大语言模型系列-Transformer
DeepSeek
Transformer模型是深度学习领域中一种革命性的架构,它在自然语言处理(NLP)任务中取得了巨大的成功。Transformer模型由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,其核心思想是利用自注意力(self-attention)机制来捕捉输入序列中的长距离依赖关系,从而有效地处理序列数据。
Transformer模型的主要组成部分:
-
编码器(Encoder):
-
由多个相同的层堆叠而成,每一层包含两个主要的子层结构:多头自注意力(Multi-Head Self-Attention)机制和位置全连接前馈网络(Position-wise Feed-Forward Network)。
-
每个子层后面都跟着一个残差连接(Residual Connection)和层归一化(Layer Normalization)。
-
-
解码器(Decoder):
-
同样由多个相同的层堆叠而成,每一层包含三个子层结构:多头自注意力机制、编码器-解码器注意力(Encoder-Decoder Attention)机制和位置全连接前馈网络。
-
同样,每个子层后面都跟着残差连接和层归一化。
-
-
自注意力机制(Self-Attention):
-
允许模型在处理序列的每个位置时,都能考虑到序列中的所有位置,从而捕捉到序列内部的长距离依赖关系。
-
多头注意力机制允许模型在不同的表示子空间中学习信息。
-
-
位置编码(Positional Encoding):
-
由于Transformer模型没有循环结构,因此需要通过位置编码来为模型提供序列中单词的顺序信息。
-
位置编码可以与词嵌入相加,从而为模型提供位置信息。
-
-
线性层和Softmax层:
-
解码器的输出通过一个线性层变换,然后通过一个Softmax层来生成最终的输出概率分布,用于预测下一个单词。
-
Transformer模型的优势:
-
并行计算能力:由于没有循环结构,Transformer模型可以利用GPU的并行计算能力,加速训练过程。
-
长距离依赖捕捉:自注意力机制能够直接捕捉序列中的长距离依赖关系,不需要像RNN那样逐步传递信息。
-
灵活性和可扩展性:Transformer模型的结构允许通过增加层数或隐藏层大小来轻松扩展模型,以适应更复杂的任务。
Transformer模型的应用:
-
机器翻译:Transformer模型在机器翻译任务中取得了当时的最佳性能。
-
文本摘要:自动生成文章或新闻的摘要。
-
问答系统:理解和回答自然语言问题。
-
语言模型:预测下一个单词或生成连贯的文本。
随着技术的发展,Transformer模型已经成为许多高级NLP模型的基础,如BERT、GPT、T5等,这些模型在各种NLP任务中都取得了突破性的进展。

讯飞星火
Transformer是一种基于自注意力机制的深度学习模型架构,广泛应用于自然语言处理(NLP)等领域。
Transformer的概念最初由Vaswani等人在2017年的论文《Attention is All You Need》中提出。这一架构彻底改变了自然语言处理领域的研究和应用,尤其在构建大规模语言模型方面表现突出。它的核心是自注意力(Self-Attention)机制,这使得模型能够在处理序列数据时高效地捕捉到长距离依赖关系。
Transformer由编码器和解码器组成。编码器负责将输入序列转换成连续的表示,而解码器将这些表示转换为输出序列。具体来说,每个编码器和解码器包含两个主要子层:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。在解码器中还有一个额外的子层,即编码器-解码器注意力机制(Encoder-Decoder Attention),用于将编码器的输出和解码器的输入关联起来。
自注意力机制允许模型在处理某个元素(如一个单词)时,同时考虑输入序列中的其他所有元素。这种机制通过计算不同元素之间的相关性,为每个元素生成一个加权表示。这可以类比于在阅读一篇文章时,人们会根据上下文来理解每个词的意义。在数学上,自注意力机制通过计算查询(Query)、键(Key)和值(Value)之间的点积注意力得分来实现。
Transformer的优势在于其并行处理能力和高效的长距离依赖捕获能力。传统的循环神经网络(RNN)在处理长序列时容易受到梯度消失或爆炸等问题的困扰,而Transformer通过自注意力机制避免了这些问题。此外,由于不需要逐步处理序列,Transformer能够大幅度提高训练和推断的速度。
目前许多表现优异的大型语言模型都基于Transformer架构,例如GPT系列(如GPT-3、GPT-4)和BERT系列(如BERT、RoBERTa)。GPT主要用于生成式任务,采用解码器结构;而BERT则用于理解式任务,采用编码器结构。这些模型在机器翻译、文本生成、问答系统等应用中取得了令人瞩目的成绩。
综上所述,Transformer作为自然语言处理领域的一个里程碑式进展,其自注意力机制和灵活的架构设计极大地推动了语言模型的发展。从理论探讨到实际应用,Transformer展示了强大的性能和广泛的应用前景,成为当前NLP研究和应用的重要基石。

