[Day 18] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
強化學習與生成對抗網絡(GAN)
引言
強化學習 (Reinforcement Learning, RL) 和生成對抗網絡 (Generative Adversarial Networks, GANs) 是現代人工智能中的兩大關鍵技術。強化學習使得智能體可以通過與環境交互學習最佳行動策略,而生成對抗網絡則通過兩個相互競爭的神經網絡生成高質量的合成數據。本文將詳細介紹這兩種技術的基本概念、應用場景以及實現方法,並通過多段代碼示例展示其具體實現細節。
一、強化學習
1. 強化學習基本概念
強化學習是一種機器學習方法,智能體通過與環境交互學習最優策略,以最大化其累積獎勵。強化學習的主要組成部分包括:
- 智能體 (Agent):進行行動並從環境中獲得反饋的實體。
- 環境 (Environment):智能體進行行動的空間。
- 狀態 (State, s):環境在某一時刻的表徵。
- 行動 (Action, a):智能體在某一狀態下採取的行動。
- 獎勵 (Reward, r):環境對智能體行動的反饋。
- 策略 (Policy, π):智能體在給定狀態下選擇行動的概率分佈。
2. Q-Learning實現
Q-Learning 是一種經典的強化學習算法,用於學習行動值函數 (Q-Value Function),這個函數表示在特定狀態下採取某一行動的預期累積獎勵。以下是Q-Learning算法的Python實現。
import numpy as np
import gym# 環境初始化
env = gym.make('FrozenLake-v0')# Q-表格初始化
Q = np.zeros((env.observation_space.n, env.action_space.n))# 參數初始化
alpha = 0.8 # 學習率
gamma = 0.95 # 折扣因子
epsilon = 0.1 # 探索率# 訓練過程
for episode in range(10000):state = env.reset()done = Falsewhile not done:if np.random.uniform(0, 1) < epsilon:action = env.action_space.sample() # 探索else:action = np.argmax(Q[state, :]) # 利用next_state, reward, done, _ = env.step(action)# Q值更新Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action])state = next_stateprint("Q-Table:")
print(Q)
代碼解釋
env = gym.make('FrozenLake-v0'):使用OpenAI Gym庫中的FrozenLake環境。Q = np.zeros((env.observation_space.n, env.action_space.n)):初始化Q表格,大小為狀態數乘以行動數。alpha, gamma, epsilon:設置學習率、折扣因子和探索率。env.reset():重置環境,獲取初始狀態。env.action_space.sample():隨機選擇一個行動,用於探索。np.argmax(Q[state, :]):選擇Q值最大的行動,用於利用。env.step(action):執行選擇的行動,獲取下個狀態和獎勵。Q[state, action] = ...:更新Q值。
3. DQN(深度Q-Learning網絡)
DQN將深度學習引入Q-Learning中,用神經網絡替代Q表格,能夠處理更大規模的狀態空間。以下是DQN的簡化實現。
import tensorflow as tf
from tensorflow.keras import layers# 神經網絡模型定義
def build_model(input_shape, output_shape):model = tf.keras.Sequential([layers.Dense(24, input_dim=input_shape, activation='relu'),layers.Dense(24, activation='relu'),layers.Dense(output_shape, activation='linear')])model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=0.001))return model# 參數設定
input_shape = env.observation_space.n
output_shape = env.action_space.nmodel = build_model(input_shape, output_shape)
target_model = build_model(input_shape, output_shape)# 訓練過程
def train_dqn(episodes):for episode in range(episodes):state = env.reset()state = np.reshape(state, [1, input_shape])done = Falsewhile not done:if np.random.rand() <= epsilon:action = env.action_space.sample()else:action = np.argmax(model.predict(state))next_state, reward, done, _ = env.step(action)next_state = np.reshape(next_state, [1, input_shape])target = model.predict(state)if done:target[0][action] = rewardelse:t = target_model.predict(next_state)target[0][action] = reward + gamma * np.amax(t)model.fit(state, target, epochs=1, verbose=0)state = next_statetrain_dqn(1000)
代碼解釋
build_model:定義神經網絡模型,包含兩個隱藏層,每層24個神經元。model.compile:編譯模型,使用均方誤差損失函數和Adam優化器。train_dqn:DQN訓練過程,每次從環境中獲取狀態並更新神經網絡。model.predict(state):預測當前狀態的Q值。model.fit(state, target):訓練模型,更新神經網絡參數。
二、生成對抗網絡(GAN)
1. GAN基本概念
GAN由生成器 (Generator) 和判別器 (Discriminator) 兩個神經網絡組成。生成器試圖生成逼真的假數據,而判別器則試圖區分真實數據和生成數據,兩者相互對抗,共同提升生成數據的質量。
2. GAN結構與訓練過程
- 生成器:從隨機噪聲中生成數據。
- 判別器:區分真實數據與生成數據。
- 損失函數:判別器和生成器的損失函數互為對手,生成器希望最大化判別器的錯誤率,而判別器希望最大化識別率。
3. GAN實現
以下是GAN在MNIST數據集上的實現示例。
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np# 生成器模型
