redis持久化主从哨兵分片集群
文章目录
- 1. 单点Redis的问题
- 数据丢失问题
- 并发能力问题
- 故障恢复问题
- 存储能力问题
- 2. Redis持久化 -> 数据丢失问题
- RDB持久化
- linux单机安装Redis步骤
- RDB持久化与恢复示例(详细)
- RDB机制
- RDB配置示例
- RDB的fork原理
- 总结
- AOF持久化
- AOF配置示例(详细)
- AOF文件重写
- RDB与AOF对比
- 3. Redis主从 -> 并发能力问题
- 主从架构
- 搭建主从架构示例(详细)
- 集群架构
- 准备实例和配置
- 启动
- 开启主从关系
- 测试
- 主从数据同步原理
- 主从的全量同步原理
- 简述全量同步的流程
- 主从的增量同步原理
- 主从数据同步优化点
- 总结
- 4. Redis哨兵 -> 故障恢复问题
- 哨兵的作用和原理
- 服务状态监控
- 选举新的master
- 如何实现故障转移
- 总结
- 搭建哨兵集群(详细)
- 集群结构
- 准备实例和配置
- 准备sentinel-cluster文件夹
- 启动哨兵
- 模拟主节点宕机
- 测试哨兵是否生效
- 重启原来的主节点
- RedisTemplate的哨兵模式
- 配置步骤
- 哨兵配置示例(详细)
- 引入依赖
- 配置文件
- HelloController
- RedisDemoApplication
- 测试
- 5. Redis分片集群 -> 存储能力问题
- 分片集群结构
- 搭建分片集群示例(详细)
- 集群结构
- 准备实例和配置
- 启动各节点
- 创建集群
- 散列插槽
- 总结
- 集群伸缩
- 添加集群节点&分片插槽示例(详细)
- 故障转移
- 自动故障转移
- 自动故障转移示例(详细)
- 手动故障转移
- 手动故障转移示例(详细)
- RedisTemplate访问分片集群
- 配置步骤
- 配置示例
- 引入依赖
- 配置文件
- HelloController
- RedisDemoApplication
- 测试
- 读写分离
- 分片测试
- 宕机测试
【redis学习篇】主从&哨兵&集群架构详解
redis搭建集群模式、Cluster模式(6节点,3主3从集群模式,添加删除节点)
【已解决】redis集群创建的时候一直卡在Waiting for the cluster to join …上、一直没有反应
redis专栏
解决 阿里云 搭建redis集群 ip变成内网
解决云服务器搭建redis集群, 域名解析成内网ip
06-redis集群模式(中) 项目测试的云服务ip变内网等(解决大多数问题)
spring-data-example github代码示例代码
1. 单点Redis的问题
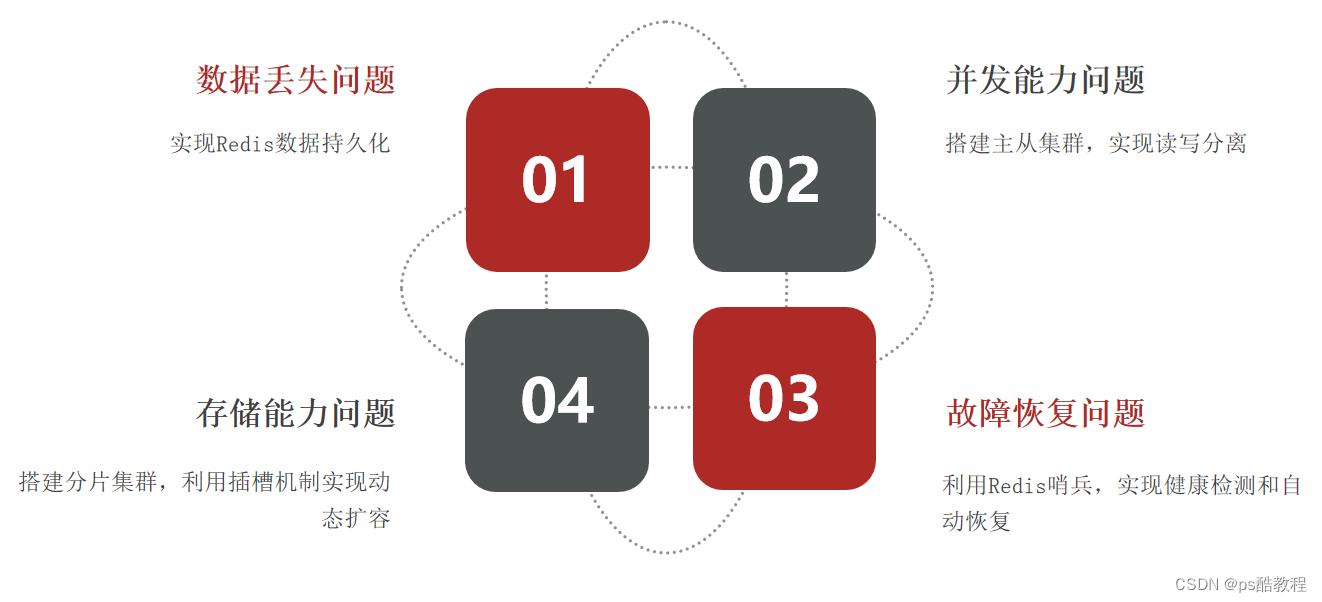
数据丢失问题
Redis是内存存储,服务重启可能会丢失数据
并发能力问题
单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景
故障恢复问题
如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段
存储能力问题
Redis基于内存,单节点能存储的数据量难以满足海量数据需求
2. Redis持久化 -> 数据丢失问题
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件称为RDB文件,默认是保存在当前运行目录。

save命令:由于redis是单线程执行的,使用此save命令时,主进程会阻塞其它的命令,而将数据持久化到磁盘的耗时比较久,等到save命令结束,主进程才能执行其它命令。不推荐使用此命令,它通常用在Redis停机时使用。
bgsave命令:后台异步执行,它会开启子进程执行RDB,避免主进程收到影响,推荐使用该命令作RDB。
Redis停机时会自动执行一次RDB(通过redis-cli连接上redis服务之后,输入shutdown命令即可让redis服务停止或者在redis未开启以守护模式运行时通过ctrl+c停止运行时,会自动执行一次RDB)。
linux单机安装Redis步骤
首先需要安装Redis所需要的依赖:
yum install -y gcc tcl
然后将课前资料提供的Redis安装包上传到虚拟机的任意目录:
例如,我放到了/tmp目录:
解压缩:
tar -xvf redis-6.2.4.tar.gz
解压后:
进入redis目录:
cd redis-6.2.4
运行编译命令:
make && make install
如果没有出错,应该就安装成功了(redis的默认安装位置是/usr/local/bin,在此/usr/local/bin目录下有:redis-server、redis-cli、redis-benchmark、redis-sentinel等可执行文件;同时在redis-6.2.4目录下有redis.conf和sentinel.conf配置文件;同时在redis-6.2.4目录下的是src目录中也有redis-server、redis-cli、redis-benchmark、redis-sentinel等可执行文件)。
然后修改redis.conf文件中的一些配置:
# 绑定地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问
bind 0.0.0.0# 数据库数量,设置为1
databases 1
启动Redis:
redis-server redis.conf # 使用redis-server命令启动redis, 并指定配置文件; 其中redis-server命令可在任意目录下执行
停止redis服务:
redis-cli shutdown # 其中redis-cli命令可在任意目录下执行
RDB持久化与恢复示例(详细)
按照【单机安装Redis步骤】中的步骤安装好redis后:
- 在/usr/local/bin目录下有redis-server、redis-cli、redis-benchmark、redis-sentinel等可执行文件,并且
- 在/usr/local/redis6/redis6.2.4/src目录下也有这些可执行文件;
- 在/usr/local/redis6/redis6.2.4/src下有redis.conf和sentinel.conf配置文件。
(这里主要是说明安装情况)
在如上安装好redis之后,这里演示下在关闭redis服务时,redis会自动执行RDB的案例
现在切换/usr/local/redis6/redis-6.2.4目录下(不是必须在这个目录,在其它目录也可以执行redis-server命令)
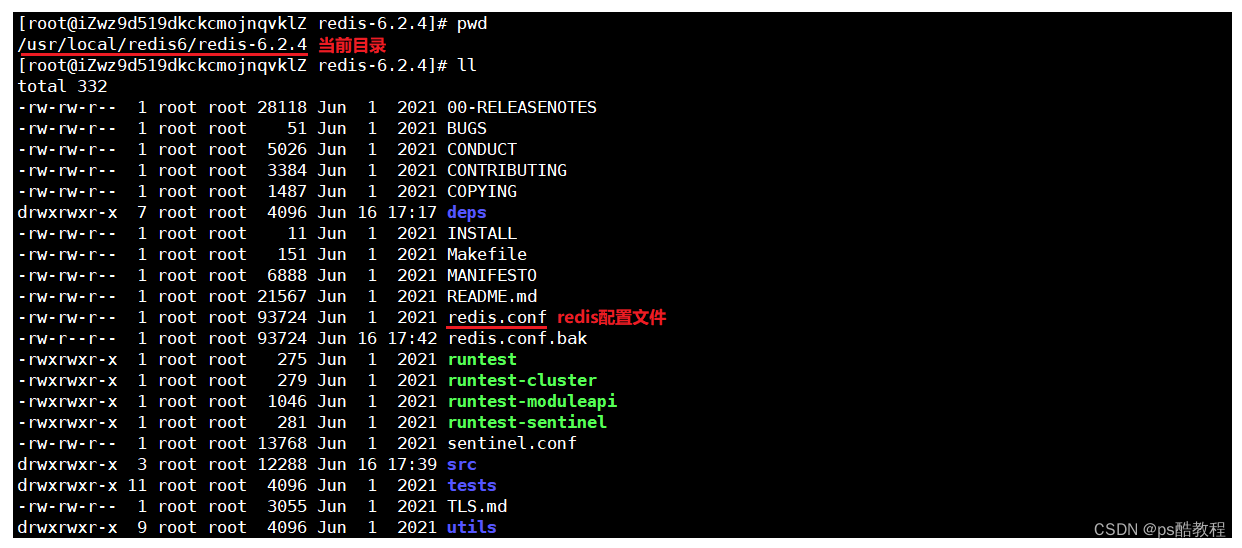
使用redis-server ./redis.conf 命令,来指定对应的配置文件启动redis服务,redis开始接收连接
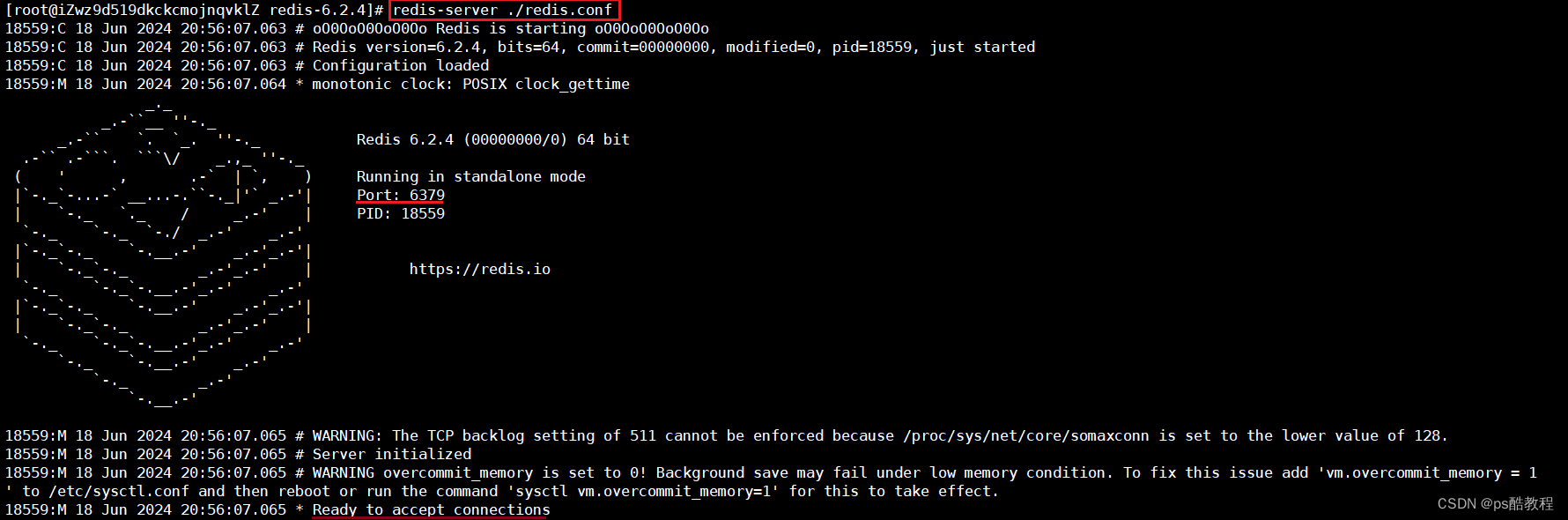
现在开启另外1个窗口,使用set num 123来保存1条数据到redis内存中,然后发出shutdown的命令,让redis关闭服务,此时redis服务会自动做1次RDB操作,将内存中的数据持久化到dump.rdb文件中(此dump.rdb文件默认会生成在运行redis-server命令时所在的目录中,这里在/usr/local/redis6/redis-6.2.4目录下)
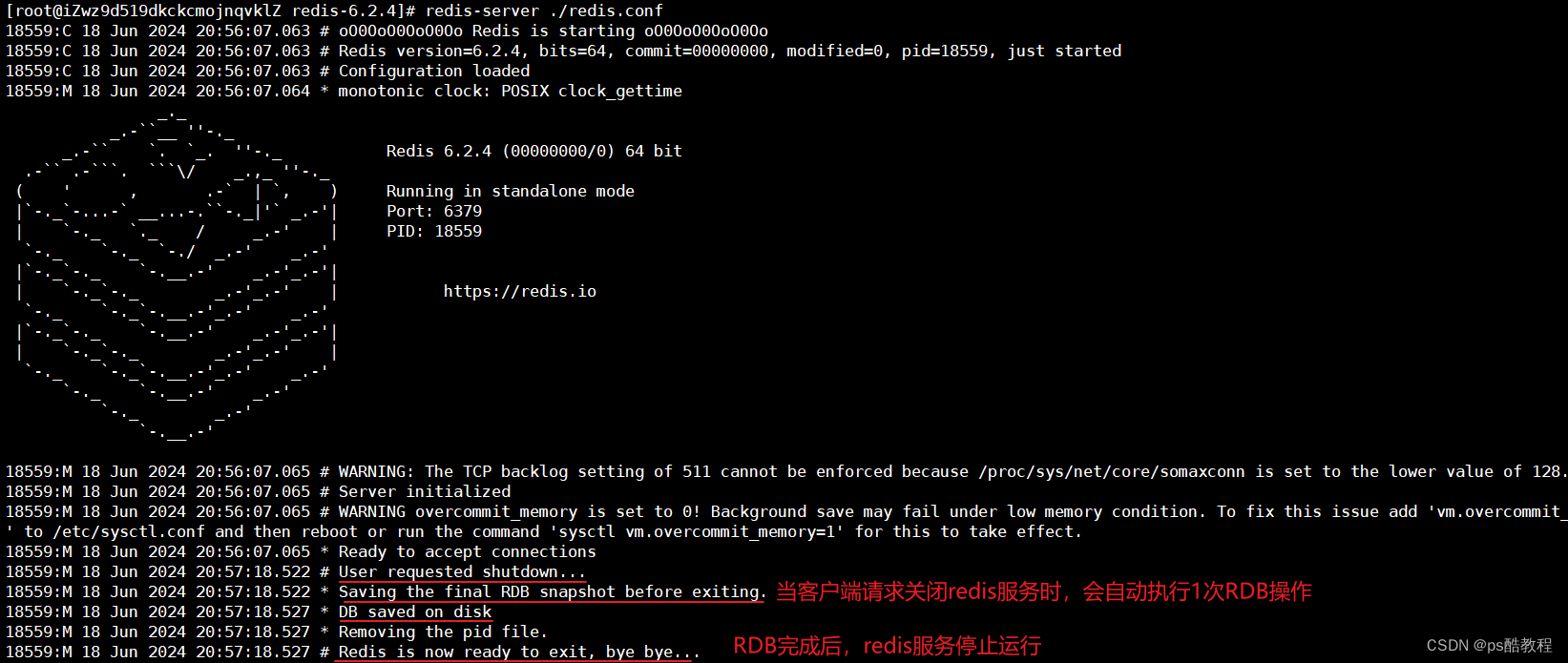
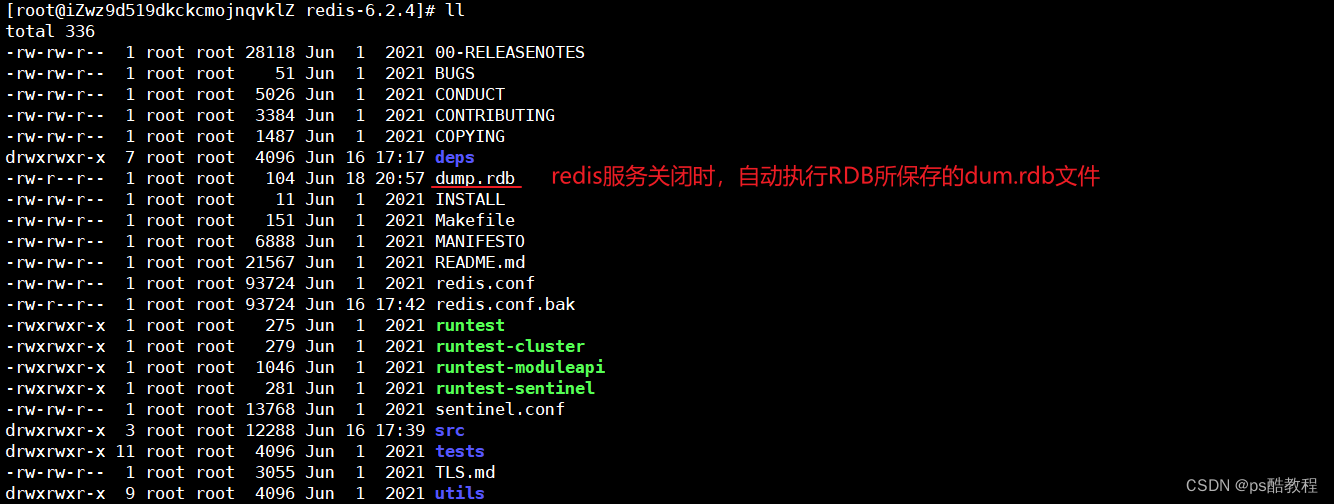
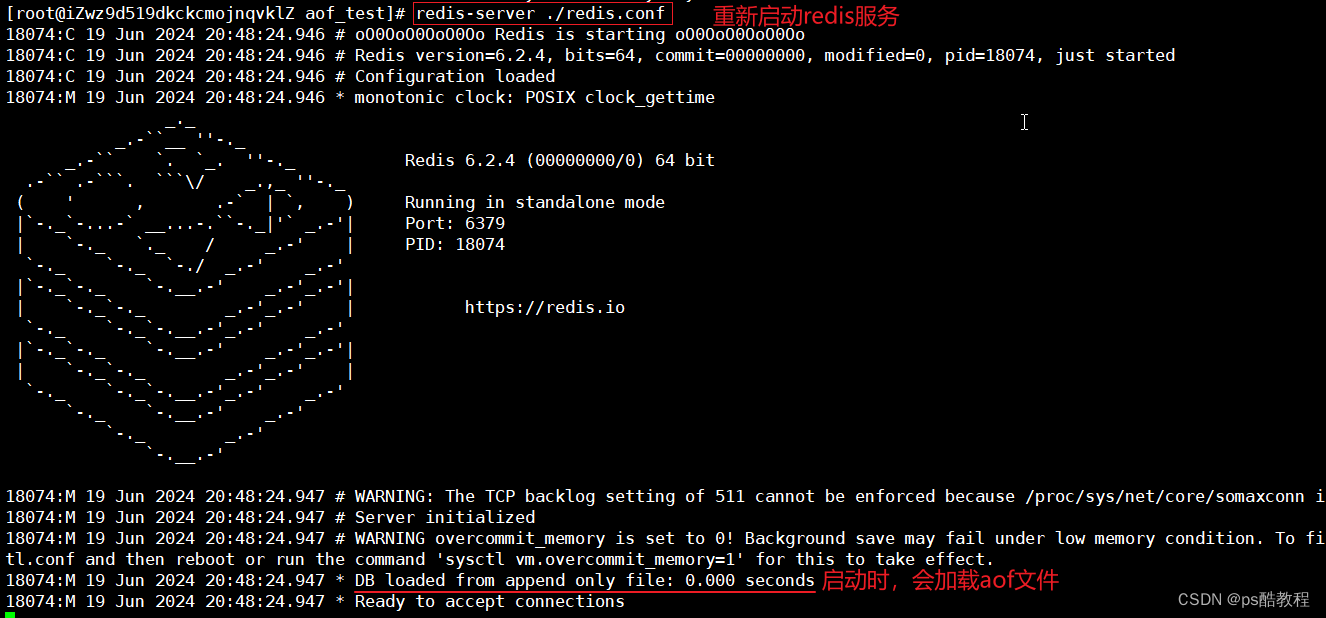
现在/usr/local/redis6/redis-6.2.4目录下,继续在重新启动redis服务,查看前面通过RDB持久化的文件是否恢复到内存当中(这里就没有指定redis.conf了,也可以指定对应的配置文件)
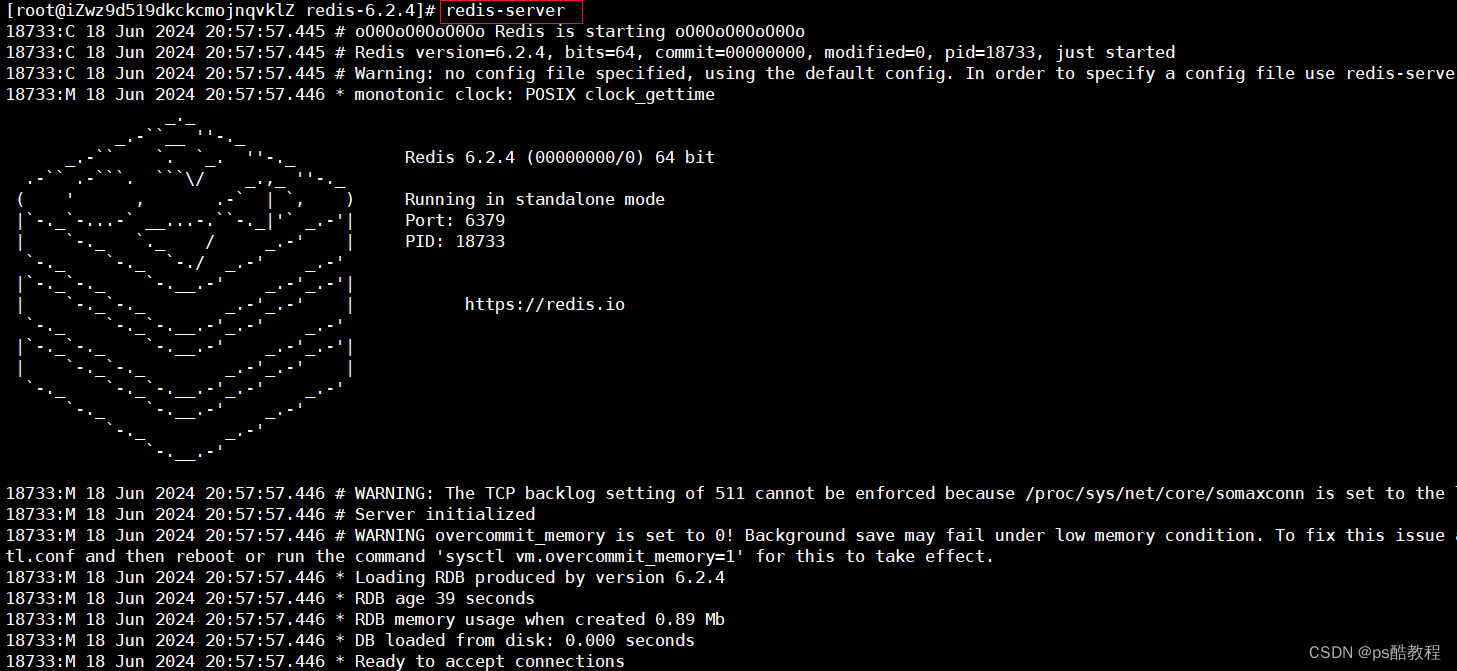
在另外1个窗口,使用redis-cli连接上redis服务,查看数据,发现数据没有丢失,说明redis能够从持久化的文件恢复到内存中

RDB机制
上面案例演示了在redis服务关闭时,会自动执行RDB命令,将内存中的数据持久化到磁盘中。但是,假设redis运行过程中,突然宕机了,此时还没持久化到磁盘中,那么在存储在redis内存中的数据将会全部丢失,所以redis应该要有一套自动持久化的机制。
Redis内部有触发RDB的机制,可以在redis.conf文件中找到(这3个配置默认是被注释的,默认情况下RDB是开启的),格式如下:

RDB的其它配置也可以在redis.conf文件中设置:

