sklearn之各类朴素贝叶斯原理
sklearn之贝叶斯原理
- 前言
- 1 高斯朴素贝叶斯
- 1.1 对连续变量的处理
- 1.2 高斯朴素贝叶斯算法原理
- 2 多项式朴素贝叶斯
- 2.1 二项分布和多项分布
- 2.2 详细原理
- 2.3 如何判断是否符合多项式贝叶斯
- 3 伯努利朴素贝叶斯
- 4 类别贝叶斯
- 4 补充朴素贝叶斯
- 4.1 核心原理
- 4.2 算法流程
前言
如果想看sklearn之贝叶斯应用可看:Sklearn之朴素贝叶斯应用
贝叶斯的原理可以看:贝叶斯分类器详解
根据这篇文章提到的原理,可知贝叶斯的核心公式是:
y = a r g m a x c k P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) ( 1 ) y=argmax_{c_{k}}P(Y=c_{k})\prod \limits_{j=1}^{n}P(X^{(j)}=x^{(j)}|Y=c_{k}) ~~(1) y=argmaxckP(Y=ck)j=1∏nP(X(j)=x(j)∣Y=ck) (1)
”朴素贝叶斯“的多种变形算法的主要区别在于对条件概率的处理上,即: P ( X ( j ) = x ( j ) ∣ Y = c k ) P(X^{(j)}=x^{(j)}|Y=c_{k}) P(X(j)=x(j)∣Y=ck),接下来围绕着这个公式对多种变形贝叶斯展开原理分析
1 高斯朴素贝叶斯
1.1 对连续变量的处理
例如:设汉堡的重量为特征 X i X_{i} Xi,令 X i = 100 X_{i}=100 Xi=100,则一个汉堡是100g的概率 P ( X i = 100 ∣ Y ) P(X_{i}=100|Y) P(Xi=100∣Y)是多少呢?由于重量是连续型数据,即重量有无数种情况,因此有:
P ( X i = 100 ∣ Y ) = lim N → ∞ 1 N = 0 P(X_{i}=100|Y)=\lim_{N→\infty }\frac{1}{N}=0 P(Xi=100∣Y)=N→∞limN1=0
因此,考虑某点的概率没有任何意义,这种估算方法不可行
考虑换个角度:随机买一个汉堡,汉堡的重量在98g~102g之间的概率是多少?令特征 X i X_{i} Xi的取值为x,即所求概率为 P ( 98 < x < 102 ∣ Y ) P(98<x<102|Y) P(98<x<102∣Y),假设购买了100个汉堡,其中重量在98g-102g的汉堡有m个,则有:
P ( 98 < x < 102 ∣ Y ) = m 100 P(98<x<102|Y)=\frac{m}{100} P(98<x<102∣Y)=100m
基于100个汉堡绘制直方图,并规定每4g为一个区间,横坐标为汉堡的重量的分布,纵坐标为这个区间上汉堡的个数,如下图所示:

