关于scrapy模块中setting.py文件的介绍
作用
在Scrapy框架中,settings.py 文件起着非常重要的作用,它用于配置和控制整个Scrapy爬虫项目的行为、性能和功能。
setting.py文件的介绍
# Scrapy settings for haodaifu project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html# 设置爬虫的名称
BOT_NAME = "spidername"# 指定包含的爬虫代码的模块
SPIDER_MODULES = ["spidername.spiders"]
NEWSPIDER_MODULE = "spidername.spiders"# 设置用户代理,用于模拟浏览器或特定的爬虫身份
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"# 配置爬虫是否遵循robots.txt柜子
# Obey robots.txt rules
ROBOTSTXT_OBEY = False# 控制并发请求的数量(默认为16)
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 64# 设置下载延迟,控制请求之间的时间间隔,以避免对目标服务器造成过大负载
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3# 配置每个域名的最大并发请求数
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16# 设置每个IP地址的最大并发请求数
CONCURRENT_REQUESTS_PER_IP = 16# 启用或禁用cookies
# Disable cookies (enabled by default)
COOKIES_ENABLED = False# 启用或禁用Telnet控制台
# Disable Telnet Console (enabled by default)
TELNETCONSOLE_ENABLED = False# 默认的请求头
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Referer': 'https://www.xxx.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}# 启用或禁用爬虫中间件
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# 爬虫中间件及其顺序
SPIDER_MIDDLEWARES = {"spidername.middlewares.SpidernameSpiderMiddleware": 543,
}# 启用或禁用下载中间件
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# 下载中间件及其顺序
DOWNLOADER_MIDDLEWARES = {"spidername.middlewares.SpidernameDownloaderMiddleware": 543,
}# 启用和配置scrapy扩展
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
EXTENSIONS = {"scrapy.extensions.telnet.TelnetConsole": None,
}# 启用或禁用项目管道
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 项目管道
ITEM_PIPELINES = {"spidername.pipelines.spidernamePipeline": 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# 是否启用自动限速
AUTOTHROTTLE_ENABLED = True# 初始化下载延迟(秒)
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5# 最大下载延迟(秒)
# The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to
# each remote server
# scrapy 的目标并发请求数
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# Enable showing throttling stats for every response received:
# 是否启用自动限速调试模式
AUTOTHROTTLE_DEBUG = False# 启用和配置http缓存
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# 是否启用HTTP缓存
HTTPCACHE_ENABLED = True# 缓存超时时间(秒)
HTTPCACHE_EXPIRATION_SECS = 0# 缓存目录
HTTPCACHE_DIR = "httpcache"# 忽略缓存的HTTP状态码列表
HTTPCACHE_IGNORE_HTTP_CODES = []HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"# 输出feed的编码
FEED_EXPORT_ENCODING = "utf-8"
相关文章:

关于scrapy模块中setting.py文件的介绍
作用 在Scrapy框架中,settings.py 文件起着非常重要的作用,它用于配置和控制整个Scrapy爬虫项目的行为、性能和功能。 setting.py文件的介绍 # Scrapy settings for haodaifu project # # For simplicity, this file contains only settings consider…...

