用MySQL和navicatpremium做一个项目—(财务管理系统)。
1 ER图缩小的话怕你们看不清,所以截了两张图


2 vsdx绘图结果

3DDL和DML,都有点长分了好多次上传,慢慢看
DDL
-- 用户表
CREATE TABLE users (user_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户ID',username VARCHAR(50) NOT NULL UNIQUE COMMENT '用户名',password VARCHAR(255) NOT NULL COMMENT '用户密码',email VARCHAR(100) UNIQUE COMMENT '用户邮箱',gender ENUM('男', '女') NOT NULL COMMENT '用户性别',phone VARCHAR(20) UNIQUE COMMENT '用户电话'
)ENGINE=InnoDB;-- 角色表
CREATE TABLE roles (role_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '角色ID',role_name VARCHAR(50) NOT NULL UNIQUE COMMENT '角色名称'
)ENGINE=InnoDB;-- 用户角色关联表
CREATE TABLE user_roles (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户角色关联ID',user_id INT COMMENT '用户ID',role_id INT COMMENT '角色ID',FOREIGN KEY (user_id) REFERENCES users(user_id),FOREIGN KEY (role_id) REFERENCES roles(role_id)
)ENGINE=InnoDB;-- 账户表
CREATE TABLE accounts (account_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '账户ID',account_name VARCHAR(100) NOT NULL COMMENT '账户名称',account_type VARCHAR(50) NOT NULL COMMENT '账户类型',balance DECIMAL(10, 2) NOT NULL DEFAULT 0.00 COMMENT '账户余额',user_id INT COMMENT '用户ID',FOREIGN KEY (user_id) REFERENCES users(user_id)
)ENGINE=InnoDB;-- 分类表
CREATE TABLE categories (category_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '分类ID',category_name VARCHAR(100) NOT NULL UNIQUE COMMENT '分类名称')ENGINE=InnoDB;-- 交易表
CREATE TABLE transactions (transaction_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '交易ID',transaction_date DATE NOT NULL COMMENT '交易日期',description VARCHAR(255) NOT NULL COMMENT '交易描述',amount DECIMAL(10, 2) NOT NULL COMMENT '交易金额',account_id INT COMMENT '账户ID',category_id INT COMMENT '分类ID',FOREIGN KEY (account_id) REFERENCES accounts(account_id),FOREIGN KEY (category_id) REFERENCES categories(category_id)
)ENGINE=InnoDB;-- 预算表
CREATE TABLE budgets (budget_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '预算ID',budget_name VARCHAR(100) NOT NULL COMMENT '预算名称',start_date DATE NOT NULL COMMENT '开始日期',end_date DATE NOT NULL COMMENT '结束日期',amount DECIMAL(10, 2) NOT NULL COMMENT '预算金额',account_id INT COMMENT '账户ID',FOREIGN KEY (account_id) REFERENCES accounts(account_id)
)ENGINE=InnoDB;DML
#1.用户表 (users)
-- 插入用户信息
INSERT INTO users (username, password, email, gender, phone)
VALUES('史密斯', '123', 'alice.smith@example.com', '女', '111-222-3333'),('琼斯', '456', 'bob.jones@example.com', '男', '222-333-4444'),('查理斯', '789', 'charlie.davis@example.com', '男', '333-444-5555'),('威尔逊', '123', 'emma.wilson@example.com', '女', '444-555-6666'),('弗兰克', 'p@ssw0rd', 'frank.thompson@example.com', '男', '555-666-7777');
#2.角色表 (roles)
-- 插入角色信息
INSERT INTO roles (role_name)
VALUES('管理员'),('用户'),('经理'),('访客'),('开发者');
#3.用户角色关联表 (user_roles)
-- 插入用户角色关联
INSERT INTO user_roles (user_id, role_id)
VALUES(1, 1), -- 用户ID为1分配角色ID为1的角色 (管理员)(2, 2), -- 用户ID为2分配角色ID为2的角色 (用户)(3, 3), -- 用户ID为3分配角色ID为3的角色 (经理)(4, 2), -- 用户ID为4分配角色ID为2的角色 (用户)(5, 5); -- 用户ID为5分配角色ID为5的角色 (开发者)
#4.账户表 (accounts)
-- 插入账户信息
INSERT INTO accounts (account_name, account_type, balance, user_id)
VALUES('储蓄账户', '储蓄', 5000.00, 1), -- 用户ID为1的账户('支票账户', '支票', 3000.00, 2), -- 用户ID为2的账户('投资账户', '投资', 10000.00, 3), -- 用户ID为3的账户('信用卡', '信用', -500.00, 4), -- 用户ID为4的账户('加密货币钱包', '加密货币', 2000.00, 5); -- 用户ID为5的账户
#5.分类表 (categories)
-- 插入分类信息
INSERT INTO categories (category_name)
