Python爬虫从入门到入狱之爬取知乎用户信息
items中的代码主要是我们要爬取的字段的定义
class UserItem(scrapy.Item):id \= Field()name \= Field()account\_status \= Field()allow\_message\= Field()answer\_count \= Field()articles\_count \= Field()avatar\_hue \= Field()avatar\_url \= Field()avatar\_url\_template \= Field()badge \= Field()business \= Field()employments \= Field()columns\_count \= Field()commercial\_question\_count \= Field()cover\_url \= Field()description \= Field()educations \= Field()favorite\_count \= Field()favorited\_count \= Field()follower\_count \= Field()following\_columns\_count \= Field()following\_favlists\_count \= Field()following\_question\_count \= Field()following\_topic\_count \= Field()gender \= Field()headline \= Field()hosted\_live\_count \= Field()is\_active \= Field()is\_bind\_sina \= Field()is\_blocked \= Field()is\_advertiser \= Field()is\_blocking \= Field()is\_followed \= Field()is\_following \= Field()is\_force\_renamed \= Field()is\_privacy\_protected \= Field()locations \= Field()is\_org \= Field()type \= Field()url \= Field()url\_token \= Field()user\_type \= Field()logs\_count \= Field()marked\_answers\_count \= Field()marked\_answers\_text \= Field()message\_thread\_token \= Field()mutual\_followees\_count \= Field()participated\_live\_count \= Field()pins\_count \= Field()question\_count \= Field()show\_sina\_weibo \= Field()thank\_from\_count \= Field()thank\_to\_count \= Field()thanked\_count \= Field()type \= Field()vote\_from\_count \= Field()vote\_to\_count \= Field()voteup\_count \= Field()
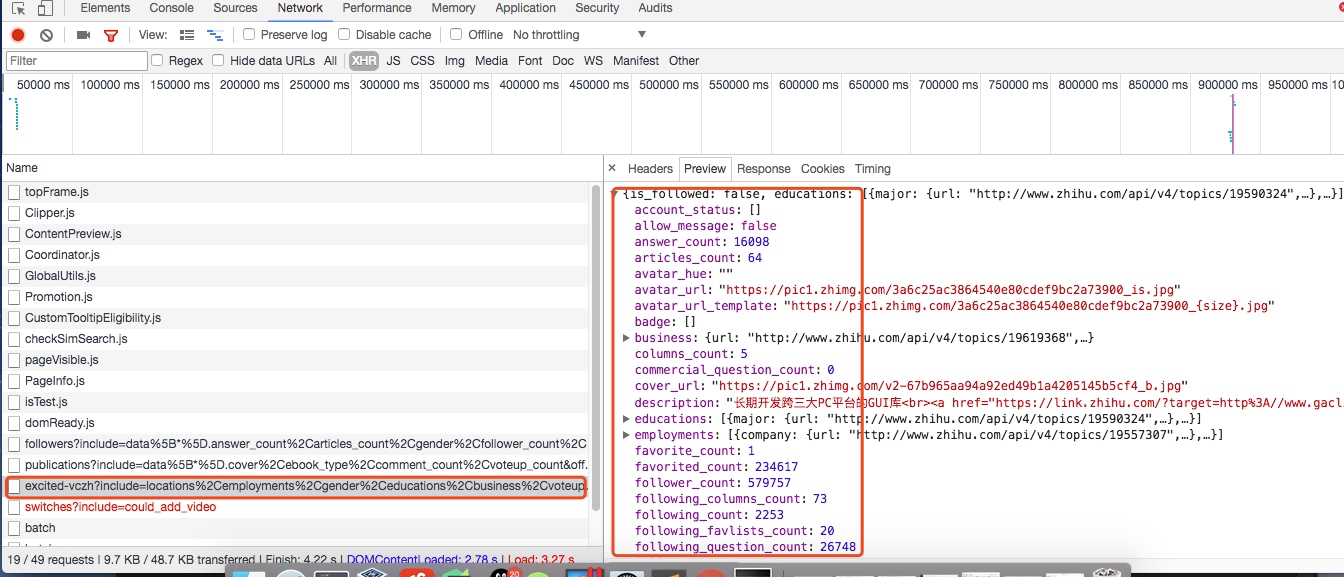
这些字段的是在用户详细信息里找到的,如下图所示,这里一共有58个字段,可以详细研究每个字段代表的意思:
关于spiders中爬虫文件zhihu.py中的主要代码
这段代码是非常重要的,主要的处理逻辑其实都是在这里
class ZhihuSpider(scrapy.Spider):name \= "zhihu"allowed\_domains \= \["www.zhihu.com"\]start\_urls \= \['http://www.zhihu.com/'\]#这里定义一个start\_user存储我们找的大V账号start\_user = "excited-vczh"#这里把查询的参数单独存储为user\_query,user\_url存储的为查询用户信息的url地址user\_url = "https://www.zhihu.com/api/v4/members/{user}?include={include}"user\_query \= "locations,employments,gender,educations,business,voteup\_count,thanked\_Count,follower\_count,following\_count,cover\_url,following\_topic\_count,following\_question\_count,following\_favlists\_count,following\_columns\_count,avatar\_hue,answer\_count,articles\_count,pins\_count,question\_count,columns\_count,commercial\_question\_count,favorite\_count,favorited\_count,logs\_count,marked\_answers\_count,marked