异步爬虫:aiohttp 异步请求库使用:
使用requests 请求库虽然可以完成爬虫业务,但是对于异步任务来说,它是做不到的, 这时候我们需要借助 aiohttp 异步请求库来完成异步爬虫的编写:
话不多说,直接看示例:
注意:楼主使用的python版本是最新的,3.12的py版本, 另外pycharm使用的也是最新版的 2024版本的。 请务必与我保持一致, 否则会报很多莫名其妙的异常信息。
下载:
使用aiohttp 异步请求库请先pip 下载:
pip install aiohttp基本实例:
import asyncio
import aiohttpasync def get(session, url):async with session.get(url) as response:return await response.text(), response.statusasync def test():url = "http://www.baidu.com"async with aiohttp.ClientSession() as session:html_text, status = await get(session, url)print(html_text)print(status)if __name__ == '__main__':asyncio.run(test())以上代码示例首先我们需要导入两个库,分别是aiohttp, asyncio, 因为要实现异步任务,而启动异步需要使用asyncio, 关于异步的知识点请自行查阅补充。
其次使用 async 关键字定义了一个 get 异步函数, 它接受了 session, url 两个参数, 而session则为aiohttp 中客户端ClientSession() 对象, 因为aiohttp 它提供了两套业务功能, 分别是服务端和客服端, 服务端主要就是实现处理客户端发送请求的异步业务, 而客户端,就是发送请求的,我们学爬虫,就需要学aiohttp 提供的客户端操作功能。 言归正传, 在这个get 方法中, 使用 async 关键字来声明一个异步上下文管理器<with ... as ...>, 然后返回所得到的响应,
而在test 异步函数中, 创建了一个ClientSession 对象, 然后调用get 函数,将session对象和url传递进去, 最后调用asyncio.run 启动协程任务。
请求:
GET:
对于一些有关于Get 请求携带参数的情况,我们可以使用 params 形参来完成
async def test():params = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/get"async with aiohttp.ClientSession() as session:# 使用params 形参传递get 请求数据async with session.get(url=url, params=params) as response:print(await response.text())if __name__ == '__main__':asyncio.run(test())aiohttp 也提供了 POST, PUT, DELETE, HEAD, PATCH, OPTIONS 等请求方式。
POST:
而对于post 请求表单提交的数据, 例如Content-Type 为: application/X-www-form-urlencoded 的数据, 我们可以使用 data 形参来完成, 楼主看了一下源码,如果post 传递的数据为 json, 楼主斗胆猜一下,应该为json 形参,我们可以看一下源码:
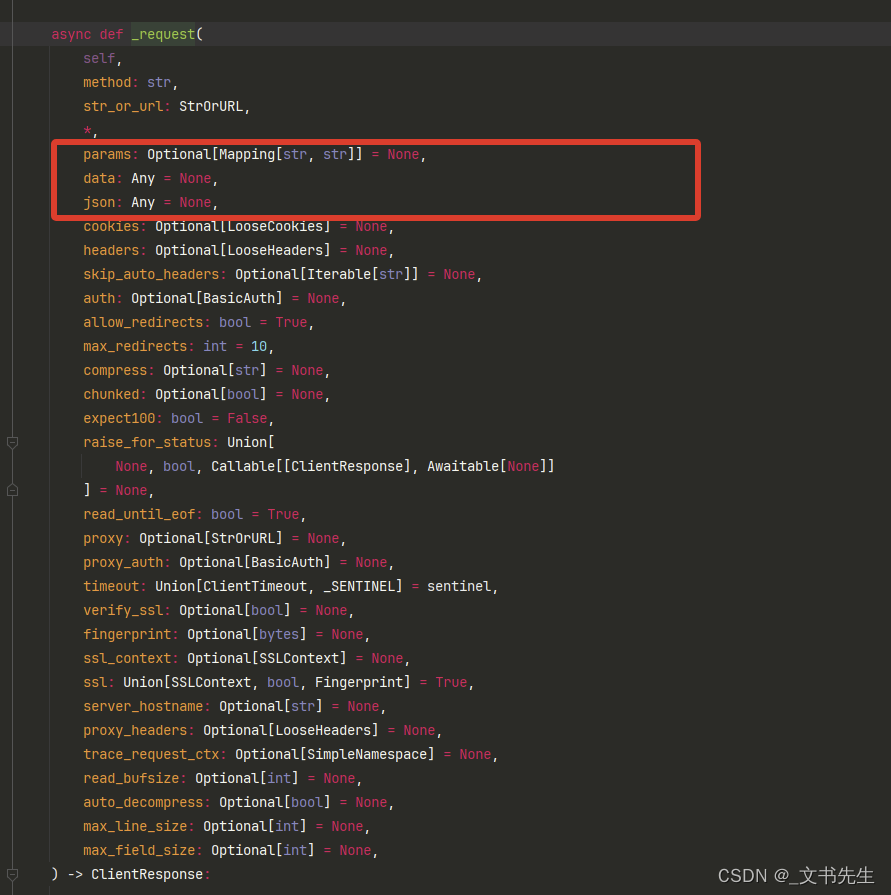
由此可见,它的使用方式几乎和 requests 同步请求库一模一样
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"async with aiohttp.ClientSession() as session:# 使用 data 形参 传递 表单提交的数据async with session.post(url=url, data=data) as response:print(await response.text())if __name__ == '__main__':asyncio.run(test())响应:
对于响应结果,我们可以调用一下方法来获取其中的:状态码,响应头,响应体,响应体二进制内容,响应体JSON数据。
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"async with aiohttp.ClientSession() as session:async with session.post(url, data=data) as response:print(response.status) # 响应状态码print(response.headers) # 响应头print(await response.text()) # 获取响应体print(await response.read()) # 获取二进制数据print(await response.json()) # 获取相响应的JSON数据if __name__ == '__main__':asyncio.run(test())超时设置:
我们可以借助aiohttp 提供的 ClientTimeout 对象来实现超时, 如果超时还未请求到数据,则抛异常
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"timeout = aiohttp.ClientTimeout(total=1) # 设置超时时间,单位为 秒async with aiohttp.ClientSession(timeout=timeout) as session:async with session.post(url, data=data) as response:passif __name__ == '__main__':asyncio.run(test())ClientTimeout 对象同样还提供了其它参数, 例如:connect, socket_connect 等等, 详细参考官方文档:
https://docs.aiohttp.org.en.stable/client_quickstart.html#timeouts
并发限制:
由于异步爬虫拥有非常非常高的并发量, 如几万,几十万,甚至上百万都有可能, 但是如此高的并发量,目标服务器很可能无法再短时间内响应,而且有瞬间将目标服务器爬挂掉的危险, 所以,我们需要控制一下爬取的并发量。
我们可以借助asyncio 的 Semaphore 来控制并发量:
# 最高并发 5 个
CONCURRENCY = 5url = "http://www.baidu.com"# 创建信号量对象 并将最大并发量常量传递进来
semaphores = asyncio.Semaphore(CONCURRENCY)session = Noneasync def test():# 使用信号量对象创建异步上下文即可控制最高并发量async with semaphores:print("爬取ing: ", url)async with session.get(url) as response:await asyncio.sleep(1)return await response.text()async def main():global sessionsession = aiohttp.ClientSession()test_tasks = [test() for i in range(1000)]await asyncio.gather(*test_tasks)if __name__ == '__main__':asyncio.run(main())完了.... aiohttp 官方网站: https://docs.aiohttp.org/
相关文章:
异步爬虫:aiohttp 异步请求库使用:
使用requests 请求库虽然可以完成爬虫业务,但是对于异步任务来说,它是做不到的, 这时候我们需要借助 aiohttp 异步请求库来完成异步爬虫的编写: 话不多说,直接看示例: 注意:楼主使用的python版…...

