使用Flink CDC实时监控MySQL数据库变更
在现代数据架构中,实时数据处理变得越来越重要。Flink CDC(Change Data Capture)是一种强大的工具,可以帮助我们实时捕获数据库的变更,并进行处理。本文将介绍如何使用Flink CDC从MySQL数据库中读取变更数据,并将其打印到控制台。
环境准备
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.12.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.12.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.12.0</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>1.12.0</version>
</dependency>
<dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.0.0</version>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.23</version>
</dependency>
- 获取Flink执行环境
首先,我们需要获取Flink的执行环境。这是所有Flink作业的起点。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- 启用检查点和设置并行度
为了确保作业的容错性和状态恢复,我们需要启用检查点,并设置作业的并行度。
env.enableCheckpointing(500); // 每500毫秒创建一个检查点
env.setParallelism(1); // 设置作业的并行度为1
- 使用Debezium Source读取MySQL的binlog
接下来,我们使用Debezium Source读取MySQL的binlog。我们需要配置MySQL的连接信息、监控的数据库和表、反序列化器以及启动选项。
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder().serverTimeZone("Asia/Shanghai") // 设置时区为亚洲/上海.hostname("localhost") // MySQL的IP地址.port(3306) // MySQL的端口.username("root") // MySQL的用户名.password("123456") // MySQL的密码.databaseList("my_db") // 监控的数据库.tableList("my_db.user") // 监控的数据库下的表.deserializer(new JsonDebeziumDeserializationSchema()) // 反序列化.startupOptions(StartupOptions.initial()) // 启动选项.build();
这里 JsonDebeziumDeserializationSchema类的代码如下:
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;import java.util.List;/**
* 自定义DeserializationSchema进行反序列化。
*/public class JsonDebeziumDeserializationSchema implements DebeziumDeserializationSchema<String> {@Overridepublic void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {//创建JSON对象用于存储最终数据JSONObject result = new JSONObject();String topic = sourceRecord.topic();String[] fields = topic.split("\\.");String database = fields[1];String tableName = fields[2];Struct value = (Struct)sourceRecord.value();//获取before数据Struct before = value.getStruct("before");JSONObject beforeJson = getJson(before);//获取after数据Struct after = value.getStruct("after");JSONObject afterJson = getJson(after);//获取操作类型Envelope.Operation operation = Envelope.operationFor(sourceRecord);//将字段写入JSON对象result.put("database",database);result.put("tableName",tableName);result.put("type",operation);result.put("before",beforeJson);result.put("after",afterJson);//输出数据collector.collect(result.toJSONString());}/*** 获取字段值并写入result对象* @param before* @return*/private JSONObject getJson(Struct before) {JSONObject jsonObject = new JSONObject();if(before != null){Schema beforeSchema = before.schema();List<Field> beforeFields = beforeSchema.fields();for (Field field : beforeFields) {Object beforeValue = before.get(field);jsonObject.put(field.name(), beforeValue);}}return jsonObject;}@Overridepublic TypeInformation getProducedType() {return BasicTypeInfo.STRING_TYPE_INFO;}
}
- 添加数据源并打印数据
将Debezium源函数添加到Flink环境中,生成一个数据流,并将数据流中的数据打印到控制台。
DataStream<String> dataStreamSource = env.addSource(sourceFunction, TypeInformation.of(String.class));
DataStreamSink<String> print = dataStreamSource.print();
- 启动任务
最后,启动Flink作业,开始处理数据流。
env.execute("Flink-CDC");
6.测试

总结
通过上述步骤,我们可以使用Flink CDC实时监控MySQL数据库的变更,并将变更数据以JSON格式打印出来。这种方法不仅适用于数据监控,还可以用于实时数据处理和分析。
相关文章:
使用Flink CDC实时监控MySQL数据库变更
在现代数据架构中,实时数据处理变得越来越重要。Flink CDC(Change Data Capture)是一种强大的工具,可以帮助我们实时捕获数据库的变更,并进行处理。本文将介绍如何使用Flink CDC从MySQL数据库中读取变更数据࿰…...

