【C++】通过priority_queue、reverse_iterator加深对于适配器和仿函数的理解
苦尽甘来

文章目录
- 一、仿函数(仿函数就是一个封装()运算符重载的类)
- 1.C语言的函数指针
- 2.C++的仿函数对象
- 二、priority_queue中的仿函数
- 1.模拟实现优先级队列
- 1.1 优先级队列的本质(底层容器为vector的适配器)
- 1.2 向下调整算法建堆
- 1.3 pop堆顶元素时向下调整算法重新调整堆
- 1.4 push堆尾元素时向上调整算法重新调整堆
- 1.5 priority_queue的OJ题
- 2.在优先级队列中增加仿函数(类模板参数和函数模板参数的不同)
- 3.仿函数的高级用法(当原有仿函数无法满足要求时,需要重新写满足要求的仿函数)
- 三、reverse_iterator(正向迭代器适配器)
- 1.反向迭代器的思想(代码复用,适配模式,类封装)
- 2.反向迭代器与正向迭代器位置的对称
一、仿函数(仿函数就是一个封装()运算符重载的类)
1.C语言的函数指针
1.
仿函数实际就是一个类,这里类实例化出来的对象叫做函数对象,下面命名空间wyn中的两个仿函数就分别是两个类,在使用时直接用类进行实例化对象,然后让对象调用()的运算符重载,这样我们看到的调用形式就非常像普通的函数调用,但实际上这里并不是函数调用,而是仿函数实例化出来的对象调用了自己的operator()重载成员函数。
namespace wyn
{template <class T>class less{public:bool operator()(const T& x, const T& y)const{return x < y;}};template <class T>class greater{public://将仿函数放成public,要不然class默认是私有的bool operator()(const T& x, const T& y)const{return x > y;}};
}
int main()
{wyn::less<int> lessFunc;wyn::greater<int> greaterFunc;lessFunc(1, 2);//你以为这里是函数调用,但他其实是仿函数对象lessFunc调用了他的成员运算符重载()函数。
}
2.
C++搞出来仿函数的原因是什么呢?他在作用上可以替代C语言里面的函数指针。
在C语言阶段,如果我们想让冒泡排序一会儿排成升序,一会儿排成降序,我们该怎么做呢?我们肯定是通过函数指针的方式来完成,通过所传函数的比较方式来让冒泡排序中比较前后元素大小的逻辑发生改变,如果排升序,就后面元素小于前面元素发生交换,如果排降序,就后面元素大于前面元素发生交换。这样的工作就是由函数指针来完成的,这样的调用方式我们称之为回调函数。
3.
下面这段代码便展示了C语言回调函数的使用形式,可以看到test函数参数为一个函数指针,p指向返回值为void参数为const char *的函数,通过不同的函数名,我们就可以通过函数指针回调不同的函数。
void print( const char* str)
{printf("%s\n", str);
}
void print1( const char* str)
{printf("%s\n", str);
}
void test(void(*p)( const char*))
{p("I LOVE YOU");//调用print函数p("You are lying");//调用print1函数
}
int main()
{//函数名代表函数地址test(print);//传print函数地址test(print1);//传print1函数地址return 0;
}
2.C++的仿函数对象
1.
C++觉得函数指针使用起来太挫了,一个指针写那么长,代码可读性太差了,所以C++用仿函数就可以完全取代C语言的函数指针。例如下面的冒泡排序,我们想让冒泡排序是活的,而不是固定只能排升序或降序,在C++中我们就喜欢用仿函数来解决这样的方式。
2.
在对冒泡排序进行泛型编程时,我们利用两个模板参数,一个代表排序的数据类型是泛型,一个代表逻辑泛型,用于修改冒泡排序里面具体排序的逻辑,这个参数接收的就是我们前面所说的仿函数对象,我们将冒泡排序的比较逻辑改为仿函数对象的operator()函数调用,这样就可以通过模板参数的逻辑泛型的类型不同,实例化出不同的仿函数对象,在修改冒泡的比较逻辑那里,就可以调用不同对象所属仿函数类的operator()函数了。
3.
当然如果你觉得先定义出仿函数对象,然后再传仿函数对象比较麻烦的话,你可以直接给冒泡排序传仿函数的匿名对象,这时候就体现出来C++匿名对象的优势所在了。
4.
所以,C语言和C++在解决回调函数这样的方式上,实际函数参数类型就发生了天翻地覆的变化,C语言中的是函数指针类型定义出来的变量作为参数,C++用的是自定义类型仿函数实例化出来的仿函数对象作为参数。并且C++还支持了模板泛型编程,这也解决了代码冗余的问题。
namespace wyn
{template <class T>class less{public:bool operator()(const T& x, const T& y)const{return x < y;}};template <class T>class greater{public://将仿函数放成public,要不然class默认是私有的bool operator()(const T& x, const T& y)const{return x > y;}};
}
template<class T, class Compare>
void BubbleSort(T* a, int n, const Compare com)//传一个仿函数类型,这里的Compare是一个逻辑泛型。
//仿函数没有传引用,因为传值拷贝的代价不大,仿函数所在类中没有成员变量,所以其对象所占字节大小为1,代价很小。
{for (int j = 0; j < n; ++j){int exchange = 0;for (int i = 1; i < n - j; ++i){//if (a[i] < a[i - 1])if (com(a[i], a[i - 1]))//我们不希望这里是写死的,而是希望这里是一个泛型,通过所传参数的不同,调用达到不同{swap(a[i - 1], a[i]);exchange = 1;}}if (exchange == 0){break;}}
}
int main()
{wyn::less<int> lessFunc;wyn::greater<int> greaterFunc;lessFunc(1, 2);//你以为lessFunc是个函数名,但是lessFunc是一个仿函数的对象,函数对象调用运算符重载//lessFunc.operator()(1,2);//C语言解决升序降序的问题是通过函数指针来解决的,传一个函数指针,通过调用函数指针来实现升序和降序//C++觉得使用函数指针太挫了,尤其函数指针的定义形式还特别的长。//函数模板一般是推演实例化,类模板一般是显示实例化int arr[] = { 1,3,4,5,6,7,8,2,1 };BubbleSort(arr, sizeof(arr) / sizeof(int), lessFunc);//传lessFunc,而不是函数指针//BubbleSort(arr, sizeof(arr) / sizeof(int), wyn::less<int>());//这里可以传一个匿名对象for (auto e : arr){cout << e << " ";}cout << endl;//BubbleSort(arr, sizeof(arr) / sizeof(int), greaterFunc);BubbleSort(arr, sizeof(arr) / sizeof(int), wyn::greater<int>());for (auto e : arr){cout << e << " ";}cout << endl;//利用仿函数的函数对象,取代C语言的函数指针回调这样比较挫的方式。return 0;
}
二、priority_queue中的仿函数
1.模拟实现优先级队列
1.1 优先级队列的本质(底层容器为vector的适配器)
1.
优先级队列实际就是数据结构初阶所学的堆,堆的本质就是优先级,父节点比子节点大就是大堆,父节点比子节点小就是小堆,这其实就是优先级队列。
可以看到优先级队列中的核心成员函数包括top,push,pop以及迭代器区间为参的构造函数。