VALUES('食品'),('公用事业'),('娱乐'),('交通'),('购物');
#6.交易表 (transactions)
-- 插入交易信息
INSERT INTO transactions (transaction_date, description, amount, account_id, category_id)
VALUES('2024-06-20', '购物', 100.00, 1, 1), -- 账户ID为1的交易,分类ID为1('2024-06-20', '支付电费', 50.00, 2, 2), -- 账户ID为2的交易,分类ID为2('2024-06-21', '电影票', 25.00, 3, 3), -- 账户ID为3的交易,分类ID为3('2024-06-22', '加油', 30.00, 4, 4), -- 账户ID为4的交易,分类ID为4 ('2024-06-23', '在线购物', 150.00, 5, 5); -- 账户ID为5的交易,分类ID为5
#7.预算表 (budgets)
-- 插入预算信息
INSERT INTO budgets (budget_name, start_date, end_date, amount, account_id)
VALUES('月度食品预算', '2024-06-01', '2024-06-30', 500.00, 1), -- 账户ID为1的预算('公用事业预算', '2024-06-01', '2024-06-30', 200.00, 2), -- 账户ID为2的预算('娱乐预算', '2024-06-01', '2024-06-30', 100.00, 3), -- 账户ID为3的预算('交通预算', '2024-06-01', '2024-06-30', 150.00, 4), -- 账户ID为4的预算('购物预算', '2024-06-01', '2024-06-30', 300.00, 5); -- 账户ID为5的预算理解!让我大致讲解一下你提供的数据库表结构。### 1. 用户表 (`users`)这个表用于存储用户的基本信息,包括用户名、密码、邮箱、性别和电话号码等。- `user_id`: 用户的唯一标识,使用自增整数类型。
- `username`: 用户名,不可为空且唯一。
- `password`: 用户密码,存储为 VARCHAR 类型。
- `email`: 用户邮箱地址,唯一。
- `gender`: 用户性别,使用 ENUM 类型限定为'男'或'女'。
- `phone`: 用户电话号码,唯一。### 2. 角色表 (`roles`)该表用于存储系统中定义的角色信息,例如管理员、用户、经理等。- `role_id`: 角色的唯一标识,使用自增整数类型。
- `role_name`: 角色名称,不可为空且唯一。### 3. 用户角色关联表 (`user_roles`)这个表用于建立用户与角色之间的多对多关系。- `id`: 关联记录的唯一标识,使用自增整数类型- `user_id`: 用户ID,外键关联到 `users` 表的 `user_id` 字段。
- `role_id`: 角色ID,外键关联到 `roles` 表的 `role_id` 字段。### 4. 账户表 (`accounts`)账户表用于记录用户的不同类型账户信息,例如储蓄账户、支票账户等。- `account_id`: 账户的唯一标识,使用自增整数类型。
- `account_name`: 账户名称,不可为空。
- `account_type`: 账户类型,例如储蓄、支票等。
- `balance`: 账户余额,存储为 DECIMAL 类型。
- `user_id`: 用户ID,外键关联到 `users` 表的 `user_id` 字段。### 5. 分类表 (`categories`)这个表用于存储交易或预算所涉及的不同分类,例如食品、公用事业、娱乐等。- `category_id`: 分类的唯一标识,使用自增整数类型。
- `category_name`: 分类名称,不可为空且唯一。### 6. 交易表 (`transactions`)交易表用于记录用户账户的具体交易信息。- `transaction_id`: 交易的唯一标识,使用自增整数类型。
- `transaction_date`: 交易发生的日期,存储为 DATE 类型。
- `description`: 交易描述,例如购物、支付账单等。
- `amount`: 交易金额,存储为 DECIMAL 类型。
- `account_id`: 账户ID,外键关联到 `accounts` 表的 `account_id` 字段。
- `category_id`: 分类ID,外键关联到 `categories` 表的 `category_id` 字段。### 7. 预算表 (`budgets`)预算表用于记录用户设定的各类预算信息。- `budget_id`: 预算的唯一标识,使用自增整数类型。
- `budget_name`: 预算名称,不可为空。
- `start_date`: 预算生效开始日期,存储为 DATE 类型。
- `end_date`: 预算生效结束日期,存储为 DATE 类型。
- `amount`: 预算金额,存储为 DECIMAL 类型。
- `account_id`: 账户ID,外键关联到 `accounts` 表的 `account_id` 字段。这些表结构设计合理,能够支持用户管理、角色管理、账户管理、交易管理、分类管理和预算管理等基本功能。数据库的关系设计也考虑到了表之间的关联和数据完整性,例如外键约束确保了数据的一致性和有效性。当涉及SQL查询时,简单和复杂的定义因人而异,不过我会展示一些有挑战性的示例,涵盖不同类型的查询:### 简单查询:1. 查询用户表中所有用户的用户名和邮箱:SELECT username AS "用户名", email AS "邮箱"
FROM users;2. 查询交易表中所有交易金额大于100的交易信息:SELECT *
FROM transactions
WHERE amount > 100;3. 查询账户表中账户类型为储蓄的账户名称和余额:SELECT account_name AS "账户名称", balance AS "余额"
FROM accounts
WHERE account_type = '储蓄';### 复杂查询:1. 查询每个用户的账户数量和总余额,按总余额降序排序:SELECT u.username AS "用户名", COUNT(a.account_id) AS "账户数量", SUM(a.balance) AS "总余额"
FROM users u
LEFT JOIN accounts a ON u.user_id = a.user_id
GROUP BY u.user_id, u.username
ORDER BY "总余额" DESC;查询每个分类的总交易金额,并按交易金额降序排列。SELECT c.category_name AS "分类名称", SUM(t.amount) AS "总交易金额"
FROM categories c
LEFT JOIN transactions t ON c.category_id = t.category_id
GROUP BY c.category_id, c.category_name
ORDER BY "总交易金额" DESC;查询账户余额大于平均余额的用户及其账户信息SELECT u.username AS "用户名", a.account_name AS "账户名称", a.balance AS "余额"
FROM users u
