Apache Flink类型及序列化研读生产应用|得物技术
一、背景
序列化是指将数据从内存中的对象序列化为字节流,以便在网络中传输或持久化存储。序列化在Apache Flink中非常重要,因为它涉及到数据传输和状态管理等关键部分。Apache Flink以其独特的方式来处理数据类型以及序列化,这种方式包括它自身的类型描述符、泛型类型提取以及类型序列化框架。本文将简单介绍它们背后的概念和基本原理,侧重分享在DataStream、Flink SQL自定义函数开发中对数据类型和序列的应用,以提升任务的运行效率。
二、简单理论阐述(基于Flink 1.13)
主要参考Apache Flink 1.13
支持的数据类型
- Java Tuples and Scala Case Classes
- Java POJOs
- Primitive Types
- Regular Classes
- Values
- Hadoop Writables
- Special Types
具体的数据类型定义在此就不详细介绍了,具体描述可以前往Flink官网查看。
TypeInformation
Apache Flink量身定制了一套序列化框架,好处就是选择自己定制的序列化框架,对类型信息了解越多,可以在早期完成类型检查,更好地选取序列化方式,进行数据布局,节省数据的存储空间,甚至直接操作二进制数据。
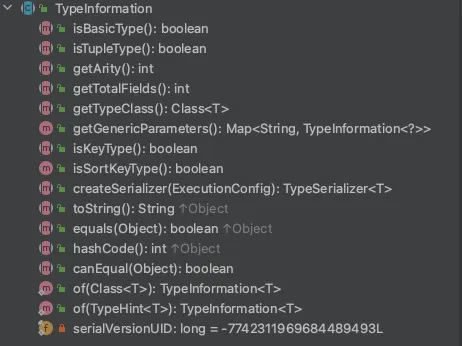
TypeInformation类是Apache Flink所有类型描述符的基类,通过阅读源码,我们可以大概分成以下几种数据类型。
- Basic types:所有的Java类型以及包装类:void,String,Date,BigDecimal,and BigInteger等。
- Primitive arrays以及Object arrays
- Composite types
- Flink Java Tuples(Flink Java API的一部分):最多25个字段,不支持空字段
- Scala case classes(包括Scala Tuples):不支持null字段
- Row:具有任意数量字段并支持空字段的Tuples
- POJO 类:JavaBeans
- Auxiliary types (Option,Either,Lists,Maps,…)
- Generic types:Flink内部未维护的类型,这种类型通常是由Kryo序列化。
我们简单看下该类的方法,核心是createSerializer,获取org.apache.flink.api.common.typeutils.TypeSerializer,执行序列化以及反序列化方法,主要是:
- org.apache.flink.api.common.typeutils.TypeSerializer#serialize
- org.apache.flink.api.common.typeutils.TypeSerializer#deserialize(org.apache.flink.core.memory.DataInputView)
何时需要数据类型获取
在Apache Flink中,算子间的数据类型传递是通过流处理的数据流来实现的。数据流可以在算子之间流动,每个算子对数据流进行处理并产生输出。当数据流从一个算子流向另一个算子时,数据的类型也会随之传递。Apache Flink使用自动类型推断机制来确定数据流中的数据类型。在算子之间传递数据时,Apache Flink会根据上下文自动推断数据的类型,并在运行时保证数据的类型一致性。
举个例子:新增一个kafka source,这个时候我们需要指定数据输出类型。
@Experimental
public <OUT> DataStreamSource<OUT> fromSource(Source<OUT, ?, ?> source,WatermarkStrategy<OUT> timestampsAndWatermarks,String sourceName,TypeInformation<OUT> typeInfo) {final TypeInformation<OUT> resolvedTypeInfo =getTypeInfo(source, sourceName, Source.class, typeInfo);return new DataStreamSource<>(this,checkNotNull(source, "source"),checkNotNull(timestampsAndWatermarks, "timestampsAndWatermarks"),checkNotNull(resolvedTypeInfo),checkNotNull(sourceName));
}
那输入类型怎么不需要指定呢?可以简单看下OneInputTransformation(单输入算子的基类)类的getInputType()方法,就是以输入算子的输出类型为输入类型的。
/** Returns the {@code TypeInformation} for the elements of the input. */
public TypeInformation<IN> getInputType() {return input.getOutputType();
}
这样source的输出类型会变成下一个算子的输入。整个DAG的数据类型都会传递下去。Apache Flink获取到数据类型后,就可以获取对应的序列化方法。
还有一种情况就是与状态后端交互的时候需要获取数据类型,特别是非JVM堆存储的后端,需要频繁的序列化以及反序列化,例如RocksDBStateBackend。
举个例子,当我们使用ValueState时需要调用以下API:
org.apache.flink.streaming.api.operators.StreamingRuntimeContext#getState
@Override
public <T> ValueState<T> getState(ValueStateDescriptor<T> stateProperties) {KeyedStateStore keyedStateStore = checkPreconditionsAndGetKeyedStateStore(stateProperties);stateProperties.initializeSerializerUnlessSet(getExecutionConfig());return keyedStateStore.getState(stateProperties);
}public void initializeSerializerUnlessSet(ExecutionConfig executionConfig) {if (serializerAtomicReference.get() == null) {checkState(typeInfo != null, "no serializer and no type info");// try to instantiate and set the serializerTypeSerializer<T> serializer = typeInfo.createSerializer(executionConfig);// use cas to assure the singletonif (!serializerAtomicReference.compareAndSet(null, serializer)) {LOG.debug("Someone else beat us at initializing the serializer.");}}
}
可以从org.apache.flink.api.common.state.StateDescriptor#initializeSerializerUnlessSet方法看出,需要通过传入的数据类型来获取具体的序列化器。来执行具体的序列化和反序列化逻辑,完成数据的交互。
数据类型的自动推断
乍一看很复杂,各个环节都需要指定数据类型。其实大部分应用场景下,我们不用关注数据的类型以及序列化方式。Flink会尝试推断有关分布式计算期间交换和存储的数据类型的信息。
这里简单介绍Flink类型自动推断的核心类:
org.apache.flink.api.java.typeutils.TypeExtractor
在数据流操作中,Flink使用了泛型来指定输入和输出的类型。例如,DataStream表示一个具有类型T的数据流。在代码中使用的泛型类型参数T会被TypeExtractor类解析和推断。在运行时,Apache Flink会通过调用TypeExtractor的静态方法来分析操作的输入和输出,并将推断出的类型信息存储在运行时的环境中。
举个例子:用的最多的flatMap算子,当我们不指定返回类型的时候,Flink会调用TypeExtractor类自动去推断用户的类型。
public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) {TypeInformation<R> outType = TypeExtractor.getFlatMapReturnTypes((FlatMapFunction)this.clean(flatMapper), this.getType(), Utils.getCallLocationName(), true);return this.flatMap(flatMapper, outType);
}
一般看开源框架某个类的功能我都会先看类的注释,也看TypeExtractor的注释,大概意思这是一个对类进行反射分析的实用程序,用于确定返回的数据类型。
/*** A utility for reflection analysis on classes, to determine the return type of implementations of* transformation functions.** <p>NOTES FOR USERS OF THIS CLASS: Automatic type extraction is a hacky business that depends on a* lot of variables such as generics, compiler, interfaces, etc. The type extraction fails regularly* with either {@link MissingTypeInfo} or hard exceptions. Whenever you use methods of this class,* make sure to provide a way to pass custom type information as a fallback.*/
我们来看下其中一个核心的静态推断逻辑,org.apache.flink.api.java.typeutils.TypeExtractor#getUnaryOperatorReturnType
@PublicEvolving