\_answers\_text,message\_thread\_token,account\_status,is\_active,is\_bind\_phone,is\_force\_renamed,is\_bind\_sina,is\_privacy\_protected,sina\_weibo\_url,sina\_weibo\_name,show\_sina\_weibo,is\_blocking,is\_blocked,is\_following,is\_followed,mutual\_followees\_count,vote\_to\_count,vote\_from\_count,thank\_to\_count,thank\_from\_count,thanked\_count,description,hosted\_live\_count,participated\_live\_count,allow\_message,industry\_category,org\_name,org\_homepage,badge\[?(type=best\_answerer)\].topics"#follows\_url存储的为关注列表的url地址,fllows\_query存储的为查询参数。这里涉及到offset和limit是关于翻页的参数,0,20表示第一页follows\_url = "https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}"follows\_query \= "data%5B\*%5D.answer\_count%2Carticles\_count%2Cgender%2Cfollower\_count%2Cis\_followed%2Cis\_following%2Cbadge%5B%3F(type%3Dbest\_answerer)%5D.topics"#followers\_url是获取粉丝列表信息的url地址,followers\_query存储的为查询参数。followers\_url = "https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}"followers\_query \= "data%5B\*%5D.answer\_count%2Carticles\_count%2Cgender%2Cfollower\_count%2Cis\_followed%2Cis\_following%2Cbadge%5B%3F(type%3Dbest\_answerer)%5D.topics"def start\_requests(self):'''这里重写了start\_requests方法,分别请求了用户查询的url和关注列表的查询以及粉丝列表信息查询:return:'''yield Request(self.user\_url.format(user=self.start\_user,include=self.user\_query),callback=self.parse\_user)yield Request(self.follows\_url.format(user=self.start\_user,include=self.follows\_query,offset=0,limit=20),callback=self.parse\_follows)yield Request(self.followers\_url.format(user=self.start\_user,include=self.followers\_query,offset=0,limit=20),callback=self.parse\_followers)def parse\_user(self, response):'''因为返回的是json格式的数据,所以这里直接通过json.loads获取结果:param response::return:'''result \= json.loads(response.text)item \= UserItem()#这里循环判断获取的字段是否在自己定义的字段中,然后进行赋值for field in item.fields:if field in result.keys():item\[field\] \= result.get(field)#这里在返回item的同时返回Request请求,继续递归拿关注用户信息的用户获取他们的关注列表yield itemyield Request(self.follows\_url.format(user = result.get("url\_token"),include=self.follows\_query,offset=0,limit=20),callback=self.parse\_follows)yield Request(self.followers\_url.format(user = result.get("url\_token"),include=self.followers\_query,offset=0,limit=20),callback=self.parse\_followers)def parse\_follows(self, response):'''用户关注列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息:param response::return:'''results \= json.loads(response.text)if 