此时可以用面积来表示概率,即:
P ( 98 < x < 102 ∣ Y ) = m × 4 100 × 4 = 浅绿色区间面积 直方图所有区间的面积 P(98<x<102|Y)=\frac{m×4}{100×4}=\frac{浅绿色区间面积}{直方图所有区间的面积} P(98<x<102∣Y)=100×4m×4=直方图所有区间的面积浅绿色区间面积
如图购买10w个汉堡的直方图所示,其类似一条曲线,因此,当购买无数个汉堡的时候形成的曲线就叫做概率密度曲线(probability density function,PDF),此时整条曲线的面积表示为: ∫ − ∞ + ∞ f ( x ) d x \int_{-\infty}^{+\infty}f(x)dx ∫−∞+∞f(x)dx
此时对于连续特征X的取值x在区间 [ x i , x i + ϵ ] [x_{i},x_{i}+ϵ] [xi,xi+ϵ]的取值概率为:
P ( x i < x < x i + ϵ ∣ Y ) = ∫ x i x i + ϵ f ( x ) d x ≈ f ( x i ) × ϵ P(x_{i}<x<x_{i}+ϵ|Y)=\int_{x_{i}}^{x_{i}+ϵ}f(x)dx≈f(x_{i})×ϵ P(xi<x<xi+ϵ∣Y)=∫xixi+ϵf(x)dx≈f(xi)×ϵ
从贝叶斯分类器详解这篇文章可知公式:
y = f ( x ) = a r g m a x c k P ( Y = c k ∣ X = x ) = P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) ∑ k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) y=f(x)=argmax_{c_{k}}P(Y=c_{k}|X=x) = \frac{P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_{k})}{\sum_{k}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_{k})} y=f(x)=argmaxckP(Y=ck∣X=x)=∑kP(Y=ck)∏jP(X(j)=x(j)∣Y=ck)P(Y=ck)∏jP(X(j)=x(j)∣Y=ck)
通过上述式子可知:ϵ可以相互抵消,则仅用 f ( x i ) f(x_{i}) f(xi)就可以估算 P ( x i ∣ Y ) P(x_{i}|Y) P(xi∣Y)了,即将求解连续型变量下某个点取值的概率问题,转化成了求解一个函数 f ( x ) f(x) f(x)在点 x i x_{i} xi上的取值的问题。令 f ( x ) f(x) f(x)服从高斯分布,用该 f ( x ) f(x) f(x)去估算条件概率 P ( x i ∣ Y ) P(x_{i}|Y) P(xi∣Y),这就是高斯朴素贝叶斯
1.2 高斯朴素贝叶斯算法原理
(1)原理
根据上述结论有:高斯贝叶斯算法假定数据样本在各个类别下,每个特征变量的条件概率均服从高斯分布 f ( x ) f(x) f(x),即:
f ( x i ) = p ( x i ∣ y c ) = 1 2 π σ c i 2 e x p ( − ( x i − μ c i ) 2 2 σ c i 2 ) f(x_{i})=p(x_{i}|y_{c})=\frac{1}{\sqrt{2\pi\sigma_{ci}^{2}}}exp(-\frac{(x_{i}-\mu_{ci})^{2}}{2\sigma_{ci}^{2}}) f(xi)=p(xi∣yc)=2πσci21exp(−2σci2(xi−μci)2)
- 其中表示第 i i i个特征维度, σ c i \sigma_{ci} σci和 μ c i \mu_{ci} μci分别表示在类别 y = c y=c y=c下特征 x i x_{i} xi对应的标准差与期望。注意:这和1.1里面所讲的 x i x_{i} xi不是一个意思
由前言可知,之后进行极大化后验概率,为了防止下溢(结果小于所能表示的最小值的情况),因此取对数(以e为底),可得:
y = a r g m a x y c l o g ( P ( y c ) ∏ i = 0 n P ( x i ∣ y c ) ) = a r g m a x y c l o g ( P ( y c ) ∏ i = 0 n 1 2 π σ c i 2 e x p ( − ( x i − μ c i ) 2 2 σ c i 2 ) ) = a r g m a x y c [ l o g P ( y c ) + ∑ i = 0 n l o g ( 1 2 π σ c i 2 e x p ( − ( x i − μ c i ) 2 2 σ c i 2 ) ) ] = a r g m a x y c ( l o g P ( y c ) − 1 2 ∑ i = 0 n l o g 2 π σ c i 2 − 1 2 ∑ i = 0 n ( x i − μ c i ) 2 σ c i 2 ) \begin {aligned} {} y &=argmax_{y_{c}}log(P(y_{c})\prod\limits_{i=0}^{n}P(x_{i}|y_{c})) \\ &=argmax_{y_{c}}log(P(y_{c})\prod\limits_{i=0}^{n}\frac{1}{\sqrt{2\pi\sigma_{ci}^{2}}}exp(-\frac{(x_{i}-\mu_{ci})^{2}}{2\sigma_{ci}^{2}}))\\ & =argmax_{y_{c}}\begin{bmatrix} logP(y_{c})+\sum\limits_{i=0}^{n}log(\frac{1}{\sqrt{2\pi\sigma_{ci}^{2}}}exp(-\frac{(x_{i}-\mu_{ci})^{2}}{2\sigma_{ci}^{2}})) \end{bmatrix}\\ &=argmax_{y_{c}}(logP(y_{c})-\frac{1}{2}\sum\limits_{i=0}^{n}log2π\sigma_{ci}^{2}-\frac{1}{2}\sum\limits_{i=0}^{n}\frac{(x_{i}-\mu_{ci})^{2}}{\sigma_{ci}^{2}}) \end {aligned} y=argmaxyclog(P(yc)i=0∏nP(xi∣yc))=argmaxyclog(P(yc)i=0∏n2πσci21exp(−2σci2(xi−μci)2))=argmaxyc[logP(yc)+i=0∑nlog(2πσci21exp(−2σci2(xi−μci)2))]=argmaxyc(logP(yc)−21i=0∑nlog2πσci2−21i=0∑nσci2(xi−μci)2)
(2)示例
假设有如下连续型数据,一共有两个特征 x 0 x_{0} x0、 x 1 x_{1} x1,如下表所示,预测x=[0.15,0.25]所属的类别,对数以底数e为底
| 样本 | x 0 x_{0} x0 | x 1 x_{1} x1 | 所属类别 |
|---|---|---|---|
| 0 | 0.3 | 0.5 | 0 |
| 1 | 0.4 | 0.6 | 0 |
| 2 | 0.7 | 0.9 | 1 |
| 3 | 0.6 | 0.7 | 1 |
第一步:求先验概率
P ( y = 0 ) = l o g 1 2 ≈ − 0.693 P(y=0)=log\frac{1}{2}≈-0.693 P(y=0)=log21≈−0.693
P ( y = 1 ) = l o g 1 2 ≈ − 0.693 P(y=1)=log\frac{1}{2}≈-0.693 P(y=1)=log21≈−0.693
第二步:求方差和期望
在 y = 0 和 x 0 y=0和x_{0} y=0和x0时,对应的期望和方差分别为:
μ 00 = 0.3 + 0.4 2 = 0.35 \mu_{00}=\frac{0.3+0.4}{2}=0.35 μ00=20.3+0.4=0.35
σ 00 2 = ( 0.3 − 0.35 ) 2 + ( 0.4 − 0.35 ) 2 2 = 0.0025 \sigma_{00}^{2}=\frac{(0.3-0.35)^{2}+(0.4-0.35)^2}{2}=0.0025 σ002=2(0.3−0.35)2+(0.4−0.35)2=0.0025
同理,最终可得期望矩阵和方差矩阵
μ = [ 0.35 0.55 0.65 0.8 ] \mu=\begin{bmatrix} 0.35&0.55 \\ 0.65& 0.8 \end{bmatrix} μ=[0.350.650.550.8]
σ 2 = [ 0.0025 0.0024 0.0025 0.01 ] \sigma^{2}=\begin{bmatrix} 0.0025& 0.0024\\ 0.0025 & 0.01 \end{bmatrix} σ2=[0.00250.00250.00240.01]
第三步:求条件概率
对于x=[0.15,0.25],当 y = 0 y=0 y=0时,有:
P ( x ∣ y = 0 ) = − 1 2 ∑ i = 0 n l o g 2 π σ 0 i 2 − 1 2 ∑ i = 0 n ( x i − μ 0 i ) 2 σ 0 i 2 = − 1 2 [ l o g ( 2 π × 0.0025 ) + l o g ( 2 π × 0.0024 ) ] − 1 2 [ ( 0.15 − 0.35 ) 2 0.0025 + ( 0.25 − 0.55 ) 2 0.0024 ] ≈ − 22.576 \begin {aligned} {} P(x|y=0)& =-\frac{1}{2}\sum\limits_{i=0}^{n}log2π\sigma_{0i}^{2}-\frac{1}{2}\sum\limits_{i=0}^{n}\frac{(x_{i}-\mu_{0i})^{2}}{\sigma_{0i}^{2}} \\&=-\frac{1}{2} [log(2π×0.0025)+log(2π×0.0024)]-\frac{1}{2}[\frac{(0.15-0.35)^{2}}{0.0025}+\frac{(0.25-0.55)^{2}}{0.0024}] \\ &≈-22.576 \end {aligned} P(x∣y=0)=−21i=0∑nlog2πσ0i2−21i=0∑nσ0i2(xi−μ0i)2=−21[log(2π×0.0025)+log(2π×0.0024)]−21[0.0025(0.15−0.35)2+0.0024(0.25−0.55)2]≈−22.576
同理可得:
P ( x ∣ y = 1 ) ≈ − 61.665 P(x|y=1)≈-61.665 P(x∣y=1)≈−61.665
第四步:求结果
对于x=[0.15,0.25],当 y = 0 y=0 y=0时,有:
P ( y = 0 ∣ x ) = P ( y = 0 ) + P ( x ∣ y = 0 ) = − 0.693 − 22.576 = − 23.269 P(y=0|x)=P(y=0)+P(x|y=0)=-0.693-22.576=-23.269 P(y=0∣x)=P(y=0)+P(x∣y=0)=−0.693−22.576=−23.269
对于x=[0.15,0.25],当 y = 1 y=1 y=1时,有:
P ( y = 1 ∣ x ) = P ( y = 1 ) + P ( x ∣ y = 1 ) = − 0.693 − 61.665 = − 62.358 P(y=1|x)=P(y=1)+P(x|y=1)=-0.693-61.665=-62.358 P(y=1∣x)=P(y=1)+P(x∣y=1)=−0.693−61.665=−62.358
综上,x属于y=0的概率最大,故x属于y=0这个类别
2 多项式朴素贝叶斯
2.1 二项分布和多项分布
(1)二项分布

