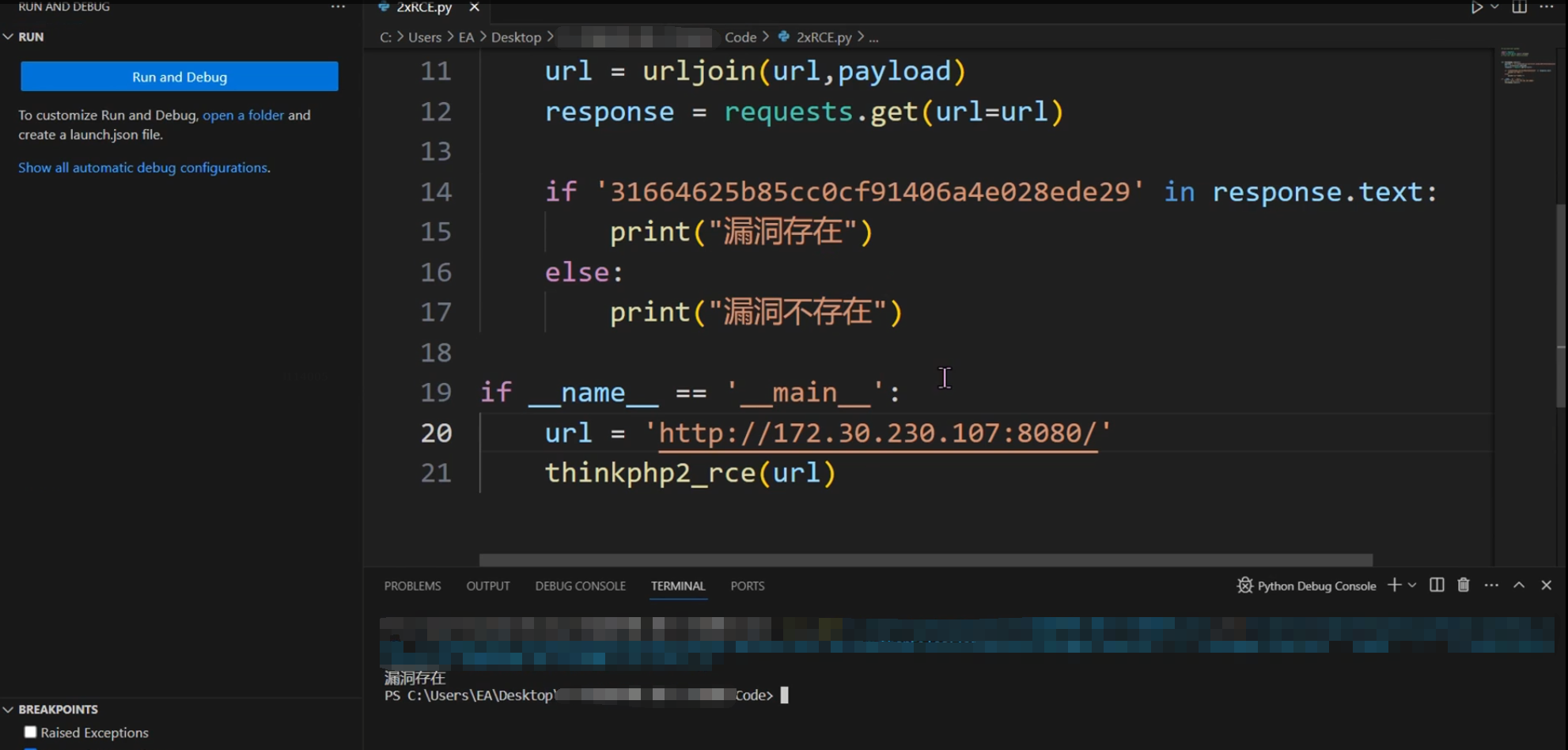
Python武器库开发-武器库篇之ThinkPHP 2.x 任意代码执行漏洞(六十三)
Python武器库开发-武器库篇之ThinkPHP 2.x 任意代码执行漏洞(六十三) PHP代码审计简介 PHP代码审计是指对PHP程序进行安全审计,以发现潜在的安全漏洞和风险。PHP是一种流行的服务器端脚本语言,广泛用于开发网站和Web应用程序。由…...

SQLite数据库(数据库和链表双向转换)
文章目录 SQLite数据库一、SQLite简介1、SQLite和MySQL2、基于嵌入式的数据库 二、SQLite数据库安装三、SQLite的常用命令四、SQLite的编程操作1、SQLite数据库相关API(1)头文件(2)sqlite3_open()(3)sqlite…...

