Python实现性能测试(locust)
一、安装locust
pip install locust -- 安装(在pycharm里面安装或cmd命令行安装都可)
locust -V -- 查看版本,显示了就证明安装成功了
或者直接在Pycharm中安装locust:
搜索locust并点击安装,其他的第三方包也可以通过这种方式

二、locust介绍
Locust 是一种易于使用、可编写脚本且可扩展的性能测试工具。并且有一个用户友好的 Web 界面,可以实时显示测试进度。甚至可以在测试运行时更改负载。它也可以在没有 UI 的情况下运行,使其易于用于 CI/CD 测试。
Locust 使运行分布在多台机器上的负载测试变得容易。Locust 基于事件(gevent),因此可以在一台计算机上支持数千个并发用户。与许多其他基于事件的应用程序相比,它不使用回调。相反,它通过gevent使用轻量级进程。并发访问站点的每个Locust(蝗虫)实际上都在其自己的进程中运行(Greenlet)。这使用户可以在Python中编写非常有表现力的场景,而不必使用回调或其他机制。
三、脚本
1.方式一(直接在HttpUser中定义任务)
from locust import HttpUser, task, constant
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(1)
@task
def login_test(self):
url = '/api/user/login'
data = {"userName":"xuyang@test.ai","password":"xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, data=data, headers=headers, name='login登录')
HttpUser:控制用户发请求的频率、用户的思考时间、设置主机的IP地址、也可以定义任务
@task:@task用来标记哪个方法是任务,什么任务,我要做性能测试执行哪个接口
host:被测系统,你要发送请求到哪个服务器
wait_time:每次请求的间隔、停顿时间、思考时间
constant:为固定的思考时间,这里可以简单理解为固定定时器(只是wait_time的其中一种等待时间的方式,其它的可以自己研究一下)
描述:
1.创建一个User类FalshUser, 继承HttpUser,然后定义主机IP地址、思考时间;
2.在类下面编写一个测试接口,跟我们使用request类似,有个别区别;
3.用@task的方式进行定义任务,这个为什么要用task上面解释说了
4.接口方法内需要注意的点:
1)url只需要写路径即可,请求时自动拼接host;
2)发送请求的时候要用self.client.request去请求,并且增加method,和name两个入参,method就是请求方法、name就是接口名称;
3)self.client.request 它的发送请求跟我们常用的接口测试的request库非常类似,因为底层封装的就是request库;
运行描述:
打开你的Terminal,然后cd到你写的测试文件目录下,.py的文件;
运行命令:locust -f 测试文件.py;
回车运行,之后如果出现第一张图显示的那样,就证明运行成功了;
打开你的浏览器输入http://localhost:8089,回车就会打开第二张图显示的GUI的locust页面

locust页面字段解释:
Number of users to simulate:设置模拟的用户总数;
Hatch rate (users spawned/second):每秒启动的虚拟用户数;
host:就是你脚本内写的被测系统地址,打开页面后自动填入的;
Start swarming:开始运行性能测试;
输入模拟的用户总数、输入每秒启动的虚拟用户数,点击Start swarming即可运行
运行结果:


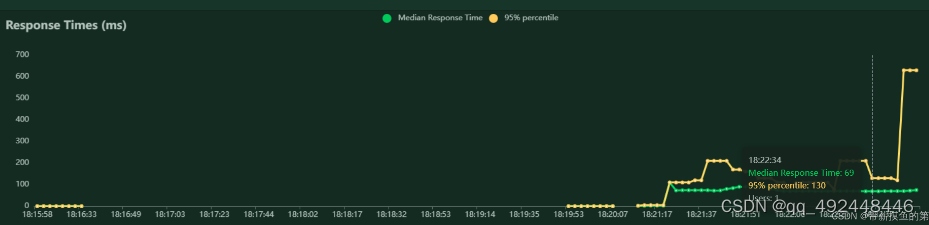
大概就是这样,可以看类似jmeter聚合报告一样的表格,和tps监测、IO监测、可以导出各种类型的测试报告
2.方式二(写在模块内
from locust import HttpUser, task, constant
@task
def my_self_api(user):
url = '/api/user/login'
data = {"userName":"xuyang@test.ai","password":"xy123456"}
headers = {"Content-Type": "application/json"}
# 可以通过user.去调用client
user.client.request(method='POST', url=url, data=data, headers=headers, name='login登录')
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/' # 被测系统的地址
wait_time = constant(1) # 每次请求的间隔、停顿时间、LR里面叫做思考时间(constant为固定的思考时间)
tasks = [my_self_api]
描述:
跟方式一代码类似,把User类和任务方法剥离,单独写开,用户操作用FlashUser管理,方法单独管理;
其中任务类剥离后,需要传入一个user字段,我们需要在任务函数里面来通过HttpUser传入的实例self->user来进行调用请求,需要注意我们任务函数传入的这个user,这个user就是FlashUser对象本身,就是FlashUser的一个实例,user指的就是self,这个时候我们就可以通过user.client来请求接口;
tasks解释:定义测试的范围,而测试方法的定义,可以放在测试类的外部,也就说可以用包去管理测试的方法,而真正要测试的时候,引入业务包,然后配置tasks即可,所以[ ]内我传了我写的任务名称,就是说我要执行这个任务,不然User不知道执行谁;
运行方式参考方式一GUI模式运行
3.方式三(把任务写在任务集里面)
from locust import HttpUser, constant, task, TaskSet
class TaskApi(TaskSet):
@task(1)
def login1(self):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, json=data, headers=headers, name='login-登录接口1')
@task(2)
def login2(self):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
self.client.request(method='POST', url=url, json=data, headers=headers, name='login-登录接口2')
class FlashUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(2)
tasks = [TaskApi]
描述:
TaskSet解释:任务集,所谓的任务集,我理解的就是我有很多的性能测试任务/接口,那么我可以把这些接口写在一个类里面,和User类剥离出来,用User类来控制用户数和条件去进行执行;
方式三我把任务方法做了升级,写了一个TaskApi类,通过继承TaskSet来管理我的任务,这个类我主要写一些测试任务,每个需要执行性能测试的任务用@task标记;
那么代码怎么知道哪个是任务集呢?用TaskSet,需要作为任务集的类TaskApi,继承TaskSet,这样User类就知道,这个是任务集的类;
@task(1)、@task(2)里面的数字是什么意思?@task用来标记哪个方法是任务,括号里面的数字,我理解的是任务权重,比如:1、2,那么可以理解为如果用户有9个,那么@task(1)执行3个,@task(2)执行6个;
关于self.client:当我们在任务集的类中去写发送请求的时候,会发现self.后会出现user,这个user就是User类的实例,也就是说User类让哪个任务去执行,它就会把它自己的对象传给任务本身,当然你可以不写self.user, 直接self.client,当我们写了self.client后,ctrl+鼠标左键点击client,进去client底层方法会发现,它底层封装的是self.user.client;
注意:以上三种方式在执行性能测试的任务的时候,凡是带@task的标签的任务都是是并行运行的、是无序的,而不是按照代码逻辑从上往下执行
4.方式四(SequentialTaskSet)
SequentialTaskSet:如果需要有序的,我们可以继承该方法来进行创建任务
"""按顺序运行"""
class SeqSupTech(SequentialTaskSet):
url = '/api/user/login'
data = {"userName": "xuyang@test.ai", "password": "xy123456"}
headers = {"Content-Type": "application/json"}
@task(1)
def login1(self):
self.client.request(method="POST", url=self.url, json=self.data, headers=self.headers, name='登录接口1')
@task(5)
def login2(self):
self.client.request(method="POST", url=self.url, json=self.data, headers=self.headers, name='登录接口2')
class RequestUser(HttpUser):
host = 'http://127.0.0.1:8080/'
wait_time = constant(2)
tasks = [SeqSupTech]
描述:
只需要在创建任务集的类的时候继承SequentialTaskSet,那么这个任务集在运行的时候就会按照上下组合的顺序根据权重进行执行,比如上面这段代码的@task(1)和@task(5),代表先执行login1,再执行login2,循环执行;
四、非GUI模式运行并生成Html报告
命令:
locust -f denom_chain_query.py --headless -u 1 -r 1 -t 1m --html locust_report.html
-f locust_test.py //代表执行哪一个压测脚本
--headless //代表无界面执行
-u 100 //模拟100个用户操作
-r 100 //每秒用户增长数
-t 10m //压测10分钟
--html report.html //html结果输出的文件路径名称,无需提前创建,自动生成
运行:
Html报告:


最后建议接口传参的name用英文的,不要汉字,容易乱码,这个问题有解决的,可以在评论区讲下,我也学习一下
相关文章:
Python实现性能测试(locust)
一、安装locustpip install locust -- 安装(在pycharm里面安装或cmd命令行安装都可)locust -V -- 查看版本,显示了就证明安装成功了或者直接在Pycharm中安装locust:搜索locust并点击安装,其他的第三方包也可以通过这种方式二、loc…...

【数论】试除法判断质数,分解质因数,筛质数
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 现已更新完KMP算法、排序模板,之…...
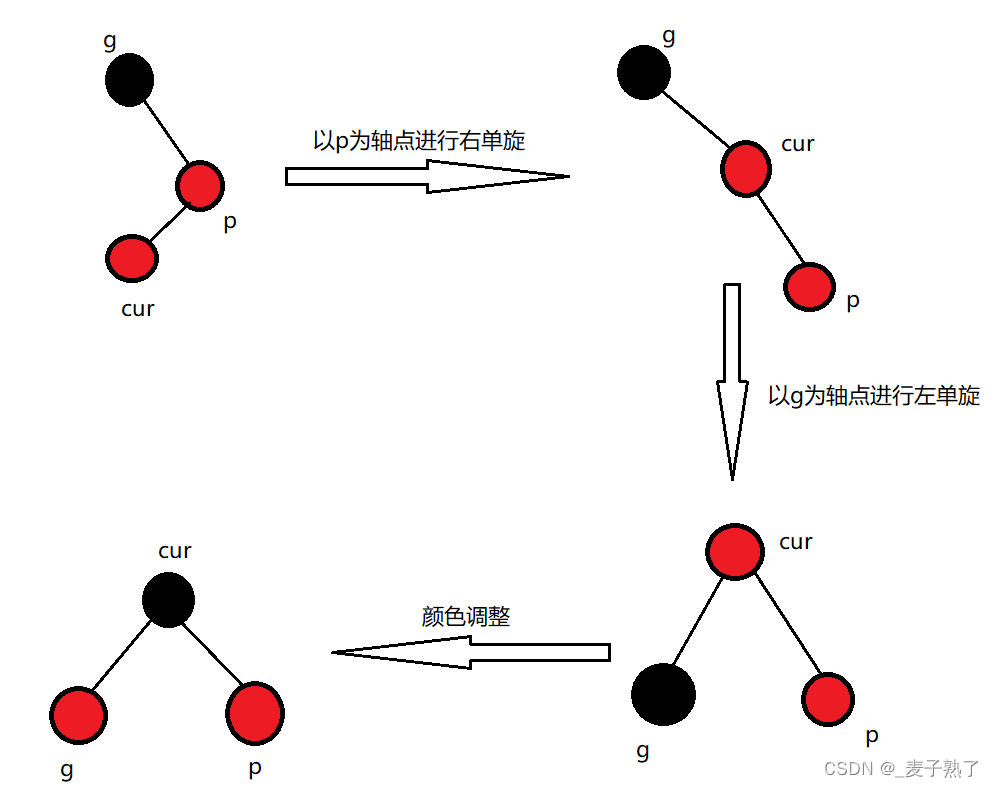
【C++】红黑树