代码随想录算法训练营第四十七天|LeetCode123 买卖股票的最佳时机Ⅲ
题1: 指路:123. 买卖股票的最佳时机 III - 力扣(LeetCode) 思路与代码: 买卖股票专题中三者不同的是Ⅰ为只买卖一次,Ⅱ可多次买卖,Ⅲ最多可买卖两次。那么我们将买买卖行为分为五个状态部分(…...
将知乎专栏文章转换为 Markdown 文件保存到本地
一、参考内容 参考知乎文章代码 | 将知乎专栏文章转换为 Markdown 文件保存到本地,利用代码为GitHub:https://github.com/chenluda/zhihu-download。 二、步骤 1.首先安装包flask、flask-cors、markdownify 2. 运行app.py 3.在浏览器中打开链接&…...
【notes2】并发,IO,内存
文章目录 1.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象2.并发:cpu,线程2.1 可见性:volatile2.2 原子性(读写原子):AtomicInteger/synchronized…...

Python题目
实例 3.1 兔子繁殖问题(斐波那契数列) 兔子从出生后的第三个月开始,每月都会生一对兔子,小兔子成长到第三个月后也会生一对独自。初始有一对兔子,假如兔子都不死,那么计算并输出1-n个月兔子的数量 n int…...

Hive怎么调整优化Tez引擎的查询?在Tez上优化Hive查询的指南
文章目录 在Tez上优化Hive查询的指南调优指南理解Tez中的并行化理解mapper数量理解reducer数量 并发案例1:未指定队列名称案例2:指定队列名称并发的指南/建议 容器复用和预热容器容器复用预热容器 一般Tez调优参数 在Tez上优化Hive查询的指南 在Tez上优…...

关于小程序内嵌H5页面交互的问题?
有木有遇到?有木有遇到。 小程序内嵌了H5,然后H5某个按钮,需要打开小程序某个页面进行信息完善或登记,登记后要返回H5页面,而H5页面要动态显示刚才在小程序页面登记的信息。 操作流程是这样: 方案1&#…...

Linux下手动查杀木马与Rootkit的实战指南
模拟木马程序的自动运行 黑客可以通过多种方式让木马程序自动运行,包括: 计划任务 (crontab):通过设置定时任务来周期性地执行木马脚本。开机启动:在系统的启动脚本中添加木马程序,确保系统启动时木马也随之运行。替…...
电商爬虫API的定制开发:满足个性化需求的解决方案
一、引言 随着电子商务的蓬勃发展,电商数据成为了企业决策的重要依据。然而,电商数据的获取并非易事,特别是对于拥有个性化需求的企业来说,更是面临诸多挑战。为了满足这些个性化需求,电商爬虫API的定制开发成为了解决…...

nuc马原复习资料
哲学:世界观的理论形态,或者说是系统化、理论化的世界观;世界观和方法论的统一。马克思主义哲学:辩证唯物主义和历史唯物主义,关于自然。社会和思维发展的普遍规律的学说,无产阶级世界观的理论体系。世界观…...

Node.js是什么(基础篇)
前言 Node.js是一个基于Chrome V8 JavaScript引擎的开源、跨平台JavaScript运行时环境,主要用于开发服务器端应用程序。它的特点是非阻塞I/O模型,使其在处理高并发请求时表现出色。 一、Node JS到底是什么 1、Node JS是什么 Node.js不是一种独立的编程…...

淘客返利平台的微服务架构实现
淘客返利平台的微服务架构实现 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨淘客返利平台的微服务架构设计与实现,旨在提高系统的灵…...

【database1】mysql:DDL/DML/DQL,外键约束/多表/子查询,事务/连接池
文章目录 1.mysql安装:存储:集合(内存:临时),IO流(硬盘:持久化)1.1 服务端:双击mysql-installer-community-5.6.22.0.msi1.2 客户端:命令行输入my…...

模拟木马程序自动运行:Linux下的隐蔽攻击技术
模拟木马程序自动运行:Linux下的隐蔽攻击技术 在网络安全领域,木马程序是一种常见的恶意软件,它能够悄无声息地在受害者的系统中建立后门,为攻击者提供远程访问权限。本文将探讨攻击者如何在Linux系统中模拟木马程序的自动运行&a…...