'data' in results.keys():for result in results.get('data'):yield Request(self.user\_url.format(user = result.get("url\_token"),include=self.user\_query),callback=self.parse\_user)#这里判断page是否存在并且判断page里的参数is\_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页if 'page' in results.keys() and results.get('is\_end') == False:next\_page \= results.get('paging').get("next")#获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息yield Request(next\_page,self.parse\_follows)def parse\_followers(self, response):'''这里其实和关乎列表的处理方法是一样的用户粉丝列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息:param response::return:'''results \= json.loads(response.text)if 'data' in results.keys():for result in results.get('data'):yield Request(self.user\_url.format(user = result.get("url\_token"),include=self.user\_query),callback=self.parse\_user)#这里判断page是否存在并且判断page里的参数is\_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页if 'page' in results.keys() and results.get('is\_end') == False:next\_page \= results.get('paging').get("next")#获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息yield Request(next\_page,self.parse\_followers)
上述的代码的主要逻辑用下图分析表示:
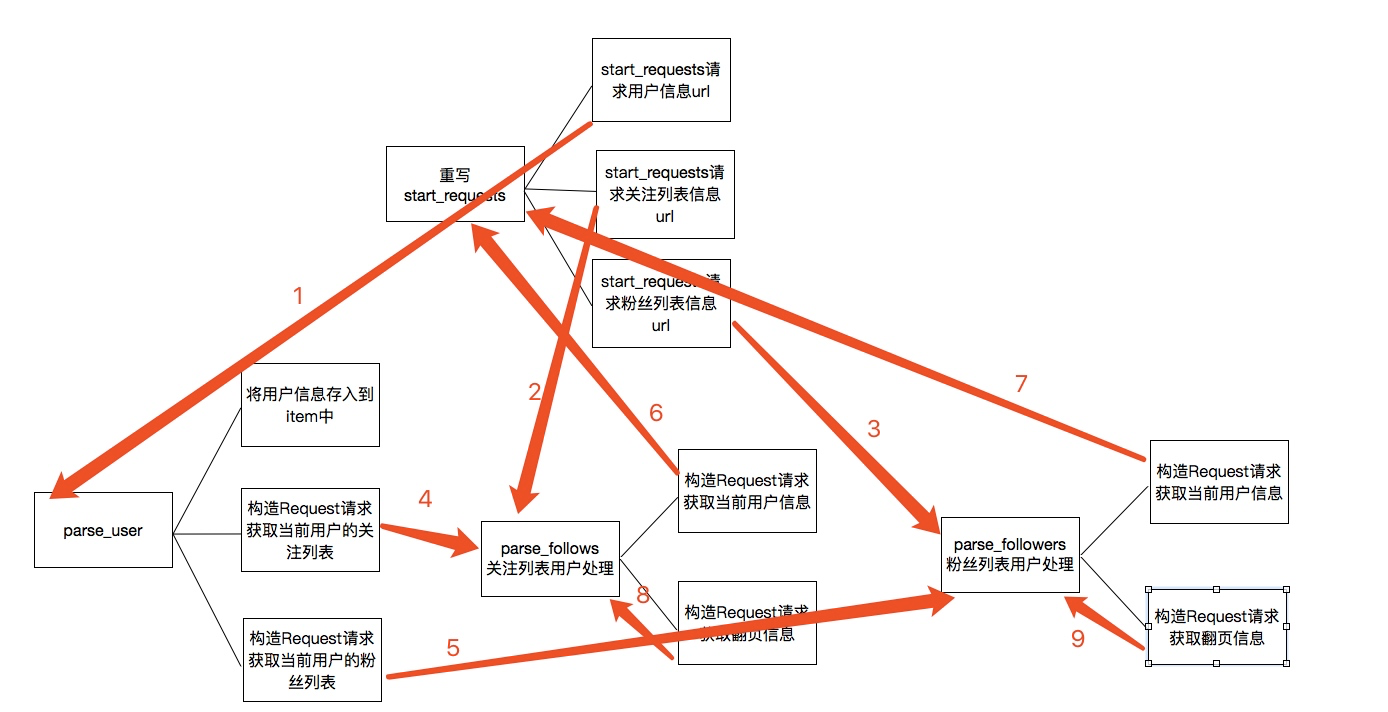
关于上图的一个简单描述:
1. 当重写start_requests,一会有三个yield,分别的回调函数调用了parse_user,parse_follows,parse_followers,这是第一次会分别获取我们所选取的大V的信息以及关注列表信息和粉丝列表信息
2. 而parse分别会再次回调parse_follows和parse_followers信息,分别递归获取每个用户的关注列表信息和分析列表信息
3. parse_follows获取关注列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_follows
4. parse_followers获取粉丝列表里的每个用户的信息回调了parse_user,并进行翻页获取回调了自己parse_followers
通过上面的步骤实现所有用户信息的爬取,最后是关于数据的存储
关于数据存储到mongodb
这里主要是item中的数据存储到mongodb数据库中,这里主要的一个用法是就是插入的时候进行了一个去重检测
class MongoPipeline(object):def \_\_init\_\_(self, mongo\_uri, mongo\_db):self.mongo\_uri \= mongo\_uriself.mongo\_db \= mongo\_db@classmethoddef from\_crawler(cls, crawler):return cls(mongo\_uri\=crawler.settings.get('MONGO\_URI'),mongo\_db\=crawler.settings.get('MONGO\_DATABASE', 'items'))def open\_spider(self, spider):self.client \= pymongo.MongoClient(self.mongo\_uri)self.db \= self.client\[self.mongo\_db\]def close\_spider(self, spider):self.client.close()def process\_item(self, item, spider):#这里通过mongodb进行了一个去重的操作,每次更新插入数据之前都会进行查询,判断要插入的url\_token是否已经存在,如果不存在再进行数据插入,否则放弃数据self.db\['user'\].update({'url\_token':item\["url\_token"\]},{'$set':item},True)return item仅作项目练习,切勿商用!!!
由于文章篇幅有限,文档资料内容较多,需要这些文档的朋友,可以加小助手微信免费获取,【保证100%免费】,中国人不骗中国人。