(配置的含义就是 在指定的一段时间内,有指定数量的key被修改了,那么就执行1次RDB操作,将内存中的数据持久化到指定的目录下的指定的文件中。当然,redis启动时,也会从这个指定的目录下查找这个指定的文件加载到内存中。)
当有了RDB后,即使不关闭redis服务,也能通过配置将redis内存中的数据持久化到磁盘上,但是它会每隔一段时间,才会执行RDB操作。如果在某段时间内,尚未执行RDB时,此时宕机了,那么这段时间内的数据就丢失了。所以,可能会想着把间隔时间设置的尽可能短,但如果间隔时间很短,执行RDB的操作就太频繁了,影响redis的性能。所以使用默认的就好了。
RDB配置示例
说明:5s内,如果有1个key发生变化,那么持久化内存钟的数据到指定的文件中。其中,修改redis.conf文件部分如下:
# 5s内,如果有1个key发生变化, 则触发1次RDB持久化(如果需要禁用RDB, 则配置: save "" 即可)
save 5 1# 指定持久化文件的名字
dbfilename test.data # 指定RDB持久化文件的所在目录
dir ./my_data_dir
在/usr/local/redis6/redis-6.2.4下创建rdb_test目录,并在此rdb_test目录下创建my_data_dir文件夹用于存放持久化文件。修改号redis.conf配置文件后,使用该配置文件启动redis。
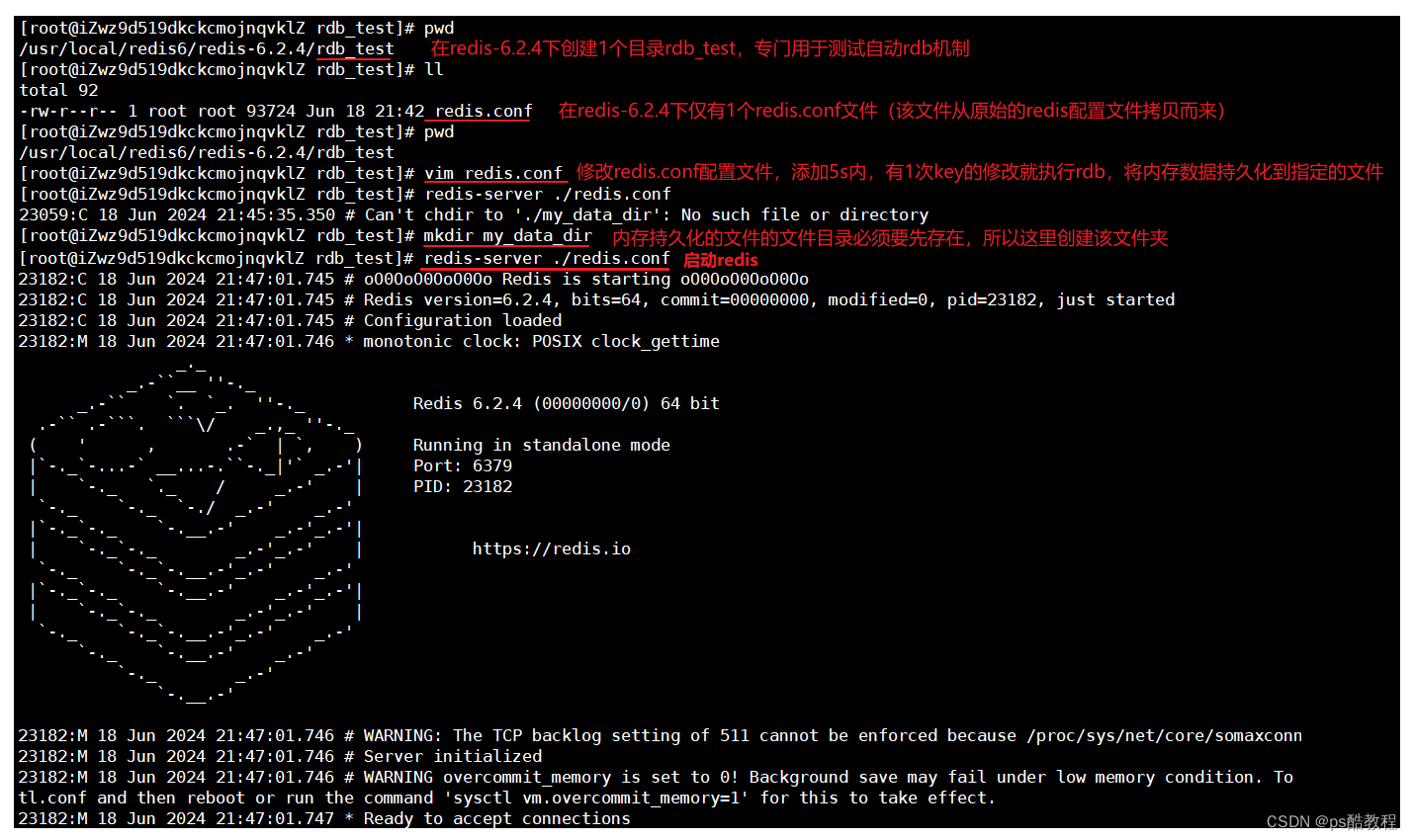
redis启动后,使用redis-cli连接上redis服务,并向redis中存储2条数据,然后观察redis服务的控制台上观察输出,看到了redis执行持久化的日志,关闭redis后,查看my_data_dir文件夹,看到了test.data数据持久化文件

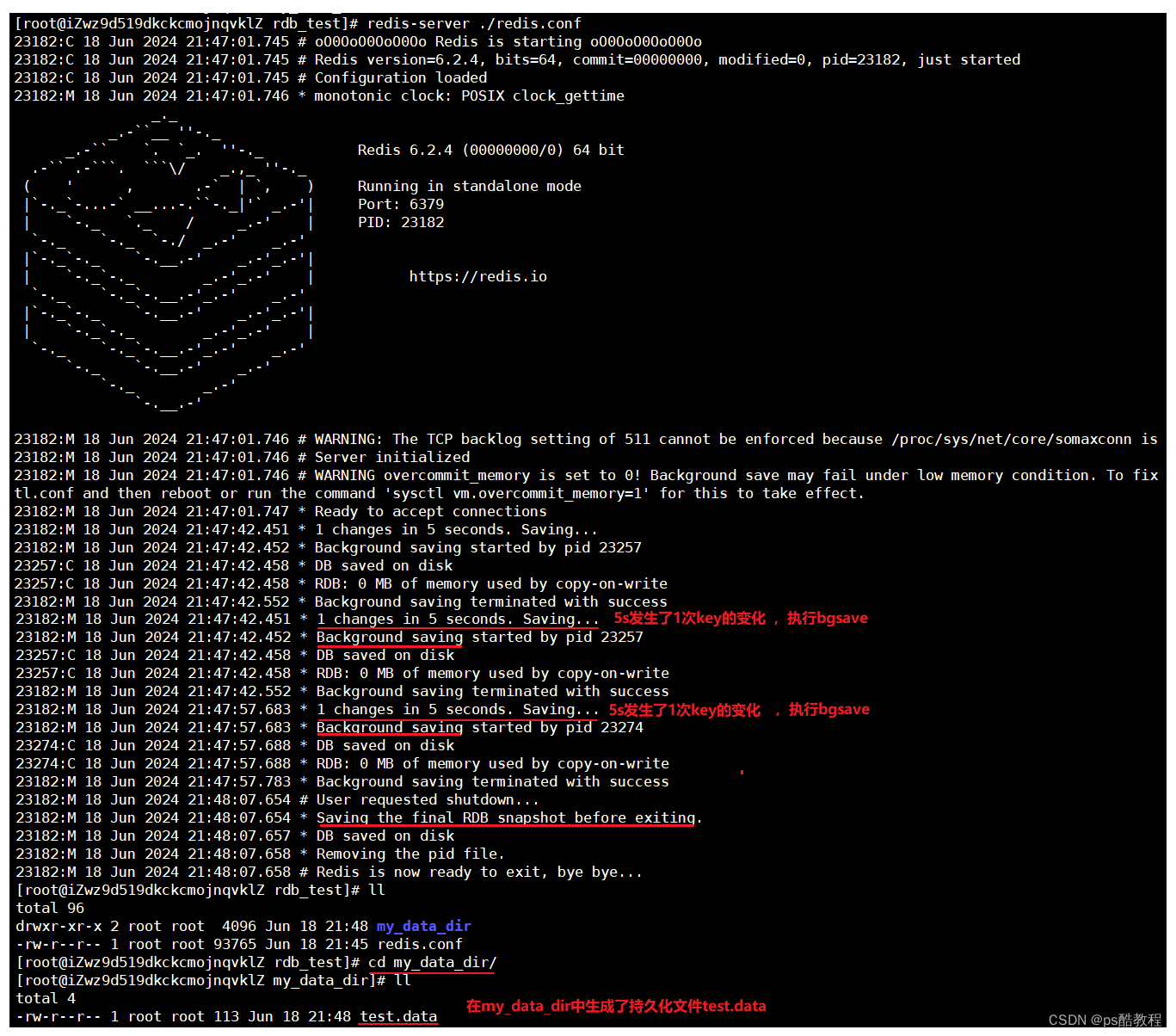
再次使用指定的配置文件,启动redis,使用redis-cli再次查询数据,发现数据已恢复

RDB的fork原理
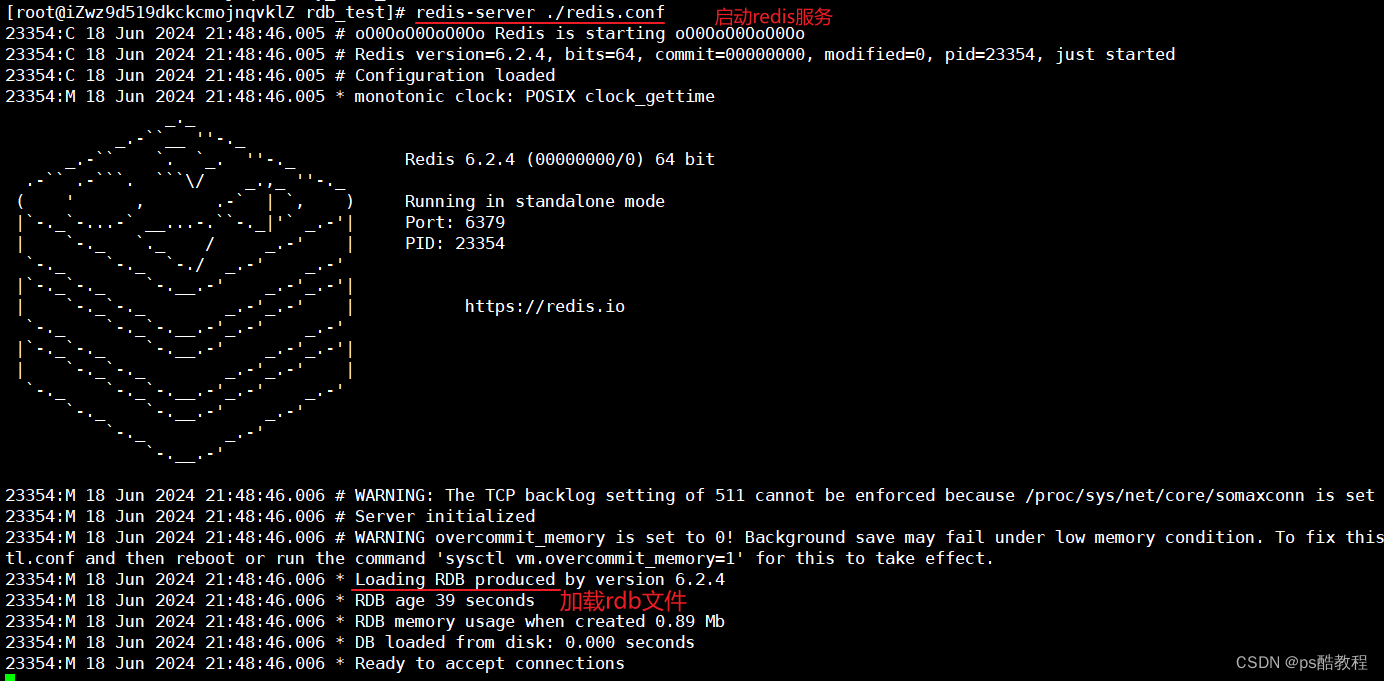
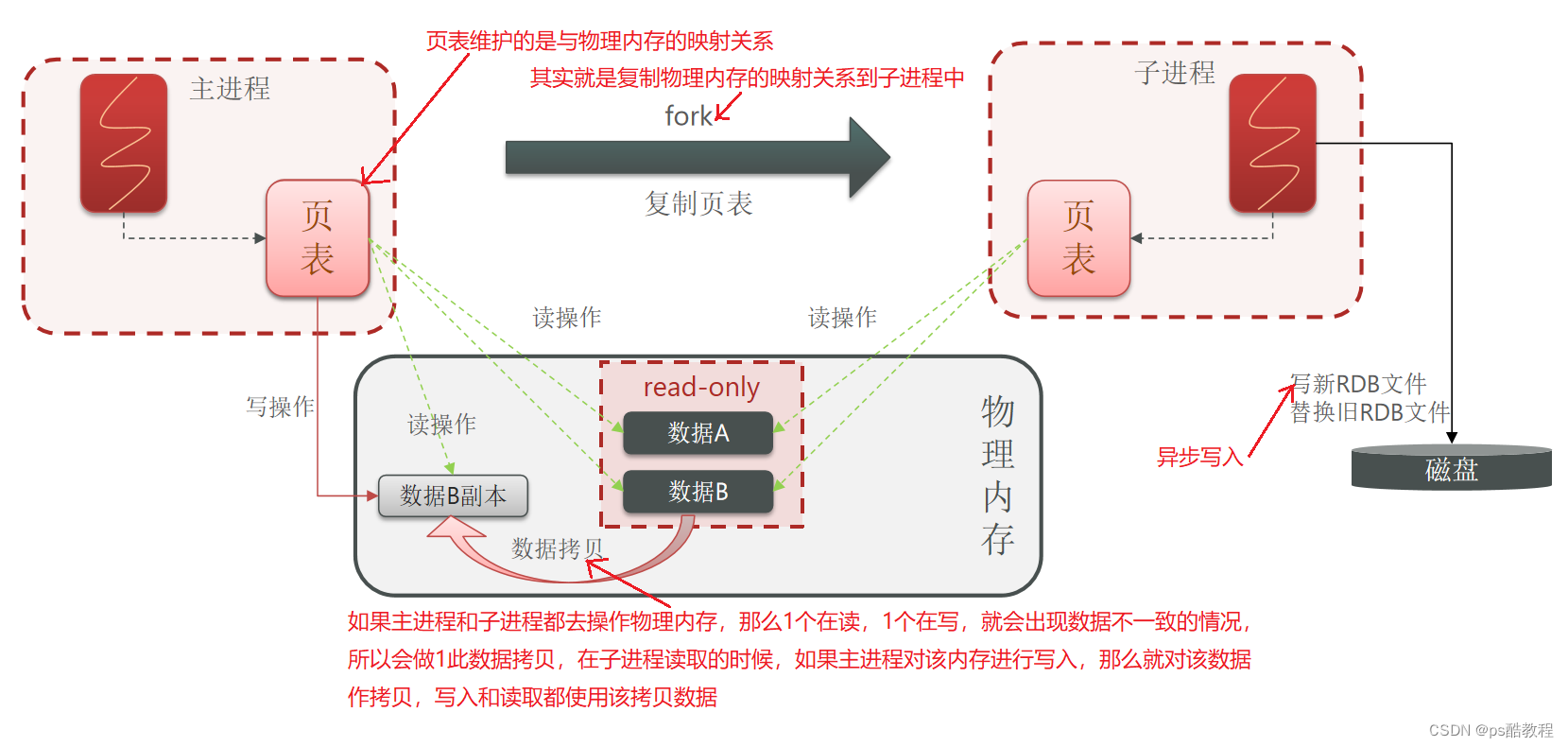
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。(bgsave是异步执行持久化的,对主进程几乎零阻塞,零阻塞的原因在于主进程在执行fork得到子进程时,此fork操作会阻塞,此时无法处理客户端请求)
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作(当此时针对很多key写操作时,就相当于要拷贝大量数据作为副本,此时就需要事先考虑给redis预留足够的空间)
总结
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并异步写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时。
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。

AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF的命令记录的频率也可以通过redis.conf文件来配:

| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘(redis接收到命令后,使用命令操作完内存后,把此命令写到AOF文件磁盘中,此时主进程是阻塞的,等到写完AOF才返回给用户,主进程再处理其它请求) | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘(redis接收到命令后,使用命令操作完内存后,把此命令写到内存缓冲区中,写完缓冲区后,主进程立即返回。1s后再通过异步的方式将缓冲区中的数据写到AOF文件磁盘中,因为主进程是面对内存缓冲区中的读写,所以效率高,但是如果在写入的过程中宕机了,那么就会丢失这1s内的所有操作。它是默认方案。) | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制(由操作系统决定,可能频率会比较低) | 性能最好 | 可靠性较差,可能丢失大量数据 |
AOF配置示例(详细)
说明:AOF会记录每条执行的redis命令到aof文件中,这里关闭了rdb机制,开启了aof机制
# 关闭RDB机制
save ""# aof文件将会保存在此目录, 启动时会读取该目录下的aof文件(与RDB持久化文件所保存的目录相同)
dir ./aof_data_dir# 开启aof
appendonly yes# aof文件名
appendfilename "my_aof.data"# aof刷盘策略, 默认就是everysec, 不需要修改
appendfsync everysec
在/usr/local/redis6/redis-6.2.4下创建aof_test目录,并在此aof_test目录下创建aof_data_dir文件夹用于存放aof文件。修改好redis.conf配置文件后,使用该配置文件启动redis。
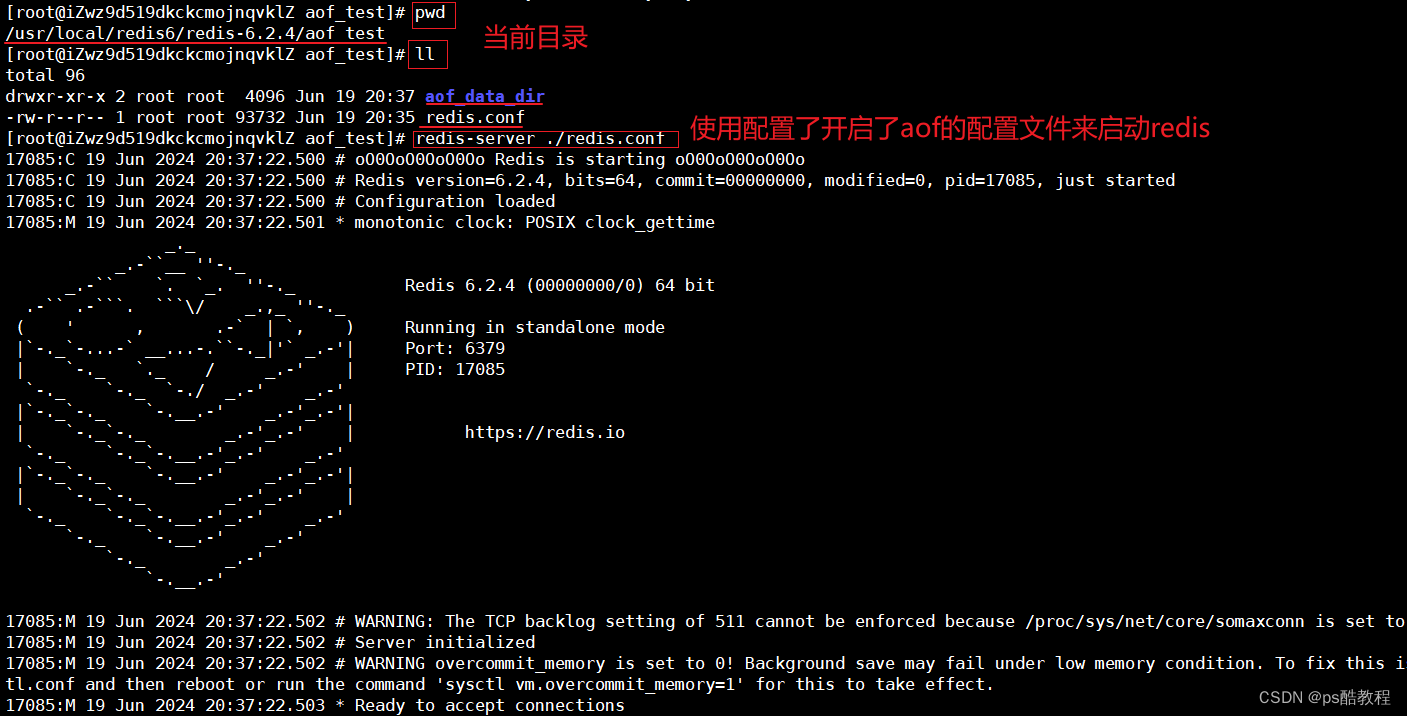
使用redis-cli客户端连接上redis服务,并且保存1条数据,然后退出redis-cli客户端,就可以在指定的目录下看到保存的aof文件了,并且这里看到了aof文件的内容,aof文件确实记录了每条redis命令
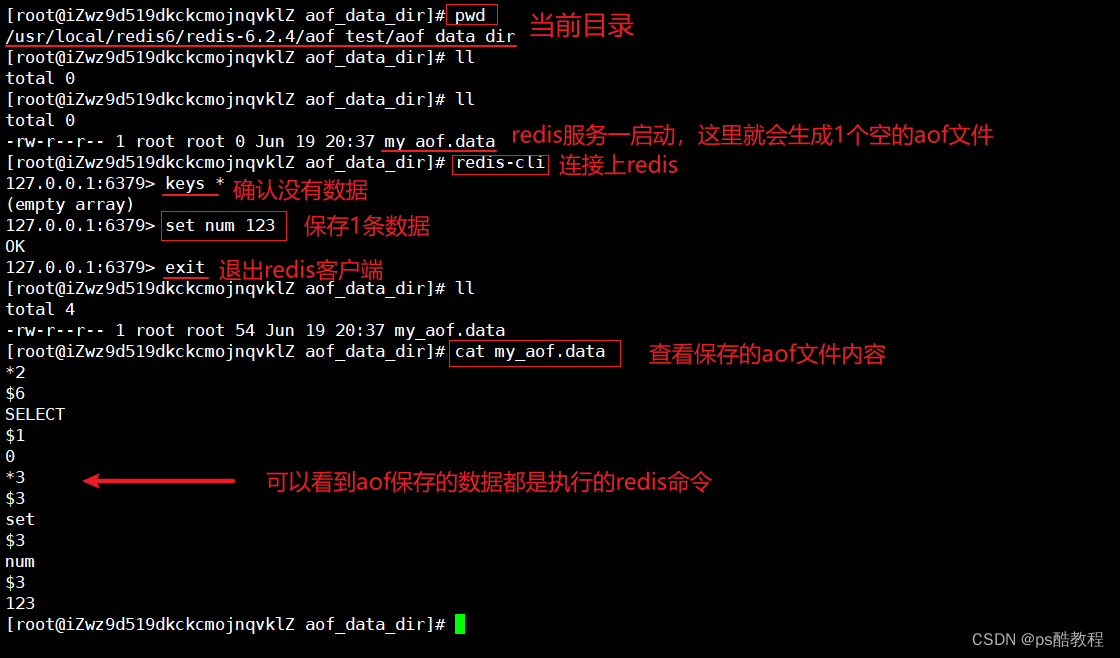
关闭redis时,redis也会执行1次aof
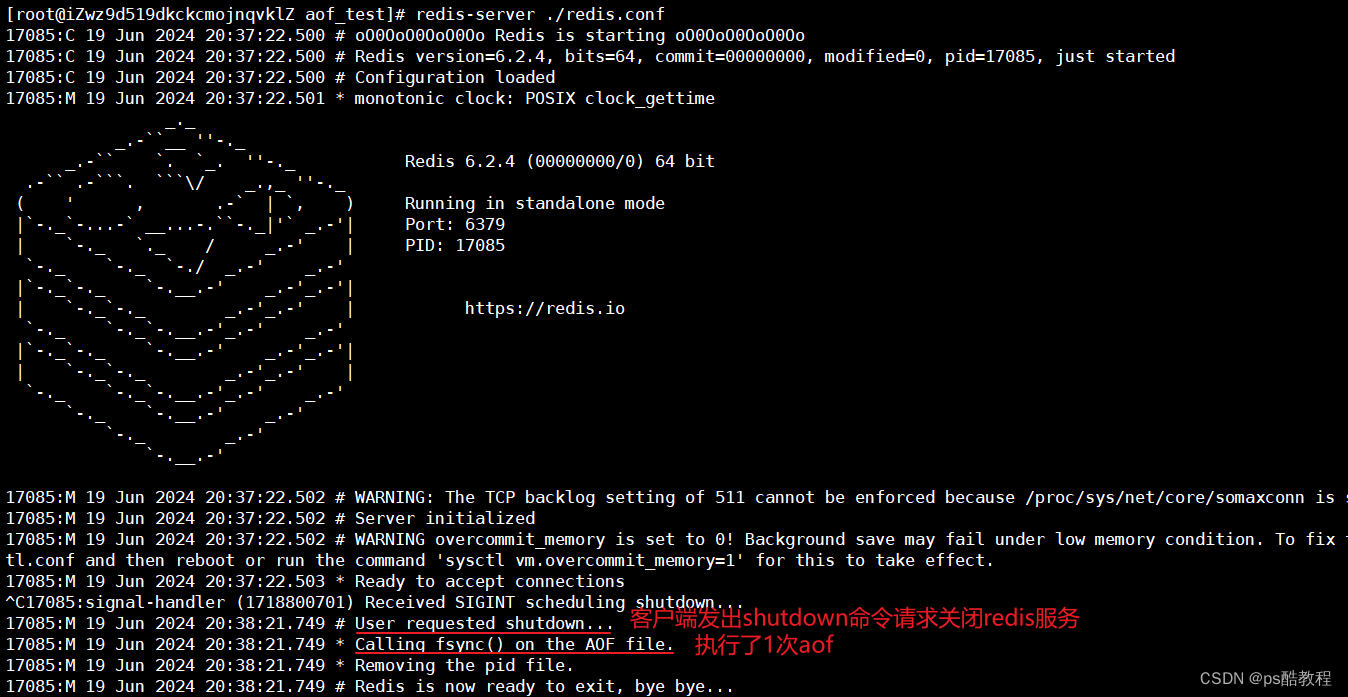
重新启动redis服务,会自动加载aof文件,然后使用redis-cli客户端连接上redis服务,查询redis服务关闭之前所保存的数据,能够查询到,说明aof文件被加载了

AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果(此命令为异步执行,他会让aof文件变小,并对内容作编码处理)。

Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| 特点 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
-
RDB与AOF数据恢复优先级:当目录下同时存在AOF与RDB文件时,会优先使用AOF文件来恢复数据,因为AOF文件数据更加完整,而RDB会丢失从上次备份的数据后到发生故障时这段时间内的数据。所以RDB更适合作为一种数据备份的手段。
-
AOF操作是异步的
3. Redis主从 -> 并发能力问题
主从架构
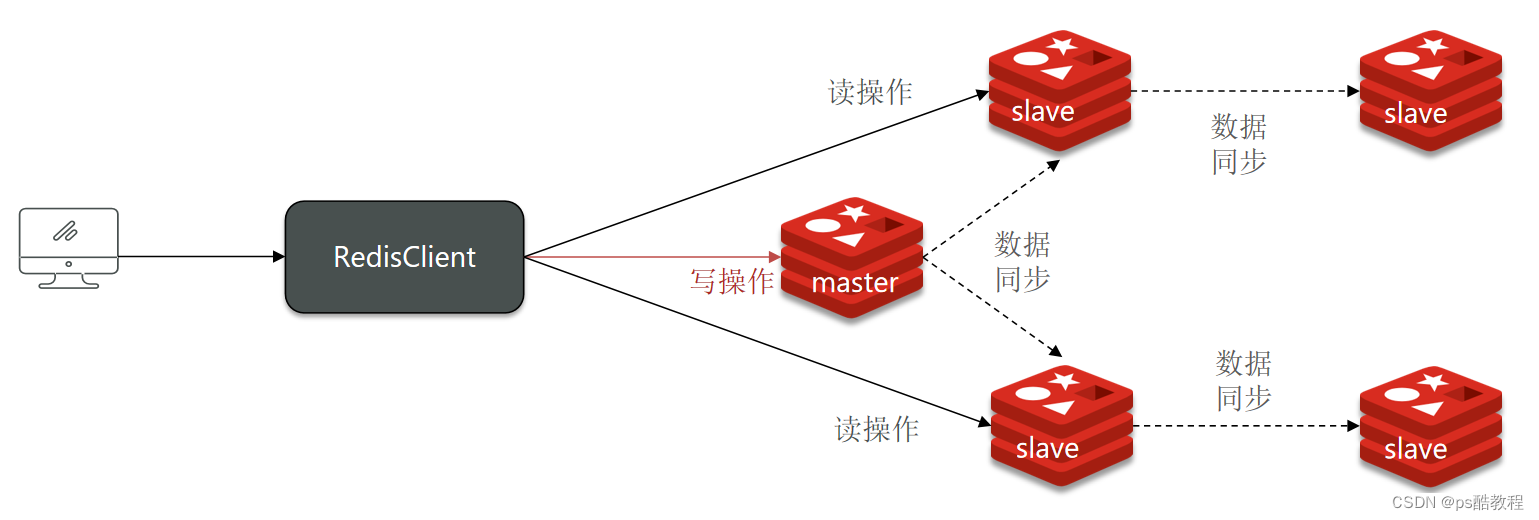
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群(而不是负载均衡的那种集群),实现读写分离(因为redis查询操作多,增删改比较少,所以需要更多的处理读的压力,实现读写分离,提高读的并发能力)。
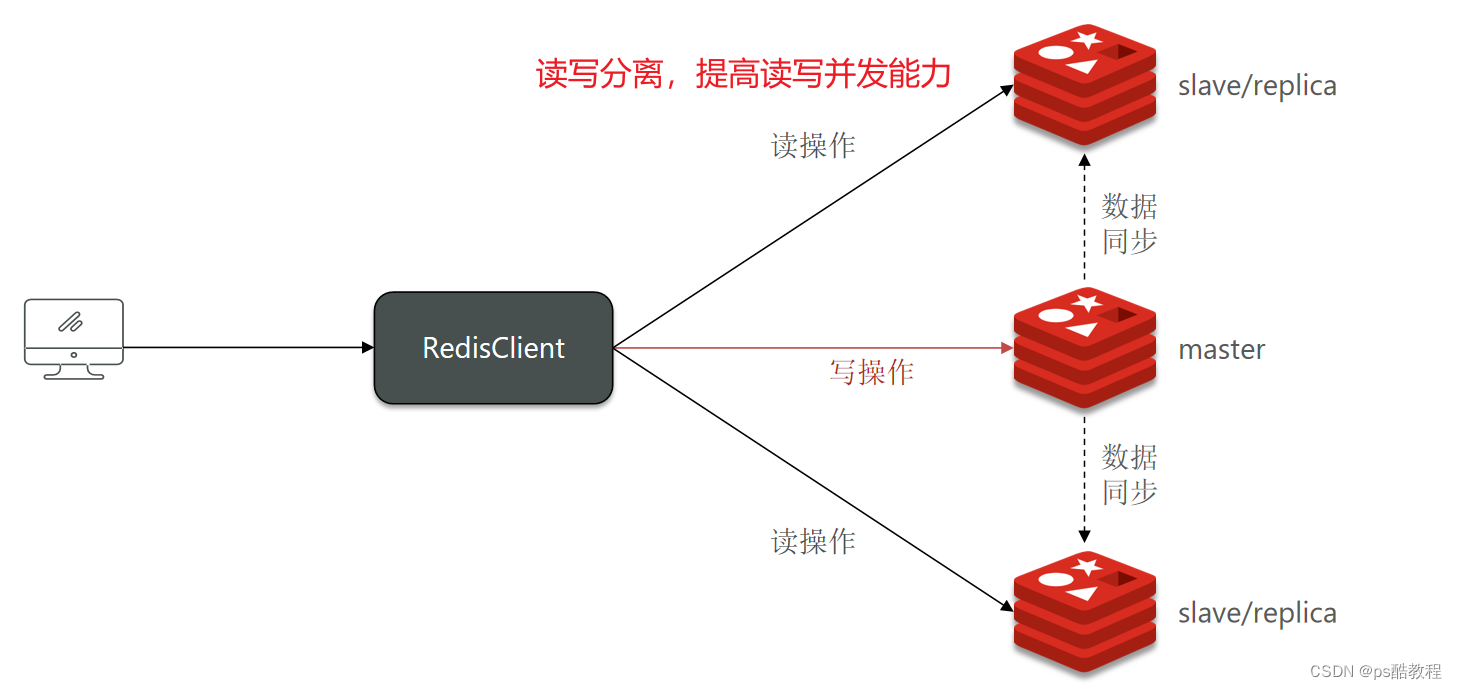
搭建主从架构示例(详细)
集群架构
我们搭建的主从集群结构如图:
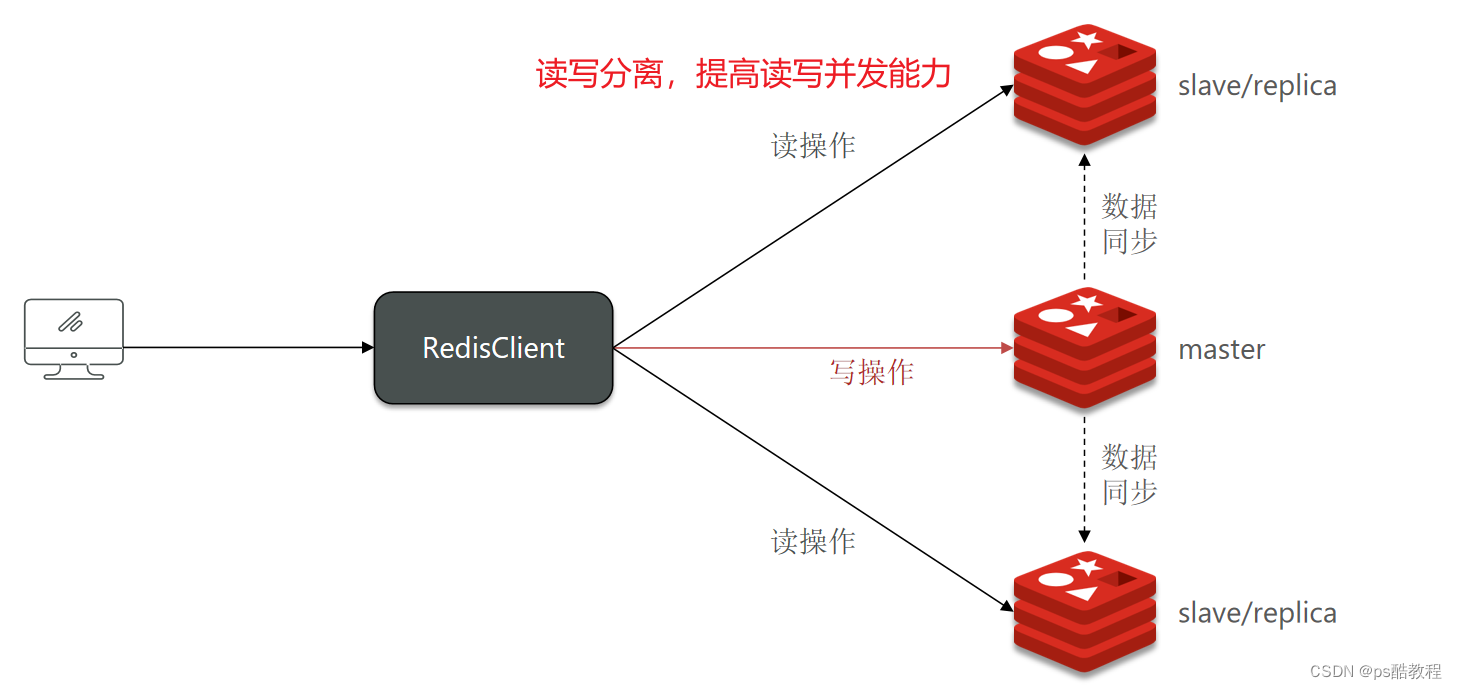
共包含三个节点,一个主节点,两个从节点。这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 172.17.23.234 | 7001 | master |
| 172.17.23.234 | 7002 | slave |
| 172.17.23.234 | 7003 | slave |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
1)创建目录
我们在/usr/local/redis6/redis-6.2.4/master-slave-cluster目录下,创建三个文件夹,名字分别叫redis7001、redis7002、redis7003,和1个最初的redis.conf配置文件(未作任何修改)
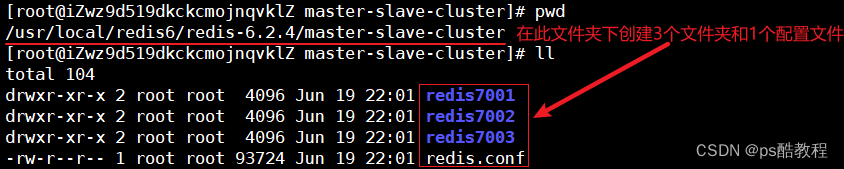
修改redis.conf配置文件:将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态;配置bind允许远程连接;虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息。然后,将此redis.conf分别拷贝到redis7001、redis7002、redis7003中,然后分别修改他们对应的端口为:7001,7002,7003。
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000# 关闭AOF
appendonly no# 允许远程连接(不设置此配置, 会无法同步)
bind 0.0.0.0# 虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息
replica-announce-ip 172.17.23.234# 这个目录在本示例中为了方便就不改了, 但是注意启动的时候, 需要到对应的目录下去启动, 否则rdb生成的文件会在redis-server的运行目录下
dir ./# 端口: redis7001、redis7002、redis7003中,然后分别修改他们对应的端口为:7001,7002,7003
port 7001 # 这里以7001为例
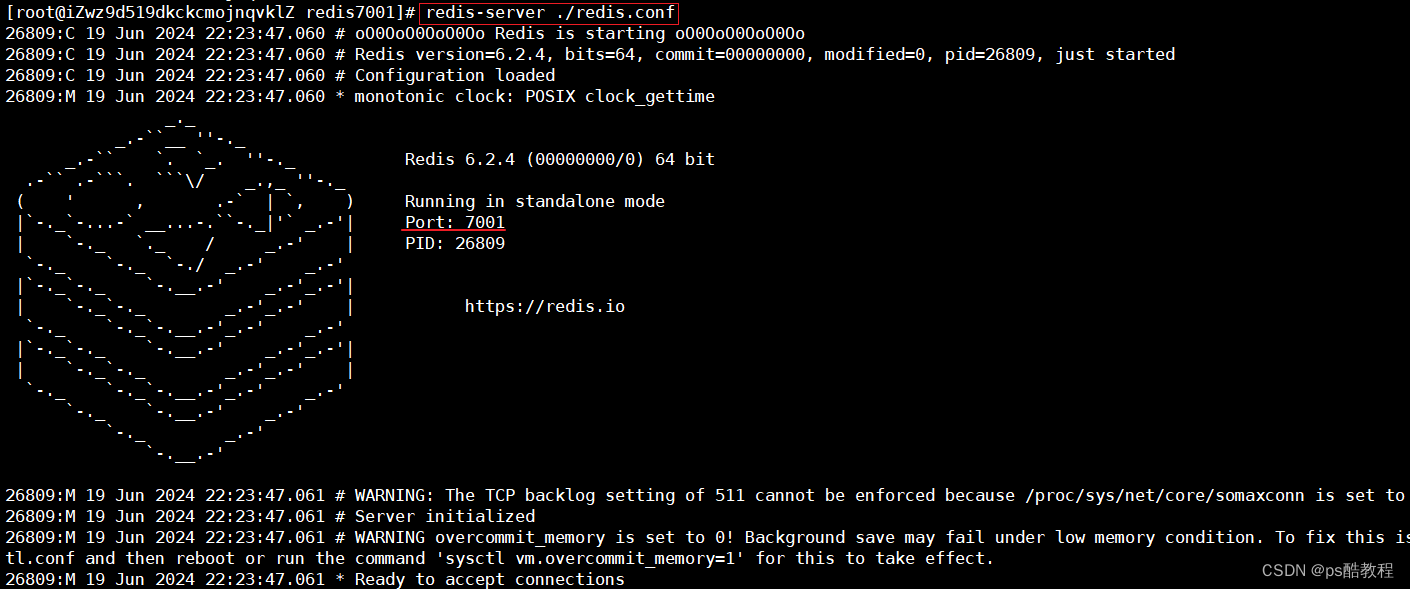
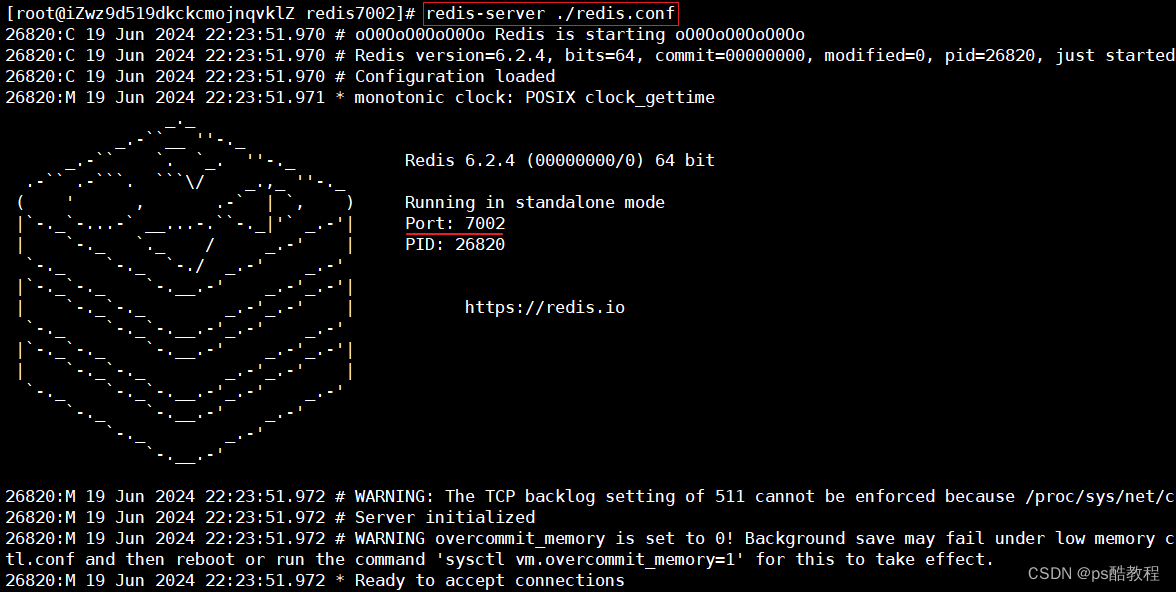
启动
分别在redis7001目录下启动7001,redis7002目录下7002,redis7003目录下7003(注意运行redis-server命令的目录,因为我们的dir配置的是./)

开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
(搭建完主从之后,可以连接上任意一个节点,通过info replication命令查看主从集群状态)
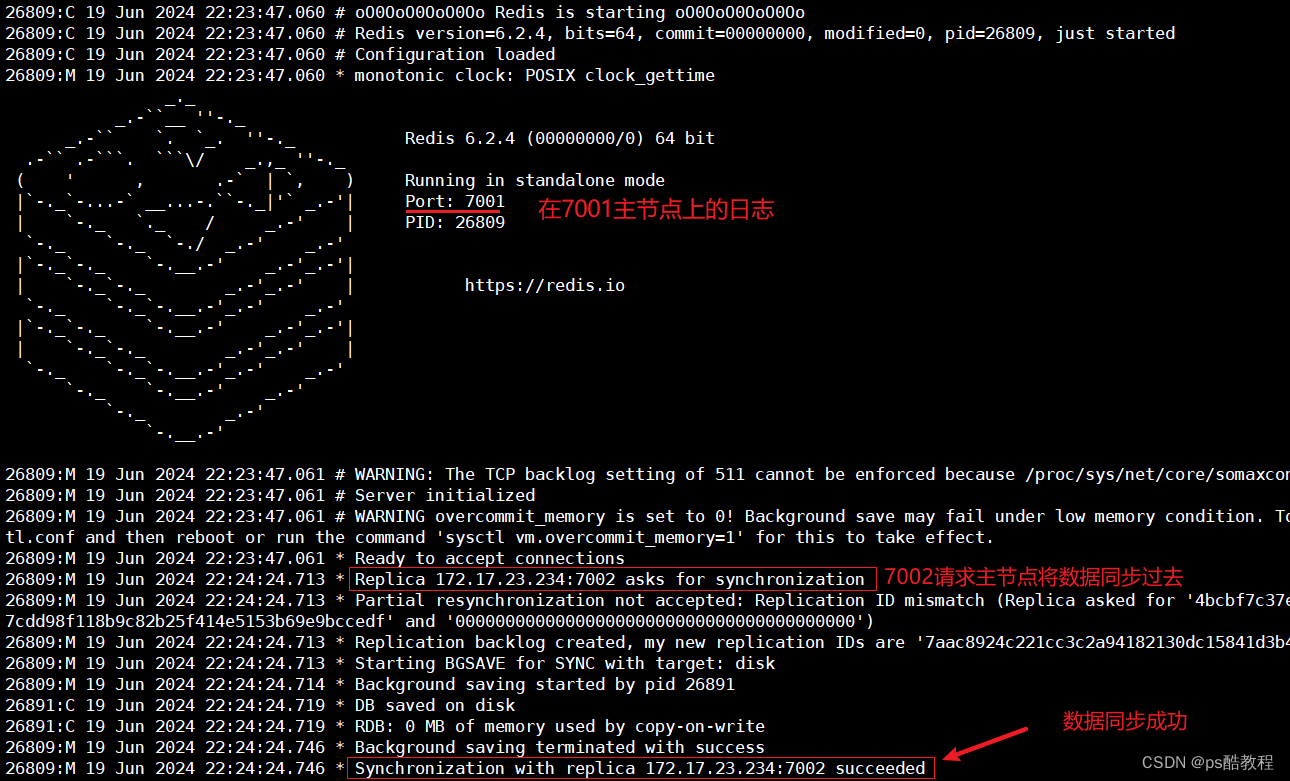
这里让7002成为7001的slave,即让7002成为7001的从节点,执行该命令后,就会把7001主节点的数据同步过来

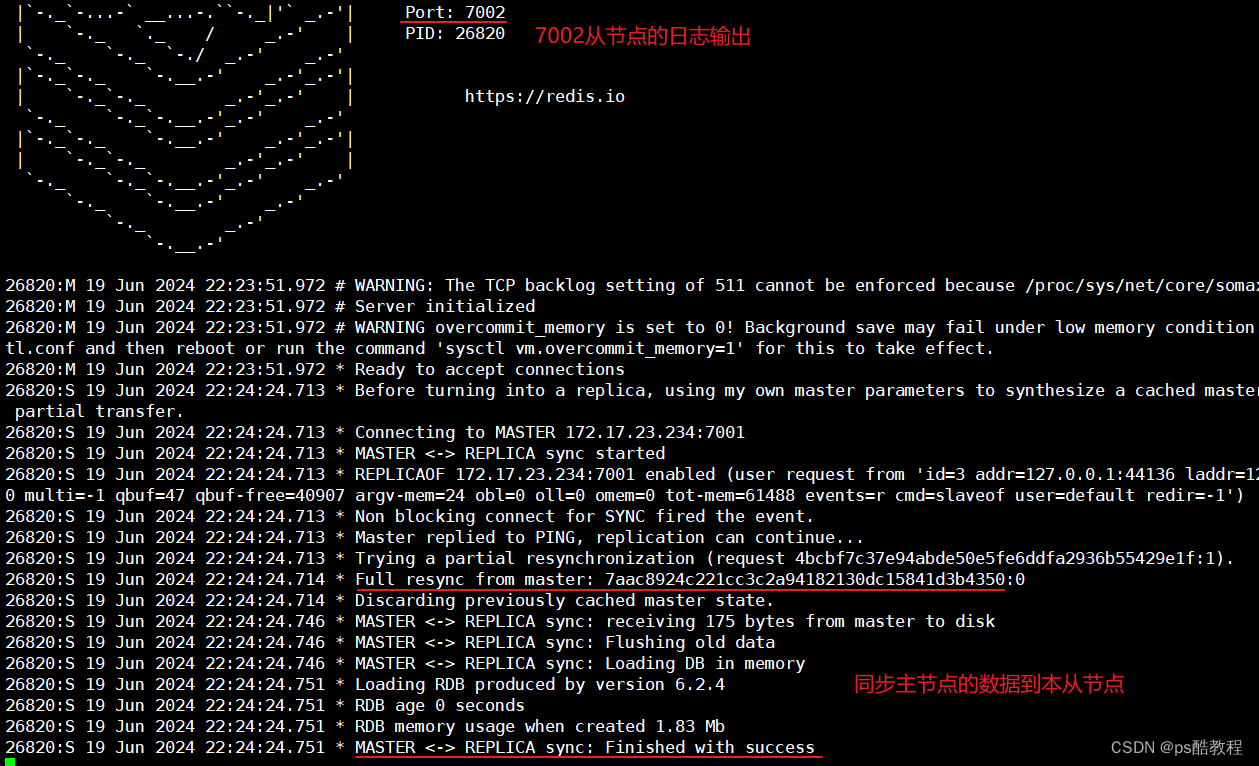
让7003成为7001的slave,并且从节点只能读取数据,不能够写入数据,只有主节点才能写入数据