Kimi
Transformer是一种基于自注意力机制的神经网络架构,它在自然语言处理(NLP)领域取得了革命性的进展。以下是对Transformer模型的详细介绍:
1. 引入背景
在2017年,由Vaswani等人提出的Transformer模型,首次在论文《Attention Is All You Need》中被描述。它的核心思想是使用自注意力机制来处理序列数据,替代了之前广泛使用的循环神经网络(RNN)和卷积神经网络(CNN)结构。
2. 主要概念
- 自注意力(Self-Attention):允许输入序列的每个元素都与序列中的其他元素进行交互,从而捕捉序列内部的长距离依赖关系。
- 编码器-解码器架构(Encoder-Decoder):Transformer模型由编码器和解码器组成,编码器处理输入序列,解码器生成输出序列。
3. 关键组件
- 多头注意力(Multi-Head Attention):通过在不同的表示子空间中并行处理信息,增强了模型捕获信息的能力。
- 位置编码(Positional Encoding):为了使模型能够利用序列中单词的顺序信息,将位置信息编码到输入中。
- 前馈网络(Feed-Forward Neural Network):在每个编码器和解码器层中,自注意力层的输出会通过一个前馈网络。
4. 训练过程
- 掩码(Masking):在训练过程中,为了确保解码器不会看到未来的输出,使用掩码来防止信息泄露。
- 优化器(Optimizer):通常使用Adam优化器进行参数更新。
5. 应用领域
- 机器翻译:Transformer模型在机器翻译任务中表现出色,超越了之前的最佳方法。
- 文本摘要:自动生成文本的摘要。
- 文本分类:对文本进行分类,如情感分析。
6. 变体和发展
- BERT(Bidirectional Encoder Representations from Transformers):通过在预训练阶段使用双向编码器,BERT能够更好地理解上下文信息。
- GPT(Generative Pre-trained Transformer):专注于文本生成的大型Transformer模型。
- T5(Text-to-Text Transfer Transformer):将所有文本任务统一为文本到文本的格式。
7. 挑战和限制
- 计算资源:Transformer模型通常需要大量的计算资源进行训练。
- 数据需求:需要大量的训练数据来捕获语言的复杂性。
- 可解释性:模型的决策过程不够透明,难以解释。
8. 未来方向
- 效率优化:研究如何减少Transformer模型的计算和内存需求。
- 鲁棒性提升:提高模型对异常输入和对抗性攻击的鲁棒性。
- 多模态学习:探索Transformer在图像、视频等非文本数据上的应用。
Transformer模型的出现标志着自然语言处理领域的一个重大突破,它为理解和生成人类语言提供了强大的工具。随着技术的不断发展,我们可以期待Transformer及其变体在未来将有更多的创新和应用。

通义千问
大语言模型系列,尤其是基于Transformer架构的模型,近年来在自然语言处理领域取得了革命性的进展。Transformer最初由Vaswani等人在2017年的论文《Attention is All You Need》中提出,它彻底改变了以往基于循环神经网络(RNN)和长短期记忆网络(LSTM)的序列处理方式,成为现代自然语言处理模型的核心组件。以下是关于Transformer模型的一些关键要点:
1. 自注意力(Self-Attention)机制
Transformer的核心创新在于其自注意力机制。在传统的RNN和LSTM中,模型需要按顺序处理序列中的每个元素,这限制了并行计算的能力。而Transformer通过自注意力机制,能够同时考虑句子中所有词对的相互关系,从而捕捉序列中的长距离依赖关系,且天然支持并行计算,大大加速了训练过程。
2. 多头注意力(Multi-Head Attention)
Transformer模型中的多头注意力机制进一步增强了模型的注意力能力。它将自注意力机制拆分成多个“头”(heads),每个头独立地关注输入的不同部分,然后将这些信息汇总。这样做增加了模型的并行性和对不同特征的关注能力,使得模型能够学习到更加丰富和细致的上下文信息。
3. 编码器-解码器架构
Transformer模型采用了编码器-解码器架构,其中编码器负责将输入序列编码成一个固定长度的向量,解码器则基于这个向量和先前生成的词来预测下一个词。两部分都由多个相同的层堆叠而成,每层包含多头注意力、层归一化、全连接层(称为前馈神经网络,FFN)等组件。
4. 位置编码(Positional Encoding)
由于Transformer摒弃了循环结构,为了解决模型无法区分输入序列中元素顺序的问题,引入了位置编码。位置编码以一种固定的方式将序列中每个位置的绝对位置信息编码到输入向量中,确保模型能够识别序列中的相对位置信息。
5. 层归一化(Layer Normalization)
在Transformer的每层之后都使用了层归一化,它能够稳定训练过程,加速收敛速度,通过调整网络层的输入使其具有零均值和单位方差,使得模型更容易学习。
6. 模型规模的扩大
随着计算能力的提升,Transformer模型的规模也在不断扩大,从最初的Transformer模型到后来的BERT、GPT系列、T5、BERT-large、GPT-3、PaLM等,模型参数量从百万级别增长到了数十亿乃至数千亿级别。更大的模型往往能学习到更复杂的语言结构和知识,展现出更强的生成和理解能力。
7. 应用广泛
Transformer模型广泛应用于机器翻译、文本摘要、问答系统、情感分析、命名实体识别等多个自然语言处理任务,并且还在持续拓展到跨模态、代码生成、药物研发等更广泛的领域。
总的来说,Transformer模型以其强大的表达能力、高效的并行计算特性,以及不断扩大的规模,推动了自然语言处理技术的快速发展,成为当前和未来一段时间内自然语言处理领域的核心技术之一。

