Unity-ECS详解
今天我们来了解Unity最先进的技术——ECS架构(EntityComponentSystem)。
Unity官方下有源码,我们下载源码后来学习。
ECS
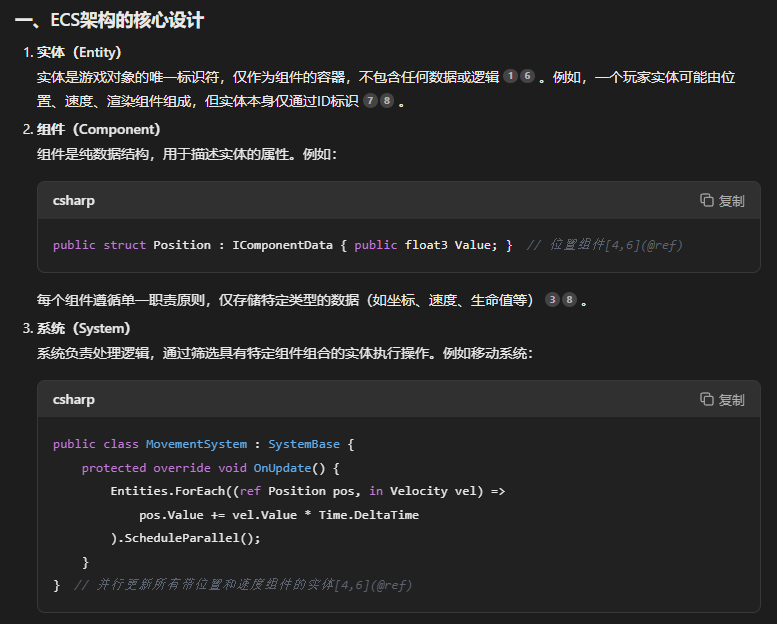
与OOP(Object-Oriented Programming)对应,ECS是一种完全不同的编程范式与数据架构,ECS(实体-组件-系统)以数据驱动为核心,通过组合与分离逻辑提升性能,适用于高并发场景。
总的来说,如果场景内有大量的对象或者数据需要处理,我们就可以用ECS来完成以大大提高计算效率。
当然,这里还是要提一嘴相关概念,关于DOTS:

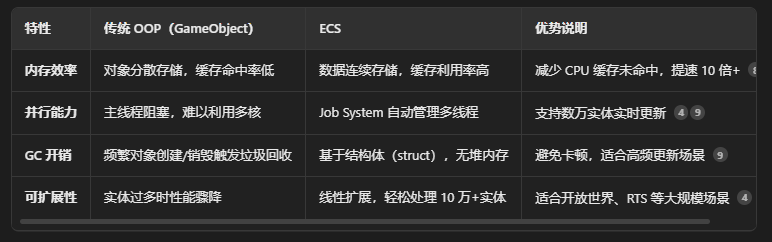
DOTS是以ECS为骨架、Job System为肌肉、Burst为加速引擎的高性能开发生态。它通过数据连续存储(ECS)、多线程调度(Job)和机器码编译(Burst),解决了传统游戏开发中内存碎片化、多核利用率低、GC卡顿三大痛点,尤其适用于开放世界/RTS/大规模模拟场景。
Unity提供的源码下载下来后长这样:
由于内容过多,就不一一展开细说了,我们主要来学习这个Dots101的内容:这是一个帮助我们快速入门的项目示例文件夹。
Dots101
我们先从最基础的Dots101开始吧,这个文件夹的内容就是帮助我们快速理解和上手Dots的。
不过话说回来居然要求Unity6000.0.32,版本要求这么高干嘛?
可以看到Dots101里就包含了Entities,Jobs,Netcode,Physics和一些其他内容的示例,是一个精华版的ECS架构展示。
Entities101
关于Entities:在Unity DOTS中,Entities是实现数据与逻辑分离的核心手段,其核心目标是通过连续内存存储优化CPU缓存命中率和并行效率。

首先ECS的分工是这样的:E就是实体——作为一个标识符,并不存储任何信息,C则是组件,专门负责存储数据,S是系统,用来处理所有的复杂逻辑。在ECS的底层中,会根据实体的组件组成来划分不同的原型分类,每一个内存块,也就是chunk,就只对应一个原型分类。当我们需要访问数据时,我们先根据实体ID找到原型分类后再找到对应的chunk。
这个文件夹里给了四个学习的示例:
分别是消防队员救火,生成方块,踢球小游戏和龙卷风模拟。
消防员救火:
首先这个示例中做了一个对比:主线程 vs 单线程作业 vs 并行作业的对比。
private void HeatSpread_MainThread(ref SystemState state, DynamicBuffer<Heat> heatBuffer, Config config){var heatRW = heatBuffer;NativeArray<Heat> heatRO = heatBuffer.ToNativeArray(Allocator.Temp);var speed = SystemAPI.Time.DeltaTime * config.HeatSpreadSpeed;int numColumns = config.GroundNumColumns;int numRows = config.GroundNumRows;for (int index = 0; index < heatRO.Length; index++){int row = index / numColumns;int col = index % numRows;var prevCol = col - 1;var nextCol = col + 1;var prevRow = row - 1;var nextRow = row + 1;float increase = 0;increase += Index(row, nextCol, heatRO, numColumns, numRows);increase += Index(row, prevCol, heatRO, numColumns, numRows);increase += Index(prevRow, prevCol, heatRO, numColumns, numRows);increase += Index(prevRow, col, heatRO, numColumns, numRows);increase += Index(prevRow, nextCol, heatRO, numColumns, numRows);increase += Index(nextRow, prevCol, heatRO, numColumns, numRows);increase += Index(nextRow, col, heatRO, numColumns, numRows);increase += Index(nextRow, nextCol, heatRO, numColumns, numRows);increase *= speed;heatRW[index] = new Heat{Value = math.min(1, heatRO[index].Value + increase)};}}这是主线程的实现。
[BurstCompile]public struct HeatSpreadJob_SingleThreaded : IJob{public NativeArray<Heat> heatRW;[ReadOnly] public NativeArray<Heat> heatRO;public float HeatSpreadSpeed;public int NumColumns;public int NumRows;public void Execute(){for (int index = 0; index < heatRO.Length; index++){int row = index / NumColumns;int col = index % NumColumns;var prevCol = col - 1;var nextCol = col + 1;var prevRow = row - 1;var nextRow = row + 1;float increase = 0;increase += Index(row, nextCol);increase += Index(row, prevCol);increase += Index(prevRow, prevCol);increase += Index(prevRow, col);increase += Index(prevRow, nextCol);increase += Index(nextRow, prevCol);increase += Index(nextRow, col);increase += Index(nextRow, nextCol);increase *= HeatSpreadSpeed;heatRW[index] = new Heat{Value = math.min(1, heatRO[index].Value + increase)};}}private float Index(int row, int col){if (col < 0 || col >= NumColumns ||row < 0 || row >= NumRows){return 0;}return heatRO[row * NumColumns + col].Value;}}这是单线程实现(但是Burst编译器优化)。
[BurstCompile]public struct HeatSpreadJob_Parallel : IJobParallelFor{public NativeArray<Heat> heatRW;[ReadOnly] public NativeArray<Heat> heatRO;public float HeatSpreadSpeed;public int NumColumns;public int NumRows;public void Execute(int index){int row = index / NumColumns;int col = index % NumColumns;var prevCol = col - 1;var nextCol = col + 1;var prevRow = row - 1;var nextRow = row + 1;float increase = 0;increase += Index(row, nextCol);increase += Index(row, prevCol);increase += Index(prevRow, prevCol);increase += Index(prevRow, col);increase += Index(prevRow, nextCol);increase += Index(nextRow, prevCol);increase += Index(nextRow, col);increase += Index(nextRow, nextCol);increase *= HeatSpreadSpeed;heatRW[index] = new Heat{Value = math.min(1, heatRO[index].Value + increase)};}private float Index(int row, int col){if (col < 0 || col >= NumColumns ||row < 0 || row >= NumRows){return 0;}return heatRO[row * NumColumns + col].Value;}}这个就是并行处理的实现,同样是Burst编译器优化。
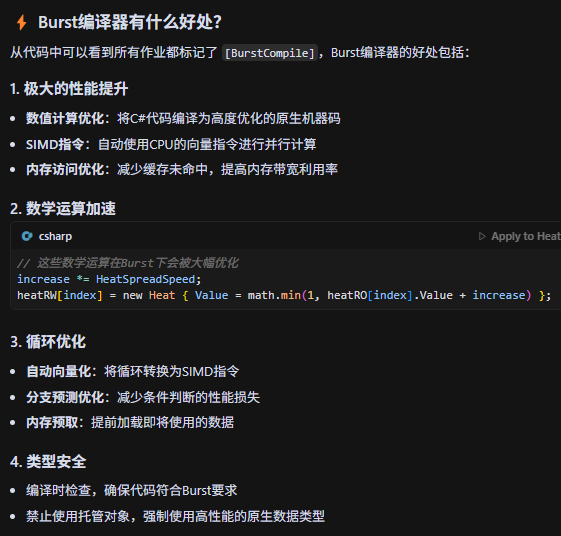
Burst 编译器是 Unity DOTS(数据导向技术栈)中的高性能代码优化引擎,专为大规模数据计算设计,通过将 C# 代码编译为高度优化的机器码,显著提升并行计算效率。
关于这个SIMD指令:SIMD(Single Instruction, Multiple Data,单指令多数据流)是一种并行计算技术,允许CPU用一条指令同时对多个数据元素执行相同的操作,从而大幅提升数据处理效率。
关于Burst编译器,我们至少要了解他是一个在大密度大数量高性能计算场景下非常厉害的编译器即可。