public static <IN, OUT> TypeInformation<OUT> getUnaryOperatorReturnType(Function function,Class<?> baseClass,int inputTypeArgumentIndex,int outputTypeArgumentIndex,int[] lambdaOutputTypeArgumentIndices,TypeInformation<IN> inType,String functionName,boolean allowMissing) {Preconditions.checkArgument(inType == null || inputTypeArgumentIndex >= 0,"Input type argument index was not provided");Preconditions.checkArgument(outputTypeArgumentIndex >= 0, "Output type argument index was not provided");Preconditions.checkArgument(lambdaOutputTypeArgumentIndices != null,"Indices for output type arguments within lambda not provided");// explicit result type has highest precedenceif (function instanceof ResultTypeQueryable) {return ((ResultTypeQueryable<OUT>) function).getProducedType();}// perform extractiontry {final LambdaExecutable exec;try {exec = checkAndExtractLambda(function);} catch (TypeExtractionException e) {throw new InvalidTypesException("Internal error occurred.", e);}if (exec != null) {// parameters must be accessed from behind, since JVM can add additional parameters// e.g. when using local variables inside lambda function// paramLen is the total number of parameters of the provided lambda, it includes// parameters added through closurefinal int paramLen = exec.getParameterTypes().length;final Method sam = TypeExtractionUtils.getSingleAbstractMethod(baseClass);// number of parameters the SAM of implemented interface has; the parameter indexing// applies to this rangefinal int baseParametersLen = sam.getParameterTypes().length;final Type output;if (lambdaOutputTypeArgumentIndices.length > 0) {output =TypeExtractionUtils.extractTypeFromLambda(baseClass,exec,lambdaOutputTypeArgumentIndices,paramLen,baseParametersLen);} else {output = exec.getReturnType();TypeExtractionUtils.validateLambdaType(baseClass, output);}return new TypeExtractor().privateCreateTypeInfo(output, inType, null);} else {if (inType != null) {validateInputType(baseClass, function.getClass(), inputTypeArgumentIndex, inType);}return new TypeExtractor().privateCreateTypeInfo(baseClass,function.getClass(),outputTypeArgumentIndex,inType,null);}} catch (InvalidTypesException e) {if (allowMissing) {return (TypeInformation<OUT>)new MissingTypeInfo(functionName != null ? functionName : function.toString(), e);} else {throw e;}}
}
- 首先判断该算子是否实现了ResultTypeQueryable接口,本质上就是用户是否显式指定了数据类型,例如我们熟悉的Kafka source就实现了该方法,当使用了JSONKeyValueDeserializationSchema,就显式指定了类型,用户自定义Schema就需要自己指定。
public class KafkaSource<OUT>implements Source<OUT, KafkaPartitionSplit, KafkaSourceEnumState>,ResultTypeQueryable<OUT>
//deserializationSchema 是需要用户自己定义的。
@Override
public TypeInformation<OUT> getProducedType() {return deserializationSchema.getProducedType();
}
//JSONKeyValueDeserializationSchema
@Override
public TypeInformation<ObjectNode> getProducedType() {return getForClass(ObjectNode.class);
}
- 未实现ResultTypeQueryable接口,就会通过反射的方法获取ReturnType,判断逻辑大概是从是否是Java 8 lambda方法开始判断的。获取到返回类型后再通过new TypeExtractor()).privateCreateTypeInfo(output,inType,(TypeInformation)null)封装成Flink内部能识别的数据类型;大致分为2类,泛型类型变量TypeVariable以及非泛型类型变量。这个封装的过程也是非常重要的,推断的数据类型是Flink内部封装好的类型,序列化基本都很高效,如果不是, 就会推断为GenericTypeInfo走Kryo等序列化方式。如感兴趣,可以看下这块的源码,在此不再赘述。
通过以上的代码逻辑的阅读,我们大概能总结出以下结论:Flink内部维护了很多高效的序列化方式,通常只有数据类型被推断为org.apache.flink.api.java.typeutils.GenericTypeInfo时我们才需要自定义序列化类型,否则性能就是灾难;或者无法推断类型的时候,例如Flink SQL复杂类型有时候是无法自动推断类型的,当然某些特殊的对象Kryo也无法序列化,比如之前遇到过TreeMap无法Kryo序列化 (也可能是自己姿势不对),建议在开发Apache Flink作业时可以养成显式指定数据类型的好习惯。
三、开发实践
Flink代码作业
如何显式指定数据类型
这个简单了,几乎所有的source、Keyby、算子等都暴露了指定TypeInformation typeInfo的构造方法,以下简单列举几个:
- source
@Experimental
public <OUT> DataStreamSource<OUT> fromSource(Source<OUT, ?, ?> source, WatermarkStrategy<OUT> timestampsAndWatermarks, String sourceName, TypeInformation<OUT> typeInfo) {TypeInformation<OUT> resolvedTypeInfo = this.getTypeInfo(source, sourceName, Source.class, typeInfo);return new DataStreamSource(this, (Source)Preconditions.checkNotNull(source, "source"), (WatermarkStrategy)Preconditions.checkNotNull(timestampsAndWatermarks, "timestampsAndWatermarks"), (TypeInformation)Preconditions.checkNotNull(resolvedTypeInfo), (String)Preconditions.checkNotNull(sourceName));
}
- map
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) {return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
- 自定义Operator
@PublicEvolving
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {return this.doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
- keyBy
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key, TypeInformation<K> keyType) {Preconditions.checkNotNull(key);Preconditions.checkNotNull(keyType);return new KeyedStream(this, (KeySelector)this.clean(key), keyType);
}
- 状态后端
public ValueStateDescriptor(String name, TypeInformation<T> typeInfo) {super(name, typeInfo, (Object)null);
}
自定义数据类型&自定义序列化器
当遇到复杂数据类型,或者需要优化任务性能时,需要自定义数据类型,以下分享几种场景以及实现代码:
- POJO类
例如大家最常用的POJO类,何为POJO类大家可以自行查询,Flink对POJO类做了大量的优化,大家使用Java对象最好满足POJO的规范。
举个例子,这是一个典型的POJO类:
@Data
public class BroadcastConfig implements Serializable {public String config_type;public String date;public String media_id;public String account_id;public String label_id;public long start_time;public long end_time;public int interval;public String msg;public BroadcastConfig() {}}
我们可以这样指定其数据类型,返回的数据类就是一个TypeInformation
HashMap<String, TypeInformation<?>> pojoFieldName = new HashMap<>();
pojoFieldName.put("config_type", Types.STRING);
pojoFieldName.put("date", Types.STRING);
pojoFieldName.put("media_id", Types.STRING);
pojoFieldName.put("account_id", Types.STRING);
pojoFieldName.put("label_id", Types.STRING);
pojoFieldName.put("start_time", Types.LONG);
pojoFieldName.put("end_time", Types.LONG);
pojoFieldName.put("interval", Types.INT);
pojoFieldName.put("msg", Types.STRING);return Types.POJO(BroadcastConfig.class,pojoFieldName
);
如感兴趣,可以看下org.apache.flink.api.java.typeutils.runtime.PojoSerializer,看Flink本身对其做了哪些优化。
- 自定义TypeInformation
某些特殊场景可能还需要复杂的对象,例如,需要极致的性能优化,在Flink Table Api中数据对象传输,大部分都是BinaryRowdata,效率非常高。我们在Flink Datastram代码作业中也想使用,怎么操作呢?这里分享一种实现方式——自定义TypeInformation,当然还有更优的实现方式,这里就不介绍了。