学生课程信息管理系统
摘 要 目前,随着科学经济的不断发展,高校规模不断扩大,所招收的学生人数越来越 多;所开设的课程也越来越多。随之而来的是高校需要管理更多的事务。对于日益增 长的学生相关专业的课程也在不断增多,高校对其管理具有一…...
如何看待鸿蒙HarmonyOS?
鸿蒙系统,自2019年8月9日诞生就一直处于舆论风口浪尖上的系统,从最开始的“套壳”OpenHarmony安卓的说法,到去年的不再兼容安卓的NEXT版本的技术预览版发布,对于鸿蒙到底是什么,以及鸿蒙的应用开发的讨论从来没停止过。…...
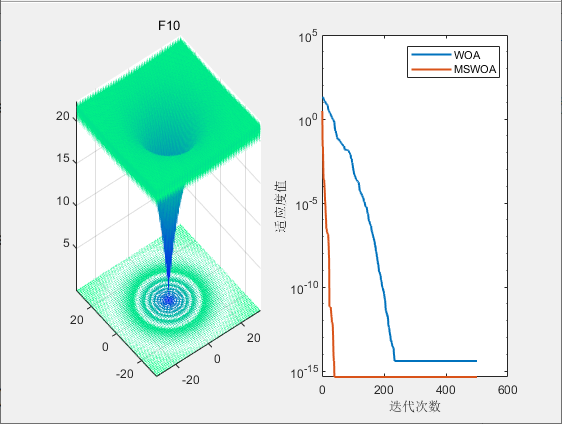
【论文复现|智能算法改进】一种基于多策略改进的鲸鱼算法
目录 1.算法原理2.改进点3.结果展示4.参考文献5.代码获取 1.算法原理 SCI二区|鲸鱼优化算法(WOA)原理及实现【附完整Matlab代码】 2.改进点 混沌反向学习策略 将混沌映射和反向学习策略结合,形成混沌反向学习方法,通过该方 法…...

yarn安装配置及使用教程
Yarn 是一款 JavaScript 的包管理工具,是 Facebook, Google, Exponent 和 Tilde 开发的一款新的 JavaScript 包管理工具,它提供了确定性、依赖关系树扁平化等特性,并且与 npm 完全兼容。以下是 Yarn 的安装及使用教程: Yarn 安装…...

有那么点道理。
...

蔚蓝资源包和数据分析
代码如下 /* * COMPUTER GENERATED -- DO NOT EDIT* */#include <windows.h>static FARPROC __Init_Fun_2__; int __RestartAppIfNecessary__Fun() {return 0; } int Init_Fun() {__Init_Fun_2__();return 1; }static FARPROC __GameServer_BSecure__; static FARPROC _…...
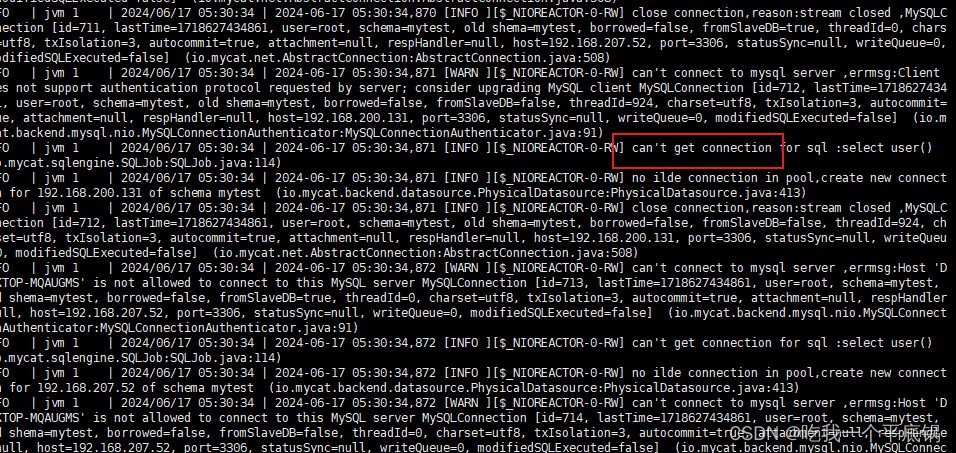
MySQL----利用Mycat配置读写分离
首先确保主从复制是正常的,具体步骤在MySQL----配置主从复制。MySQL----配置主从复制 环境 master(CtenOS7):192.168.200.131 ----ifconfig查看->ens33->inetslave(win10):192.168.207.52 ----ipconfig查看->无线局域网适配器 WLA…...

