迁移学习——CycleGAN
CycleGAN
- 1.导入需要的包
- 2.数据加载
- (1)to_img 函数
- (2)数据加载
- (3)图像转换
- 3.随机读取图像进行预处理
- (1)函数参数
- (2)数据路径
- (3)读取文件列表
- (4)初始化结果列表
- (5)随机采样
- (6)读取和预处理图像
- (7)返回结果
- 4.残差网络块
- (1)构造函数
- (2)残差块层
- (3)跳跃连接
- 5.生成器网络
- (1)构造函数
- (2)编码器部分
- (3)残差块部分
- (4)解码器部分
- (5)输出层
- (6)模型初始化
- (7)前向传播
- 6.判别器网络
- (1)构造函数
- (2)判别器层
- (3)全卷积网络部分
- (4)输出
- 7.缓存生成器
- (1)构造函数
- (2)push_and_pop 方法
- 8.训练生成对抗网络(GAN)
- 9.优化器
- 10.训练循环的迭代次数
- 11.训练循环
- 12.训练生成器
- 13.训练判别器
- 14.损失打印,存储伪造图片
- 全部代码
CycleGAN(循环一致性对抗网络),用于实现两个域(例如,风格或主题不同的图像)之间的无监督图像到图像转换。
CycleGAN的核心思想是使用生成器(Generator)和判别器(Discriminator)来学习从源域(source
domain)到目标域(target domain)的映射,同时保持循环一致性,即从目标域映射回源域应该尽可能接近原始源域图像。
1.导入需要的包
from random import randint: 从Python的random模块中导入randint函数,用于生成随机整数。
import numpy as np: 导入Numpy库,并将其重命名为np,以便在代码中使用。
import torch:导入PyTorch库。
torch.set_default_tensor_type(torch.FloatTensor):设置PyTorch的默认Tensor类型为torch.FloatTensor。
import torch.nn as nn:导入PyTorch的神经网络模块,并将其重命名为nn。
import torch.optim as optim:导入PyTorch的优化器模块,并将其重命名为optim。
import torchvision.datasets as datasets: 导入PyTorch的图像数据集模块,并将其重命名为datasets。
import torchvision.transforms as transforms:导入PyTorch的图像变换模块,并将其重命名为transforms。
import os:导入Python的操作系统模块,用于处理文件和目录。
import matplotlib.pyplot as plt:导入matplotlib的Pyplot模块,用于绘图。
import torch.nn.functional as F:导入PyTorch的函数模块,并将其重命名为F。
from torch.autograd import Variable:从PyTorch的自动求导模块中导入Variable类。
from torchvision.utils import save_image: 从PyTorch的图像处理模块中导入save_image函数。
import shutil:导入Python的文件操作模块,用于删除文件和目录。
import cv2: 导入OpenCV库,用于图像处理和计算机视觉。
import random: 导入Python的随机模块。
from PIL import Image:从Pillow库中导入Image类。
import itertools: 导入Python的迭代工具模块。
from random import randint
import numpy as np
import torch
torch.set_default_tensor_type(torch.FloatTensor)
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import os
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision.utils import save_image
import shutil
import cv2
import random
from PIL import Image
import itertools
2.数据加载
(1)to_img 函数
out = 0.5 * (x + 1): 将输入张量 x 的值从 [-1, 1] 范围转换到 [0, 1] 范围。这是因为在训练过程中,图像通常会被归一化到 [-1, 1] 范围,而显示图像时需要将其转换回 [0, 1] 范围。
out = out.clamp(0, 1): 确保所有像素值都在 [0, 1] 范围内。clamp 函数将小于0的值设为0,大于1的值设为1。
out = out.view(-1, 3, 256, 256): 将张量 out 的形状重新调整为批次的形状,其中每个样本是一个 3通道(RGB)的 256x256 图像。-1 表示自动计算批次大小。
def to_img(x):out = 0.5 * (x + 1)out = out.clamp(0, 1) out = out.view(-1, 3, 256, 256) return out
(2)数据加载
data_path = os.path.abspath('D:\probject\pythonProject1\pytorch\CycleGAN\data'):定义了数据的路径,使用os.path.abspath()将相对路径转换为绝对路径。
image_size = 256:指定图像的大小为256x256。
batch_size = 1:定义了批处理的大小为1。
data_path = os.path.abspath('D:\probject\pythonProject1\pytorch\CycleGAN\data')
image_size = 256
batch_size = 1
(3)图像转换
transform = transforms.Compose([: 创建一个由多个图像转换操作组成的管道。
transforms.Resize(int(image_size * 1.12), Image.BICUBIC): 将图像大小调整为原始大小的 1.12 倍。这样做是为了在后续的随机裁剪中提供更多的裁剪选择。
transforms.RandomCrop(image_size): 从调整大小后的图像中随机裁剪出 256x256 像素大小的区域。
transforms.RandomHorizontalFlip(): 以 50% 的概率随机水平翻转图像。
transforms.ToTensor(): 将 PIL 图像转换为 PyTorch 张量。
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)):对图像进行归一化处理,将每个通道的像素值从 [0, 1] 范围转换为 [-1, 1] 范围。
transform = transforms.Compose([transforms.Resize(int(image_size * 1.12), Image.BICUBIC), transforms.RandomCrop(image_size), transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))])
3.随机读取图像进行预处理
(1)函数参数
batch_size: 一个整数,表示每个批次中图像的数量。默认值为1。
def _get_train_data(batch_size=1):
(2)数据路径
train_a_filepath: 训练集A的文件路径。
train_b_filepath: 训练集B的文件路径。
train_a_filepath = data_path + '\\trainA\\'train_b_filepath = data_path + '\\trainB\\'
(3)读取文件列表
train_a_list: 读取训练集A目录中的所有文件名。
train_b_list: 读取训练集B目录中的所有文件名。
train_a_list = os.listdir(train_a_filepath)train_b_list = os.listdir(train_b_filepath)
(4)初始化结果列表
train_a_result: 存储处理后的训练集A图像。
train_b_result: 存储处理后的训练集B图像。
train_a_result = []train_b_result = []
(5)随机采样
numlist: 从0到训练集A长度之间的范围中随机采样 batch_size 个索引。
numlist = random.sample(range(0, len(train_a_list)), batch_size)
(6)读取和预处理图像
对于 numlist 中的每个索引 i: 读取训练集A和B中对应的文件名。 使用 PIL.Image.open
打开图像文件,并将其转换为RGB格式。 应用之前定义的 transform 方法对图像进行预处理(包括调整大小、裁剪、翻转和归一化)。
将预处理后的图像添加到 train_a_result 和 train_b_result 列表中。
for i in numlist:a_filename = train_a_list[i]a_img = Image.open(train_a_filepath + a_filename).convert('RGB')res_a_img = transform(a_img)train_a_result.append(torch.unsqueeze(res_a_img, 0))b_filename = train_b_list[i]b_img = Image.open(train_b_filepath + b_filename).convert('RGB')res_b_img = transform(b_img)train_b_result.append(torch.unsqueeze(res_b_img, 0))(7)返回结果
使用
torch.cat将train_a_result和train_b_result
列表中的图像堆叠成一个批次,并返回这两个批次的图像。
4.残差网络块