2.
priority_queue和queue以及stack一样,他们都是由底层容器适配出来的适配器,之不过priority_queue采用的适配容器不再是deque而是vector,选择vector的原因也非常简单,在调用向上或向下调整算法时,需要大量频繁的进行下标随机访问,这样的情境下,vector就可以完美展现出自己结构的绝对优势。
1.2 向下调整算法建堆
1.
在建堆时如果采用向上调整算法建堆,则算法时间复杂度为O(N*logN),如果采用向下调整算法,则时间复杂度为O(N),所以在建堆时,为了提升效率,采用向下调整算法来进行建堆。
堆的向上向下调整算法的分析
2.
在实现时还是有很多坑的,找出子节点中两个的最大一个和父节点进行比较,但是父节点不一定有右孩子,所以如果你上来就定义left_child和right_child的话,逻辑就出问题了,你只能定义一个child,是否有右孩子还需要进行判断。
3.
这里还涉及一个编程技巧,我们先假设child是子节点中大的那个,然后后面在判断,如果有右孩子,并且右孩子大于左孩子,那我们就让child+=1,这样child始终都表示的是孩子结点中最大的那个结点。(这样的方法称之为假设法,如果假设错误,我们就修改一下,让假设变成对的即可)
4.
向下调整算法的结束条件就是父节点的child小于堆的size大小。
5.
在利用迭代器区间为参的构造函数构造优先级队列时,使用的也是向下调整算法,从堆的倒数第二层的父节点开始进行遍历,依次进行向下调整,直到父节点为根节点时,是最后一次调整。
void adjust_down(size_t parent)//默认建成大堆
{//父结点一定有左孩子,但不一定有右孩子,所以下面的定义方式是错的。//size_t left = parent * 2 + 1, right = parent * 2 + 2;size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && _con[child] < _con[child + 1])//必须保证在有右孩子的前提下才能child+=1child += 1;if(_con[parent]<_con[child]){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
template <class InputIterator>
priority_queue(InputIterator first,InputIterator last):_con(first,last)
{for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i){adjust_down(i);//对于建堆来说,向下调整算法比较高,因为不用管最后一行的元素}
}
1.3 pop堆顶元素时向下调整算法重新调整堆
1.
如果直接pop堆顶元素,利用vector挪动数据的特征,然后从根节点位置开始向下调整堆,这样的方法确实可以将堆重新搞好。
但是挪动数据的消耗可不低,而且一旦挪动数据势必会打乱堆的结构,再次向下调整,那就不是向下调整了,而是向下重新建堆,这也会带来性能的消耗。
2.
所以在pop后,我们采用首尾元素交换的方法,然后尾删掉交换后的尾部元素,最后再从根节点向下调整建堆,而不是在打乱堆结构之后向下调整建堆,这样的方式性能就会高很多了。
void pop()
{swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);//pop交换元素之后,老大可能坐的位置不稳了,我们需要判断他是否还有资格坐在老大的位置。
}
1.4 push堆尾元素时向上调整算法重新调整堆
1.
push队尾元素后,我们用父节点和子节点进行比较,直到child到根节点位置的时候,循环结束,利用的思想还是迭代,将父节点和子节点的位置不断向上迭代,直到堆结构调整完毕。
2.
向上和向下调整的核心思想实际都是一样的,都是用父节点和子节点进行比较,唯一不同的就是在建堆这个场景下,向下调整无需考虑最后一层结点,而向下调整需要从最后一层结点开始调整。
两个算法就是一个将父子结点位置向下迭代(adjust_down),一个将父子结点位置向上迭代(adjust_up)。
void adjust_up(size_t child)//默认建成大堆
{int parent = (child - 1) / 2;while (child > 0){if (_con[child] > _con[parent]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}elsebreak;}
}
void push(const T& x)
{_con.push_back(x);adjust_up(_con.size() - 1);//push插入子结点后,需要向上欺师灭祖,调整自己在族谱的地位。
}
1.5 priority_queue的OJ题
数组中的第K个最大元素
1.
我们可以直接利用优先级队列的结构特点,先利用vector的迭代器区间构造一个默认是大堆的优先级队列,然后依次pop k-1次堆顶的数据,最后的堆顶数据就是第K个最大的元素,直接返回即可。
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {priority_queue<int> q(nums.begin(),nums.end());while(--k)q.pop();return q.top();}
};
2.
上面那样的方法,需要不断的挪动数据,而且每次都会打乱堆结构,效率比较低。另一种方法就是建造k个数的小堆,然后遍历剩余的vector元素,只要元素大于小堆堆顶元素,我们就pop小堆,然后将遍历到的元素push到小堆里面,等到数组遍历结束之后,小堆中的元素就是数组中前k个最大的元素,小堆堆顶就是第k个最大的元素,然后将此元素返回即可。
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {priority_queue<int, vector<int>, greater<int>> kq(nums.begin(), nums.begin()+k);//构造k个数的小堆for(int i=k; i<nums.size(); i++){if(nums[i] > kq.top()){kq.pop();kq.push(nums[i]);}}return kq.top();}
};
2.在优先级队列中增加仿函数(类模板参数和函数模板参数的不同)
1.
在优先级队列中增加仿函数也是比较简单的,具体的逻辑和前面所说的冒泡排序实际是差不多的,唯一不同的是,冒泡排序那里是函数模板,对于函数模板所传参数是仿函数实例化出来的对象,或者是函数指针类型定义出来的指针变量,所以函数模板接收的参数是变量或者对象。而priority_queue是一个类,类模板接受的是类型,是仿函数这样的自定义类型,或者是其他的内置类型。
2.
下面实现中,我们可以给priority_queue的成员变量多加一个仿函数按照所传类模板参数实例化出来的对象,这样的话只要将adjust_down和adjust_up里面比较的逻辑换成仿函数对象的operator()调用即可,这样的priority_queue就可以根据类模板参数的不同实例化出不同的类,默认建大堆,但只要传greater< int >仿函数,优先级队列就可以建小堆了。
namespace wyn