前面提到了三种处理方式:主线程、单线程和并行,如何看出三者的性能差距呢?
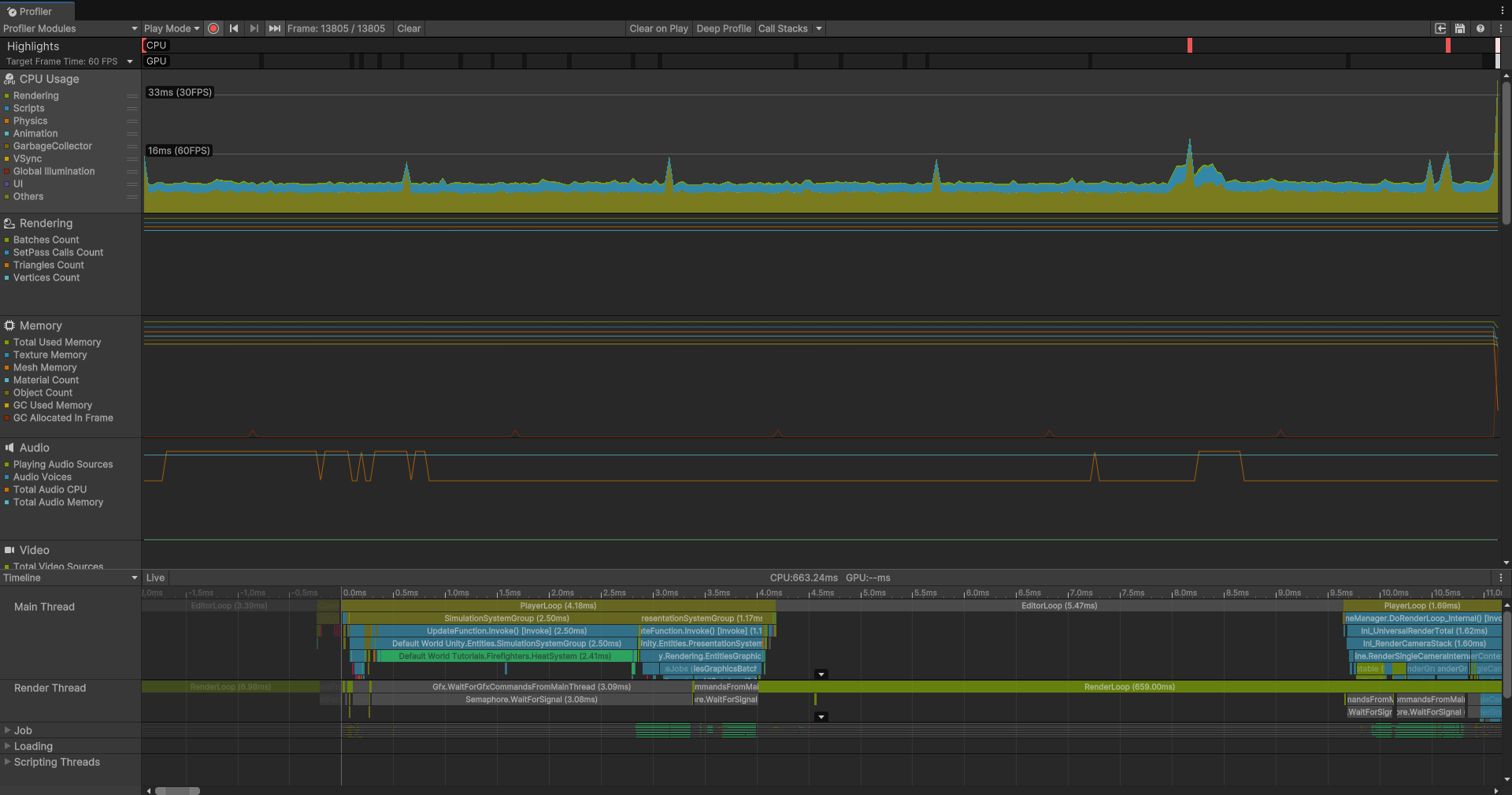
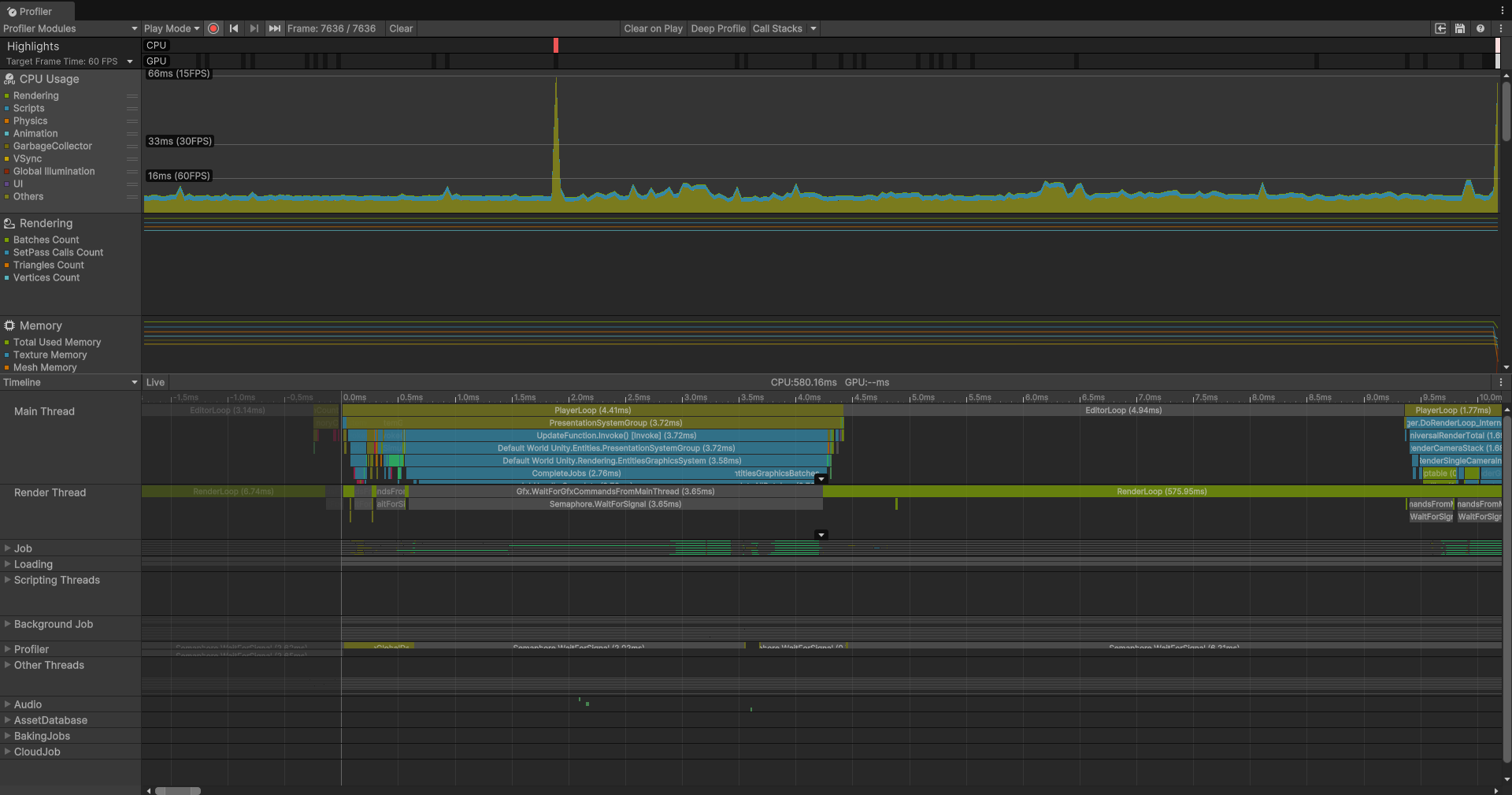
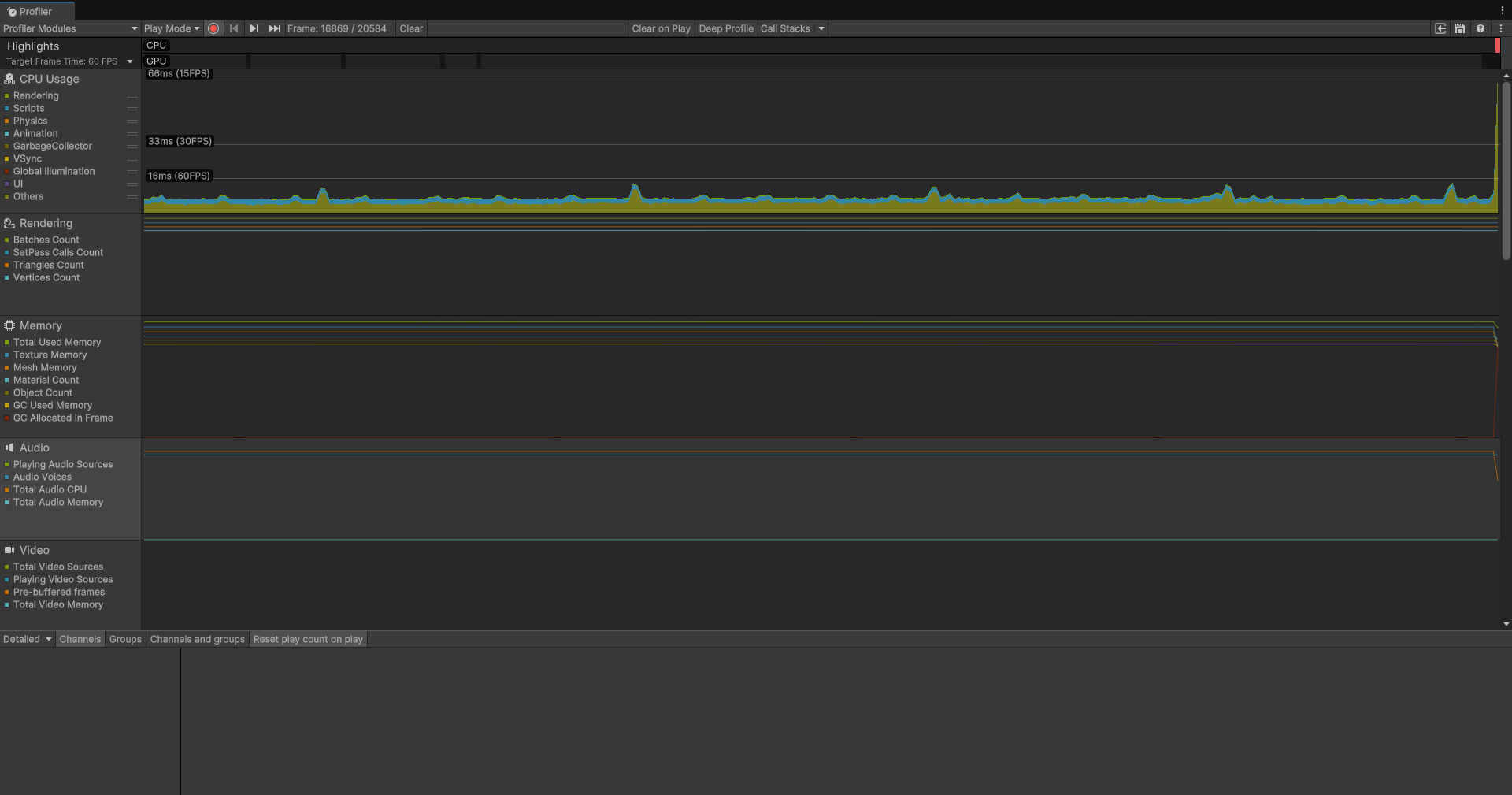
这就是三种处理方式的Profiler的性能表现:

可见当我们需要大规模的计算和生成时,并行处理是最好的选择,在Unity中,有专门这样一个库负责处理大规模并行任务:
还有值得一提的是:Unity 的 Jobs 库(Job System) 是专门针对 CPU 多核并行计算 设计的,而 GPU 无法直接执行 Job System 的任务,这是由两者的硬件架构和执行逻辑的差异决定的。Job System 是 Unity 提供的 多线程任务调度框架,旨在将计算密集型任务(如物理模拟、AI 决策)拆分为子任务,分配到多个 CPU 核心并行执行,其设计目标是最大化 CPU 多核利用率,避免主线程阻塞。
然后是这个HelloCubes示例:
HelloCube通过ECS架构实现高效的大量立方体生成:首先在场景中配置SpawnerAuthoring组件并引用立方体预制体,烘焙时转换为ECS的Spawner组件;然后SpawnSystem检测到场景中没有立方体时,使用EntityManager.Instantiate(prefab, 500, Allocator.Temp)一次性批量生成500个实体;接着通过并行作业为每个立方体设置随机位置,使用独立的随机种子确保线程安全;立方体在FallAndDestroySystem中旋转下落,当Y坐标小于0时通过EntityCommandBuffer延迟销毁;最后当所有立方体被销毁后,SpawnSystem再次检测到场景为空,重新开始生成循环,形成一个持续的"生成→下落→销毁→重新生成"的高性能循环系统。
Spawner组件负责存储GameObject由Baker转换而来的Entity引用,Entity物体就可以被EntityManager来实现大批量生成的效果;EntityCommandBuffer则是一个命令缓冲区,在这个区会缓冲一系列我们对于Entity物体的命令。
效果如图:
Jobs101
Unity Job System 是 Unity 引擎提供的一套多线程任务调度框架,旨在通过并行化计算密集型任务,充分利用多核 CPU 性能,提升游戏运行效率并降低主线程压力。
现代 CPU 普遍拥有多核心,但传统 Unity 代码默认运行在主线程,无法充分利用多核资源,而Job System 将任务拆分为小单元(Job),分配到多个 CPU 核心并行执行,显著提升计算效率。
在官方的示例代码中,我们的Jobs101生成了大量的方块,蓝色方块(Seeker)会去寻找最近红色方块(Target)。
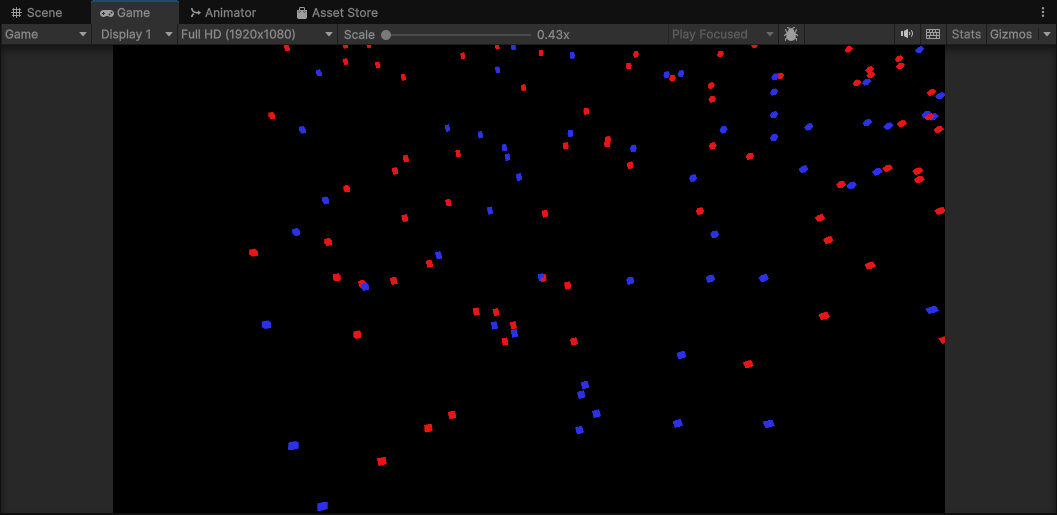
我们用四种方法来实现这个效果并比较性能:
首先是无Job,全部主线程暴力遍历:
// 在MonoBehaviour的Update里
foreach (var seeker in seekers)
{float minDist = float.MaxValue;Vector3 nearest = Vector3.zero;foreach (var target in targets){float dist = Vector3.Distance(seeker.position, target.position);if (dist < minDist){minDist = dist;nearest = target.position;}}// 画线Debug.DrawLine(seeker.position, nearest, Color.white);
}相信不用我多说都知道有多慢,首先只用主线程就很糟糕了,这个暴力的时间复杂度不知道是On多少了都,不卡是不可能的,Profiler效果如下:
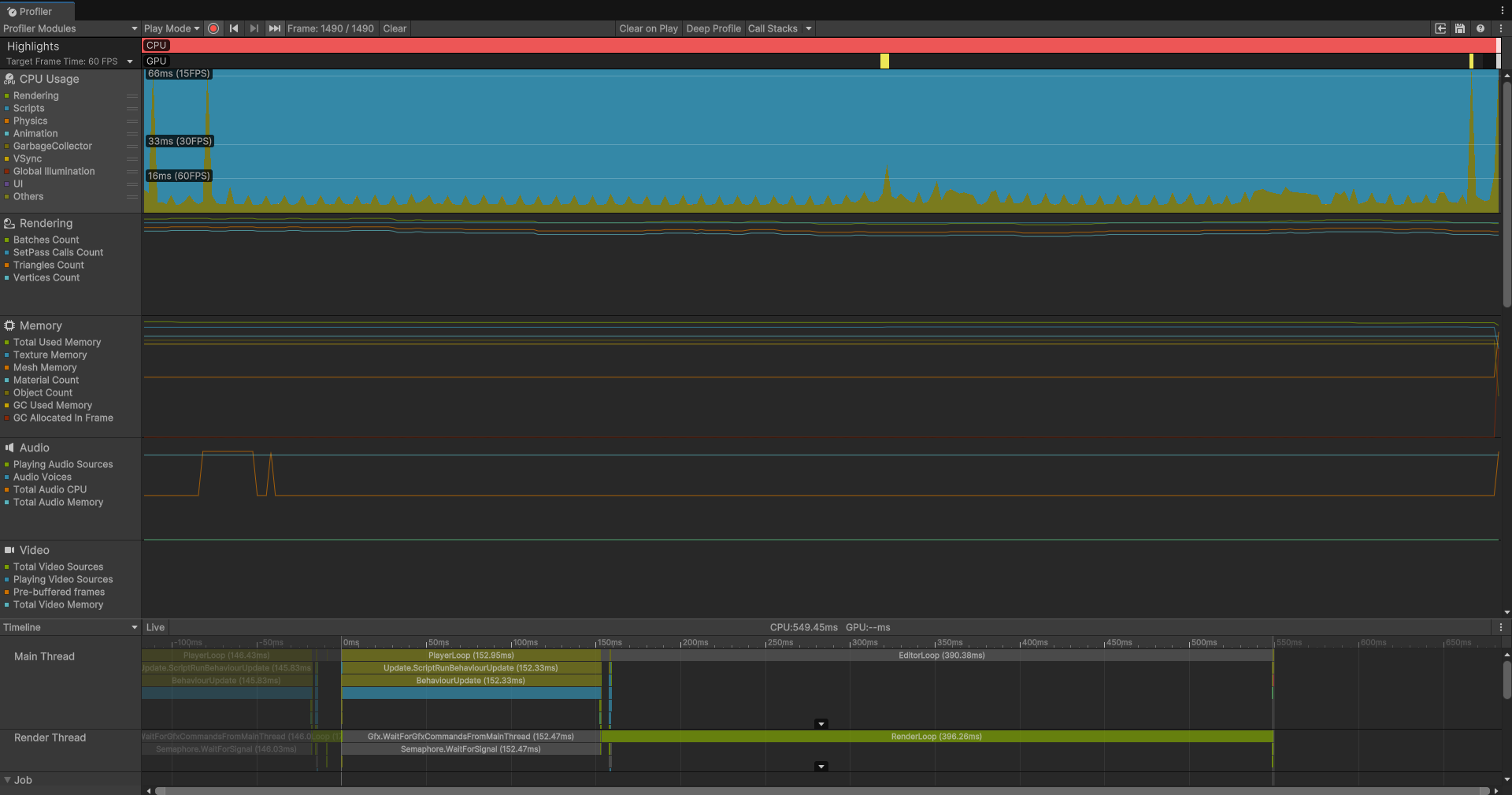
别的不说,就这大片大片的蓝色,这糟糕的帧数,体验有多差可想而知。(蓝色表示CPU的主要开销来源是Scripts,也就是脚本)。
然后是单线程Job:
public struct FindNearestJob : IJob
{[ReadOnly] public NativeArray<float3> TargetPositions;[ReadOnly] public NativeArray<float3> SeekerPositions;public NativeArray<float3> NearestTargetPositions;public void Execute(){for (int i = 0; i < SeekerPositions.Length; i++){float minDist = float.MaxValue;float3 nearest = float3.zero;for (int j = 0; j < TargetPositions.Length; j++){float dist = math.distance(SeekerPositions[i], TargetPositions[j]);if (dist < minDist){minDist = dist;nearest = TargetPositions[j];}}NearestTargetPositions[i] = nearest;}}
}可以看到我们的方法基于IJob的接口实现,实现这个接口的方法会默认将我们的任务放在Job System分配的工作线程上,而Job System是和我们的Burst编译器深度集成的,我们基于Job System分配的任务就可以去使用Burst编译器进行加速了。
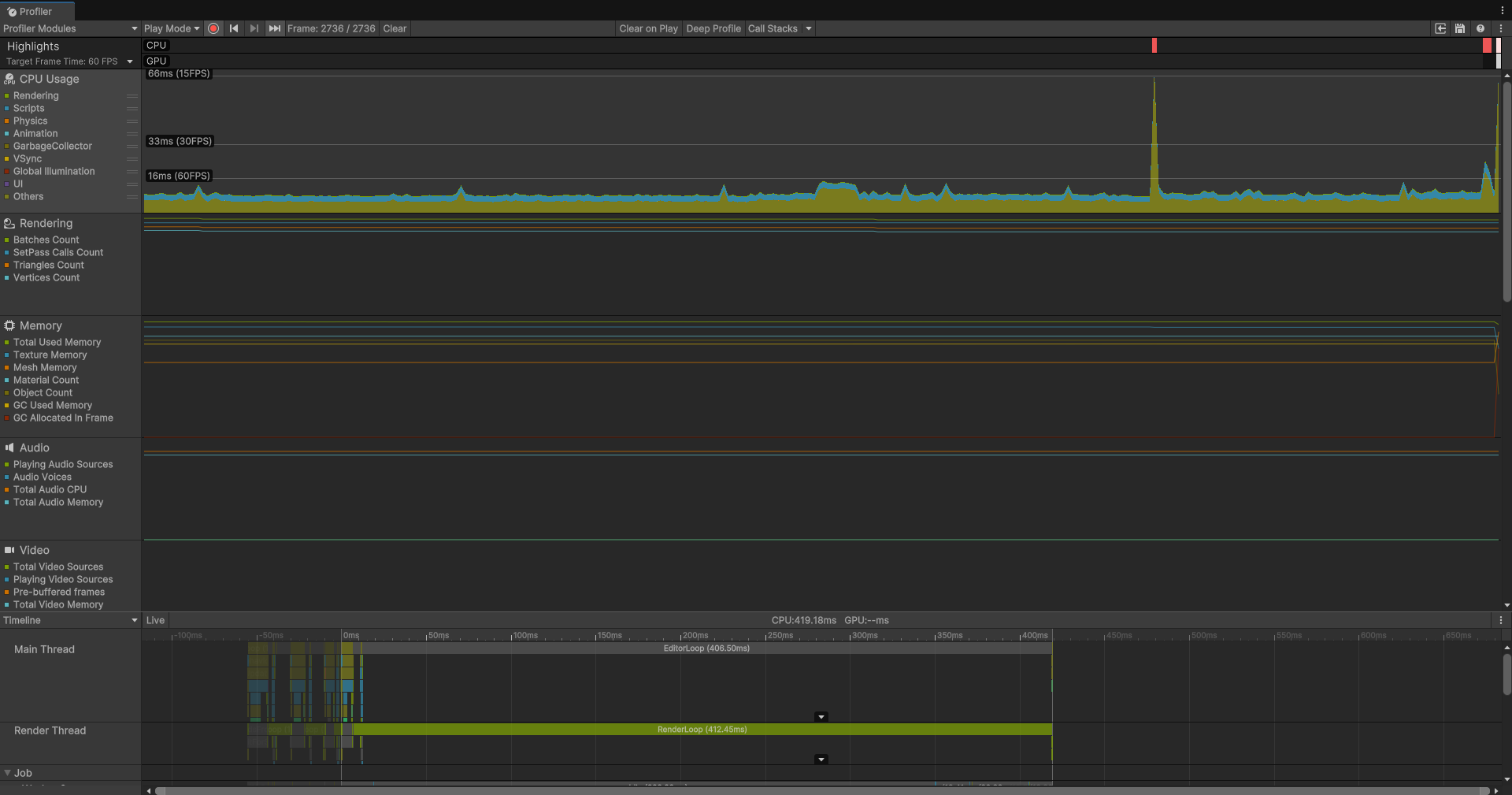
可以看到单线程Job的效果就非常好了,首先帧数大大提高,然后可以看到CPU开销主要的来源都是渲染相关的准备。
我们在这个基础上加入并行:并行Job。
用IJobParallelFor,每个Seeker的查找任务分配到不同线程,充分利用多核CPU,极大提升速度。
public struct FindNearestJob : IJobParallelFor
{[ReadOnly] public NativeArray<float3> TargetPositions;[ReadOnly] public NativeArray<float3> SeekerPositions;public NativeArray<float3> NearestTargetPositions;public void Execute(int i){float minDist = float.MaxValue;float3 nearest = float3.zero;for (int j = 0; j < TargetPositions.Length; j++){float dist = math.distance(SeekerPositions[i], TargetPositions[j]);if (dist < minDist){minDist = dist;nearest = TargetPositions[j];}}NearestTargetPositions[i] = nearest;}
}效果如下:
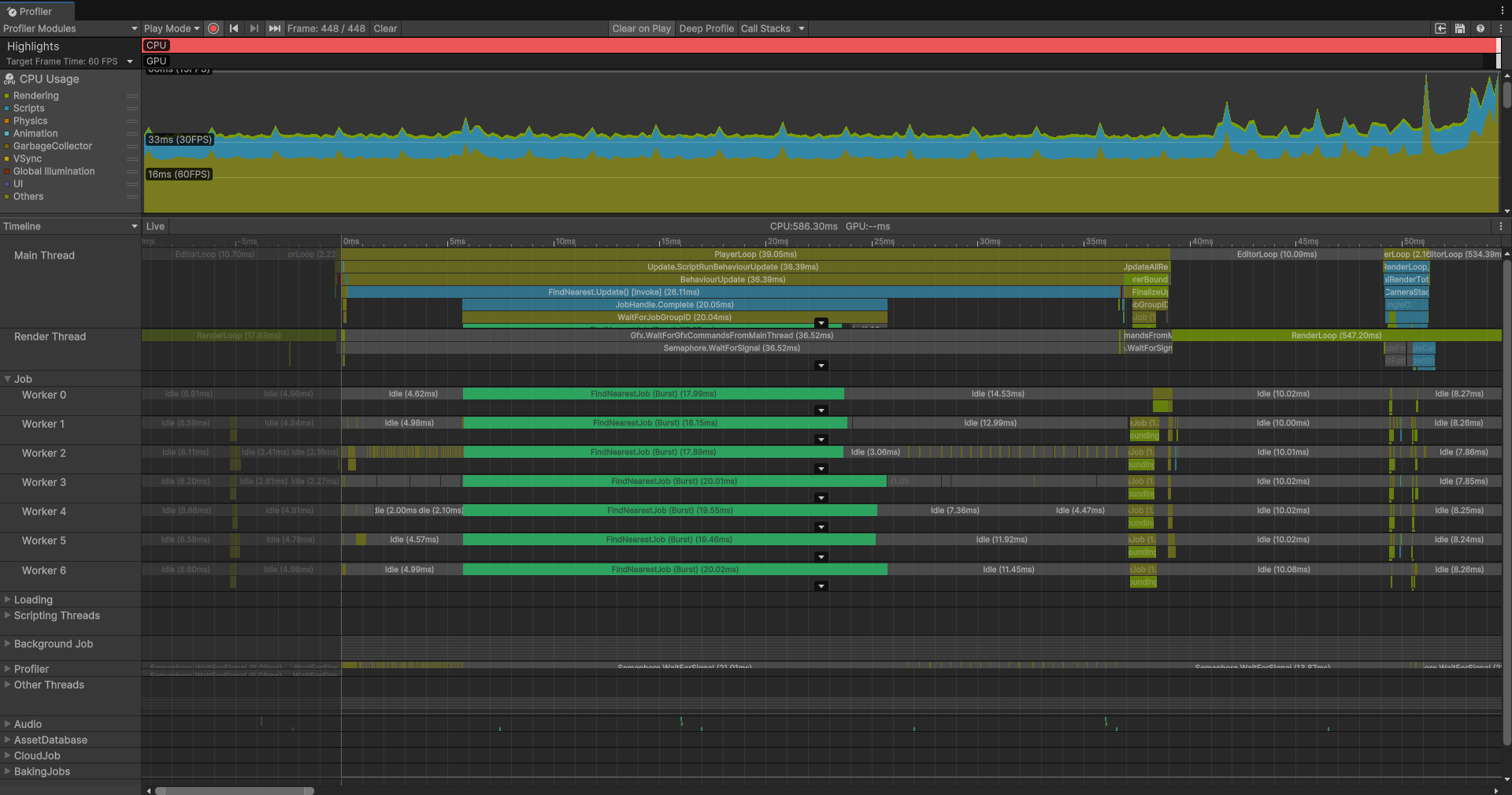
可以看到并行开启后,更多的worker出现了,但是我们会发现总的CPU开销反而还在提高——这显然是反常识的,我也感觉非常奇怪,那么出现这种现象的只有一种说法就是:线程的切换和调度的开销改过了本身利用CPU的多核提高效率的改善,尤其是当单个Job工作量其实不大时。还有一个点就是虽然我们充分利用了CPU,但是我们没有去改善算法,那么时间复杂度依然很爆炸。
所以我们需要最后的做法:并行Job + 优化算法(空间分区/排序)
using System.Collections.Generic;
using Unity.Burst;
using Unity.Collections;
using Unity.Jobs;
using Unity.Mathematics;namespace Tutorials.Jobs.Step4
{[BurstCompile]public struct FindNearestJob : IJobParallelFor{[ReadOnly] public NativeArray<float3> TargetPositions; // 已按X排序[ReadOnly] public NativeArray<float3> SeekerPositions;public NativeArray<float3> NearestTargetPositions;public void Execute(int index){float3 seekerPos = SeekerPositions[index];// 1. 二分查找X坐标最近的Targetint startIdx = TargetPositions.BinarySearch(seekerPos, new AxisXComparer { });// 2. 处理未精确命中情况if (startIdx < 0) startIdx = ~startIdx;if (startIdx >= TargetPositions.Length) startIdx = TargetPositions.Length - 1;float3 nearestTargetPos = TargetPositions[startIdx];float nearestDistSq = math.distancesq(seekerPos, nearestTargetPos);// 3. 向右查找Search(seekerPos, startIdx + 1, TargetPositions.Length, +1, ref nearestTargetPos, ref nearestDistSq);// 4. 向左查找Search(seekerPos, startIdx - 1, -1, -1, ref nearestTargetPos, ref nearestDistSq);NearestTargetPositions[index] = nearestTargetPos;}// 辅助查找函数void Search(float3 seekerPos, int startIdx, int endIdx, int step,ref float3 nearestTargetPos, ref float nearestDistSq){for (int i = startIdx; i != endIdx; i += step){float3 targetPos = TargetPositions[i];float xdiff = seekerPos.x - targetPos.x;// X轴距离的平方大于当前最小距离,提前终止if ((xdiff * xdiff) > nearestDistSq) break;float distSq = math.distancesq(targetPos, seekerPos);if (distSq < nearestDistSq){nearestDistSq = distSq;nearestTargetPos = targetPos;}}}}// 用于X轴排序的比较器public struct AxisXComparer : IComparer<float3>{public int Compare(float3 a, float3 b){return a.x.CompareTo(b.x);}}
}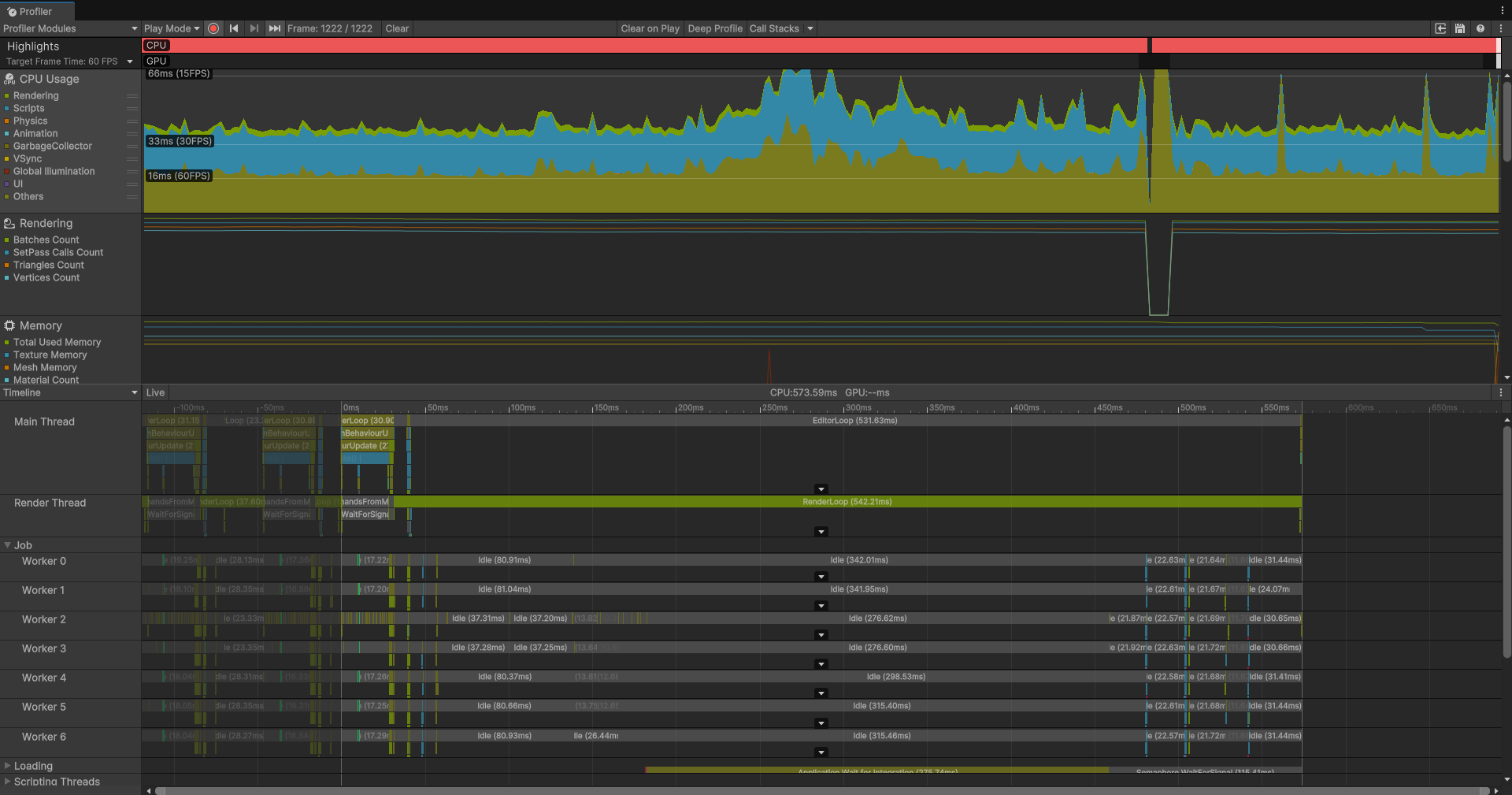
虽然可以看到实际的效果好像不是很好,但至少首先我们的CPU开销渲染的部分降低了而脚本的开销变大了,然后多个线程在同时工作,也算是符合预期吧。
那么从以上的示例可以知道的是:
Job System是一个专门为CPU设计的多线程任务处理器,可以充分利用CPU的多核优势,并且和Burst编译器深度集成,针对大数据计算任务尤其有优势。