残差块是一种常用的构建块,用于深度卷积神经网络,特别是在
ResNet(残差网络)架构中。它允许网络在学习过程中保留和利用之前层的信息,通过跳跃连接(shortcut
connections)来解决深层网络训练过程中的梯度消失问题。
(1)构造函数
def __init__(self, in_features): 构造函数接收一个参数 in_features,表示输入特征图的通道数。
super(ResidualBlock, self).__init__(): 调用父类 nn.Module 的构造函数。
self.block_layer: 定义一个顺序模型 nn.Sequential,包含残差块的所有层。
class ResidualBlock(nn.Module):def __init__(self, in_features):super(ResidualBlock, self).__init__()self.block_layer = nn.Sequential
(2)残差块层
nn.ReflectionPad2d(1):使用反射填充(padding)来扩展输入张量的边界。这种填充方式在边缘反射输入数据,以保持边缘信息的连续性。
nn.Conv2d(in_features, in_features, 3): 使用 3x3的卷积核进行卷积操作,输入和输出通道数相同。
nn.InstanceNorm2d(in_features):应用实例归一化(Instance Normalization)来对每个样本的特征图进行归一化处理。这与批量归一化(Batch Normalization)不同,它不对整个批次的数据进行归一化,而是对单个样本的特征图进行归一化。
nn.ReLU(inplace=True): 应用 ReLU 激活函数,并设置 inplace=True以便直接修改输入张量,减少内存使用。
(nn.ReflectionPad2d(1),nn.Conv2d(in_features, in_features, 3),nn.InstanceNorm2d(in_features),nn.ReLU(inplace=True),nn.ReflectionPad2d(1),nn.Conv2d(in_features, in_features, 3),nn.InstanceNorm2d(in_features))
(3)跳跃连接
return x + self.block_layer(x): 这是残差块的核心,它将输入张量 x 与
self.block_layer(x) 的输出相加,形成跳跃连接。这样,即使 self.block_layer
的输出为零(即网络未能学习到任何东西),输入 x 仍然可以通过跳跃连接直接传递到下一层,从而保持了信息的流通。
def forward(self, x):return x + self.block_layer(x)
5.生成器网络
生成器的目的是将输入图像从一个域转换到另一个域。
(1)构造函数
super(Generator, self).__init__(): 调用父类 nn.Module 的构造函数。
model: 初始化一个列表,用于存储生成器网络中的层。
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()
(2)编码器部分
nn.ReflectionPad2d(3): 使用反射填充(padding)来扩展输入张量的边界。
nn.Conv2d(3, 64, 7): 使用 7x7 的卷积核将输入图像(3 通道)转换为 64 通道的特征图。
nn.InstanceNorm2d(64):应用实例归一化。
nn.ReLU(inplace=True): 应用 ReLU 激活函数。
for _ in range(2):重复以下层两次,以逐渐减少特征图的尺寸。
nn.Conv2d(in_features, out_features, 3,stride=2, padding=1): 使用 3x3 的卷积核,步长为 2,进行降采样。
nn.InstanceNorm2d(out_features): 应用实例归一化。
nn.ReLU(inplace=True):应用 ReLU 激活函数。
model = [nn.ReflectionPad2d(3), nn.Conv2d(3, 64, 7), nn.InstanceNorm2d(64), nn.ReLU(inplace=True)]in_features = 64out_features = in_features * 2for _ in range(2):model += [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True)]in_features = out_featuresout_features = in_features*2
(3)残差块部分
for _ in range(9): 重复添加 9 个残差块,这些块是 CycleGAN 生成器的核心,用于学习域之间的映射。
for _ in range(9):model += [ResidualBlock(in_features)]
(4)解码器部分
out_features = in_features // 2: 准备进行上采样,将特征图的尺寸加倍。
for _ in range(2): 重复以下层两次,以逐渐增加特征图的尺寸。
nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1): 使用 3x3 的转置卷积核,步长为 2,进行上采样。
nn.InstanceNorm2d(out_features): 应用实例归一化。
nn.ReLU(inplace=True): 应用 ReLU 激活函数。
out_features = in_features // 2for _ in range(2):model += [nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True)]in_features = out_featuresout_features = in_features // 2
(5)输出层
nn.ReflectionPad2d(3): 使用反射填充。
nn.Conv2d(64, 3, 7): 使用 7x7的卷积核将特征图转换回 3 通道的图像。
nn.Tanh(): 应用 Tanh 激活函数,将输出值范围映射到 [-1, 1]。
model += [nn.ReflectionPad2d(3), nn.Conv2d(64, 3, 7), nn.Tanh()]
(6)模型初始化
self.gen = nn.Sequential( * model): 将所有层组合成一个顺序模型。
self.gen = nn.Sequential( * model)
(7)前向传播
def forward(self, x): 定义前向传播函数。
x = self.gen(x): 通过生成器网络传递输入 x。
return x: 返回生成器的输出。
def forward(self, x):x = self.gen(x)return x
6.判别器网络
(1)构造函数
super(Discriminator, self).__init__(): 调用父类 nn.Module 的构造函数。
self.dis: 定义一个顺序模型 nn.Sequential,包含判别器网络的所有层。
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.dis = nn.Sequential
(2)判别器层
nn.Conv2d(3, 64, 4, 2, 1, bias=False): 使用 4x4 的卷积核,步长为2,进行降采样,输入通道数为 3(RGB),输出通道数为 64。
nn.LeakyReLU(0.2, inplace=True): 应用Leaky ReLU 激活函数,设置斜率为 0.2。
for _ in range(3): 重复以下层三次,以逐渐减少特征图的尺寸。
nn.Conv2d(in_features, out_features, 4, 2, 1, bias=False): 使用 4x4 的卷积核,步长为 2,进行降采样。
nn.InstanceNorm2d(out_features): 应用实例归一化。
nn.LeakyReLU(0.2, inplace=True): 应用 Leaky ReLU 激活函数。
(nn.Conv2d(3, 64, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, 4, 2, 1, bias=False),nn.InstanceNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 256, 4, 2, 1, bias=False),nn.InstanceNorm2d(256),nn.LeakyReLU(0.2, inplace=True),
(3)全卷积网络部分
nn.Conv2d(256, 512, 4, padding=1): 使用 4x4 的卷积核,不进行降采样,输入通道数为256,输出通道数为 512。
nn.InstanceNorm2d(512): 应用实例归一化。
nn.LeakyReLU(0.2, inplace=True): 应用 Leaky ReLU 激活函数。
nn.Conv2d(512, 1, 4, padding=1):使用 4x4 的卷积核,不进行降采样,输入通道数为 512,输出通道数为 1。
nn.Conv2d(256, 512, 4, padding=1),nn.InstanceNorm2d(512),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(512, 1, 4, padding=1))
(4)输出
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1):对判别器输出的特征图进行平均池化操作,然后将其展平为一维向量。这个一维向量将作为最终的判别结果,其长度为 1,表示输入图像的真实性(接近 1表示真实,接近 0 表示假)。
def forward(self, x):x = self.dis(x)return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
7.缓存生成器
(1)构造函数