腾讯元宝
- 1. 深度解析 Transformer 模型:原理、应用与实践指南【收藏版】
- 2. 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
- 3. 深入理解Transformer技术原理 | 得物技术
- 4. 【Transformer 模型结构原理超级详细解析】_z = softmax(q,k)*v-CSDN博客
- 5. 一文彻底搞懂 Transformer(图解+手撕)
- 6. Transformer结构及其应用详解——GPT、BERT、MT-DNN、GPT-2
- 7. AI创世纪|Transformer是大模型基石,但一家创业公司却想挑战它
Transformer模型是一种基于自注意力机制的深度学习模型,由Google在2017年提出,主要用于解决传统序列到序列模型在处理长距离依赖问题上的不足1。以下是对Transformer模型原理、应用以及与其他模型的对比的详细介绍:
Transformer模型原理
- 自注意力机制:允许模型同时关注输入序列中的所有位置,并计算每个位置对当前位置的重要性,从而得到更加准确的表示1。
- 多头注意力机制:通过将输入分别投影到多个不同的子空间中,并计算每个子空间的注意力权重,最后将多个子空间的表示进行组合,得到最终的输出1。
- 编码器-解码器结构:Transformer模型采用了编码器-解码器结构,其中编码器负责将输入序列编码成表示,而解码器负责根据编码器的输出生成目标序列1。
Transformer模型应用
Transformer模型在自然语言处理任务中取得了显著的进展,如机器翻译、文本生成等。例如,在机器翻译任务中,多头注意力机制帮助模型同时关注源语言句子中的不同语义信息,从而提高了翻译质量1。
Transformer与其他模型的对比
与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transformer模型通过引入自注意力机制和多头注意力机制,成功地解决了长文本序列处理中的梯度消失或爆炸问题,提升了模型的并行性,加快了训练速度1。
通过上述分析,我们可以看到Transformer模型在自然语言处理领域的重要性和广泛应用。

Claude3 Opus
Transformer是一种基于自注意力机制的序列到序列模型,广泛应用于自然语言处理任务中,被认为是当前最优秀的语言模型之一。它是由Vaswani等人在2017年提出的,通过引入自注意力机制来解决长距离依赖的问题,取得了很好的效果。
Transformer模型的核心思想是通过自注意力机制来捕捉输入序列中的上下文信息,而不依赖于传统的循环神经网络(RNN)或卷积神经网络(CNN)。自注意力机制允许模型在生成输出时对输入的任何位置都能进行加权处理,从而能够更好地捕捉到不同位置间的依赖关系。
Transformer模型由编码器和解码器组成。编码器将输入序列转换为一系列的上下文表示,而解码器则根据这些上下文表示生成输出序列。
在编码器中,Transformer模型使用多层的自注意力机制和前馈神经网络。自注意力机制利用注意力机制来计算输入序列中每个位置对所有位置的重要性权重,从而得到位置相对于其他位置的上下文表示。前馈神经网络能够对每个位置的上下文表示进行非线性映射和特征提取。
在解码器中,Transformer模型在编码器的基础上进一步引入了另一个自注意力机制,用于在生成每个输出位置时对输入和已生成的输出位置进行加权处理。解码器还使用编码器输出的上下文表示来帮助生成正确的输出序列。
Transformer模型的训练通常使用序列到序列的方式,通过最大似然估计(MLE)来最小化生成序列的负对数似然损失。在训练过程中,使用了一种叫做遮蔽的技术来确保模型在生成序列时只能依赖于之前的位置。
除了在机器翻译任务中的应用,Transformer模型在许多其他自然语言处理任务中也取得了显著的成果,如文本摘要、情感分析、问答系统等。
总的来说,Transformer模型在语言建模和自然语言处理领域取得了巨大的成功,并成为当前最主流的语言模型之一。它的引入极大地改变了传统序列模型的设计思路,提供了一种新的、高效的序列建模方法。