首先可以知道的是Job System的底层是一个线程池,但是与传统线程池不同的是,Job System还添加了很多内容:
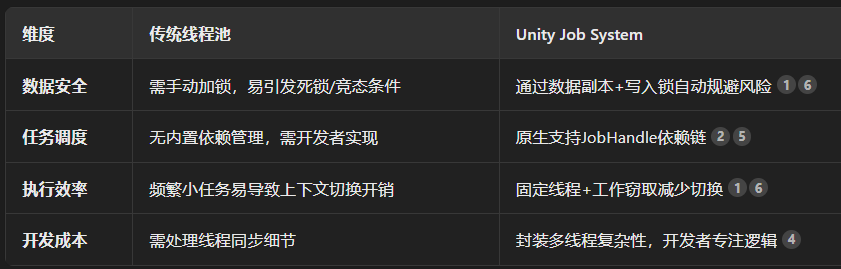
NetCode101
这个示例则是一个具体的ECS架构的使用,一般来说我们来做游戏时:


因为这个示例代码中没有提供基于OOP实现的游戏示例,我们也没法直观地通过Profiler来判断二者的性能差异。
Physics101
终于来到我们真正的目标——物理引擎了。我们之前已经走马观花地看过了PhysX引擎的内容了,现在问题来了:Unity DOTS Physics与PhysX的区别在哪呢?