文章目录红黑树的概念红黑树的性质特征红黑树结点的定义红黑树的插入操作情况1情况2情况3特殊情况代码实现红黑树的验证红黑树的删除红黑树和AVL树的比较红黑树的应用红黑树的概念 红黑树,是一种二叉搜索树,但是每一个结点都增加一个存储位表示结点的颜…...
【剧前爆米花--爪哇岛寻宝】进程的调度以及并发和并行,以及PCB中属性的详解。
作者:困了电视剧 专栏:《JavaEE初阶》 文章分布:这是关于进程调度、并发并行以及相关属性详解的文章,我会在之后文章中更新有关线程的相关知识,并将其与进程进行对比,希望对你有所帮助。 目录 什么是进程/…...
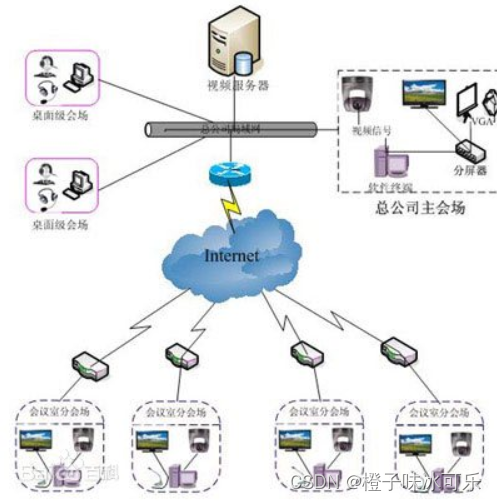
网络的瓶颈效应
python从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129328397?spm1001.2014.3001.5501 ❤ 网络的瓶颈效应 网络瓶颈,指的是影响网络传输性能及稳定性的一些相关因素,如网络拓扑结构,网线࿰…...
