【SQL】count(1)、count(*) 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释:
1. COUNT(1)
- 定义:
COUNT(1)计算查询结果集中的行数。 - 实现: 在执行过程中,
COUNT(1)会将1作为一个非空的常量值,并对每一行进行计数。 - 效率: 现代的 SQL 优化器通常会将
COUNT(1)和COUNT(*)优化为相同的执行计划,因此性能基本相同。 - 用途: 适用于计算总行数,与
COUNT(*)无区别。
SELECT COUNT(1) FROM employees;
2. COUNT(*)
- 定义:
COUNT(*)计算查询结果集中的总行数,包括所有列,不会忽略任何行,即使某些列包含NULL。 - 实现: SQL 优化器会对
COUNT(*)进行优化,将其转换为统计行数的操作。 - 效率: 通常是最常用和推荐的方式,因为其语义明确且优化器能够很好地处理。
- 用途: 适用于计算总行数,性能通常优于
COUNT(列名)。
SELECT COUNT(*) FROM employees;
3. COUNT(列名)
- 定义:
COUNT(列名)计算查询结果集中某一列非NULL值的行数。 - 实现: 只有当指定列的值不为
NULL时,该行才会被计入结果。 - 效率: 由于需要检查每行中的特定列是否为
NULL,性能可能略低于COUNT(*)和COUNT(1)。 - 用途: 适用于计算某一特定列中非
NULL值的数量。
SELECT COUNT(department_id) FROM employees;
示例代码
下面是一个使用 JDBC 示例代码,展示如何使用 COUNT(1)、COUNT(*) 和 COUNT(列名):
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.SQLException;public class CountExample {private static final String JDBC_URL = "jdbc:mysql://localhost:3306/yourdatabase";private static final String JDBC_USER = "yourusername";private static final String JDBC_PASSWORD = "yourpassword";public static void main(String[] args) {try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD);Statement stmt = conn.createStatement()) {// 使用 COUNT(1)String count1SQL = "SELECT COUNT(1) AS total FROM employees";ResultSet rs1 = stmt.executeQuery(count1SQL);if (rs1.next()) {int total1 = rs1.getInt("total");System.out.println("Total rows (COUNT(1)): " + total1);}// 使用 COUNT(*)String countAllSQL = "SELECT COUNT(*) AS total FROM employees";ResultSet rsAll = stmt.executeQuery(countAllSQL);if (rsAll.next()) {int totalAll = rsAll.getInt("total");System.out.println("Total rows (COUNT(*)): " + totalAll);}// 使用 COUNT(column)String countColumnSQL = "SELECT COUNT(department_id) AS total FROM employees";ResultSet rsColumn = stmt.executeQuery(countColumnSQL);if (rsColumn.next()) {int totalColumn = rsColumn.getInt("total");System.out.println("Total rows (COUNT(department_id)): " + totalColumn);}} catch (SQLException e) {e.printStackTrace();}}
}
在上述代码中,演示了如何使用 COUNT(1)、COUNT(*) 和 COUNT(列名) 进行统计查询。请根据需要调整数据库连接字符串、用户名、密码和 SQL 语句。
执行速度
对 COUNT(1)、COUNT(*) 和 COUNT(列名) 的执行速度进行排序,通常在现代的 SQL 数据库管理系统中,COUNT(1) 和 COUNT(*) 的性能基本相同,而 COUNT(列名) 的性能可能略低一些。排序如下:
- COUNT(1)
- COUNT(*)
- COUNT(列名)
详细解释
1. COUNT(1)
- 执行速度:
COUNT(1)只是将每一行的计数加一,现代 SQL 优化器通常会将COUNT(1)和COUNT(*)优化为相同的执行计划,因此执行速度非常快。 - 优化器行为: 优化器能够识别
COUNT(1)的语义并进行优化处理,使其与COUNT(*)的性能基本一致。
2. COUNT(*)
- 执行速度:
COUNT(*)计算表中所有行的数量,包括所有列,不忽略任何行。现代 SQL 优化器对此有非常好的优化,因此执行速度也非常快,通常与COUNT(1)无异。 - 优化器行为: 优化器会将
COUNT(*)优化为高效的行计数操作。
3. COUNT(列名)
- 执行速度:
COUNT(列名)只计算指定列非NULL值的行数。在执行过程中,数据库需要检查每一行中特定列是否为NULL,这会增加一些额外的处理时间。 - 优化器行为: 尽管现代优化器对
COUNT(列名)也有优化,但由于需要额外的NULL检查,性能可能略低于COUNT(1)和COUNT(*)。
示例验证
为了验证上述结论,可以使用以下 SQL 脚本在 MySQL 或其他 SQL 数据库中进行测试。请确保表中有足够多的数据,以便更明显地观察执行时间的差异。
创建测试表并插入数据
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY,department_id INT,name VARCHAR(255),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);-- 插入大量数据
INSERT INTO employees (department_id, name)
SELECT FLOOR(RAND() * 10), CONCAT('Employee', FLOOR(RAND() * 1000))
FROM (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) t1
CROSS JOIN (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) t2
CROSS JOIN (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) t3
CROSS JOIN (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) t4
CROSS JOIN (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) t5;
执行计数查询并记录执行时间
-- 计时 COUNT(1)
SET @start_time = NOW(6);
SELECT COUNT(1) FROM employees;
SELECT TIMEDIFF(NOW(6), @start_time) AS execution_time;-- 计时 COUNT(*)
SET @start_time = NOW(6);
SELECT COUNT(*) FROM employees;
SELECT TIMEDIFF(NOW(6), @start_time) AS execution_time;-- 计时 COUNT(department_id)
SET @start_time = NOW(6);
SELECT COUNT(department_id) FROM employees;
SELECT TIMEDIFF(NOW(6), @start_time) AS execution_time;
这些查询将显示每个 COUNT 语句的执行时间。通常,COUNT(1) 和 COUNT(*) 的执行时间几乎相同,而 COUNT(列名) 的执行时间可能稍长一些。
总结
COUNT(1): 计算查询结果集中的行数,性能与COUNT(*)基本相同。COUNT(*): 计算查询结果集中的总行数,包括所有列,不忽略任何行,通常是最常用和推荐的方式。COUNT(列名): 计算查询结果集中某一列非NULL值的行数,适用于统计特定列中的有效数据。
相关文章:
、count(*) 与 count(列名) 的区别)
【SQL】count(1)、count(*) 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释: 1. COUNT(1) 定义: COUNT(1) 计算查询结果集中的行数。实现: 在执行…...