我们拿两段代码出来比对一下就能看出差别了:
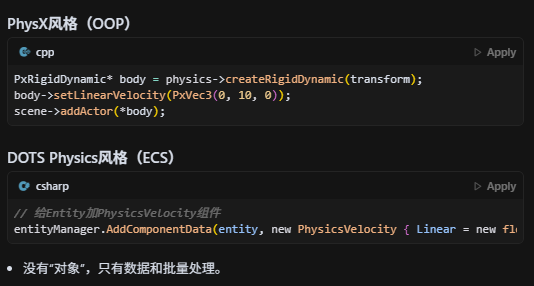
在Dots101中实现了很多物体内容啊,我们来挑几个比较重要的来说说:
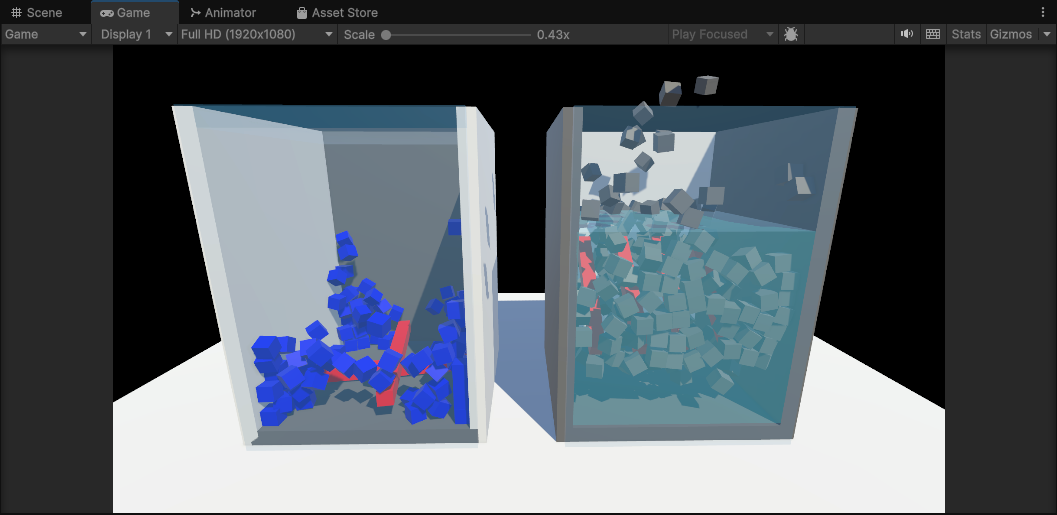
这个示例中模拟了水的浮力以及阻力的效果,以及旋转叶片与旋转叶片的碰撞的效果。
public struct Blade : IComponentData
{public float3 AngularVelocity;
}public partial struct RotateBladeSystem : ISystem
{public void OnUpdate(ref SystemState state){foreach (var (bladeData, velocity) in SystemAPI.Query<RefRO<Blade>, RefRW<PhysicsVelocity>>()){velocity.ValueRW.Angular = bladeData.ValueRO.AngularVelocity;}}
}每个叶片是一个Entity,带有Blade组件(包含角速度),系统每帧将Blade.AngularVelocity赋值给PhysicsVelocity.Angular,实现持续旋转。
public struct Buoyancy : IComponentData, IEnableableComponent
{public float WaterLevel;public float BuoyancyForce;public float Drag;
}public partial struct BuoyancySystem : ISystem
{public void OnUpdate(ref SystemState state){foreach (var (buoyant, transform, velocity, mass) inSystemAPI.Query<RefRO<Buoyancy>, RefRW<LocalTransform>, RefRW<PhysicsVelocity>, RefRO<PhysicsMass>>()){float depth = buoyant.ValueRO.WaterLevel - transform.ValueRW.Position.y;float buoyancyForce = depth * buoyant.ValueRO.BuoyancyForce * deltaTime;velocity.ValueRW.ApplyLinearImpulse(mass.ValueRO, new float3(0, buoyancyForce, 0));velocity.ValueRW.Linear *= 1.0f - buoyant.ValueRO.Drag * deltaTime;}}
}立方体带有Buoyancy组件(包含水面高度、浮力系数、阻力系数),系统每帧计算立方体与水面的相对深度,施加向上的浮力和线性阻力。
public partial struct BuoyancyZoneSystem : ISystem
{public void OnUpdate(ref SystemState state){// 先禁用所有立方体的浮力var buoyancyQuery = SystemAPI.QueryBuilder().WithAll<Buoyancy>().Build();state.EntityManager.SetComponentEnabled<Buoyancy>(buoyancyQuery, false);// 监听TriggerEvents,激活进入水区的立方体浮力var sim = SystemAPI.GetSingleton<SimulationSingleton>().AsSimulation();sim.FinalJobHandle.Complete();foreach (var triggerEvent in sim.TriggerEvents){// 判断哪个是立方体,哪个是水区// ...(省略判断代码)// 复制水区的浮力参数到立方体cubeBuoyancy.ValueRW = zone.ValueRO.Buoyancy;SystemAPI.SetComponentEnabled<Buoyancy>(cubeEntity, true);}}
}水区是一个带有BuoyancyZone组件的Entity,系统监听物理TriggerEvents(触发事件),当立方体进入水区时,激活其Buoyancy组件并复制水区的浮力参数。
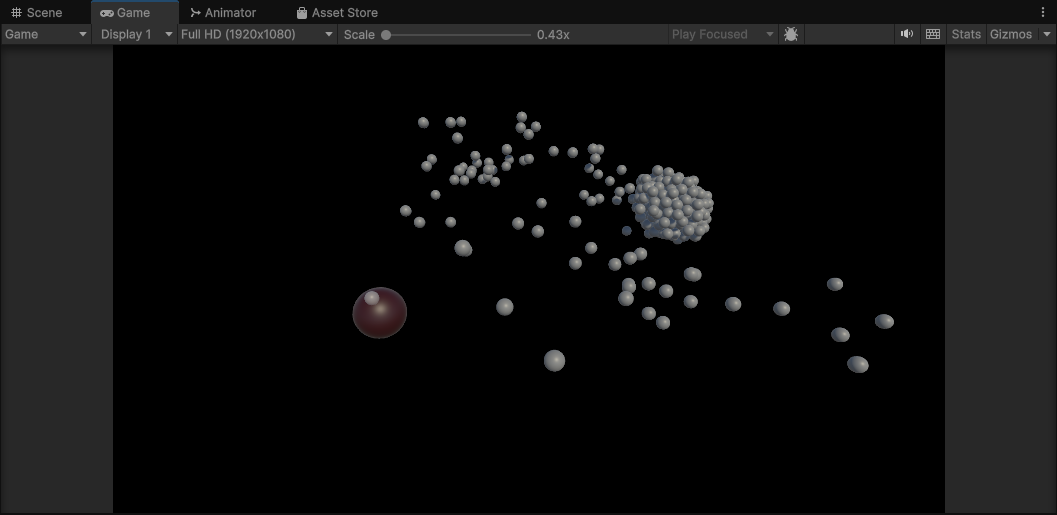
这里是实现了一个重力井的效果,重力井绕着圆心旋转,并不断吸附附近的小球。
// GravityWellSystem.cs
foreach (var (wellTransform, well) inSystemAPI.Query<RefRW<LocalTransform>, RefRW<GravityWell>>())
{// 让重力井的角度不断增加,实现绕圆心旋转well.ValueRW.OrbitPos += config.WellOrbitSpeed * dt;math.sincos(well.ValueRW.OrbitPos, out var s, out var c);wellTransform.ValueRW.Position = new float3(c, 0, s) * config.WellOrbitRadius;
}这是让重力井实现圆周运动的代码。
// 获取所有重力井的位置
var wellQuery = SystemAPI.QueryBuilder().WithAll<GravityWell, LocalTransform>().Build();
var wellTransforms = wellQuery.ToComponentDataArray<LocalTransform>(Allocator.Temp);// 对每个小球
foreach (var (velocity, collider, mass, ballTransform) inSystemAPI.Query<RefRW<PhysicsVelocity>, RefRO<PhysicsCollider>,RefRO<PhysicsMass>, RefRO<LocalTransform>>())
{// 对每个重力井for (int i = 0; i < wellTransforms.Length; i++){var wellTransform = wellTransforms[i];// 施加“吸引力”,本质是ApplyExplosionForce的负值velocity.ValueRW.ApplyExplosionForce(mass.ValueRO,collider.ValueRO,ballTransform.ValueRO.Position,ballTransform.ValueRO.Rotation,-config.WellStrength, // 负值=吸引wellTransform.Position,0, // 半径为0,表示无限远都有效dt,math.up());}
}实现吸附。
其他的相关示例还有很多,大家感兴趣的可以自行查阅。
相关文章:
Unity-ECS详解
今天我们来了解Unity最先进的技术——ECS架构(EntityComponentSystem)。 Unity官方下有源码,我们下载源码后来学习。 ECS 与OOP(Object-Oriented Programming)对应,ECS是一种完全不同的编程范式与数据架构…...
uni-app学习笔记二十七--设置底部菜单TabBar的样式
官方文档地址:uni.setTabBarItem(OBJECT) | uni-app官网 uni.setTabBarItem(OBJECT) 动态设置 tabBar 某一项的内容,通常写在项目的App.vue的onLaunch方法中,用于项目启动时立即执行 重要参数: indexnumber是tabBar 的哪一项&…...