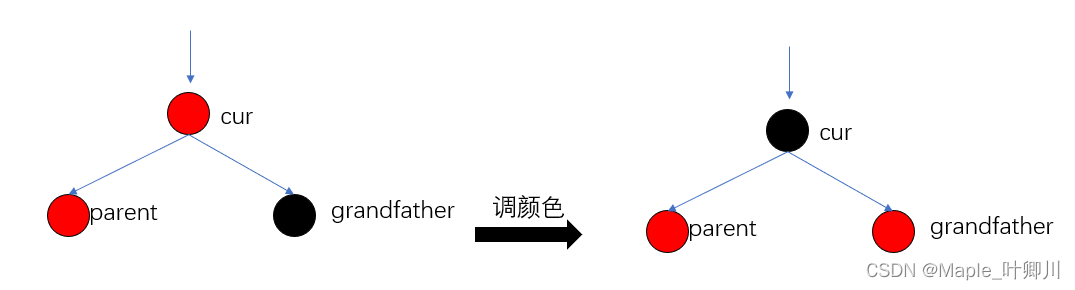
【C++进阶】四、红黑树(三)
目录 一、红黑树的概念 二、红黑树的性质 三、红黑树节点的定义 四、红黑树的插入 五、红黑树的验证 六、红黑树与AVL树的比较 七、完整代码 一、红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可…...
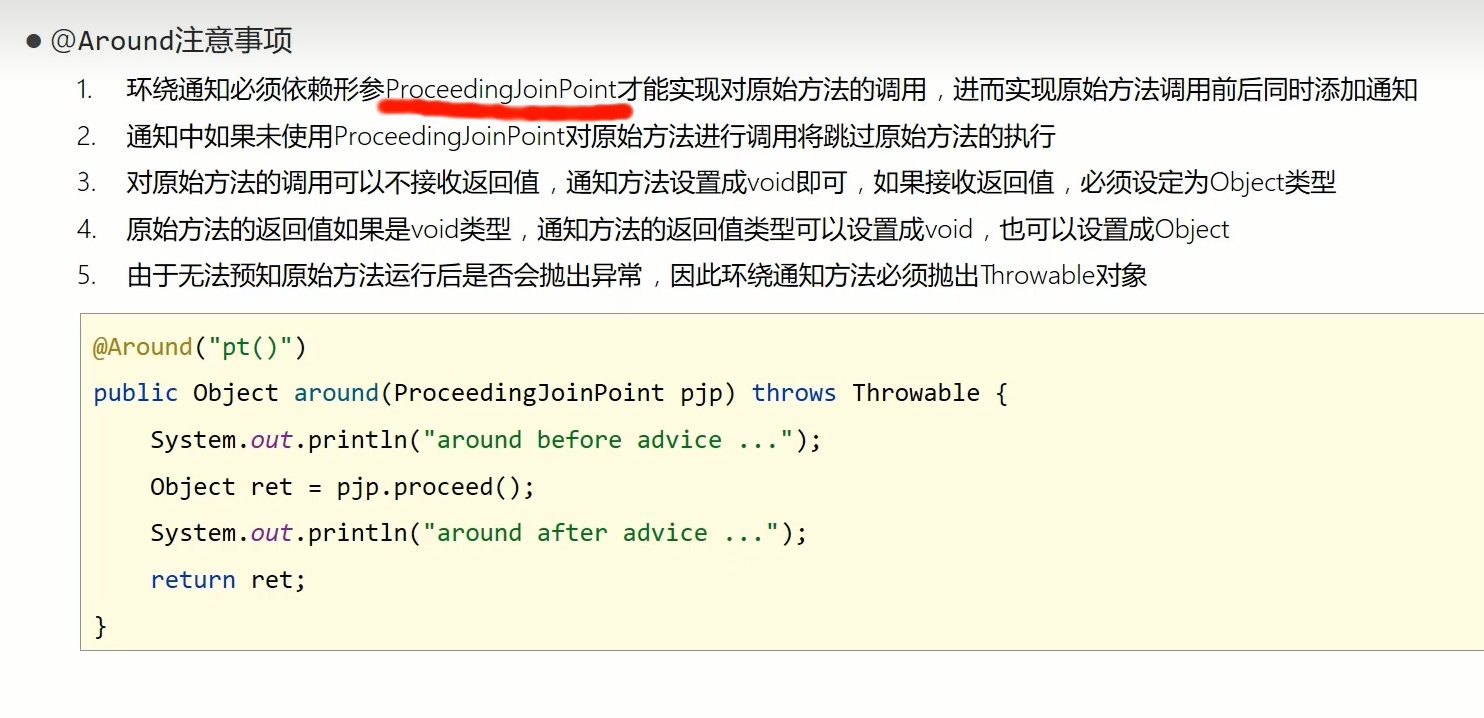
Spring——AOP切入点表达式和AOP通知类型
切入点:要进行增强的方法 切入点表达式:要进行增强的方法的描述式 第一种方法的本质是基于接口实现的动态代理(jdk) 第二种是基于cglib实现的动态代理 AOP切入点表达式 而需要加载多个切入点时,不可能每个切入点都写一个切入点表达式 例子 下面的代理描述的是匹配…...