def build_generator():model = tf.keras.Sequential([layers.Dense(256, input_dim=100, activation='relu'),layers.BatchNormalization(),layers.Dense(512, activation='relu'),layers.BatchNormalization(),layers.Dense(1024, activation='relu'),layers.BatchNormalization(),layers.Dense(28 * 28 * 1, activation='tanh'),layers.Reshape((28, 28, 1))])return model# 判別器模型
def build_discriminator():model = tf.keras.Sequential([layers.Flatten(input_shape=(28, 28, 1)),layers.Dense(512, activation='relu'),layers.Dense(256, activation='relu'),layers.Dense(1, activation='sigmoid')])model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.0002, 0.5), metrics=['accuracy'])return model# GAN模型
def build_gan(generator, discriminator):discriminator.trainable = Falsemodel = tf.keras.Sequential([generator, discriminator])model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.0002, 0.5))return model# 創建模型
generator = build_generator()
discriminator = build_discriminator()
gan = build_gan(generator, discriminator)# 訓練過程
def train_gan(epochs, batch_size=128):(X_train, _), (_, _) = tf.keras.datasets.mnist.load_data()X_train = (X_train.astype(np.float32) - 127.5) / 127.5 # Normalize to [-1, 1]X_train = np.expand_dims(X_train, axis=3)for epoch in range(epochs):# 訓練判別器idx = np.random.randint(0, X_train.shape[0], batch_size)real_images = X_train[idx]noise = np.random.normal(0, 1, (batch_size, 100))fake_images = generator.predict(noise)d_loss_real = discriminator.train_on_batch(real_images, np.ones((batch_size, 1)))d_loss_fake = discriminator.train_on_batch(fake_images, np.zeros((batch_size, 1)))d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)# 訓練生成器noise = np.random.normal(0, 1, (batch_size, 100))valid_y = np.array([1] * batch_size)g_loss = gan.train_on_batch(noise, valid_y)# 打印進度if epoch % 1000 == 0:print(f"{epoch} [D loss: {d_loss[0]} | D acc.: {100*d_loss[1]}] [G loss: {g_loss}]")train_gan(10000)
代碼解釋
build_generator:定義生成器模型,包含多層全連接層和批量歸一化層,最終輸出生成的圖像。build_discriminator:定義判別器模型,包含多層全連接層,最終輸出0或1,表示真假。build_gan:將生成器和判別器結合成GAN模型,並設置判別器在GAN模型中不可訓練。train_gan:GAN訓練過程,首先訓練判別器,再訓練生成器,交替進行。
三、強化學習與GAN的聯動應用
強化學習和GAN的聯動應用在很多領域都有廣泛的前景。以下是一個簡單的例子,展示如何結合這兩種技術實現更加智能的數據生成和策略學習。
1. 生成環境數據並訓練智能體
假設我們希望通過GAN生成虛擬環境數據,然後使用強化學習在這些虛擬環境中訓練智能體。以下是基本步驟:
四、結論
強化學習和生成對抗網絡是現代人工智能中兩個非常重要的技術,它們各有特色並且在很多應用場景中相互補充。通過理解和實現這些技術,讀者可以在企業級應用中充分利用它們的強大功能。本文詳細介紹了強化學習和GAN的基本概念、實現方法以及聯動應用,希望對讀者有所幫助。
- 使用GAN生成高質量的環境數據。
- 使用強化學習在這些生成的環境中訓練智能體,學習最佳策略。
import gym from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense# 簡單的環境數據生成器 def simple_data_generator():noise = np.random.normal(0, 1, (1, 100))generated_data = generator.predict(noise)return generated_data# 簡單的強化學習模型 def simple_rl_model():inputs = Input(shape=(28, 28, 1))x = Dense(24, activation='relu')(inputs)x = Dense(24, activation='relu')(x)outputs = Dense(4, activation='linear')(x) # 假設有4個動作model = Model(inputs, outputs)model.compile(optimizer='adam', loss='mse')return model# 訓練智能體 def train_rl_agent(episodes, data_generator, rl_model):for episode in range(episodes):state = data_generator()done = Falsewhile not done:action = np.argmax(rl_model.predict(state))next_state = data_generator() # 使用生成器生成下一個狀態reward = compute_reward(state, action, next_state) # 定義獎勵函數target = reward + gamma * np.max(rl_model.predict(next_state))target_f = rl_model.predict(state)target_f[0][action] = targetrl_model.fit(state, target_f, epochs=1, verbose=0)state = next_state# 訓練過程 rl_model = simple_rl_model() train_rl_agent(1000, simple_data_generator, rl_model)代碼解釋
simple_data_generator:使用生成器生成簡單的環境數據。simple_rl_model:定義簡單的強化學習模型,包含兩層全連接層,輸出四個動作的Q值。train_rl_agent:使用生成的環境數據訓練強化學習智能體。
相关文章:

[Day 18] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
強化學習與生成對抗網絡(GAN) 引言 強化學習 (Reinforcement Learning, RL) 和生成對抗網絡 (Generative Adversarial Networks, GANs) 是現代人工智能中的兩大關鍵技術。強化學習使得智能體可以通過與環境交互學習最佳行動策略,而生成對抗網絡則通過兩個相互競爭…...

【Mac】DMG Canvas for mac(DMG镜像制作工具)软件介绍
软件介绍 DMG Canvas 是一款专门用于创建 macOS 磁盘映像文件(DMG)的软件。它的主要功能是让用户可以轻松地设计、定制和生成 macOS 上的安装器和磁盘映像文件,以下是它的一些主要特点和功能。 主要特点和功能 1. 用户界面设计 DMG Canva…...

RAG分块方法 从固定大小到自然语言处理分块——深入研究文本分块技术
发掘文本分块-准确的搜索结果和更智能的语言模型背后的秘诀,通过了解如何有效地分块文本,我们可以改进索引文档、处理用户查询和利用搜索结果的方式。准备好揭开文本分块的秘密了吗? 一、了解分块 分块是一种旨在嵌入尽可能少噪音的内容,同…...

FFmpeg 系列
📚 此篇文章是先引入ffmpeg的概念以及主要的功能,后面会根据每一个特点进行详解,喜欢ffmpeg的可以持续关注。 ffmpeg是什么? FFmpeg 是一个开源的跨平台音视频处理工具,它可以用来录制、转换以及流化音视频内容。具体…...
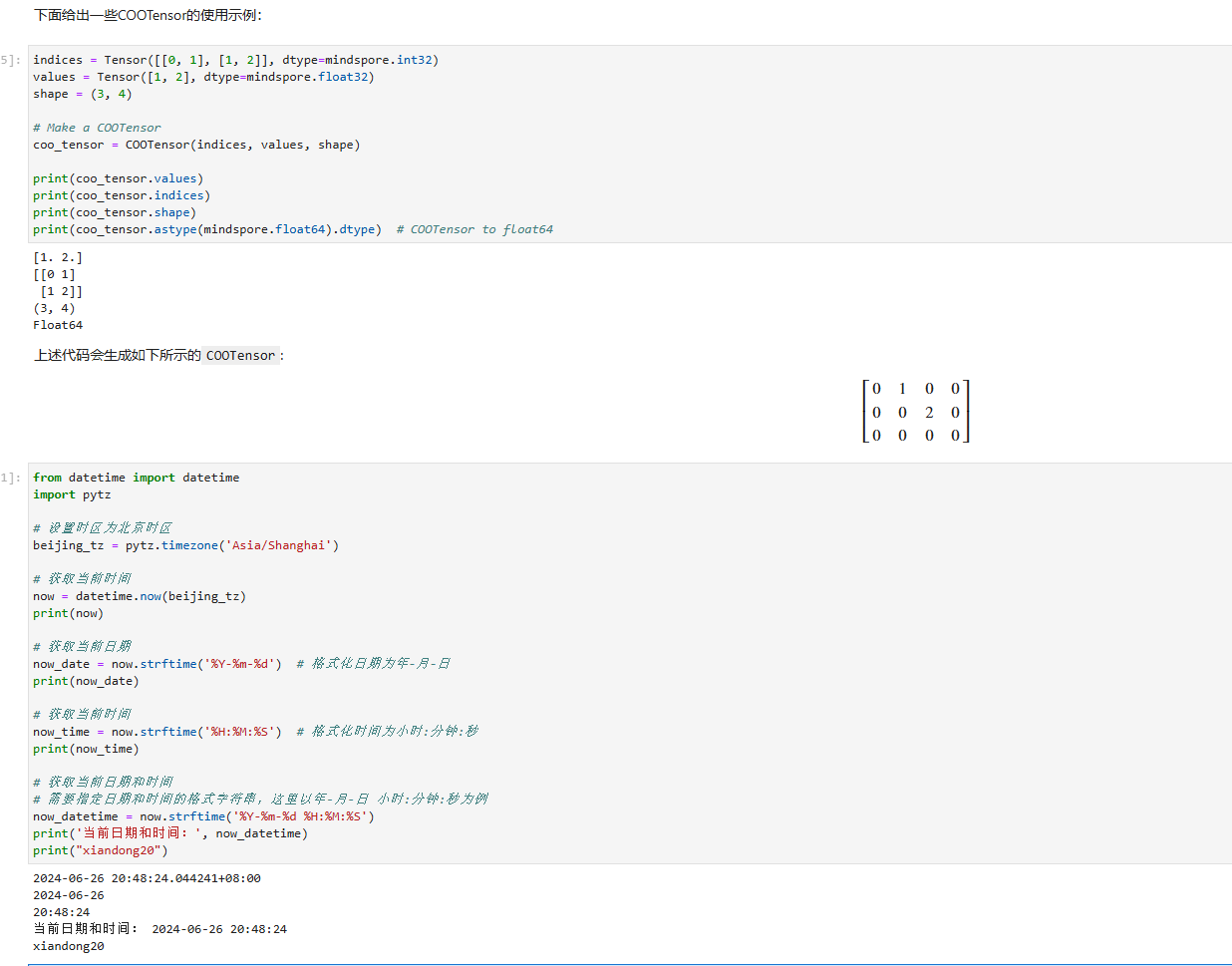
240626_昇思学习打卡-Day8-稀疏矩阵
240626_昇思学习打卡-Day8-稀疏矩阵 稀疏矩阵 在一些应用场景中,比如训练二值化图像分割时,图像的特征是稀疏的,使用一堆0和极个别的1表示这些特征即费事又难看,此时就可以使用稀疏矩阵。通过参考大佬博文,结合个人理…...

Docker: 使用容器化数据库
使用容器化数据库 使用本地容器化数据库提供了灵活性和简易的设置,使您能够在不需要传统数据库安装开销的情况下,紧密模拟生产环境。Docker 简化了这一过程,只需几条命令就可以在隔离的容器中部署、管理和扩展数据库。 在本指南中,您将学习如何: 运行本地容器化数据库访…...

Oracle对用户敏感数据进行编码处理
由于系统运行时间比较长,没有对用户的身份证号、邮箱、手机号进行脱敏处理,后期对数据进行了编码。 更新表数据 sql UPDATE sys_staff SET MOBIL_PHONE CASEWHEN MOBIL_PHONE IS NULL THEN ELSE utl_raw.cast_to_varchar2(utl_encode.base64_encode(ut…...