JOIN accounts a ON u.user_id = a.user_id
JOIN (SELECT AVG(balance) AS avg_balanceFROM accounts
) AS avg_table ON a.balance > avg_table.avg_balance;当从 categories 表中删除分类时,级联删除关联的预算和所有交易记录。DELIMITER //CREATE TRIGGER trg_delete_category_cascade
AFTER DELETE ON categories
FOR EACH ROW
BEGIN-- 删除该分类关联的预算DELETE FROM budgetsWHERE category_id = OLD.category_id;-- 删除该分类关联的交易记录DELETE FROM transactionsWHERE category_id = OLD.category_id;
END;
//DELIMITER ;存储过程(Stored Procedure)是一组预先编译好的 SQL 语句集合,可以接受参数输入并执行复杂的数据库操作。下面我将编写一个简单的存储过程示例,假设我们要查询指定用户的账户信息。```sqlDELIMITER //CREATE PROCEDURE get_user_accounts(IN p_user_id INT)
BEGINSELECT *FROM accountsWHERE user_id = p_user_id;
END;
//DELIMITER ;
```### 解释说明:- **DELIMITER**:因为存储过程通常包含多条 SQL 语句,为了区分每条语句的结束,我们使用 `DELIMITER` 命令将分隔符设置为 `//`。- **CREATE PROCEDURE**:创建存储过程的语法。在 `CREATE PROCEDURE` 后面是存储过程的名称 `get_user_accounts`,`IN p_user_id INT` 指定了一个输入参数 `p_user_id`,类型为整数。- **BEGIN ... END**:存储过程的主体部分,包含了具体的 SQL 查询语句。在这个例子中,我们使用 `SELECT` 查询语句来获取指定用户 (`p_user_id`) 的所有账户信息。- **DELIMITER ;**:将分隔符设置回默认的 `;`。### 调用存储过程:要调用这个存储过程,可以使用 `CALL` 语句,并传入相应的参数。```sql
CALL get_user_accounts(1);
```这将会执行存储过程 `get_user_accounts`,并返回用户ID为 1 的所有账户信息。存储过程可以帮助简化复杂的查询和操作,提高数据库的性能和安全性,特别是在需要经常执行相同操作的情况下。可以根据具体的业务需求和数据库操作来编写和调用存储过程。好的,这里再为你编写一个稍复杂的存储过程示例,假设我们要实现以下功能:1. 查询指定用户的所有交易记录。
2. 计算该用户的总收入和总支出。
3. 返回该用户的总收入、总支出和净收入。```sql
DELIMITER //CREATE PROCEDURE calculate_user_income_expense(IN p_user_id INT
)
BEGINDECLARE total_income DECIMAL(10, 2);DECLARE total_expense DECIMAL(10, 2);DECLARE net_income DECIMAL(10, 2);-- 计算总收入SELECT SUM(amount)INTO total_incomeFROM transactionsWHERE account_id IN (SELECT account_id FROM accounts WHERE user_id = p_user_id)AND amount > 0;-- 计算总支出SELECT SUM(amount)INTO total_expenseFROM transactionsWHERE account_id IN (SELECT account_id FROM accounts WHERE user_id = p_user_id)AND amount < 0;-- 计算净收入SET net_income = total_income - ABS(total_expense);-- 返回结果SELECT total_income AS '总收入', total_expense AS '总支出', net_income AS '净收入';
END;
//DELIMITER ;### 解释说明:- **DELIMITER**:设置分隔符为 `//`,因为存储过程包含多条语句。- **CREATE PROCEDURE**:创建存储过程的语法。`calculate_user_income_expense` 是存储过程的名称,`IN p_user_id INT` 是输入参数,用于指定用户ID。- **DECLARE**:声明三个局部变量 `total_income`、`total_expense` 和 `net_income`,分别用于存储总收入、总支出和净收入的计算结果。- **SELECT ... INTO**:分别查询该用户的总收入和总支出,并将结果存储到对应的变量中。这里使用了子查询来获取该用户所有账户的交易记录。- **SET**:计算净收入,即总收入减去总支出的绝对值。- **SELECT total_income AS '总收入', total_expense AS '总支出', net_income AS '净收入'**:最后一条 `SELECT` 语句返回计算出的总收入、总支出和净收入,作为存储过程的结果。- **DELIMITER ;**:将分隔符设置回默认的 `;`。### 调用存储过程:要调用这个存储过程,可以使用 `CALL` 语句,并传入相应的参数。```sql
CALL calculate_user_income_expense(1);
```这将会执行存储过程 `calculate_user_income_expense`,并计算用户ID为 1 的所有账户的总收入、总支出和净收入,并返回这些信息。这个示例展示了如何利用存储过程计算复杂的业务逻辑,包括多个查询和变量的使用,以及返回多个计算结果。存储过程在处理复杂的数据处理和报告生成时非常有用,可以提高数据库操作的效率和一致性。好的,我将为你编写一个稍复杂一点的存储过程示例,假设我们要实现以下功能:1. 查询指定用户的账户信息。
2. 计算该用户所有账户的总余额。
3. 如果总余额超过一个指定的阈值,则向一个事务表中插入一条记录,记录该用户的信息和总余额。
```sql
DELIMITER //CREATE PROCEDURE process_user_accounts(IN p_user_id INT,IN p_threshold DECIMAL(10, 2)
)
BEGINDECLARE total_balance DECIMAL(10, 2);-- 查询指定用户的账户信息SELECT SUM(balance) INTO total_balanceFROM accountsWHERE user_id = p_user_id;-- 如果总余额超过阈值,则插入记录到事务表中IF total_balance > p_threshold THENINSERT INTO transaction_log (user_id, total_balance, transaction_date)VALUES (p_user_id, total_balance, NOW());END IF;-- 返回总余额信息SELECT total_balance AS '用户总余额';