GPT-4o (OpenAI)
Transformer模型是近年来自然语言处理(NLP)领域的一个重要突破。自从Vaswani et al. 在论文《Attention is All You Need》中提出Transformer模型以来,它已经逐渐成为许多NLP任务的标准方法。下面让我为你介绍Transformer模型的核心概念及其工作原理。
### Transformer模型的核心概念
Transformer模型主要由两个部分构成:编码器(Encoder)和解码器(Decoder)。
1. **编码器(Encoder)**:编码器的主要任务是将输入序列转换为一个隐层表示(hidden representation)。每一个编码器层通常包含以下子组件:
- **多头自注意力机制(Multi-Head Self-Attention Mechanism)**:这是Transformer的核心模块,可以让模型在处理某个位置的词时同时关注多个不同位置的词。
- **前向完全连接网络(Feed-Forward Neural Network, FFN)**:对自注意力机制的输出进行进一步的非线性变换。
2. **解码器(Decoder)**:解码器的主要任务是生成输出序列。在训练过程中,解码器会接收编码器的输出和已生成的部分输出序列。每一个解码器层通常包含以下子组件:
- **多头自注意力机制**:类似于编码器中的自注意力机制,但仅能关注到当前位置之前的词,以保证自回归生成。
- **多头编码器-解码器注意力机制(Multi-Head Encoder-Decoder Attention Mechanism)**:使解码器能够关注编码器输出的隐层表示。
- **前向完全连接网络**:与编码器中的FFN类似。
3. **位置编码(Positional Encoding)**:由于Transformer模型中没有循环神经网络(RNN)等顺序处理机制,因此需要显式地加入位置编码来引入序列中的位置信息。
### 核心机制详解
#### 自注意力机制(Self-Attention Mechanism)
自注意力机制允许模型根据输入序列中的所有位置计算每个位置的表示。具体来说,对于输入序列中的每个位置,计算其与序列中其他所有位置的相似度,并根据这些相似度加权求和。
公式如下:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V \]
其中,\( Q \)(queries)、\( K \)(keys)、\( V \)(values)是从输入序列中通过线性变换获得的矩阵。
#### 多头注意力机制(Multi-Head Attention Mechanism)
多头注意力机制是将上面的自注意力机制并行运行多次,以捕捉不同的关系结构:
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O \]
每个"头" \( \text{head}_i \) 都是独立的自注意力机制,并将其结果串联后再进行全连接变换。
#### 前向完全连接网络(Feed-Forward Neural Network, FFN)
每层编码器和解码器最后都有一个前向完全连接网络,作用是对通过注意力机制变换的表示进行非线性变换和进一步处理。通常包括两个线性层和一个激活函数(如ReLU):
\[ FFN(x) = \text{max}(0, xW_1 + b_1)W_2 + b_2 \]
### Transformer的训练
Transformer模型通常使用端到端的方式进行训练,即通过将模型的输出与目标序列进行对比,计算损失,并通过反向传播优化模型参数。常用的优化方法是Adam。
### Transformer的应用
Transformer模型在很多NLP任务中得到了成功应用,包括但不限于:
- 机器翻译(Machine Translation)
- 文本生成(Text Generation)
- 自然语言理解(Natural Language Understanding)
- 问答系统(Question Answering)
- 语义匹配(Semantic Matching)
后来基于Transformer的变体,包括BERT、GPT等模型,进一步推动了Transformer在实际应用中的广泛应用。
### 实现Transformer模型
如果你想使用MindSpore或其他深度学习框架实现Transformer模型,可以参考许多开源代码和教程。例如,MindSpore支持多种NLP任务和模型,并提供了良好的文档和示例代码。以下是一个简要的实现步骤概述,可以帮助你了解如何在MindSpore中实现Transformer模型。
#### 1. 数据准备
首先需要准备训练数据,这通常包括输入序列和目标序列。对于机器翻译任务,输入序列和目标序列分别是源语言和目标语言的句子。
#### 2. 模型构建
构建Transformer模型,包括定义编码器和解码器。MindSpore提供了模块化的接口,可以很方便地定义和组合不同的层。
import mindspore.nn as nn
import mindspore.ops as opsclass MultiHeadAttention(nn.Cell):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()self.num_heads = num_headsself.d_model = d_modelself.depth = d_model // num_headsself.Wq = nn.Dense(d_model, d_model)self.Wk = nn.Dense(d_model, d_model)self.Wv = nn.Dense(d_model, d_model)self.dense = nn.Dense(d_model, d_model)def construct(self, Q, K, V):batch_size = Q.shape[0]Q = self.split_heads(self.Wq(Q), batch_size)K = self.split_heads(self.Wk(K), batch_size)V = self.split_heads(self.Wv(V), batch_size)attention_output = self.scaled_dot_product_attention(Q, K, V)attention_output = self.combine_heads(attention_output, batch_size)return self.dense(attention_output)def split_heads(self, x, batch_size):x = x.view(batch_size, -1, self.num_heads, self.depth)return x.transpose(1, 2)def combine_heads(self, x, batch_size):x = x.transpose(1, 2)return x.contiguous().view(batch_size, -1, self.d_model)def scaled_dot_product_attention(self, Q, K, V):matmul_qk = ops.matmul(Q, K.transpose(-2, -1))dk = K.shape[-1]scaled_attention_logits = matmul_qk / ops.sqrt(dk)attention_weights = ops.softmax(scaled_attention_logits, axis=-1)output = ops.matmul(attention_weights, V)return output这是一个多头注意力机制的简化实现示例。
#### 3. 模型训练
准备数据并通过训练数据训练模型。通常使用交叉熵损失函数和优化器(例如Adam)来训练Transformer模型。
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=1e-4)model.train(epoch, train_dataset, callbacks=[loss, optimizer])#### 4. 评估模型
在训练过程中,通过验证数据集监控模型性能,调整超参数以获得更好的结果。
model.eval()#### 5. 推理和应用
训练完成后,可以使用训练好的模型进行推理和应用,例如生成翻译结果或进行问答。
output = model(input_data)### 总结
Transformer模型因其强大的表示能力和并行计算效率,成为现代NLP任务中的主流模型。通过理解其核心机制,如自注意力、多头注意力和前向完全连接网络,以及实践中的模型构建和训练步骤,你可以在各种语言处理任务中应用并扩展Transformer模型。