代码实现:本质上就是继承TypeInformation,实现对应的方法。核心逻辑是createSerializer()方法,这里我们直接使用Table Api中已经实现的BinaryRowDataSerializer,就可以达到同Flink SQL相同的性能优化。
public class BinaryRowDataTypeInfo extends TypeInformation<BinaryRowData> {private static final long serialVersionUID = 4786289562505208256L;private final int numFields;private final Class<BinaryRowData> clazz;private final TypeSerializer<BinaryRowData> serializer;public BinaryRowDataTypeInfo(int numFields) {this.numFields=numFields;this.clazz=BinaryRowData.class;serializer= new BinaryRowDataSerializer(numFields);}@Overridepublic boolean isBasicType() {return false;}@Overridepublic boolean isTupleType() {return false;}@Overridepublic int getArity() {return numFields;}@Overridepublic int getTotalFields() {return numFields;}@Overridepublic Class<BinaryRowData> getTypeClass() {return this.clazz;}@Overridepublic boolean isKeyType() {return false;}@Overridepublic TypeSerializer<BinaryRowData> createSerializer(ExecutionConfig config) {return serializer;}@Overridepublic String toString() {return "BinaryRowDataTypeInfo<" + clazz.getCanonicalName() + ">";}@Overridepublic boolean equals(Object obj) {if (obj instanceof BinaryRowDataTypeInfo) {BinaryRowDataTypeInfo that = (BinaryRowDataTypeInfo) obj;return that.canEqual(this)&& this.numFields==that.numFields;} else {return false;}}@Overridepublic int hashCode() {return Objects.hash(this.clazz,serializer.hashCode());}@Overridepublic boolean canEqual(Object obj) {return obj instanceof BinaryRowDataTypeInfo;}
}
所以这里建议Apache Flink代码作业开发可以尽可能使用已经优化好的数据类型,例如BinaryRowdata,可以用于高性能的数据处理场景,例如在内存中进行批处理或流式处理。由于数据以二进制形式存储,可以更有效地使用内存和进行数据序列化。同时,BinaryRowData还提供了一组方法,用于访问和操作二进制数据。
- 自定义TypeSerializer
上面的例子只是自定义了TypeInformation,当然还会遇到自定义TypeSerializer的场景,例如Apache Flink本身没有封装的数据类型。
代码实现:这里以位图存储Roaring64Bitmap为例,在某些特殊场景可以使用bitmap精准去重,减少存储空间。
我们需要继承TypeSerializer,实现其核心逻辑也是serialize() 、deserialize() 方法,可以使用Roaring64Bitmap自带的序列化、反序列化方法。如果你使用的复杂对象没有提供序列化方法,你也可以自己实现或者找开源的序列化器。有了自定义的TypeSerializer就可以在你自定义的TypeInformation中调用。
public class Roaring64BitmapTypeSerializer extends TypeSerializer<Roaring64Bitmap> {/*** Sharable instance of the Roaring64BitmapTypeSerializer.*/public static final Roaring64BitmapTypeSerializer INSTANCE = new Roaring64BitmapTypeSerializer();private static final long serialVersionUID = -8544079063839253971L;@Overridepublic boolean isImmutableType() {return false;}@Overridepublic TypeSerializer<Roaring64Bitmap> duplicate() {return this;}@Overridepublic Roaring64Bitmap createInstance() {return new Roaring64Bitmap();}@Overridepublic Roaring64Bitmap copy(Roaring64Bitmap from) {Roaring64Bitmap copiedMap = new Roaring64Bitmap();from.forEach(copiedMap::addLong);return copiedMap;}@Overridepublic Roaring64Bitmap copy(Roaring64Bitmap from, Roaring64Bitmap reuse) {from.forEach(reuse::addLong);return reuse;}@Overridepublic int getLength() {return -1;}@Overridepublic void serialize(Roaring64Bitmap record, DataOutputView target) throws IOException {record.serialize(target);}@Overridepublic Roaring64Bitmap deserialize(DataInputView source) throws IOException {Roaring64Bitmap navigableMap = new Roaring64Bitmap();navigableMap.deserialize(source);return navigableMap;}@Overridepublic Roaring64Bitmap deserialize(Roaring64Bitmap reuse, DataInputView source) throws IOException {reuse.deserialize(source);return reuse;}@Overridepublic void copy(DataInputView source, DataOutputView target) throws IOException {Roaring64Bitmap deserialize = this.deserialize(source);copy(deserialize);}@Overridepublic boolean equals(Object obj) {if (obj == this) {return true;} else if (obj != null && obj.getClass() == Roaring64BitmapTypeSerializer.class) {return true;} else {return false;}}@Overridepublic int hashCode() {return this.getClass().hashCode();}@Overridepublic TypeSerializerSnapshot<Roaring64Bitmap> snapshotConfiguration() {return new Roaring64BitmapTypeSerializer.Roaring64BitmapSerializerSnapshot();}public static final class Roaring64BitmapSerializerSnapshotextends SimpleTypeSerializerSnapshot<Roaring64Bitmap> {public Roaring64BitmapSerializerSnapshot() {super(() -> Roaring64BitmapTypeSerializer.INSTANCE);}}
}
Flink SQL自定义函数
如何显式指定数据类型
这里简单分享下,在自定义Function开发下遇到复杂数据类型无法在accumulator 或者input、output中使用的问题,这里我们只介绍使用复杂数据对象如何指定数据类型的场景。
我们可以先看下FunctionDefinitionConvertRule,这是Apache Flink中的一个规则(Rule),用于将用户自定义的函数定义转换为对应的实现。其中通过getTypeInference()方法返回用于执行对此函数定义的调用的类型推理的逻辑。
@Override
public Optional<RexNode> convert(CallExpression call, ConvertContext context) {FunctionDefinition functionDefinition = call.getFunctionDefinition();// built-in functions without implementation are handled separatelyif (functionDefinition instanceof BuiltInFunctionDefinition) {final BuiltInFunctionDefinition builtInFunction =(BuiltInFunctionDefinition) functionDefinition;if (!builtInFunction.getRuntimeClass().isPresent()) {return Optional.empty();}}TypeInference typeInference =functionDefinition.getTypeInference(context.getDataTypeFactory());if (typeInference.getOutputTypeStrategy() == TypeStrategies.MISSING) {return Optional.empty();}switch (functionDefinition.getKind()) {case SCALAR:case TABLE:List<RexNode> args =call.getChildren().stream().map(context::toRexNode).collect(Collectors.toList());final BridgingSqlFunction sqlFunction =BridgingSqlFunction.of(context.getDataTypeFactory(),context.getTypeFactory(),SqlKind.OTHER_FUNCTION,call.getFunctionIdentifier().orElse(null),functionDefinition,typeInference);return Optional.of(context.getRelBuilder().call(sqlFunction, args));default:return Optional.empty();}
}