(2)多项分布

2.2 详细原理
(1)原理
多项式朴素贝叶斯处理词袋模型时,则是将每个维度的词频在总词频中的占比来作为条件概率进行建模(一般使用词频法和TF-IDF表示法来配合多项式朴素贝叶斯的使用,这里讲的是词频法,详情见词袋模型)
多项式朴素贝叶斯中,在一种标签类别 Y = c Y=c Y=c下,将条件概率分布的分布参数化为 θ c = ( θ c 1 , θ c 2 , ⋯ , θ c n ) \theta_{c}=(\theta_{c1},\theta_{c2},\cdots,\theta_{cn}) θc=(θc1,θc2,⋯,θcn)
- n表示训练集中的特征维度
- θ c i \theta_{ci} θci是类别c下特征i的条件概率 P ( x i ∣ Y = c ) P(x_{i}|Y=c) P(xi∣Y=c),表示当 Y = c Y=c Y=c条件固定时,一组样本在 x i x_{i} xi特征上的取值被取到的概率
参数通过极大似然估计可得:
θ c i = N c i N c \theta_{ci}=\frac{N_{ci}}{N_{c}} θci=NcNci
- 其中 N c i N_{ci} Nci表示在训练集T中样本属于 Y = c Y=c Y=c类别下特征为 i i i的出现的频次,即 N c i = ∑ x ∈ T x i N_{ci}=\sum_{x \in T }x_{i} Nci=∑x∈Txi
- N c N_{c} Nc表示在训练集T中样本属于 Y = c Y=c Y=c类别下所有特征的总频次,即 N c = ∑ i = 1 n N c i N_{c}=\sum\limits_{i=1}^{n}N_{ci} Nc=i=1∑nNci。
令α>0来防止训练数据中出现0概率,以避免让参数θ为0的情况,可得如下式子:
θ c i = N c i + α N c + α n \theta_{ci}=\frac{N_{ci}+\alpha }{N_{c}+\alpha n} θci=Nc+αnNci+α
- 将α设置为1,则这个平滑叫做拉普拉斯平滑
- 如果α小于1,则把它叫做利德斯通平滑
- 两种平滑都属于自然语言处理中比较常用的用来平滑分类数据的统计手段
由前言可知,之后进行极大化后验概率,为了防止下溢(结果小于所能表示的最小值的情况),因此取对数,可得:
y = a r g m a x c k l o g ( P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) ) y=argmax_{c_{k}}log(P(Y=c_{k})\prod \limits_{j=1}^{n}P(X^{(j)}=x^{(j)}|Y=c_{k})) y=argmaxcklog(P(Y=ck)j=1∏nP(X(j)=x(j)∣Y=ck))
由对数性质可知:
y = a r g m a x c k [ l o g ( P ( Y = c k ) ) + ∑ j = 1 n l o g ( P ( X ( j ) = x ( j ) ∣ Y = c k ) ) ] y=argmax_{c_{k}}[log(P(Y=c_{k}))+\sum\limits_{j=1}^{n}log(P(X^{(j)}=x^{(j)}|Y=c_{k}))] y=argmaxck[log(P(Y=ck))+j=1∑nlog(P(X(j)=x(j)∣Y=ck))]
条件概率计算的是训练集中特征维度的词频在总词频中的占比,而某个特征(即词语)可能出现多次,因此会出现连乘,在取对数的情况下,变成了加和(例如词语文本aab,特征a出现了两次),因此需要同时考虑到每个维度的词频:
y = a r g m a x c k [ l o g ( P ( Y = c k ) ) + ∑ j = 1 n f i l o g ( P ( X ( j ) = x ( j ) ∣ Y = c k ) ) ] y=argmax_{c_{k}}[log(P(Y=c_{k}))+\sum\limits_{j=1}^{n}f_{i}log(P(X^{(j)}=x^{(j)}|Y=c_{k}))] y=argmaxck[log(P(Y=ck))+j=1∑nfilog(P(X(j)=x(j)∣Y=ck))]
- 其中 f i f_{i} fi表示特征维度i的词频
(2)例子
下述例子对数都以10为底
例子1
在词袋模型这篇文章中,中,由词频法的例子并假设都在类别Y=c中,可得:
| Beijing | Chinese | Japan | Macao | Shanghai | Tokyo | Y | |
|---|---|---|---|---|---|---|---|
| Chinese Beijing Chinese | 1 | 2 | 0 | 0 | 0 | 0 | c |
| Chinese Chinese Shanghai | 0 | 2 | 0 | 0 | 1 | 0 | c |
| Chinese Macao | 0 | 1 | 0 | 1 | 0 | 0 | c |
| Tokyo Japan Chinese | 0 | 1 | 1 | 0 | 0 | 1 | c |
如上表格就是一个特征矩阵,行代表样本,列代表特征维度
仅以BeiJing特征作为例子,取α=1,求条件概率得:
θ = P ( B e i J i n g ∣ Y = c ) = 1 + 1 11 + 6 = 2 17 \theta=P(BeiJing|Y=c)=\frac{1+1}{11+6}=\frac{2}{17} θ=P(BeiJing∣Y=c)=11+61+1=172
例子2
对类别和特征进行修改,为了方便,这里不再做平滑处理,如下所示:
| Beijing | Shanghai | Y | |
|---|---|---|---|
| Beijing Beijing Beijing Shanghai | 3 | 1 | 0 |
| Beijing Shanghai Shanghai | 1 | 2 | 1 |
现预测x=[25,2]所属的类别,取α=1
第一步:算各个类别的先验概率
P ( Y = 0 ) = l o g ( 1 2 ) ≈ − 0.30 P ( Y = 1 ) = l o g ( 1 2 ) ≈ − 0.30 P(Y=0)=log(\frac{1}{2})\approx -0.30 \\ \enspace \\ P(Y=1)=log(\frac{1}{2})\approx -0.30 P(Y=0)=log(21)≈−0.30P(Y=1)=log(21)≈−0.30
第二步:算条件概率
在类别Y=0的情况下有:
P ( B e i j i n g ∣ Y = 0 ) = l o g ( 3 3 + 1 ) ≈ − 0.12 P ( S h a n g h a i ∣ Y = 0 ) = l o g ( 1 3 + 1 ) ≈ − 0.60 P(Beijing|Y=0)=log(\frac{3}{3+1})\approx -0.12 \\ \enspace \\ P(Shanghai|Y=0)=log(\frac{1}{3+1})\approx -0.60 P(Beijing∣Y=0)=log(3+13)≈−0.12P(Shanghai∣Y=0)=log(3+11)≈−0.60
在类别Y=1的情况下有:
P ( B e i j i n g ∣ Y = 1 ) = l o g ( 1 1 + 2 ) ≈ − 0.48 P ( S h a n g h a i ∣ Y = 1 ) = l o g ( 2 1 + 2 ) ≈ − 0.18 P(Beijing|Y=1)=log(\frac{1}{1+2})\approx -0.48 \\ \enspace \\ P(Shanghai|Y=1)=log(\frac{2}{1+2})\approx -0.18 P(Beijing∣Y=1)=log(1+21)≈−0.48P(Shanghai∣Y=1)=log(1+22)≈−0.18
第三步:求后验概率