Hadoop学习:Yarn
1.YARN介绍 一个通用的资源管理系统和调度平台 YARN不分配磁盘,由HDFS分配 相当于一个分布式的操作系统平台,为上层MR等计算程序提供运算所需要的资源(内存、CPU等) 2.YARN三大组件 不要忘记AppMaster,他是程序内部…...

Spring Data JPA
文章目录一、Spring Data基础概念二、JPA与JDBC的相同与不同之处三、Hibernate & JPA快速搭建1.添加依赖2.实体类3.hibernate的配置文件 ——hibernate.cfg.xml四、测试——基于hibernate的持久化(单独使用)五、测试——基于JPA的持久化(…...

java List报错Method threw ‘java.lang.UnsupportedOperationException‘ exception. 解决
问题描述:List使用Arrays.asList()初始化后,再add对象时报错:Method threw java.lang.UnsupportedOperationException exception.错误示例如下: List<ExportListVO.ExportSheet> sheetVOList Arrays.asList(new ExportList…...
数据结构-用栈实现队列
前言: 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾 int pop() 从队列的开头移除并返回元素 int…...

第十四章 从 Windows 客户端控制 IRIS
文章目录第十四章 从 Windows 客户端控制 IRISIRISctlGetDirsSyntaxReturn ValuesIRISctlConfigStatusSyntaxReturn ValuesIRISctlControlSyntaxReturn Values第十四章 从 Windows 客户端控制 IRIS IRIS 为 Windows 客户端程序提供了一种机制来控制 IRIS 配置并启动 IRIS 进程…...
数据结构---双链表
专栏:数据结构 个人主页:HaiFan. 专栏简介:从零开始,数据结构!! 双链表前言双链表各接口的实现为要插入的值开辟一块空间BuyLN初始化LNInit和销毁LNDestory打印链表中的值LNPrint尾插LNPushBack和尾删LNPop…...

Windows 环境安装Scala详情
为了进一步学习Spark,必须先学习Scala 编程语言。首先开始Scala 环境搭建。温馨提示:本文是基于Windows 11 安装Scala 2.13.1 版本第一步:确保本机已经正确安装JDK1.8 环境第二步:Scala 官网下载我们所属scala版本文件。Scala 官网…...
C++ Qt自建网页浏览器
C Qt自建网页浏览器如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<C Qt自建网页浏览器>>编写代码,代码整洁,规则,易读。 学习与应用推荐首选。文…...
Flink从入门到精通系列(四)
5、DataStream API(基础篇) Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。…...
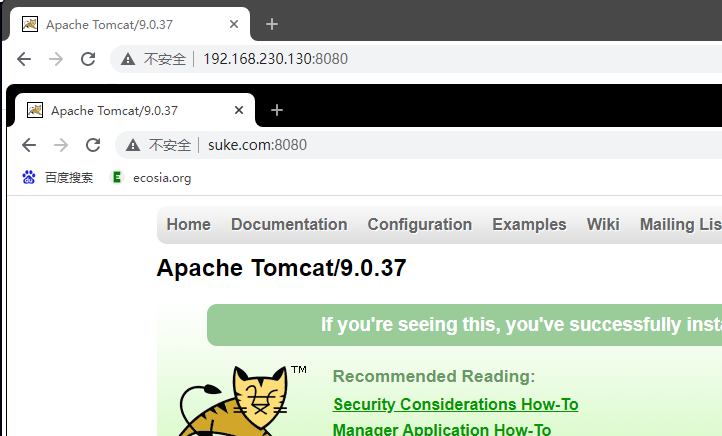
Nginx 配置实例-反向代理案例一
实现效果:使用nginx反向代理,访问 www.suke.com 直接跳转到本机地址127.0.0.1:8080 一、准备工作 Centos7 安装 Nginxhttps://liush.blog.csdn.net/article/details/125027693 1. 启动一个 tomcat Centos7安装JDK1.8https://liush.blog.csdn.net/arti…...