那我们指定复杂类型也会从通过该方法实现,不多说了,直接上代码实现。
- 指定accumulatorType
这是之前写的AbstractLastValueWithRetractAggFunction功能主要是为了实现具有local-global的逻辑的LastValue,提升作业性能。
accumulator对象:LastValueWithRetractAccumulator,可以看到该对象是一个非常复杂的对象,包含5个属性,还有List 复杂嵌套,以及MapView等可以操作状态后端的对象,甚至有Object这种通用的对象。
public static class LastValueWithRetractAccumulator {public Object lastValue = null;public Long lastOrder = null;public List<Tuple2<Object, Long>> retractList = new ArrayList<>();public MapView<Object, List<Long>> valueToOrderMap = new MapView<>();public MapView<Long, List<Object>> orderToValueMap = new MapView<>();@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (!(o instanceof LastValueWithRetractAccumulator)) {return false;}LastValueWithRetractAccumulator that = (LastValueWithRetractAccumulator) o;return Objects.equals(lastValue, that.lastValue)&& Objects.equals(lastOrder, that.lastOrder)&& Objects.equals(retractList, that.retractList)&& valueToOrderMap.equals(that.valueToOrderMap)&& orderToValueMap.equals(that.orderToValueMap);}@Overridepublic int hashCode() {return Objects.hash(lastValue, lastOrder, valueToOrderMap, orderToValueMap, retractList);}}
getTypeInference() 是FunctionDefinition接口的方法,而所有的用户自定义函数都实现了该接口,我们只需要重新实现下该方法就可以,以下是代码实现。
这里我们还需要用到工具类TypeInference,这是Flink中的一个模块,用于进行类型推断和类型推理。
可以看出我们在accumulatorTypeStrategy方法中传入了一个构建好的TypeStrategy;这里我们将LastValueWithRetractAccumulator定义为了一个STRUCTURED,不同的属性定义为具体的数据类型,DataTypes工具类提供了很多丰富的对象形式,还有万能的RAW类型。
public TypeInference getTypeInference(DataTypeFactory typeFactory) {return TypeInference.newBuilder().accumulatorTypeStrategy(callContext -> {List<DataType> dataTypes = callContext.getArgumentDataTypes();DataType argDataType;if (dataTypes.get(0).getLogicalType().getTypeRoot().getFamilies().contains(LogicalTypeFamily.CHARACTER_STRING)) {argDataType = DataTypes.STRING();} elseargDataType = DataTypeUtils.toInternalDataType(dataTypes.get(0));DataType accDataType = DataTypes.STRUCTURED(LastValueWithRetractAccumulator.class,DataTypes.FIELD("lastValue", argDataType.nullable()),DataTypes.FIELD("lastOrder", DataTypes.BIGINT()),DataTypes.FIELD("retractList", DataTypes.ARRAY(DataTypes.STRUCTURED(Tuple2.class,DataTypes.FIELD("f0", argDataType.nullable()),DataTypes.FIELD("f1", DataTypes.BIGINT()))).bridgedTo(List.class)),DataTypes.FIELD("valueToOrderMap",MapView.newMapViewDataType(argDataType.nullable(),DataTypes.ARRAY(DataTypes.BIGINT()).bridgedTo(List.class))),//todo:blink 使用SortedMapView 优化性能,开源使用MapView key天然字典升序,倒序遍历性能可能不佳DataTypes.FIELD("orderToValueMap",MapView.newMapViewDataType(DataTypes.BIGINT(),DataTypes.ARRAY(argDataType.nullable()).bridgedTo(List.class))));return Optional.of(accDataType);}).build();
}
- 指定outputType
这个也很简单,直接上代码实现,主要就是outputTypeStrategy中传入需要输出的数据类型即可。
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {return TypeInference.newBuilder().outputTypeStrategy(callContext -> {List<DataType> dataTypes = callContext.getArgumentDataTypes();DataType argDataType;if (dataTypes.get(0).getLogicalType().getTypeRoot().getFamilies().contains(LogicalTypeFamily.CHARACTER_STRING)) {argDataType = DataTypes.STRING();} elseargDataType = DataTypeUtils.toInternalDataType(dataTypes.get(0));return Optional.of(argDataType);}).build();
}
- 指定intputType
在此就不做介绍了,同以上类似,在inputTypeStrategy方法传入定义好的TypeStrategy就好。
- 根据inputType动态调整outType或者accumulatorType
在某些场景下,我们需要让函数功能性更强,比如当我输入是bigint类型的时候,我输出bigint类型等,类似的逻辑。
大家可以发现outputTypeStrategy或者 accumulatorTypeStrategy的入参都是 实现了 TypeStrategy接口的对象,并且需要实现inferType方法。在Flink框架调用该方法的时候会传入一个上下文对象CallContext,提供了获取函数入参类型的api getArgumentDataTypes();
代码实现:这里的逻辑是将获取到的第一个入参对象的类型指定为输出对象的类型。
.outputTypeStrategy(callContext -> {List<DataType> dataTypes = callContext.getArgumentDataTypes();DataType argDataType;if (dataTypes.get(0).getLogicalType().getTypeRoot().getFamilies().contains(LogicalTypeFamily.CHARACTER_STRING)) {argDataType = DataTypes.STRING();} elseargDataType = DataTypeUtils.toInternalDataType(dataTypes.get(0));return Optional.of(argDataType);
}
自定义DataType
可以发现以上分享几乎都是使用的DataTypes封装好的类型,比如DataTypes.STRING()、DataTypes.Long()等。那如果我们需要封装一些其他对象如何操作呢?上文提到DataTypes提供了一个自定义任意类型的方法。
/*** Data type of an arbitrary serialized type. This type is a black box within the table* ecosystem and is only deserialized at the edges.** <p>The raw type is an extension to the SQL standard.** <p>This method assumes that a {@link TypeSerializer} instance is present. Use {@link* #RAW(Class)} for automatically generating a serializer.** @param clazz originating value class* @param serializer type serializer* @see RawType*/
public static <T> DataType RAW(Class<T> clazz, TypeSerializer<T> serializer) {return new AtomicDataType(new RawType<>(clazz, serializer));
}
我们有这样的一个场景,需要在自定义的函数中使用bitmap计算UV值,需要定义Roaring64Bitmap为accumulatorType,直接上代码实现。
这里的Roaring64BitmapTypeSerializer已经在《自定义TypeSerializer》小段中实现,有兴趣的同学可以往上翻翻。
public TypeInference getTypeInference(DataTypeFactory typeFactory) {return TypeInference.newBuilder().accumulatorTypeStrategy(callContext -> {DataType type = DataTypes.RAW(Roaring64Bitmap.class,Roaring64BitmapTypeSerializer.INSTANCE);return Optional.of(type);}).outputTypeStrategy(callContext -> Optional.of(DataTypes.BIGINT())).build();
}
四、结语
本文主要简单分享了一些自身对Flink类型及序列化的认识和应用实践,能力有限,不足之处欢迎指正。
引用:
https://nightlies.apache.org/flink/flink-docs-release-1.13/
*文/ 木木
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!
相关文章:
Apache Flink类型及序列化研读生产应用|得物技术
一、背景 序列化是指将数据从内存中的对象序列化为字节流,以便在网络中传输或持久化存储。序列化在Apache Flink中非常重要,因为它涉及到数据传输和状态管理等关键部分。Apache Flink以其独特的方式来处理数据类型以及序列化,这种方式包括它…...