VXLAN详解:概念、架构、原理、搭建过程、常用命令与实战案例
一、VXLAN概述 1.1 VXLAN的定义 VXLAN(Virtual Extensible LAN,虚拟可扩展局域网)是一种网络虚拟化技术,通过在现有IP网络上创建虚拟网络,使数据中心可以实现大规模的网络隔离和扩展。VXLAN使用MAC-in-UDP封装技术&a…...

Redis-数据类型-Hash
文章目录 1、查看redis是否启动2、通过客户端连接redis3、切换到db3数据库4、插入新数据返回15、获取指定哈希(hash)对象的所有字段(field)名6、获取存储在指定哈希(hash)对象中的所有字段(fiel…...
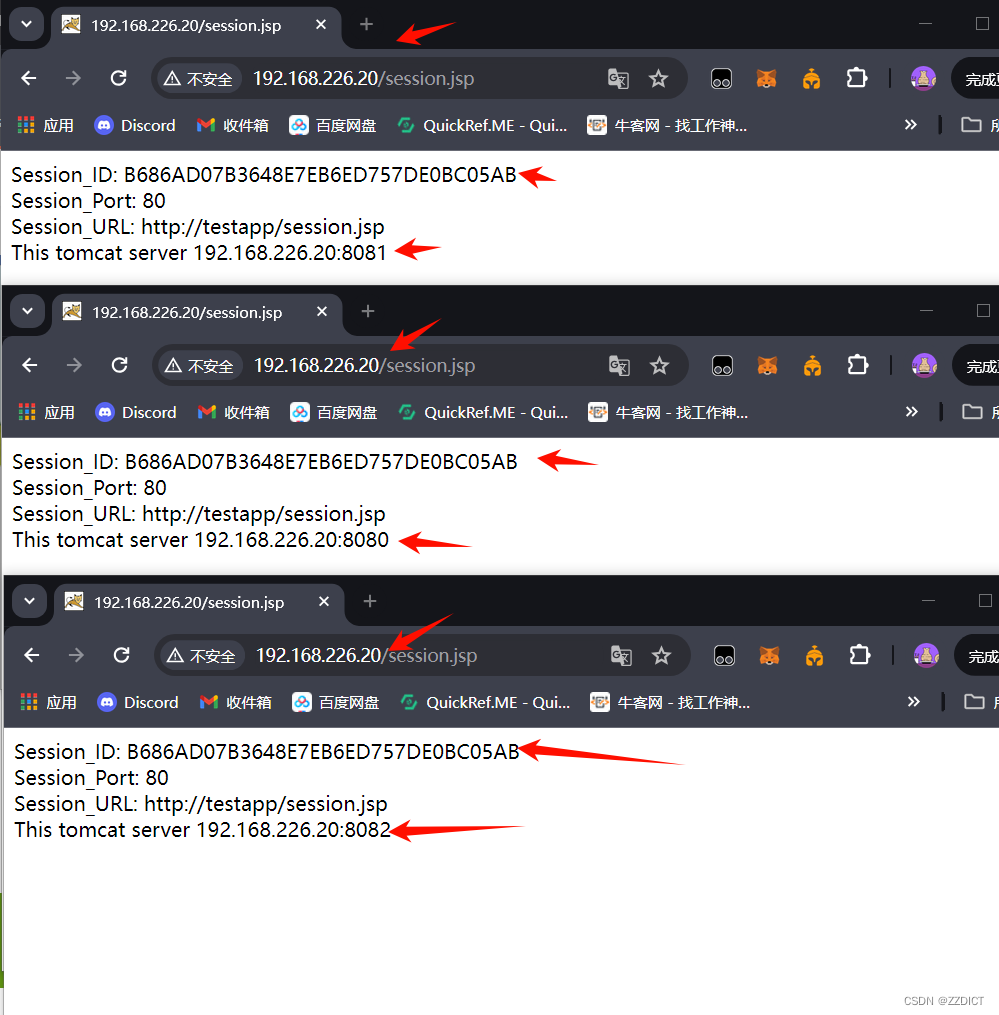
基于redisson实现tomcat集群session共享
目录 1、环境 2、修改server.xml 3、修改context.xml 4、新增redisson配置文件 5、下载并复制2个Jar包到Tomcat Lib目录中 6、 安装redis 7、配置nginx负载均衡 8、配置测试页面 9、session共享测试验证 前言: 上篇中,Tomcat session复制及ses…...
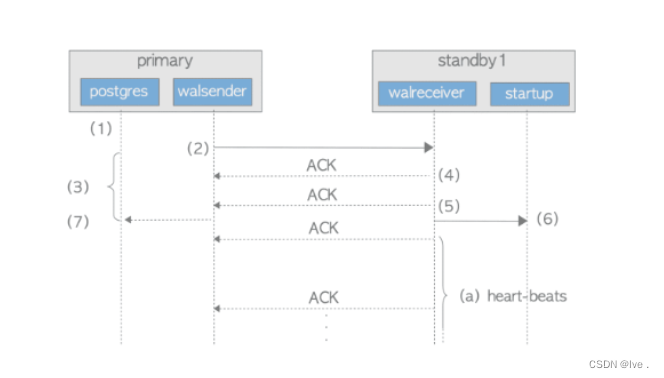
postgres数据库的流复制
1. 流复制和逻辑复制的差异 逻辑复制和流复制最直观的不同是,逻辑复制支持表级别复制区分点事原理不同 逻辑日志是在wal日志产生的数据库上,由逻辑解析模块对wal日志进行初步的解析,解析结果是ReorderBufferChange(理解为HeapTup…...