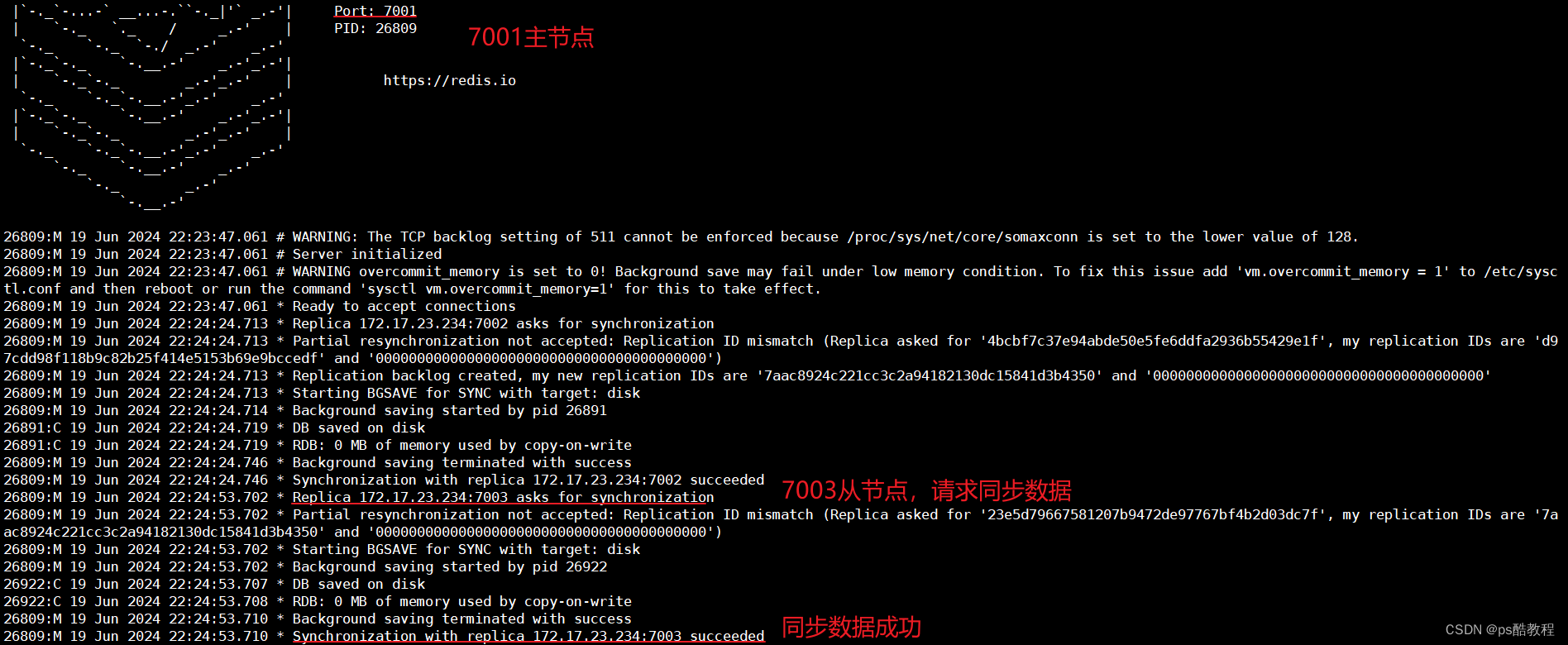
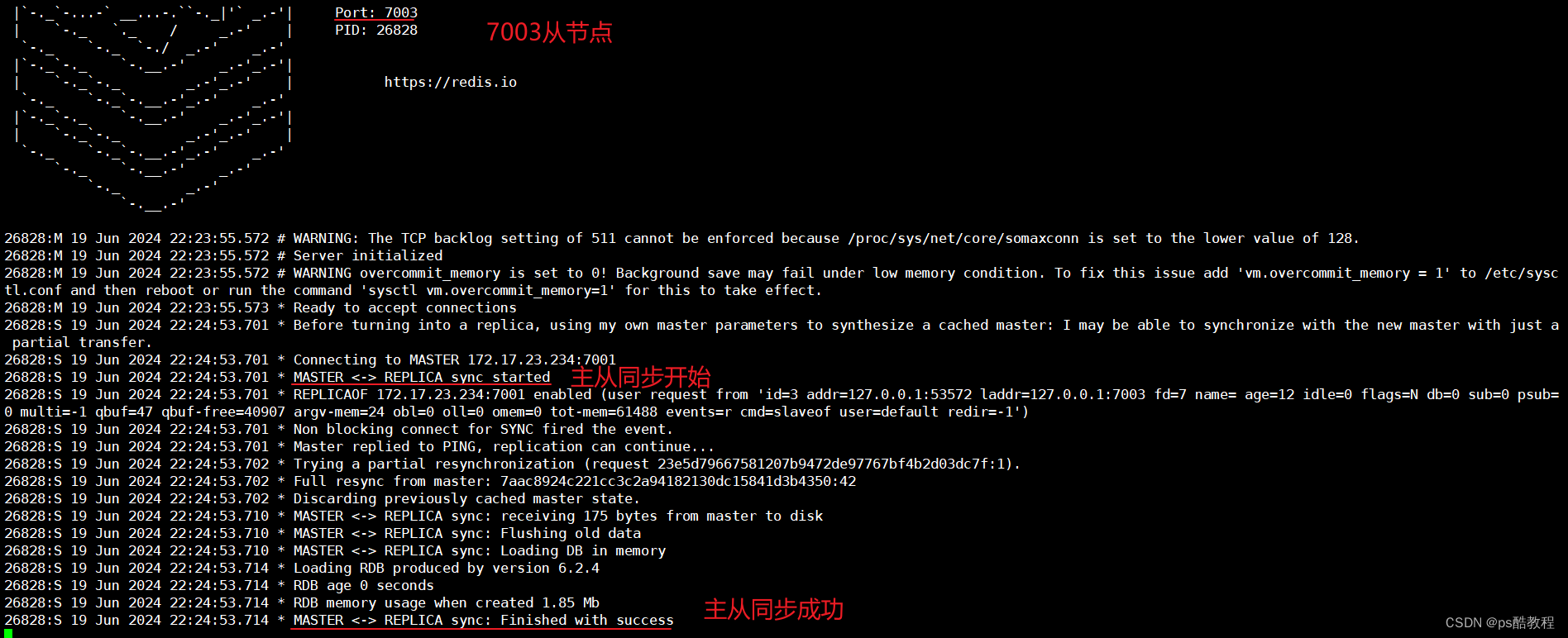
测试
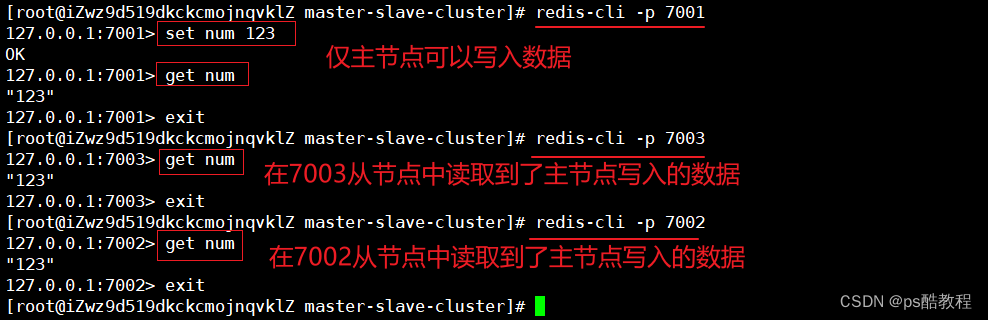
在主节点中写入数据,再分别从7002、7003从节点中读取到了数据,证明主从数据同步成功了。可以执行info replication查看主从集群状态。
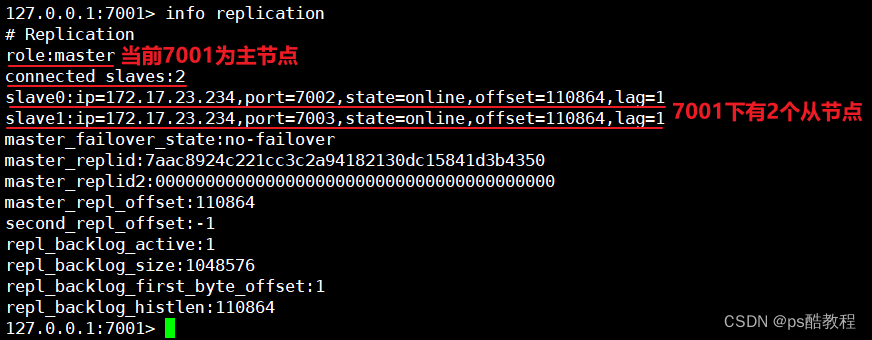

主从数据同步原理
主从的全量同步原理
主从第一次同步是全量复制
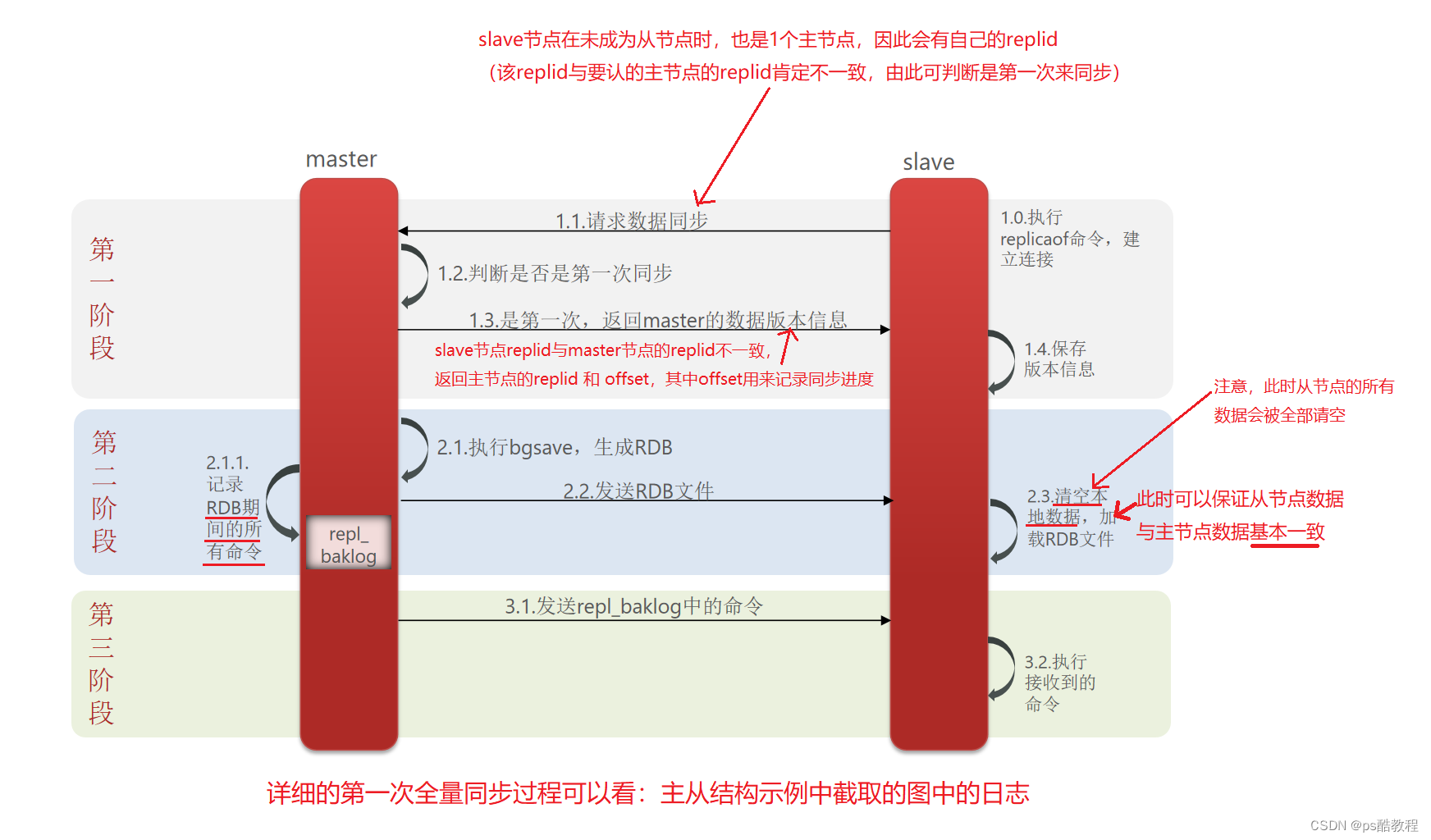
master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replidoffset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据
全量同步过程:从节点将自己的replication id发给主节点,主节点判断此replication id是否与自己的replication id是否一致,如果replication id不一致,说明该从节点是第一次来,主节点需要执行bgsave命令来做RDB保存起来,然后将自己的全量数据和offset同步到该从节点;如果replication id一致,说明从节点之前已经来过了,做过了全量同步了,并且从节点将offset也发过来了,因此主节点就可以从offset得知从节点的同步进度,因此主节点就将offset后面的数据发过去给从节点)
简述全量同步的流程
-
第1步:slave与master建立连接
-
第2步:slave节点请求增量同步
-
第3步:master节点判断replid,发现不一致,拒绝增量同步
-
第4步:master将完整内存数据生成RDB,发送RDB到slave
-
第5步:slave清空本地数据,加载master的RDB
-
第6步:master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
-
第7步:slave执行接收到的命令,保持与master之间的同步
主从的增量同步原理
主从第一次同步是全量同步,,但如果slave重启后同步,则执行增量同步。
增量同步过程:从节点重启后,依然需要携带自己的replid和offset向主节点请求同步数据,主节点收到该节点发过来的replid后,与自己的replid比较,发现一致,说明不是第一次来同步的,因此,就查看该节点发过来的offset查看该节点之前的同步进度,然后从repl_baklog中读取大于此offset的命令发送给从节点去同步。如果主节点这边检测到该未同步的数据已经被覆盖了,那么就会要求该节点做全量同步。
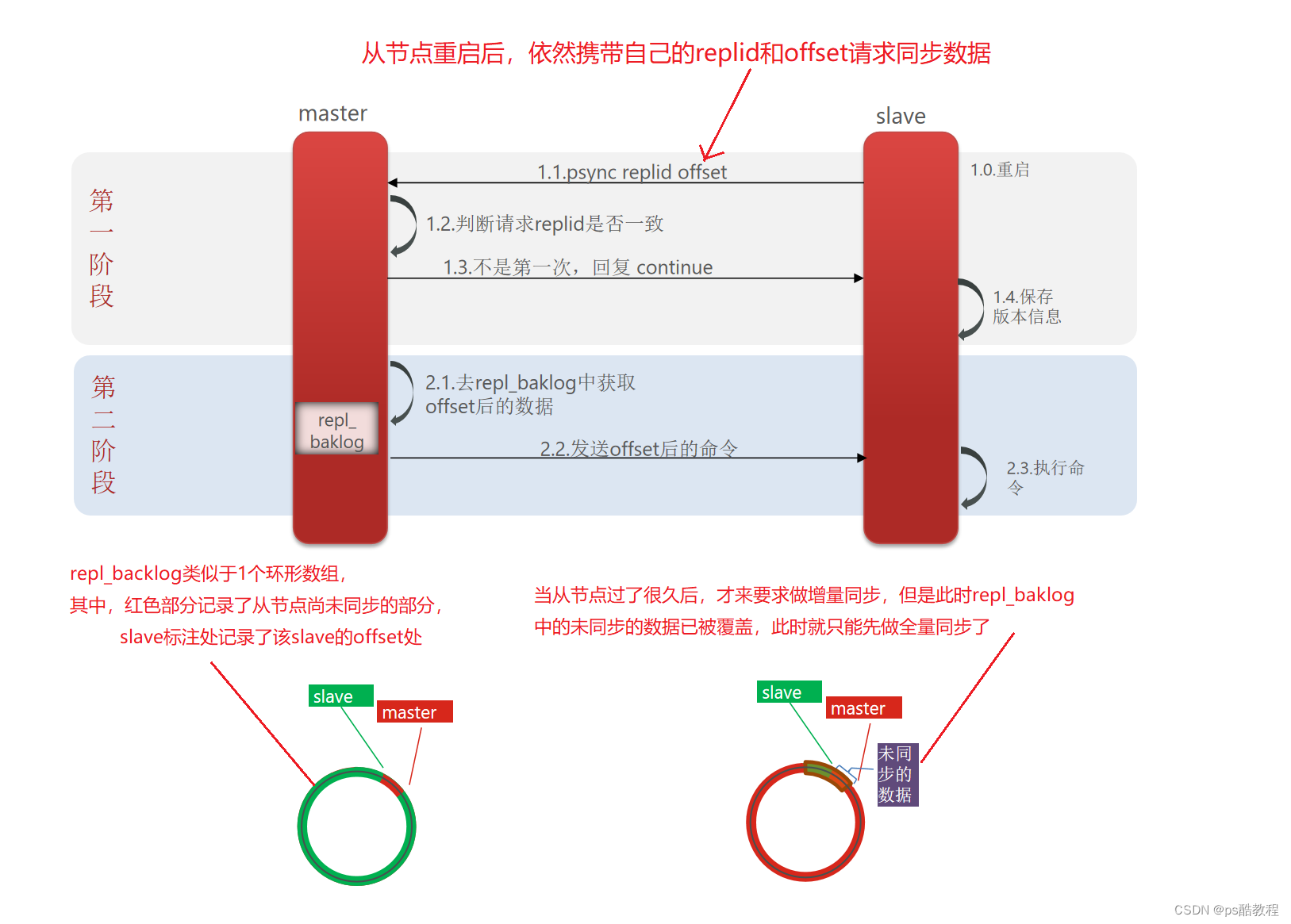
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,此时只能再次全量同步。
主从数据同步优化点
可以从以下几个方面来优化Redis主从就集群:
-
在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO(需要网络带宽足够大)。
-
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
-
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
-
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
总结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
4. Redis哨兵 -> 故障恢复问题
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?如果master宕机了,那么redis集群仅靠从节点只能提供读的能力,而无法提供写的能力,即redis集群的写能力对外界不可用.因此,需要有一种机制来监控redis的集群状态,当主节点宕机了,仍可以确保redis集群提供完整的读写能力(从节点是有同步过主节点的数据的,因此只需要把这个从节点改为主节点,即可对外提供写的能力)。
哨兵的作用和原理
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。
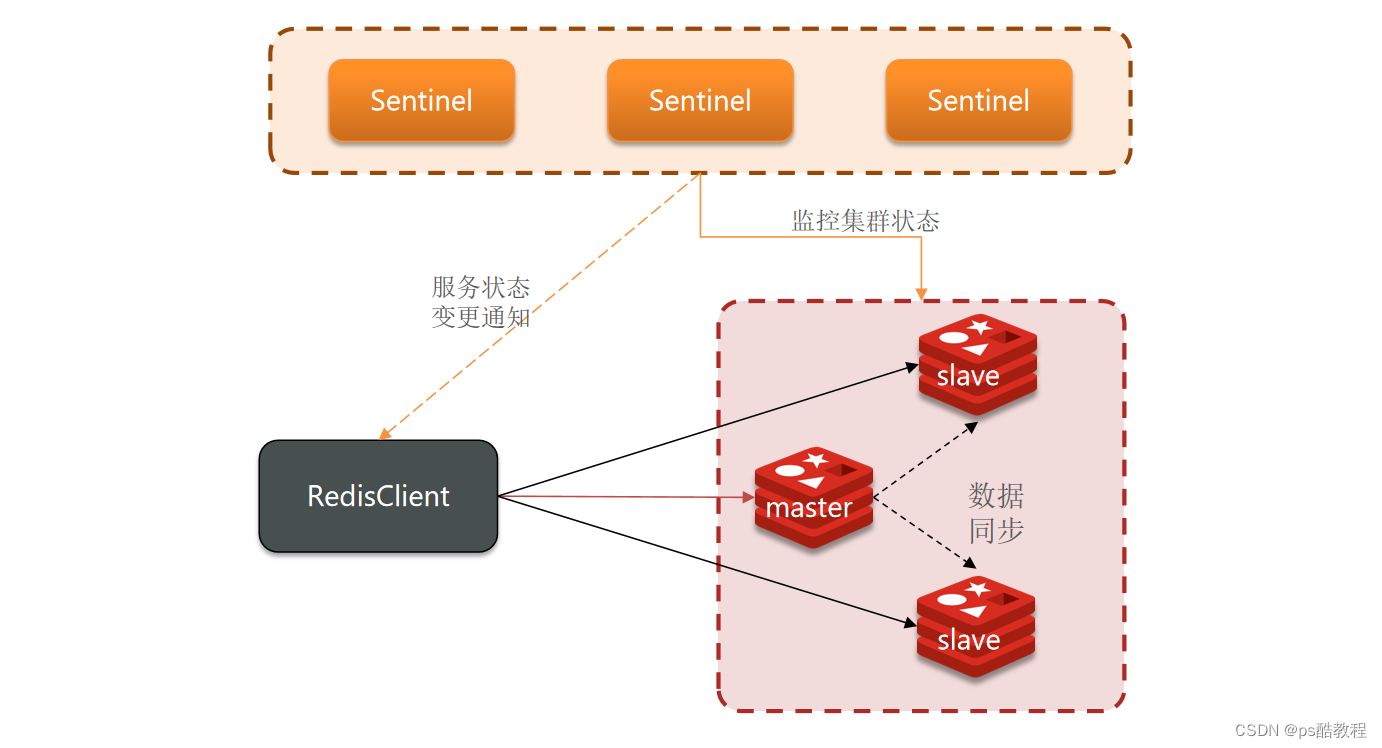
哨兵的结构和作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作(哨兵会监测redis集群中的所有节点状态)
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主(哨兵实现Redis集群的主从切换)
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端(当redis集群中,主节点宕机了,发生主从切换后,主节点的ip和端口信息已然发生变化,因此,哨兵需要让连接到该集群的redis客户端知道该往新的主节点写数据,去其它从节点读数据)
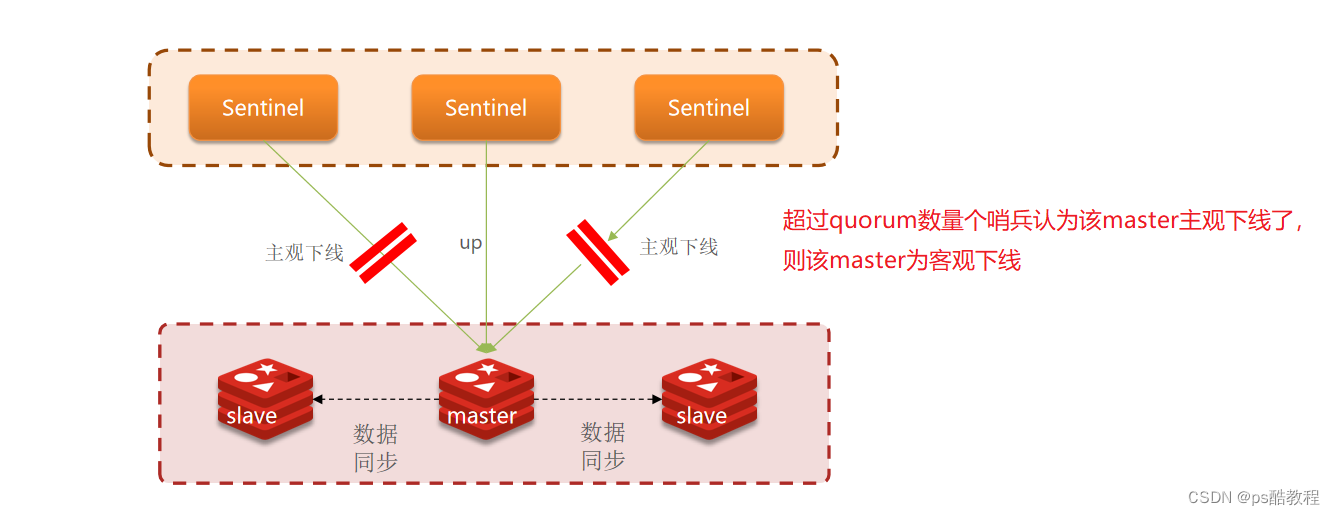
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例
主观下线。 - 客观下线:若超过指定数量(quorum,这个在redis.conf中可配置)的sentinel都认为该实例主观下线,则该实例
客观下线。quorum值最好超过Sentinel实例数量的一半。
选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10,这个在redis.conf中可配置,不配置的话,会使用默认值)则会排除该slave节点(因为断开时间越长,就越可能与原master节点的数据的差异越大)
- 然后判断slave节点的slave-priority值(这个在redis.conf中可配置),越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高(offset其实就衡量了从节点与原主节点的数据同步的进度)
- 最后是判断slave节点的运行id大小,越小优先级越高。
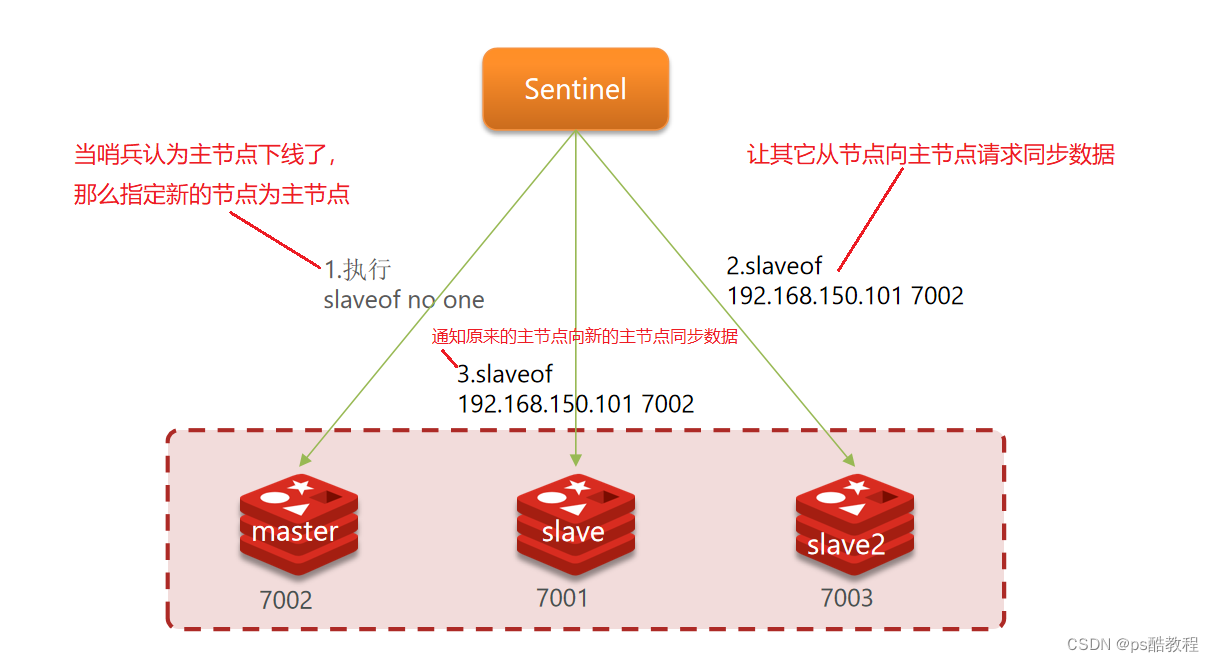
如何实现故障转移
当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下:
- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave(会直接改这个故障节点的配置文件,写上slaveof 新的主节点ip 新的主节点port),当故障节点恢复后,会自动成为新的master的slave节点
总结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
搭建哨兵集群(详细)
集群结构
在前面,我们在/usr/local/redis6/redis-6.2.4/master-slave-cluster目录下创建了3个文件夹:redis7001、redis7002、redis7003,并且分别在这3个文件夹下创建了redis.conf文件,并且分别在这3个文件夹下启动了,并且让7002和7003成为了7001的从节点,形成了1个redis集群。现在在这个基础之上,搭建1个sentinel集群来监控这个redis集群的状态。
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
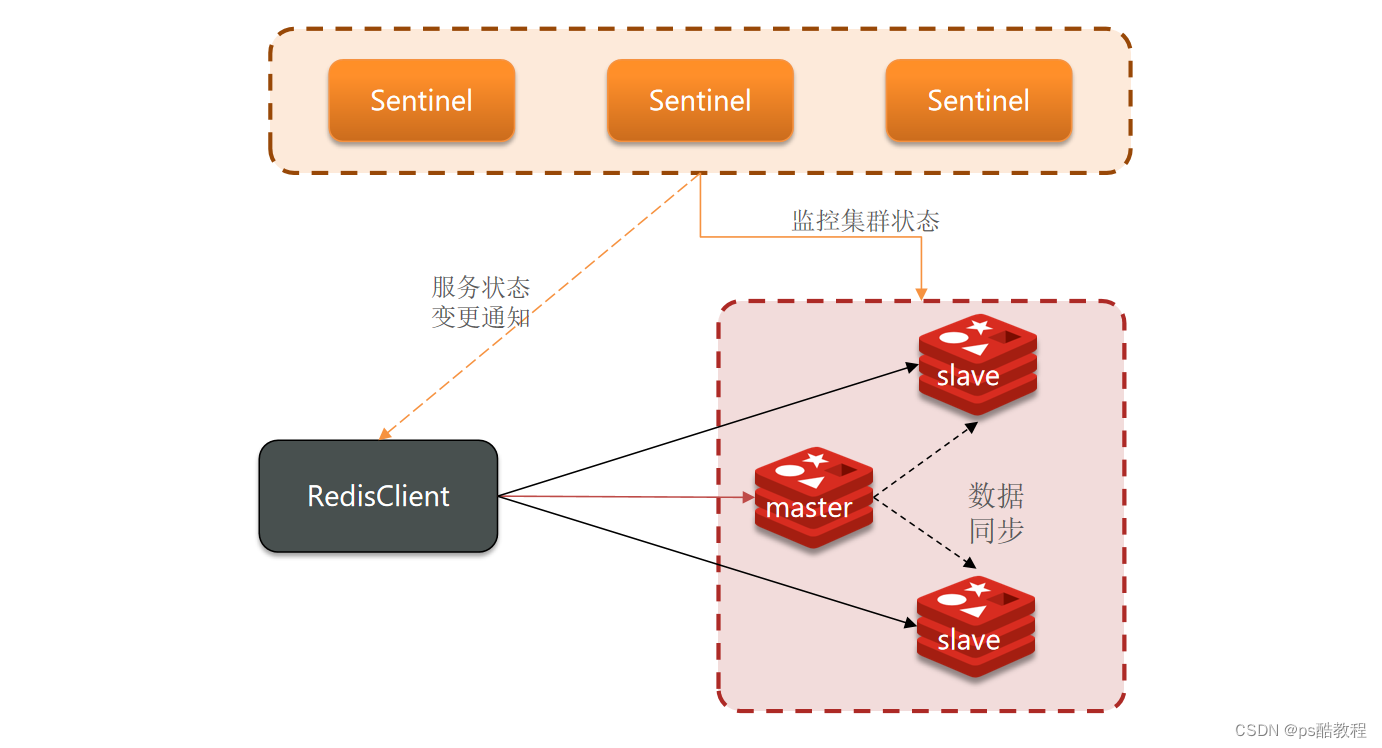
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 172.17.23.234 | 27001 |
| s2 | 172.17.23.234 | 27002 |
| s3 | 172.17.23.234 | 27003 |
准备实例和配置
准备sentinel-cluster文件夹
在/usr/local/redis6/redis-6.2.4目录下创建sentinel-cluster文件夹,并且在该sentinel-cluster文件夹下创建sentinel27001、sentinel27002、sentinel27003这3个文件夹,这3个文件夹用来分别启动redis的sentinel哨兵。
在sentinel.conf文件,添加下面的内容:
# 当前sentinel实例的端口
port 27001# 虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息
sentinel announce-ip 172.17.23.234# 指定主节点信息(这里监控的是master, 从master上可以知道该master下所有的slave信息, 因此能监控整个redis集群)
sentinel monitor mymaster 172.17.23.234 7001 2# slave与master断开最大超时时间
sentinel down-after-milliseconds mymaster 5000# slave故障恢复超时时间
sentinel failover-timeout mymaster 60000# 哨兵存放数据的工作目录(这里使用的是相对于redis-sentinel命令的运行目录, 所以redis-sentinel命令是在各自的目录下运行的)
dir ./
解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 172.17.23.234 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写172.17.23.234:主节点的ip和端口2:选举master时的quorum值(超过quarunm数量的sentinel认为主节点主观下线了,那么该master就是客观下线了)
并且,此时我们的redis的3个服务是正在运行的