P ( Y = 0 ∣ x ) = P ( Y = 0 ) + 25 × P ( B e i j i n g ∣ Y = 0 ) + 2 × P ( S h a n g h a i ∣ Y = 0 ) = − 0.30 + 25 × − 0.12 + 2 × − 0.60 = − 4.5 P ( Y = 1 ∣ x ) = P ( Y = 1 ) + 25 × P ( B e i j i n g ∣ Y = 1 ) + 2 × P ( S h a n g h a i ∣ Y = 1 ) = − 0.30 + 25 × − 0.48 + 2 × − 0.18 = − 12.66 \begin {aligned} {} P(Y=0|x) & =P(Y=0)+25 \times P(Beijing|Y=0) +2\times P(Shanghai|Y=0) \\ & =-0.30+25\times -0.12+2\times-0.60\\ & =-4.5 \end {aligned}\\ \enspace \\ \begin {aligned} {} P(Y=1|x) & =P(Y=1)+25 \times P(Beijing|Y=1) +2\times P(Shanghai|Y=1) \\ & =-0.30+25\times -0.48+2\times-0.18\\ & =-12.66 \end {aligned} P(Y=0∣x)=P(Y=0)+25×P(Beijing∣Y=0)+2×P(Shanghai∣Y=0)=−0.30+25×−0.12+2×−0.60=−4.5P(Y=1∣x)=P(Y=1)+25×P(Beijing∣Y=1)+2×P(Shanghai∣Y=1)=−0.30+25×−0.48+2×−0.18=−12.66
显然在类别为0时概率更大,综上所述,x属于类0
2.3 如何判断是否符合多项式贝叶斯
根据多项分布的概念,以词袋模型为例,在文本分类中有如下假设:
- 不考虑文本中单词之间的次序,即认为这两个文本‘ Love and Peace’和‘ Peace and Love’最后建模出来对应于同一个特征向量。不考虑文本单词之间的次序,会导致文本语义丢失。
- 在类别为Y=c的文本中,每个单词的出现是相互独立。即在类别为Y=c的文本中,每次随机试验为随机从词表中抽取一个单词,进行n次独立重复试验。
第2个假设只有满足了才保证了文本的特征随机向量 X X X满足多项式分布,即给定类别Y=c的文本,满足:
X ∼ M u l t i N o r m i a l ( n , θ c 1 , θ c 2 , ⋯ , θ c n ) X\sim MultiNormial(n,\theta_{c1},\theta_{c2},\cdots,\theta_{cn}) X∼MultiNormial(n,θc1,θc2,⋯,θcn)
即满足了上述要求,可用多项式朴素贝叶斯推导过程里的方法求条件概率
3 伯努利朴素贝叶斯
(1)原理
BernoulliNB实现了按多元伯努利分布的数据的朴素贝叶斯训练和分类算法,即可能有多个特征,但每个特征都被假定为一个二元值(Bernoulli,boole)变量。因此,该类要求样本被表示为二值化的特征向量
伯努利朴素贝叶斯计算 P ( x i ∣ y ) P(x_{i}|y) P(xi∣y)仍然用到多项式朴素贝叶斯的方法:
θ c i = N c i + α N c + α n \theta_{ci}=\frac{N_{ci}+\alpha }{N_{c}+\alpha n} θci=Nc+αnNci+α
但伯努利朴素贝叶斯对条件概率新增处理是:
P ( x i ∣ y ) = P ( i ∣ y ) x i + ( 1 − P ( i ∣ y ) ( 1 − x i ) P(x_{i}|y)=P(i|y)x_{i}+(1-P(i|y)(1-x_{i}) P(xi∣y)=P(i∣y)xi+(1−P(i∣y)(1−xi)
- 与多项式朴素贝叶斯的区别是,明确惩罚特征i的不出现,而多项式朴素贝叶斯会忽略未出现的特征
(2)例子
上述原理会觉得很难理解,给定具体例子就很好理解了,使用词袋模型这篇文章中所提到的独热法,得到下述数据:
| Beijing | Shanghai | Y | |
|---|---|---|---|
| Beijing Beijing | 1 | 0 | 0 |
| Shanghai Shanghai | 0 | 1 | 1 |
| Shanghai Beijing | 1 | 1 | 2 |
为了方便,这里不再取对数且不做平滑处理,假设有一文本x为:Beijing,那它应该属于哪个类别?
第一步:算各个类别的先验概率
P ( Y = 0 ) = 1 3 P ( Y = 1 ) = 1 3 P ( Y = 2 ) = 1 3 P(Y=0)=\frac{1}{3} \\ \enspace \\ P(Y=1 )=\frac{1}{3} \\ \enspace \\ P(Y=2 )=\frac{1}{3} P(Y=0)=31P(Y=1)=31P(Y=2)=31
第二步:算条件概率
在类别Y=0的情况下有:
P ( B e i j i n g ∣ Y = 0 ) = 1 1 + 0 ) = 1 P ( S h a n g h a i ∣ Y = 0 ) = 0 1 + 0 = 0 P(Beijing|Y=0)=\frac{1}{1+0})=1 \\ \enspace \\ P(Shanghai|Y=0)=\frac{0}{1+0}=0 P(Beijing∣Y=0)=1+01)=1P(Shanghai∣Y=0)=1+00=0
在类别Y=1的情况下有:
P ( B e i j i n g ∣ Y = 1 ) = 0 1 + 0 = 0 P ( S h a n g h a i ∣ Y = 1 ) = 1 1 + 0 = 1 P(Beijing|Y=1)=\frac{0}{1+0}=0 \\ \enspace \\ P(Shanghai|Y=1)=\frac{1}{1+0}=1 P(Beijing∣Y=1)=1+00=0P(Shanghai∣Y=1)=1+01=1
在类别Y=2的情况下有:
P ( B e i j i n g ∣ Y = 2 ) = 1 1 + 1 = 0.5 P ( S h a n g h a i ∣ Y = 2 ) = 1 1 + 1 = 0.5 P(Beijing|Y=2)=\frac{1}{1+1}=0.5 \\ \enspace \\ P(Shanghai|Y=2)=\frac{1}{1+1}=0.5 P(Beijing∣Y=2)=1+11=0.5P(Shanghai∣Y=2)=1+11=0.5
第三步:求后验概率
P ( Y = 0 ∣ x ) = P ( Y = 0 ) × P ( B e i j i n g ∣ Y = 0 ) × (1-P(Shanghai|Y=0)) = 1 3 P ( Y = 1 ∣ x ) = P ( Y = 1 ) × P ( B e i j i n g ∣ Y = 1 ) × (1-P(Shanghai|Y=1)) = 0 P ( Y = 2 ∣ x ) = P ( Y = 2 ) × P ( B e i j i n g ∣ Y = 2 ) × (1-P(Shanghai|Y=2)) = 1 12 P(Y=0|x) =P(Y=0)×P(Beijing|Y=0)× \textbf{(1-P(Shanghai|Y=0))} =\frac{1}{3} \\ \enspace \\ P(Y=1|x) =P(Y=1)×P(Beijing|Y=1)× \textbf{(1-P(Shanghai|Y=1))} =0 \\ \enspace \\ P(Y=2|x) =P(Y=2)×P(Beijing|Y=2)× \textbf{(1-P(Shanghai|Y=2))} =\frac{1}{12} P(Y=0∣x)=P(Y=0)×P(Beijing∣Y=0)×(1-P(Shanghai|Y=0))=31P(Y=1∣x)=P(Y=1)×P(Beijing∣Y=1)×(1-P(Shanghai|Y=1))=0P(Y=2∣x)=P(Y=2)×P(Beijing∣Y=2)×(1-P(Shanghai|Y=2))=121
因此属于类0,上述加粗算式就是伯努利朴素贝叶斯的改进地方。对于某一个文本,若不存在该单词,若某类该单词概率越高,通过上述加粗算式的操作,使得该文本出现在该类的概率越低,这就是惩罚,而多项式朴素贝叶斯没有这种操作。
4 类别贝叶斯
(1)原理
这篇文章:贝叶斯分类器详解中所说的算法实际上就是朴素贝叶斯(可以直接看这篇文章即可),对条件概率的处理是:
P ( x i = t ∣ y = c ) = N t i c + α N c + α n i P(x_{i}=t|y=c)=\frac{N_{tic}+α}{N_{c}+αn_{i}} P(xi=t∣y=c)=Nc+αniNtic+α
- N t i c N_{tic} Ntic是样本特征 x i x_{i} xi中出现类 t t t的次数,这些样本属于类别c; N c N_{c} Nc属于c类的样本数, n i n_{i} ni是特征i的可用类别数
- 将α设置为1,则这个平滑叫做拉普拉斯平滑
- 如果α小于1,则把它叫做利德斯通平滑
- 两种平滑都属于自然语言处理中比较常用的用来平滑分类数据的统计手段
(2)例子

