Elasticsearch:倒数排序融合 - Reciprocal rank fusion - 8.14
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。语法可能会在正式发布之前发生变化。Elastic 将努力修复任何问题,但技术预览中的功能不受官方正式发布功能的支持 SLA 约束。
倒数排序融合 (reciprocal rank fusion - RRF) 是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法。RRF 无需调整,并且不同的相关性指标不必相互关联即可获得高质量的结果。
注意:在今天的文章中,RFF 有别于之前版本。这个描述是从 8.14.0 开始的。在这个版本之前,请参阅 “Elasticsearch:倒数排序融合 - Reciprocal rank fusion (RRF)”。8.13.0 版本的描述在地址可以看到。在它里面它使用 sub_searches 而不是 rertievers。
RRF 使用以下公式来确定对每个文档进行排名的分数:
score = 0.0
for q in queries:if d in result(q):score += 1.0 / ( k + rank( result(q), d ) )
return score# where
# k is a ranking constant
# q is a query in the set of queries
# d is a document in the result set of q
# result(q) is the result set of q
# rank( result(q), d ) is d's rank within the result(q) starting from 1一个例子是:

倒数排序融合 API
你可以将 RRF 用作 search 的一部分,使用来自使用 RRF 检索器的子检索器(child retrievers)组合的独立顶级文档集(结果集)来组合和排名文档。排名至少需要两个子检索器。
RRF 检索器是一个可选对象,定义为搜索请求的检索器参数(retriever parameter)的一部分。 RRF 检索器对象包含以下参数:
| 参数 | 描述 |
|---|---|
| retrievers | (必需,检索器对象数组) 子检索器列表,用于指定哪些返回的顶级文档集将应用 RRF 公式。每个子检索器作为 RRF 公式的一部分具有相等的权重。需要两个或更多个子检索器。 |
| rank_constant | (可选,整数) 此值决定每个查询中单个结果集中的文档对最终排名结果集的影响程度。值越高,表示排名较低的文档影响力越大。此值必须大于或等于 1。默认为 60。 |
| window_size | (可选,整数) 此值决定每个查询的单个结果集的大小。较高的值将提高结果相关性,但会降低性能。最终排名的结果集将缩减为搜索请求的大小。window_size 必须大于或等于 size 且大于或等于 1。默认为 size 参数。 |
使用 RRF 的示例请求:
GET example-index/_search
{"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"term": {"text": "shoes"}}}},{"knn": {"field": "vector","query_vector": [1.25,2,3.5],"k": 50,"num_candidates": 100}}],"window_size": 50,"rank_constant": 20}}
}在上面的例子中,我们独立执行 knn 和标准检索器。然后我们使用 rrf 检索器来合并结果。
- 首先,我们执行 knn 检索器指定的kNN搜索以获取其全局前 50 个结果。
- 其次,我们执行 standard 检索器指定的查询以获取其全局前 50 个结果。
-
然后,在协调节点上,我们将 kNN 搜索热门文档与查询热门文档相结合,并使用来自 rrf 检索器的参数根据 RRF 公式对它们进行排序,以使用默认 size 为 10 获得组合的顶级文档。
注意,如果 knn 搜索中的 k 大于 window_size,则结果将被截断为 window_size。如果 k 小于 window_size,则结果为 k 大小。
倒数排序融合支持的特征
rrf 检索器支持:
- aggregations
- from
rrf 检索器目前不支持:
- scroll
- point in time
- sort
- rescore
- suggesters
- highlighting
- collapse
- explain
- profiling