React框架的来龙去脉,react的技术原理及技术难点和要点,小白的进阶之路
React 框架的来龙去脉:技术原理及技术难点和要点 1. React 的起源与发展 React 是由 Facebook 开发的一个用于构建用户界面的 JavaScript 库。它最初由 Jordan Walke 创建,并在 2013 年开源。React 的出现是为了解决在大型应用中管理复杂用户界面的问题…...
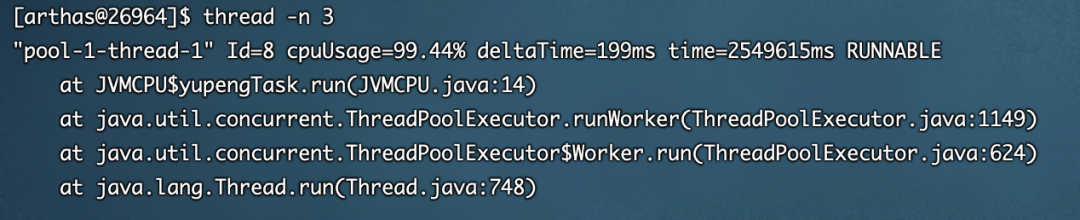
CPU飙升100%怎么办?字节跳动面试官告诉你答案!
小北说在前面 CPU占用率突然飙升是技术人员常遇到的一个棘手问题,它是一个与具体技术无关的普遍挑战。 这个问题可以很简单,也可以相当复杂。 有时候,只是一个死循环在作祟。 有时候,是死锁导致的。 有时候,代码中有…...

物理层(二)
2.2 传输介质 2.2.1 双绞线、同轴电缆、光纤和无线传输介质 传输介质也称传输媒体,是数据传输系统中发送器和接收器之间的物理通路。传输介质可分为:①导向传输介质,指铜线或光纤等,电磁波被导向为沿着固体介质传播:②)非导向传输介质&…...

C#——文件读取IO操作File类详情
文件读取操作 IO类 就是对应文件的操作的类I/O类 包含各种不同的类 用于执行各种文件操作,创建文件删除文件读写文件 常用的类: File处理文件操作的类 FilleStream用于文件当中任何位置的读写 File类 1.文件创建 File.Create() 在指定路径下创建…...
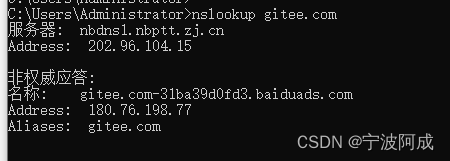
昨天gitee网站访问不了,开始以为电脑哪里有问题了
昨天gitee网站下午访问不了,开始以为是什么毛病。 结果同样的网络,手机是可以访问的。 当然就ping www.gitee.com 结果也下面那样是正常的 以为是好的,但就是访问www.gitee.com也是不行,后来用阿里云的服务器curl访问是下面情况&…...