def __init__(self, max_size=50): 定义了一个构造函数 init,用于在创建ReplayBuffer 对象时初始化其属性。
self.max_size = max_size: 初始化缓冲区的大小。
self.data = []: 初始化一个空列表 self.data,用于存储缓存的数据。
class ReplayBuffer():
# """
# 缓存队列,若不足则新增,否则随机替换
# """def __init__(self, max_size=50):self.max_size = max_sizeself.data = []
(2)push_and_pop 方法
def push_and_pop(self, data): 定义了一个方法,用于将新数据推入缓冲区,并在需要时弹出旧数据。
to_return = []: 初始化一个空列表 to_return,用于存储从缓冲区中弹出的数据。
for element in data.data:: 遍历传入的数据 data.data 中的每个元素。
element = torch.unsqueeze(element, 0):将每个元素展平为一维张量。这通常是为了确保张量的形状与预期的形状匹配,以便后续的操作可以正确执行。
if len(self.data) < self.max_size:: 如果缓冲区中还没有达到最大容量,则将新元素添加到缓冲区。
self.data.append(element): 将新元素添加到缓冲区。
to_return.append(element): 将新元素添加到 to_return 列表中。
else:: 如果缓冲区已满,则随机替换缓冲区中的一个元素。
if random.uniform(0,1) > 0.5:: 如果随机数大于 0.5,则从缓冲区中随机选择一个元素替换。
i = random.randint(0, self.max_size-1): 随机选择一个索引。
to_return.append(self.data[i].clone()): 将缓冲区中的元素复制并添加到 to_return列表中。
self.data[i] = element: 用新元素替换缓冲区中的元素。
else:: 如果随机数小于或等于 0.5,则直接添加新元素到 to_return 列表中。
to_return.append(element): 将新元素添加到 to_return 列表中。
return Variable(torch.cat(to_return)): 返回 to_return 列表中所有元素的拼接张量。Variable 是一个 PyTorch 类,用于表示可变的张量。torch.cat 函数用于将多个张量拼接在一起。
def push_and_pop(self, data):to_return = []for element in data.data:element = torch.unsqueeze(element, 0)if len(self.data) < self.max_size:self.data.append(element)to_return.append(element)else:if random.uniform(0,1) > 0.5:i = random.randint(0, self.max_size-1)to_return.append(self.data[i].clone())self.data[i] = elementelse:to_return.append(element)return Variable(torch.cat(to_return))
8.训练生成对抗网络(GAN)
fake_A_buffer = ReplayBuffer(): 创建了一个名为 fake_A_buffer 的 ReplayBuffer实例。ReplayBuffer是一个用于缓存和随机替换数据的结构,在训练循环中用于缓存生成器生成的假图像,以便在后续的训练步骤中用于训练判别器。
fake_B_buffer = ReplayBuffer(): 创建了一个名为 fake_B_buffer 的 ReplayBuffer实例。这个缓冲区的作用与 fake_A_buffer 类似,用于缓存从生成器 netG_B2A 生成的假图像。
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
netG_A2B = Generator(): 创建了一个名为 netG_A2B 的 Generator 实例。Generator是一个用于生成新图像的神经网络,在这里,它将从域 A 生成域 B 的图像。
netG_B2A = Generator(): 创建了一个名为 netG_B2A 的 Generator 实例。这个生成器将从域 B生成域 A 的图像。
netD_A = Discriminator(): 创建了一个名为 netD_A 的 Discriminator实例。Discriminator 是一个用于判断图像是否真实的神经网络,在这里,它用于判断 A 类图像是否真实。
netD_B = Discriminator(): 创建了一个名为 netD_B 的 Discriminator实例。这个判别器用于判断 B 类图像是否真实。
netG_A2B = Generator()
netG_B2A = Generator()
netD_A = Discriminator()
netD_B = Discriminator()
criterion_GAN = torch.nn.MSELoss(): 定义了一个名为 criterion_GAN 的 MSELoss
损失函数。这个损失函数用于计算 GAN 损失,即判别器对真实图像和假图像的预测之间的差异。
criterion_cycle = torch.nn.L1Loss(): 定义了一个名为 criterion_cycle 的 L1Loss损失函数。这个损失函数用于计算循环一致性损失,即生成器生成的图像与其输入图像之间的差异。
criterion_identity = torch.nn.L1Loss(): 定义了一个名为 criterion_identity 的 L1Loss损失函数。这个损失函数用于计算身份损失,即生成器生成的图像与其输入图像之间的差异。
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
d_learning_rate = 3e-4: 定义了判别器的学习率。
g_learning_rate = 3e-4:定义了生成器的 learning rate。
optim_betas = (0.5, 0.999): 定义了优化器的超参数betas,这是用于计算梯度下降的动量项的值。
d_learning_rate = 3e-4
g_learning_rate = 3e-4
optim_betas = (0.5, 0.999)
9.优化器
g_optimizer = optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()), lr=d_learning_rate): 创建了一个名为 g_optimizer 的Adam 优化器实例。Adam 是一种常用的优化算法,用于调整神经网络的权重。这里,itertools.chain函数用于将两个生成器的参数合并为一个单一的迭代器,以便于一起优化。lr 参数指定了学习率,它用于控制权重更新的速度。
da_optimizer = optim.Adam(netD_A.parameters(), lr=d_learning_rate):创建了一个名为 da_optimizer 的 Adam 优化器实例,用于训练判别器 netD_A。
db_optimizer = optim.Adam(netD_B.parameters(), lr=d_learning_rate):创建了一个名为 db_optimizer 的 Adam 优化器实例,用于训练判别器 netD_B。
g_optimizer = optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()), lr=d_learning_rate)
da_optimizer = optim.Adam(netD_A.parameters(), lr=d_learning_rate)
db_optimizer = optim.Adam(netD_B.parameters(), lr=d_learning_rate)
10.训练循环的迭代次数
num_epochs = 100: 定义了训练循环的迭代次数。epoch是一个训练周期,在这个周期内,所有数据都会被遍历一次。在这里,训练循环将执行 100 个周期。
num_epochs = 100
11.训练循环
for epoch in range(num_epochs):: 开始一个循环,该循环将执行指定的次数(由 num_epochs定义)。
real_a, real_b = _get_train_data(batch_size): 从数据集中获取一批真实图像real_a 和 real_b。
target_real = torch.full((batch_size,), 1).float():创建一个全为 1 的张量 target_real,用于指示真实图像。
target_fake =torch.full((batch_size,), 0).float(): 创建一个全为 0 的张量target_fake,用于指示假图像。
g_optimizer.zero_grad():清除生成器的梯度,以便于下一次前向传播和反向传播时不会累积梯度。
for epoch in range(num_epochs): real_a, real_b = _get_train_data(batch_size)target_real = torch.full((batch_size,), 1).float()target_fake = torch.full((batch_size,), 0).float()g_optimizer.zero_grad()
12.训练生成器
same_B = netG_A2B(real_b).float(): 使用生成器 netG_A2B 从真实图像 real_b生成相似的图像 same_B。
loss_identity_B = criterion_identity(same_B, real_b) * 5.0: 计算same_B 和 real_b 之间的身份损失,并乘以 5.0 以增加其权重。
same_A = netG_B2A(real_a).float(): 使用生成器 netG_B2A 从真实图像 real_a生成相似的图像 same_A。