END;
//DELIMITER ;
```### 解释说明:- **DELIMITER**:设置分隔符为 `//`,因为存储过程包含多条语句。- **CREATE PROCEDURE**:创建存储过程的语法。`process_user_accounts` 是存储过程的名称,`IN p_user_id INT` 和 `IN p_threshold DECIMAL(10, 2)` 是输入参数,分别用于指定用户ID和阈值。- **DECLARE**:声明一个局部变量 `total_balance`,用于存储计算出的总余额。- **SELECT ... INTO**:查询指定用户的账户余额总和,并将结果存储到 `total_balance` 变量中。- **IF ... THEN ... END IF**:条件判断,如果 `total_balance` 超过 `p_threshold`,则执行 `INSERT` 语句将相关信息插入 `transaction_log` 表中。- **INSERT INTO**:将超过阈值的用户信息和总余额插入到 `transaction_log` 表中,包括用户ID、总余额和当前时间戳。- **SELECT total_balance AS '用户总余额'**:最后一条 `SELECT` 语句返回计算出的总余额,作为存储过程的结果。- **DELIMITER ;**:将分隔符设置回默认的 `;`。### 调用存储过程:要调用这个存储过程,可以使用 `CALL` 语句,并传入相应的参数。```sql
CALL process_user_accounts(1, 5000.00);
```这将会执行存储过程 `process_user_accounts`,并计算用户ID为 1 的所有账户的总余额。如果总余额超过 5000.00,则会将相关信息插入到 `transaction_log` 表中,并返回总余额信息。这个示例展示了如何利用存储过程执行复杂的数据库操作,包括条件判断、变量声明和使用、以及数据插入操作。存储过程能够帮助简化和优化复杂的数据库逻辑,在数据库层面实现业务逻辑的复用和统一管理。4 触发器过程
假设你想要在向 `users` 表中插入新记录时,自动初始化一些默认数据,例如向 `accounts` 表中插入新用户的默认账户信息。以下是一个示例触发器,它在插入新用户时自动在 `accounts` 表中创建一个默认账户。```sql
DELIMITER //CREATE TRIGGER trg_insert_user_default_account
AFTER INSERT ON users
FOR EACH ROW
BEGINDECLARE default_account_id INT;-- 插入默认账户信息INSERT INTO accounts (account_name, account_type, balance, user_id)VALUES ('默认账户', '储蓄', 0.00, NEW.user_id);-- 获取新插入账户的自增IDSET default_account_id = LAST_INSERT_ID();-- 可选:更新用户表中的默认账户ID字段UPDATE usersSET default_account_id = default_account_idWHERE user_id = NEW.user_id;
END;
//DELIMITER ;
```### 解释说明:- **触发器类型和时间**:这是一个 `AFTER INSERT` 触发器,意味着当向 `users` 表中插入新记录后,触发器会执行。- **FOR EACH ROW**:表示触发器会为每一行新插入的记录执行一次。- **BEGIN ... END**:包裹触发器内部的逻辑操作。- **DECLARE**:声明一个局部变量 `default_account_id`,用于存储新插入账户的自增ID。- **INSERT INTO accounts**:在 `accounts` 表中插入新的默认账户信息,其中 `NEW.user_id` 是新插入用户的 `user_id`。- **LAST_INSERT_ID()**:获取最后插入行的自增ID,这里用于获取新插入账户的ID。- **UPDATE users**:可选操作,如果 `users` 表中有一个字段需要记录默认账户的ID,可以在这里更新。这个触发器示例演示了如何在插入新用户时,自动向 `accounts` 表中插入一条默认账户记录,并且可以根据具体业务需求进行调整和扩展。请根据你的实际需求和表结构,适配和修改这个触发器。触发器(Triggers)是在表上执行的数据库操作,它们会在特定的数据事件(如插入、更新、删除)发生时自动触发。根据你提供的 MySQL 表结构,我将写几个简单的触发器示例来展示其用法。### 触发器示例:1. 在用户表 (`users`) 上创建一个触发器,当插入新用户时,在角色关联表 (`user_roles`) 中自动插入对应的默认角色(假设默认角色为 ID 为 2 的角色)。```sql
CREATE TRIGGER after_insert_user
AFTER INSERT ON users
FOR EACH ROW
BEGININSERT INTO user_roles (user_id, role_id) VALUES (NEW.user_id, 2);
END;
```这个触发器在每次向 `users` 表中插入新行时触发,将用户ID和默认角色ID(2)插入到 `user_roles` 表中。2. 创建一个触发器,在交易表 (`transactions`) 中更新账户余额 (`accounts` 表中的 `balance` 字段) 后,自动更新对应账户的最后交易日期 (`last_transaction_date` 字段)。```sql
CREATE TRIGGER after_update_transaction_balance
AFTER UPDATE ON transactions
FOR EACH ROW
BEGINUPDATE accountsSET last_transaction_date = NEW.transaction_dateWHERE account_id = NEW.account_id;
END;
```这个触发器在每次更新 `transactions` 表中的交易记录后触发,会自动更新对应账户在 `accounts` 表中的 `last_transaction_date` 字段。3. 创建一个触发器,当删除账户 (`accounts`) 时,自动删除与之相关的预算记录 (`budgets`)。```sql
CREATE TRIGGER after_delete_account
AFTER DELETE ON accounts
FOR EACH ROW
BEGINDELETE FROM budgetsWHERE account_id = OLD.account_id;
END;
```这个触发器在每次从 `accounts` 表中删除账户记录时触发,会自动删除与该账户相关的所有预算记录。这些示例演示了触发器如何在数据库操作过程中自动执行指定的逻辑,以确保数据的完整性和一致性。触发器能够在特定事件发生时进行复杂的逻辑处理,使得数据库操作更加灵活和自动化。目录
1 ER图缩小的话怕你们看不清,所以截了两张图
2 vsdx绘图结果
3DDL和DML,都有点长分了好多次上传,慢慢看
4 触发器过程
5 接下来是PPT展示过程 结果在右侧。
5 接下来是PPT展示过程 结果在右侧。

