【科学计算与可视化】2. pandas 基础
1. 安装 Pandas 首先,确保你已经安装了 Pandas。你可以使用以下命令安装:pip install pandas 2. 导入 Pandas 在开始使用 Pandas 之前,你需要先导入它:import pandas as pd 3. 创建数据结构 Pandas 主要有两种数据结构&#…...

医学记录 --- 腋下异味
逻辑图地址 症状 病因 汗液分泌旺盛:由于天气炎热、活动出汗、肥胖等因素导致汗液分泌旺盛,可引起腋下有异味表现。在这种情况下,建议保持身体清洁,特别是在炎热和潮湿的环境下。可以使用抗菌洗液、喷雾或霜剂来帮助减少细菌滋…...
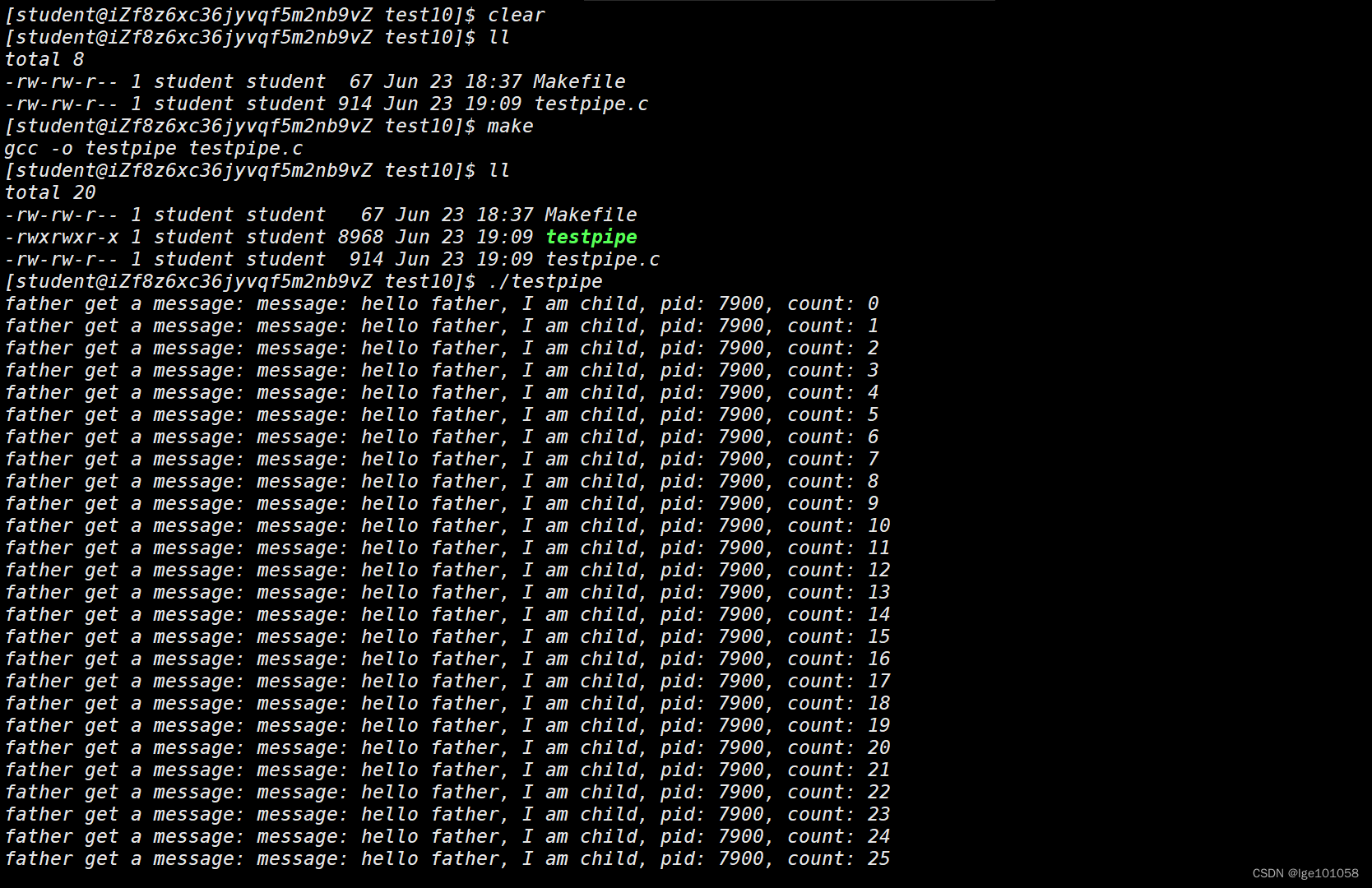
【Linux】进程间通信_1
文章目录 七、进程间通信1. 进程间通信分类管道 未完待续 七、进程间通信 进程间由于 进程具有独立性 ,所以不可以直接进行数据传递。但是我们通常需要多个进程协同,共同完成一件事,所以我们需要进程间通信的手段。进程间通信的本质就是先让…...
 5.6 在kernel 中实现系统复位和系统关机驱动)
Linux Kernel入门到精通系列讲解(RV-Kernel 篇) 5.6 在kernel 中实现系统复位和系统关机驱动
1. 概述 上一章节Qemu篇我们已经实现了我们SOC的power reset和 power down 寄存器,本章节我们就在Linux driver中去实现它。 2. Linux kernel 访问其他节点 Linux kernel中有一种机制,就是在driver中访问其它设备树节点的信息,了解设备树的应该都知道,每个设备节点都有一…...