laravel Blade 指令的趣味性
首先,我们通过几个要点来解释 Blade 引擎的工作原理。 您选择一个 Blade 模板进行渲染。引擎使用一系列正则表达式来解析和编译模板。该引擎生成一个普通的 PHP 文件并将其写入磁盘(以便将其缓存以供将来渲染)。包含 PHP 文件并使用输出缓冲…...
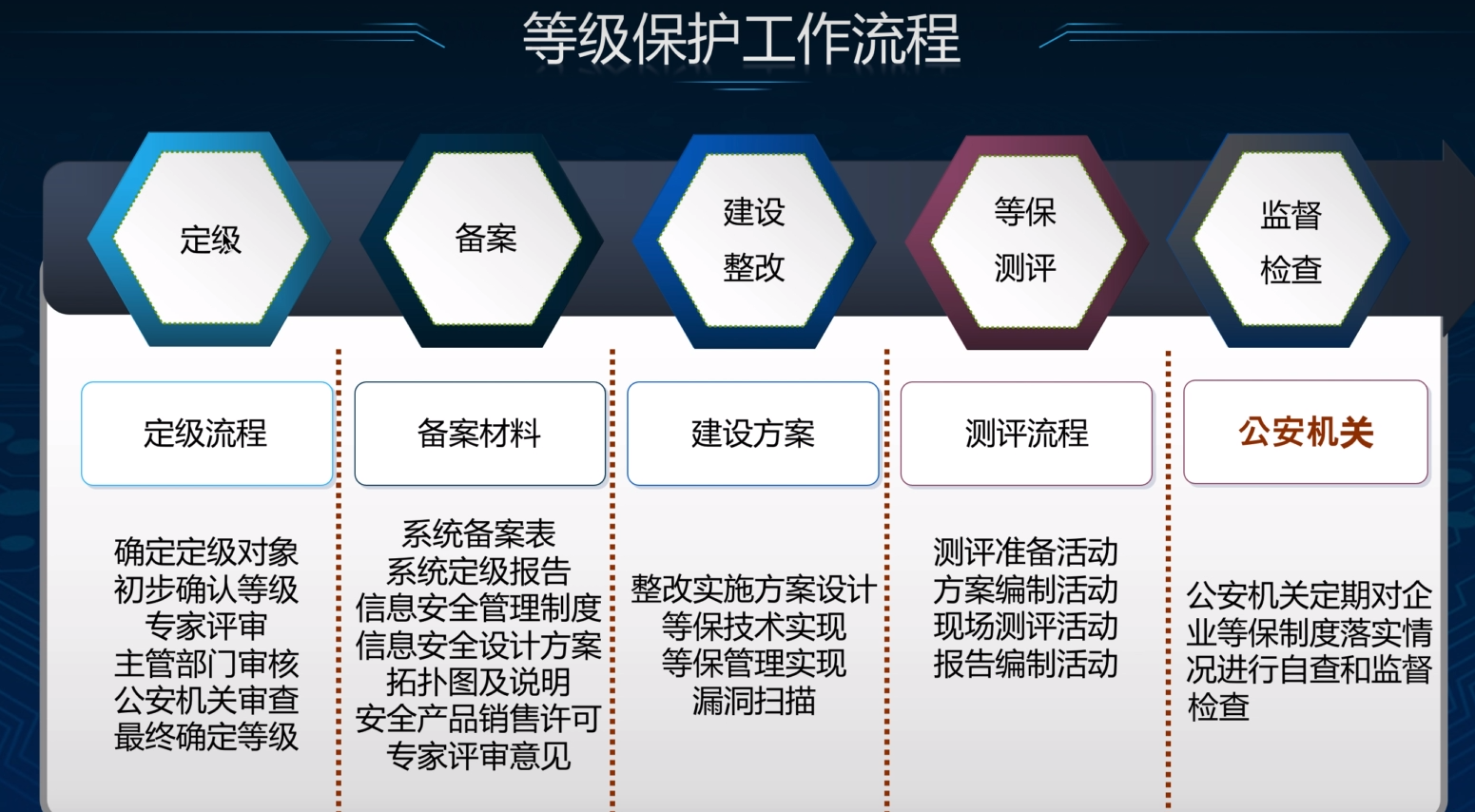
【面试题】等保(等级保护)的工作流程
等保(等级保护)的工作流程主要包括以下几个步骤,以下将详细分点介绍: 系统定级: 确定定级对象:根据《信息系统等级保护管理办法》和《信息系统等级保护定级指南》的要求,确定需要进行等级保护的…...