在使用 rrf 检索器进行搜索时使用不受支持的功能会导致异常。
使用多个 standard 检索器的倒数排序融合
rrf 检索器提供了一种组合和排名多个标准检索器的方法。主要用例是组合来自传统 BM25 查询和 ELSER 查询的顶级文档,以提高相关性。
使用 RRF 和多个 standard 检索器的示例请求:
GET example-index/_search
{"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"term": {"text": "blue shoes sale"}}}},{"standard": {"query": {"text_expansion": {"ml.tokens": {"model_id": "my_elser_model","model_text": "What blue shoes are on sale?"}}}}}],"window_size": 50,"rank_constant": 20}}
}在上面的例子中,我们分别独立执行两个 standard 检索器。然后我们使用 rrf 检索器来合并结果。
- 首先,我们使用标准 BM25 评分算法运行 standard 检索器,指定 “blue shoes sales” 的术语查询。
- 接下来,我们使用 ELSER 评分算法运行 standard 检索器,指定 “What blue shoes are on sale?”的文本扩展查询。
- rrf 检索器允许我们将完全独立的评分算法生成的两个顶级文档集以相等的权重组合在一起。
这不仅消除了使用线性组合确定适当权重的需要,而且 RRF 还显示出比单独查询更高的相关性。
使用子搜索的倒数排学融合
使用子搜索的 RRF 不再受支持。请改用 retriever API。请参阅使用多个标准检索器的示例。
相互排名融合完整示例
我们首先创建一个带有文本字段、向量字段和整数字段的索引映射,并索引多个文档。对于此示例,我们将使用只有一个维度的向量,以便更容易解释排名。
PUT example-index
{"mappings": {"properties": {"text": {"type": "text"},"vector": {"type": "dense_vector","dims": 1,"index": true,"similarity": "l2_norm"},"integer": {"type": "integer"}}}
}PUT example-index/_doc/1
{"text" : "rrf","vector" : [5],"integer": 1
}PUT example-index/_doc/2
{"text" : "rrf rrf","vector" : [4],"integer": 2
}PUT example-index/_doc/3
{"text" : "rrf rrf rrf","vector" : [3],"integer": 1
}PUT example-index/_doc/4
{"text" : "rrf rrf rrf rrf","integer": 2
}PUT example-index/_doc/5
{"vector" : [0],"integer": 1
}POST example-index/_refresh我们现在使用 rrf 检索器执行搜索,其中 standard 检索器指定 BM25 查询,knn 检索器指定 kNN 搜索,以及术语聚合
GET example-index/_search
{"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"term": {"text": "rrf"}}}},{"knn": {"field": "vector","query_vector": [3],"k": 5,"num_candidates": 5}}],"window_size": 5,"rank_constant": 1}},"size": 3,"aggs": {"int_count": {"terms": {"field": "integer"}}}
}我们收到了带有排名 hits 和术语聚合结果的响应。请注意,_score 为空,我们改用 _rank 来显示排名靠前的文档。