启动哨兵
将/usr/local/redis6/redis-6.2.4/sentinel-cluster文件夹下的sentinel.conf配置文件拷贝到sentinel27001、sentinel27002、sentinel27003文件夹下,并修改为各自所对应的哨兵端口!然后,在各自的目录下使用各自的sentinel.conf配置文件,使用redis-sentinel ./sentinel.conf命令分别启动这3个哨兵
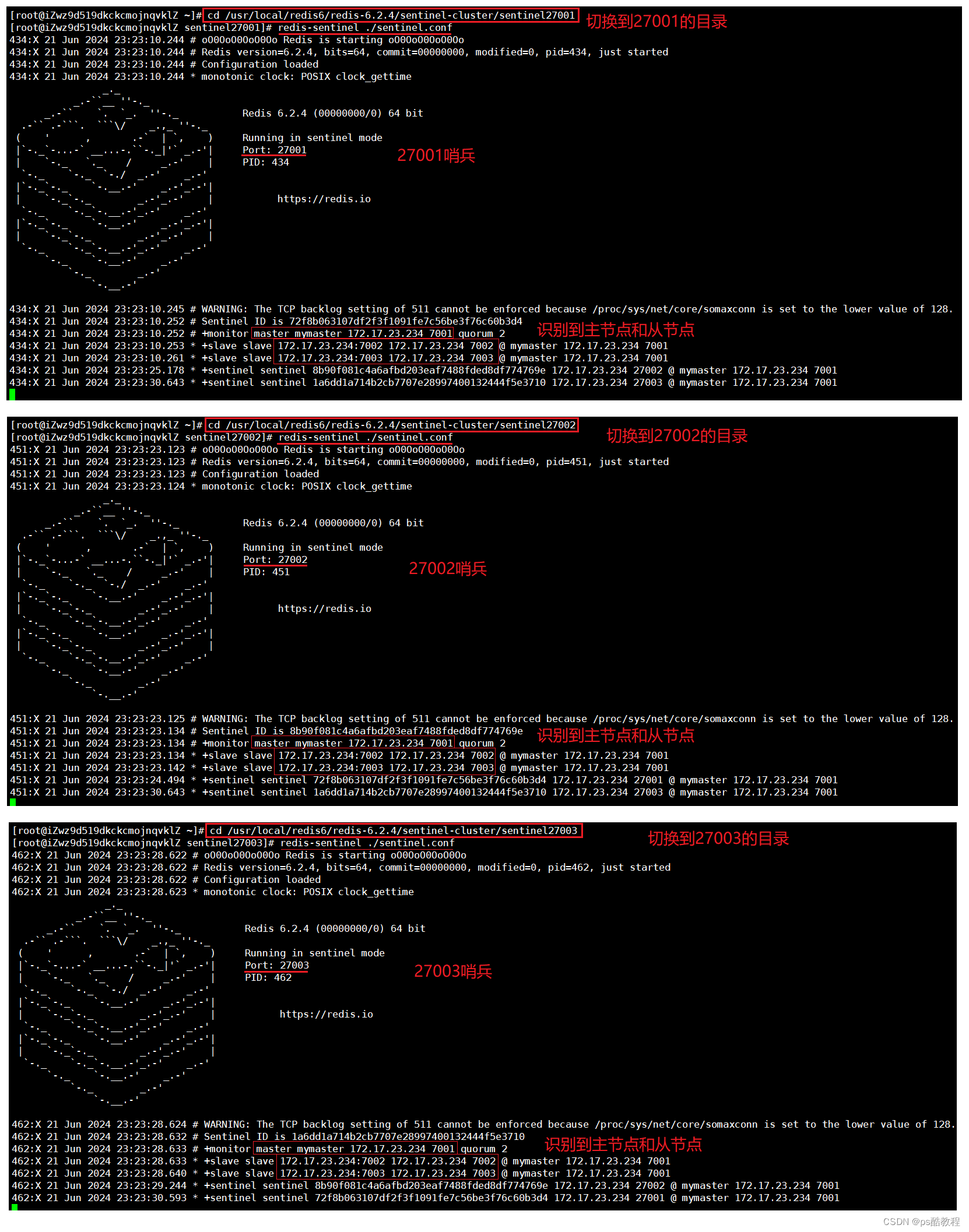
模拟主节点宕机
现在连接上7001这台redis,执行shutdown,即关闭7001的服务。然后,观察哨兵的日志,发现发生了故障转移,并且选举了7002作为新的master,并且会修改7001,7002,7003的配置文件(刚开始启动这3个redis服务时,是使用redis命令来临时指定主节点的),现在哨兵发现7001关闭后,是直接改了7001,7002,7003的配置文件。

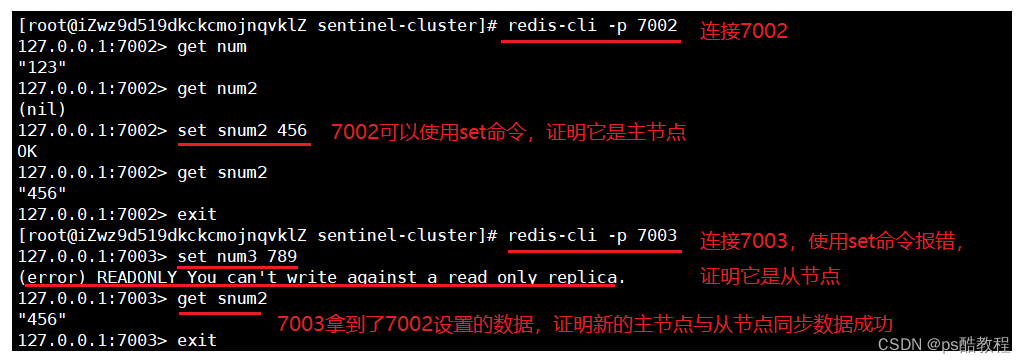
测试哨兵是否生效
连接上7002,测试是否能够使用set命令,能使用set命令说明它是主节点,而7003不能使用set命令,说明它是从节点。并且7003能够拿到7002设置的数据,证明主从数据同步成功
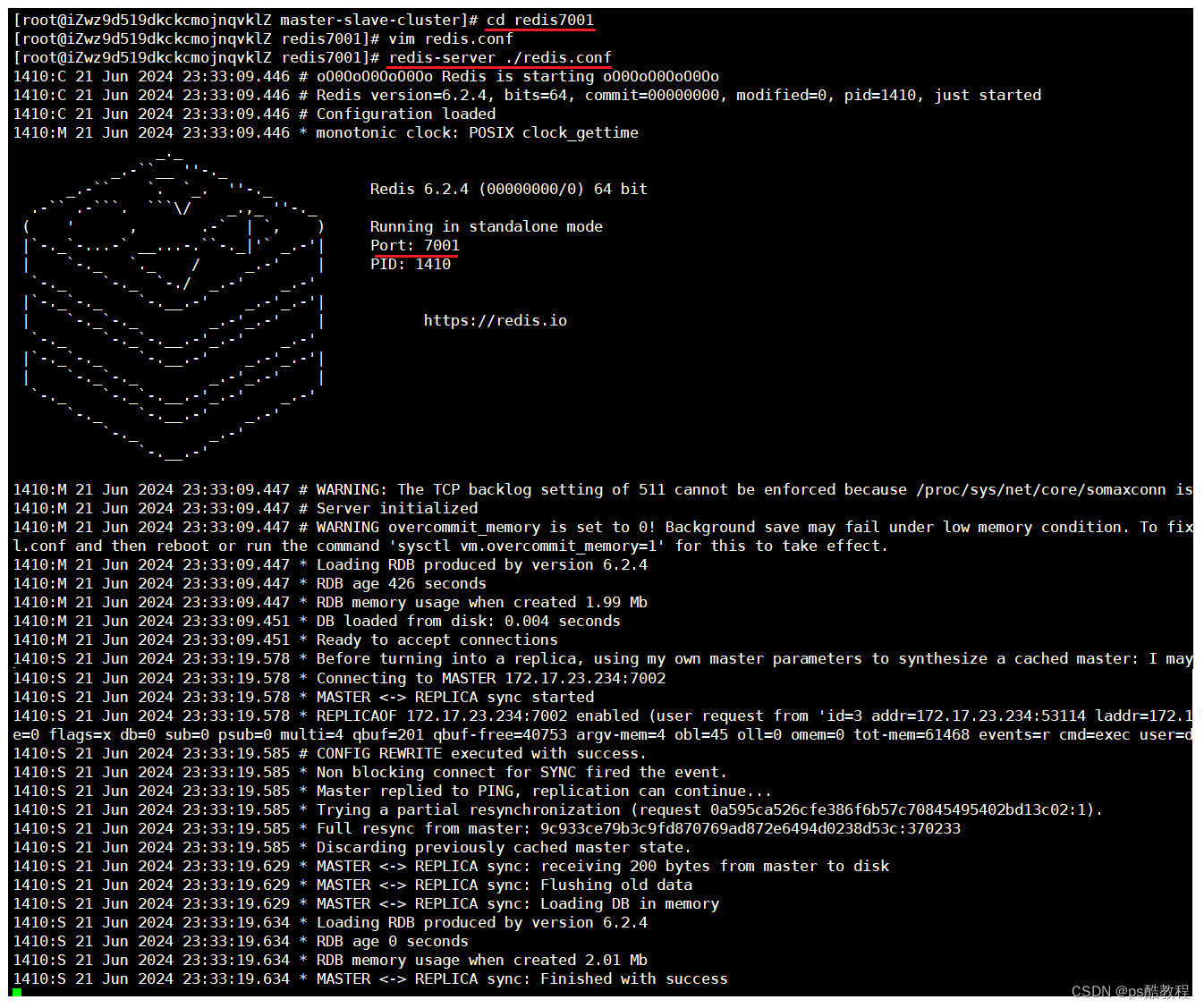
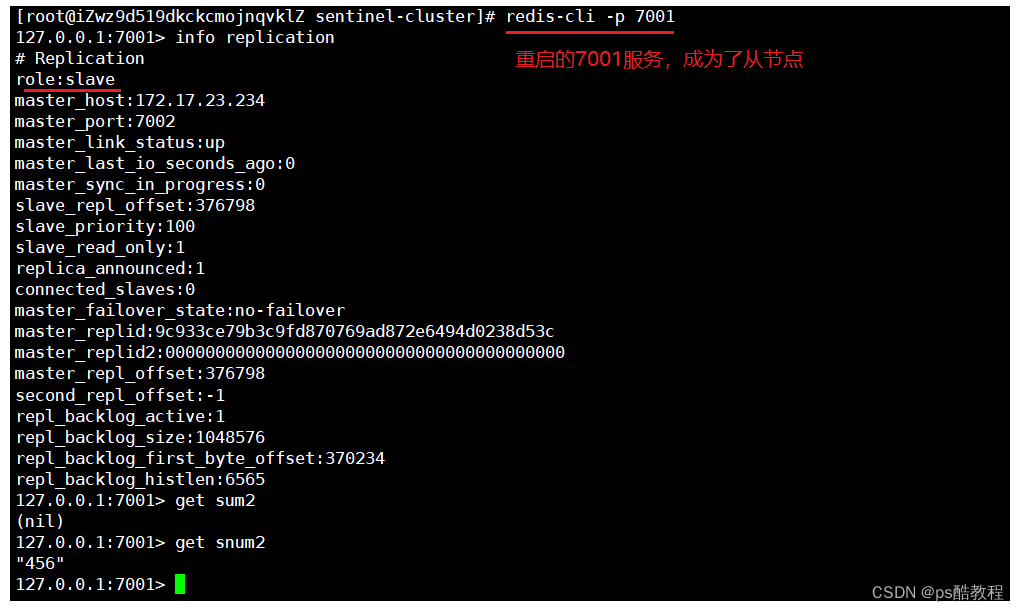
重启原来的主节点
重新启动7001,查看7001的节点信息,发现原来的7001主节点成为了新主节点7002的从节点,并且7001请求同步7002主节点的数据
RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生主从切换的变化,Redis的客户端必须感知这种变化,及时更新连接信息(因为Redis主从集群中实现了读写分离,只有主节点能读写,从节点只能读)。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
前面提到:哨兵的1个作用是通知,也就是当使用sentinel监控redis主从集群时,当redis主从集群中的主节点发生宕机,发生主从切换时,哨兵负责选举出新的主节点,并让其它节点成为从节点,并且哨兵需要通知给连接redis服务的客户端主节点的ip和端口信息已然发生变化。
配置步骤
1、在pom文件中引入redis的starter依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、然后在配置文件application.yml中指定sentinel相关信息:
(注意:这里配置的不是redis集群的地址,而是sentinel的地址,在使用sentinel监控redis集群时,redis集群的主节点宕机时会发生主从切换,主节点地址会发生变更,所以主节点地址不能写死,所以不需要知道redis集群的地址,而只要知道sentinel的地址即可。基于哨兵来做对redis服务的发现,因此下面配置的就是哨兵的地址了。因为哨兵通过监控哨兵配置文件里配置的的redis主节点,就能知道所有redis从节点的信息。)
spring:redis:sentinel:master: mymaster # 指定master名称(哨兵配置文件设置的集群名称)nodes: # 指定redis-sentinel集群信息- 172.17.23.234:27001- 172.17.23.234:27002- 172.17.23.234:27003
3、配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这里的ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master(推荐)
哨兵配置示例(详细)
按照之前的步骤搭建redis主从集群(7002是主节点,7001和7003是从节点),并且搭建1个sentinel集群(27001,27002,和27003这3个哨兵)来监控这个redis集群。在redis主从集群中,只有主节点能够读取和写入数据,从节点只能读取数据,即读写分离。当redis主从集群中的主节点发生宕机时,哨兵就会从redis主从集群中,选举新的主节点,并完成主从切换,完成主从切换后,哨兵就要将新的主从信息通知给连接该redis集群的客户端。
这里在测试前,按照之前的配置,只修改了ip配置为公网ip,然后重新启动了redis主从集群和sentinel哨兵集群用于测试。
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.9.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>cn.itcast</groupId><artifactId>redis-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>redis-demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>配置文件
logging:level:io.lettuce.core: debugpattern:dateformat: MM-dd HH:mm:ss:SSS
spring:redis:sentinel:master: mymasternodes:- 119.23.61.24:27001- 119.23.61.24:27002- 119.23.61.24:27003
HelloController
@RestController
public class HelloController {@Autowiredprivate StringRedisTemplate redisTemplate;@GetMapping("/get/{key}")public String hi(@PathVariable String key) {return redisTemplate.opsForValue().get(key);}@GetMapping("/set/{key}/{value}")public String hi(@PathVariable String key, @PathVariable String value) {redisTemplate.opsForValue().set(key, value);return "success";}}
RedisDemoApplication
@SpringBootApplication
public class RedisDemoApplication {public static void main(String[] args) {SpringApplication.run(RedisDemoApplication.class, args);}/* 配置优先从 从节点读取数据(而只能是主节点才能写入) */@Beanpublic LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);}
}测试
访问:http://localhost:8080/set/name/zzhua写入数据,
再访问:http://localhost:8080/get/name读取数据。
日志输出如下:
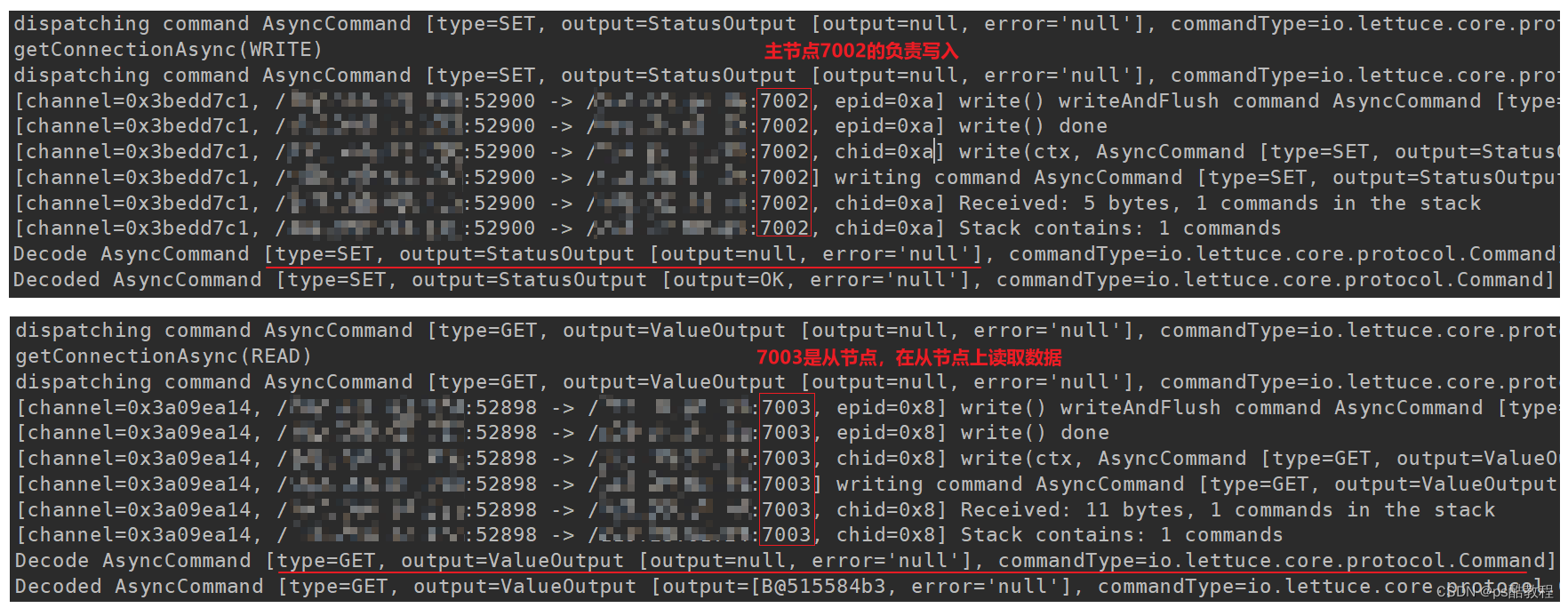
此时,关闭7002主节点的服务,7003切换为主节点。此时客户端收到了通知,日志输出如下:
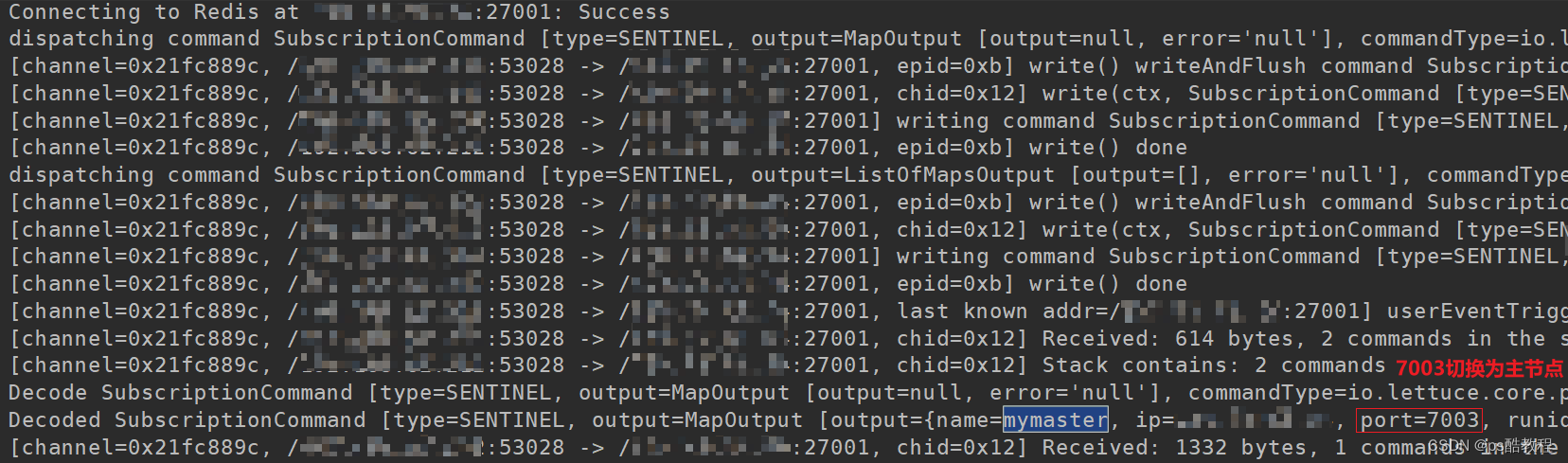
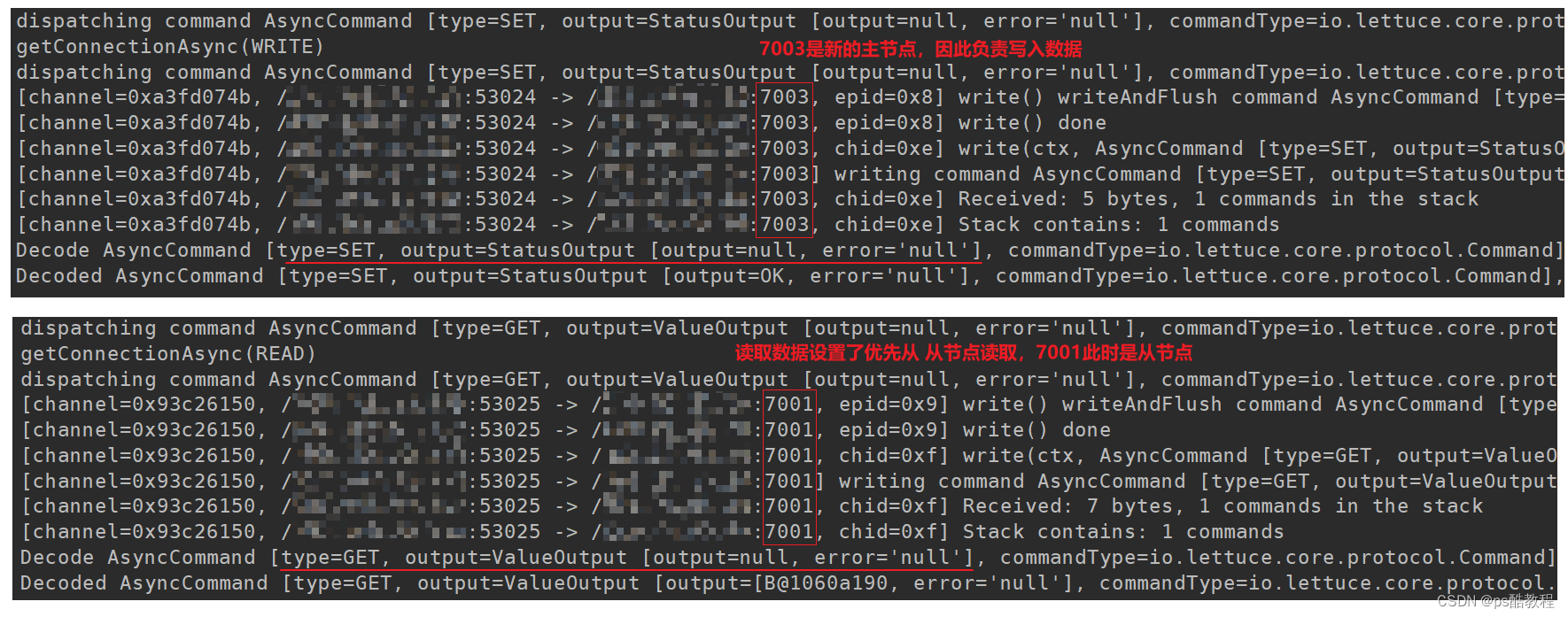
访问:http://localhost:8080/set/a/b写入数据,
再访问:http://localhost:8080/get/a读取数据。
日志输出如下,可以看到新的主节点负责写入数据了:
5. Redis分片集群 -> 存储能力问题
分片集群结构
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题(单节点的redis服务的内存不能过高,如果过高会导致RDB持久化或者全量同步时,会导致大量的IO,致使性能下降;redis服务内存既然不能过高,但是如果有海量数据需要存储,又会无法应对)
- 高并发写的问题(主从集群可以应对高并发读的问题,但如果此时有大量写的请求需要处理,那么就应对不了高并发写的问题了)
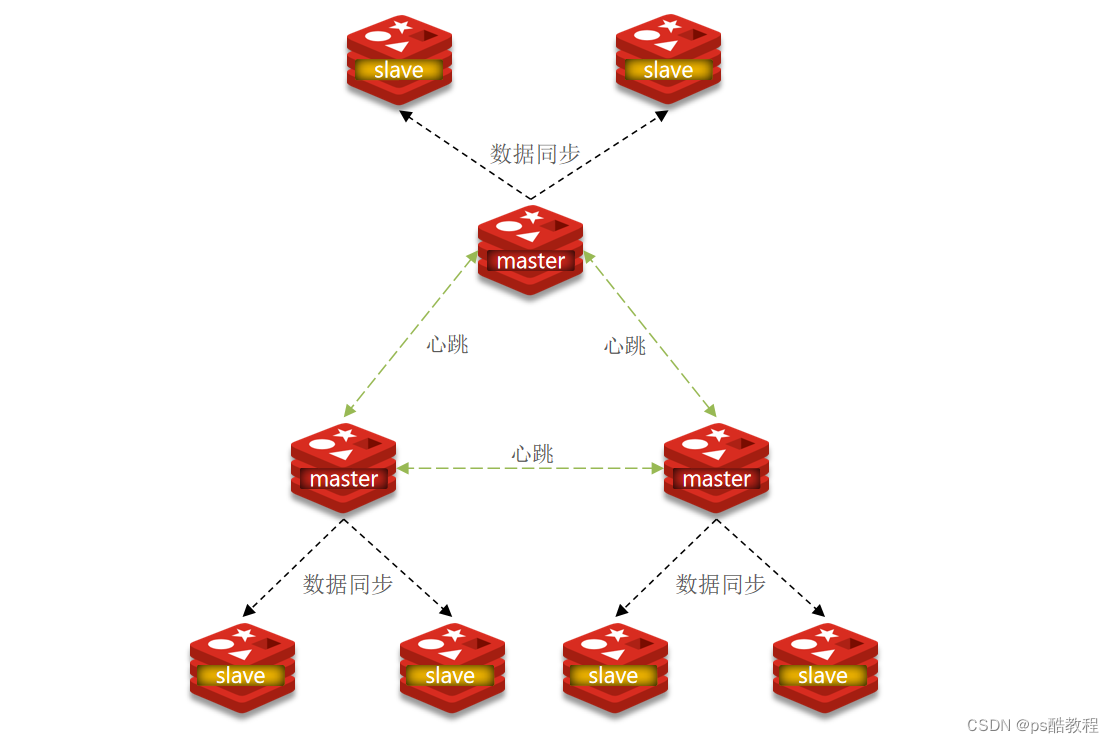
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据(此时,redis服务存储上限就是各master存储量之和,应对了海量数据存储的问题;写入时也可从多个master中选择,写的能力也提升了,应对了高并发写的问题;)
- 每个master都可以有多个slave节点(应对了高并发读的问题)
- master之间通过ping监测彼此健康状态(此时不需要哨兵了,master与master之间会互相监测,就起到了哨兵的作用)
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点(当某个master宕机了,此时就会发生主从切换,如果没有哨兵,该怎么通知客户端呢?其实,master与master之间会做自动的路由,客户端可以访问任意1个master节点,它都会将请求转发到正确的节点,因此就不再需要哨兵了,但是又具备了哨兵的所有功能)
搭建分片集群示例(详细)
集群结构
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
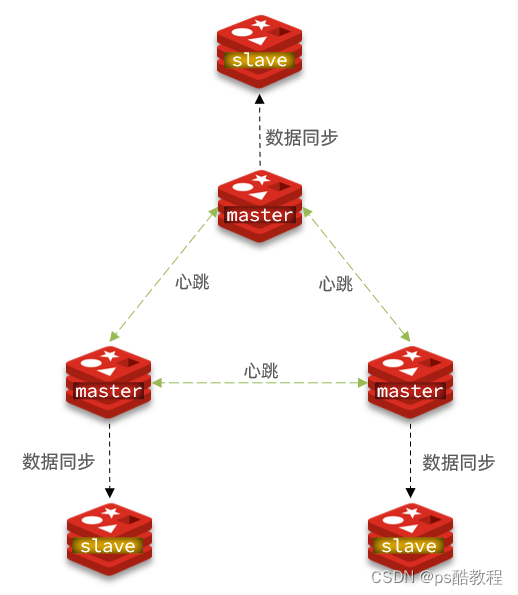
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 119.23.61.24 | 7001 | master |
| 119.23.61.24 | 7002 | master |
| 119.23.61.24 | 7003 | master |
| 119.23.61.24 | 8001 | slave |
| 119.23.61.24 | 8002 | slave |
| 119.23.61.24 | 8003 | slave |
准备实例和配置
在/usr/local/redis6/redis-6.2.4下创建slice-redis-cluster目录,并在这个slice-redis-cluster目录下创建node7001、node7002、node7003、node8001、node8002、node8003,并创建1个redis.conf的配置文件,文件内容如下。
# 端口(指定各自的端口)
port 7001# 开启集群功能
cluster-enabled yes# 集群的配置文件名称,不需要我们创建,由redis自己维护(指定各自的集群配置文件, 记住千万不需要创建; 后面由于返回给java客户端的ip是内网ip, 所以生成node.conf之后, 将所有节点的内网ip改为公网ip,然后重启整个集群)
cluster-config-file /usr/local/redis6/redis-6.2.4/slice-redis-cluster/node7001/node.conf# 节点心跳失败的超时时间(集群之间互相发送心跳, 如果5s之内没有收到, 那么认为宕机了)
cluster-node-timeout 5000# 持久化文件存放目录(指定各自的持久化目录)
dir /usr/local/redis6/redis-6.2.4/slice-redis-cluster/node7001# 绑定地址(设置为0.0.0.0, 则任何人都能访问)
bind 0.0.0.0# 让redis后台运行(以守护进程运行)
daemonize yes# 注册的实例ip
replica-announce-ip 119.23.61.24# 保护模式(不需要做用户名、密码的校验了)
protected-mode no# 数据库数量
databases 1# 日志(指定各自的日志文件的位置)
logfile /usr/local/redis6/redis-6.2.4/slice-redis-cluster/node7001/run7001.log