python调用麦克风和扬声器,并调用阿里云实时语音转文字
import time import queue import sounddevice as sd import numpy as np import nls import sys# 阿里云配置信息 URL "wss://nls-gateway-cn-shanghai.aliyuncs.com/ws/v1" TOKEN "XXXX" # 参考https://help.aliyun.com/document_detail/450255.html获…...
的常见模式。)
描述在React中集成第三方库(如Redux或React Router)的常见模式。
在React中集成第三方库,如状态管理库Redux或路由库React Router,通常遵循一些常见的模式和最佳实践。下面是一些集成这些库的步骤和模式: 集成Redux 安装Redux及相关包: 安装Redux及其中间件(如redux-thunk或redux-saga…...
)
JavaScript语法特性篇-空值合并运算符(??)
1、基本使用 空值合并运算符(??)英文名称为 Nullish coalescing operator,是一个逻辑运算符。 特性:当左侧的操作数为 null 或者 undefined 时,返回其右侧操作数,否则返回左侧操作数。 const foo nul…...
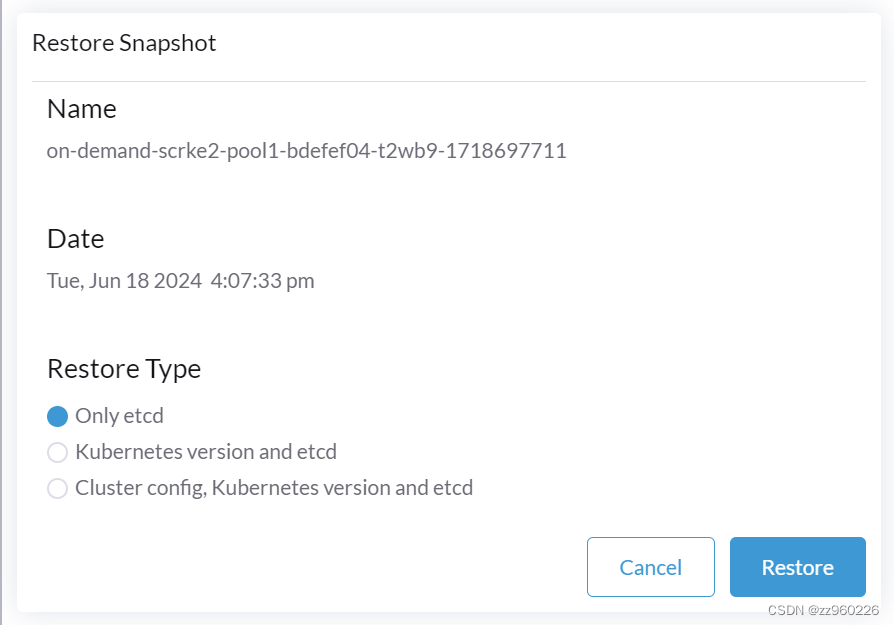
rancher快照备份至S3
巧用rancher的S3快照备份功能,快速实现集群复制、集群转移、完全崩溃后的极限修复 1.进入集群管理,在对应的集群菜单后,点击编辑配置 2.选择ETCD,启用,Backup Snapshots to S3选项 并填入你的minio 3 配置成功后 手…...
ChatGPT API教程在线对接OpenAI APIKey技术教程
一、OpenAI基本库介绍 您可以通过 HTTP 请求与 API 进行交互,这可以通过任何编程语言实现。我们提供官方的 Python 绑定、官方的 Node.js 库,以及由社区维护的库。 要安装官方的 Python 绑定,请运行以下命令: pip install open…...

随心而遇,跟着感觉走
分数限制下,选好专业还是选好学校? 24年高考结束,很多学生犹豫选择专业还是好学校,我的建议是,选择好学校。 本人体验来说,电子,工地,计科,数学,工科相关的…...

LeetCode题练习与总结:只出现一次的数字--136
一、题目描述 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。 示例 1 : …...

常见的中间件都在解决什么问题?
常见的中间件都在解决什么问题 RocketMQ RocketMQ 是一款功能强大的分布式消息系统。 RocketMQ 源码地址:https://github.com/apache/rocketmq(opens new window) RocketMQ 官方网站:https://rocketmq.apache.org 什么场景下用 RocketMQ?…...

微信小程序-scroll-view实现上拉加载和下拉刷新
一.scroll-view实现上拉加载 scroll-view组件通过自身一些属性实现上拉加载的功能。 lower-threshold“100"属性表示距离底部多少px就会实现触发下拉加载的事件。 类似于在.json文件里面配置"onReachBottomDistance”: 100 bindscrolltolower"getMore"属…...