loss_identity_A = criterion_identity(same_A, real_a) * 5.0: 计算same_A 和 real_a 之间的身份损失,并乘以 5.0 以增加其权重。
fake_B = netG_A2B(real_a).float(): 使用生成器 netG_A2B 从真实图像 real_a 生成假图像fake_B。
pred_fake = netD_B(fake_B).float(): 使用判别器 netD_B 判断 fake_B 是否为假图像。
loss_GAN_A2B = criterion_GAN(pred_fake, target_real): 计算判别器对 fake_B的预测和真实图像的损失,即 GAN 损失。
fake_A = netG_B2A(real_b).float(): 使用生成器 netG_B2A 从真实图像 real_b 生成假图像fake_A。
pred_fake = netD_A(fake_A).float(): 使用判别器 netD_A 判断 fake_A 是否为假图像。
loss_GAN_B2A = criterion_GAN(pred_fake, target_real): 计算判别器对 fake_A的预测和真实图像的损失,即 GAN 损失。
recovered_A = netG_B2A(fake_B).float(): 使用生成器 netG_B2A 从假图像 fake_B生成恢复的图像 recovered_A。
loss_cycle_ABA = criterion_cycle(recovered_A, real_a) * 10.0: 计算recovered_A 和 real_a 之间的循环一致性损失,并乘以 10.0 以增加其权重。
recovered_B = netG_A2B(fake_A).float(): 使用生成器 netG_A2B 从假图像 fake_A生成恢复的图像 recovered_B。
loss_cycle_BAB = criterion_cycle(recovered_B, real_b) * 10.0: 计算recovered_B 和 real_b 之间的循环一致性损失,并乘以 10.0 以增加其权重。
loss_G = (loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB): 将所有损失加在一起,得到生成器的总损失。
loss_G.backward(): 对总损失进行反向传播,计算每个参数的梯度。
g_optimizer.step():会对生成器的所有参数进行梯度更新,以最小化生成器损失函数。
# 第一步:训练生成器same_B = netG_A2B(real_b).float()loss_identity_B = criterion_identity(same_B, real_b) * 5.0 same_A = netG_B2A(real_a).float()loss_identity_A = criterion_identity(same_A, real_a) * 5.0fake_B = netG_A2B(real_a).float()pred_fake = netD_B(fake_B).float()loss_GAN_A2B = criterion_GAN(pred_fake, target_real)fake_A = netG_B2A(real_b).float()pred_fake = netD_A(fake_A).float()loss_GAN_B2A = criterion_GAN(pred_fake, target_real)recovered_A = netG_B2A(fake_B).float()loss_cycle_ABA = criterion_cycle(recovered_A, real_a) * 10.0recovered_B = netG_A2B(fake_A).float()loss_cycle_BAB = criterion_cycle(recovered_B, real_b) * 10.0 loss_G = (loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB)loss_G.backward() g_optimizer.step()
13.训练判别器
da_optimizer.zero_grad(): 清除判别器 A 的梯度,以便于下一次前向传播和反向传播时不会累积梯度。
pred_real = netD_A(real_a).float(): 使用判别器 A 来判断真实图像 real_a 是否为真实图像。
loss_D_real = criterion_GAN(pred_real, target_real): 计算判别器 A对真实图像的预测和真实图像的损失,即 GAN 损失。
fake_A = fake_A_buffer.push_and_pop(fake_A): 从 fake_A_buffer 中获取一批fake_A 图像,这些图像是从生成器 A 生成的假图像。
pred_fake = netD_A(fake_A.detach()).float(): 使用判别器 A 来判断 fake_A是否为假图像。由于 fake_A 是从 fake_A_buffer 中获取的,它已经与生成器的梯度解耦,因此不需要梯度信息。
loss_D_fake = criterion_GAN(pred_fake, target_fake): 计算判别器 A 对fake_A 的预测和假图像的损失,即 GAN 损失。
loss_D_A = (loss_D_real + loss_D_fake) * 0.5: 将判别器 A的真实图像损失和假图像损失加在一起,得到判别器 A 的总损失。
loss_D_A.backward(): 对判别器 A 的总损失进行反向传播,计算每个参数的梯度。
da_optimizer.step(): 使用之前计算的梯度来更新判别器 A 的参数。
# 第二步:训练判别器# 训练判别器Ada_optimizer.zero_grad()pred_real = netD_A(real_a).float()loss_D_real = criterion_GAN(pred_real, target_real)fake_A = fake_A_buffer.push_and_pop(fake_A)pred_fake = netD_A(fake_A.detach()).float()loss_D_fake = criterion_GAN(pred_fake, target_fake)loss_D_A = (loss_D_real + loss_D_fake) * 0.5loss_D_A.backward()da_optimizer.step()# 训练判别器Bdb_optimizer.zero_grad()pred_real = netD_B(real_b)loss_D_real = criterion_GAN(pred_real, target_real)fake_B = fake_B_buffer.push_and_pop(fake_B)pred_fake = netD_B(fake_B.detach())loss_D_fake = criterion_GAN(pred_fake, target_fake)loss_D_B = (loss_D_real + loss_D_fake) * 0.5loss_D_B.backward()db_optimizer.step()
14.损失打印,存储伪造图片
print('Epoch[{}],loss_G:{:.6f} ,loss_D_A:{:.6f},loss_D_B:{:.6f}' .format(epoch, loss_G.data.item(), loss_D_A.data.item(), loss_D_B.data.item())):打印当前训练周期(epoch)的损失,包括生成器损失(loss_G)和两个判别器损失(loss_D_A 和 loss_D_B)。
if (epoch + 1) % 20 == 0 or epoch == 0:: 检查当前训练周期是否是 20的倍数,或者是否是第一个周期。如果是,则执行以下操作。
b_fake = to_img(fake_B.data): 将判别器 B的输入(fake_B)转换回图像格式。
a_fake = to_img(fake_A.data): 将判别器 A的输入(fake_A)转换回图像格式。
a_real = to_img(real_a.data): 将真实图像 A 转换回图像格式。
b_real = to_img(real_b.data): 将真实图像 B 转换回图像格式。
save_image(a_fake,'../tmp/a_fake.png'): 将 a_fake 图像保存到文件 …/tmp/a_fake.png。
save_image(b_fake, '../tmp/b_fake.png'): 将 b_fake 图像保存到文件…/tmp/b_fake.png。
save_image(a_real, '../tmp/a_real.png'): 将 a_real图像保存到文件 …/tmp/a_real.png。
save_image(b_real, '../tmp/b_real.png'):将 b_real 图像保存到文件 …/tmp/b_real.png。
#损失打印,存储伪造图片print('Epoch[{}],loss_G:{:.6f} ,loss_D_A:{:.6f},loss_D_B:{:.6f}'.format(epoch, loss_G.data.item(), loss_D_A.data.item(), loss_D_B.data.item()))if (epoch + 1) % 20 == 0 or epoch == 0: b_fake = to_img(fake_B.data)a_fake = to_img(fake_A.data)a_real = to_img(real_a.data)b_real = to_img(real_b.data)save_image(a_fake, '../tmp/a_fake.png') save_image(b_fake, '../tmp/b_fake.png') save_image(a_real, '../tmp/a_real.png') save_image(b_real, '../tmp/b_real.png')