{"took": 14,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 5,"relation": "eq"},"max_score": null,"hits": [{"_index": "example-index","_id": "1","_score": null,"_rank": 1,"_source": {"text": "rrf","vector": [5],"integer": 1}},{"_index": "example-index","_id": "3","_score": null,"_rank": 2,"_source": {"text": "rrf rrf rrf","vector": [3],"integer": 1}},{"_index": "example-index","_id": "2","_score": null,"_rank": 3,"_source": {"text": "rrf rrf","vector": [4],"integer": 2}}]},"aggregations": {"int_count": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": 1,"doc_count": 3},{"key": 2,"doc_count": 2}]}}
}让我们分析一下这些命中结果的排名方式。我们首先分别运行指定查询的标准检索器和指定 kNN 搜索的 knn 检索器,以收集它们各自的命中结果。
首先,我们查看 standard 检索器中查询的命中结果。
GET example-index/_search
{"query": {"term": {"text": {"value": "rrf"}}}
}"hits" : [{"_index" : "example-index","_id" : "4","_score" : 0.16152832, "_source" : {"integer" : 2,"text" : "rrf rrf rrf rrf"}},{"_index" : "example-index","_id" : "3", "_score" : 0.15876243,"_source" : {"integer" : 1,"vector" : [3],"text" : "rrf rrf rrf"}},{"_index" : "example-index","_id" : "2", "_score" : 0.15350538,"_source" : {"integer" : 2,"vector" : [4],"text" : "rrf rrf"}},{"_index" : "example-index","_id" : "1", "_score" : 0.13963442,"_source" : {"integer" : 1,"vector" : [5],"text" : "rrf"}}
]- rank 1, _id 4
- rank 2, _id 3
- rank 3, _id 2
- rank 4, _id 1
请注意,我们的第一个结果没有向量字段的值。现在,我们来看看 knn 检索器的 kNN 搜索的结果。
GET example-index/_search
{"knn": {"field": "vector","query_vector": [3],"k": 5,"num_candidates": 5}
}"hits" : [{"_index" : "example-index","_id" : "3", "_score" : 1.0,"_source" : {"integer" : 1,"vector" : [3],"text" : "rrf rrf rrf"}},{"_index" : "example-index","_id" : "2", "_score" : 0.5,"_source" : {"integer" : 2,"vector" : [4],"text" : "rrf rrf"}},{"_index" : "example-index","_id" : "1", "_score" : 0.2,"_source" : {"integer" : 1,"vector" : [5],"text" : "rrf"}},{"_index" : "example-index","_id" : "5", "_score" : 0.1,"_source" : {"integer" : 1,"vector" : [0]}}
]- rank 1, _id 3
- rank 2, _id 2
- rank 3, _id 1
- rank 4, _id 5
我们现在可以获得两个单独排名的结果集,并使用 rrf 检索器的参数对它们应用 RRF 公式以获得最终排名。
# doc | query | knn | score
_id: 1 = 1.0/(1+4) + 1.0/(1+3) = 0.4500
_id: 2 = 1.0/(1+3) + 1.0/(1+2) = 0.5833
_id: 3 = 1.0/(1+2) + 1.0/(1+1) = 0.8333
_id: 4 = 1.0/(1+1) = 0.5000