相关文章:
用MySQL和navicatpremium做一个项目—(财务管理系统)。
1 ER图缩小的话怕你们看不清,所以截了两张图 2 vsdx绘图结果 3DDL和DML,都有点长分了好多次上传,慢慢看 DDL -- 用户表 CREATE TABLE users (user_id INT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,username VARCHAR(50) NOT NULL UNIQUE COMMENT 用…...

Jenkins教程-5-gitee自动化测试任务构建
上一小节我们学习了Jenkins构建gitlab自动化测试任务的方法,本小节我们讲解一下gitee自动化测试任务的构建方法。 接下来我们以windows系统为例,讲解一下构建实际自动化测试任务的具体步骤。 安装git和gitee插件 点击进入Jenkins插件管理页面 安装完插…...
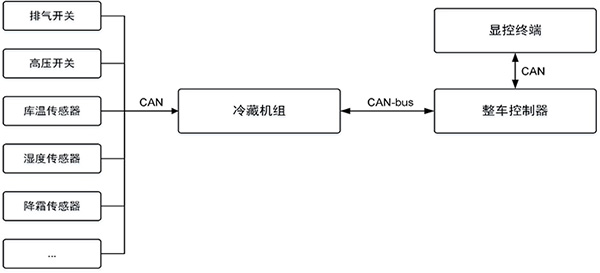
CAN-bus总线在冷链运输中的应用
CAN-bus总线在冷链运输中的应用 如图1所示,疫苗冷链是指为保证疫苗从疫苗生产企业到接种单位运转过程中的质量而装备的存储、运输冷藏设施、设备。由于疫苗对温度敏感,从疫苗制造的部门到疫苗使用的现场之间的每一个环节,都可能因温度过高而失效。在储运过程中,一旦温度超…...

Vue 与 React 区别
Vue.js和React是现代Web开发中两种非常流行的前端框架,两者在**核心概念、组件以及生态系统扩展性**等方面存在区别。具体分析如下: 1. **核心概念** - **Vue**:Vue是一个渐进式JavaScript框架,它致力于视图层,易于上手…...

docker+[nginx] 部署nacos2.x 集群
docker+[nginx] 部署nacos2.x 集群 由于机器有限,本文搭建伪集群 准备: nacos1 :192.168.50.9:8848 nacos2:192.168.50.9:8858 nacos3:192.168.50.9:8868 mysql nginx 【可选,见文末】 创建容器共享网络 便于直接使用容器名连接mysql,如果不创建,连接mysql直接使用i…...