{template <class T>class less{public:bool operator()(const T& x, const T& y)const{return x < y;}};template <class T>class greater{public://将仿函数放成public,要不然class默认是私有的bool operator()(const T& x, const T& y)const{return x > y;}};//模板的第三个缺省参数是仿函数,仿函数是一种自定义类型,像类一样,和vector<T>地位一样。template <class T,class Container = vector<T>,class compare = less<T>>//默认建堆用的是向下调整,父节点向下和子节点比较,如果父结点小于子节点,发生交换,所以compare缺省参数是less<T>class priority_queue{public://只要我们写了构造函数,编译器就不会默认生成,无论你写的是带参的还是不带参的构造,编译器都不会生成。priority_queue()//自己写一个无参的构造函数{}template <class InputIterator>priority_queue(InputIterator first,InputIterator last):_con(first,last){for (size_t i = (_con.size() - 1 - 1) / 2; i >= 0; --i){adjust_down(i);//对于建堆来说,向下调整算法比较高,因为不用管最后一行的元素}}void adjust_up(size_t child)//默认建成大堆{//int parent = (child - 1) / 2;//我们传child==0时,parent是-1,下面会发生越界访问。size_t parent = (child - 1) / 2;while (child > 0){//if (_con[child] > _con[parent])if (comp(_con[parent],_con[child]))//comp为less<T>()匿名对象时,父节点小于子节点发生交换,默认建大堆{swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}elsebreak;}}void adjust_down(size_t parent)//默认建成大堆{//父结点一定有左孩子,但不一定有右孩子,所以下面的定义方式是错的。//size_t left = parent * 2 + 1, right = parent * 2 + 2;size_t child = parent * 2 + 1;//while (child < _con.size())while (child < _con.size()){//if (child + 1 < _con.size() && _con[child] < _con[child + 1])//必须保证在有右孩子的前提下才能child+=1if (child + 1 < _con.size() && comp(_con[child],_con[child+1]))child += 1;//if(_con[parent]<_con[child])if (comp(_con[parent],_con[child]))//这里不是死的,取决于所传的仿函数对象是什么。{swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}elsebreak;}}void push(const T& x){_con.push_back(x);adjust_up(_con.size() - 1);//push插入子结点后,需要向上欺师灭祖,调整自己在族谱的地位。}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);//pop交换元素之后,老大可能坐的位置不稳了,我们需要判断他是否还有资格坐在老大的位置。}const T& top()const//非const和const对象都能调用{return _con[0];}bool empty(){return _con.empty();}size_t size()const{return _con.size();}private:Container _con;//成员变量为自定义类型实例化出来的对象。compare comp;//仿函数实例化出来的comp对象};
}
测试wyn优先级队列的仿函数
int main()
{wyn::priority_queue<int> pq;//默认建大堆,和库里面的priority_queue保持一致//wyn::priority_queue<int, vector<int>, greater<int>> pq;//大于建小堆,出来的是升序pq.push(3);pq.push(1);pq.push(2);pq.push(5);pq.push(7);pq.push(8);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;//由依次取堆顶元素后的打印结果可知,默认是大堆.//算法库的默认排序是升序,推荐传参数为随机迭代器sort(RandomAccessIterator first,RandomAccessIterator last)//优先级队列适配器提供的top返回的是const引用,不允许被修改,如果你修改数据之后,还得手动调用向下调整算法,//库就需要暴露向下调整算法,这破坏了封装性,所以不可能提供给你普通引用,让你有修改数据的可能性。return 0;
}
3.仿函数的高级用法(当原有仿函数无法满足要求时,需要重新写满足要求的仿函数)
1.
当优先级队列存储的数据为日期类对象时,在push对象到priority_queue后,一定会出现比较两个日期大小的情况,所以我们必须在日期类里面提供operator>()和operator<()的运算符重载函数,在发生比较时,会先调用仿函数,然后仿函数内部比较对象时,日期类对象就会调用运算符重载。
2.
但是当优先级队列存储的数据不再是日期类对象,而是日期类对象的地址时,那在优先级队列内部比较的时候,就不再是比较日期了,而变成比较地址的大小了,但是各个对象之间的地址又没有关系,这个时候原有的仿函数无法满足我们的要求了,因为我们不是简单的比较存储内容之间的大小了,而是要比较对象地址所指向的内容,那么这个时候就需要重新写仿函数。
3.
重新写的仿函数也比较简单,只需要将优先级队列内容先进行解引用,拿到地址所指向的内容后,再对指向的内容进行比较,这个时候就回到刚开始的日期类对象之间的运算符重载的调用了。
4.
在显示实例化类模板时,我们就不再使用之前的仿函数,而是使用新写的仿函数,这个仿函数可以支持优先级队列存储内容为日期类对象地址的这样一种情况。
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d)//友元函数{_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};
struct PDateLess
{bool operator()(const Date* d1, const Date* d2){return *d1 < *d2;//直接调用成员函数}
};
struct PDateGreater
{bool operator()(const Date* d1, const Date* d2){return *d1 > *d2;}
};void TestPriorityQueue()
{// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q1;q1.push(Date(2018, 10, 29));//让优先级队列存储日期类的匿名构造q1.push(Date(2018, 10, 28));q1.push(Date(2018, 10, 30));cout << q1.top() << endl;// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q2;//用库里面模板的仿函数q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));cout << q2.top() << endl;//大堆priority_queue<Date*, vector<Date*>, PDateLess> q3;//用自己写的仿函数,没搞模板,这里只针对日期类,不用模板也行。q3.push(new Date(2018, 10, 29));q3.push(new Date(2018, 10, 28));q3.push(new Date(2018, 10, 30));cout << *q3.top() << endl;// 如果要创建小堆,需要用户提供>的重载//小堆priority_queue<Date*,vector<Date*>,PDateGreater> q4;//优先级队列底层的vector存的是日期类的指针,比较大小的时候按照日期类对象的地址进行比较,而不是日期的大小进行比较//所以我们需要自己写仿函数,用wyn里的那个仿函数已经无法满足我们的要求了。q4.push(new Date(2018, 10, 29));q4.push(new Date(2018, 10, 28));q4.push(new Date(2018, 10, 30));cout << *q4.top() << endl;