_id: 5 = 1.0/(1+4) = 0.2000我们根据 RRF 公式对文档进行排序,window_size 为 5,截断 RRF 结果集中 size 为 3 的底部 2 个文档。最终结果为 _id:3 作为 _rank:1,_id:2 作为 _rank:2,_id:4 作为 _rank:3。此排名与原始 RRF 搜索的结果集匹配,符合预期。
RRF 中的分页
使用 rrf 时,你可以使用 from 参数对结果进行分页。由于最终排名完全取决于原始查询排名,因此为了确保分页时的一致性,我们必须确保虽然 from 发生变化,但我们已经看到的顺序保持不变。为此,我们使用固定的 window_size 作为可以进行分页的整个可用结果集。这本质上意味着,如果:
- from + size ≤ window_size :我们可以从最终的 rrf 排名结果集中返回 results[from: from+size] 文档
- from + size > window_size :我们将得到 0 个结果,因为请求超出了可用的 window_size 大小的结果集。
这里要注意的一件重要事情是,由于 window_size 是我们将从各个查询组件中看到的所有结果,因此分页保证了一致性,即,当且仅当 window_size 保持不变时,不会跳过或重复多个页面中的文档。如果 window_size 发生变化,那么结果的顺序也可能会发生变化,即使是相同的排名。
为了说明上述所有内容,让我们考虑以下简化的示例,其中我们有两个查询,queryA 和 queryB 以及它们的排名文档:
| queryA | queryB |
_id: | 1 | 5 |
_id: | 2 | 4 |
_id: | 3 | 3 |
_id: | 4 | 1 |
_id: | | 2 |对于 window_size=5,我们将看到来自 queryA 和 queryB 的所有文档。假设 rank_constant=1,rrf 分数将是:
# doc | queryA | queryB | score
_id: 1 = 1.0/(1+1) + 1.0/(1+4) = 0.7
_id: 2 = 1.0/(1+2) + 1.0/(1+5) = 0.5
_id: 3 = 1.0/(1+3) + 1.0/(1+3) = 0.5
_id: 4 = 1.0/(1+4) + 1.0/(1+2) = 0.533
_id: 5 = 0 + 1.0/(1+1) = 0.5因此,最终排名结果集将是 [1, 4, 2, 3, 5],我们将对其进行分页,因为 window_size == len(results)。在这种情况下,我们将有:
- from=0, size=2 将返回文档 [1, 4],排名为 [1, 2]
- from=2, size=2 将返回文档 [2, 3],排名为 [3, 4]
- from=4, size=2 将返回文档 [5],排名为 [5]
- from=6, size=2 将返回一个空结果集,因为没有更多结果可以迭代
现在,如果我们的 window_size=2,我们只能分别看到查询 queryA 和 queryB 的 [1, 2] 和 [5, 4] 文档。计算一下,我们会发现结果现在会略有不同,因为我们不知道这两个查询中位置 [3: end] 的文档。
# doc | queryA | queryB | score
_id: 1 = 1.0/(1+1) + 0 = 0.5
_id: 2 = 1.0/(1+2) + 0 = 0.33
_id: 4 = 0 + 1.0/(1+2) = 0.33
_id: 5 = 0 + 1.0/(1+1) = 0.5最终排序的结果集将是 [1, 5, 2, 4],并且我们将能够对顶部的 window_size 结果进行分页,即 [1, 5]。因此,对于与上述相同的参数,我们现在将有:
- from=0, size=2 将返回 [1, 5],排名为 [1, 2]
- from=2, size=2 将返回一个空结果集,因为它超出了可用的 window_size 结果范围。
相关文章:
Elasticsearch:倒数排序融合 - Reciprocal rank fusion - 8.14
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。语法可能会在正式发布之前发生变化。Elastic 将努力修复任何问题,但技术预览中的功能不受官方正式发布功能的支持 SLA 约束。 倒数排序融合 (reciprocal rank fusion - RRF) 是一…...
Day13—大语言模型
定义 大语言模型(Large Language Models)是一种基于深度学习的自然语言处理(NLP)模型,用于处理和生成人类语言文本。 一、认识NLP 什么是NLP NLP(Natural Language Processing)࿰…...