7种分类数据编码技术详解:从原理到实战
在数据分析和机器学习领域,分类数据(Categorical Data)的处理是一个基础但至关重要的环节。分类数据指的是由有限数量的离散值组成的数据类型,如性别(男/女)、颜色(红/绿/蓝)或产品类…...
【字节拥抱开源】字节团队开源视频模型 ContentV: 有限算力下的视频生成模型高效训练
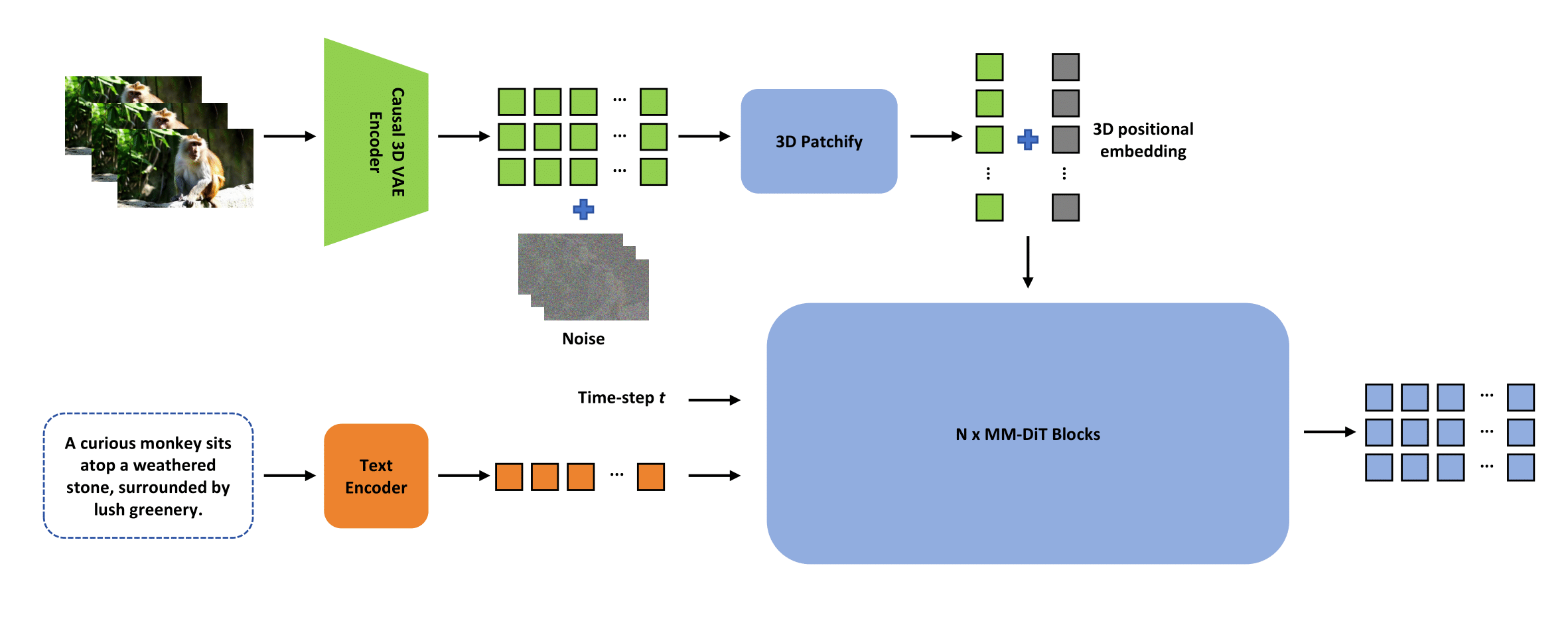
本项目提出了ContentV框架,通过三项关键创新高效加速基于DiT的视频生成模型训练: 极简架构设计,最大化复用预训练图像生成模型进行视频合成系统化的多阶段训练策略,利用流匹配技术提升效率经济高效的人类反馈强化学习框架&#x…...
本地部署drawDB结合内网穿透技术实现数据库远程管控方案
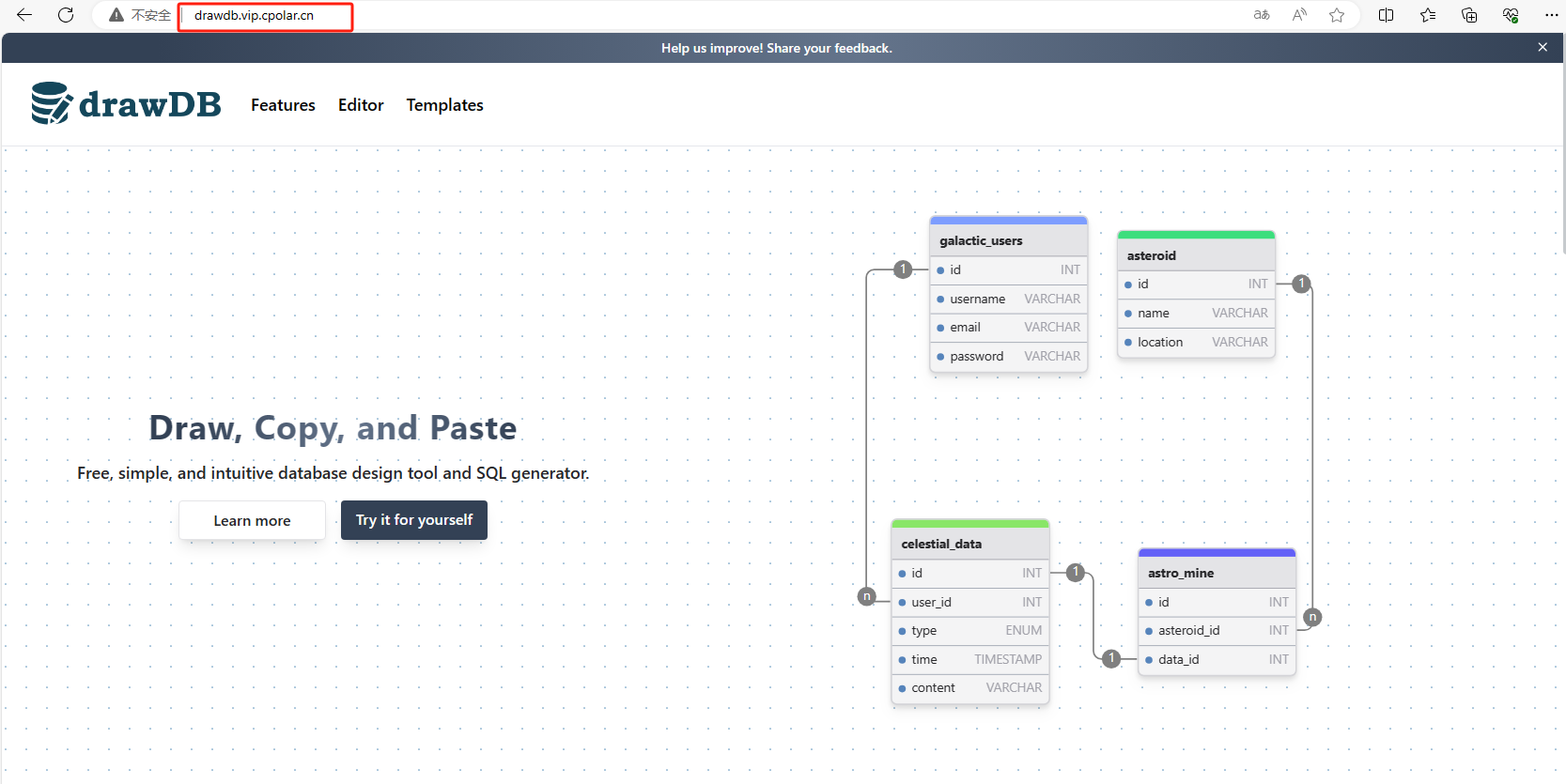
文章目录 前言1. Windows本地部署DrawDB2. 安装Cpolar内网穿透3. 实现公网访问DrawDB4. 固定DrawDB公网地址 前言 在数字化浪潮席卷全球的背景下,数据治理能力正日益成为构建现代企业核心竞争力的关键因素。无论是全球500强企业的数据中枢系统,还是初创…...
可视化预警系统:如何实现生产风险的实时监控?
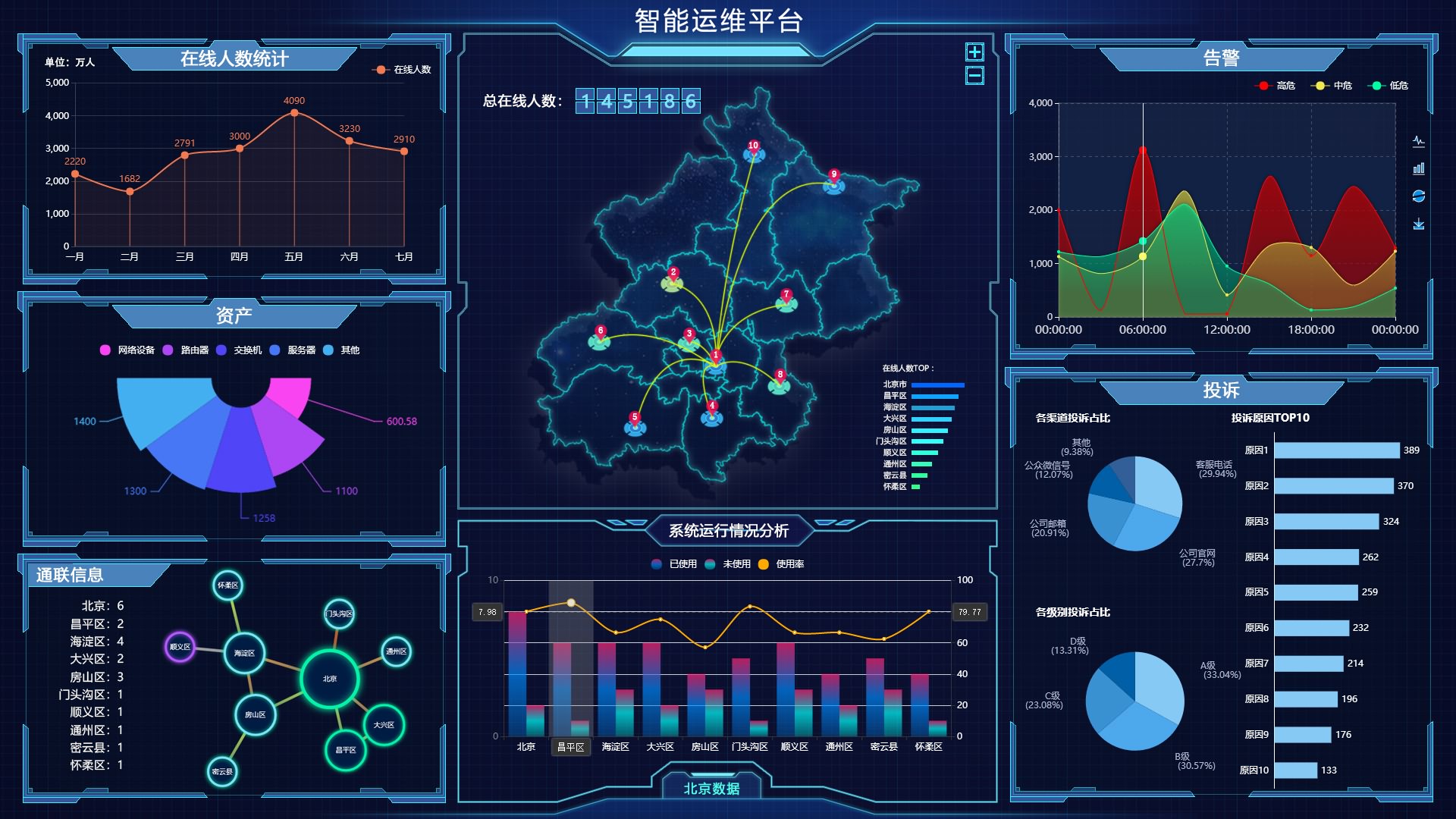
在生产环境中,风险无处不在,而传统的监控方式往往只能事后补救,难以做到提前预警。但如今,可视化预警系统正在改变这一切!它能够实时收集和分析生产数据,通过直观的图表和警报,让管理者第一时间…...

多模态大语言模型arxiv论文略读(112)
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文标题:Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文作者:Jea…...
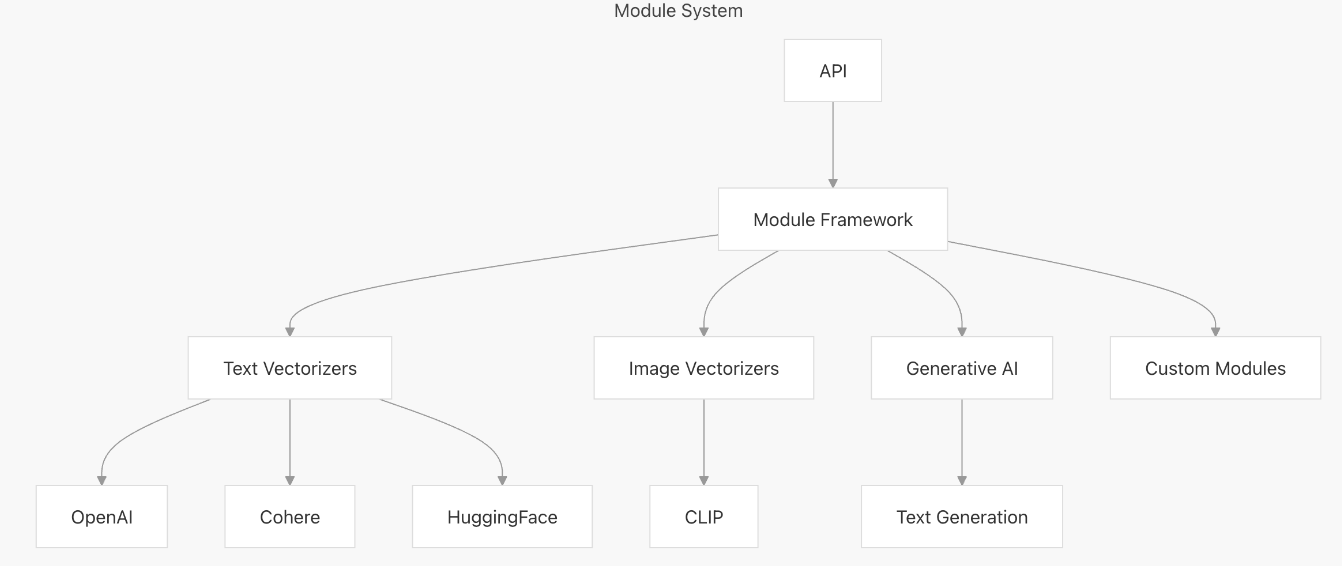
【向量库】Weaviate概述与架构解析
文章目录 一、什么是weaviate二、High-Level Architecture1. Core Components2. Storage Layer3. 组件交互流程 三、核心组件1. API Layer2. Schema Management3. Vector Indexing3.1. 查询原理3.2. 左侧:Search Process(搜索流程)3.3. 右侧&…...