如何使用代理 IP 防止多个 Facebook 帐户关联 - 最佳实践
在社交媒体被广泛应用的今天,Facebook作为全球最大的社交网络平台之一,面临着很多挑战,其中之一就是用户行为的管理和安全。 为了防止多个账户之间的关联和滥用,Facebook需要采取一系列措施,其中包括使用静态住宅代理…...

DDei在线设计器-API-DDeiAbstractShape
DDeiAbstractShape DDeiAbstractShape代表是所有可见图形的父类,定义了图形所需要的公共属性和方法。 DDeiAbstractShape实例包含了一个图形的所有数据和渲染器,在获取后可以通过它访问其他内容。DDeiAbstractShape中的layer指向所在图层,stage指向所…...

IPython的使用技巧整理
关于IPython的使用技巧有很多,这里只是梳理了几个常用的以及我目前遇到过的,其他的技巧还没使用过,所以就没有列出来。 01|Tab键自动完成:在shell中输入表达式时,只要按下Tab键,当前命名空间中任何与已输入的字符串相…...

vue项目纯前端实现导出pdf文件
1、下载插件 npm install html2canvas npm install jspdf2、创建htmlToPdf.js,地址:src/utils/htmlToPdf.js import html2Canvas from html2Canvas import JsPDF from jspdf export default { install(Vue, options) { Vue.prototype.getPdfFromH…...
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
以Bert训练为例,测试torch不同的运行方式,并用torch.profileHolisticTraceAnalysis分析性能瓶颈 1.参考链接:2.性能对比3.相关依赖或命令4.测试代码5.HolisticTraceAnalysis代码6.可视化A.优化前B.优化后 以Bert训练为例,测试torch不同的运行方式,并用torch.profileHolisticTra…...