TS中interface和type的区别
在 TypeScript 中,interface 和 type 都可以用来定义对象的类型,但它们之间存在一些差异。 以下是 interface 和 type 的主要区别: 扩展(Extending): interface 可以通过 extends 关键字来扩展其他 interface。interfa…...
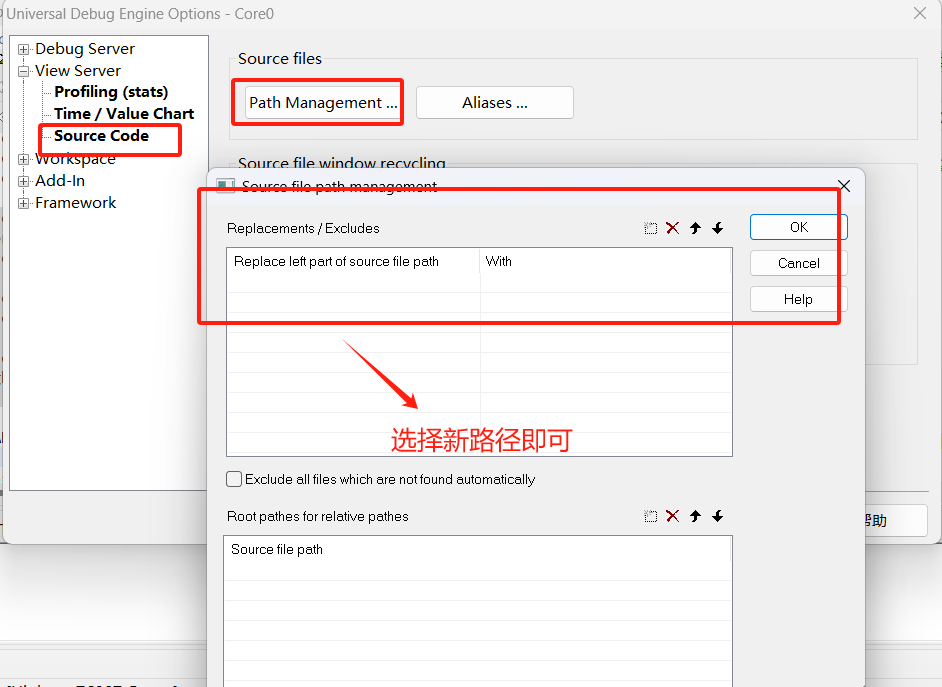
Hightec编译器系列之高级调试技巧精华总结
Hightec编译器系列之高级调试技巧精华总结 小T为了便于大家理解,本文的思维导图大纲如下: 之前可能很多小伙伴没有使用过Hightec编译器,大家可以参考小T之前的文章《Hightec编译器系列之白嫖就是爽》可以下载一年试用版本。 小T使用过适配英…...

【论文笔记】LoRA LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
题目:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 来源: ICLR 2022 模型名称: LoRA 论文链接: https://arxiv.org/abs/2106.09685 项目链接: https://github.com/microsoft/LoRA 文章目录 摘要引言问题定义现有方法的问题方法将 LORA 应用于 Transformer 实…...

【Sa-Token|4】Sa-Token微服务项目应用
若微服务数量多,如果每个服务都改动,工作量大,则可以只在网关和用户中心进行改动,也是可以实现服务之间的跳转。 这种方式可以通过在网关服务中生成和验证 Sa-Token,并将其与现有的 Token关联存储在 Redis 中。用户中心…...
】)
鸿蒙开发系统基础能力:【@ohos.hilog (日志打印)】
日志打印 hilog日志系统,使应用/服务可以按照指定级别、标识和格式字符串输出日志内容,帮助开发者了解应用/服务的运行状态,更好地调试程序。 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用…...

SpringMVC系列十: 中文乱码处理与JSON处理
文章目录 中文乱码处理自定义中文乱码过滤器Spring提供的过滤器处理中文 处理json和HttpMessageConverter<T>处理JSON-ResponseBody处理JSON-RequestBody处理JSON-注意事项和细节HttpMessageConverter<T\>文件下载-ResponseEntity<T\>作业布置 上一讲, 我们学…...
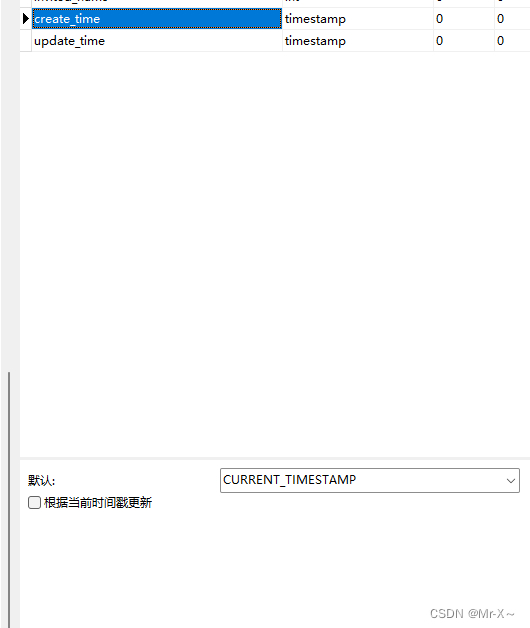
使用MyBatisPlus进行字段的自动填充
使用MyBatisPlus进行字段的自动填充 需求场景 当我们往数据库里面插入一条数据,或者是更新一条数据时,一般都需要标记创建时间create_time和更新时间update_time的值,但是如果我们每张表的每个请求,在执行sql语句的时候我们都手…...