vuex的配置主要内容
1、state 作用:负责存储数据; 2、getters 作用:state计算属性(有缓存); 3、mutaions 作用:负责同步更新state数据 mutaions是唯一可以修改state数据的方式; 4、actions 作用:负责异步操作&a…...
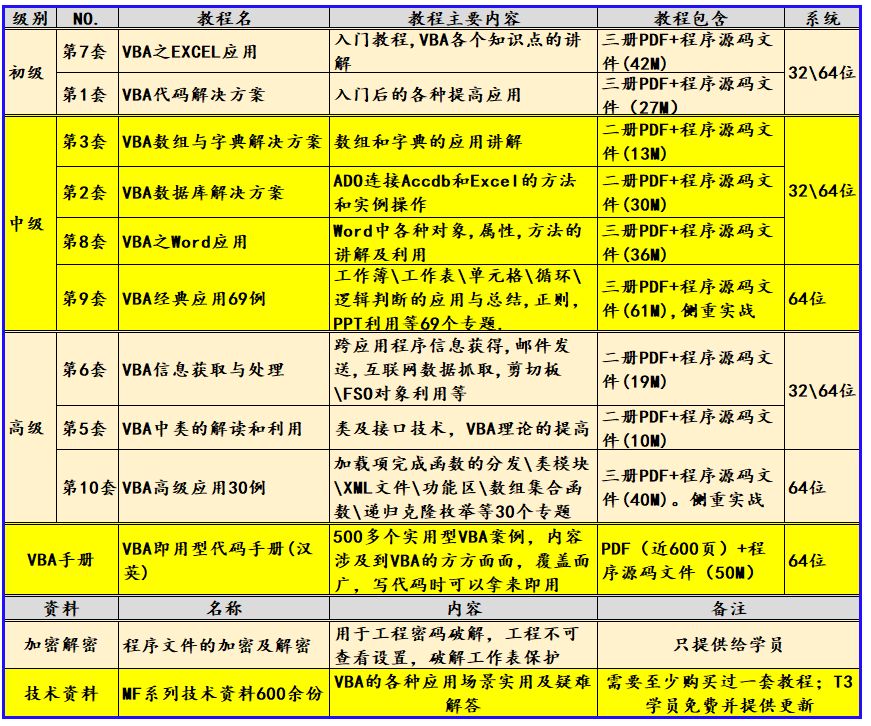
VBA技术资料MF164:列出文件夹中的所有文件和创建日期
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...
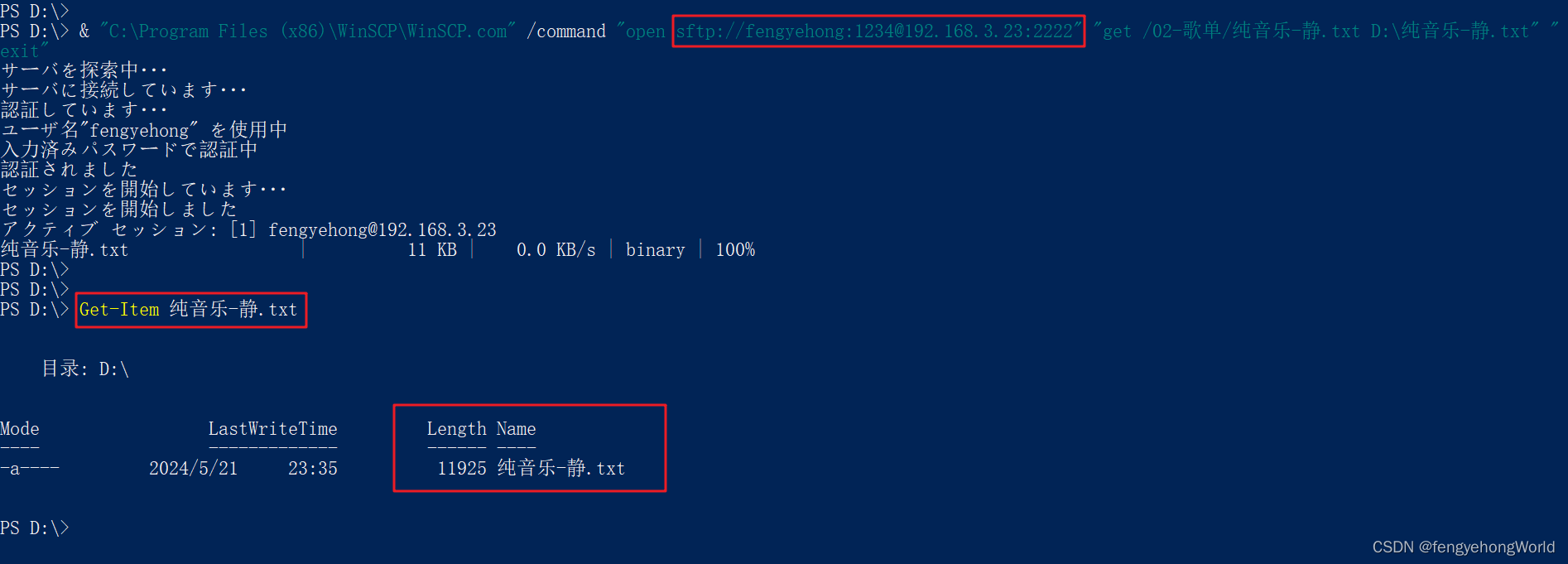
linux 简单使用 sftp 和 lftp命令
目录 一. 环境准备二. sftp命令连接到SFTP服务器三. lftp命令3.1 连接FTP和SFTP服务器3.2 将文件从sftp服务器下载到本地指定目录 四. 通过WinSCP命令行从SFTP服务器获取文件到Windows 一. 环境准备 ⏹在安卓手机上下载个MiXplorer,用作SFTP和FTP服务器 官网: htt…...