将redis.conf文件拷贝到这6个节点文件夹中,并且修改对应的端口和其它配置(就是全局替换,比如:将所有的7001改为7002即可,vim中的操作命令如下,依次修改即可)
:%s/7001/7002/g
现在/usr/local/redis6/redis-6.2.4/slice-redis-cluster目录下有6个节点文件夹和1个redis.conf配置文件,每个节点文件夹下仅有1个redis.conf配置文件(并且已经修改了配置)。
启动各节点
因为已经配置了后台启动模式,所以可以直接启动服务,分别启动各个redis节点
查看redis是否都正常启动了(如果要关闭所有的redis,此时可执行:如果要关闭所有redis的进程,可以执行命令:ps -ef | grep redis | awk '{print $2}' | xargs kill,或 者使用redis-cli -p 端口挨个连接上去使用shutdown关闭即可)

创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
实战操作如下:
这里我们使用redis-cli --cluster命令来创建集群(可以使用redis-cli --cluster help来查看帮助)
使用如下命令创建集群,命令的解释在上方已详述(这里有个坑:如果使用阿里云执行该命令时,需要先放开7001、7002、7003、8001、8002、8003,还有:17001、17002、17003、18001、18002、18003,其实就是节点的端口加上10000所得到的端口也得放开(否则会一直卡在Waiting for the cluster to join那里不动),这一点可以从成功启动后的下方日志可以看到)
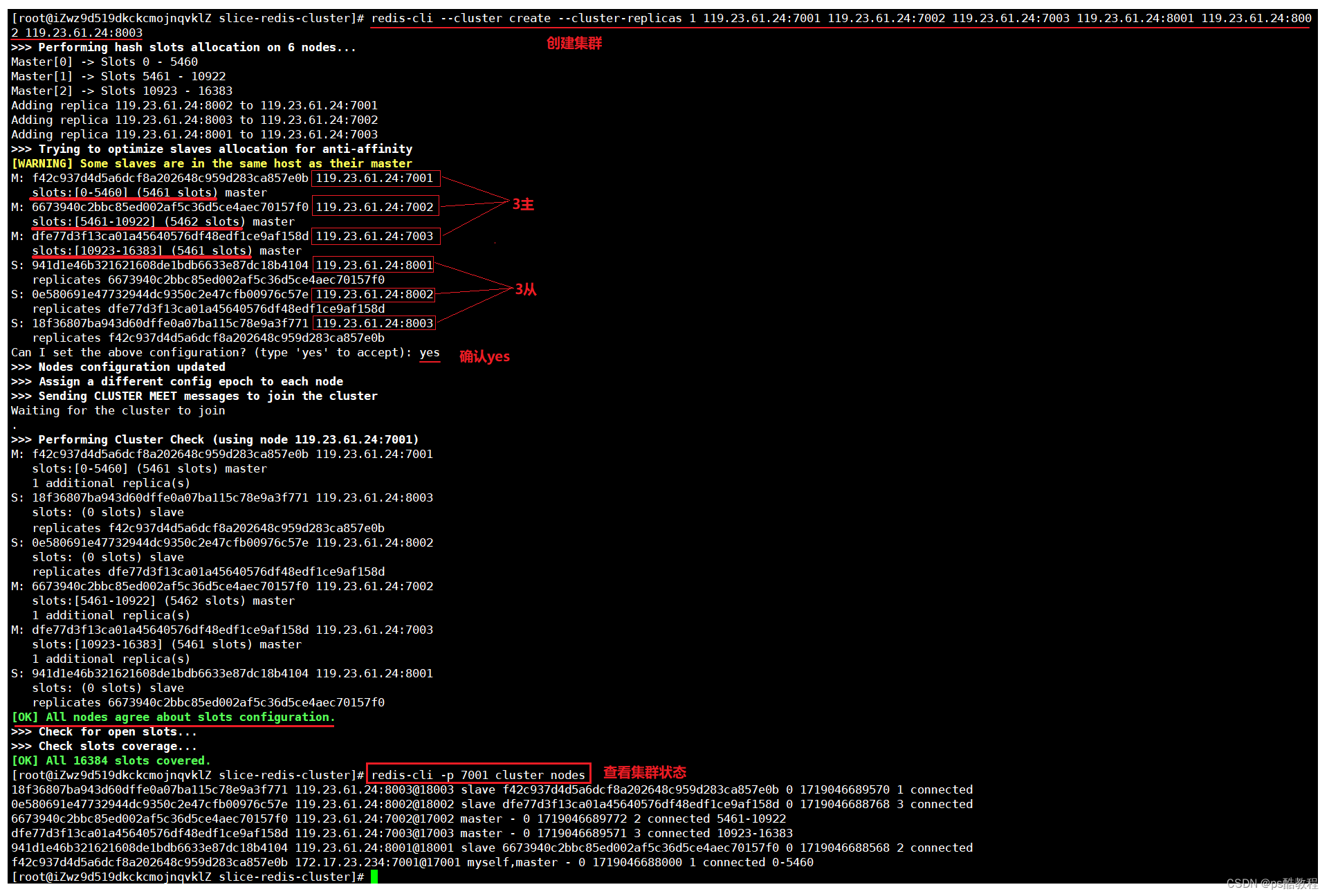
redis-cli --cluster create --cluster-replicas 1 119.23.61.24:7001 119.23.61.24:7002 119.23.61.24:7003 119.23.61.24:8001 119.23.61.24:8002 119.23.61.24:8003
# 忽略下面的这些命令, 只是实战的时候, 出了些问题, 就记录下这些命令方便复制
ps -ef | grep redis | awk '{print $2}' | xargs kill
ps -ef|grep redis
rm -rf node700*/*.rdb node700*/node.conf node700*/*.log node800*/*.rdb node8*/node.conf node800*/*.log
redis-cli -p 7001 cluster nodes
redis-cli --cluster add-node 119.23.61.24:7004 119.23.61.24:7001
创建集群后,通过命令可以查看集群状态(在其中可以看到不同范围插槽分布在哪些节点上):
redis-cli -p 7001 cluster nodes
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:

数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
(为什么这样设计:redis的主节点可能会出现宕机的情况,或者是集群扩容增加节点,或者是集群伸缩删除的节点,如果1个节点删除了或者宕机了,那么在这个节点上的数据也就丢失了,而如果数据是跟插槽绑定的,此时当节点宕机时,将此宕机节点的插槽转移到还存活的节点上去;当集群扩容时,将插槽进行转移,这样数据跟着插槽走,就一定能找到数据存储的位置。)
总结
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例(因为不在同一个redis节点,那么就需要重定向到其它节点去获取值)?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀(使用这种方法,可以设置key的有效部分,来控制存储数据时,一定落在相同的节点)
集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:
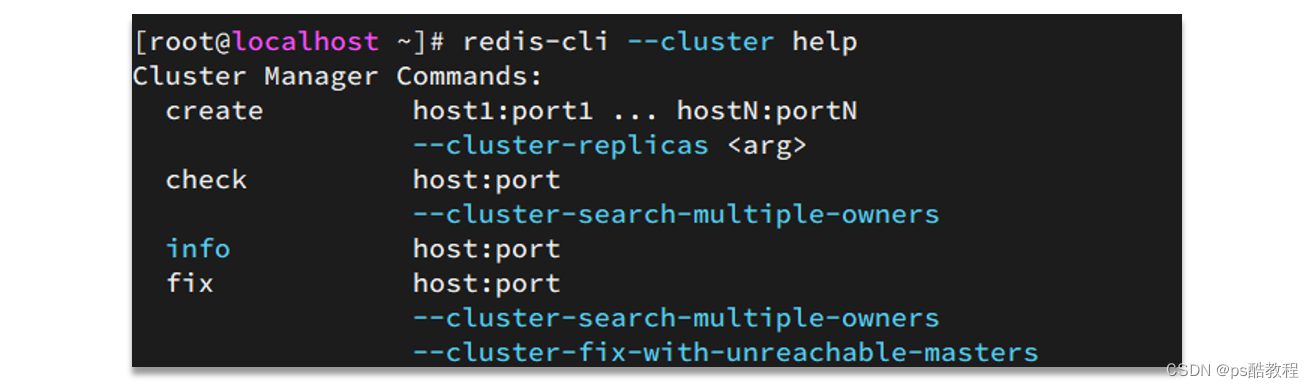
比如,添加节点的命令(如果添加上–cluster-slave表示添加进去就是从节点,并且–cluster-master-id表示作为哪个主节点的从节点;如果不加这2个配置项,表示加进去就是主节点;):

添加集群节点&分片插槽示例(详细)
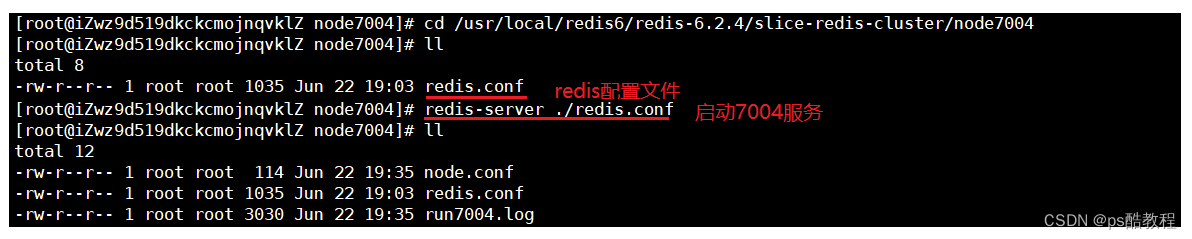
在/usr/local/redis6/redis-6.2.4/slice-redis-cluster目录下创建node7004文件夹,并且在node7004文件夹下创建redis.conf,配置的内容就直接复制《搭建分片集群示例》中的配置内容,并且把里面的7001全改成7004即可。然后,启动7004服务。
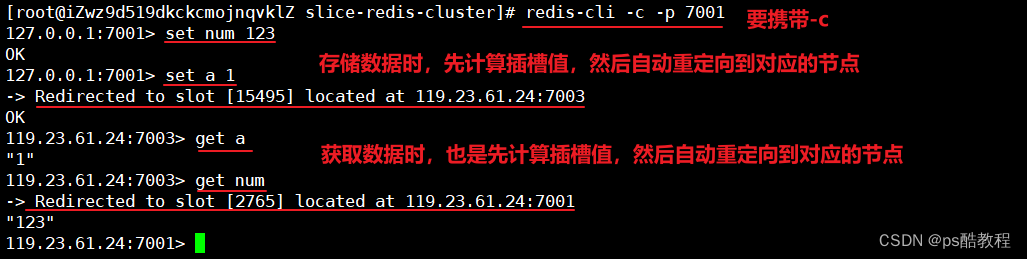
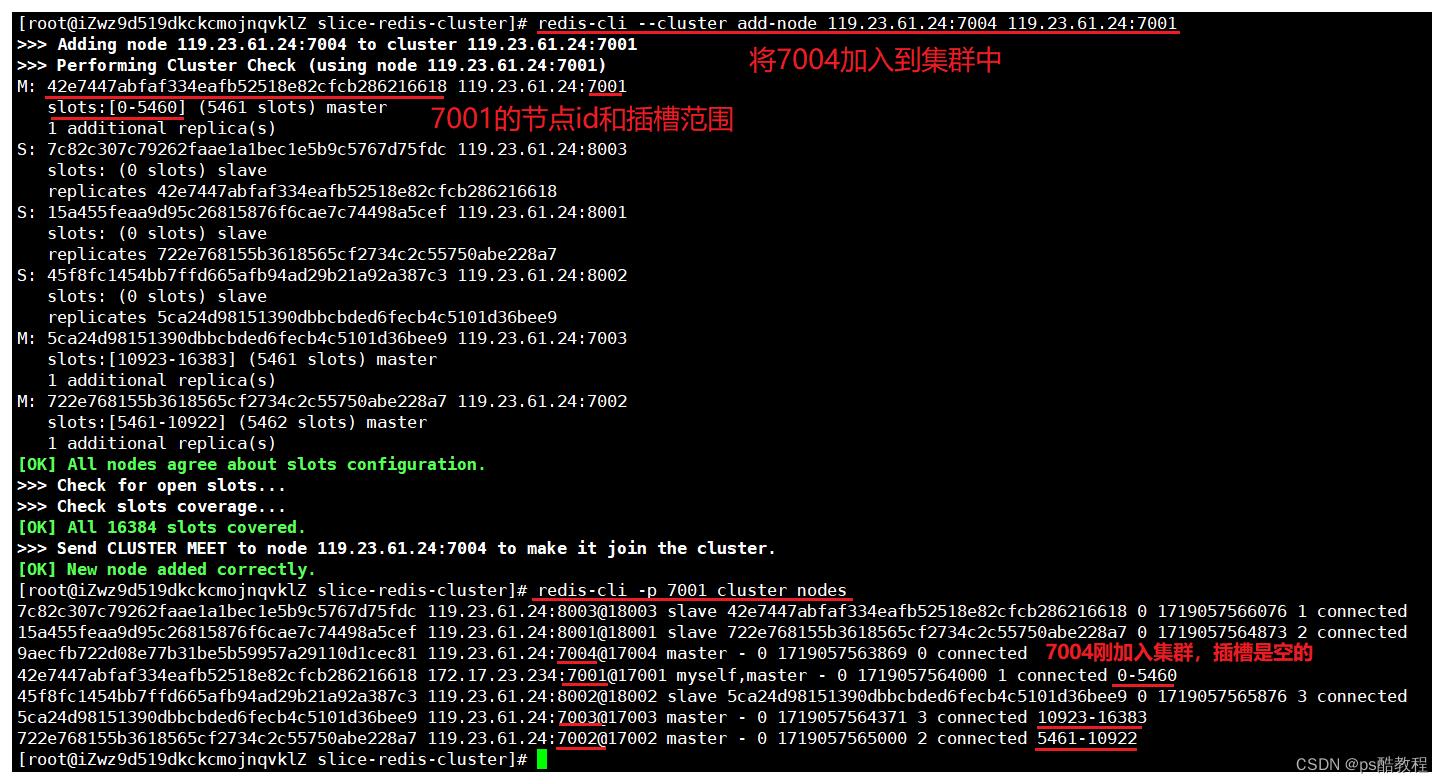
在前面《搭建分片集群示例》的基础上,使用redis-cli --cluster add-node 119.23.61.24:7004 119.23.61.24:7001(可以通过redis-cli --cluster help命令查看帮助文档)将7004服务添加到集群作为1个新的master节点(可以通过redis-cli --cluster help命令查看add-node命令的参数介绍了解,如果不添加后续参数,那么添加的就是master主节点,也可以指定后续参数来添加为指定主节点的从节点),其中第二个参数只需要填1个已知的节点即可。这里再通过redis-cli -p 7001 cluster nodes命令可以查看到集群的状态和各个主节点的插槽范围。
现在使用redis-cli -c -p 7001命令访问分片集群,连接上7001服务,可以看到num是在7001服务上,并且是2756插槽上。现在把7001的前3000个插槽,即0-2999范围内的插槽移到7004服务上去。现在可以使用redis-cli -p 7001 cluster nodes命令查看集群状态和各个主节点的插槽范围,可以看到7004服务现在负责0-2999范围内的插槽。
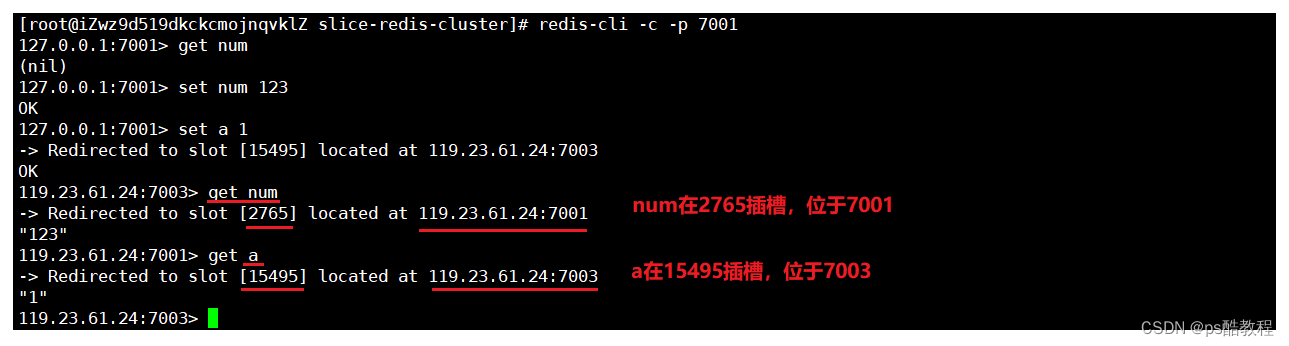
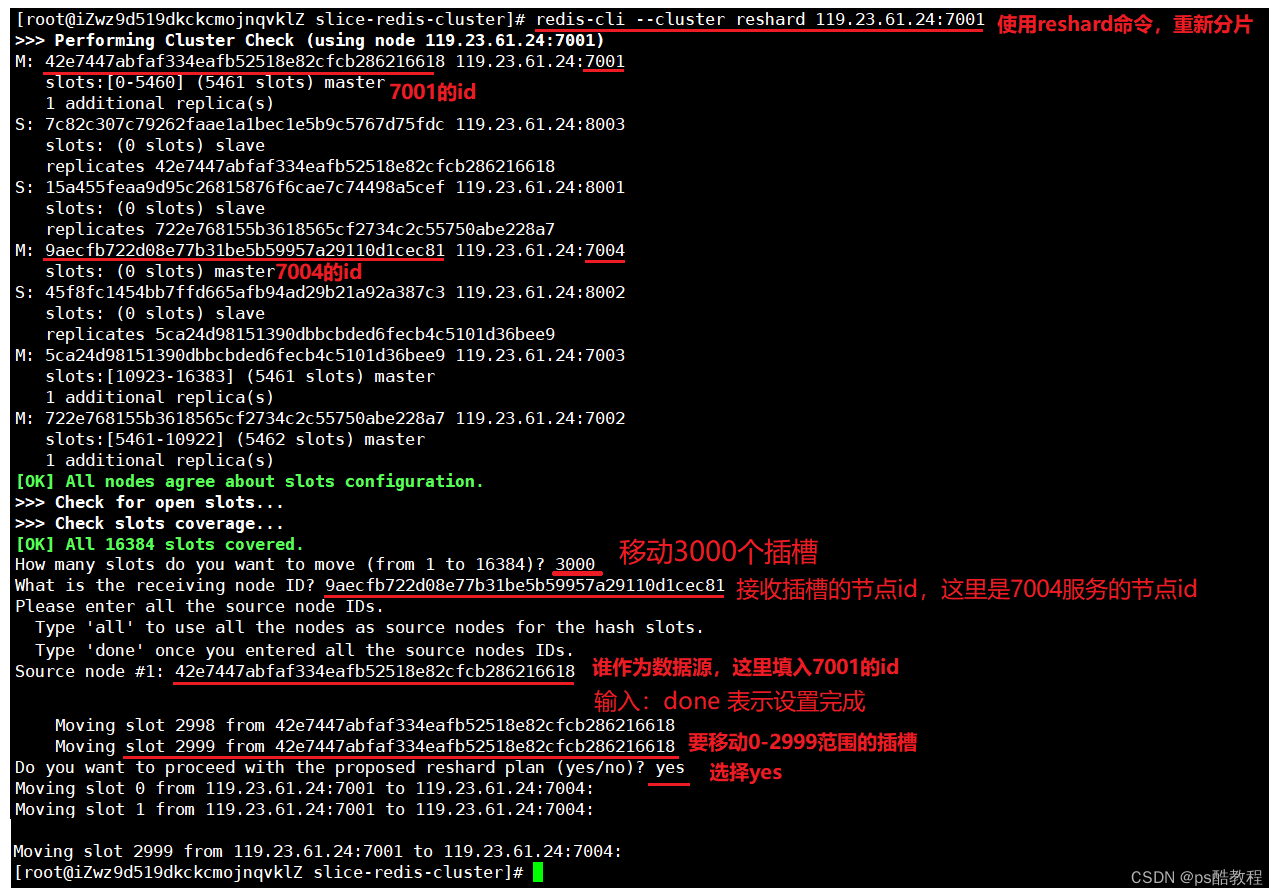