GPT-3.5 (OpenAI)
Transformer是一种新型的神经网络结构,最初被用于自然语言处理任务,如机器翻译。相比于传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer模型能够处理更长的文本序列,同时也不会出现梯度消失的问题。
Transformer模型主要由以下几部分组成:
1. Encoder(编码器):用于将输入的文本序列中,每个位置的词向量进行编码,产生一系列编码后的向量。
2. Decoder(解码器):使用编码器中的词向量作为输入,并通过对编码后的向量执行类似于RNN的操作来生成输出序列。
3. Multi-Head Attention(多头注意力机制):是Transformer最核心的部分。它用于捕捉输入序列中的相关信息,从而使得模型能够学习到更高层次的语义信息。
4. Positional Encoding(位置编码):用于将输入序列中每个位置的信息转换成向量表示,以使得模型能够捕捉到序列中的顺序信息。
通过以上几部分的组合,Transformer模型能够学习到更好的文本表示,从而在机器翻译、文本生成和机器阅读理解等自然语言处理任务中达到了极好的效果。
相关文章:
大语言模型系列-Transformer
DeepSeek Transformer模型是深度学习领域中一种革命性的架构,它在自然语言处理(NLP)任务中取得了巨大的成功。Transformer模型由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,其核心思想是利用自注意力&#x…...

Node.js 语言特定指南
Node.js 语言特定指南 本 Node.js 语言特定指南将教您如何使用 Docker 容器化 Node.js 应用程序。在本指南中,您将学习如何: 容器化并运行一个 Node.js 应用程序设置一个本地环境以使用容器开发 Node.js 应用程序使用容器为 Node.js 应用程序运行测试使…...

科普:什么是 BC-404 ?全方位解读最新通缩型 NFT 标准
区块链技术飞速发展的今天,创新从未停歇。继 ERC-404 标准问世后,一个名为 BC-404 的新标准应运而生,为 NFT 市场带来了全新的可能性。BC-404(Bonding Curve 404)—基于对 ERC-404 的改进,加密货币中第一个…...