}int main()
{TestPriorityQueue();return 0;
}
三、reverse_iterator(正向迭代器适配器)
1.反向迭代器的思想(代码复用,适配模式,类封装)
1.
单向迭代器是不用支持反向迭代器的,例如单链表的迭代器就是单向迭代器,但是双向迭代器和随机迭代器都要支持反向迭代器,从使用的角度来看,其实反向迭代器的++就是正向迭代器的 - -,反向迭代器的 - -就是正向迭代器的++,只不过反向迭代器的rbegin是从end的前一个位置开始的,他的rend是到begin位置结束的。
2.
所以从上面反向迭代器和正向迭代器的关系我们就可以看出一些猫腻,反向迭代器的功能完全可以由正向迭代器来实现,那我们是不是可以封装正向迭代器变成一个新的类,这个类实例化出的对象就可以满足反向迭代器的要求。这里的思想实际又回到list的迭代器实现那里了,原生指针无法满足list迭代器的要求,那就封装原生指针为一个新的类,让这个类实例化出来的对象能够满足list迭代器的要求。是不是回到当初类封装的思想了呢?
3.
所以反向迭代器就是正向迭代器适配器,这里还是利用已有的东西封装出你想要的东西的设计思想,这样的思想就是适配模式。反向迭代器也支持++ - - * 解引用→!=等运算符重载,我们利用相应的正向迭代器完成这些运算符重载的功能。
4.
我们用一个类模板来完成反向迭代器的泛型编程,这样无论你是什么容器的正向迭代器,我都可以适配出相应的反向迭代器,反向迭代器的类模板与正向迭代器很相似,后两个参数分别为T&和T*,在实例化反向迭代器时,可以传const或非const的模板参数,以此来实例化出const或非const反向迭代器。
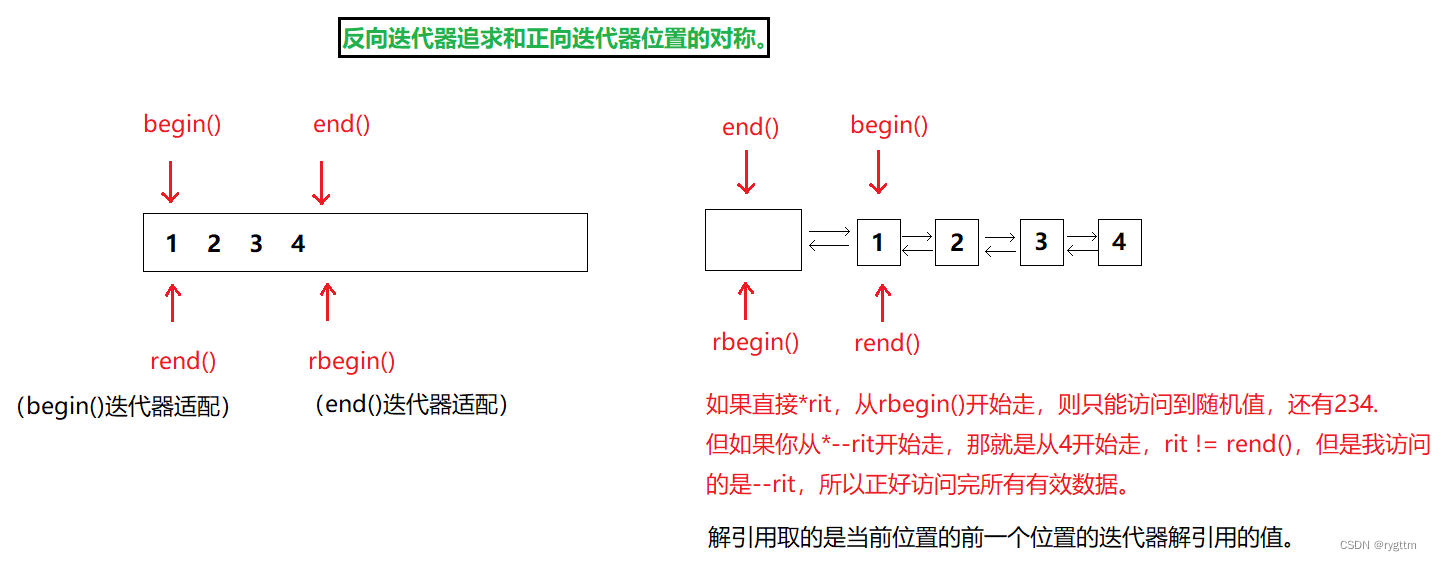
2.反向迭代器与正向迭代器位置的对称
1.
访问反向迭代器数据时,我们返回当前位置的前一个位置的迭代器,这样就可以正好访问完所有的有效数据,否则对于链表来说rbegin指向的正好是头结点位置,并且遍历的时候rbegin!=rend的话,rend位置的数据还无法访问到。
但又为了支持两个迭代器的对称,所以在解引用反向迭代器时,返回的是前一个位置的迭代器内容,修改完*运算符重载后,→的运算符重载也会由于代码复用被修改,我们无需关心。
Ref operator*()
{Iterator tmp = _it;return *--tmp;//返回的是当前位置的前一个位置的迭代器内容
}
Ptr operator->()
{return &(*_it);
}
2.
实现const反向迭代器时,可以增加模板参数来解决,道理和之前实现const正向迭代器类似,这里也增加了Ref和Ptr两个模板参数,通过实例化类模板时所传参数便可以实现const_reverse_iterator
template <class Iterator, class Ref, class Ptr>
//用传过来的正向迭代器去适配出反向迭代器,这里是一个迭代器的模板,所有容器的迭代器都要适配出反向迭代器。
//Ref和Ptr分别对应const或非const版本的数据类型和数据类型的指针,对应着实现*和→两种解引用运算符的重载函数
class ReverseIterator
{typedef ReverseIterator<Iterator, Ref, Ptr> Self;
public:ReverseIterator(Iterator it)//用正向迭代器构造反向迭代器:_it(it){}Ref operator*(){Iterator tmp = _it;return *--tmp;//返回的是当前位置的前一个位置的迭代器内容}Ptr operator->(){return &(*_it);}Self& operator++(){--_it;//只有双向迭代器和随机迭代器需要反向迭代器,单链表的单向迭代器是不需要反向迭代器的,因为他的迭代器只能++不能--return *this;}Self& operator--(){++_it;return *this;}bool operator!=(const Self& s)const{return _it != s._it;//两个由正向迭代器适配出来的反向迭代器进行比较。}
private:Iterator _it;//这里的迭代器有可能是原生指针,也有可能是类封装后迭代器类实例化出的对象。
};
3.
下面的vector和list容器都可以通过自身的正向迭代器来完成反向迭代器的适配。
#include "Iterator.h"
namespace wyn
{template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;typedef ReverseIterator<iterator, T&, T*> reverse_iterator;typedef ReverseIterator<const_iterator, T&, T*> const_reverse_iterator;reverse_iterator rbegin(){return reverse_iterator(end());}reverse_iterator rend(){return reverse_iterator(begin());}const_reverse_iterator rbegin()const{return const_reverse_iterator(end());}const_reverse_iterator rend()const{return const_reverse_iterator(begin());}}
template<class T>class list{typedef list_node<T> node;public:typedef __list_iterator<T,T&,T*> iterator;//iterator是类模板的typedef,模板也是类型,只不过还没有实例化//typedef __list_const_iterator<T> const_iterator;typedef __list_iterator<T,const T&,const T*> const_iterator;typedef ReverseIterator<iterator, T&, T*> reverse_iterator;typedef ReverseIterator<const_iterator, const T&, const T*> const_reverse_iterator;//反向迭代器就是正向迭代器的适配器reverse_iterator rbegin(){return reverse_iterator(end());}reverse_iterator rend(){return reverse_iterator(begin());}const_reverse_iterator rbegin()const{return const_reverse_iterator(end());}const_reverse_iterator rend()const{return const_reverse_iterator(begin());}}
相关文章:
【C++】通过priority_queue、reverse_iterator加深对于适配器和仿函数的理解
苦尽甘来 文章目录一、仿函数(仿函数就是一个封装()运算符重载的类)1.C语言的函数指针2.C的仿函数对象二、priority_queue中的仿函数1.模拟实现优先级队列1.1 优先级队列的本质(底层容器为vector的适配器)1.2 向下调整算法建堆1.3…...