Dxf库中的DL_Extrusion类
类DL_Extrusion DL_Extrusion 是 DXF 库中的一个类,用于表示三维实体的扩展信息。在 DXF 文件中,DL_Extrusion 类通常用于表示具有高度的三维图形实体,如立方体、圆柱体等,以及其它具有体积的几何对象。 以下是一个简单的示例代…...
“ONLYOFFICE 8.1版本评测:功能更强大,用户体验更佳”
最新版本的在线编辑器已经发布 ONLYOFFICE在线编辑器的最新版本8.1已经发布,整个套件带来了30多个新功能和432个bug修复。这个强大的文档编辑器支持处理文本文档、电子表格、演示文稿、可填写的表单和PDF,并允许多人在线协作,同时支持AI集成…...

搜维尔科技:【研究】触觉手套比控制器更能带来身临其境、更安全、更高效的虚拟体验
自然交互可提高VR模拟的有效性。研究表明,触觉手套比控制器更能带来身临其境、更安全、更高效的虚拟体验。 以下是验证 医疗培训中的触觉技术 “ 95.5%的参与者表示触摸是 XR 教育的重要组成部分,90.9% 的参与者表示 XR 触觉将提供一个安全的学习场所。…...

【小学期】实体类设计——以学生管理系统为例
项目目录中的位置 将Student.java文件放在src/model目录中,即: student_management │ ├── src │ ├── model │ │ ├── Student.java // 这里是Student实体类 │ │ └── StudentDAO.java │ │ │ ├── view │ │ …...

Java测试类
在Java中,为了编写测试类,通常使用JUnit框架。 1. 首先,创建一个名为Calculator的简单Java类,它包含一个方法add用于计算两个整数的和: public class Calculator {public int add(int a, int b) {return a b;} } 2.…...

python 中面向对象编程:深入理解封装、继承和多态
在本章中,我们将深入探讨Python中的高级面向对象编程概念,包括封装、继承和多态。让我们开始吧! 目录 面向对象简介类和实例属性和方法继承和多态 高级面向对象概念私有变量使用 property使用 __slots__类的特殊成员__doc____call____str____…...

OpenCV练习(2)图像校正
1、傅里叶变换 霍夫变换 直线 角度 旋转2、边缘检测 霍夫变换 直线角度 旋转3、四点透视 角度 旋转4、检测矩形轮廓 角度 旋转 1.目的 实现类似全能扫面王的图像校正功能 2. 基于轮廓提取和透射变换 基于轮廓提取和透射变换的矫正算法更适用于车牌、身份证、人民…...

Excel中的“点选输入”——次级下拉列表创建
在Excel中,用“数据验证”功能可以设置下拉列表,二级下拉列表需要设置公式。 (笔记模板由python脚本于2024年06月16日 18:36:37创建,本篇笔记适合经常使用Excel处理数据的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网:http…...