如何在Java中进行单元测试?
如何在Java中进行单元测试? 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Java中进行单元测试,这是一项确保代码质…...

代码随想录训练营Day32
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、买卖股票的最佳时机2二、跳跃游戏三、跳跃游戏2四、K次取反后最大化的数组和 前言 今天是跟着代码随想录刷题的第32天,主要是学了买卖股票的最…...

代码随想录训练营Day31
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、分发饼干二、摆动序列三、最大子树组合 前言 今天是跟着代码随想录刷题的第31天,主要学习了分发饼干,摆动序列和最大子树组合这三个…...

Docker 多阶段构建
多阶段构建 目录 尝试创建 Dockerfile构建容器镜像运行 Spring Boot 应用程序使用多阶段构建额外资源 在传统构建中,所有构建指令都在一个构建容器中顺序执行:下载依赖项、编译代码、打包应用程序。所有这些层最终都在你的最终镜像中。这种方法虽然可行…...
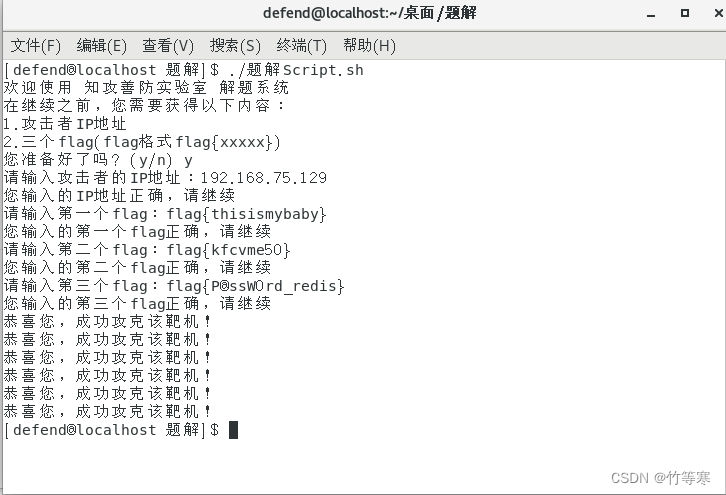
Linux应急响应——知攻善防应急靶场-Linux(1)
文章目录 查看history历史指令查看开机自启动项异常连接和端口异常进程定时任务异常服务日志分析账户排查总结 靶场出处是知攻善防 Linux应急响应靶机 1 前景需要: 小王急匆匆地找到小张,小王说"李哥,我dev服务器被黑了",快救救我&…...