全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
好了今天的分享就到这里了
相关文章:
Python爬虫从入门到入狱之爬取知乎用户信息
items中的代码主要是我们要爬取的字段的定义 class UserItem(scrapy.Item):id \ Field()name \ Field()account\_status \ Field()allow\_message\ Field()answer\_count \ Field()articles\_count \ Field()avatar\_hue \ Field()avatar\_url \ Field()avatar\_url\_template…...
apk反编译修改教程系列-----去除apk软件更新方法步骤列举 记录八种最常见的去除方法
在前面几期博文中 有说明去除apk软件更新的步骤方法。我们在对应软件反编译去除更新中要灵活运用。区别对待。同一个软件可以有不同的去除更新方法可以适用。今天的教程对于软件更新去除列举几种经常使用的修改步骤。 通过基础课程可以了解 1-----软件反编译更新去除的几种常…...

SpringMVC系列六: 视图和视图解析器
视图和视图解析器 💞基本介绍💞 自定义视图为什么需要自定义视图自定义试图实例-代码实现自定义视图工作流程小结Debug源码默认视图解析器执行流程多个视图解析器执行流程 💞目标方法直接指定转发或重定向使用实例指定请求转发流程-Debug源码…...

MySQL数据备份的分类
MySQL数据库的备份 在我们使用MySQL数据库的过程中,一些意外情况的发生,有可能造成数据的损失。例如,意外的停电,不小心的操作失误等都可能造成数据的丢失。 所以为了保证数据的安全与一致性,需要定期对数据进行备份。…...
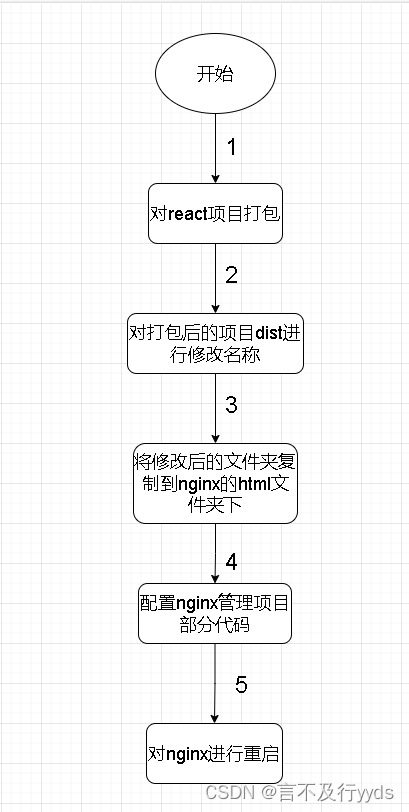
node+nginx实现对react进行一键打包部署--windows版
文章目录 nodenginx实现对react进行一键打包部署--windows版1.功能展示及项目准备1.1功能展示 1.2 项目准备1.2.1技术点1.2.2安装相关配置(windows) 2.实现2.1 实现思路2.2 实现步骤2.1 项目准备2.1.1 创建env文件2.1.2 创建api/index.js文件2.1.3 添加解决跨域代码 2.2 项目实…...