深入理解适配器模式:Java实现与框架应用
适配器模式是一种结构型设计模式,它允许将一个类的接口转换成客户端希望的另一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的类可以协同工作。在本篇博客中,我们将详细介绍适配器模式,并演示如何在Java中实现它。最后࿰…...
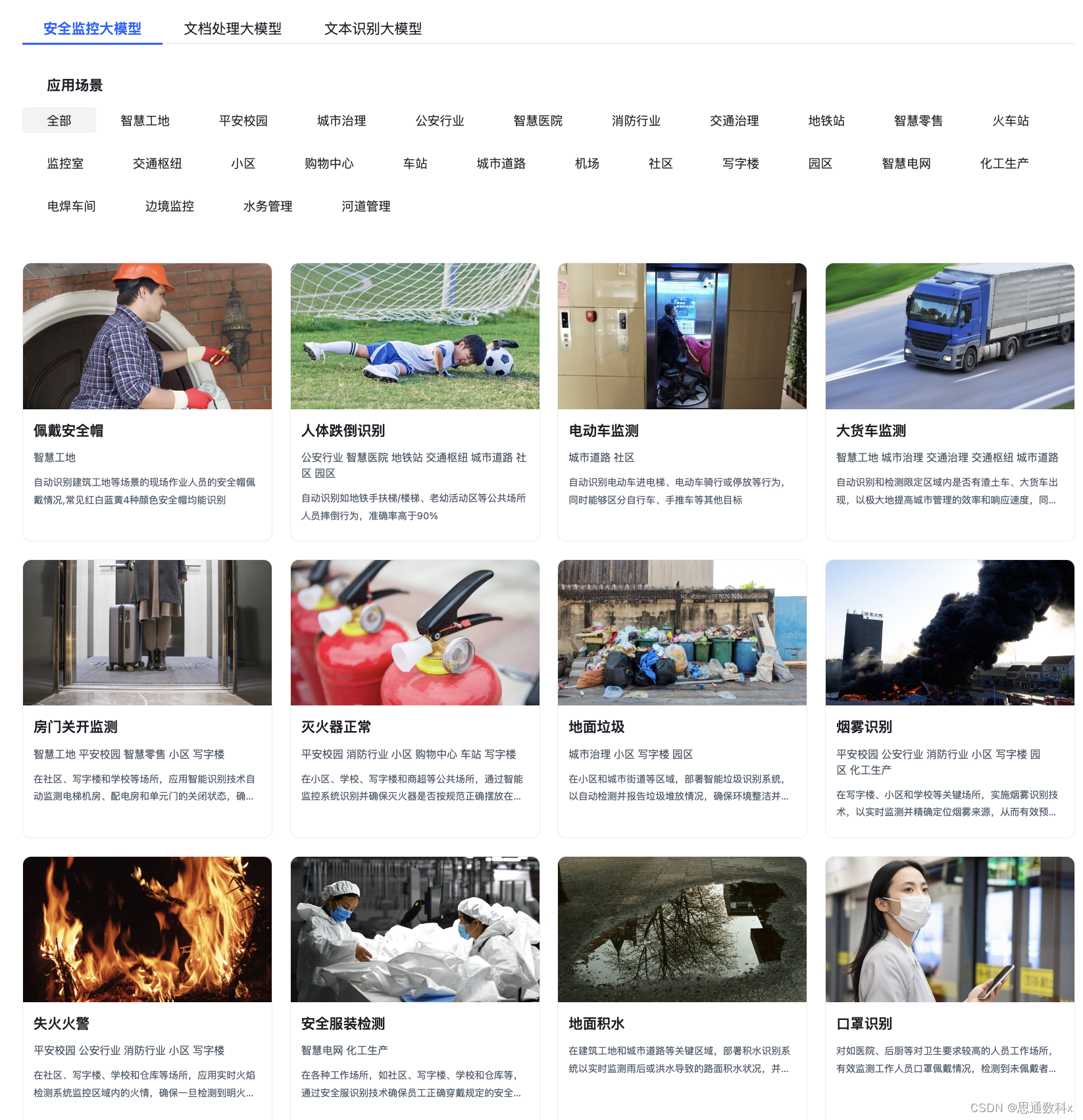
跌倒识别:守护公共安全的AI技术应用场景-免费API调用
随着科技的不断进步,人工智能在各个领域的应用日益广泛,其中在公共安全领域,智能跌倒识别系统正逐渐成为守护人们安全的重要工具。本文将分享智能跌倒识别系统在不同场景下的应用及其重要性。 产品在线体验地址-API调用或本地化部署 AI算法模…...
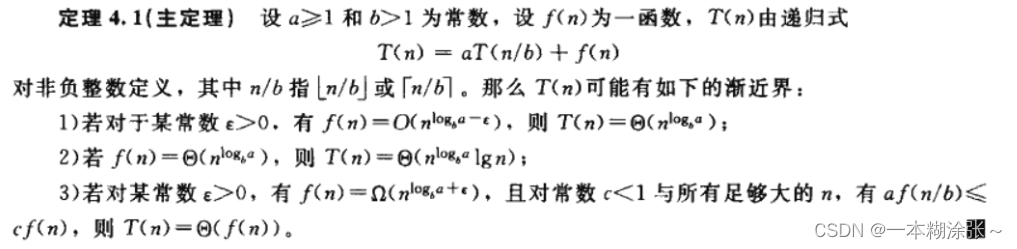
算法:渐进记号的含义及时间复杂度计算
渐进记号及时间复杂度计算 渐近符号渐近记号 Ω \Omega Ω渐进记号 Θ \Theta Θ渐进记号小 ο \omicron ο渐进记号小 ω \omega ω渐进记号大 O \Omicron O常见的时间复杂度关系 时间复杂度计算:递归方程代入法迭代法套用公式法 渐近符号 渐近记号 Ω \Omega Ω …...

idea导入文件里面的子模块maven未识别处理解决办法
1、File → Project Structure → 点击“Modules” → 点击“” → “Import Model” 2、可以看到很多子模块,选择子模块下的 pom.xml 文件导入一个一个点累死了,父目录下也没有pom文件 解决办法:找到子模块中有一个pom.xml文件,…...