网络安全 -- 常见的攻击方式和防守
网络安全 – 常见的攻击方式和防守 一 . 网页中出现黑链 特点: 隐藏,不易发现,字体大小是0,表面上看不出来,代码层面可以查出来,也可能极限偏移,颜色一致 表现: 多表现为非法植入链接,一般点击会跳转至其他网页 例如: 1.澳门新葡京等赌博网站,获取流量,有人甚至会充钱参与赌…...
Android中实现滑动的7种方法
Android中实现滑动的7种方法前置知识Android坐标系视图坐标系触控事件---MotionEvent获取坐标的方法实现滑动的7种方法layout方法offsetLeftAndRight()和offsetTopAndBottom()LayoutParamsscrollTo和scrollByScroller属性动画ViewDragHelper参考前置知识 Android坐标系 Andro…...
【hadoop】介绍
目录 介绍 版本 优势 大数据技术生态体系 介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 解决 存储和分析计算Google在大数据方面的三篇论文GFS --->HDFS Map-Reduce --->MR BigTable --->HBaseHadoop创始人Doug Cutting版本 Hadoop 三大发行版本&a…...
【C语言】有关的经典题型内含数组及递归函数题型讲解(入门适用)
C语音经典题型1. 在屏幕上输出9*9乘法口诀表2. 求10 个整数中最大值3. 计算1/1-1/21/3-1/41/5 …… 1/99 - 1/100 的值,打印出结果4. 编写程序数一下 1到 100 的所有整数中出现多少个数字95. 能把函数处理结果的二个数据返回给主调函数6. 实现一个函数,…...
MyBatis操作数据库
目录 MyBatis 功能架构 学习MyBatis 第一个MyBatis查询 1、创建数据库和表 2、搭建MyBatis开发环境 2.1、在项目中添加MyBatis框架 2.2、配置数据库连接信息 2.3、配置MyBatis中xml的保存路径(规则) 3、添加业务代码 3.1、创建实体类 3.2、构…...
与Object.values(obj)的用法)
Object.keys(obj)与Object.values(obj)的用法
语法 Object.keys(obj) 参数:要返回其枚举自身属性的对象 返回值:一个表示给定对象的所有枚举属性的字符串数组 传入对象,返回属性名 1 var obj {a:123,b:345}; 2 console.log(Object.keys(obj)); //[a,b] 处理字符串,返回索…...

