Pytorch深度解析:Transformer嵌入层源码逐行解读
前言
本部分博客需要先阅读博客:
《Transformer实现以及Pytorch源码解读(一)-数据输入篇》
作为知识储备。
Embedding使用方式
如下面的代码中所示,embedding一般是先实例化nn.Embedding(vocab_size, embedding_dim)。实例化的过程中输入两个参数:vocab_size和embedding_dim。其中的vocab_size是指输入的数据集合中总共涉及多少个去重后的单词;embedding_dim是指,每个单词你希望用多少维度的向量表示。随后,实例化的embedding在forward中被调用self.embeddings(inputs)。
class Transformer(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_class,dim_feedforward=512, num_head=2, num_layers=2, dropout=0.1, max_len=512, activation: str = "relu"):super(Transformer, self).__init__()# 词嵌入层self.embedding_dim = embedding_dimself.embeddings = nn.Embedding(vocab_size, embedding_dim)self.position_embedding = PositionalEncoding(embedding_dim, dropout, max_len)# 编码层:使用Transformerencoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head, dim_feedforward, dropout, activation)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)# 输出层self.output = nn.Linear(hidden_dim, num_class)def forward(self, inputs, lengths):inputs = torch.transpose(inputs, 0, 1)hidden_states = self.embeddings(inputs)hidden_states = self.position_embedding(hidden_states)attention_mask = length_to_mask(lengths) == Falsehidden_states = self.transformer(hidden_states, src_key_padding_mask=attention_mask).transpose(0, 1)logits = self.output(hidden_states)log_probs = F.log_softmax(logits, dim=-1)return log_probs数据被怎样变换了?
如下图所示,第一个tensor表示input,该input表示一个句子( sentence),只是该句子中的单词用整数进行了代替,相同的整数表示相同的单词。而每个1在embedding之后,变成了相同过的向量。
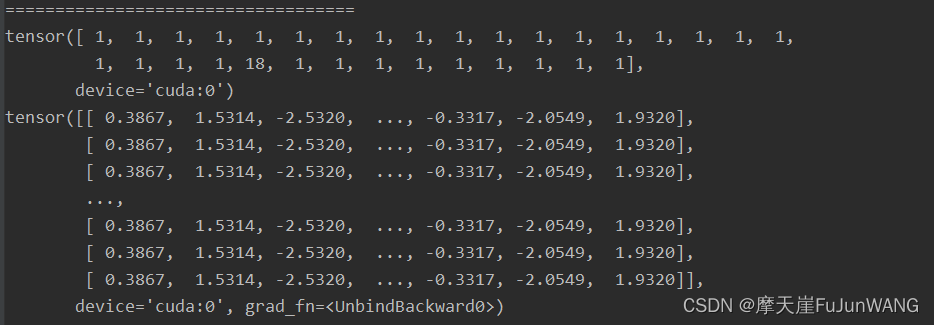
我们将以上的代码重新的运行一遍,发现表示1的向量改变了,这说明embedding 的过程不是确定的,而是随机的。