对先验概率也做了一定的处理,可以忽略,重在看懂条件概率的处理过程

4 补充朴素贝叶斯
4.1 核心原理
(1)多项式朴素贝叶斯公式改写
前面已经说过,多项式朴素贝叶斯的核心公式是:
θ c i = N c i + α N c + α n \theta_{ci}=\frac{N_{ci}+\alpha }{N_{c}+\alpha n} θci=Nc+αnNci+α
现假设在标签类别下 Y = c Y=c Y=c下,结构为(m,n)的特征矩阵如下:
X y = [ x 11 x 12 x 13 ⋯ x 1 n x 21 x 22 x 23 ⋯ x 2 n x 31 x 32 x 33 ⋯ x 3 n ⋯ x m 1 x m 2 x m 3 ⋯ x m n ] X_{y}=\begin{bmatrix} x_{11} & x_{12} &x_{13} & \cdots & x_{1n} \\ x_{21} & x_{22} & x_{23} &\cdots & x_{2n} \\ x_{31} & x_{32} & x_{33} &\cdots & x_{3n} \\ & & \cdots & & \\ x_{m1} & x_{m2} & x_{m3} &\cdots & x_{mn} \end{bmatrix} Xy= x11x21x31xm1x12x22x32xm2x13x23x33⋯xm3⋯⋯⋯⋯x1nx2nx3nxmn
- x j i x_{ji} xji表示样本 j j j的特征 i i i发生的次数,样本数为行,特征为列
根据该特征矩阵,可以对多项式朴素贝叶斯核心公式进行改写,如下:
θ c i = ∑ y i = c x j i + α ∑ i = 1 n ∑ y i = c x j i + α n \theta_{ci}=\frac{\sum_{y_{i}=c}x_{ji} +\alpha }{\sum_{i=1}^{n}\sum_{y_{i}=c}x_{ji}+\alpha n} θci=∑i=1n∑yi=cxji+αn∑yi=cxji+α
(2)补充朴素贝叶斯原理
其使用来自每个标签类别的补集的概率,并以此来计算每个特征的权重,如下:
θ i , y ≠ c = α i + ∑ y i ≠ c x i j α + ∑ i , y ≠ c ∑ i = 1 n x i j \theta_{i,y≠c}=\frac {\alpha_{i} + \sum_{y_{i}≠c}x_{ij} } {\alpha + \sum_{i,y≠c}\sum_{i=1}^{n}x_{ij}} θi,y=c=α+∑i,y=c∑i=1nxijαi+∑yi=cxij
- x i j x_{ij} xij表示样本 j j j上对于特征 i i i下的取值,特征为行,样本为列
- ∑ y i ≠ c x i j \sum_{y_{i}≠c}x_{ij} ∑yi=cxij指特征 i i i下,所有标签类别不为 c c c的样本的特征取值之和
- ∑ i , y ≠ c ∑ i = 1 n x i j \sum_{i,y≠c}\sum_{i=1}^{n}x_{ij} ∑i,y=c∑i=1nxij指所有特征下,所有标签类别不为 c c c的样本的特征取值之和
- α = ∑ i α i \alpha=\sum_{i}\alpha_{i } α=∑iαi
从上述公式可以看出:这就是多项式朴素贝叶斯的逆向思路
为了防止下溢,对其取对数,有:
w c i = l o g θ i , y ≠ c w_{ci}=log\theta_{i,y≠c} wci=logθi,y=c
还可以选择除以它的L2范式,以解决了在多项式分布中,特征取值比较多的样本(比如说比较长的文档)支配参数估计的情况。如下:
w c i = l o g θ i , y ≠ c ∑ j ∣ l o g θ i , y ≠ c ∣ w_{ci}=\frac {log\theta_{i,y≠c}} {\sum_{j}|log\theta_{i,y≠c}|} wci=∑j∣logθi,y=c∣logθi,y=c
例如,样本1在参数估计中权重显然更大:
| 样本1 | 样本2 | |
|---|---|---|
| x 1 x_{1} x1 | 5 | 0 |
| x 2 x_{2} x2 | 1 | 1 |
基于 w c i w_{ci} wci,对于一个样本 X X X, x i x_{i} xi是样本 X X X的特征,补充朴素贝叶斯的一个样本预测规则为:
P ( Y ≠ c ∣ X ) = a r g m i n c ∑ i x i w c i P(Y≠c|X)=argmin_{c}\sum\limits_{i}x_{i}w_{ci} P(Y=c∣X)=argminci∑xiwci
即我们求解出的最小补集概率所对应的标签就是样本的标签,因为 Y ≠ c Y≠c Y=c的概率越小,则 Y = c Y=c Y=c概率越大,因此属于类 c c c
4.2 算法流程
补充朴素贝叶斯的算法流程
令 X = { x 1 , ⋯ , x n } X=\{x_{1},\cdots,x_{n}\} X={x1,⋯,xn}是一组数据集, x i j x_{ij} xij是 j j j文本中单词 i i i的计数
令 Y = { y 1 , ⋯ , y n } Y=\{y_{1},\cdots,y_{n}\} Y={y1,⋯,yn}是该组数据集的标签
输入X和Y:
- x i j = l o g ( x i j + 1 ) \large{x_{ij}=log(x_{ij}+1)} xij=log(xij+1)
- x i j = x i j l o g ∑ k 1 ∑ k δ i k \large{x_{ij}=x_{ij}log\frac{\sum_{k}1}{\sum_{k}δ_{ik}}} xij=xijlog∑kδik∑k1
- x i j = x i j ∑ k ( x k j ) 2 \large{x_{ij}=\frac{x_{ij}}{\sqrt{\sum_{k}(x_{kj})^{2}}}} xij=∑k(xkj)2xij
- θ i , y ≠ c = α i + ∑ y i ≠ c x i j α + ∑ i , y ≠ c ∑ i = 1 n x i j \large{\theta_{i,y≠c}=\frac{\alpha_{i} + \sum_{y_{i}≠c}x_{ij} }{\alpha + \sum_{i,y≠c}\sum_{i=1}^{n}x_{ij}}} θi,y=c=α+∑i,y=c∑i=1nxijαi+∑yi=cxij
- w c i = l o g θ i , y ≠ c \large{w_{ci}=log\theta_{i,y≠c}} wci=logθi,y=c
- w c i = w c i ∑ i w c i \large{w_{ci}=\frac{w_{ci}}{\sum_{i}w_{ci}}} wci=∑iwciwci
- 令 t = { t 1 , ⋯ , t n } t=\{t_{1},\cdots,t_{n}\} t={t1,⋯,tn}是测试文本, t i t_{i} ti是单词 i i i的计数
- 最后基于预测规则求出所属类别: l ( t ) = a r g m i n c ∑ i t i w c i l(t)=argmin_{c}\sum\limits_{i}t_{i}w_{ci} l(t)=argminci∑tiwci
这里对一些细节进行说明:
- x i j = l o g ( x i j + 1 ) \large{x_{ij}=log(x_{ij}+1)} xij=log(xij+1)可以更真实地处理文本,同时具备多项式朴素贝叶斯的优势
- x i j = x i j l o g ∑ k 1 ∑ k δ i k \large{x_{ij}=x_{ij}log\frac{\sum_{k}1}{\sum_{k}δ_{ik}}} xij=xijlog∑kδik∑k1对于 δ i k δ_{ik} δik,若单词 i i i出现在文本 k k k上,则 δ i k = 1 δ_{ik}=1 δik=1,否则为0。这个方法是为了对那些在每篇文档都出现的字进行处理,这些字不太重要,具体可看词袋模型的TF-IDF方法
- x i j = x i j ∑ k ( x k j ) 2 \large{x_{ij}=\frac{x_{ij}}{\sqrt{\sum_{k}(x_{kj})^{2}}}} xij=∑k(xkj)2xij文本中词的相互依赖性很强,一个词首次出现在文本中后,就更有可能再一次出现。由于朴素贝叶斯假定发生独立,冗长的文本会对参数估计产生负面影响。因此标准化文本单词数避免这个问题
相关文章:
sklearn之各类朴素贝叶斯原理
sklearn之贝叶斯原理 前言1 高斯朴素贝叶斯1.1 对连续变量的处理1.2 高斯朴素贝叶斯算法原理 2 多项式朴素贝叶斯2.1 二项分布和多项分布2.2 详细原理2.3 如何判断是否符合多项式贝叶斯 3 伯努利朴素贝叶斯4 类别贝叶斯4 补充朴素贝叶斯4.1 核心原理4.2 算法流程 前言 如果想看…...