关于ES6新特性的总结
目录1.let & const2.解构赋值3.模板字符串4.简化对象写法5.箭头函数6.函数参数的默认值设置7.rest参数8.扩展运算符9.SymbolSymbol特点创建SymbolSymbol使用场景Symbol内置值10.迭代器11.生成器12.Promise基本使用Promise封装读取文件Promise封装ajaxPromise.prototype.the…...

13. CSS 处理
提取 Css 成单独文件CSS 文件目前被打包到 js 文件中,当 js 文件加载时,会创建一个 style 标签来生成样式,加载一个页面的时候,先 html -> js -> css,会有页面闪屏现象,用户体验不好。应该是单独的 Css 文件&…...

One-hot编码
One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。 例如: 自然状态码为:000,001,010,011,100,1…...
Java中的深克隆与浅克隆
浅克隆: 实现Cloneable接口即可实现,浅克隆只对象内部的基础数据类型(包括包装类)被克隆,引用数据类型(负责对象)会被使用引用的方式传递。 简单来说,就是浅克隆属性如果是复杂对象…...

如何使用MyBatis框架实现对数据库的增删查改?
目录:1.创建MyBatis项目以及如何配置2.MyBatis操作数据库的模式3.实现增删查改注意:在我们操作数据库之前,先要保证我们已经在数据库建好了一张表。创建MyBatis项目以及如何配置我们在创建项目的时候,引入MyBatis相关依赖配置数据…...
结构体内存大小
000、前言 要想计算结构体内存大小,就会涉及到一个结构体内存对齐的问题,而不是对其成员进行简单的加运算 (1)在写本博客之前 有位同学和我讨论了一个学校的题目,题目如下: 我借这道题目问了另外一位同…...
gerrit操作和jinkens编译合入代码
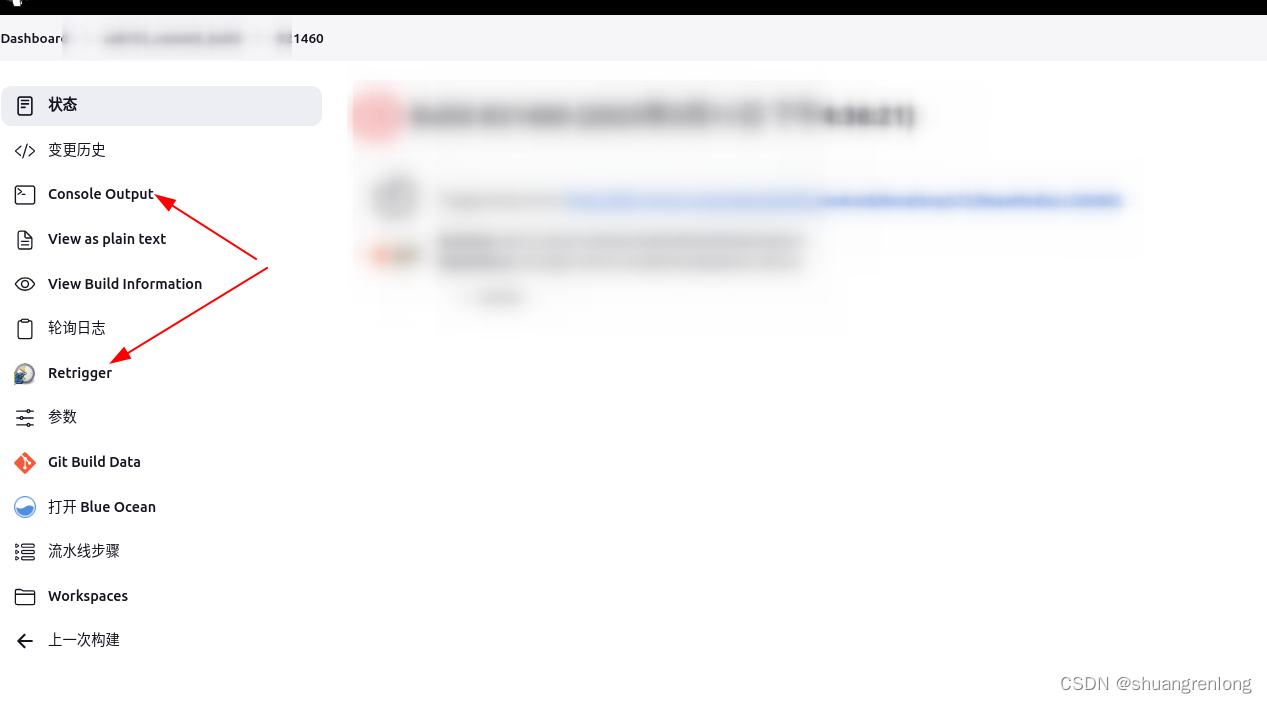
gerrit 先 查看自己的push 找到后添加reviewer 填写邮箱开头就可以出来 记得1 然后send 让人review 编译不过,gerrit上查看 1.是不是checkstyle问题 2.编译不过,去jinkens查看 先retrigger重新编译 如果发现多次编译失败 则要看下console output 查…...