基于CDMA的多用户水下无线光通信(1)——背景介绍
研究生期间做多用户水下无线光通信(Underwater Optical Wireless Communication,UOWC),写几篇博客分享一下学的内容。导师给了大方向,让我用直接序列码分多址(Direct Sequence Code Division Multiple Acce…...

基于springboot websocket和okhttp实现消息中转
1、业务介绍 消息源服务的消息不能直接推给用户侧,用户与中间服务建立websocket连接,中间服务再与源服务建立websocket连接,源服务的消息推给中间服务,中间服务再将消息推送给用户。流程如下图: 此例中我们定义中间服…...

一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单
一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 你是否曾为管理Steam游戏文件而烦恼?想备份心爱的游戏却不知从…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

智能体开发实战:从框架选型到部署优化的完整指南
1. 项目概述:一个为智能体开发者准备的“军火库”如果你正在或打算踏入智能体(Agent)开发这个领域,那么你很可能已经体会过那种“万事开头难”的迷茫。从选择哪个框架开始,到如何设计一个有效的智能体工作流࿰…...

嘎嘎降AI和PaperRR深度对比:2026年学术期刊SCI论文降AI性能完整评测报告
嘎嘎降AI和PaperRR深度对比:2026年学术期刊SCI论文降AI性能完整评测报告 总有人问我选哪个降AI工具,这篇文章把主流的几款对比清楚。 综合推荐嘎嘎降AI(www.aigcleaner.com),4.8元,99.26%达标率。不同需求…...
)
告别小白恐惧!用PyCharm+PyQt6从零打造你的第一个桌面应用(附打包exe避坑指南)
告别小白恐惧!用PyCharmPyQt6从零打造你的第一个桌面应用(附打包exe避坑指南) 你是否曾遇到过这样的场景:精心编写的Python脚本需要交给同事使用,但对方却被命令行界面吓退?或是作为数据分析师,…...

基于ADT7410与ESP8266的物联网温度监测系统实战指南
1. 项目概述:从传感器到云端的温度监测闭环在嵌入式开发和物联网项目中,温度监测是一个经典且高频的需求场景。无论是实验室环境监控、智能家居的恒温控制,还是工业设备的状态感知,一个稳定、精确且能远程访问的温度数据流都是基础…...

书成紫微动,律定凤凰驯:一破一立,铁哥的两部作品如何构成完整的文化闭环
书成紫微动,律定凤凰驯。 —— 唐《开元占经》卷一〇三 引言:千年谶语里的文明算法 无破则旧局不死,无立则新局不生。 一句千古古句,藏着文明迭代最严谨的底层逻辑: 先破后立,破立相生,方能形成…...

YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件
YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件 【免费下载链接】YouMightNotNeedJS 项目地址: https://gitcode.com/gh_mirrors/yo/YouMightNotNeedJS 在现代网页开发中,实现跨设备兼容的响应式界面是提升用户体验的关键。YouMig…...

5分钟搞定Windows和Office永久激活:智能KMS工具完全指南
5分钟搞定Windows和Office永久激活:智能KMS工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成…...