地球地图:快速进行先进土地监测和气候评估的新工具Earth Map
地球地图:快速进行先进土地监测和气候评估的新工具 这个工具是居于GEE 开发的多功能的一个APP应用,主要进行土地监测和气候评估 Earth Map 什么是地球地图? 地球地图是联合国粮食及农业组织(粮农组织)在粮农组织与谷歌合作框架内开发的一个创新、免费和开放源码的工具。…...
6.22套题
B. Dark 题意:每次能在数列中能使相邻两个数-1,求当数列没有连续非0值的最小贡献 解法:设表示前i个数中前i-1个数是否为0,当前数是j的最小贡献。表示i1以后减掉d的最小贡献。 C. 幸运值 D. 凤凰院真凶...

openEuler搭建hadoop Standalone 模式
Standalone 升级软件安装常用软件关闭防火墙修改主机名和IP地址修改hosts配置文件下载jdk和hadoop并配置环境变量配置ssh免密钥登录修改配置文件初始化集群windows修改hosts文件测试 1、升级软件 yum -y update2、安装常用软件 yum -y install gcc gcc-c autoconf automake…...

nginx更新https/ssl证书的步骤
一、上传nginx证书到服务器 上传步骤略。。。 二、更新证书 (一)确认nginx的安装目录 我这里的环境是/etc/nginx/ (二)确认nginx的证书目录 查看/etc/nginx/nginx.conf,证书目录就在/etc/nginx目录下 将新的证书tes…...