年薪50w+的项目经理,手把手教你如何复盘
复盘是一种重要的学习和改进工具,对于项目经理来说,能帮助识别项目中的成功与失败,为未来的项目管理提供宝贵经验。 理论部分 定义目标。在开始复盘之前,明确复盘的目标是什么。是为了找出项目中的问题并提出解决方案,…...

Web3新视野:Lumoz节点的潜力与收益解读
摘要:低估值、高回报、无条件退款80%...... Lumoz正通过其 zkVerifier 节点销售活动,引领一场ZK计算革命。 长期以来,加密市场以其独特的波动性和增长潜力,持续吸引着全球投资者的目光。而历史数据表明,市场往往在一年…...

【shell脚本速成】mysql备份脚本
文章目录 案例需求脚本应用场景:解决问题脚本思路实现代码 🌈你好呀!我是 山顶风景独好 🎈欢迎踏入我的博客世界,能与您在此邂逅,真是缘分使然!😊 🌸愿您在此停留的每一刻…...
高考志愿填报,理科生如何分析选专业?
理科生选择专业的范围更大一些,相比文科说理工科的院校也更多,如何选择适合自己的专业,这是一个比较重要的课题,毕竟大学专业直接关系到职业,是一辈子的大事。 那么理科究竟如何选择专业呢?需要从什么地方…...

qt 简单实验 json格式的文件写入配置文件
1.概要 2.代码 //#include "mainwindow.h"#include <QApplication> #include <QFile> #include <QJsonDocument> #include <QJsonObject> //读取json数据的配置文件int main(int argc, char *argv[]) {QApplication a(argc, argv);QString…...

将WIN10的wifi上网分享给以太网接口
目录 打开网络设置设置属性点这里的设置将wlan主机的以太网接口IP设为自动获取 如果连接不成功,拔网线重连一次 打开网络设置 设置属性 点这里的设置 将wlan主机的以太网接口IP设为自动获取 如果连接不成功,拔网线重连一次...

在 iPhone 上恢复已删除联系人的 5 种简便方法
想象一下:您正在 iPhone 上滚动并搜索要拨打的联系人,但却找不到任何结果。然后您想起昨晚您试图删除一个名字相似的联系人,但不知何故删除了错误的联系人。或者您的孩子错误地删除了一些联系人。这些情况足以让您感到迷茫。但别担心…...