数据是怎样被变化的?
Embedding类在调用过程中主要涉及到以下几个核心方法:_
init
,rest_parameters,forward:
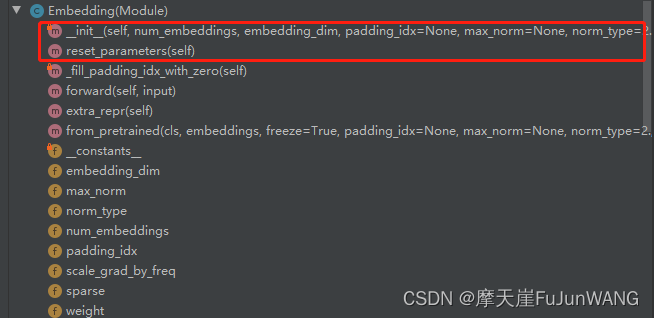
Embedding类的初始化过程如下所示。当_weight没有的情况下调用Parameter初始化一个空的向量,该向量的维度与输入数据中的去重单词个数(num_bembeddings)一样。然后调用reset_parameters方法。
def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None,max_norm: Optional[float] = None, norm_type: float = 2., scale_grad_by_freq: bool = False,sparse: bool = False, _weight: Optional[Tensor] = None,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super(Embedding, self).__init__()self.num_embeddings = num_embeddingsself.embedding_dim = embedding_dimif padding_idx is not None:if padding_idx > 0:assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'elif padding_idx < 0:assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'padding_idx = self.num_embeddings + padding_idxself.padding_idx = padding_idxself.max_norm = max_normself.norm_type = norm_typeself.scale_grad_by_freq = scale_grad_by_freqif _weight is None:self.weight = Parameter(torch.empty((num_embeddings, embedding_dim), **factory_kwargs))# print("===========================================1")# print(self.weight)#将self.weight进行nornal归一化self.reset_parameters()print("===========================================2")print(self.weight)else:assert list(_weight.shape) == [num_embeddings, embedding_dim], \'Shape of weight does not match num_embeddings and embedding_dim'self.weight = Parameter(_weight)self.sparse = sparsereset_parameters的实现如下所示,主要是调用了init.norma_方法。
def reset_parameters(self) -> None:init.normal_(self.weight)self._fill_padding_idx_with_zero()init.normal_又调用了torch.nn.init中的normal方法。该方法将空的self.weight矩阵填充为一个符合 (0,1)正太分布的矩阵。
N
(
mean
,
std
2
)
.
\mathcal{N}(\text{mean}, \text{std}^2).
N
(
mean
,
std
2
)
.
def normal_(tensor: Tensor, mean: float = 0., std: float = 1.) -> Tensor:r"""Fills the input Tensor with values drawn from the normaldistribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`.Args:tensor: an n-dimensional `torch.Tensor`mean: the mean of the normal distributionstd: the standard deviation of the normal distributionExamples:>>> w = torch.empty(3, 5)>>> nn.init.normal_(w)"""return _no_grad_normal_(tensor, mean, std)继续追踪_no_grad_normal_(tensor, mean, std)我们发现,该方法是通过c++实现,所在的源码文件目录为:
namespace torch {
namespace nn {
namespace init {
namespace {
struct Fan {explicit Fan(Tensor& tensor) {const auto dimensions = tensor.ndimension();TORCH_CHECK(dimensions >= 2,"Fan in and fan out can not be computed for tensor with fewer than 2 dimensions");if (dimensions == 2) {in = tensor.size(1);out = tensor.size(0);} else {in = tensor.size(1) * tensor[0][0].numel();out = tensor.size(0) * tensor[0][0].numel();}}int64_t in;int64_t out;
};
Tensor normal_(Tensor tensor, double mean, double std) {NoGradGuard guard;return tensor.normal_(mean, std);
}forward方法的c++实现如下所示。
torch::Tensor EmbeddingImpl::forward(const Tensor& input) {return F::detail::embedding(input,weight,options.padding_idx(),options.max_norm(),options.norm_type(),options.scale_grad_by_freq(),options.sparse());
}继续追踪,发现weight中的每个变量被下面的c++代码填充了正太分布的随机数。
void normal_kernel(const TensorBase &self, double mean, double std, c10::optional<Generator> gen) {CPUGeneratorImpl* generator = get_generator_or_default<CPUGeneratorImpl>(gen, detail::getDefaultCPUGenerator());templates::cpu::normal_kernel(self, mean, std, generator);
}随机数的生成调用如下的代码,首先询问:目前代码是在什么设备上运行,并调用cpu或者gup上的随机数生成方法。
template <typename T>
static inline T * check_generator(c10::optional<Generator> gen) {TORCH_CHECK(gen.has_value(), "Expected Generator but received nullopt");TORCH_CHECK(gen->defined(), "Generator with undefined implementation is not allowed");TORCH_CHECK(T::device_type() == gen->device().type(), "Expected a '", T::device_type(), "' device type for generator but found '", gen->device().type(), "'");return gen->get<T>();
}/*** Utility function used in tensor implementations, which* supplies the default generator to tensors, if an input generator* is not supplied. The input Generator* is also static casted to* the backend generator type (CPU/CUDAGeneratorImpl etc.)*/
template <typename T>
static inline T* get_generator_or_default(const c10::optional<Generator>& gen, const Generator& default_gen) {return gen.has_value() && gen->defined() ? check_generator<T>(gen) : check_generator<T>(default_gen);
}至此,embedding的每个随机数的生成过程都清楚了。
总结
Embedding的过程,其实就是为每个单词对应一个向量的过程。该向量为(0,1)正太分布,该矩阵在Embedding的实例化过程就已经被初始化完成。在调用Embedding示例的时候即forward开始工作的时候,只是做了一个匹配的过程,也就是将<字典,向量>的对应关系应用到input上。前期解读该部分源码的困惑是一只找不到forward中的对应处理过程,以为embedding的处理逻辑是在forward的阶段展开的,显然这种想法是不对的。Pytorch的架构设计的的确优雅!
相关文章:
Pytorch深度解析:Transformer嵌入层源码逐行解读
前言 本部分博客需要先阅读博客: 《Transformer实现以及Pytorch源码解读(一)-数据输入篇》 作为知识储备。 Embedding使用方式 如下面的代码中所示,embedding一般是先实例化nn.Embedding(vocab_size, embedding_dim)。实例化的…...