IOS Swift 从入门到精通:协议和扩展
文章目录 协议协议继承扩展协议扩展面向协议的编程总结: 今天你将学习一些真正的 Swifty 功能:协议和面向协议的编程(POP)。 POP 摒弃了庞大而复杂的继承层次结构,代之以更小、更简单、可以组合在一起的协议。这确实应…...

Vue插件开发:Vue.js的插件架构允许开发者扩展Vue的核心功能,我们可以探讨如何开发一个Vue插件并与社区分享
了解Vue插件 Vue插件的概念: Vue插件用于为Vue.js添加全局级别的功能。它提供了一种开箱即用的机制来应用全局性的功能扩展。这些插件通常用来将全局方法或属性,组件选项,Vue实例的方法,或者注入一些组件选项比如mixins和自定义方法添加至Vue.js。 Vue插件的使用场景:…...

学习面向对象前--Java基础练习题
前言 写给所有一起努力学习Java的朋友们,敲代码本身其实是我们梳理逻辑的一个过程。我们在学习Java代码的过程中,除了需要学习Java的一些基本操作及使用,更重要的是我们需要培养好的逻辑思维。逻辑梳理好之后,我们编写代码实现需要…...
用Python实现抖音新作品监控助手,实时获取博主动态
声明: 本文以教学为基准、本文提供的可操作性不得用于任何商业用途和违法违规场景。本人对任何原因在使用本人中提供的代码和策略时可能对用户自己或他人造成的任何形式的损失和伤害不承担责任。包含关注,点赞等 该项目的主要功能是通过Python代码&…...

图像分隔和深度成像技术为什么受市场欢迎-数字孪生技术和物联网智能汽车技术的大爆发?分析一下图像技术的前生后世
图像分隔和深度成像是计算机视觉和图像处理领域的两项重要技术,它们各自有不同的技术基础和要点。 图像分隔技术基础: 机器学习和模式识别: 图像分隔通常依赖于机器学习算法,如支持向量机(SVM)、随机森林…...
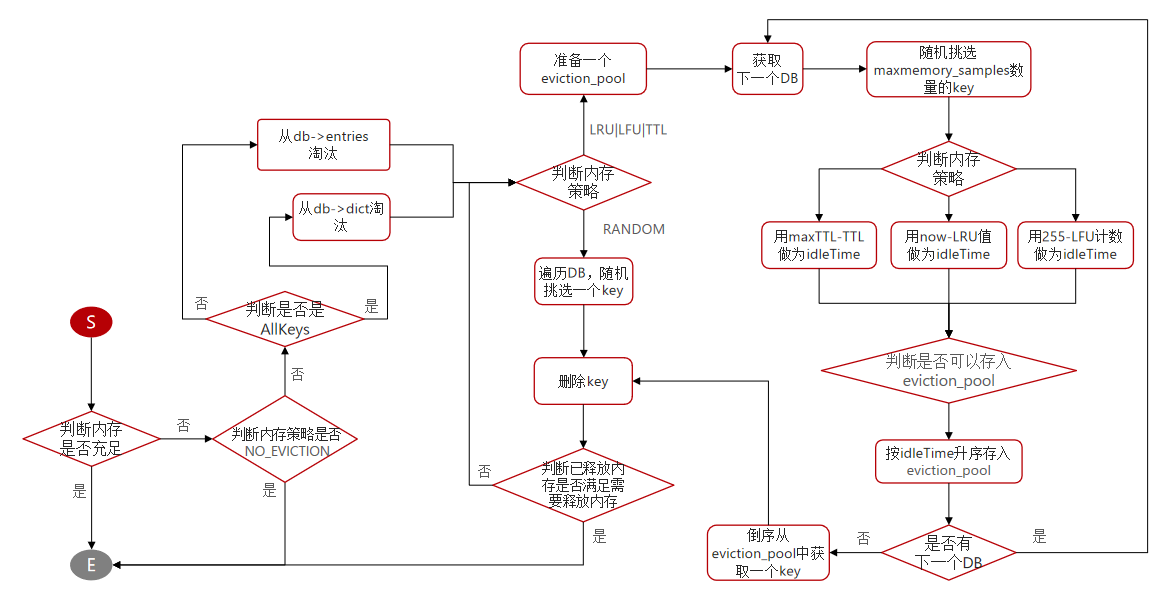
Redis 内存策略
一、Redis 内存回收 Redis 之所以性能强,最主要的原因就是基于内存存储。然而单节点的 Redis 其内存大小不宜过大,会影响持久化或主从同步性能。 我们可以通过修改配置文件来设置 Redis 的最大内存: # 格式: # maxmemory <byt…...