【机器学习】基于Gumbel-Sinkhorn网络的“潜在排列问题”求解
1. 引言 1.1.“潜在排列”问题 本文将深入探索一种特殊的神经网络方法,该方法在处理离散对象时展现出卓越的能力,尤其是针对潜在排列问题的解决方案。在现代机器学习和深度学习的领域中,处理离散数据一直是一个挑战,因为传统的神经网络架构通常是为连续数据设计的。然而,…...

create-react-app创建的项目中设置webpack配置
create-react-app 创建的项目默认使用的是 react-scripts(存在于node_modules文件夹中)来处理开发服务器和构建,它内置了一些webpack相关配置。一般不会暴露出来给开发者,但是在有些情况下我们需要修改下webpack默认配置ÿ…...
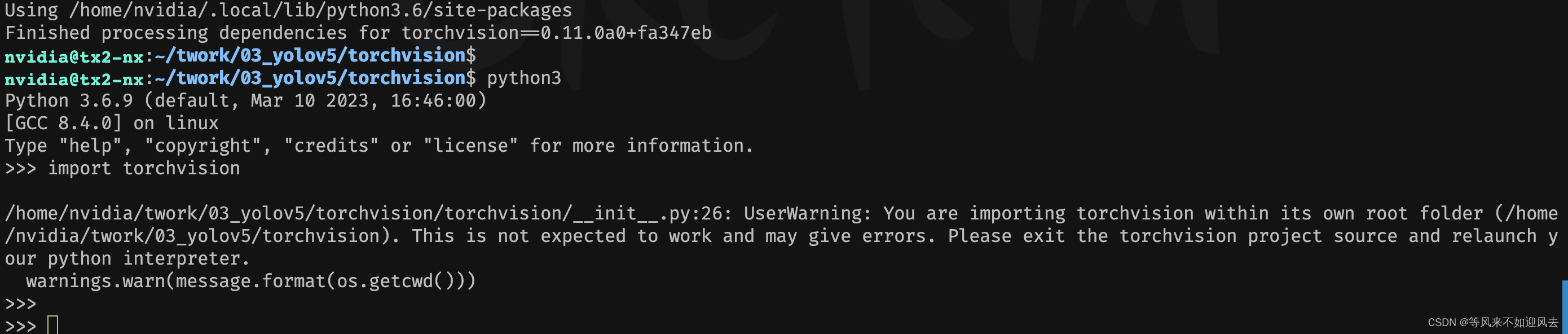
【ai】tx2 nx :安装torch、torchvision for yolov5
torchvision 是自己本地构建的验证torchvision nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ nvidia@tx2-nx:~/twork/03_yolov5/torchvision$ python3 Python 3.6.9 (default, Mar 10 2023, 16:46:00) [GCC 8.4.0] on linux Type "help", "copyright",…...

【报错】在终端中输入repo命令后系统未能识别这个命令
1 报错 已经使用curl命令来下载repo工具,但是在终端中输入repo命令后系统未能识别这个命令。 2 分析 通常是因为repo...

【机器学习】K-Means算法详解:从原理到实践
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 K-Means算法详解:从原理到实践引言1. 基本原理1.1 簇与距离度量1.2 …...