如果插槽移动成功,那么原先在7001服务上的num,现在应该到了7004服务上了。从下面可以看到原本在7001服务的key现在重定向到了7004服务,说明插槽移动成功。

现在在上面的基础上,再从分片集群上移除掉7004这个节点
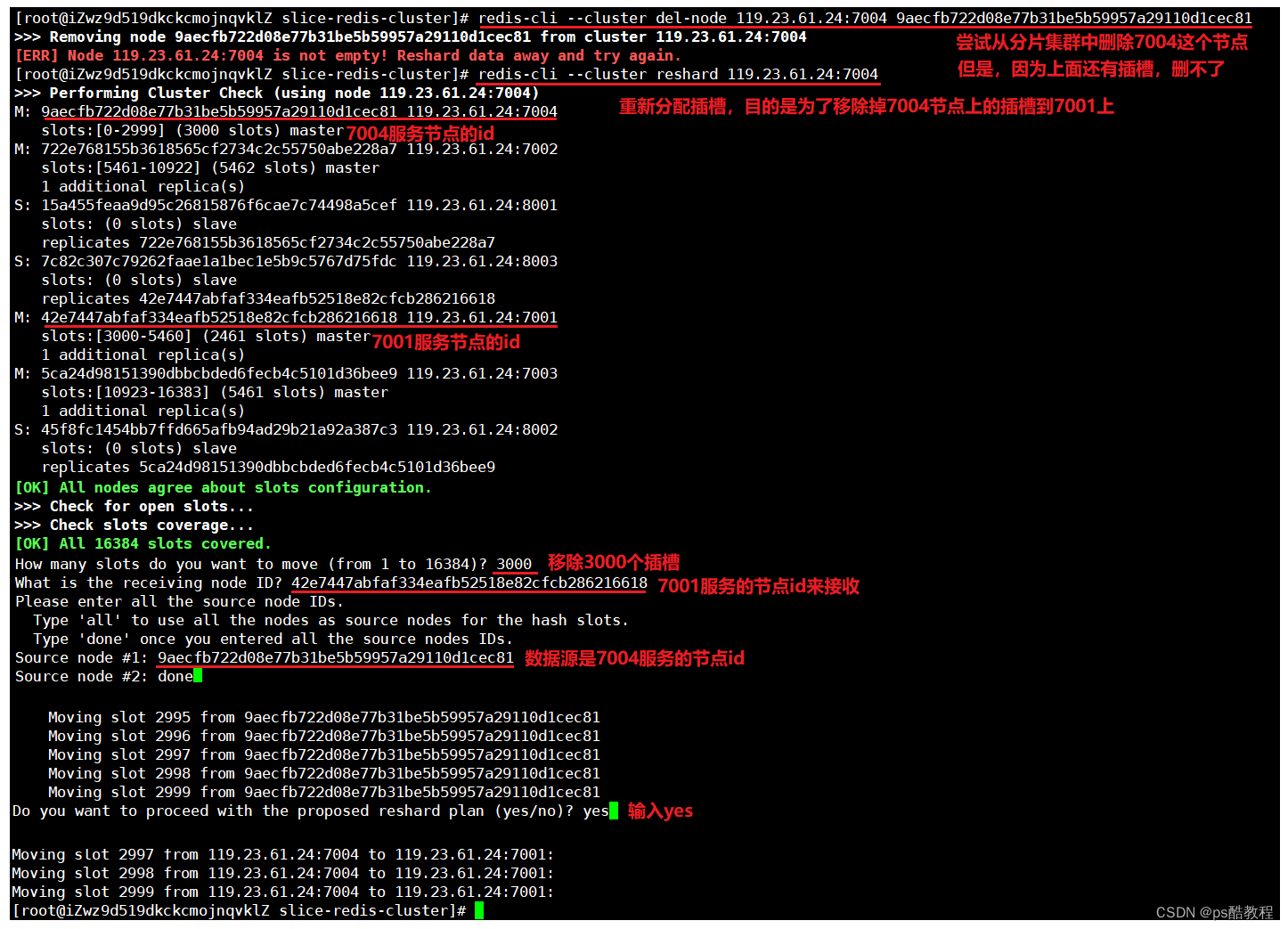
查看集群状态,7004节点的插槽范围没有了,都转移到了7001节点上了
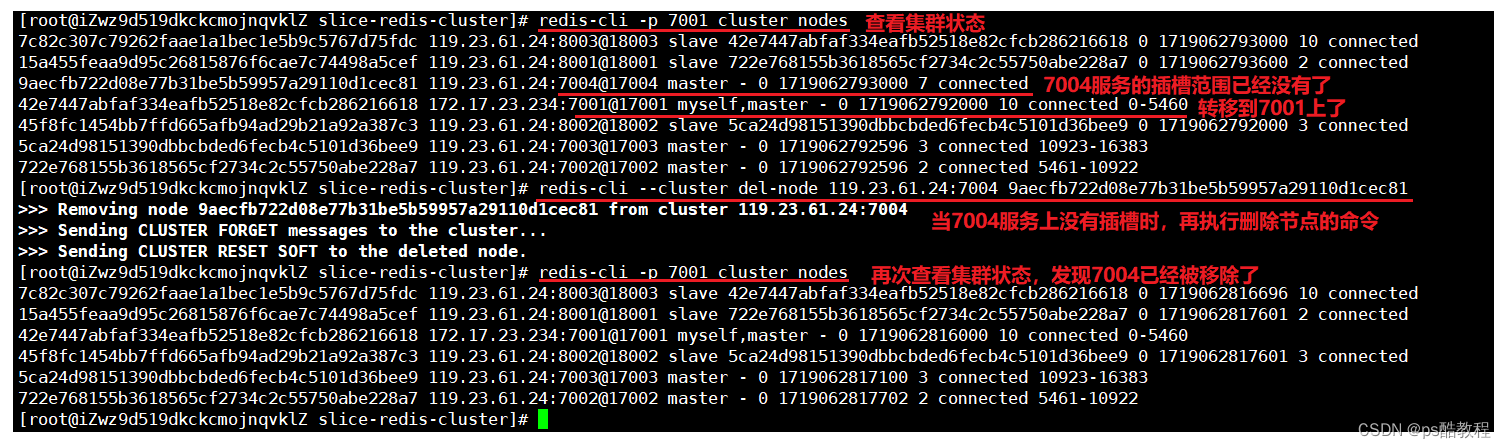
故障转移
分片集群虽然没有哨兵,但是也具有故障转移的功能。
自动故障转移
redis分片集群不需要哨兵,当某个master宕机时,会自动的完成主从切换。
当集群中有一个master宕机会发生什么呢?
- 首先是该实例与其它实例失去连接
- 然后是疑似宕机:
- 最后是确定下线,自动提升一个slave为新的master:
自动故障转移示例(详细)
下面在前面搭建的分片集群的基础上测试:通过watch redis-cli -p 7001 cluster nodes开启集群监控,然后关闭7002节点,在监控板上可以看到7002fail了,然后8001成为了master主节点。随后启动7002,此时的7002成为了slave。这说明分片集群自动具有哨兵的功能,能自动完成故障转移。这种情况发生在某个主节点意外宕机时。
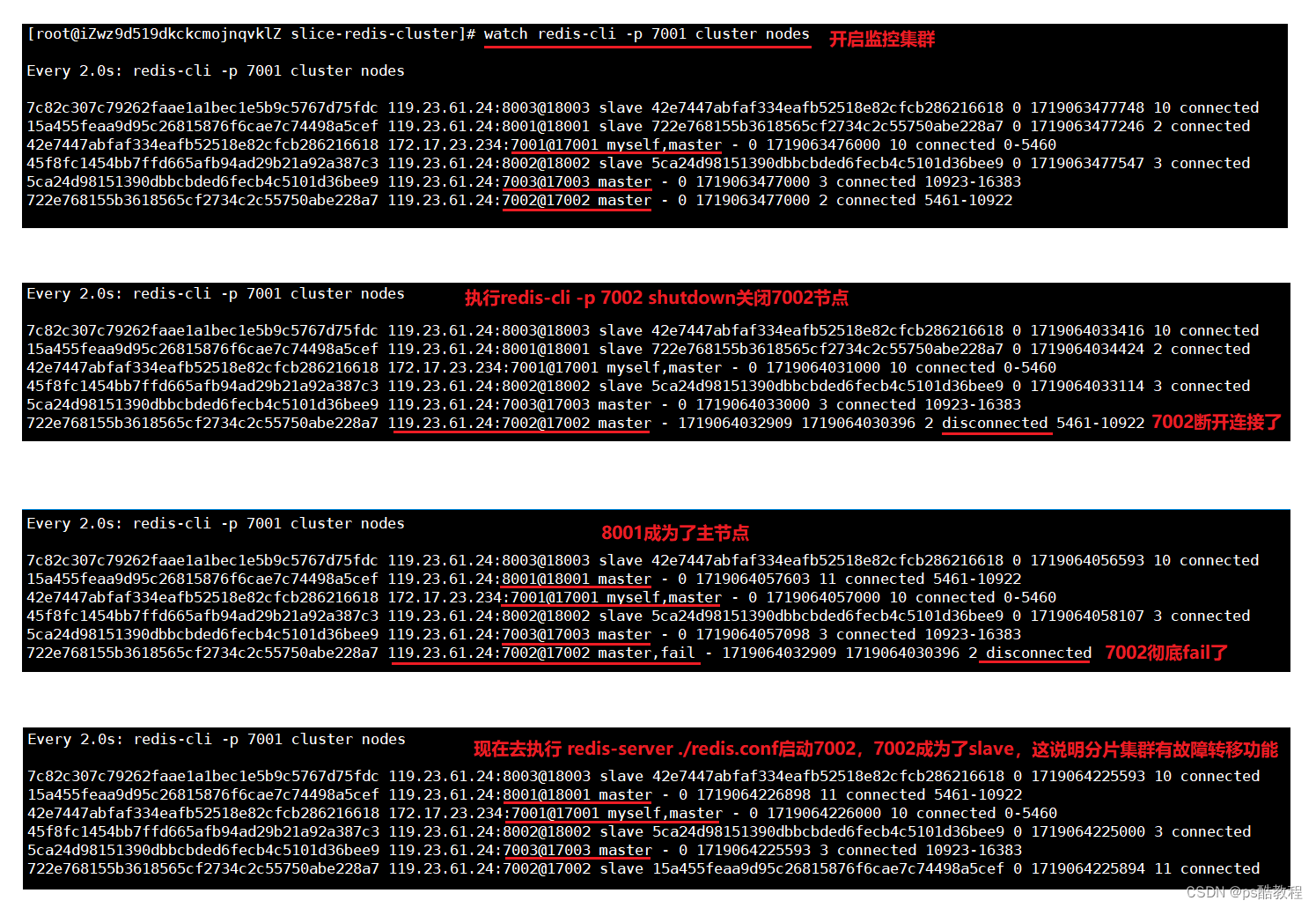
现在的主节点是:7001,7003,8001
手动故障转移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点(这个slave将替换这个master,而成为master主节点),实现无感知的数据迁移。其流程如下:
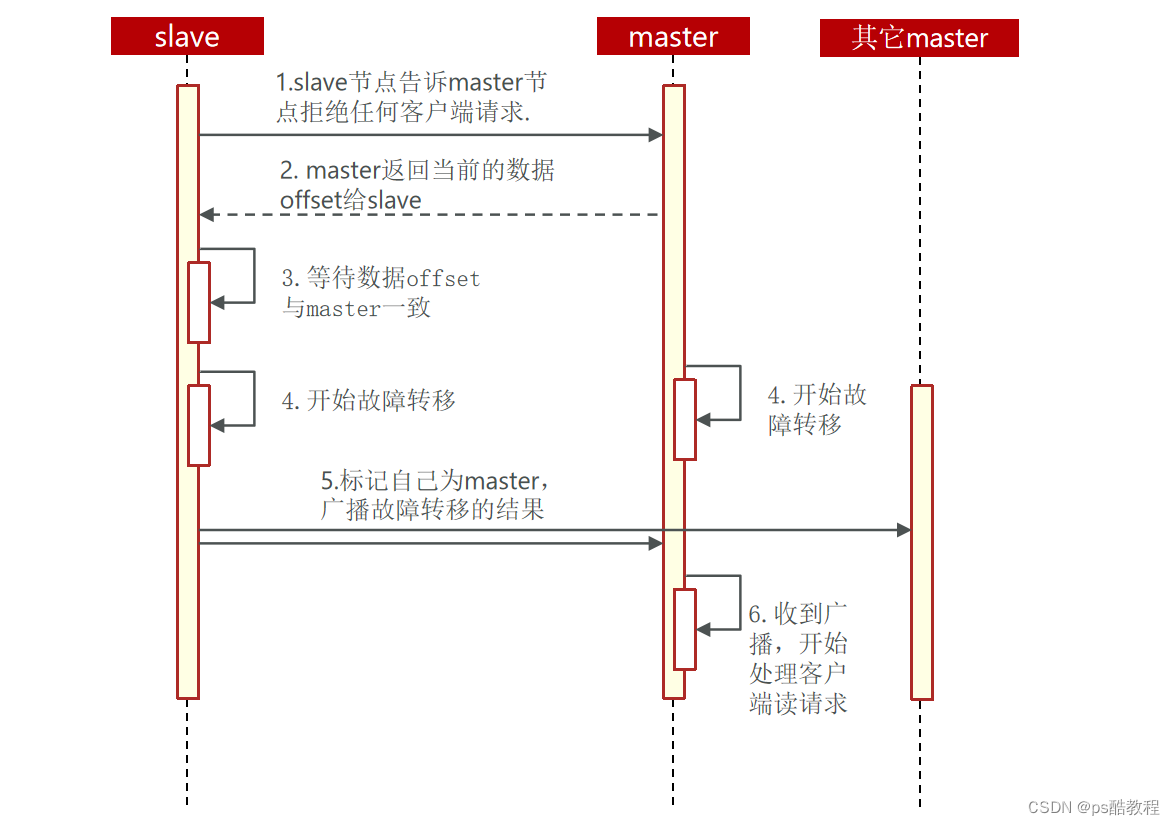
手动的Failover支持三种不同模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验(省略了2、3步,不管数据是否同步,上来就替换,比较暴力)
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见(更暴力)
手动故障转移示例(详细)
在前面自动故障转移示例的基础上,作如下测试:
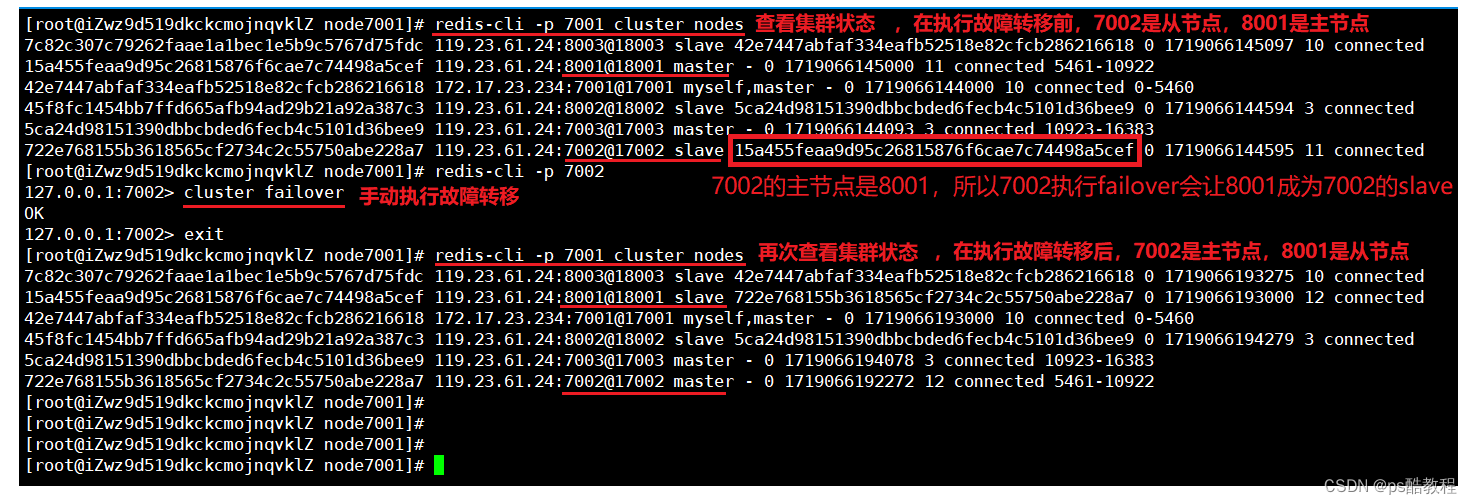
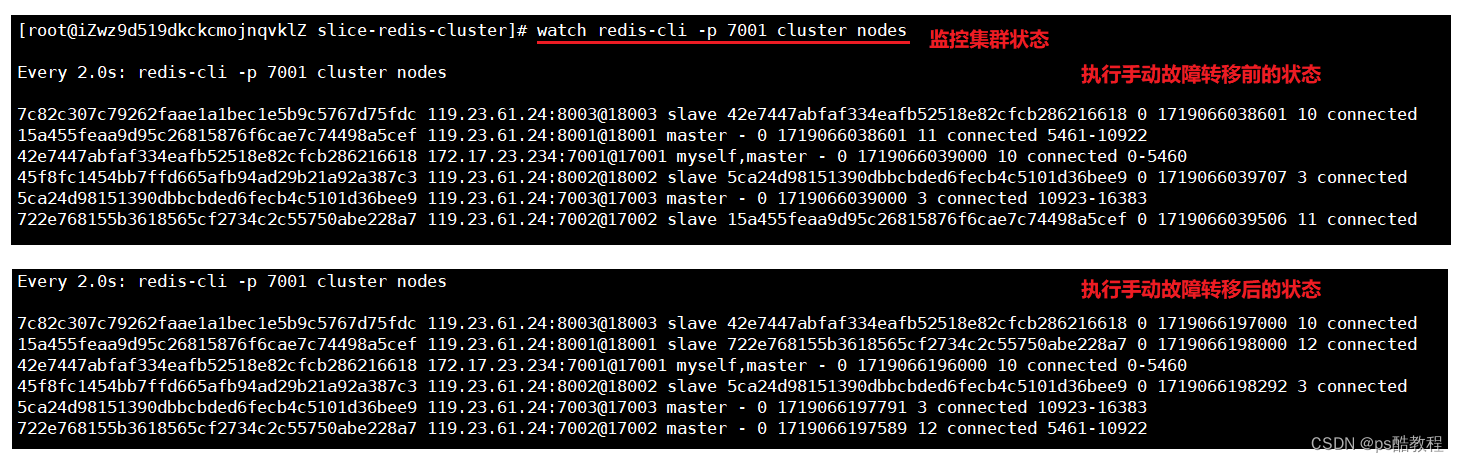
在操作之前查看集群状态,现在的主节点是:7001,7003,8001(可以看出:7002的主节点是xxx5cef,很明显5cef是8001这个节点,所以后续7002执行failover,会替换掉8001成为主节点)
连接上7002,然后执行cluster failover,现在的主节点是:7001,7003,7002。原来的8001成为了从节点。(后续作服务升级时,就可以先让新的节点成为要替换的主节点的从节点,然后让新的节点执行failover即可)
同时,可查看监控集群状态的变化,如下:
RedisTemplate访问分片集群
配置步骤
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
-
引入redis的starter依赖
-
配置分片集群地址
-
配置读写分离
-
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes: # 指定分片集群的每一个节点信息- 119.23.61.24:7001- 119.23.61.24:7002- 119.23.61.24:7003- 119.23.61.24:8001- 119.23.61.24:8002- 119.23.61.24:8003
配置示例
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.9.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>cn.itcast</groupId><artifactId>redis-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>redis-demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>配置文件
logging:level:io.lettuce.core: debugpattern:dateformat: MM-dd HH:mm:ss:SSS
spring:redis:cluster:nodes: # 指定分片集群的每一个节点信息- 119.23.61.24:7001- 119.23.61.24:7002- 119.23.61.24:7003- 119.23.61.24:8001- 119.23.61.24:8002- 119.23.61.24:8003
HelloController
@RestController
public class HelloController {@Autowiredprivate StringRedisTemplate redisTemplate;@GetMapping("/get/{key}")public String hi(@PathVariable String key) {return redisTemplate.opsForValue().get(key);}@GetMapping("/set/{key}/{value}")public String hi(@PathVariable String key, @PathVariable String value) {redisTemplate.opsForValue().set(key, value);return "success";}}
RedisDemoApplication
@SpringBootApplication
public class RedisDemoApplication {public static void main(String[] args) {SpringApplication.run(RedisDemoApplication.class, args);}/* 配置优先从 从节点读取数据(而只能是主节点才能写入) */@Beanpublic LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);}
}测试
此前遇到问题:阿里云搭建redis分片集群,在客户端里获取的ip是阿里云的内网ip,导致连接超时报错,所以修改了所有节点的node.conf文件,将其中的所有内网ip改为公网ip。然后重启整个集群。
测试前,先查看下集群状态信息。
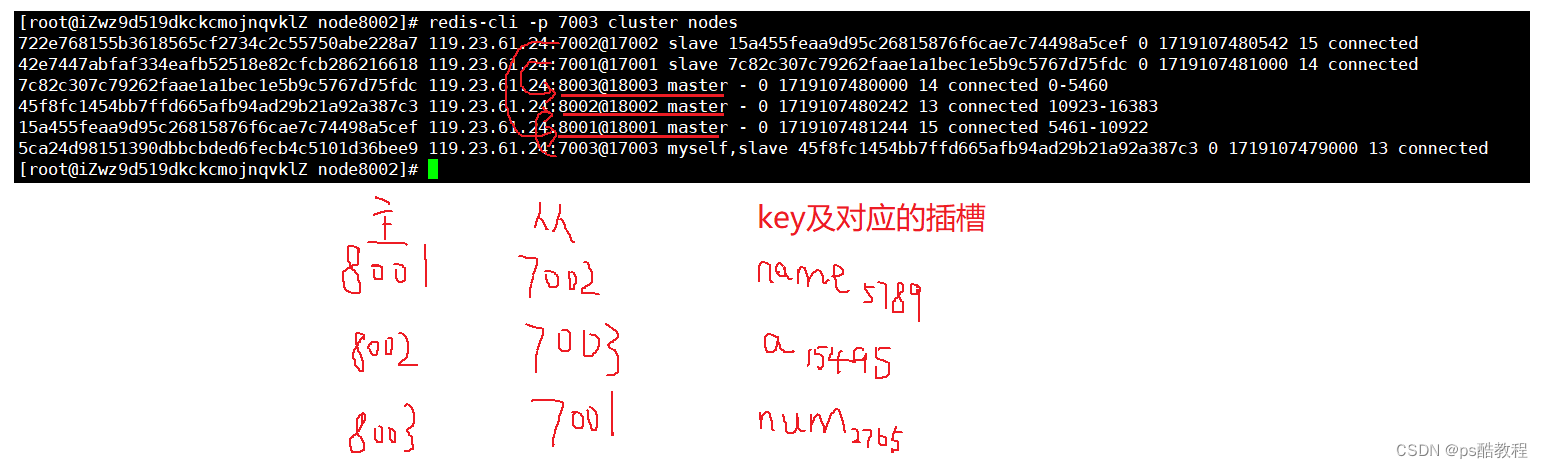
(注意添加-c的命令,来访问集群,否则会报Moved…。下图说明了3个key所属插槽分别在不同的节点上)
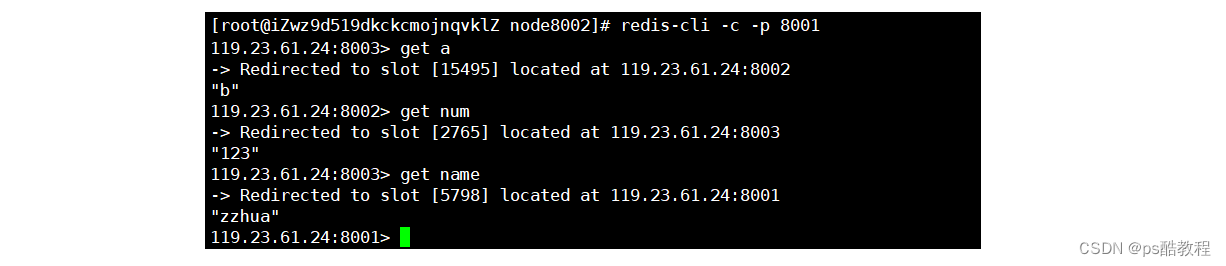
读写分离
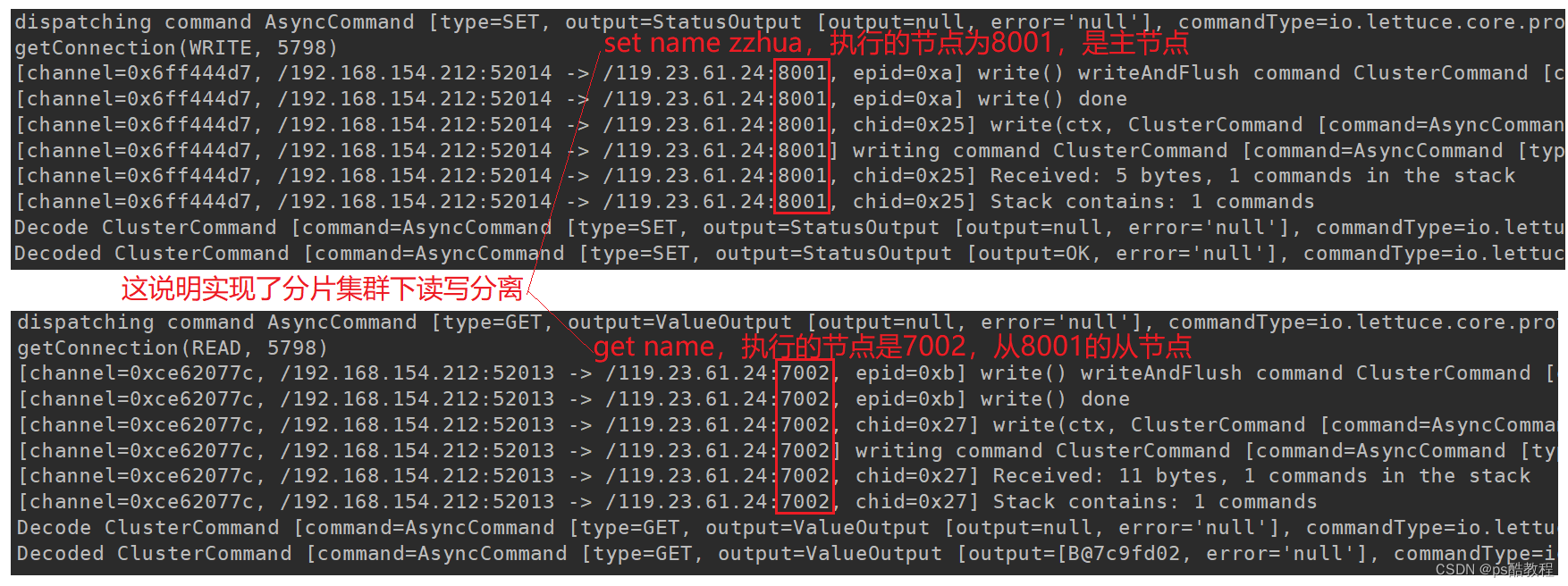
访问:http://localhost:8080/set/name/zzhua写入数据,
再访问:http://localhost:8080/get/name读取数据。
日志输出如下:
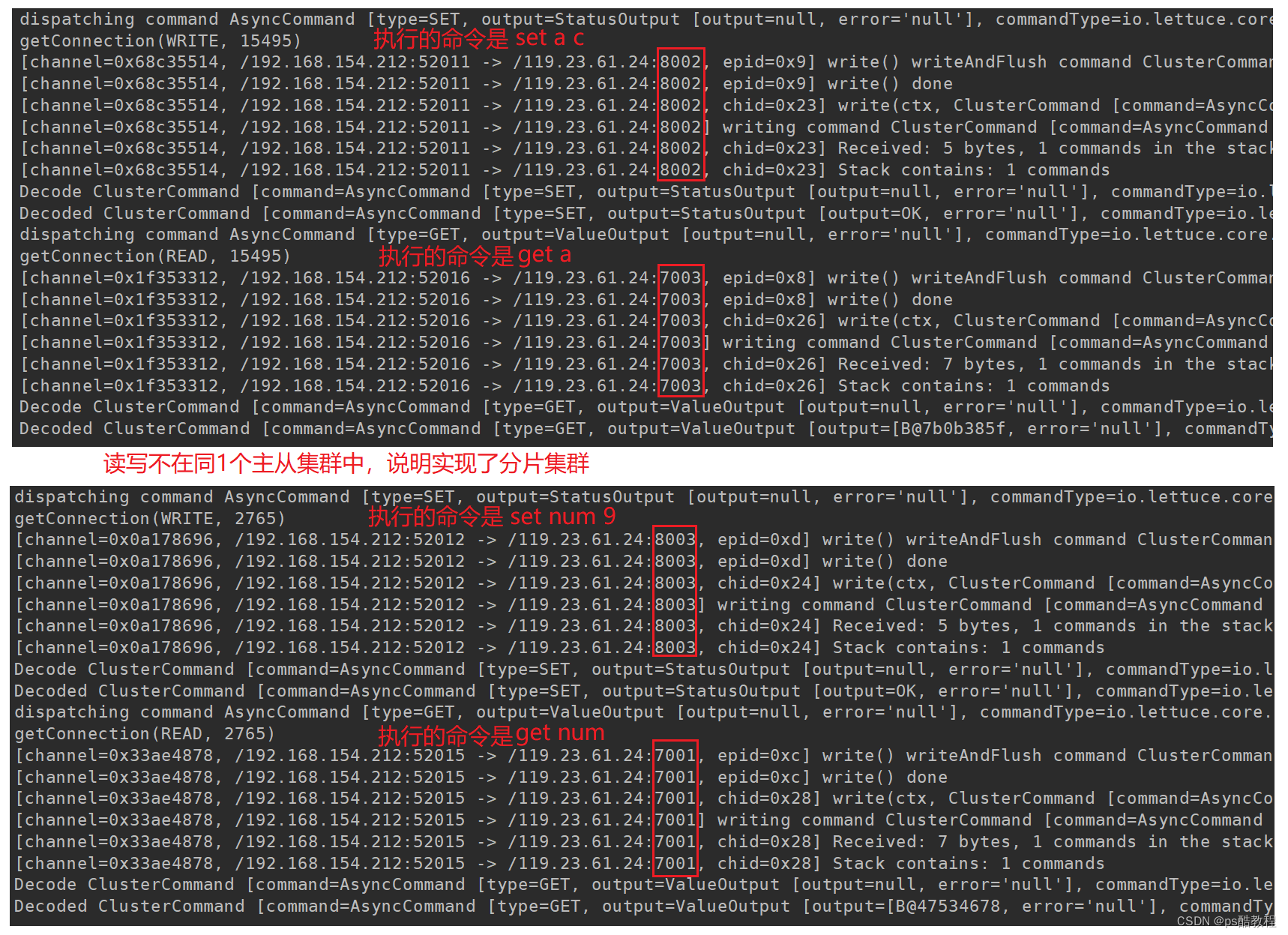
分片测试
访问:http://localhost:8080/set/a/b写入数据,
再访问:http://localhost:8080/get/a读取数据。
日志输出如下:
(不同的key根据其hash值分布在不同的插槽上面,即实现了分片集群)
宕机测试
现在的主从情况是:8001主(7002从)、8002主(7003从)、8003主(7001从),现在让8003主节点挂掉
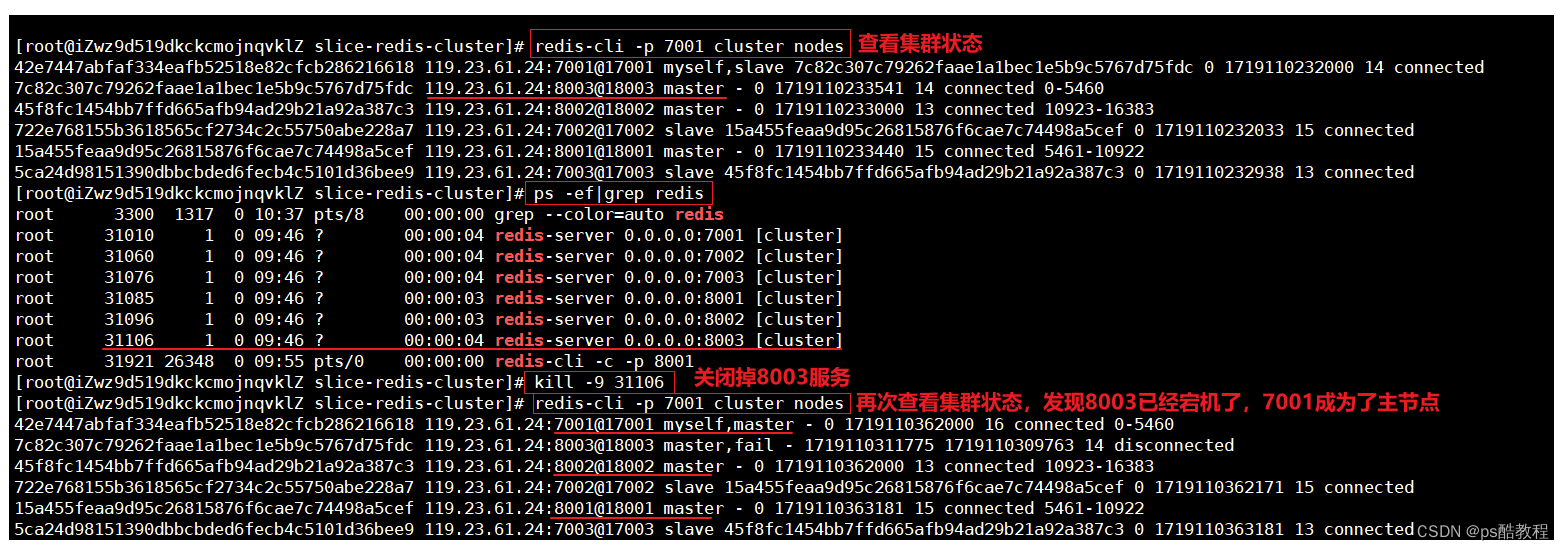
此时访问:http://localhost:8080/get/num 能够获取到数据,
而访问:http://localhost:8080/set/num/9写入数据会报错
所以,这个是不是得使用哨兵才能通知到客户端?因为写入数据,日志输出表明还是访问8003这个服务。
相关文章:
redis持久化主从哨兵分片集群
文章目录 1. 单点Redis的问题数据丢失问题并发能力问题故障恢复问题存储能力问题 2. Redis持久化 -> 数据丢失问题RDB持久化linux单机安装Redis步骤RDB持久化与恢复示例(详细)RDB机制RDB配置示例RDB的fork原理总结 AOF持久化AOF配置示例(详…...