php基础语法_面向对象
PHP php代码标记 多种标记来区分php脚本 ASP标记:<% php代码 %> 短标记: 脚本标记: 标准标记(常用): 简写风格: ASP风格:<% php代码 %> 注意:简写风格和ASP风格…...
)
开源模型应用落地-LangChain高阶-LCEL-表达式语言(八)
一、前言 尽管现在的大语言模型已经非常强大,可以解决许多问题,但在处理复杂情况时,仍然需要进行多个步骤或整合不同的流程才能达到最终的目标。然而,现在可以利用langchain来使得模型的应用变得更加直接和简单。 LCEL是什么? LCEL是一种非常灵活和强大的语言,可以帮助您更…...

c# 协议数据计算陀螺仪的角度,带符号
subStrL str.Substring((76 - 8), 2); subStrH str.Substring((78 - 8), 2); Data[7] (short)(Convert.ToInt16(subStrH, 16) * 256 Convert.ToInt16(subStrL, 16));//角度X subStrL str.Substring((80 - 8), 2); subStrH str.Subst…...

ArcGIS arcpy代码工具——批量要素裁剪栅格影像
系列文章目录 ArcGIS arcpy代码工具——批量对MXD文件的页面布局设置修改 ArcGIS arcpy代码工具——数据驱动工具批量导出MXD文档并同步导出图片 ArcGIS arcpy代码工具——将要素属性表字段及要素截图插入word模板 ArcGIS arcpy代码工具——定制属性表字段输出表格 ArcGIS arc…...
discuz插件之优雅草超级列表互动增强v1.2版本更新
https://doc.youyacao.com/9/2142 v1.2更新 discuz插件之优雅草超级列表互动增强v1.2版本更新 [title]20220617 v1.2发布[/title] 增加了对php8的支持 增加了 对discuz3.5的支持...
三、用户中心项目笔记----后端多环境实战+原始部署
后端多环境主要是修改: 依赖的环境地址 数据库地址 缓存地址 消息队列地址 项目端口号 服务器配置 后端怎么去区分不同的环境? 我们后端的SpringBoot项目,通过application.yml添加不同后缀来区分配置文件 application.yml就是公共的配置&a…...
SpringMVC的使用
SpringMVC详情 RequestMapping("/hello") 负责用户的请求路径与后台服务器之间的映射关系 如果请求路径不匹配,则用户报错404 ResponseBody 作用: 将服务器的返回值转化为JSON. 如果服务器返回的是String类型,则按照自身返回. 新增: post请求类型 PostMapping("…...
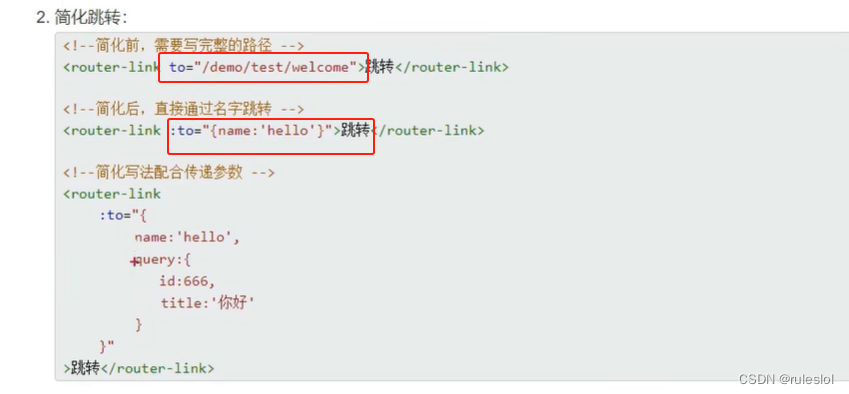
Vue73-命名路由
一、路由的name属性 二、小结...