解决qiankun项目与子应用样式混乱问题
背景 qiankun项目用的是Vue2Antdesign2,但其中一个子应用用的是Vue3Antdesign4。集成之后发现子应用的样式混乱,渲染的是Antdesign2的样式。 解决 以下步骤在子应用里操作 1. 在main.js引入ConfigProvider ,在app全局注册ConfigProvider …...
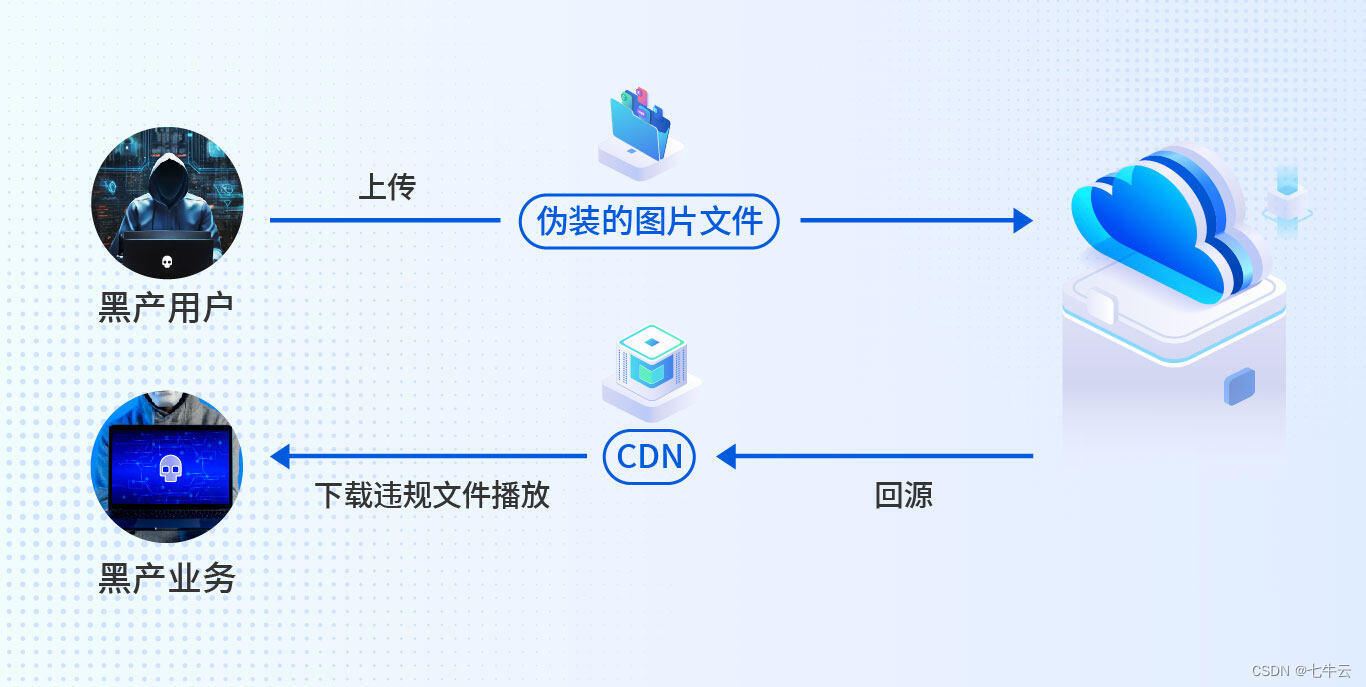
黑产当前,如何识别异常图片?
在这个人人都是创作者的年代, UGC 已成为诸多平台的重要组成。 有利益的地方就会有黑产存在, 不少 UGC 平台都被黑产「薅羊毛」搞的心烦意乱, 用户传的图片,怎么就变成视频链接了? 正常运营的平台,为何流量…...

数据模型(models)
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 (1)在App中添加数据模型 在app1的models.py中添加如下代码: from django.db import models # 引入django.…...
743. 网络延迟时间 - Dijkstra算法题解)
【CS.AL】算法核心之贪心算法 —— 力扣(LeetCode)743. 网络延迟时间 - Dijkstra算法题解
文章目录 题目描述References 题目描述 743. 网络延迟时间 - 力扣(LeetCode) 有 N 个网络节点,标记为 1 到 N。 给定一个列表 times,其中 times[i] (u, v, w) 表示有一条从节点 u 到节点 v 的时延为 w 的有向边。 现在…...