全部代码
from random import randint
import numpy as np
import torch
torch.set_default_tensor_type(torch.FloatTensor)
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import os
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision.utils import save_image
import shutil
import cv2
import random
from PIL import Image
import itertools
def to_img(x):out = 0.5 * (x + 1)out = out.clamp(0, 1) out = out.view(-1, 3, 256, 256) return out# 数据加载
data_path = os.path.abspath('D:\probject\pythonProject1\pytorch\CycleGAN\data')
image_size = 256
batch_size = 1transform = transforms.Compose([transforms.Resize(int(image_size * 1.12), Image.BICUBIC), transforms.RandomCrop(image_size), transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))])
def _get_train_data(batch_size=1):train_a_filepath = data_path + '\\trainA\\'train_b_filepath = data_path + '\\trainB\\'train_a_list = os.listdir(train_a_filepath)train_b_list = os.listdir(train_b_filepath)train_a_result = []train_b_result = [] numlist = random.sample(range(0, len(train_a_list)), batch_size)for i in numlist:a_filename = train_a_list[i]a_img = Image.open(train_a_filepath + a_filename).convert('RGB')res_a_img = transform(a_img)train_a_result.append(torch.unsqueeze(res_a_img, 0))b_filename = train_b_list[i]b_img = Image.open(train_b_filepath + b_filename).convert('RGB')res_b_img = transform(b_img)train_b_result.append(torch.unsqueeze(res_b_img, 0))return torch.cat(train_a_result, dim=0), torch.cat(train_b_result, dim=0)# """
# 残差网络block
class ResidualBlock(nn.Module):def __init__(self, in_features):super(ResidualBlock, self).__init__()self.block_layer = nn.Sequential(nn.ReflectionPad2d(1),nn.Conv2d(in_features, in_features, 3),nn.InstanceNorm2d(in_features),nn.ReLU(inplace=True),nn.ReflectionPad2d(1),nn.Conv2d(in_features, in_features, 3),nn.InstanceNorm2d(in_features))def forward(self, x):return x + self.block_layer(x)
# 生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()model = [nn.ReflectionPad2d(3), nn.Conv2d(3, 64, 7), nn.InstanceNorm2d(64), nn.ReLU(inplace=True)]in_features = 64out_features = in_features * 2for _ in range(2):model += [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True)]in_features = out_featuresout_features = in_features*2for _ in range(9):model += [ResidualBlock(in_features)]out_features = in_features // 2for _ in range(2):model += [nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(out_features), nn.ReLU(inplace=True)]in_features = out_featuresout_features = in_features // 2model += [nn.ReflectionPad2d(3), nn.Conv2d(64, 3, 7), nn.Tanh()]self.gen = nn.Sequential( * model)def forward(self, x):x = self.gen(x)return x
# 判别器 class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.dis = nn.Sequential(nn.Conv2d(3, 64, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, 4, 2, 1, bias=False),nn.InstanceNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 256, 4, 2, 1, bias=False),nn.InstanceNorm2d(256),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(256, 512, 4, padding=1),nn.InstanceNorm2d(512),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(512, 1, 4, padding=1)) def forward(self, x):x = self.dis(x)return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)class ReplayBuffer():
# """
# 缓存队列,若不足则新增,否则随机替换
# """def __init__(self, max_size=50):self.max_size = max_sizeself.data = []def push_and_pop(self, data):to_return = []for element in data.data:element = torch.unsqueeze(element, 0)if len(self.data) < self.max_size:self.data.append(element)to_return.append(element)else:if random.uniform(0,1) > 0.5:i = random.randint(0, self.max_size-1)to_return.append(self.data[i].clone())self.data[i] = elementelse:to_return.append(element)return Variable(torch.cat(to_return))fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()netG_A2B = Generator()
netG_B2A = Generator()
netD_A = Discriminator()
netD_B = Discriminator()criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()d_learning_rate = 3e-4 # 3e-4
g_learning_rate = 3e-4
optim_betas = (0.5, 0.999)g_optimizer = optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()), lr=d_learning_rate)
da_optimizer = optim.Adam(netD_A.parameters(), lr=d_learning_rate)
db_optimizer = optim.Adam(netD_B.parameters(), lr=d_learning_rate)num_epochs = 100
for epoch in range(num_epochs): real_a, real_b = _get_train_data(batch_size)target_real = torch.full((batch_size,), 1).float()target_fake = torch.full((batch_size,), 0).float()g_optimizer.zero_grad()# 第一步:训练生成器same_B = netG_A2B(real_b).float()loss_identity_B = criterion_identity(same_B, real_b) * 5.0 same_A = netG_B2A(real_a).float()loss_identity_A = criterion_identity(same_A, real_a) * 5.0fake_B = netG_A2B(real_a).float()pred_fake = netD_B(fake_B).float()loss_GAN_A2B = criterion_GAN(pred_fake, target_real)fake_A = netG_B2A(real_b).float()pred_fake = netD_A(fake_A).float()loss_GAN_B2A = criterion_GAN(pred_fake, target_real)recovered_A = netG_B2A(fake_B).float()loss_cycle_ABA = criterion_cycle(recovered_A, real_a) * 10.0recovered_B = netG_A2B(fake_A).float()loss_cycle_BAB = criterion_cycle(recovered_B, real_b) * 10.0 loss_G = (loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB)loss_G.backward() g_optimizer.step()# 第二步:训练判别器# 训练判别器Ada_optimizer.zero_grad()pred_real = netD_A(real_a).float()loss_D_real = criterion_GAN(pred_real, target_real)fake_A = fake_A_buffer.push_and_pop(fake_A)pred_fake = netD_A(fake_A.detach()).float()loss_D_fake = criterion_GAN(pred_fake, target_fake)loss_D_A = (loss_D_real + loss_D_fake) * 0.5loss_D_A.backward()da_optimizer.step()# 训练判别器Bdb_optimizer.zero_grad()pred_real = netD_B(real_b)loss_D_real = criterion_GAN(pred_real, target_real)fake_B = fake_B_buffer.push_and_pop(fake_B)pred_fake = netD_B(fake_B.detach())loss_D_fake = criterion_GAN(pred_fake, target_fake)loss_D_B = (loss_D_real + loss_D_fake) * 0.5loss_D_B.backward()db_optimizer.step()#损失打印,存储伪造图片print('Epoch[{}],loss_G:{:.6f} ,loss_D_A:{:.6f},loss_D_B:{:.6f}'.format(epoch, loss_G.data.item(), loss_D_A.data.item(), loss_D_B.data.item()))if (epoch + 1) % 20 == 0 or epoch == 0: b_fake = to_img(fake_B.data)a_fake = to_img(fake_A.data)a_real = to_img(real_a.data)b_real = to_img(real_b.data)save_image(a_fake, '../tmp/a_fake.png') save_image(b_fake, '../tmp/b_fake.png') save_image(a_real, '../tmp/a_real.png') save_image(b_real, '../tmp/b_real.png') 相关文章:
迁移学习——CycleGAN
CycleGAN 1.导入需要的包2.数据加载(1)to_img 函数(2)数据加载(3)图像转换 3.随机读取图像进行预处理(1)函数参数(2)数据路径(3)读取文…...