03-ES6新语法
1. ES6 函数 1.1 函数参数的扩展 1.1.1 默认参数 function fun(name,age17){console.log(name","age); } fn("张美丽",18); // "张美丽",18 fn("张美丽",""); // "张美丽" fn("张美丽"); // &…...

Linux中的文本编辑器vi与vim
摘要: 本文将深入探讨VI和VIM编辑器的基本概念、特点、使用方法以及它们在Linux环境中的重要性。通过对这两款强大的文本编辑器的详细分析,读者将能够更全面地理解它们的功能,并掌握如何有效地使用它们进行日常的文本编辑和处理任务。 引言&…...
)
MATLAB基础应用精讲-【数模应用】三因素方差(附R语言、MATLAB和python代码实现)
目录 几个高频面试题目 群体分布是否服从高斯分布? 数据是否不匹配? “误差”是否独立存在? 您是否真的想比较平均值? 是否存在三项因素? 这三项因素是否均属于“固定因素”,而非“随机因素”? 算法原理 EXCEL spss三因素方差分析步骤 一、spss三因素…...
Linux ubuntu安装pl2303USB转串口驱动
文章目录 1.绿联PL2303串口驱动下载2.驱动安装3.验证方法 1.绿联PL2303串口驱动下载 下载地址:https://www.lulian.cn/download/16-cn.html 也可以直接通过CSDN下载:https://download.csdn.net/download/Axugo/89447539 2.驱动安装 下载后解压找到Lin…...
关于使用命令行打开wps word文件
前言 在学习python-docx时,想在完成运行时使用命令行打开生成的docx文件。 总结 在经过尝试后,得出以下代码: commandrstart "C:\Users\86136\AppData\Local\Kingsoft\WPS Office\12.1.0.16929\office6\wps.exe" "./result…...
将Vite添加到您现有的Web应用程序
Vite(发音为“veet”)是一个新的JavaScript绑定器。它包括电池,几乎不需要任何配置即可使用,并包括大量配置选项。哦——而且速度很快。速度快得令人难以置信。 本文将介绍将现有项目转换为Vite的过程。我们将介绍别名、填充webp…...