HSP_10章 Python面向对象编程oop_基础部分
文章目录 P107 类与实例的关系1.类与实例的关系示意图2.类与实例的代码分析 P109 对象形式和传参机制1. 类与对象的区别和联系2. 属性/成员变量3. 类的定义和使用4. 对象的传递机制 P110 对象的布尔值P111 成员方法1. 基本介绍2. 成员方法的定义和基本使用3.注意事项和使用细节…...

JavaWeb系列十七: jQuery选择器 上
jQuery选择器 jQuery基本选择器jquery层次选择器基础过滤选择器内容过滤选择器可见度过滤选择器 选择器是jQuery的核心, 在jQuery中, 对事件处理, 遍历 DOM和Ajax 操作都依赖于选择器jQuery选择器的优点 $(“#id”) 等价于 document.getElementById(“id”);$(“tagName”) 等价…...

Gone框架介绍30 - 使用`goner/gin`提供Web服务
gone是可以高效开发Web服务的Golang依赖注入框架 github地址:https://github.com/gone-io/gone 文档地址:https://goner.fun/zh/ 使用goner/gin提供Web服务 文章目录 使用goner/gin提供Web服务注册相关的Goners编写Controller挂载路由路由处理函数io.Rea…...
Lipowerline5.0 雷达电力应用软件下载使用
1.配网数据处理分析 针对配网线路点云数据,优化了分类算法,支持杆塔、导线、交跨线、建筑物、地面点和其他线路的自动分类;一键生成危险点报告和交跨报告;还能生成点云数据采集航线和自主巡检航线。 获取软件安装包联系邮箱:289…...

STM32学习之一:什么是STM32
目录 1.什么是STM32 2.STM32命名规则 3.STM32外设资源 4. STM32的系统架构 5. 从0到1搭建一个STM32工程 学习stm32已经很久了,因为种种原因,也有很久一段时间没接触过stm32了。等我捡起来的时候,发现很多都已经忘记了,重新捡…...

AI绘画Stable Diffusion 超强一键去除图片中的物体,免费使用!
大家好,我是设计师阿威 在生成图像时总有一些不完美的小瑕疵,比如多余的物体或碍眼的水印,它们破坏了图片的美感。但别担心,今天我们将介绍一款神奇的工具——sd-webui-cleaner,它可以帮助我们使用Stable Diffusion轻…...

零基础STM32单片机编程入门(一)初识STM32单片机
文章目录 一.概要二.单片机型号命名规则三.STM32F103系统架构四.STM32F103C8T6单片机启动流程五.STM32F103C8T6单片机主要外设资源六.编程过程中芯片数据手册的作用1.单片机外设资源情况2.STM32单片机内部框图3.STM32单片机管脚图4.STM32单片机每个管脚可配功能5.单片机功耗数据…...

Github上前十大开源Rust项目
在github上排名前十的Rust开源项目整理出来与大家共享,以当前的Star数为准。 Deno Deno 是 V8 上的安全 TypeScript 运行时。Deno 是一个建立在V8、Rust和Tokio之上的 JavaScript、TypeScript 和 WebAssembly 的运行时环境,具有自带安全的设置和出色的开…...