【软件测试】对于测试中的bug,我们真正了解了吗?
目录 1.软件测试的生命周期 1.1.软件测试阶段流程 1.2.各流程的任务 2.什么是bug 2.1.bug的概念 2.2.怎么描述bug 2.3.bug的级别 2.4.bug的生命周期 1.软件测试的生命周期 在学习bug前,我们先来学习一下软件测试的生命周期,也就是测试人员进行测…...

Packer-Fuzzer一款好用的前端高效安全扫描工具
★★免责声明★★ 文章中涉及的程序(方法)可能带有攻击性,仅供安全研究与学习之用,读者将信息做其他用途,由Ta承担全部法律及连带责任,文章作者不承担任何法律及连带责任。 1、Packer Fuzzer介绍 Packer Fuzzer是一款针对Webpack…...

解决卸载TabX explorer软件后导致系统文件资源管理器无法正常使用问题
最近安装了最新版本的鲁大师,安装过程中不小心同时安装了捆绑软件TabX explorer。这个软件和系统自带的文件资源管理器很像,最后弹出会员到期才发现,这个不是系统文件资源管理器,是第三方的文件资源管理器,就按正常流程…...

qt for android 使用打包sqlite数据库文件方法
1.在使用sqlite数据库时,先将数据库文件打包,放置在assets中如下图: 将文件放置下android中的assets下的所有文件都会打包在APK中,可以用7zip查看apk文件 2.在qt代码读取数据文件,注意在assets下的文件都是Read-Only,需…...

MYBATIS大于等于、小于等于的写法
mybatis使用的是xml格式的文件。使用>和<号的时候,会存在与xml的标签的规范冲突。需要写成如下形式,否则会报错。 第一种写法 原符号 替换符号 < < < <> > > >& & &…...