软件测试学习笔记丨JUnit5执行顺序
本文转自测试人社区,原文链接: https://ceshiren.com/t/topic/28025 指定顺序使用场景 测试用例有业务逻辑相关集成测试(主流程测试) 排序方式 方法排序类排序Suite官方网站没有明确说明默认排序的具体规则 方法排序的类型 方法排序-Order 注解指定排序 …...
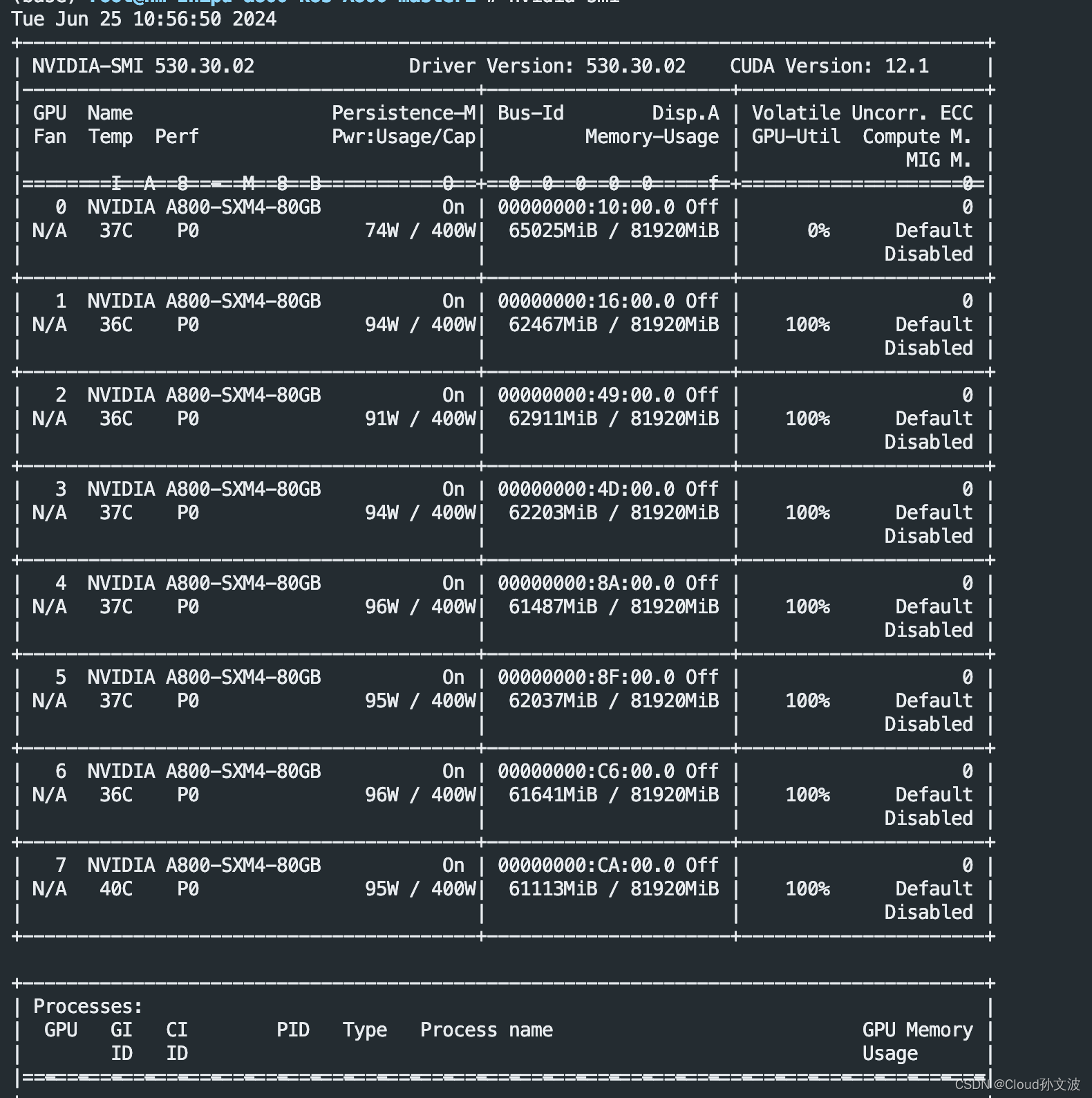
解决GPU 显存未能完全释放
一、 现象 算法同学反馈显存未能完全释放。 二、解决方法 一条命令搞定 注意:执行时注意不要误杀其他的python进程,需要确认好。 我的这条命令是将所有python进程都杀死了 ps -elf | grep python | awk {print $4} | xargs kill -s 9...
3D资产爆发,轻量化需求再度冲高,见证下一代3D崛起!
数字经济不断发展,3D资产和实体经济迎来深度融合的窗口期,3D资产应用外延催生大量新场景、新业态,一个3D资产构建的数字世界正出现在我们眼前。 数字经济不断发展,3D资产和实体经济迎来深度融合的窗口期,3D资产应用外…...