为什么北欧的顶级程序员数量远超中国?
说起北欧,很多人会想到寒冷的冬天,漫长的极夜,童话王国和圣诞老人,但是如果我罗列下诞生于北欧的计算机技术,恐怕你会惊掉下巴。Linux:世界上最流行的开源操作系统,最早的内核由Linus Torvalds开…...
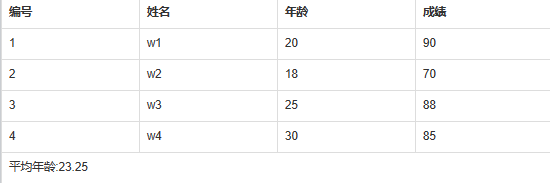
vuex getters的作用和使用(求平均年龄),以及辅助函数mapGetters
getters作用:派生状态数据mapGetters作用:映射getters中的数据使用:方法名自定义,系统自动注入参数:state,每一个方法中必须有return,其return的结果被该方法名所接收。在state中声明数据listst…...
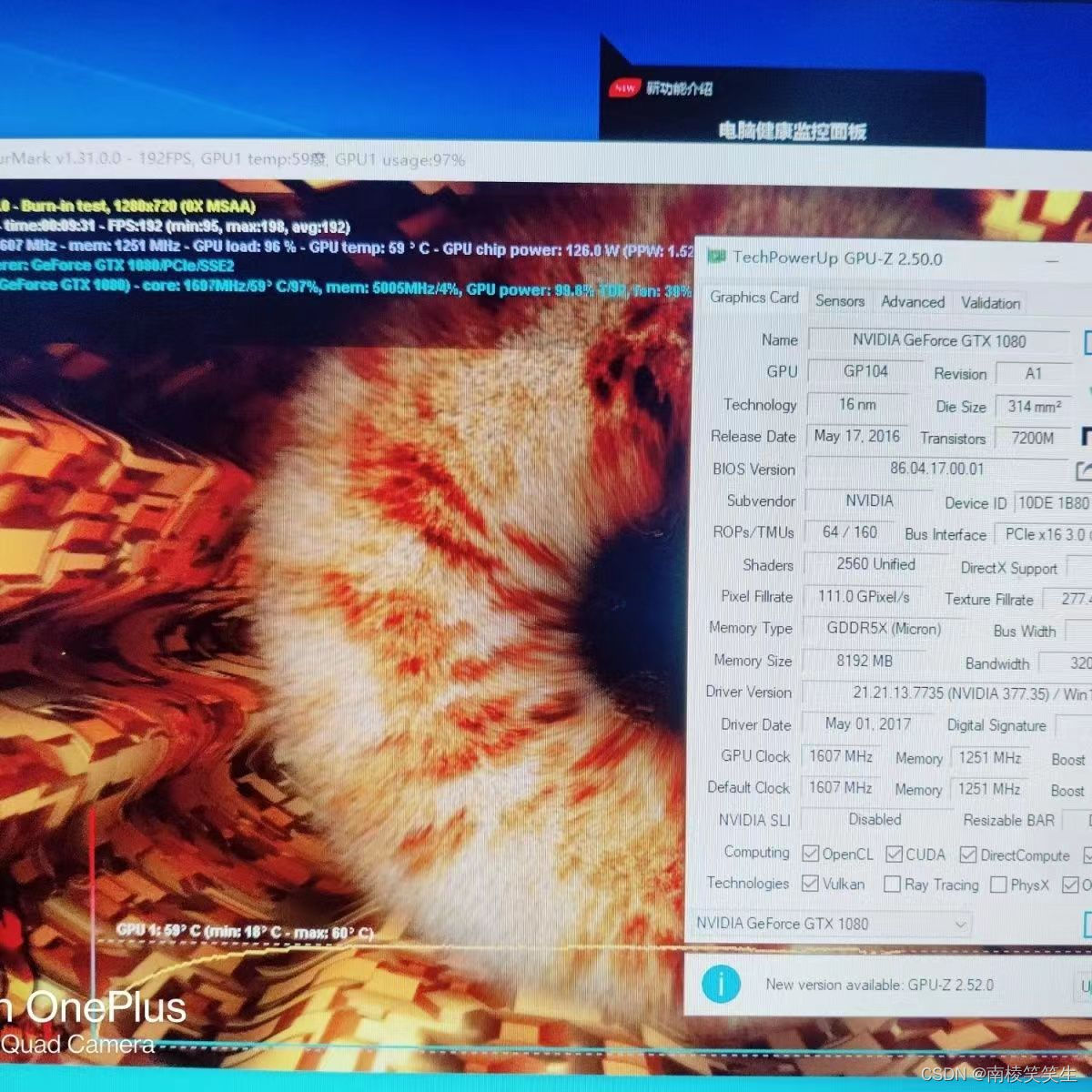
20230311给Ubuntu18.04下的GTX1080M安装驱动
20230311给Ubuntu18.04下的GTX1080M安装驱动 2023/3/11 12:50 2. 安装GTX1080驱动 安装 Nvidia 驱动 367.27 sudo add-apt-repository ppa:graphics-drivers/ppa 第一次运行出现如下的警告: Fresh drivers from upstream, currently shipping Nvidia. ## Curren…...