Linux学习第54天:Linux WIFI 驱动:蓝星互联
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 数字化、现代化的今天,随处的WIFI给与了大众极大的方便,也感受到了科技的力量。万物互联、无线互联越来越成为一个不可逆转的趋势。现在比较火…...

芯片后端之 PT 使用 report_timing 产生报告如何阅读
今天,就PT常用的命令,做一个介绍,希望对大家以后的工作,起到帮助作用。 在PrimeTime中,使用report_timing -delay max命令生成此报告。switch -delay max表示定时报告用于设置(这是默认值)。 首先,我们整…...

基于elastic stack搭建的ELK系统资源占用预估
1、ES 1.1 内存:ES非常消耗内存,不是JVM用到的内存,而是机器的物理内存,ES在运行期间对JVM Heap(堆内存)的需求较小 实践建议: 数据量过百万,建议单台服务器的内存至少要有16GB;数据量过亿,建议单台服务器的内存至少要有64GB 1.2 CPU:ES集…...

LiteDB - 一个单数据文件 .NET NoSQL 文档存储
LiteDB 一个小巧、快速、轻量级的 NoSQL 嵌入式数据库。 Serverless NoSQL 文档存储类似于 MongoDB 的简单 API100% C# 代码,支持 .NET 3.5 / .NET 4.0 / NETStandard 1.3 / NETStandard 2.0,单 DLL (小于 300 kb)支持线程和进程安全支持文档/操作级别的 ACID支持写失败后的数…...

视觉理解与图片问答,学习如何使用 GPT-4o (GPT-4 Omni) 来理解图像