基于 Spring AOP 实现安全检查
在现代应用程序中,安全性是一个至关重要的方面。通过对系统中的关键操作进行安全检查,可以有效防止未授权的访问和操作。Spring AOP(面向切面编程)提供了一种优雅的方式来实现安全检查,而无需修改业务逻辑代码。本文将…...

别再手动改路由了!用Ant Design Vue的Menu组件动态生成“顶一左多”级导航菜单
基于Ant Design Vue的声明式导航菜单架构设计 在复杂后台管理系统开发中,导航菜单的动态生成与权限控制一直是架构设计的难点。传统方案往往需要在多个组件中硬编码菜单结构,导致维护成本高、权限同步困难。本文将介绍如何利用Ant Design Vue的Menu组件与…...

tabtoy性能优化秘籍:多核并发导出与缓存加速技巧
tabtoy性能优化秘籍:多核并发导出与缓存加速技巧 【免费下载链接】tabtoy 高性能表格数据导出器 项目地址: https://gitcode.com/gh_mirrors/ta/tabtoy 在处理大量表格数据导出时,性能往往是开发者面临的主要挑战。tabtoy作为一款高性能表格数据导…...

PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解
PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解 在处理数据库时,日期和时间操作几乎是每个开发者都会遇到的挑战。PostgreSQL作为功能强大的开源关系型数据库,提供了丰富的日期时间处理函数,能够…...

AI图像生成预设库:开源项目kaushalrao/ai-editor-presets使用指南
1. 项目概述:AI驱动的编辑预设库如果你和我一样,经常在各类AI图像生成工具里“炼丹”,那你一定对“预设”(Presets)这个概念不陌生。简单来说,预设就是一套预先配置好的参数组合,它能让你一键复…...

Dell R630服务器RAID实战:8块硬盘如何混搭RAID1和RAID0?保姆级图文教程
Dell R630服务器混合RAID配置实战:系统盘与数据盘的黄金分割方案 在企业级IT基础设施中,存储配置的灵活性与可靠性往往决定着整个系统的稳定边界。当一台Dell PowerEdge R630服务器配备8块硬盘时,如何通过RAID技术的组合拳实现系统安全与数据…...

从架构到体验:友猫社区平台的全栈技术解析与功能体系详解
一、项目概述 友猫社区平台由宠友信息技术有限公司自主研发,是一套面向社区、社交、电商和即时通讯一体化的综合型系统。 平台采用前后端分离、Java微服务架构,配合VueUniApp多端适配方案,能够支持Web端、Android端与iOS端同步运行。 演示网…...

Mastra AI编排框架:构建生产级智能工作流的完整指南
1. 项目概述:一个面向开发者的AI应用编排框架最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:如何把不同的AI模型、工具和数据源高效地串联起来,形成一个稳定、可维护的智能工作流。无论是想做个智能客服,还是搞…...

Arm Neoverse CMN-650架构与缓存一致性协议解析
1. Arm Neoverse CMN-650架构概述在现代多核处理器设计中,缓存一致性互连网络是决定系统扩展性和性能的关键组件。Arm Neoverse CMN-650作为第二代Coherent Mesh Network解决方案,采用了创新的分布式目录协议和优化的传输机制,能够支持多达12…...

【仅限首批内测用户验证】:Midjourney v8“隐性美学协议”曝光——92%设计师尚未察觉的4类负向提示陷阱
更多请点击: https://intelliparadigm.com 第一章:Midjourney v8“隐性美学协议”的本质解构 Midjourney v8 并未公开发布传统意义上的“美学参数文档”,其核心创新在于将图像生成的审美判断内化为一套不可见但可触发的上下文响应机制——即…...

PP 蜂窝板生产线智能控制系统架构与 PLC 程序设计思路
PP 蜂窝板生产线智能控制系统架构与 PLC 程序设计思路摘要:针对 PP 蜂窝板产线多段速度同步、温度压力闭环、真空度稳定与定长裁切精度要求,本文介绍基于 PLCHMI 的智能控制系统整体架构,分模块阐述挤出温控、真空定型、牵引同步、在线测厚与…...