小白指南:前端使用javascript如何判断集合是不是空集合?
背景 最近在开发一个Web应用时,我遇到了一个关于集合处理的问题。具体来说,我需要判断一个集合是否为空。集合可以是数组、对象、Map或Set等不同的数据结构。就简单的整理了一下如何在JavaScript中有效地判断一个集合是否为空呢? 解决方案 …...
人力资源招聘社会校企类型招聘系统校园招聘小程序
校企社会人力资源招聘小程序:开启高效招聘新时代 🚀开篇:打破传统,开启招聘新篇章 在快速发展的现代社会,人力资源招聘已经成为企业和学校共同关注的重要议题。为了更高效、便捷地满足双方的招聘需求,一款…...
docker重要操作与直连方法
文章目录 前言一、nvidia-docker安装方法1、nvidia-docker安装2、重启动ssh 二、构建镜像1、构建镜像docker拉取构建本地镜像加载构建 2、容器转镜像3、镜像打包4、删除镜像 三、构建容器1、容器构建2、启动镜像3、删除容器 四、docker直连(ssh -p)1、docker更改密码2、物理机操…...
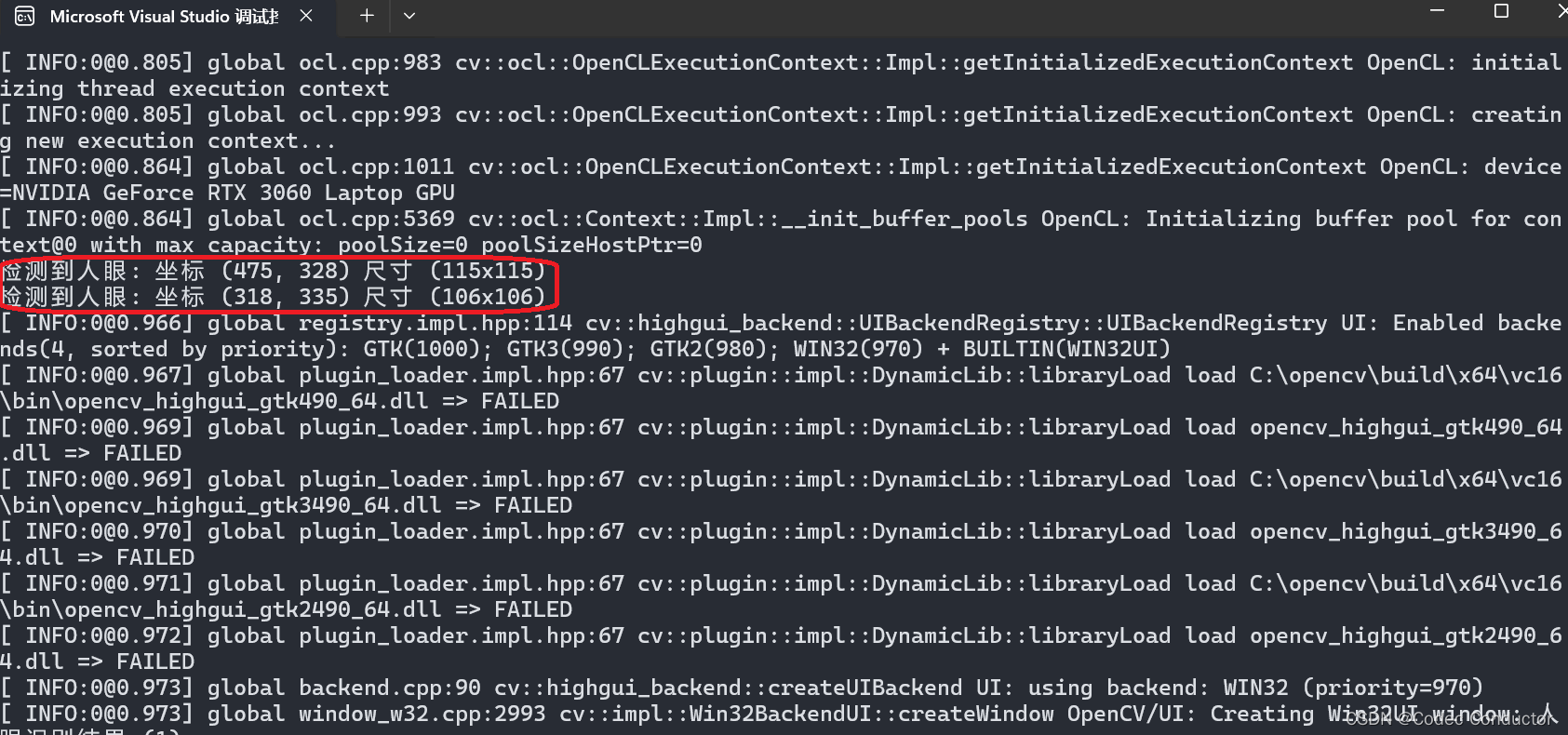
Windows环境利用 OpenCV 中 CascadeClassifier 分类器识别人眼 c++
Windows环境中配置OpenCV 关于在Windows环境中配置opencv的说明,具体可以参考:VS2022 配置OpenCV开发环境详细教程。 CascadeClassifier 分类器 CascadeClassifier 是 OpenCV 库中的一个类,它用于实现一种快速的物体检测算法,称…...

Golang | Leetcode Golang题解之第167题两数之和II-输入有序数组
题目: 题解: func twoSum(numbers []int, target int) []int {low, high : 0, len(numbers) - 1for low < high {sum : numbers[low] numbers[high]if sum target {return []int{low 1, high 1}} else if sum < target {low} else {high--}}r…...

【软件工程】【23.04】p2
关键字: 计算机软件定义、需求基本性质、创建系统类图所涉及的工作、RUP创建系统用况模型活动、软件生存周期模型、能力等级和成熟度等级区别联系; 模块结构图:深度宽度、扇入扇出、作用域、控制域; 程序流程图:语句…...