【Android面试八股文】说一说Handler的sendMessage和postDelay的区别?
文章目录 一、`sendMessage` 方法1.1 主要用法1.2 适用场景二、`postDelayed` 方法2.1 主要用法2.2 适用场景三、 区别总结3.1 区别3.2 本质上有差别吗?四、实例对比4.1 使用`sendMessage`4.2 使用`postDelayed`五、结论Handler类在Android中用于消息传递和任务调度。 sendMe…...
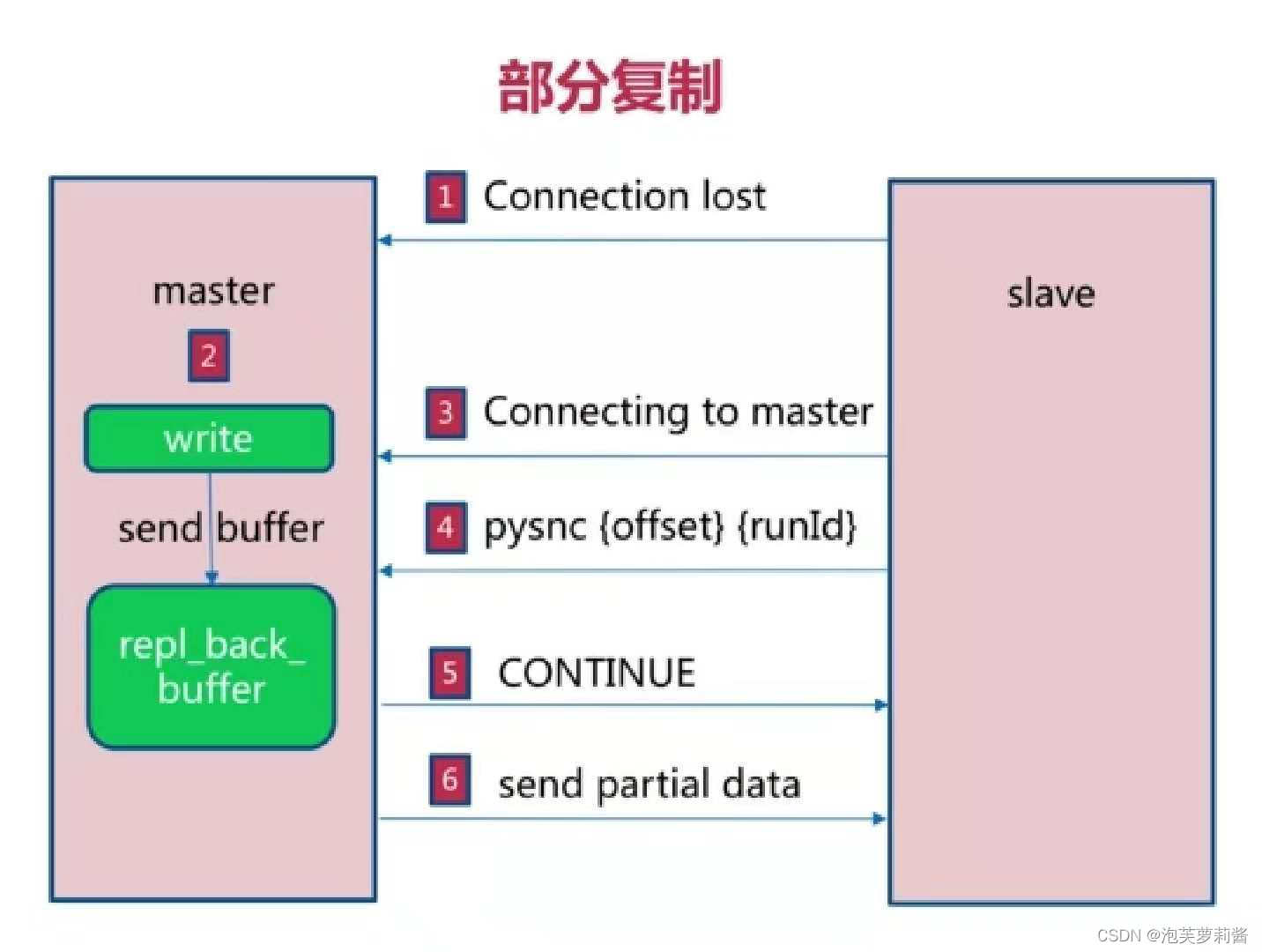
Java学习 - Redis主从复制
主从复制是什么 用于建立一个和主数据库完全一样的数据库环境,称为从数据库 主从复制的作用 数据备份读写分离 主从复制使用方式 通过slaveof命令 创建从节点 redis-slave> slaveof 127.0.0.1 6379取消从节点 redis-slave> slaveof no one通过配置 配置…...

图的拓扑排序
图的拓扑排序(Topological Sorting)是一种线性排序,用于有向无环图(Directed Acyclic Graph,DAG)。拓扑排序将图中的顶点排成一个线性序列,使得对于每一条有向边 (u, v),顶点 u 都排…...

windows USB 设备驱动开发-总章
通用串行总线 (USB) 提供可扩展的即插即用串行接口,确保外围设备的标准、低成本的连接。 USB 设备包括键盘、鼠标、游戏杆、打印机、扫描仪、存储设备、调制解调器、视频会议摄像头等。USB-IF 是一个特别兴趣组 (SIG),负责维护官方 USB 规范、测试规范和…...
springboot解析自定义yml文件
背景 公司产品微服务架构下有十几个模块,几乎大部分模块都要连接redis。每次在客户那里部署应用,都要改十几遍配置,太痛苦了。当然可以用nacos配置中心的功能,配置公共参数。不过我是喜欢在应用级别上解决问题,因为并不…...