基于堆叠长短期记忆网络 Stacked LSTM 预测A股股票价格走势
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...
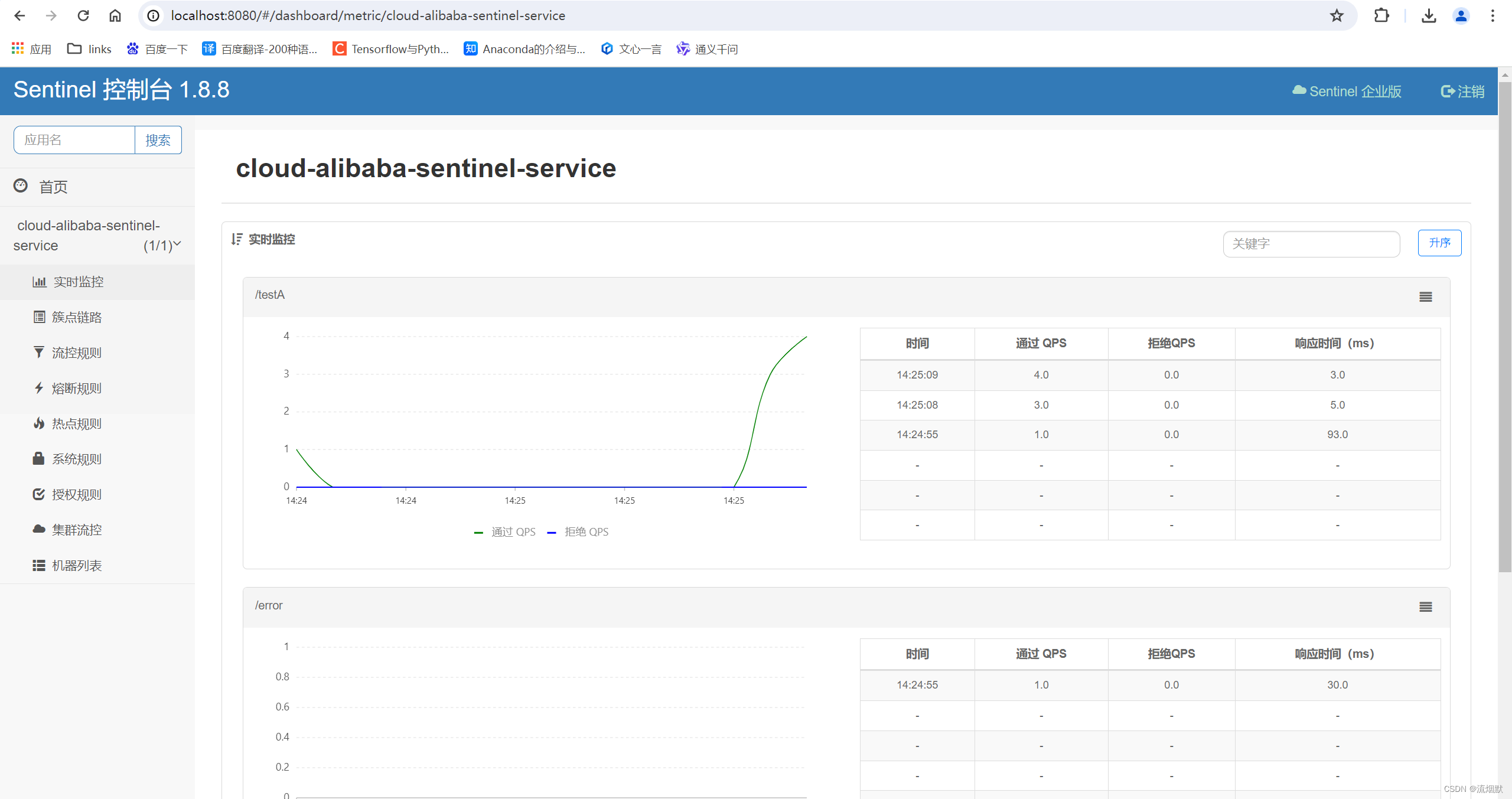
SpringCloud Alibaba Sentinel基础入门与安装
GitHub地址:https://github.com/alibaba/Sentinel 中文文档:https://sentinelguard.io/zh-cn/docs/introduction.html 下载地址:https://github.com/alibaba/Sentinel/releases Spring Cloud Alibaba 官方说明文档:Spring Clou…...
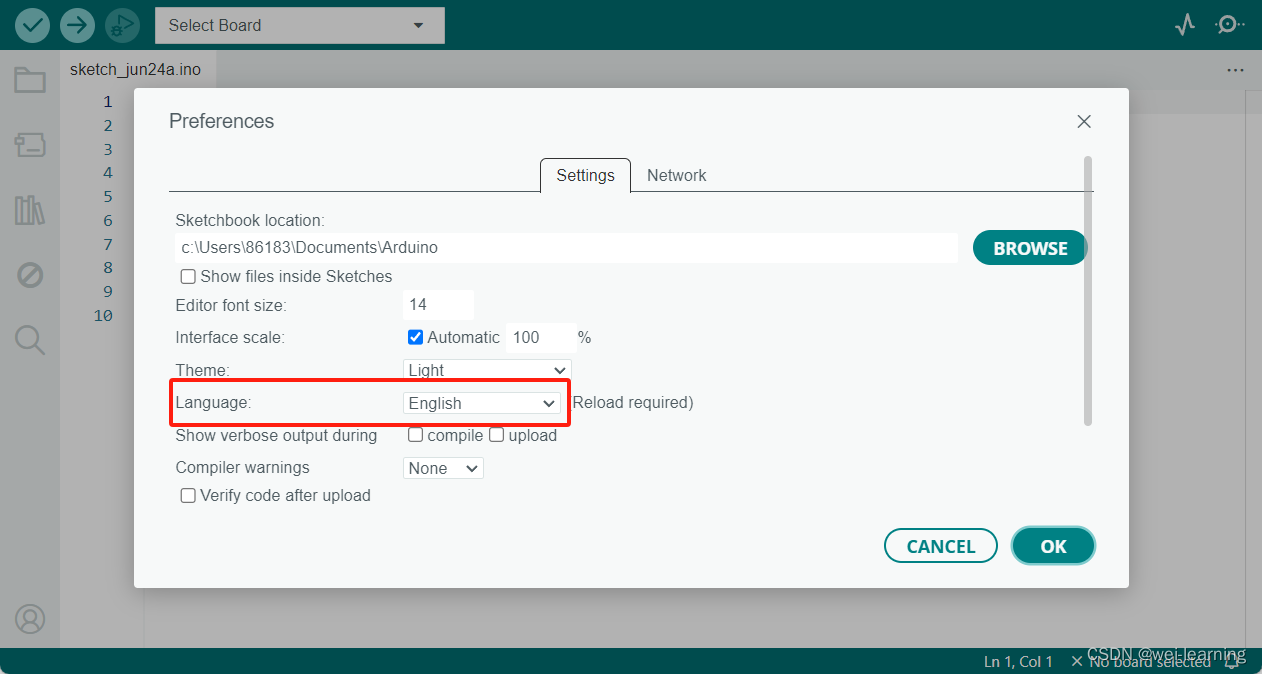
Arduino IDE下载、安装和配置
文章开始先把我自己网盘里的安装包分享给大家,链接:https://pan.baidu.com/s/1cb2_3m0LnuSKLnWP_YoWPw?pwdwwww 提取码:wwww 里面一个是Arduino IDE的安装包,另一个是即将发布的版本。 第一个安装包打开直接按照我的步骤安装就…...
SOBEL图像边缘检测器的设计
本项目使用FPGA设计出SOBEL图像边缘检测器,通过分析项目在使用过程中的工作原理和相关软硬件设计进行分析详细介绍SOBEL图像边缘检测器的设计。 资料获取可联系wechat 号:comprehensivable 边缘可定义为图像中灰度发生急剧变化的区域边界,它是图像最基本…...

Day35:2734. 执行字串操作后的字典序最小字符串
Leetcode 2734. 执行字串操作后的字典序最小字符串 给你一个仅由小写英文字母组成的字符串 s 。在一步操作中,你可以完成以下行为: 选择 s 的任一非空子字符串,可能是整个字符串,接着将字符串中的每一个字符替换为英文字母表中的前…...

【高考志愿】机械工程
目录 一、专业概述 二、学科特点 三、就业前景 四、机械工程学科排名 五、专业选择建议 高考志愿选择机械工程,这是一个需要深思熟虑的决定,因为它不仅关乎未来的学习和职业发展,更是对自我兴趣和潜能的一次重要考量。 一、专业概述 机…...

ffmpeg将mp4转换为swf
文章目录 ffmpeg安装、配置java运行报错 Cannot run program "ffmpeg" ffmpeg命令mp4转为swf示例 ### ffmpeg -i input.mkv -b:v 600 -c:v libx264 -vf scale1920:1080 -crf 10 -ar 48000 -r 24 output.swfmkv转为swf示例 其他文档命令参数简介 需要将mp4转换为swf&a…...

论文学习 --- RL Regret-based Defense in Adversarial Reinforcement Learning
前言 个人拙见,如果我的理解有问题欢迎讨论 (●′ω`●) 原文链接:https://www.ifaamas.org/Proceedings/aamas2024/pdfs/p2633.pdf 研究背景 深度强化学习(Deep Reinforcement Learning, DRL)在复杂和安全关键任务中取得了显著成果,例如自动驾驶。然而,DRL策略容易受…...