Apache Kafka与Spring整合应用详解
引言 Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,…...
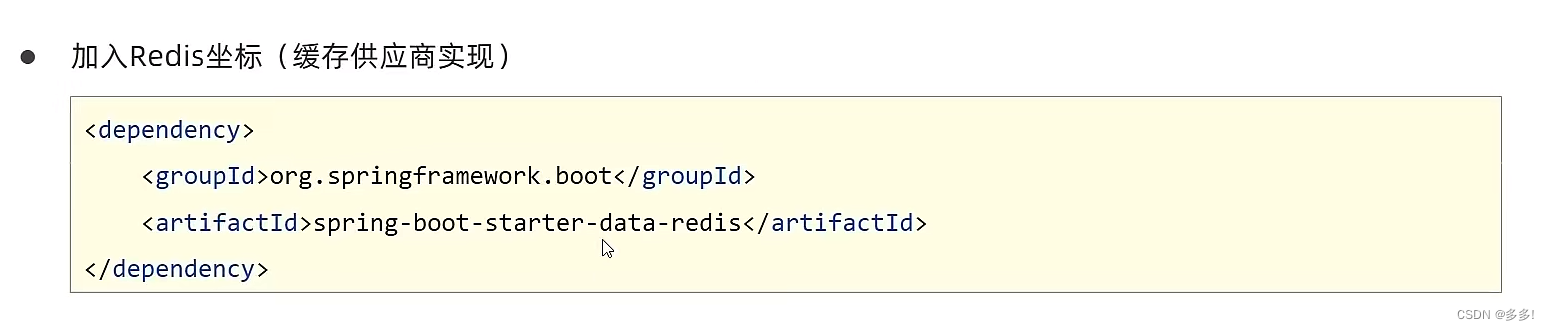
SpringBoot配置第三方专业缓存技术Redis
Redis缓存技术 Redis(Remote Dictionary Server)是一个开源的内存中数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的功能和灵活的…...
以及使用)
javascript的toFixed()以及使用
toFixed() 是 JavaScript 中数字类型(Number)的一个方法,用来将数字转换为指定小数位数的字符串表示形式。 使用方式和示例: let num 123.45678; let fixedNum num.toFixed(2); console.log(fixedNum); // 输出 "123.46&qu…...

软件功能测试和性能测试包括哪些测试内容?又有什么联系和区别?
软件功能测试和性能测试是保证软件质量和稳定性的重要手,无论是验证软件的功能正确性,还是评估软件在负载下的性能表现,这些测试都是必不可少的。 一、软件功能测试 软件功能测试是指对软件的各项功能进行验证和确认,确保软件…...
从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。 目录 评价标准1 效率2 用户体验分析从用户的维度来看从市场的维度来看从产品的维度来看 3 用户体验的基本原则…...

【软件设计】详细设计说明书(word原件,项目直接套用)
软件详细设计说明书 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件全套资料:本文末个人名片直接获取或者进主页。...
优缺点,以及适用场景)
java本地缓存(map,Guava,echcache,caffeine)优缺点,以及适用场景
前言 在高并发系统环境下,jvm本地缓存扮演着至关重要的角色,合理的应用能够使系统响应迅速,提高用户体验感,而分布式缓存redis则存在着网络io,以及流量消耗问题,需要和本地缓存搭配使用,才能使…...

Monica
在 《long long ago》中,我论述了on是一个刚出生的孩子的脐带连接在其肚子g上的形象,脐带就是long的字母l和字母n,l表脐带很长,n表脐带曲转冗余和连接之性,on表一,是孩子刚诞生的意思,o是身体&a…...

国产数据库中读写分离实现机制
在数据库高可用架构下会存在1主多备的部署,备节点可以根据业务场景分发一部分流量以充分利用资源,并减轻主库的压力,因此在数据库的功能上需要读写分离来实现。 充分利用备节点的资源,提升业务的吞吐量;防止运维等非业…...

kubernetes部署dashboard
kubernetes部署dashboard 1. 简介 Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息&#…...

FPGA早鸟课程第二弹 | Vivado 设计静态时序分析和实际约束
在FPGA设计领域,时序约束和静态时序分析是提升系统性能和稳定性的关键。社区推出的「Vivado 设计静态时序分析和实际约束」课程,旨在帮助工程师们掌握先进的设计技术,优化设计流程,提高开发效率。 课程介绍 关于课程 权威认证&…...