python爬虫之aiohttp多任务异步爬虫
python爬虫之aiohttp多任务异步爬虫 爬取的flash服务如下: from flask import Flask import timeapp Flask(__name__)app.route(/bobo) def index_bobo():time.sleep(2)return Hello boboapp.route(/jay) def index_jay():time.sleep(2)return Hello jayapp.rout…...

NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题
NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否曾因Windows自动休眠而中断重要的远程演…...

HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案
HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...
)
CubeMX默认配置的坑:STM32 LPUART的ORE溢出错误如何彻底解决(从寄存器到HAL库的避坑指南)
STM32 LPUART的ORE溢出错误:从硬件机制到HAL库的深度解决方案 当你在深夜调试STM32的LPUART接口时,突然发现串口"神秘"地停止了响应——这种场景对于经验丰富的嵌入式工程师来说并不陌生。问题的根源往往指向那个容易被忽视的Overrun Error&am…...

【51单片机】直流电机PWM调速实战:从驱动电路到闭环控制
1. 直流电机驱动基础与硬件选型 第一次玩直流电机时,我直接拿杜邦线把电机接在51单片机的IO口上,结果电机纹丝不动,还差点烧了芯片。这个教训让我明白:驱动电路是电机控制的第一道门槛。常见的直流电机工作电压通常在3-6V…...
)
保姆级避坑指南:用GGCNN源码搞定Cornell抓取数据集转换(附.mat/.tiff生成全流程)
保姆级避坑指南:用GGCNN源码搞定Cornell抓取数据集转换全流程 当你第一次尝试复现GGCNN这个经典的机器人抓取项目时,Cornell数据集的预处理往往会成为第一个拦路虎。作为一个曾经在这个环节卡了整整两天的过来人,我深知那些官方文档没写的细节…...
)
从布加勒斯特到蒂米什瓦拉:ElevenLabs罗马尼亚语语音在11个地区口音适配中的3大断层(含IPA音标对齐失败案例库)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs罗马尼亚语语音合成的技术基底与地域语言学前提 ElevenLabs 的罗马尼亚语语音合成并非简单套用通用 TTS 架构,而是深度耦合了东欧罗曼语支的音系特征、正字法规范及社会语言变体。…...
设计模式与最佳实践)
人机协同智能体(Human-in-the-loop)设计模式与最佳实践
从零到落地:构建高效可控的人机协同智能体(Human-in-the-loop)设计模式与最佳实践副标题:从ChatGPT插件监控到企业级合规风控,覆盖全场景的HITL实践指南摘要/引言 问题陈述 2023年被称为大语言模型(LLM&…...

AI智能体规划框架skill-daydreaming:让AI像人一样思考与执行复杂任务
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“skill-daydreaming”,作者是regiep4。光看这个名字,你可能觉得有点玄乎——“技能白日梦”?这到底是干嘛的?作为一个在AI和自动化工具领域折腾了十多年…...

说说唯一ID与CAS 元一软件
一、从数据的唯一标识开讲数据区分与标识表现数据和算法组成了我们现有的应用软件,当然互联网应用也不例外。为了区分应用系统收集和运行所必要的这些数据,我们通过各种方法,来组织其存储形式,方便其为我们所用。从数据结构、文件…...

怎么降低维普AI率最对路?看你AI率多少+预算多少就知道选!
怎么降低维普AI率最对路?看你AI率多少预算多少就知道选! 选降维普 AI 工具的纠结 打开搜索框搜「降低维普 AI 率」——出来一堆产品介绍。每款都说自己最对路。你看了 1 小时,还是不知道选哪款。 其实不是工具多,是选工具的判断…...