25、架构-微服务的驱动力
微服务架构的驱动力可以从多方面探讨,包括灵活性、独立部署、技术异构性、团队效率和系统弹性等。 灵活性和可维护性 灵活性是微服务架构的一个主要优势。通过将单体应用拆分成多个独立的微服务,开发团队可以更容易地管理、维护和更新各个服务。每个微…...
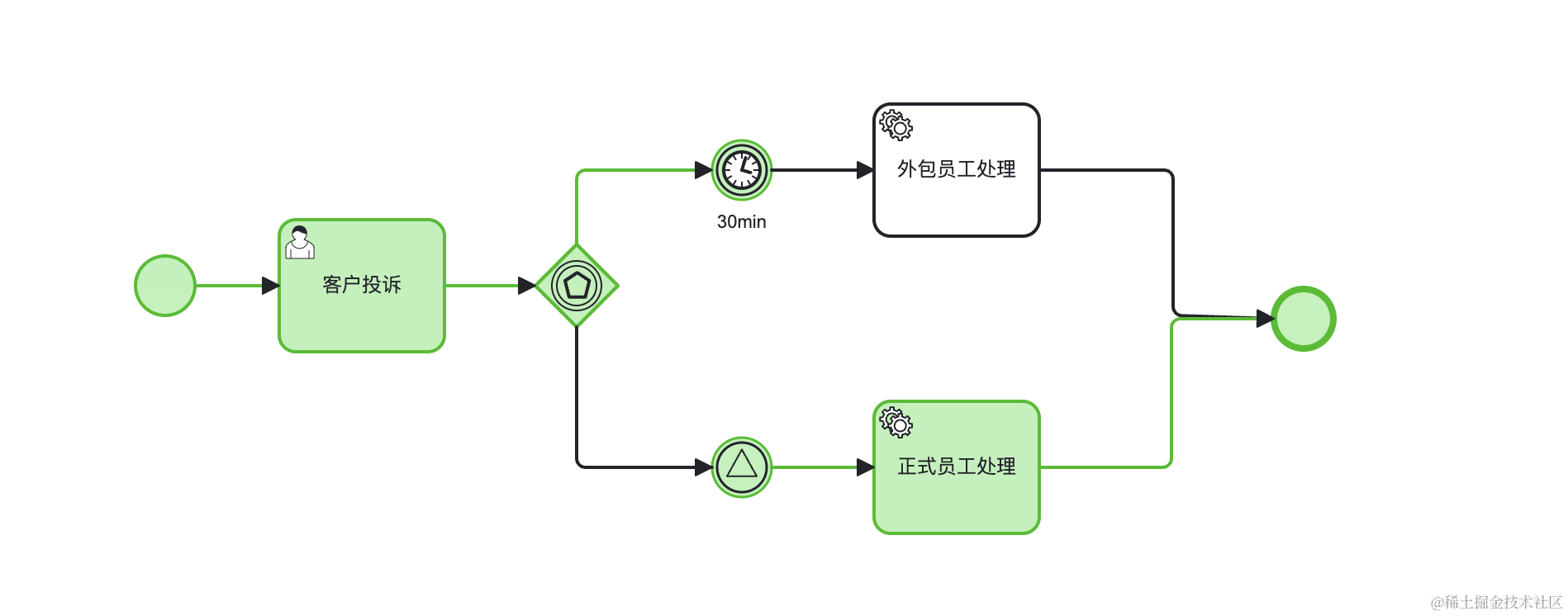
JeecgFlow事件网关概念及案例
事件网关 通常网关基于连线条件决定后续路径,但事件网关有所不同,其基于事件决定后续路径。事件网关的每条外出顺序流都需要连接一个捕获中间事件。 事件网关只有分支行为,流程的走向完全由中间事件决定。可以从多条候选分支中选择事件最先达…...
使用鸿蒙HarmonyOs NEXT 开发 快速开发 简单的购物车页面
目录 资源准备:需要准备三张照片:商品图、向下图标、金钱图标 1.显示效果: 2.源码: 资源准备:需要准备三张照片:商品图、向下图标、金钱图标 1.显示效果: 定义了一个购物车页面的布局&#x…...
) 修饰的函数)
iOS 中 attribute((constructor)) 修饰的函数
开发环境声明:此文描述的 attribute((constructor)) 特指使用 Objective-C 开发 iOS、MacOS,Swift 语言不支持这种属性修饰符。 初识 attribute((constructor)) 在 Objective-C 开发中,attribute((constructor)) 是一个 GCC 和 Clang 编译器…...