STM32项目分享:家庭环境监测系统
目录 一、前言 二、项目简介 1.功能详解 2.主要器件 三、原理图设计 四、PCB硬件设计 1.PCB图 2.PCB板打样焊接图 五、程序设计 六、实验效果 七、资料内容 项目分享 一、前言 项目成品图片: 哔哩哔哩视频链接: https://www.bilibili.…...

华为HCIP Datacom H12-821 卷5
1.单选题 下列哪种工具不能被 route-policy 的 apply 子句直接引用? A、IP-Prefix B、tag C、community D、origin 正确答案: A 解析: 因route-policy工具中, apply 后面跟的是路由的相关属性。 但是ip-prefix是用来匹配路由的工具。 2.单选题...
)
别再一行行读DXF了!用C#和netDxf库5分钟搞定CAD数据提取(附完整代码)
用C#和netDxf库高效解析DXF文件的实战指南 在CAD数据处理领域,DXF文件解析一直是开发者面临的常见挑战。传统的手动解析方法不仅耗时费力,还容易出错。本文将带你探索如何利用C#和netDxf库快速实现DXF文件的高效解析,彻底告别逐行读取的原始方…...

紫光同创FPGA网络摄像头方案中,RGMII转GMII模块的Verilog实现与调试避坑指南
紫光同创FPGA网络摄像头方案中RGMII-GMII转换模块的深度解析与实战指南 当你在调试紫光同创FPGA网络摄像头方案时,是否遇到过这样的场景:PHY芯片与FPGA之间的物理层连接已经建立,但网络数据始终无法正常传输?或者上位机接收到的视…...

Verilog数值转换:数字设计工程师必须掌握的底层规则与工程实践
1. 项目概述:为什么Verilog数值转换是数字设计的基石在数字电路设计和FPGA开发中,Verilog是我们描述硬件行为的主要语言。很多刚入行的朋友,包括我当年,都曾以为写Verilog就是写“另一种编程语言”,把C语言或Python的习…...

启扬RK3568核心板如何赋能智能炒菜机:从嵌入式主控到AI烹饪
1. 项目概述:当嵌入式核心板遇上智能炒菜机在餐饮后厨这个看似传统,实则对效率、成本和一致性要求极高的领域,痛点一直非常明确。人工炒菜,老师傅的手艺固然可贵,但出餐速度受限于体力,菜品口味因厨师状态、…...

OpenClaw Provider Manager:统一管理第三方服务的微服务治理框架
1. 项目概述与核心价值最近在折腾一些自动化流程和微服务治理,发现一个挺普遍但处理起来又有点琐碎的问题:如何高效、统一地管理那些分散在各个角落的第三方服务提供商(Provider)?比如短信发送、邮件推送、对象存储、支…...

别再让电池充不满!用CN3791芯片设计太阳能充电电路,这几个调试坑我帮你踩了
太阳能充电电路实战:CN3791芯片调试避坑指南 当阳光洒在太阳能板上,理论上我们应该获得源源不断的清洁能源。但现实往往比理想骨感得多——尤其当你发现精心设计的CN3791充电电路始终无法将锂电池充满时。这不是芯片的错,而是我们在参数设置和…...

AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案
AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...
编制规范与数字化处理流程详解)
[实战] 制造业全尺寸报告(Full Dimension Report)编制规范与数字化处理流程详解
在 2026 年的精密制造与质量管理体系中,全尺寸报告(Full Dimension Report,简称 FDR)已成为首件检验(FAI)和生产件批准程序(PPAP)中不可或缺的核心文档。今天分享一下在数字化工厂环…...

碳纤维板的导电特性
简 介: 碳纤维板导电性能测试表明,其表面有机膜被刺破后会呈现导电性,电阻值从十几欧姆到几百欧姆不等,且导电性能随测量点位置变化。测试中使用尖头万用表探针穿透表面薄膜,发现同一束碳纤维连接处电阻较低࿰…...

OpenVort开源文本嵌入引擎:本地化部署与语义搜索实战指南
1. 项目概述与核心价值最近在折腾一些需要处理大量文本数据的项目,比如日志分析、文档摘要生成,或者是想给自己的应用加个智能问答功能,总是绕不开一个核心环节:如何高效、准确地将非结构化的文本转换成机器能理解的向量。这个“向…...