TrustOne发布一周年成绩单,15000家数智化转型客户的选择!
新一代终端安全TrustOne 发布一周年 交出亮眼成绩单 目前已经为 15000家数智化转型客户 带来高效、全方位的解决方案 TrustOne 新一代终端安全 2023年6月 新一代终端安全TrustOne正式发布,极简新主义的创新理念为数字变革而来; 2023年12月 IDC&…...
)
Nginx实战:故障处理_后端服务正常,nginx偶发502(Bad Gateway)
一、故障场景 用户访问服务偶发报错【502 Bad Gateway】,但是服务后端正常运行。架构如下: #mermaid-svg-4dDszusKEuPgIPlt {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-4dDszusKEuPgIPlt .error-icon{fill:#5…...
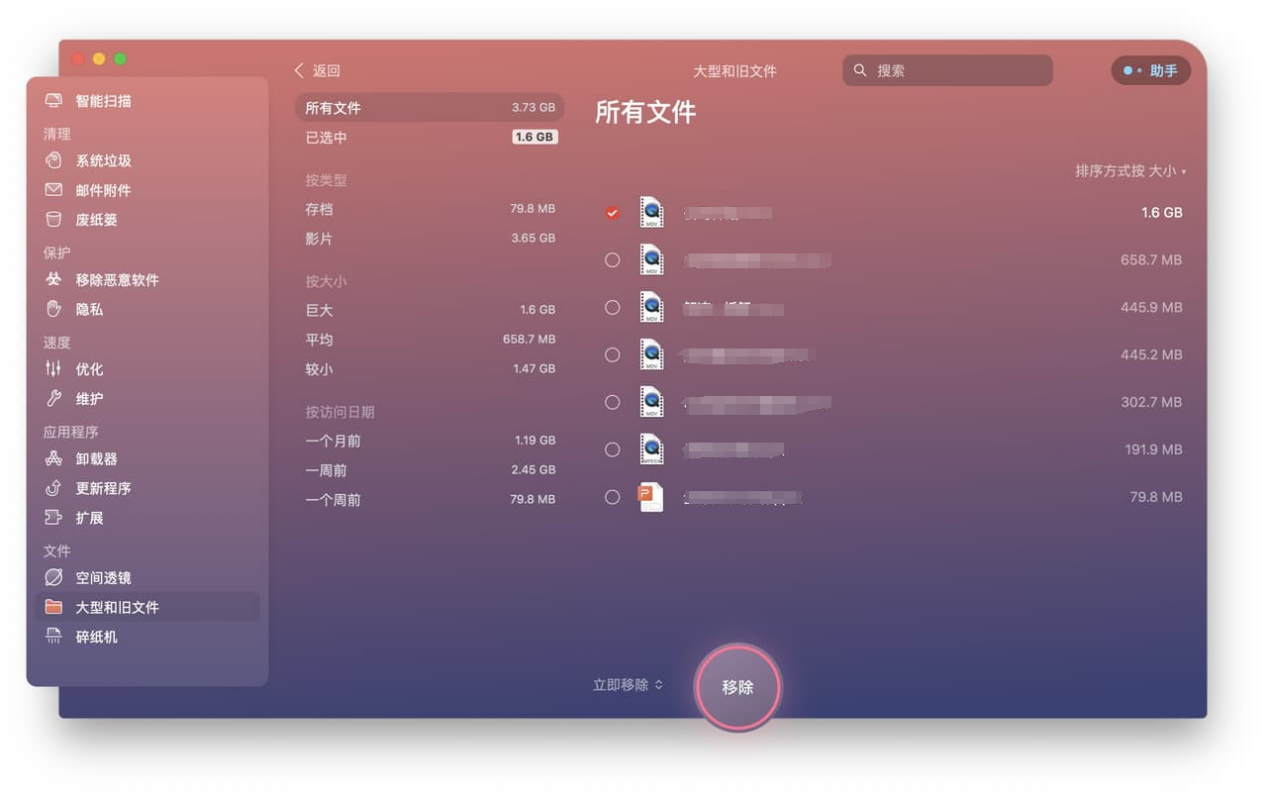
mac系统清理软件哪个好用?CleanMyMac X清理工具轻松拿捏mac
还在为 mac 电脑里的垃圾文件、无用缓存和隐私痕迹而烦恼?想找一个软件直接全面清理优化电脑?维护苹果设备的清洁和高效运行是非常重要的,特别是在设备经过长时间使用后。有效的苹果清理软件不仅可以帮助您节省时间,还能延长设备的…...

拔掉独显提升性能,AMD新一代核显可以通杀主流游戏了
在今年台北电脑展上,AMD 除了带来了全新的 Ryzen 9000 系列。 与此同时也带来了全新的移动端处理器 Ryzen AI 9 HX 300 系列。 来源:AMD 也许是在 AI 领域稍晚一步,AMD 的全新移动端处理器命名直接把 AI 焊在脸上。 也就是咱们今天的主角 R…...

关于单片机那些事?
周期 时钟周期:也叫振荡周期,就是单片机外接晶振的倒数,如12Mhz,周期就是1/12us,最小的时间单位。频率越高,速度越快 指令周期:执行一条指令需要的时间,一般由若干个机器周期组成 …...
第5章 传输层
王道学习 考纲内容 (一)传输层提供的服务 传输层的功能:传输层寻址与端口;无连接服务和面向连接服务 (二)UDP UDP数据报;UDP检验 (三)TCP …...