网络工程师面试题(面试必看)(3)
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 前言 本系列将会提供网络工程师面试题,由多位专家整合出本系列面试题,包含上百家面试时的问题。面试必考率达到80%,本系列共86道题…...
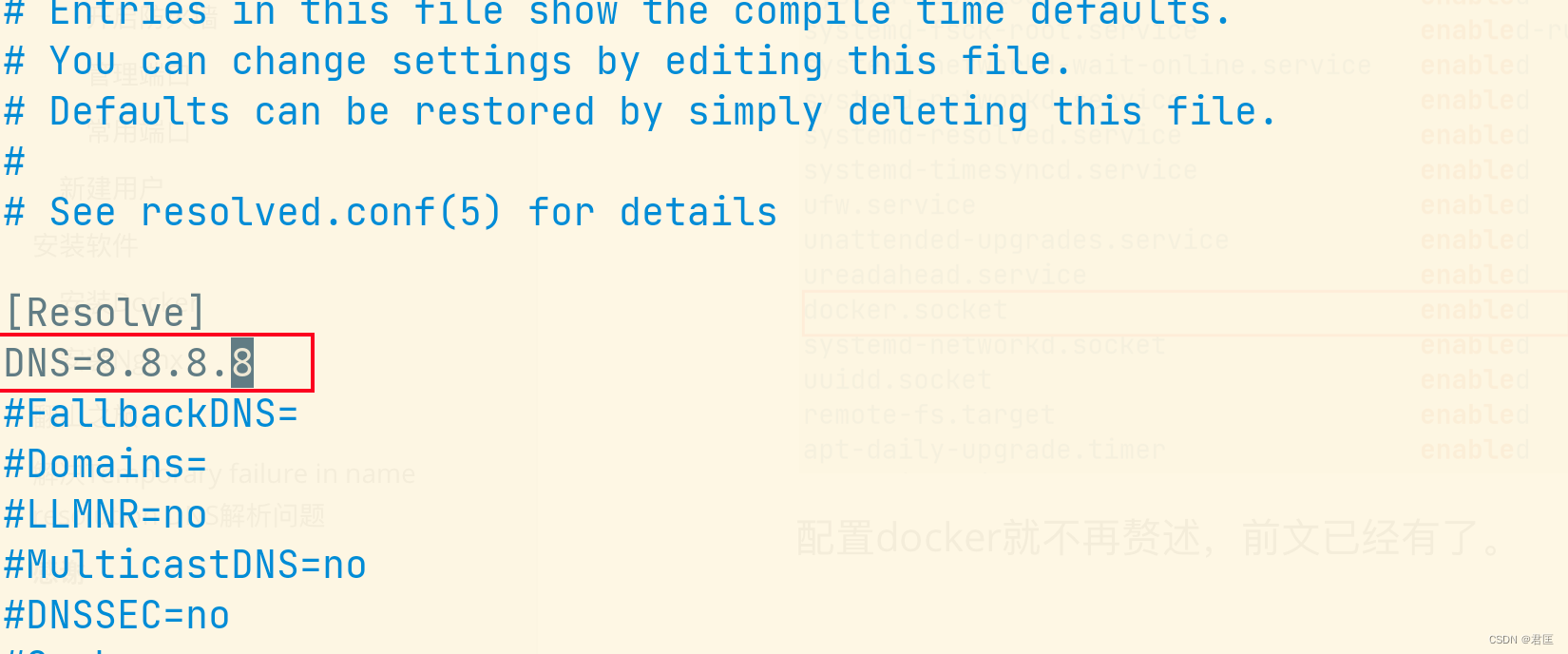
第N次重装系统之Ubtntu
前言又一次换了服务器,由于centOS已经完成了自己的生命周期,接下来我会转去使用Ubtntu系统。当然,大部分docker命令是不会收到影响的,但是一部分安装过程可能就要重新学习了。其实这个系统也有自己的老牌包管理器apt,所…...
一个 适用 vue3 ts h5移动端 table组件
vue3-h5-table 介绍 适用于 vue3 ts 的 h5 移动端项目 table 组件 支持 左侧固定 滑动 每行点击回调 支持 指定列排序 链接 :https://github.com/duKD/vue3-h5-table 效果 props说明minTableHeight表格最小高度 可选 默认600rowNum表格显示几行 可选 默认 6he…...

Vue.js 生产打包上线实战
项目管理后台采用Vue.js 架构,开发完毕后设计到打包上传到服务器发布。 发布成功后,总结出主要要决绝两个主要问题: 1.打包前,环境设置 2.上传到服务器,直接放在Tomcat中出现跨域访问问题。 此次项目实际处理方法为…...

C语言指针的算术运算
C语言指针的算术运算 C语言中,指针是一种非常重要的数据类型。除了可以指向特定的内存地址外,指针还可以进行算术运算。指针的算术运算包括加、减、比较等操作,下面我们将详细介绍这些运算符的使用方法,并提供实际的示例。 指针…...
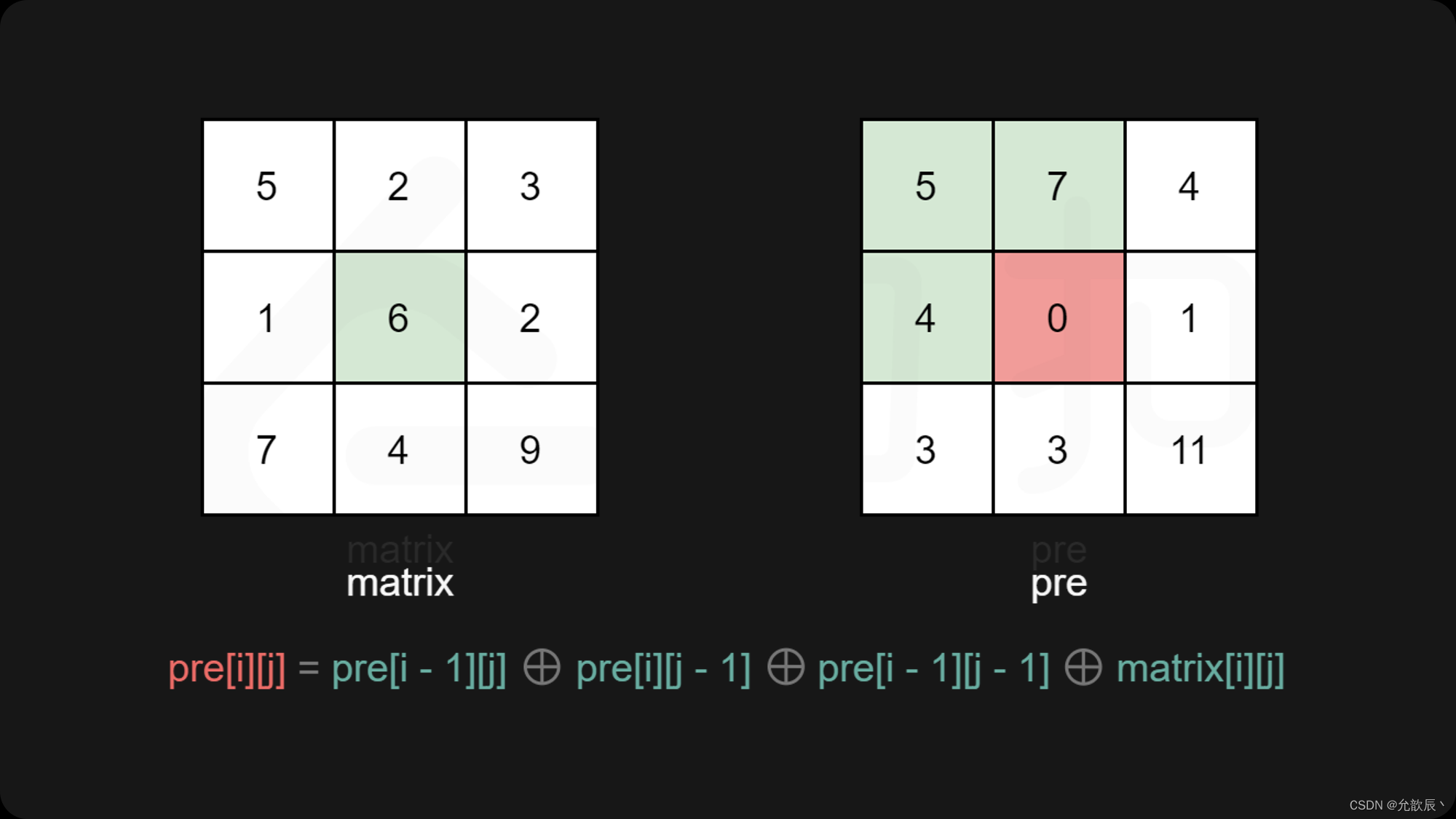
快速排序/快速选择算法
一.快速排序 1.基本介绍 快速排序(Quicksort〉是对冒泡排序的一种改进,都属于交换排序。基本思想是:通过一趟排序将要排序的数据分割成独立的两部分(每次选择中轴值),中轴值左边的元素小于中轴值,中轴值右边的元素全部大于中轴值(但不要求有序)&#x…...