【Linux小命令】一文讲清ldd命令及使用场景
一文讲清ldd命令及使用场景 前言下面进入正题:ldd命令 前言 博主今天ubuntu编译go项目出来的一个可执行文件,放centos运行发现居然依赖于XXlib库。然后我一下就想到两个系统库版本不一致,重编。换系统,导项目,配环境……...

自费5K,测评安德迈、小米、希喂三款宠物空气净化器谁才是高性价比之王
最近,家里的猫咪掉毛严重,简直成了一个活生生的蒲公英,家中、空气中各处都弥漫着猫浮毛甚至所有衣物都覆盖着一层厚厚的猫毛。令人难以置信的是,有时我甚至在抠出的眼屎中都能发现夹杂着几根猫毛。真的超级困扰了。但其实最空气中…...

1373. 二叉搜索子树的最大键值和
Problem: 1373. 二叉搜索子树的最大键值和 文章目录 思路解题方法复杂度Code 思路 解决这个问题的关键在于采用深度优先搜索(DFS)策略,并结合树形动态规划的思想。我们需要设计一个递归函数,它不仅能够遍历整棵树,还能…...
基于java + Springboot 的二手物品交易平台实现
目录 📚 前言 📑摘要 📑系统架构 📚 数据库设计 📚 系统功能的具体实现 💬 登录模块 首页模块 二手商品轮播图添加 💬 后台功能模块 二手商品商品列表 添加二手商品商品 添加购物车 &a…...
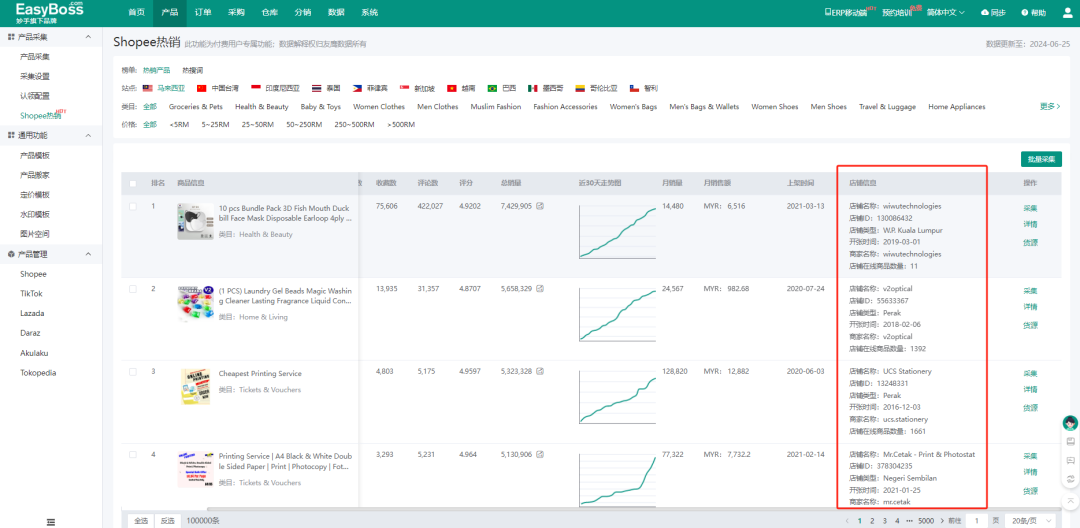
Shopee本土店选品有什么技巧?EasyBoss ERP为你整理了6个高效选品的方法!
电商圈有句话叫:七分靠选品,三分靠运营,选品对了,事半功倍,选品错了,功亏一篑! 很多卖家都会为选品发愁,特别对于Shopee本土店卖家来说,要囤货到海外仓,如果…...
3D在线展览馆的独特魅力,技术如何重塑展览业的未来?
在数字化和虚拟现实技术迅猛发展的今天,3D在线展览馆已经成为一种颇具前景的创新形式。搭建3D在线展览馆不仅能够突破传统展览的时空限制,还能为参观者提供身临其境的体验,极大地提升展示效果和用户互动。 一、3D在线展览馆的意义 1、突破时空…...

3大核心功能,让你的惠普OMEN游戏本性能彻底解放
3大核心功能,让你的惠普OMEN游戏本性能彻底解放 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件过于臃肿而烦恼吗…...

智能家居安全新突破:视觉AI如何实现从感知到认知的跨越
1. 项目概述:当视觉智能成为家庭安全的“火眼金睛”最近几年,智能家居的概念越来越火,从智能门锁到语音助手,似乎家里的一切都在变得“聪明”。但说实话,很多所谓的“智能”安全方案,比如单纯依靠门窗传感器…...

Mem Reduct:让电脑告别卡顿的必备内存清理神器
Mem Reduct:让电脑告别卡顿的必备内存清理神器 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 你的电脑是…...

白起、项羽、黄巢杀降时的第三选择
白起、项羽、黄巢,他们都曾站在“杀降”这个决策悬崖上。与其说这是他们个人的暴虐,不如说他们当时都陷入了一个由战争逻辑、资源短缺和恐惧心理共同构筑的绝境。在那个系统里,他们几乎无法做出别的选择。🎲 那场被逼到墙角的困兽…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

LabVIEW数字IO编程避坑指南:单点采样、连续采样到底怎么选?NI-MAX测试面板帮你验证
LabVIEW数字IO编程实战:采样模式选择与NI-MAX验证全攻略 在工业自动化测试领域,LabVIEW的数字IO模块是最基础也最常用的功能之一。许多工程师在初次接触数字IO编程时,往往会被各种采样模式搞得晕头转向——单点采样、N采样、连续采样…...

从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据
从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据 在半导体器件研究中,TCAD仿真数据的可视化呈现往往决定着研究成果的传达效果。许多研究者花费大量时间完成Silvaco仿真后,却苦于无法将原始数据转化为符合学术出版要求的专业…...

【管理科学】【财务领域】【社会科学】人的需求来源和由需求诞生的企业/业务/行业及其上游产业链/中游产业链/下游产业链的所有内容03
编号 类型 (核心功能) 人的需求类型 (对应场景) 人需求得以满足的信息产品/实体产品/制造加工工具/原材料/其他 由需求诞生的企业/业务/行业及其上游产业链/中工产业链/下游产业链的所有内容及多学科数学建模方程式 /时序数学方程式及货币来源及业务财务模型 流动时序方程…...

Android启动镜像深度解析:MagiskBoot技术实现与架构设计
Android启动镜像深度解析:MagiskBoot技术实现与架构设计 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk项目的核心组件,专为Android启动镜像处理而生&#…...

【云原生问题集】容器内存监控避坑:90%工程师踩过的“free命令雷区”
你有没有遇到过这种怪事?压测跑得好好的,容器突然被 OOM Kill 了。你赶紧进容器敲了个 free -h,一看内存快吃满了,心想“资源不够,加!” 加完内存,跑一会儿又被杀了。坑爹的是,你明明…...