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、引言 OpenAI 最新发布的 GPT-4 Omni 模型,也被称为 GPT-4o,是一个多模态 AI 模型,旨在提供更加自然和全面的人机交互体验。 GPT-4o 与 GPT-4 Turbo 都具备视觉功…...
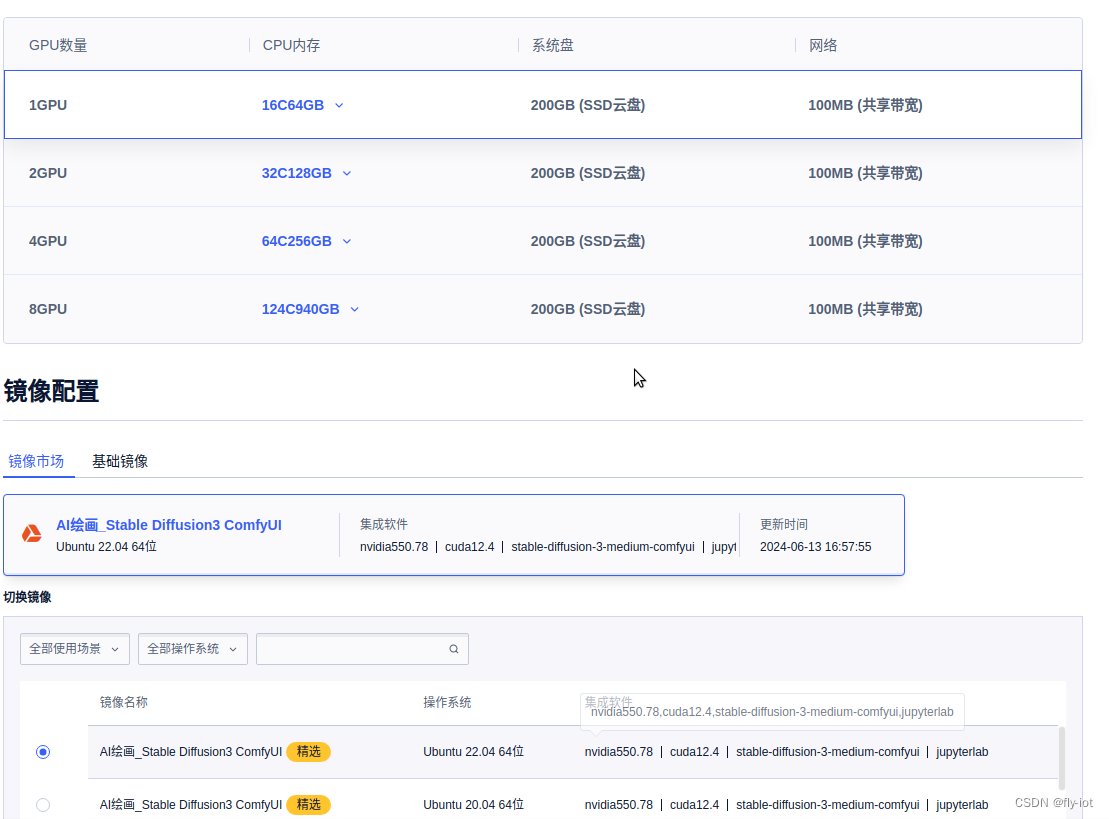
【LocalAI】(13):LocalAI最新版本支持Stable diffusion 3,20亿参数图像更加细腻了,可以继续研究下
最新版本v2.17.1 https://github.com/mudler/LocalAI/releases Stable diffusion 3 You can use Stable diffusion 3 by installing the model in the gallery (stable-diffusion-3-medium) or by placing this YAML file in the model folder: Stable Diffusion 3 Medium 正…...
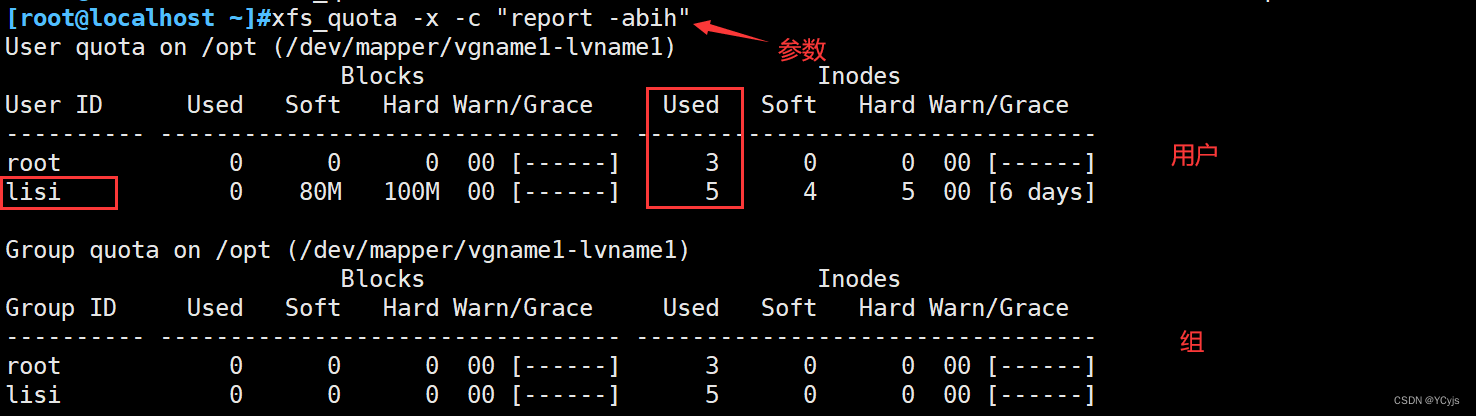
云计算【第一阶段(19)】磁盘管理与文件系统 LVM与磁盘配额(二)
目录 一、LVM概述 1.1、LVM机制的基本概念 编辑 1.2、LVM的管理命令 1.3、lvm存储 两种机制 1.4、lvm应用实例 二、磁盘配额概述 2.1、设置磁盘配额 2.2.1、实现磁盘限额的条件 2.2.2、linux磁盘限额的特点 2.2.3、磁盘配额管理 一、LVM概述 1.1、LVM机制的基本概…...