2.超声波测距模块
1.简介 2.超声波的时序图 3.基于51单片机实现的代码 #include "reg52.h" #include "intrins.h" sbit led1P3^7;//小于10,led1亮,led2灭 sbit led2P3^6;//否则,led1灭,led2亮 sbit trigP1^5; sbit echo…...

C语言之常用标准库介绍
文章目录 1 标准库1.1 诊断assert.h1.2 字符类别测试ctype.h1.3 错误处理errno.h1.4 整型常量limits.h1.5 地域环境locale.h1.6 数学函数math.h1.7 非局部跳转setjmp.h1.8 可变参数表stdarg.h1.9 公共定义stddef.h1.10 输入输出stdio.h1.11 实用函数stdlib.h1.12 日期与时间函数…...

Spring响应式编程之Reactor核心接口
响应式流的核心接口 核心接口包括:Publisher<T>、Subscriber<T>、Subscription 和 Processo<T,R> (1)Publisher<T> Publisher接口代表数据流的生产者,根据收到的请求向Subscriber发布数据。接口定义如…...

CircuitPython硬件交互实战:引脚命名、模块管理与内存优化
1. 项目概述:CircuitPython硬件交互的基石 如果你刚开始接触CircuitPython,或者从Arduino转过来,可能会对如何控制板子上的某个引脚感到困惑。板子上明明印着“A0”、“D13”,但在代码里到底该怎么写? board.A0 和 …...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...

基于CircuitPython与MagTag的电子墨水屏俳句显示器项目实践
1. 项目概述与核心价值如果你对嵌入式开发感兴趣,但又觉得传统的C/C开发环境配置繁琐、学习曲线陡峭,那么CircuitPython绝对是一个值得尝试的入口。它本质上是一个运行在微控制器上的Python 3解释器,由Adafruit主导开发,目标就是让…...

别再只用高斯噪声了!手把手教你为DDPG算法注入‘惯性’:Ornstein-Uhlenbeck噪声的Python实现与调参实战
突破DDPG探索瓶颈:Ornstein-Uhlenbeck噪声的工程实践指南 在机器人控制或自动驾驶仿真这类连续动作空间的任务中,DDPG算法常因探索效率低下导致训练停滞。当智能体在MuJoCo环境中反复"原地踏步"时,问题往往不在于算法本身…...

ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台
ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...

SAP F110自动付款:从零到精通的配置全景图
1. SAP F110自动付款入门指南 第一次接触SAP F110自动付款功能时,我也被那一堆配置项搞得晕头转向。记得当时为了搞清楚银行确定逻辑,整整花了两天时间反复测试。现在回想起来,如果有个系统性的指导手册,至少能节省一半时间。F110…...
)
别再死记公式了!用Python的NumPy库5分钟搞定极坐标与笛卡尔坐标转换(附象限处理代码)
极坐标与笛卡尔坐标转换:用NumPy实现高效科学计算 在数据分析和科学计算领域,坐标转换是一项基础但至关重要的操作。无论是处理雷达扫描数据、生成复杂数学图形,还是进行计算机视觉中的图像变换,开发者经常需要在极坐标和笛卡尔坐…...
用C++实现信奥题 P8855 [POI 2002 R1] 商务旅行)
打卡信奥刷题(3271)用C++实现信奥题 P8855 [POI 2002 R1] 商务旅行
P8855 [POI 2002 R1] 商务旅行 题目描述 某地首都的商人要经常到其他城镇去做生意,他们会按自己的路线去走。 有 NNN 个城镇,首都编号为 111。商人从首都出发,其他各城镇之间都有道路连接。 任意两个城镇之间如果有直连道路,在他们…...

告别命令行!用Python脚本批量管理Docker容器和镜像的实战技巧
告别命令行!用Python脚本批量管理Docker容器和镜像的实战技巧 在DevOps和云原生技术快速发展的今天,Docker已经成为现代应用部署的标准工具。然而,随着容器数量的增加和部署频率的提高,手动通过命令行管理Docker容器和镜像变得越来…...