PostgreSQL 对 IPv6 的支持情况
PostgreSQL 对 IPv6 的支持情况 PostgreSQL 全面支持 IPv6 网络协议,包括连接、存储和操作 IPv6 地址。以下是详细说明: 一、网络连接支持 1. 监听 IPv6 连接 在 postgresql.conf 中配置: listen_addresses 0.0.0.0,:: # 监听所有IPv4…...
)
python数据结构和算法(1)
数据结构和算法简介 数据结构:存储和组织数据的方式,决定了数据的存储方式和访问方式。 算法:解决问题的思维、步骤和方法。 程序 数据结构 算法 算法 算法的独立性 算法是独立存在的一种解决问题的方法和思想,对于算法而言&a…...

视觉slam--框架
视觉里程计的框架 传感器 VO--front end VO的缺点 后端--back end 后端对什么数据进行优化 利用什么数据进行优化的 后端是怎么进行优化的 回环检测 建图 建图是指构建地图的过程。 构建的地图是点云地图还是什么信息的地图? 建图并没有一个固定的形式和算法…...

统计按位或能得到最大值的子集数目
我们先来看题目描述: 给你一个整数数组 nums ,请你找出 nums 子集 按位或 可能得到的 最大值 ,并返回按位或能得到最大值的 不同非空子集的数目 。 如果数组 a 可以由数组 b 删除一些元素(或不删除)得到,…...

npm install 相关命令
npm install 相关命令 基本安装命令 # 安装 package.json 中列出的所有依赖 npm install npm i # 简写形式# 安装特定包 npm install <package-name># 安装特定版本 npm install <package-name><version>依赖类型选项 # 安装为生产依赖(默认&…...
)
Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现 3.1 生产者配置 在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件&#x…...

【学习记录】使用 Kali Linux 与 Hashcat 进行 WiFi 安全分析:合法的安全测试指南
文章目录 📌 前言🧰 一、前期准备✅ 安装 Kali Linux✅ 获取支持监听模式的无线网卡 🛠 二、使用 Kali Linux 进行 WiFi 安全测试步骤 1:插入无线网卡并确认识别步骤 2:开启监听模式步骤 3:扫描附近的 WiFi…...
)
后端下载限速(redis记录实时并发,bucket4j动态限速)
✅ 使用 Redis 记录 所有用户的实时并发下载数✅ 使用 Bucket4j 实现 全局下载速率限制(动态)✅ 支持 动态调整限速策略✅ 下载接口安全、稳定、可监控 🧩 整体架构概览 模块功能Redis存储全局并发数和带宽令牌桶状态Bucket4j Redis分布式限…...
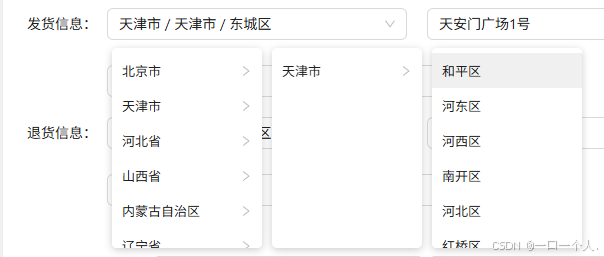
vue3 手动封装城市三级联动
要做的功能 示意图是这样的,因为后端给的数据结构 不足以使用ant-design组件 的联动查询组件 所以只能自己分装 组件 当然 这个数据后端给的不一样的情况下 可能组件内对应的 逻辑方式就不一样 毕竟是 三个 数组 省份 城市 区域 我直接粘贴组件代码了 <temp…...

Angular中Webpack与ngx-build-plus 浅学
Webpack 在 Angular 中的概念 Webpack 是一个模块打包工具,用于将多个模块和资源打包成一个或多个文件。在 Angular 项目中,Webpack 负责将 TypeScript、HTML、CSS 等文件打包成浏览器可以理解的 JavaScript 文件。Angular CLI 默认使用 Webpack 进行项目…...

大模型智能体核心技术:CoT与ReAct深度解析
**导读:**在当今AI技术快速发展的背景下,大模型的推理能力和可解释性成为业界关注的焦点。本文深入解析了两项核心技术:CoT(思维链)和ReAct(推理与行动),这两种方法正在重新定义大模…...

信息系统分析与设计复习
2024试卷 单选题(20) 1、在一个聊天系统(类似ChatGPT)中,属于控制类的是()。 A. 话语者类 B.聊天文字输入界面类 C. 聊天主题辨别类 D. 聊天历史类 解析 B-C-E备选架构中分析类分为边界类、控制类和实体类。 边界…...
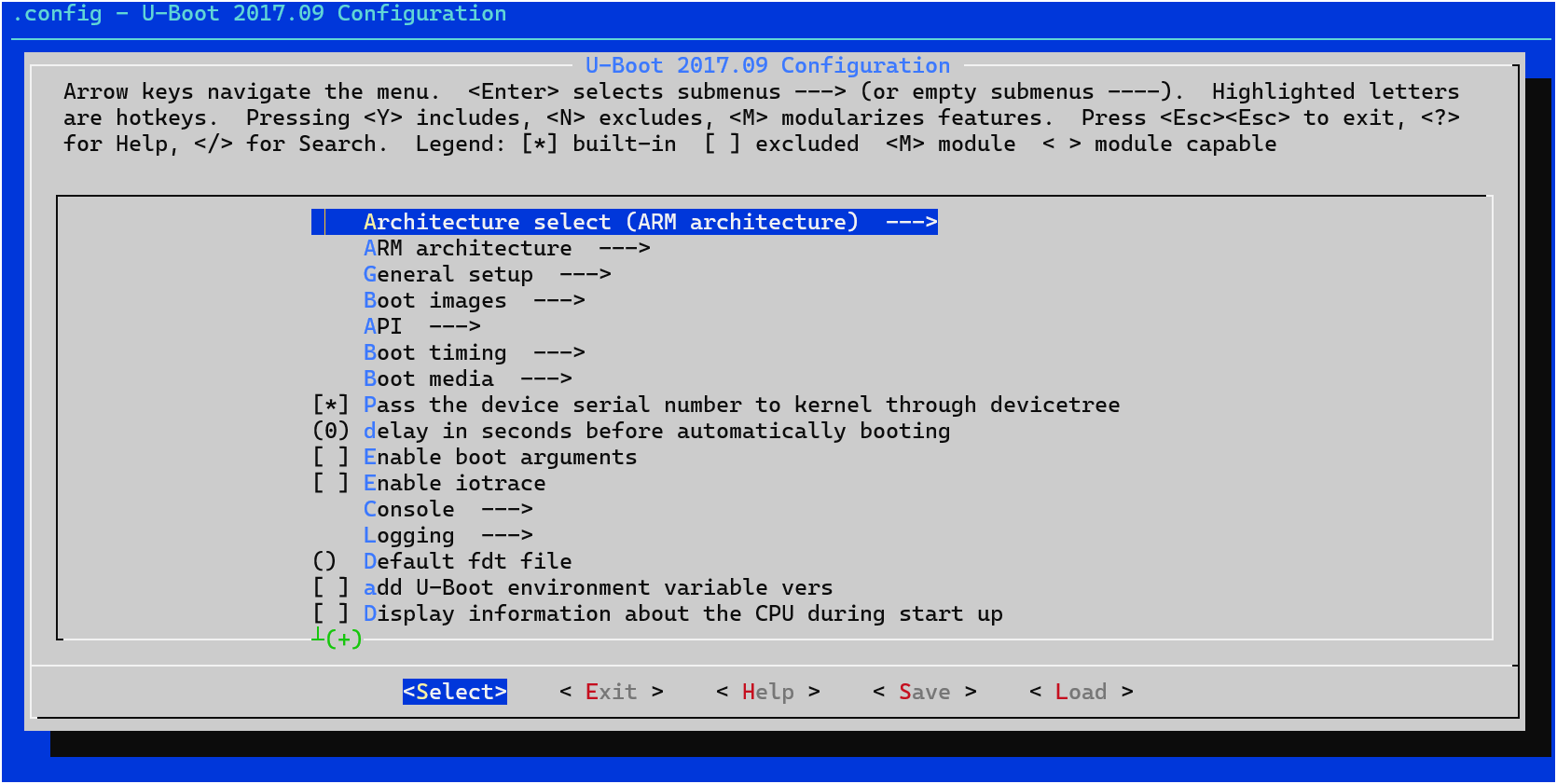
Linux【5】-----编译和烧写Linux系统镜像(RK3568)
参考:讯为 1、文件系统 不同的文件系统组成了:debian、ubuntu、buildroot、qt等系统 每个文件系统的uboot和kernel是一样的 2、源码目录介绍 目录 3、正式编译 编译脚本build.sh 帮助内容如下: Available options: uboot …...

记一次spark在docker本地启动报错
1,背景 在docker中部署spark服务和调用spark服务的微服务,微服务之间通过fegin调用 2,问题,docker容器中服务器来后,注册中心都有,调用服务也正常,但是调用spark启动任务后报错,报错…...

【向量库】Weaviate 搜索与索引技术:从基础概念到性能优化
文章目录 零、概述一、搜索技术分类1. 向量搜索:捕捉语义的智能检索2. 关键字搜索:精确匹配的传统方案3. 混合搜索:语义与精确的双重保障 二、向量检索技术分类1. HNSW索引:大规模数据的高效引擎2. Flat索引:小规模数据…...