PheroPath:自定义代谢通路构建与可视化工具在组学数据分析中的应用
1. 项目概述与核心价值最近在生物信息学和计算生物学领域,一个名为“PheroPath”的项目引起了我的注意。这个项目由用户starpig1129托管,从名字上就能嗅到一丝“信息素”和“路径”结合的味道。作为一名长期在组学数据分析、特别是代谢通路研究一线摸爬滚…...

别再被FFmpeg里的12bpp搞懵了!手把手教你理解YUV420sp与BPP的关系
别再被FFmpeg里的12bpp搞懵了!手把手教你理解YUV420sp与BPP的关系 第一次在FFmpeg文档里看到"12bpp"这个描述时,我盯着屏幕愣了半天——RGB24格式不是8bpp吗?YUV420不是应该更节省空间吗?怎么反而变成了12bpp࿱…...

如何解锁数字化制造的数据瓶颈:stltostp的轻量级STL转STEP解决方案
如何解锁数字化制造的数据瓶颈:stltostp的轻量级STL转STEP解决方案 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0转型的浪潮中,数据格式的互操作…...

慕尼黑电子展:洞察汽车电子、工业物联网与功率半导体技术趋势
1. 从慕尼黑看全球电子产业:一场技术与商业的“双向奔赴”又到了双数年的十一月,全球电子工程师和产业领袖的目光,不约而同地再次聚焦于德国慕尼黑。没错,Electronica——这个被誉为全球电子元器件行业“晴雨表”的顶级盛会&#…...

Taotoken官方价折扣活动对于高频用户的实际成本影响分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方价折扣活动对于高频用户的实际成本影响分析 1. 理解Taotoken的计费模式 Taotoken平台采用按Token消耗量计费的模式。…...

开源情报工具Openeir:自动化资产发现与关联分析实战指南
1. 项目概述:一个开源情报(OSINT)工具的诞生与使命 在信息爆炸的时代,数据本身不再是稀缺品,如何从海量、异构、碎片化的公开信息中,精准、高效地提取出有价值的情报,才是真正的挑战。无论是安全…...

如何选择AI写论文工具?
本科生、研究生写论文常陷文献难找、逻辑混乱、查重超标、AI幻觉等困境,盲目用AI工具还易触碰学术诚信红线。本文结合学术规范、查重要求、功能适配与数据安全,实测AI论文工具,帮你精准选对合规高效的写作助手。一、先守学术合规底线…...

天气图片分类模型:基于迁移学习与GPU资源优化
天气图片分类模型:基于迁移学习与GPU资源优化 1. 引言 天气识别在自动驾驶、户外监控、气象服务等领域具有重要应用价值。传统方法依赖于手工设计的特征(如纹理、颜色直方图),鲁棒性不足。深度学习尤其是卷积神经网络(CNN)能够自动从图像中学习层次化特征,显著提升分类…...

AI写作净化器:识别与消除AI文本痕迹的实用指南
1. 项目概述:为什么我们需要一个“AI写作净化器”? 如果你和我一样,每天都要和AI助手打交道,无论是用它写邮件、生成报告,还是草拟技术文档,那你一定对那种“AI味儿”深有体会。那种感觉就像喝了一杯过度调…...

计算机视觉数据集选型实战指南:从COCO到Roboflow的工程决策框架
1. 这份清单不是“资料库目录”,而是计算机视觉工程师的实战弹药箱如果你正在训练一个能识别工业零件表面微小划痕的模型,却在COCO数据集上反复调参;或者你刚拿到一批医院提供的CT影像,第一反应是去Kaggle搜“medical image datas…...