【C/C++】静态函数调用类中成员函数方法 -- 最快捷之一
背景 注册回调函数中,回调函数是一个静态函数。需要调用类对象中的一个成员函数进行后续通知逻辑。 方案 定义全局指针,用于指向类对象this指针 static void *s_this_obj;类构造函数中,将全局指针指向所需类的this指针 s_this_obj this…...

佣金的定义和类型
1. 佣金的定义 基本定义:佣金是指在商业交易中,代理人或中介机构为促成交易所获得的报酬。它通常是按交易金额的一定比例计算和支付的。支付方式:佣金可以是固定金额,也可以是交易金额的百分比。 2. 佣金的类型 销售佣金&#…...
)
python数据分析实训任务二(‘风力风向’)
import numpy as np import matplotlib.pyplot as plt # 数据 labelsnp.array([东风, 东北风, 北风, 西北风, 西风, 西南风, 南风, 东南风]) statsnp.array([2.1, 2, 0, 3, 1.5, 3, 6, 4]) # 将角度转换为弧度 anglesnp.linspace(0, 2*np.pi, len(labels), endpointFalse).toli…...
Java技术栈总结:数据库MySQL篇
一、慢查询 1、常见情形 聚合查询 多表查询 表数据量过大查询 深度分页查询 2、定位慢查询 方案一、开源工具 调试工具:Arthas运维工具:Prometheus、Skywalking 方案二、MySQL自带慢日志 在MySQL配置文件 /etc/my.conf 中配置: # …...

vue-cli 项目打包优化-基础篇
1、项目打包完运行空白 引用资源路径问题,打包完的【index.html】文件引用其他文件的引用地址不对 参考配置:https://cli.vuejs.org/zh/config 修改vue.config.js ,根据与 后端 或 运维 沟通修改 module.export {// 默认 publicPath: //…...

1k Star的p-retry,让异步操作失败自动重试
文章目录1k Star的p-retry,让异步操作失败自动重试核心功能适用场景注意事项1k Star的p-retry,让异步操作失败自动重试 sindresorhus开源的p-retry项目,目前在GitHub上获得1009个Star。这个库的核心功能是为异步操作添加重试机制,…...

大语言模型越狱攻击:真实世界提示词生态与防御策略分析
1. 项目概述:一次对“越狱”提示词的田野调查如果你在过去一年里深度使用过ChatGPT、Claude或者国内的文心一言、通义千问这类大语言模型,大概率遇到过这样的情况:你问了一个稍微敏感点的问题,比如“如何制作一个恶作剧软件”&…...

基于MCP协议与Playwright构建AI浏览器自动化服务器
1. 项目概述:当AI助手学会“动手”,一个浏览器自动化MCP服务器的诞生如果你和我一样,日常重度依赖Claude、Cursor这类AI编程助手,那你肯定遇到过这样的场景:你正和AI热烈地讨论一个技术方案,突然需要它帮你…...

在Docker环境中安装Hadoop cluster 实验报告三
在Docker环境中安装Hadoop cluster 实验报告三 1个namenode, 3个datanodes 班 级:物联网2303 学 号:231040700302 姓 名:杜子健 (30%) 安装过程 ContainersHadoop 1.1 Containers 创建与配置 (1)拉取稳定镜像…...

Cesium进阶:CallbackProperty实现Entity动态数据绑定
1. 为什么需要动态数据绑定? 在数字孪生和实时监控场景中,我们经常需要将外部数据源(如GPS定位、传感器读数、MQTT消息)实时反映到三维场景中。传统做法是通过定时器不断更新Entity属性,但这种方式存在两个致命问题&am…...

C语言--day14
指针的常见操作 指针变量,有两方面的意思 一个指针指向的内容(数据值,一级) 指针变量本身存储的数据 (地址值) #include <stdio.h> int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改…...
)
嵌入式调试进阶:JScope RTT模式移植与性能实测(对比HSS,速度提升千倍)
嵌入式调试革命:JScope RTT模式深度优化与高频数据采集实战 在电机控制、电源管理和高速信号处理等嵌入式应用场景中,开发人员经常需要实时监控关键变量的变化趋势。传统调试工具往往面临采样率低、数据延迟大等问题,而SEGGER JScope的RTT模式…...

ESP32-C3原理图设计避坑指南:从电源到天线,新手最容易忽略的7个细节
ESP32-C3原理图设计避坑指南:从电源到天线,新手最容易忽略的7个细节 第一次接触ESP32-C3原理图设计时,很多开发者会直接参考官方规格书,但实际调试时却发现各种奇怪的问题:电源不稳定导致Wi-Fi断连、复位电路响应迟缓、…...

LangChain RAG开发套件:模块化架构与生产级实践指南
1. 项目概述:一个面向RAG应用开发的“瑞士军刀”如果你正在或打算基于LangChain构建检索增强生成(RAG)应用,那么“Vargha-Kh/Langchain-RAG-DevelopmentKit”这个项目,很可能就是你一直在寻找的那个“工具箱”。它不是…...
—— 固件库配置与工程创建实战)
【GD32】从零构建GD32开发环境(Keil 5)—— 固件库配置与工程创建实战
1. 为什么需要配置固件库? 刚接触GD32单片机的朋友可能会有疑问:为什么不能直接在Keil里写代码?这就好比装修房子,固件库就像是提前准备好的建材包,里面已经包含了墙面涂料、地板材料、门窗框架等标准件。如果每次开发…...