ABB馈线保护 REJ601 BD446NN1XG
配电网基本量程数字继电器 REJ601是一种专用馈线保护继电器,用于保护一次和二次配电网络中的公用事业和工业电力系统。该继电器在一个单元中提供了保护和监控功能的优化组合,具有同类产品中最佳的性能和可用性。 REJ601是一种专用馈线保护继电器…...
Heygem50系显卡合成的视频声音杂音模糊解决方案
如果你在使用50系显卡有杂音的情况,可能还是官方适配问题,可以使用以下方案进行解决: 方案一:剪映替换音色(简单适合普通玩家) 使用剪映换音色即可,口型还是对上的,没有剪映vip的&…...
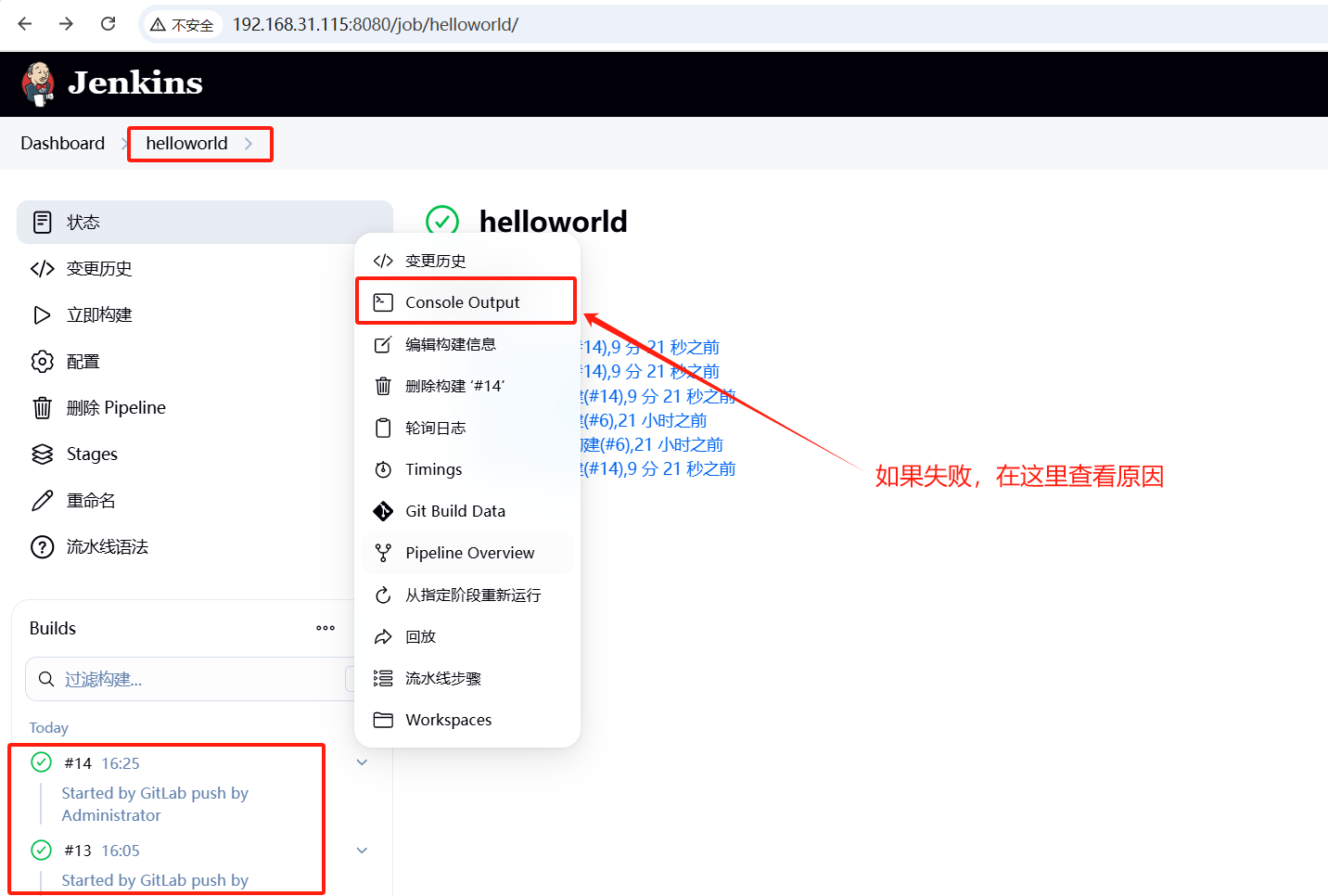
Gitlab + Jenkins 实现 CICD
CICD 是持续集成(Continuous Integration, CI)和持续交付/部署(Continuous Delivery/Deployment, CD)的缩写,是现代软件开发中的一种自动化流程实践。下面介绍 Web 项目如何在代码提交到 Gitlab 后,自动发布…...
无头浏览器技术:Python爬虫如何精准模拟搜索点击
1. 无头浏览器技术概述 1.1 什么是无头浏览器? 无头浏览器是一种没有图形用户界面(GUI)的浏览器,它通过程序控制浏览器内核(如Chromium、Firefox)执行页面加载、JavaScript渲染、表单提交等操作。由于不渲…...
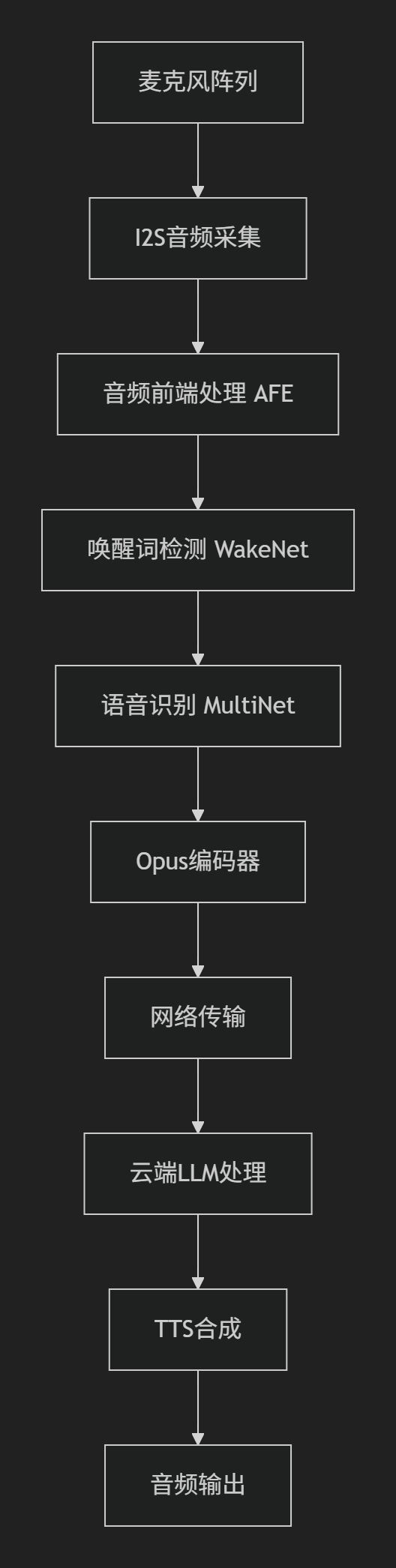
SDU棋界精灵——硬件程序ESP32实现opus编码
一、 音频处理框架 该项目基于Espressif的音频处理框架构建,核心组件包括 ESP-ADF 和 ESP-SR,以下是完整的音频处理框架实现细节: 1.核心组件 (1) 音频前端处理 (AFE - Audio Front-End) main/components/audio_pipeline/afe_processor.c功能: 声学回声…...
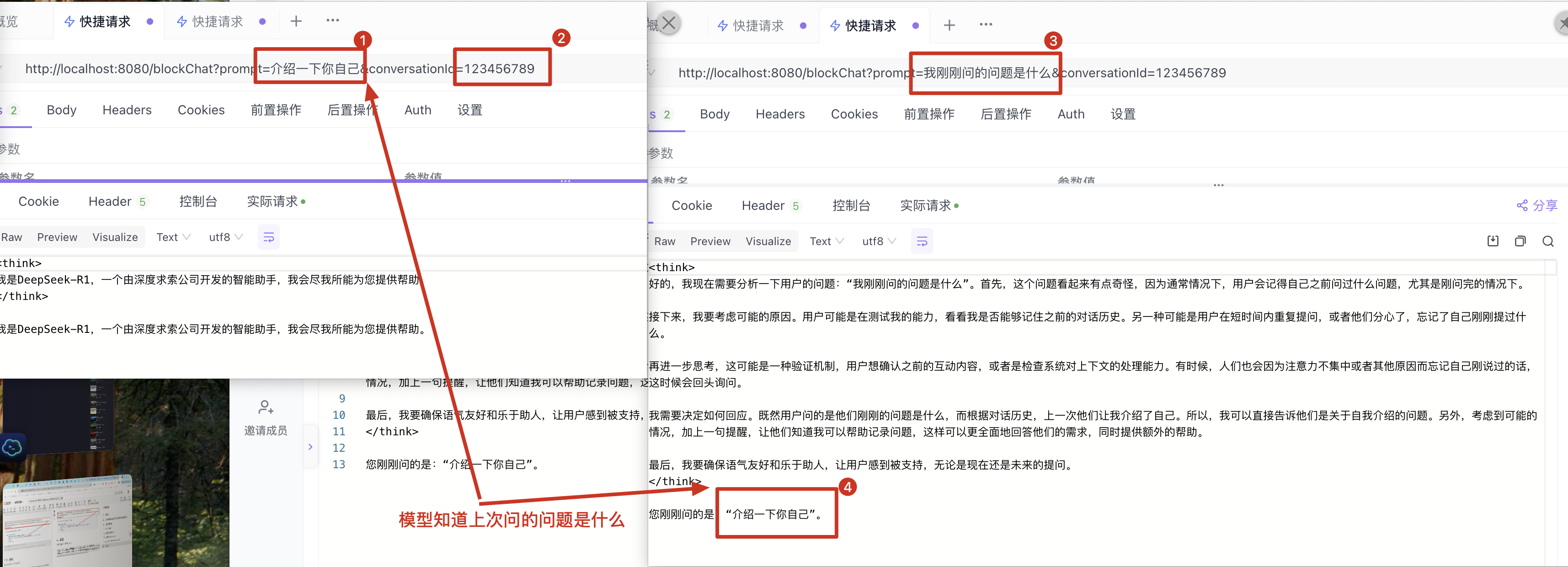
Spring AI中使用ChatMemory实现会话记忆功能
文章目录 1、需求2、ChatMemory中消息的存储位置3、实现步骤1、引入依赖2、配置Spring AI3、配置chatmemory4、java层传递conversaionId 4、验证5、完整代码6、参考文档 1、需求 我们知道大型语言模型 (LLM) 是无状态的,这就意味着他们不会保…...
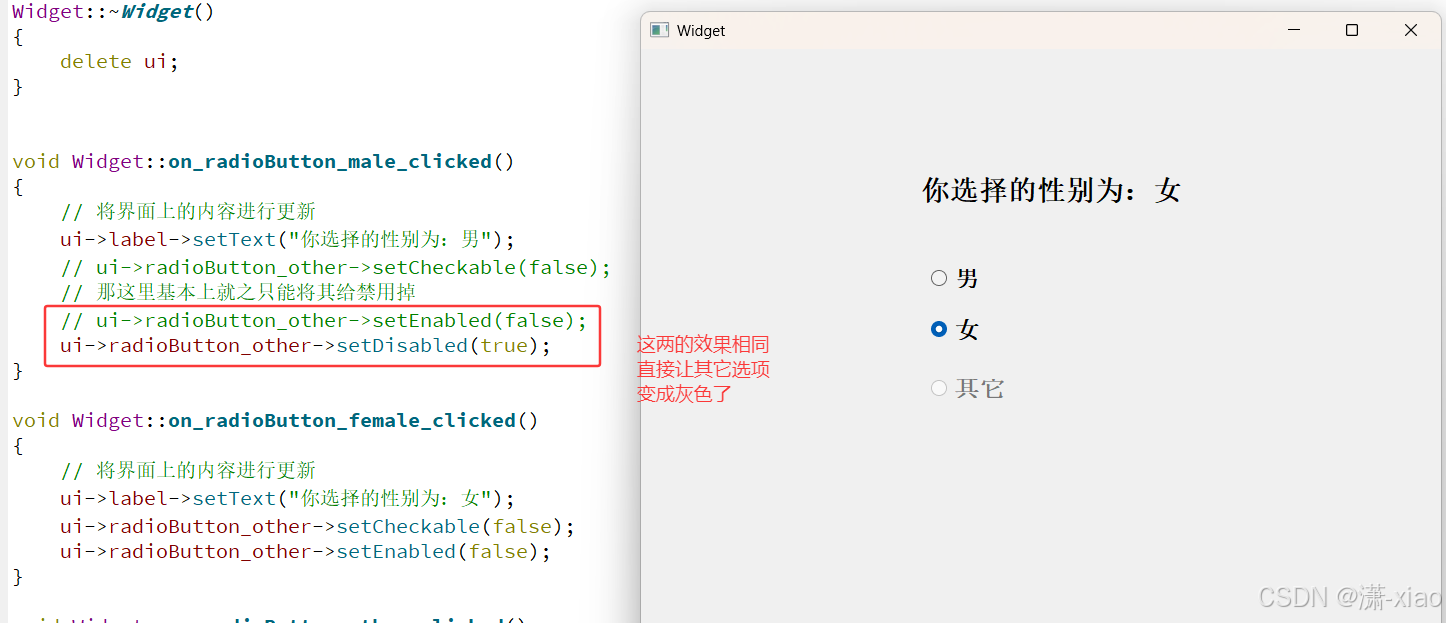
Qt 按钮类控件(Push Button 与 Radio Button)(1)
文章目录 Push Button前提概要API接口给按钮添加图标给按钮添加快捷键 Radio ButtonAPI接口性别选择 Push Button(鼠标点击不放连续移动快捷键) Radio Button Push Button 前提概要 1. 之前文章中所提到的各种跟QWidget有关的各种属性/函数/方法&#…...