AI绘画的10种变现方法,逼你躺平挣钱
AI绘画到底能多挣钱! 马上看证据,知乎和其它平台的收益,AI绘画挣的稿费,还有某音某瓜的稿费。 都是有AI绘画的一大功劳! 接下来介绍AI绘画的十种挣钱方法,有折腾的收益,也有躺平的收益&#x…...

Pura 70 系列超高速风驰闪拍,捕捉美好,告别抓拍模糊
及时而准确的将画面定格,把事件最具有表现力的瞬间直观、真实地传达给观者,以使将抓拍影响的意义发挥最大化,由于抓拍摄影作品大多反映的是比较自然,真实的人和事,得到了社会的广泛认可,抓拍摄影也正日益成…...
AI作画Prompt不会写?Amazon Bedrock Claude3.5来帮忙
最新上线的Claude3.5 Sonnet按照官方介绍的数据来看,在多方面超越了CPT-4o,是迄今为止最智能的模型。 而跟上一个版本相比,速度是Claude 3 Opus的两倍,成本只有其五分之一。 Claude3.5 Sonnet不仅擅长解释图表、图形或者从不完…...
SSL证书类型解析:DV、OV、EV证书的区别与适用场景
在互联网时代,数据安全和用户隐私保护变得尤为重要。SSL证书作为加密网站通信的主要工具,为用户提供了一个安全的浏览环境。然而,面对市场上多种类型的SSL证书,许多网站所有者常常感到困惑。本文将重点解析三种常见的SSL证书类型—…...

WPF 2024 金九银十 最新 高级 架构 面试题 C#
含入门 初级 中级 高级 不同级别WPF的面试题 相关面试题 redis安装说明书 http://t.csdnimg.cn/iM260 单体并发瓶颈 redis sqlsever mysql多少 http://t.csdnimg.cn/DTXIh Redis高频面试题http://t.csdnimg.cn/FDOnv 数据库SqlServer笔试题 数据库SqlServer笔试题-CSDN博客 SQL…...
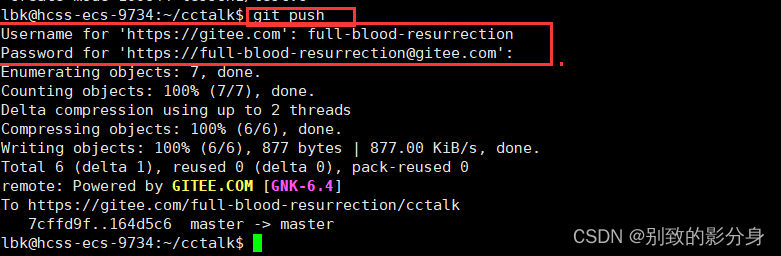
Linux上使用 git 命令行
在 Github或者 gitee 注册账号 这个比较简单 , 参考着官网提示即可 . 需要进行邮箱校验.以下以创建Github为例。 创建项目 1. 登陆成功后 , 进入个人主页 , 点击下方的 create a new repository 按钮新建项目 2. 在创建好的项目页面中复制项目的链接 , 以备接下来进行下…...

vue 中computed和watch的区别
computed与watch的区别 首先,computed是计算属性,watch是监听,监听data中的数据变化。 computed的计算属性它支持缓存,只有当依赖项发生改变的时候,它才会重新计算,否则它用的就是缓存的值。watch不支持缓…...

富豪王思聪的“爱情喜剧”从万达排片到网红聊天
王思聪,这位人生如戏、戏如人生的富二代, 在爱情的战场上可谓是屡战屡败,屡败屡战。 想当年,他向戚薇发起了猛烈的爱情攻势, 豪言壮语道:“若我以万达25%的排片量换你一笑,你可愿与我共舞&am…...

qt qml-http之XMLHttpRequest介绍详解使用
文章目录 QML中的XMLHttpRequest详解与示例基本用法示例代码代码详解更复杂的示例:POST请求代码详解结论QML中的XMLHttpRequest详解与示例 XMLHttpRequest 是 QML 中用于执行HTTP请求的一种机制,类似于Web中的AJAX。它可以用来进行异步的数据传输,可以从服务器获取数据,也…...

DBdoctor功能介绍
绍DBdoctor的主要功能,按照事件先后涵盖了事前、事中、事后三个阶段。事前的主动问题发现、SQL性能评估、自动巡检与报表、空间预测与诊断;事中的性能洞察、根因诊断、锁分析、优化建议;事后的审计分析、根因推导、问题快照。按照使用者包含了…...