原生js实现图片预览控件,支持丝滑拖拽,滚轮放缩,放缩聚焦
手撸源代码如下:注释应该很详细了,拿去直用 可以放到在线编辑器测试,记得修改图片路径 菜鸟教程在线编辑器 <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" conten…...

C语言入门课程学习笔记9:指针
C语言入门课程学习笔记9 第41课 - 指针:一种特殊的变量实验-指针的使用小结 第42课 - 深入理解指针与地址实验-指针的类型实验实验小结 第43课 - 指针与数组(上)实验小结 第44课 - 指针与数组(下)实验实验小结 第45课 …...
)
【独家首发】NotebookLM语义搜索底层架构图谱(基于2024 Q2最新API逆向分析,含7层向量映射逻辑)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM语义搜索功能全景概览 核心能力定位 NotebookLM 的语义搜索并非传统关键词匹配,而是基于用户上传文档(PDF、TXT、Google Docs)构建的私有知识图谱进行上下…...

AI行业的“隐形赛道”:AI伦理与合规人才缺口到底有多大
一、AI狂飙下的“隐形刚需”:被忽视的伦理与合规赛道当软件测试从业者还在为功能测试、性能测试的技术迭代焦头烂额时,AI行业的另一股暗流正汹涌袭来——伦理与合规人才的缺口,正成为制约AI产业可持续发展的隐形瓶颈。从ChatGPT引发生成式AI热…...

ARM NEON SIMD指令集:VMAX与VMIN向量运算详解
1. ARM SIMD指令集基础与向量运算概述在移动计算和嵌入式系统领域,ARM架构凭借其出色的能效比占据了主导地位。随着应用对计算性能需求的不断提升,SIMD(单指令多数据)技术成为提升处理器并行计算能力的关键手段。ARM的Advanced SI…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic玩转AirSim仿真(保姆级避坑指南)
告别双系统!用WSL2Ubuntu20.04ROS Noetic玩转AirSim仿真(保姆级避坑指南) 在机器人开发与自动驾驶仿真领域,AirSim与ROS的结合堪称黄金搭档——前者提供高保真物理引擎与视觉渲染,后者则是机器人算法开发的行业标准。…...

别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析
别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析 地理空间数据分析中,识别变量间的分异特征和驱动因子一直是研究难点。传统方法依赖复杂公式推导和编程实现,让许多研究者望而却步。而地理探测器(Geod…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...
)
NotebookLM新闻传播研究落地全图谱(2024最新实证报告)
更多请点击: https://kaifayun.com 第一章:NotebookLM新闻传播研究的范式演进与学科定位 NotebookLM 作为 Google 推出的面向研究者的 AI 助手,其核心设计理念——以用户上传文档为知识锚点、通过引用溯源生成可信响应——正悄然重构新闻传播…...

MySQL 跑得稳不稳,Prometheus 得能抓到这个数据才能说清楚
前言 数据库出问题的时候,最怕的不是故障本身,而是故障发生了却没人知道,等用户反馈过来才去翻日志,慢了不止一拍。 MySQL 本身有一些状态变量能反映运行状况——连接数、QPS、缓冲池命中率、慢查询数量——但这些数据要么存着没…...

CAXA 中心线
位置命令属性自由(方式)1、触发命令;2、属性如下;3、点击对象;(例如这里点击圆弧)4、输入定位点,或移动鼠标;5、点击确定中心线大小;指定延长线长度ÿ…...

基于合宙Air001的交互式地球名片:从硬件焊接、Arduino编程到触摸优化
1. 项目概述与核心思路最近在创客圈子里,合宙的Air001开发板可以说是火得一塌糊涂。包装设计得挺酷,价格更是香到没朋友,最关键的是它完美支持Arduino IDE开发,对于咱们这些习惯了Arduino生态的玩家来说,上手门槛几乎为…...