典型传感器简介及驱动安装
双目视觉传感器 Indemind 传感器简介 INDEMIND M1 是专为开发者提供的一款硬件,采用“双目摄像头IMU”多传感器融合架构与 微秒级时间同步机制,为视觉 SLAM 研究提供精准稳定数据源,以满足 SLAM 研究、导航及 避障开发、视觉动作捕捉开发、…...
linux和Win——显卡驱动、Anaconda及pytorch安装(无需单独安装cuda、cudnn)
今天给新电脑的双系统(windows11和ubuntu22.04)安装了深度学习环境,在此记录一下。 一、Linux系统 (一)安装显卡驱动 (1)在安装Nvidia显卡驱动前,一定要点一下下面的“软件更新器…...
)
机器学习之多模态学习FLAVA(Foundational Language and Vision Alignment)
FLAVA(Foundational Language and Vision Alignment)是Meta AI提出的一种多模态学习模型,旨在处理自然语言和视觉任务。FLAVA通过联合学习文本和图像的特征表示,实现了在多模态任务上的优异性能。 FLAVA的基本概念 多模态学习: 多模态学习涉及同时处理多种类型的数据,例…...

Maven高级-证书校验
文章目录 SSL忽略配置IDEA里配置SSL忽略补充场景 SSL忽略配置 mvn -X clean install -Dmaven.resolver.transportwagon -Dmaven.wagon.http.ssl.insecuretrue -Dmaven.wagon.http.ssl.allowalltrue -Dmaven.wagon.http.ssl.ignore.validity.datestrueIDEA里配置SSL忽略 两个地…...

什么是“中国词元”?——解析中国AI自主生态的核心公式与关键平台
在当前的AI发展阶段,构建自主可控的产业生态已成为关键议题。本文将解析“中国词元”(Chinese Tokens)这一核心概念,并介绍其关键支撑平台——模力方舟Moark。文章面向AI开发者、企业技术决策者及生态关注者,旨在阐明如…...

图形引擎的跨平台之舞:Skia与Direct2D的深度对话
图形引擎的跨平台之舞:Skia与Direct2D的深度对话 【免费下载链接】skia Skia is a complete 2D graphic library for drawing Text, Geometries, and Images. See documentation for contribution instructions. 项目地址: https://gitcode.com/gh_mirrors/ski/sk…...

Ghost区块链集成:NFT内容所有权与分发方案
Ghost区块链集成:NFT内容所有权与分发方案 内容创作者的数字版权困境 传统内容发布平台存在严重的数字版权问题:文章被随意转载、原创收益被平台抽成、作品归属权难以证明。根据2024年《数字内容版权报告》,78%的独立创作者曾遭遇内容侵权&…...

解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南
解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

深入解析Roll:轻量级滚动动画库的设计原理与工程实践
1. 项目概述:一个轻量级、可扩展的滚动动画库在Web前端开发中,滚动动画(Scroll Animation)早已不是新鲜概念。从早期简单的视差效果,到如今复杂的元素交互动画,滚动动画已经成为提升用户体验、增强页面叙事…...

免费APK安装器:Windows上安装Android应用的终极解决方案
免费APK安装器:Windows上安装Android应用的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行Android应用&…...

黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题
黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool 还在为黑苹果的显卡驱动、音频输出和USB识别问题而…...

wBlock Safari扩展架构详解:5个内容拦截扩展的协同工作原理
wBlock Safari扩展架构详解:5个内容拦截扩展的协同工作原理 【免费下载链接】wBlock The next-generation ad blocker for Safari. 项目地址: https://gitcode.com/gh_mirrors/wb/wBlock wBlock是一款下一代Safari广告拦截器,通过创新的多扩展架构…...

为什么MASA全家桶汉化包能彻底改变你的Minecraft模组体验?
为什么MASA全家桶汉化包能彻底改变你的Minecraft模组体验? 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为MASA模组复杂的英文界面而头疼吗?作为中文Minec…...

LaTeX列表排版避坑指南:用enumitem包轻松解决编号重置、缩进和对齐问题
LaTeX列表排版避坑指南:用enumitem包轻松解决编号重置、缩进和对齐问题 在撰写学术论文、技术文档或法律条款时,列表结构是组织内容的重要工具。但LaTeX默认的列表环境往往让用户陷入编号混乱、缩进不一致的泥潭。本文将深入剖析这些痛点的根源ÿ…...