Java多线程编程与并发控制策略
Java多线程编程与并发控制策略 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我想和大家分享一下Java多线程编程与并发控制策略的相关知识&am…...
)
Java爬虫(一)
一、Java爬虫简介 1.1 Selenium Selenium爬虫是一种基于浏览器自动化的爬虫技术,可以模拟用户的操作行为,实现对动态网页的爬取。 1.2 jsoup Jsoup拥有十分方便的api来处理html文档,比如参考了DOM对象的文档遍历方法,参考了CSS选…...
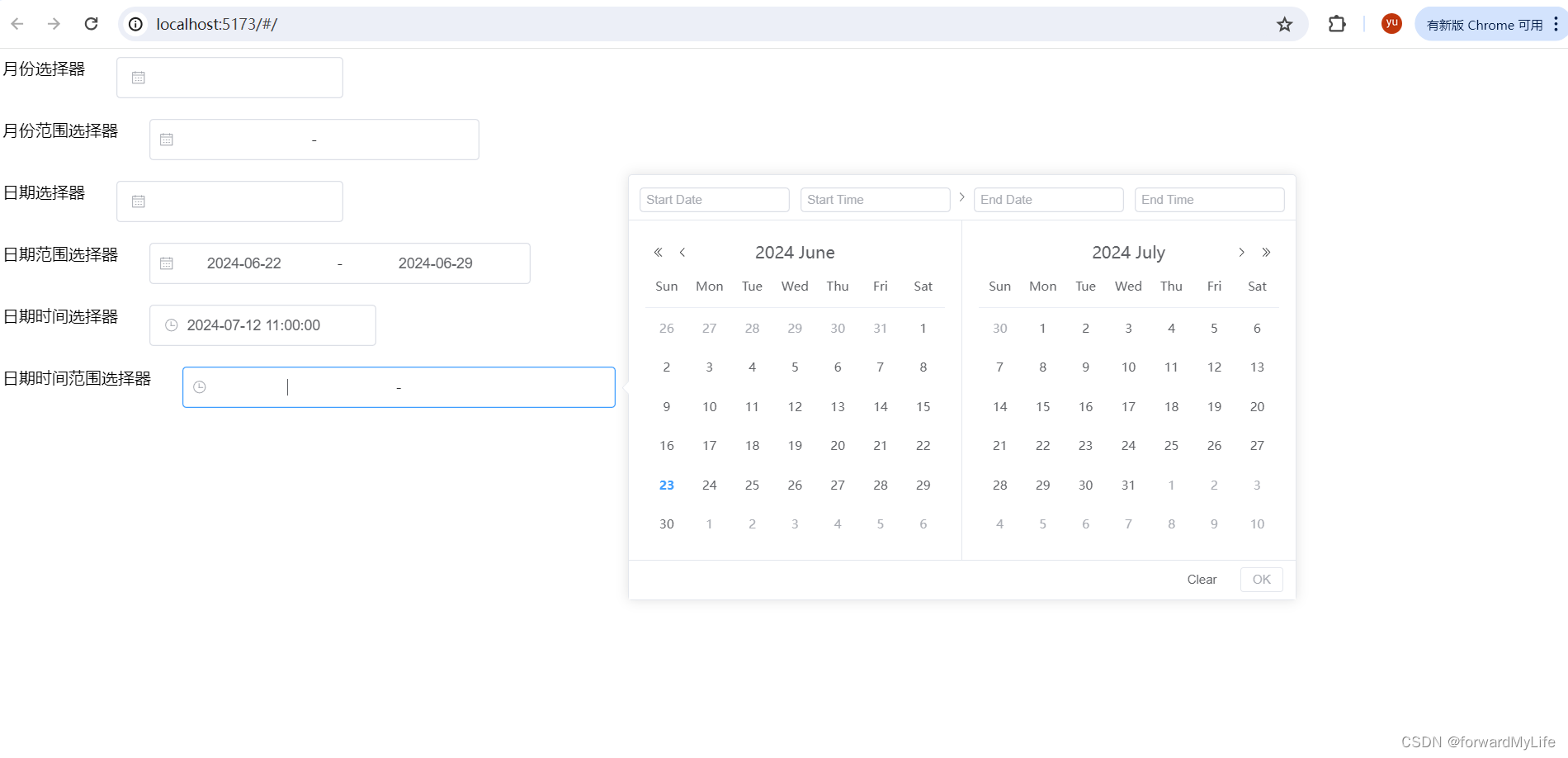
element-plus form表单组件之el-date-picker日期选择器组件
el-date-picker日期选择器组件可根据年,月,日期,时间范围来进行选择,可以自定义日期格式,和样式,还提供多种内置事件。 主要属性如下 属性名说明类型可选值默认值model-value / v-model绑定值,…...

如何与情绪好好相处,真正成为情绪的主人
一、教程描述 若要成为一个聪明的人,就要学会做情绪的主人,而不是被情绪控制自己,为什么要做情绪的主人?至少有以下两个方面原因。 其一,都说,世上还是好人多。可是,为什么你身边没有一个好人…...

RK3588/算能/Nvidia智能盒子:[AI智慧油站」,以安全为基,赋能精准经营
2021年9月,山东省应急管理厅印发了关于《全省危险化学品安全生产信息化建设与应用工作方案(2021-2022 年)》的通知,要求全省范围内加快推进危险化学品安全生产信息化、智能化建设与应用工作,建设完善全省危险化学品安全…...

【眼在手外D435相机支架】
完整UR机械臂的GRCNN抓取网络教程参考以下博客: 【眼在手外D435相机支架】 0. 【机械臂视觉抓取从理论到实战】 GRCNN抓取网络学习1【Jacquard数据集等效制作】GRCNN抓取网络学习2【自制Jacquard数据集训练】GRCNN抓取网络学习3【自制Jacquard数据集模型调优】GRCNN抓取网络学…...

为什么BaiduPCS-Web成为百度网盘下载的终极解决方案?
为什么BaiduPCS-Web成为百度网盘下载的终极解决方案? 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 你是否曾经面对百度网盘几十KB/s的下载速度感到绝望?当重要的文件需要下载,而进度条却…...

开源广告拦截工具AdGuard浏览器扩展:全平台部署与效率优化指南
开源广告拦截工具AdGuard浏览器扩展:全平台部署与效率优化指南 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension 【价值解析】AdGuard扩展如何重塑你的网络浏览体…...

SI4463项目实战:如何像调试代码一样,用WDS3工具精准调试射频参数?
SI4463射频调试实战:用WDS3实现代码级精准配置 在嵌入式开发领域,我们早已习惯了通过断点调试、日志输出和变量监控来掌控程序行为。但当面对射频模块时,许多工程师却感到束手无策——那些神秘的十六进制配置值、模糊不清的寄存器描述&#x…...

直播推流技术:突破平台限制的开发者解决方案
直播推流技术:突破平台限制的开发者解决方案 【免费下载链接】bilibili_live_stream_code 用于在准备直播时获取第三方推流码,以便可以绕开哔哩哔哩直播姬,直接在如OBS等软件中进行直播,软件同时提供定义直播分区和标题功能 项目…...

从 OData 元数据到强类型前端:SAP UI5 与 TypeScript 生成服务类型定义的完整实践
在 UI5 项目里引入 TypeScript,很多团队已经能享受到编辑器补全、静态检查、重构安全这些直接收益。可一旦应用开始真正处理业务数据,一个很现实的问题就会出现:UI5 的官方类型定义覆盖了控件、模型、事件、基类 API,但你自己服务里的实体结构,像 Person、SalesOrder、Bus…...

扫雷-HTML
<!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>扫雷游戏</title><style>* {margin:…...

戴尔G15终极散热控制指南:告别AWCC臃肿,拥抱轻量级开源方案
戴尔G15终极散热控制指南:告别AWCC臃肿,拥抱轻量级开源方案 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为戴尔G15笔记本的高温…...

华硕笔记本性能释放新选择:轻量级开源工具GHelper深度体验
华硕笔记本性能释放新选择:轻量级开源工具GHelper深度体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix…...

Node.js环境下的实时口罩检测API开发与部署教程
Node.js环境下的实时口罩检测API开发与部署教程 1. 引言 在当今的智能化场景中,实时口罩检测技术已经成为许多公共场所和企业的必备功能。无论是商场入口、办公大楼还是公共交通场所,快速准确地检测人员是否佩戴口罩都显得尤为重要。 本教程将手把手教…...

ai赋能c语言开发:让快马平台自动生成文件io与链表管理代码
AI赋能C语言开发:让快马平台自动生成文件IO与链表管理代码 最近在做一个C语言的通讯录管理系统项目,需要实现联系人信息的增删改查功能,并且要求数据能够持久化保存。作为一个有经验的开发者,我决定尝试用InsCode(快马)平台的AI辅…...