IOS Swift 从入门到精通: 结构体的访问控制、静态属性和惰性
文章目录 初始化器引用当前实例惰性属性静态属性和方法访问控制总结初始化器 初始化器是一种特殊方法,可提供创建结构体的不同方式。所有结构体都默认带有一个初始化器,称为成员初始化器- 它会要求您在创建结构体时为每个属性提供一个值。 User如果我们创建一个具有一个属性…...

SQL题:未完成率较高的50%用户近三个月答卷情况
SQL题:未完成率较高的50%用户近三个月答卷情况 这是一道牛客网上SQL进阶图库中的一道困难题目,个人花了近两个小时才通过所有用例。之所以想记录下来是因为这道题算是一个很考验基本功的题目,也不乏一些SQL中的技巧。下面我们逐步分析&#…...

挑战与机遇的交织
AI与音乐创作:挑战与机遇的交织 引言 近年来,人工智能技术的迅猛发展使得其在各个领域都展现出了巨大的潜力和影响力,音乐创作领域也不例外。最近上线的音乐大模型,无疑是这一趋势的一个重要节点,它极大地降低了素人…...
Java项目:基于SSM框架实现的精品酒销售管理系统分前后台【ssm+B/S架构+源码+数据库+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的精品酒销售管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功…...

[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?
引言 今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。 主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提…...
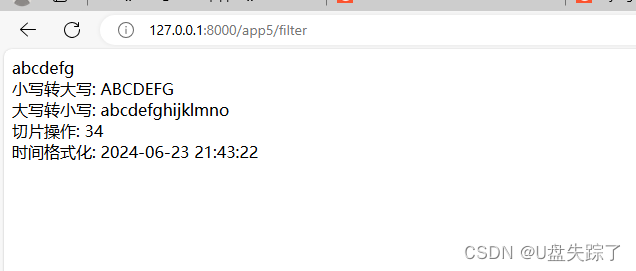
Django 模版过滤器
Django模版过滤器是一个非常有用的功能,它允许我们在模版中处理数据。过滤器看起来像这样:{{ name|lower }},这将把变量name的值转换为小写。 1,创建应用 python manage.py startapp app5 2,注册应用 Test/Test/sett…...
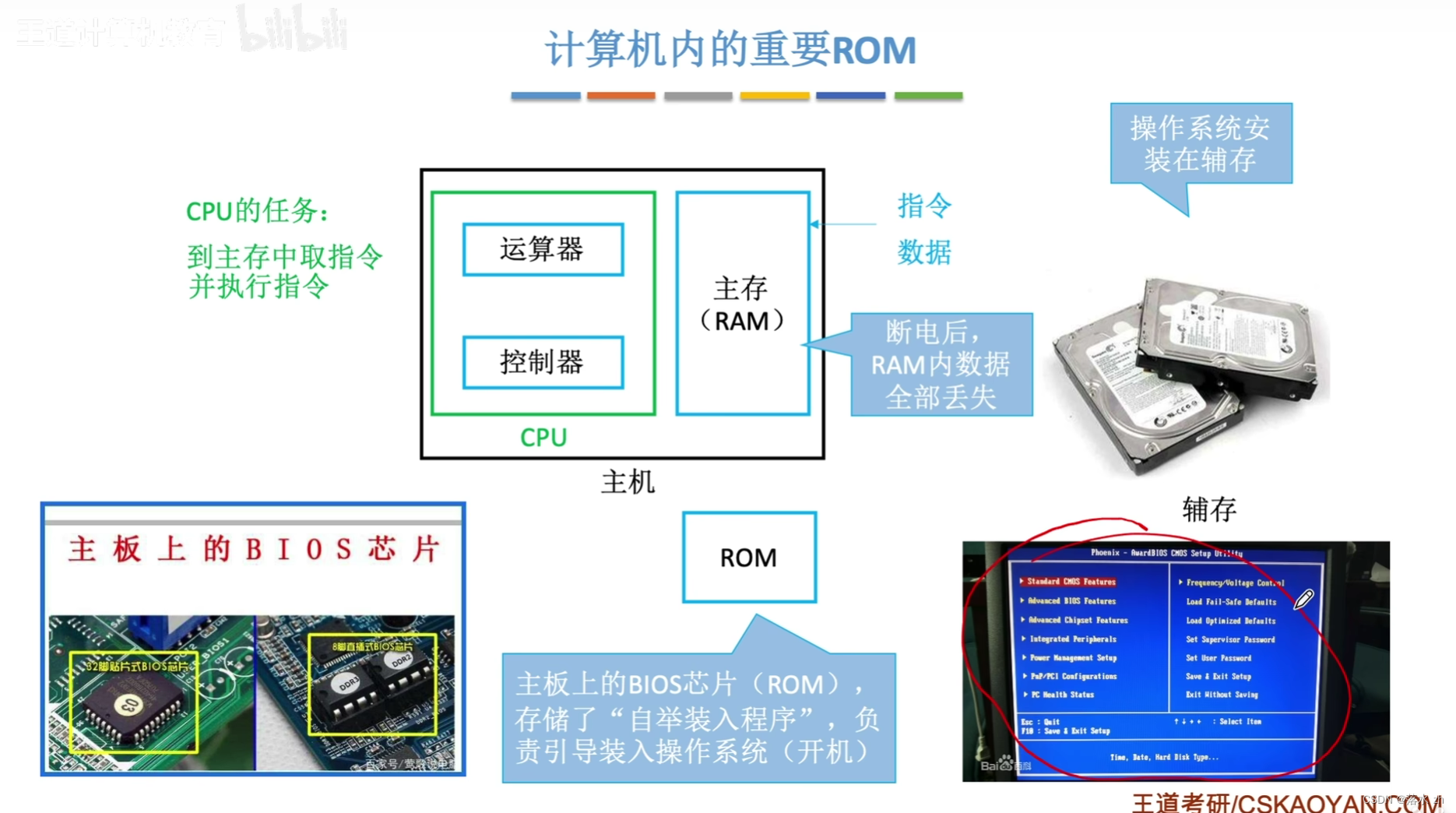
计算机组成原理 —— 存储系统(DRAM和SRAM,ROM)
计算机组成原理 —— 存储系统(DRAM和SRAM) DRAM和SRAMDRAM的刷新DRAM地址复用ROM(Read-Only Memory(只读存储器)) 我们今天来看DRAM和SRAM: DRAM和SRAM DRAM(动态随机存取存储器&…...
第22篇 Intel FPGA Monitor Program的使用<五>
Q:如何用Intel FPGA Monitor Program创建C语言工程并运行呢? A:总体过程与创建汇编语言工程类似,不同的是在指定程序类型时选择C Program。 后续用到DE2-115开发板的硬件如LED、SW和HEX等外设时,还需要将描述定义这些…...

网信办公布第六批深度合成服务算法备案清单,深兰科技大模型入选
6月12日,国家互联网信息办公室发布了第六批深度合成服务算法备案信息,深兰科技硅基知识智能对话多模态大模型算法通过相关审核,成功入选该批次《境内深度合成服务算法备案清单》。同时入选的还有腾讯混元大模型多模态算法、支付宝图像生成算法…...

ES 8.14 向量搜索优化
参考:https://blog.csdn.net/UbuntuTouch/article/details/139502650 检索器(standard、kNN 和 RRF) 检索器(retrievers)是搜索 API 中的一种新抽象概念,用于描述如何检索一组顶级文档。检索器被设计为可以…...

查看 MAC 的 shell 配置文件
在Mac上,shell的配置文件主要取决于您当前使用的shell。从macOS Catalina开始,Mac使用zsh作为默认登录Shell和交互式Shell。以下是关于Mac上zsh shell配置文件的一些详细信息: 查看当前使用的shell: 要查看当前正在使用的shell&am…...
前端下载文件流,axios设置responseType: arraybuffer/blob无效
项目中调用后端下载文件接口,设置responseType: arraybuffer,实际拿到的数据data是字符串 axios({method: post,url: /api/v1/records/recording-file/play,// 如果有需要发送的数据,可以放在这里data: { uuid: 06e7075d-4ce0-476f-88cb-87fb0a1b4844 }…...
代码实践 -卷积神经网络-14模型构造)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-14模型构造
14模型构造 import torch from torch import nn from torch.nn import functional as F#通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的 net1 nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256,10)) """ nn.…...
Django 模版转义
1,模版转义的作用 Django模版系统默认会自动转义所有变量。这意味着,如果你在模版中输出一个变量,它的内容会被转义,以防止跨站脚本攻击(XSS)。例如,如果你的变量包含HTML标签,这些…...
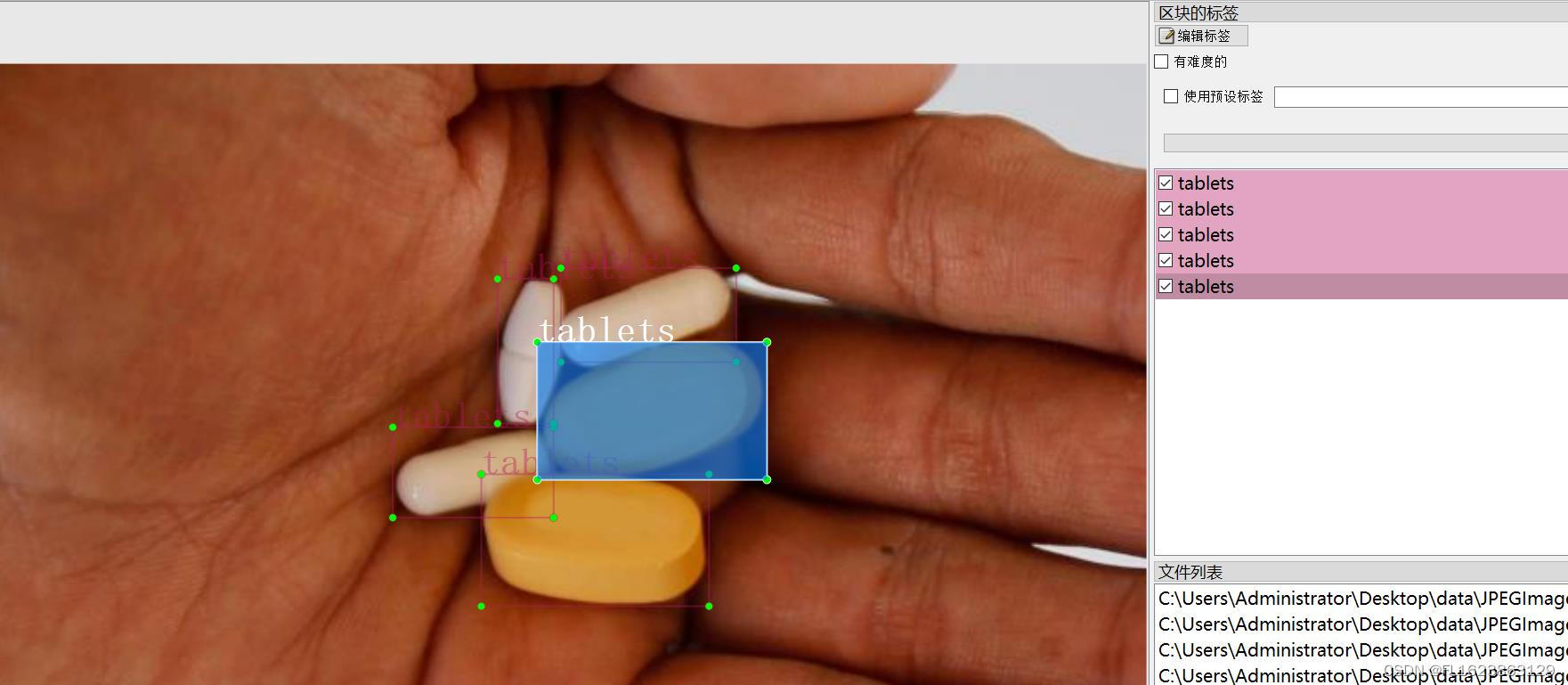
[数据集][目标检测]药片药丸检测数据集VOC+YOLO格式152张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):152 标注数量(xml文件个数):152 标注数量(txt文件个数):152 标注类别…...
)
Android SurfaceFlinger——HWC图层合成器加载(四)
在前面文章中的 Android.bp 文件中,我们可以看到里面加载了图层合成器和图形内存分配器的 HAL 服务,这里篇我们就来详细介绍一下其中的图层合成器——HWC。 一、HWC简介 HWC,全称为 Hardware Composer,是 Android 系统中一个至关重要的组件,位于硬件抽象层(HAL)。它的主…...

OpenCV--图像金字塔
图像金字塔 图像金字塔高斯金字塔拉普拉斯金字塔 图像金字塔 import cv2""" 图像金字塔:同一图像不同分辨率的子图合集 主要用于图像分割 """高斯金字塔 """ 高斯金字塔:通过高斯平滑和亚采样(采样后图像…...

创意产业如何应对AI的挑战。
最近的一个月,音乐领域迎来了一个革命性的变化。一系列音乐大模型轮番上线,它们以惊人的创作能力,将素人生产音乐的门槛降到了最低。这些AI音乐模型的出现,引发了关于AI是否会彻底颠覆音乐圈的讨论。然而,短暂的兴奋过…...

设计模式——工厂方法模式
文章目录 工厂方法模式简介工厂方法模式的组成部分工厂方法模式的结构Factory和Method的含义工厂方法模式的应用场景工厂方法模式的示例1. 文档生成器2. 数据库连接 工厂方法模式简介 工厂方法模式(Factory Method Pattern)是一种创建型设计模式&#x…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

从零构建现代化Web控制面板:安全架构与实时监控实践
1. 项目概述:一个为开发者设计的现代化控制面板最近在GitHub上看到一个挺有意思的项目,叫clawpanel,作者是kweephyo-pmt。光看名字,你可能会联想到“爪子”和“面板”,感觉像是个带点攻击性或工具属性的管理界面。实际…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

基于Docker部署OpenOffice无头服务实现文档自动化处理
1. 项目概述与核心价值最近在折腾文档处理自动化流程,发现很多老项目或者特定场景下,对Office文档的兼容性要求极高,尤其是那些需要处理.doc、.xls、.ppt等老格式的场景。直接用现代办公套件(比如LibreOffice)去处理&a…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

VT.ai:开发者AI工具集实战指南,提升编码效率与调试体验
1. 项目概述:一个面向开发者的AI工具集最近在GitHub上看到一个挺有意思的项目,叫“vinhnx/VT.ai”。乍一看这个标题,可能有点摸不着头脑,但点进去研究一番,你会发现这其实是一个开发者为自己、也为社区打造的一个AI工具…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...