Kubernetes之Kubelet详解
本文尝试从Kubelet的发展历史、实现原理、交互逻辑、伪代码实现及最佳实践5个方面对Kubelet进行详细阐述。希望对您有所帮助! 一、kubelet发展历史 Kubelet 是 Kubernetes 中的核心组件之一,负责管理单个节点上的容器运行。它的发展历史和功能演进是 K…...

大模型AI技术实现语言规范练习
人工智能技术可以为语言规范练习提供多种有效的解决方案,帮助学习者更有效地掌握语言规范。以下是一些常见的应用场景。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1. 智能纠错 利用自然语言处理技术,可以…...

202.回溯算法:全排列||(力扣)
class Solution { public:vector<int> res; // 存储当前排列vector<vector<int>> result; // 存储所有排列// 回溯函数,用于生成排列void backtracing(vector<int>& nums, vector<bool>& used) {// 如果当前排列的长度等于 n…...

什么是数据库范式,为什么要反范式?
一、典型回答 数据库范式其实是数据库的设计上的一些规范,这些规范可以让数据库的设计更加简洁、清晰,同时也会更好的保证一致性。 二、三范式 第一范式(1NF):数据库表中的属性的原子性,要求属性具有原子性…...

为什么92%的设计师调不出正宗铂金印相?3个被忽略的色彩科学陷阱与CIE LAB空间修正公式
更多请点击: https://intelliparadigm.com 第一章:铂金印相的视觉本质与历史语境 铂金印相(Platinum Print)并非一种数字图像处理技术,而是一种19世纪末诞生于摄影化学工艺巅峰的物理显影体系。其视觉本质在于——铂金…...

小红书自动化工具xhs-skill:接口逆向与数据采集实战指南
1. 项目概述:一个面向小红书内容创作的效率工具箱最近在逛GitHub的时候,发现了一个挺有意思的项目,叫PengJiyuan/xhs-skill。光看名字,你大概能猜到它和小红书有关,但具体是做什么的,可能有点模糊。作为一个…...

用Git和Markdown构建个人知识库:Wandercode项目实践指南
1. 项目概述:从“漫游代码”到个人知识管理系统的蜕变最近在GitHub上看到一个挺有意思的项目,叫“Wandercode”,直译过来就是“漫游代码”。乍一看这个标题,可能会让人联想到某种代码生成器或者自动化脚本工具。但当我深入探究其仓…...

3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式
3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在当今数字内容时代ÿ…...

基于LLM与RAG构建智能问答系统:架构、实现与优化指南
1. 项目概述:当RAG遇上LLM,构建你的智能知识问答引擎最近在GitHub上看到一个挺有意思的项目,叫“Jenqyang/LLM-Powered-RAG-System”。光看名字,圈内人大概就能猜到个七七八八:这是一个基于大语言模型(LLM&…...

避坑指南:在Python 3.7环境用ModelScope部署speech_campplus_sv_zh-cn_16k-common语音识别模型的完整流程
避坑指南:Python 3.7环境部署ModelScope语音识别模型的完整实践 在人工智能语音处理领域,说话人验证技术正逐渐成为身份认证和语音交互系统的核心组件。阿里云达摩院开源的speech_campplus_sv_zh-cn_16k-common模型作为轻量级解决方案,特别适…...
)
别再让Ubuntu20.04时间错乱了!用hwclock和timedatectl搞定硬件时钟时区(附原理详解)
彻底解决Ubuntu 20.04时间同步问题:硬件时钟与系统时钟的深度调校指南 每次重启电脑后,系统时间总是不准?在Windows和Ubuntu双系统间切换时,时间显示总是莫名其妙差8小时?这些困扰Linux用户多年的"时间错乱"…...

如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南
如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款强大的Unity游戏插件框架,为游戏模组…...

H3C HCL模拟器实战:IS-IS单区域基础配置与排错指南
1. 实验目标与网络环境准备如果你正在学习网络路由协议,特别是运营商级网络常用的IS-IS,那么通过模拟器进行实操是绕不开的一步。这次我用H3C的HCL模拟器,带大家走一遍IS-IS单区域的基本配置。这个实验的目标很明确:不是让你死记硬…...

EB Garamond 12:免费获取专业复古字体与RCS学术引用系统的完整指南
EB Garamond 12:免费获取专业复古字体与RCS学术引用系统的完整指南 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 想要为你的设计作品注入文艺复兴时期的优雅韵味,同时获得专业的学术引用功能吗&…...