基于C++实现的EventLoop与事件驱动编程
一,概念介绍 事件驱动编程(Event-Driven)是一种编码范式,常被应用在图形用户界面,应用程序,服务器开发等场景。 采用事件驱动编程的代码中,通常要有事件循环,侦听事件,…...

Android高级面试_8_热修补插件化等
Android 高级面试:插件化和热修复相关 1、dex 和 class 文件结构 class 是 JVM 可以执行的文件类型,由 javac 编译生成;dex 是 DVM 执行的文件类型,由 dx 编译生成。 class 文件结构的特点: 是一种 8 位二进制字节…...

显卡GTX与RTX有什么区别?哪一个更适合玩游戏?
游戏发烧友们可能对游戏显卡并不陌生,它直接关系到游戏画面的流畅度、细腻程度和真实感。在众多显卡品牌中,英伟达的GTX和RTX系列显卡因其出色的性能而备受关注。 一、GTX与RTX的区别 架构差异 GTX系列显卡采用的是Pascal架构,这是英伟达在…...

QT自定义信号和槽函数
在QT中最重要也是必须要掌握的机制,就是信号与槽机制,在MFC上也就是类型的机制就是消息与响应函数机制 在QT中我们不仅要学会如何使用信号与槽机制,还要会自定义信号与槽函数,要自定义的原因是系统提供的信号,在一些情…...
Atcoder Beginner Contest 359
传送门 A - Count Takahashi 时间限制:2秒 内存限制:1024MB 分数:100分 问题描述 给定 N 个字符串。 第 i 个字符串 () 要么是 Takahashi 要么是 Aoki。 有多少个 i 使得 等于 Takahashi ? 限制 N 是整数。每个…...
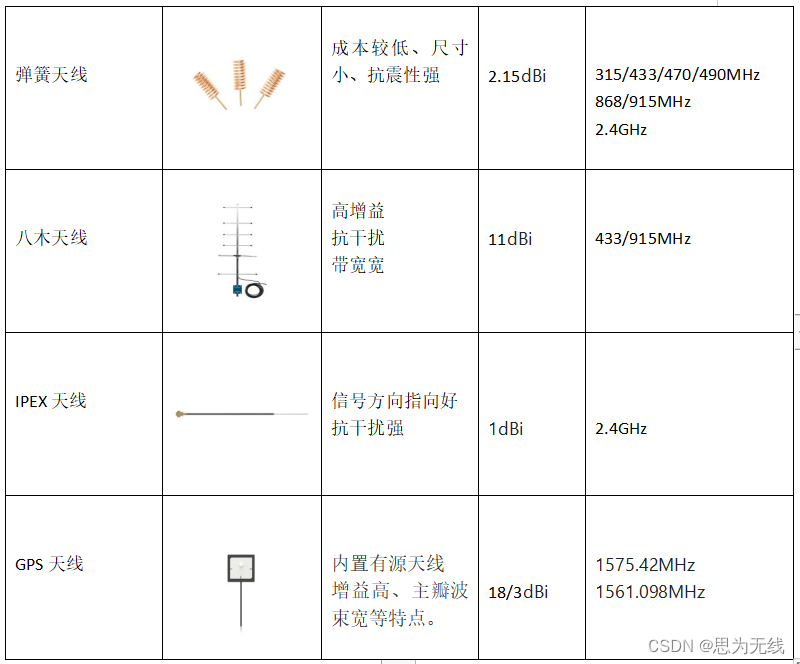
无线通讯几种常规天线类别简介
天线对于无线模块来说至关重要,合适的天线可以优化通信网络,增加其通信的范围和可靠性。天线的选型对最后的模块通信影响很大,不合适的天线会导致通信质量下降。针对不同的市场应用,天线的材质、安置方式、性能也大不一样。下面简…...
最大团问题--回溯法
一、相关定义 给定一个无向图 ,其中 V 是图的顶点集,E图的边集 完全图:如果无向图中的任何一对顶点之间都有边,这种无向图称为完全图 完全子图:给定无向图 ,如果 ,且对应任意 且 ,则…...

MBSE之简单介绍
MBSE之简单介绍 文章目录 MBSE之简单介绍1. What is MBSE?2. MBSE 最佳实践 1. What is MBSE? Model-Based Systems Engineering (MBSE), a.k.a. Model-Based Systems Development (MBSD), is a Systems Engineering process paradigm that emphasizes t…...

别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块
别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块 当PLC工程师第一次接触结构化文本(ST)时,往往会被它类似高级编程语言的语法吓退。但事实上,ST在处理复杂算法时的简洁性和高效性&#…...

轻量级容器化部署工具Ship:简化中小团队应用部署流程
1. 项目概述:一个面向开发者的轻量级容器化部署工具最近在和朋友聊起中小团队或个人开发者的部署痛点时,大家普遍觉得,虽然Kubernetes(K8s)生态强大,但对于一个快速迭代的独立项目或小团队来说,…...

微服务架构:使用Docker+Kubernetes部署应用
微服务架构:使用DockerKubernetes部署应用 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊微服务架构以及如何使用Docker和Kubernetes进行部署。作为一个全栈开发者,我经历过单体应用到微服务的转型,深刻体…...

5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行
5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

技术决策的后悔药:选型错误后的补救策略
在软件测试的全生命周期中,技术选型是影响测试效率、质量与项目成败的关键环节。小到一款测试工具的挑选,大到整个测试框架的搭建,每一次决策都如同在迷雾中航行,稍有不慎便可能驶入“选型错误”的漩涡。当测试环境兼容性问题频发…...

Cadence 17.4 保姆级教程:从DRC检查到Gerber输出的完整避坑指南
Cadence 17.4 终极避坑指南:从DRC检查到Gerber输出的全流程实战 第一次使用Cadence Allegro 17.4导出Gerber文件时,那种如履薄冰的感觉至今记忆犹新。记得去年为TMC2300电机驱动模块导出生产文件时,因为一个简单的单位设置错误,导…...

应急通信无人机中继部署与覆盖率优化【附仿真】
✨ 长期致力于应急通信、无人机、中继部署、通信覆盖率、无人机部署数目研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)视距概率信道建模与高度部署&a…...
服务)
告别LSMW!SAP S/4HANA数据迁移新宠:手把手激活Migration Cockpit (LTMC/LTMOM)服务
SAP S/4HANA数据迁移革命:Migration Cockpit全流程实战指南 在SAP生态系统中,数据迁移一直是项目实施过程中最关键的环节之一。传统LSMW工具虽然功能强大,但随着S/4HANA的推出,其局限性日益凸显。本文将带您深入探索SAP官方推荐的…...

从理论到落地,一文读懂现代AI Agent的完整记忆流水线
来源:DeepHub IMBA 本文约6500字,建议阅读13分钟本文介绍 AI Agent 四大记忆分类与流水线,解析生产架构、选型方案及常见落地误区。每一次 LLM 调用都是无状态的。模型读上下文窗口,生成响应然后忘掉一切。这对单轮问答没问题。对…...

2026最权威的十大AI辅助论文工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要降低AIGC也就是人工智能生成内容的检测率,关键之处在于减少机器生成的痕迹,还要增加文本的…...