别再搞混了!AUTOSAR通信栈里,PduR和CanTp到底为谁打工?一个DCM诊断请求的完整旅程
AUTOSAR通信栈揭秘:诊断请求如何穿越PduR与CanTp的迷宫 在汽车电子系统的开发中,诊断通信就像车辆的"健康检查系统",而AUTOSAR架构中的通信栈则是确保这些诊断命令能够准确传达的神经网络。许多工程师第一次接触AUTOSAR通信栈时&am…...

别再只会发文本了!SpringBoot整合钉钉机器人,这5种高级消息模板让你的通知更专业
SpringBoot与钉钉机器人:五种高级消息模板实战指南 如果你还在用单调的文本消息推送系统通知,那么你的团队协作工具可能只发挥了50%的潜力。钉钉机器人提供的富文本消息类型,能够将枯燥的系统通知转化为直观、交互式的信息卡片,显…...

ARM Cortex-M中断状态寄存器实战:从配置到调试的完整指南
ARM Cortex-M中断状态寄存器实战:从配置到调试的完整指南 在嵌入式开发领域,中断处理是系统实时响应的核心机制。作为ARM Cortex-M系列处理器的开发者,深入理解中断状态寄存器(Interrupt Status Register)的工作原理和操作技巧,能…...

三维点云到二维图像投影的实战指南:从原理到代码实现
1. 三维点云投影二维图像的核心原理 第一次接触三维点云投影时,我也被各种坐标系转换绕得头晕。后来发现只要抓住一个核心:三维到二维的投影本质上是坐标系转换的接力赛。想象你拿着手机拍照,物体从现实世界到手机屏幕的旅程,就是…...

Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导+代码生成真实截图
Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导代码生成真实截图 1. 模型能力概览 Cogito v1 预览版是Deep Cogito推出的混合推理模型系列,在大多数标准基准测试中均超越了同等规模下最优的开源模型。这个3B参数的模型在编码、STEM题目解答、指…...

Qwen3-4B-Instruct-2507从入门到精通:Chainlit界面定制化教程
Qwen3-4B-Instruct-2507从入门到精通:Chainlit界面定制化教程 1. 引言:为什么选择Qwen3-4B-Instruct-2507? 如果你正在寻找一个既强大又轻量、既能快速部署又能灵活定制界面的AI模型,那么Qwen3-4B-Instruct-2507绝对值得你深入了…...

搞懂 SAP Fiori 前端服务器授权模型:从看得见应用,到真正拿到数据
在很多 SAP 项目里,权限问题最容易制造一种很迷惑的现象:用户明明已经拿到了角色,却还是打不开应用;或者磁贴已经能看见了,点进去却报错;再或者应用能启动,却一条业务数据都读不出来。要把这类问题讲清楚,关键不在于死记事务码,而在于真正理解 SAP Fiori 的授权是如何…...

从Blender到虚幻引擎:除了FBX,试试GLTF格式导入的完整流程与优势对比
从Blender到虚幻引擎:GLTF格式导入的完整流程与优势解析 在三维内容创作领域,Blender与虚幻引擎的组合已经成为许多专业团队的标准工具链。当我们需要将精心制作的模型从Blender迁移到虚幻引擎时,传统的FBX格式虽然广为人知,但GLT…...

降AIGC哪家强?2026零成本保姆级教程:DeepSeek/Kimi/豆包专属降重指令实测与差异解析
很多时候大学生写论文逻辑太严谨、话术太规范,反而会导致AI率过高,且一旦AI率过高,轻则退回重改,重则取消答辩资格,这后果谁都担不起。 为了帮大家有效降低aigc率,这周我专门针对目前市面上最主流的三款大…...

如何用Python零依赖快速获取百度搜索结果?python-baidusearch深度解析
如何用Python零依赖快速获取百度搜索结果?python-baidusearch深度解析 【免费下载链接】python-baidusearch 自己手写的百度搜索接口的封装,pip安装,支持命令行执行。Baidu Search unofficial API for Python with no external dependencies …...