硬件开发笔记(二十):AD21导入外部下载的元器件原理图库、封装库和3D模型
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139707771 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

竞赛选题 python opencv 深度学习 指纹识别算法实现
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python opencv 深度学习 指纹识别算法实现 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:4分创新点:4分 该项目较为新颖…...
RK3568开发笔记(三):瑞芯微RK3588芯片介绍,入手开发板的核心板介绍
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139905873 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...
-- 如何将Igh移植到Linux/Windows/RTOS等多操作系统)
EtherCAT主站IgH解析(二)-- 如何将Igh移植到Linux/Windows/RTOS等多操作系统
版权声明:本文为本文为博主原创文章,转载请注明出处 https://www.cnblogs.com/wsg1100 如有错误,欢迎指正。 本文简单介绍如何将 igh 移植到 zephyr、freertos、rtems、rtthread等RTOS ,甚至 windows 上。 ##前言 目前࿰…...

ansible copy模块参选选项
copy模块用于将文件从ansible控制节点(管理主机)或者远程主机复制到远程主机上。其操作类似于scp(secure copy protocol)。 关键参数标红。 参数: src:(source:源) 要复制到远程…...

展厅设计主要的六大要素
1、从创意开始 展示设计的开始必须创意在先。根据整体的风格思路进行创意,首先要考虑的是主体的造型、大小高度位置以及它和周围展厅的关系。另外其他道具设计制作与运作方式也必须在创意中有明确的体现。 2、平面感 平面感是指对展示艺术设计平面图纸审美和功能两个…...
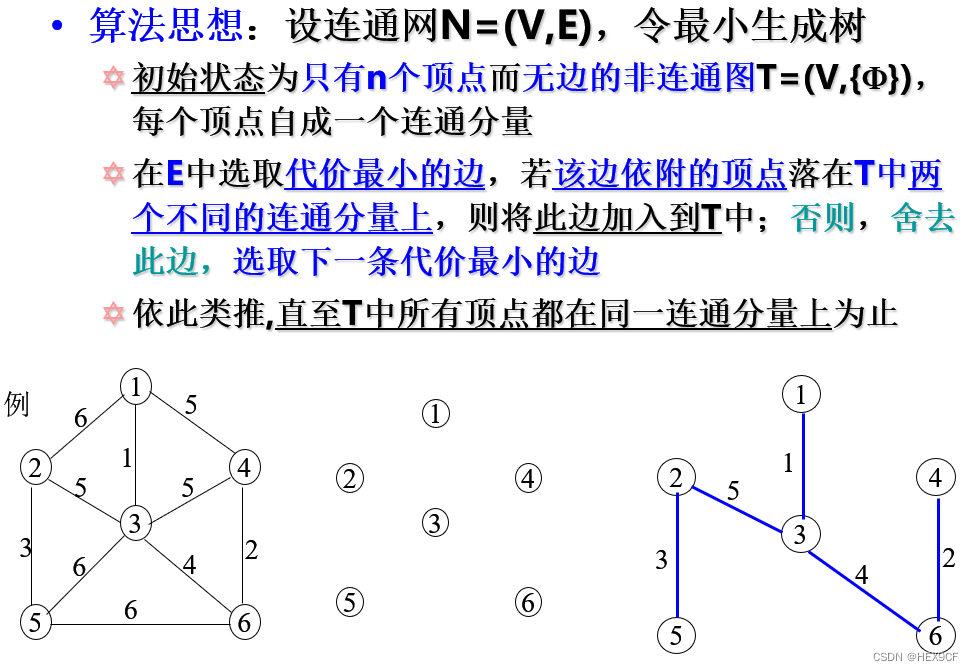
【数据结构与算法】最小生成树,Prim算法,Kruskal算法 详解
最小生成树的实际应用背景。 最节省经费的前提下,在n个城市之间建立通信联络网。 Kruskal算法(基于并查集) void init() {for (int i 1; i < n; i) {pre[i] i;} }ll root(ll a) {ll i a;while (pre[i] ! i) {i pre[i];}return i p…...