Java小实验————斗地主
早期使用的JavaSE用到的技术栈有:Map集合,数组,set集合,只是简单实现了斗地主的模拟阶段,感兴趣的小伙伴可以调试增加功能 代码如下: import java.util.*;public class Poker {public static void main(String[] arg…...
系统 CentOS7.6)
【Oracle】Linux 卸载重装 oracle 教程(如何清理干净残留)系统 CentOS7.6
总览 1.停止监听 2.删除 Oracle 数据库实例 3.删除 Oracle 相关服务 4.删除 Oracle 服务脚本 5.清理 Oracle 软件和配置文件 6.强制卸载 Oracle 软件包 一、开始干活(所有操作使用 root 权限,在 root 用户下执行) 1.停止监听 lsnrctl sto…...

告别低效收藏:MarkDownload让网页内容保存效率提升300%
告别低效收藏:MarkDownload让网页内容保存效率提升300% 【免费下载链接】markdownload A Firefox and Google Chrome extension to clip websites and download them into a readable markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownload …...

避坑指南:UR5e机器人SpeedL模式下的笛卡尔空间控制,如何避免奇异点和超限?
UR5e机器人SpeedL模式避坑实战:笛卡尔空间控制的三大安全策略 实验室里,机械臂突然发出刺耳的警报声——这可能是每个UR5e初学者都经历过的噩梦。当你在笛卡尔空间用SpeedL指令控制机器人画复杂轨迹时,关节超限、奇异点问题和自碰撞就像三个隐…...
)
Dify知识库创建全攻略:从零开始搭建你的AI问答系统(附分段模式详解)
Dify知识库创建全攻略:从零开始搭建你的AI问答系统(附分段模式详解) 在AI技术快速渗透各行各业的今天,构建专属知识库已成为企业智能化转型的核心基础设施。Dify作为一款开箱即用的AI应用开发平台,其知识库功能尤其适合…...

Vue3+AI聊天室:如何实现消息自动滚动和流式响应?
Vue3AI聊天室:消息自动滚动与流式响应的工程实践 引言:当Vue3遇见AI对话 在构建现代化AI聊天应用时,流畅的交互体验往往比功能堆砌更重要。想象这样一个场景:用户发送问题后,界面立即开始逐字显示AI回复,同…...

python基于微信小程序的家政服务与互助平台
目录技术栈选择功能模块设计数据库设计接口开发小程序前端部署与测试安全与合规项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 后端采用Python的Django或Flask框架,提供RESTful API接口。数据库使用MyS…...

从‘调不出来’到‘一次过流片’:折叠共源共栅放大器设计中那些没人告诉你的‘坑’与调试技巧
从‘调不出来’到‘一次过流片’:折叠共源共栅放大器设计中那些没人告诉你的‘坑’与调试技巧 在模拟电路设计的江湖里,折叠共源共栅(Folded Cascode)放大器就像一位身怀绝技却性格古怪的武林高手——性能强悍但极难驯服。许多工…...

实战构建c盘清理桌面应用,快马ai生成可部署完整解决方案
今天想和大家分享一个实战项目:用Python开发一个C盘清理桌面应用。这个工具不仅能解决日常C盘空间不足的烦恼,还具备完整的图形界面和实用功能。最近在InsCode(快马)平台上尝试了快速生成和部署,整个过程特别顺畅。 项目背景与核心功能 开发这…...

多模态扩展:OpenClaw+GLM-4.7-Flash处理图片信息
多模态扩展:OpenClawGLM-4.7-Flash处理图片信息 1. 为什么需要多模态能力 上周我在整理产品截图时遇到一个典型问题:需要从200多张UI截图中提取所有按钮文字和位置信息。手动操作不仅耗时,还容易遗漏细节。这让我开始思考——能否让OpenCla…...

高基数路由器的最佳拍档?深入浅出解析Flattened Butterfly拓扑的优缺点与适用场景
高基数路由器的最佳拍档?深入浅出解析Flattened Butterfly拓扑的优缺点与适用场景 在构建大规模互连网络时,拓扑结构的选择往往决定了系统的性能上限和成本下限。当工程师面对高基数路由器(High-Radix Router)的选型时,…...
)
最完整的大模型算法工程师技术栈图谱(2026版)
目录 一、基础能力(所有AI工程师的底座) 1 编程语言 2 数据结构与算法 3 数学基础 二、深度学习基础 深度学习模型基础 三、大模型核心技术 1 Transformer架构 2 预训练 3 Tokenizer 四、大模型训练体系 1 分布式训练 2 训练优化技术 3 微…...