【启明智显产品分享】Model3工业级HMI芯片详解系列专题(三):安全、稳定、高防护
芯片作为电子设备的核心部件,,根据不同的应用领域被分为不同等级。工业级芯片适用于工业自动化、控制系统和仪器仪表等领域,对芯片的安全、稳定、防护能力等等有着较高的要求。这些芯片往往需要具备更宽的工业温度范围,能够在更恶…...

【面试干货】Java中的四种引用类型:强引用、软引用、弱引用和虚引用
【面试干货】Java中的四种引用类型:强引用、软引用、弱引用和虚引用 1、强引用(Strong Reference)2、软引用(Soft Reference)3、弱引用(Weak Reference)4、虚引用(Phantom Reference…...

对称/非对称加密
对称加密和非对称加密是两种主要的加密方式,用于保护数据的机密性和完整性。它们在密钥的使用和管理上有着显著的不同。 对称加密 原理 对称加密(Symmetric Encryption)使用相同的密钥进行加密和解密。这意味着发送方和接收方必须共享相同…...

DDei在线设计器-API-DDeiSheet
DDeiSheet DDeiSheet是代表一个页签,一个页签含有一个DDeiStage用于显示图形。 DDeiSheet实例包含了一个页签的所有数据,在获取后可以通过它访问其他内容。DDeiFile中的sheets属性记录了当前文件的页签列表。 一个DDeiFile实例至少包含一个DDeiSheet…...

ROFL-Player:基于C的多版本英雄联盟回放文件解析技术实现
ROFL-Player:基于C#的多版本英雄联盟回放文件解析技术实现 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款…...

基于NXP芯片的跳频技术如何构建高安全汽车无钥匙进入系统
1. 项目概述与核心价值最近几年,汽车的无钥匙进入与启动系统(PEPS)几乎成了新车的标配,但随之而来的安全挑战也日益严峻。你可能听说过,甚至亲身经历过,不法分子利用“中继攻击”设备,在车主不知…...

计算机光标自动化控制:从模拟点击到智能交互的技术实现与应用
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Computer-cursor-tech-support”。初看这个标题,你可能会有点摸不着头脑:电脑光标和技术支持,这两者是怎么联系到一起的?是开发了一个新的光标样式&am…...

手把手教你为全志Tina Linux添加新SPI屏驱动:以GC9306和HX8357C为例
全志Tina Linux SPI屏驱动移植实战:从裸机到内核框架的完整指南 在嵌入式Linux开发中,LCD显示屏的驱动移植是一个常见但颇具挑战性的任务。不同于裸机环境下的直接寄存器操作,Linux内核要求驱动程序遵循特定的框架和规范。本文将深入探讨如何…...

终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生
终极魔兽争霸3兼容性修复指南:WarcraftHelper让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III…...

Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程
Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare是一款广受欢迎的文件对比工具,但当30天试用期…...

从分辨率、码率到蓝光:解码高清视频的三大核心要素
1. 分辨率:高清世界的基石 第一次接触高清视频时,我被商家宣传的"4K超清"搞得一头雾水。直到自己开始做视频剪辑才明白,分辨率就像织布的经纬线——它决定了画面能有多细腻。举个生活中的例子,1080P分辨率相当于用19201…...

Git多用户代理架构解析:实现细粒度权限管理与统一访问入口
1. 项目概述:从单兵作战到团队协作的代码管理跃迁如果你是一个独立开发者,或者在一个小团队里,你可能习惯了把代码往GitHub、Gitee这样的平台上一扔,设置个私有仓库,然后通过个人账号的SSH密钥来管理访问权限。这种方式…...

Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度
Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度 【免费下载链接】glass-browser A floating, always-on-top, transparent browser for Windows. 项目地址: https://gitcode.com/gh_mirrors/gl/glass-browser 当你在编写代码时需要查…...

ClawForgeAI:基于工作流编排的AIGC创意自动化平台解析
1. 项目概述:从“ClawForgeAI/clawforge”看AI驱动的创意工具新范式最近在GitHub上看到一个挺有意思的项目,叫“ClawForgeAI/clawforge”。光看这个名字,你可能会有点摸不着头脑——“ClawForge”听起来像是个游戏模组工具或者某种机械设计软…...