2024-06-27 问AI: 介绍一下 LLM building process
文心一言
LLM(Large Language Model,大语言模型)的构建过程是一个复杂且资源密集的任务,涉及多个关键步骤。以下是LLM构建过程的主要阶段,以及每个阶段的一些关键考虑因素:
- 数据收集与预处理:
- 数据收集:首先,需要收集大量的文本数据作为模型训练的输入。这些数据可能来自互联网上的公开文本、书籍、新闻报道、社交媒体内容等。
- 数据清洗:收集到的原始数据往往包含噪声、错误和不需要的信息,需要进行清洗和预处理,以提高数据质量。
- 分词与标记:将文本数据分割成词或子词单元,并可能添加一些特殊的标记,如句子边界、实体标记等。
- 模型设计:
- 模型架构选择:选择适当的神经网络架构,如Transformer模型(如GPT、BERT等),这些模型在处理自然语言任务时表现出色。
- 参数设置:确定模型的参数,如嵌入层的大小、隐藏层的大小和数量、注意力机制的类型等。
- 模型训练:
- 训练环境搭建:准备高性能的计算资源,如GPU集群,以支持模型的高效训练。
- 训练过程:使用收集到的文本数据训练模型,通过反向传播算法调整模型的参数,以最小化预测输出与真实输出之间的差异。
- 训练优化:采用各种优化技术,如学习率调整、梯度裁剪、分布式训练等,以提高训练效率和模型性能。
- 评估与调优:
- 评估指标:使用各种评估指标(如准确率、F1分数、困惑度等)来衡量模型在特定任务上的性能。
- 模型调优:根据评估结果调整模型参数、训练策略或引入新的技术来提高模型性能。
- 部署与应用:
- 模型压缩与优化:为了在实际应用中提高模型的响应速度和降低资源消耗,可能需要对模型进行压缩和优化。
- 集成与部署:将训练好的模型集成到特定的应用程序或系统中,并通过API或SDK等方式提供服务。
- 持续维护与更新:
- 监控与评估:定期监控模型的性能,并根据需要进行调整和优化。
- 数据更新与再训练:随着新数据的不断产生,可能需要对模型进行再训练以保持其性能。
在LLM的构建过程中,还需要注意以下一些关键挑战和考虑因素:
- 计算资源:LLM的训练需要大量的计算资源,包括高性能的GPU集群和大量的存储空间。
- 数据隐私与版权:在收集和使用数据时,需要遵守相关的隐私政策和版权法规。
- 模型性能与效率:需要在保持模型性能的同时,尽量降低模型的复杂性和资源消耗,以提高其在实际应用中的效率和响应速度。
- 持续更新与维护:由于语言和技术的不断发展,LLM需要持续进行更新和维护以保持其性能。
智谱清言
LLM(Large Language Model)即大型语言模型,是人工智能领域中的一个重要研究方向。它的构建过程大致可以分为以下几个步骤:
-
数据收集与预处理:
- 数据收集:从各种来源收集大量的文本数据,如书籍、文章、网页等。
- 预处理:清洗数据,去除噪声,进行分词(Tokenization),编码等操作,为后续训练做好准备。
-
模型设计:
- 设计适合的模型架构,如Transformer架构,它包括多个自注意力层和前馈网络,以及用于训练的优化器和损失函数。
-
模型训练:
- 使用大量数据对模型进行训练。训练过程通常涉及前向传播、计算损失、反向传播和参数更新等步骤。
- 训练过程中可能还会使用一些技巧,比如动态学习率调整、正则化技术等,来提高模型的性能和泛化能力。
-
模型评估:
- 在测试集或验证集上评估模型的性能,使用诸如BLEU、ROUGE、METEOR等自动评估指标来衡量模型的质量。
- 进行人工评估,检查模型是否能够理解语言的复杂性并产生符合逻辑和事实的回答。
-
模型优化与调整:
- 根据评估结果对模型进行微调,调整模型参数以改善其性能。
- 进行模型剪枝、量化等操作,以减小模型大小,提高推理效率。
-
部署与应用:
- 将训练好的模型部署到服务器上,为用户提供服务。
- 开发用户界面,确保用户能够方便地与模型交互。
在整个构建过程中,还需要考虑到模型的伦理和安全性问题,确保模型的应用不会产生歧视、虚假信息传播等不良后果。
随着技术的不断进步,LLM的构建过程也在不断地演进,研究者们持续探索更高效的训练方法、更优的模型架构以及更智能的训练策略。
豆包
LLM(Large Language Model,大型语言模型)的构建过程通常包括以下几个关键步骤:
1. 数据收集:
- 广泛收集大量的文本数据,这些数据来源多样,如互联网、书籍、新闻文章、学术论文等。
- 例如,从知名的网站抓取大量的网页内容,或者获取大规模的数字化图书库。
2. 数据清洗和预处理:
- 对收集到的数据进行清洗,去除噪声、错误和不相关的信息。
- 进行分词、标记化等预处理操作,将文本转换为模型可理解的形式。
3. 模型架构选择:
- 选择适合的深度学习架构,如 Transformer 架构,它在处理自然语言任务方面表现出色。
4. 训练模型:
- 使用预处理后的数据对模型进行训练。
- 通过优化算法不断调整模型的参数,以提高模型对语言的理解和生成能力。
5. 超参数调整:
- 例如学习率、层数、神经元数量等超参数的优化,以获得更好的模型性能。
6. 评估和验证:
- 使用各种评估指标,如准确率、召回率、F1 值等,来评估模型的性能。
- 通过在验证集上进行测试,确定模型是否过拟合或欠拟合。
7. 优化和改进:
- 根据评估结果,对模型进行进一步的优化和改进,如增加数据量、调整模型结构等。
8. 部署和应用:
- 将训练好的模型部署到实际应用中,为用户提供语言相关的服务和支持。
总之,LLM 的构建是一个复杂且需要大量计算资源和时间的过程,需要不断地优化和改进,以提高模型的性能和准确性。
讯飞星火
LLM building process,即大型语言模型构建过程,是一种自然语言处理技术,用于创建能够理解和生成人类语言的计算机程序。这个过程涉及以下几个关键步骤:
-
数据收集:首先,需要收集大量的文本数据,这些数据可以是来自互联网的各种类型的文本,如书籍、文章、论坛帖子等。这些数据将用于训练模型,使其学会理解和生成自然语言。
-
数据预处理:在训练模型之前,需要对收集到的数据进行预处理,包括去除特殊字符、标点符号、数字等,以及将文本分词(tokenization)。这有助于模型更好地理解文本中的单词和短语。
-
模型架构选择:选择合适的神经网络架构,如循环神经网络(RNN)、长短时记忆网络(LSTM)或Transformer等。这些架构决定了模型如何处理输入数据并生成预测。
-
模型训练:使用预处理后的数据集训练选定的神经网络模型。训练过程中,模型会调整其内部参数,以便更好地拟合训练数据。这个过程通常需要大量的计算资源和时间。
-
模型评估:在训练完成后,需要对模型进行评估,以确定其在各种任务(如文本分类、命名实体识别、情感分析等)上的性能。这可以通过在验证集或测试集上运行模型来实现。
-
模型优化:根据评估结果,可以对模型进行进一步优化,例如调整超参数、增加训练数据或改进模型架构。这有助于提高模型在特定任务上的性能。
-
模型部署:将训练好的模型部署到实际应用中,如聊天机器人、语音识别系统或其他自然语言处理应用。这可能需要将模型转换为特定平台或设备的格式,并进行进一步的优化以提高性能和降低延迟。
总之,LLM building process是一个复杂的过程,涉及多个步骤和技能。通过这个过程,研究人员和工程师可以创建出能够理解和生成自然语言的强大模型,从而推动自然语言处理领域的发展。
通义
LLM building process" 在不同的上下文中有不同的含义。根据您给出的信息,存在两种可能的解释:
-
建筑领域的建设过程(Building Process): 在建筑领域,"building process" 指的是从项目规划、设计、施工到竣工验收的整个建造流程。这包括但不限于准备施工文档、投标、选择承包商、地基处理、主体结构施工、安装工程、装修装饰、系统调试以及最终的项目交付。例如,在锅炉受热部件的制造中,建设过程可能涉及材料采购、部件制造、组装、检验等多个阶段。
-
LLM(Large Language Model,大型语言模型)构建过程: 在AI和自然语言处理领域,LLM指的是大型语言模型,它们是经过大规模文本数据训练得到的深度学习模型,能够完成语言生成、理解、对话等多种任务。构建LLM的过程通常涉及以下几个关键步骤:
- 数据收集与预处理:收集大量文本数据,包括互联网文本、书籍、新闻等,进行清洗、去噪,有时还需对数据进行标注以供特定任务使用。
- 模型架构设计:选择或设计神经网络架构,如Transformer等,这些架构能高效处理序列数据。
- 训练:在高性能计算集群上使用深度学习框架进行模型训练,这个过程需要大量计算资源和时间,同时要监控训练过程,调整学习率等超参数。
- 评估与微调:在验证集上评估模型性能,可能需要对模型进行微调,使其在特定任务上表现更佳。
- 部署与应用开发:将训练好的模型部署到生产环境,开发应用程序接口(API)或集成到具体产品中,如聊天机器人、AI助手、代码生成器等。
- 持续维护与优化:根据用户反馈和实际应用情况,不断优化模型性能,解决新出现的问题。
综上所述,LLM构建过程是一个高度技术化且复杂的流程,结合了机器学习、数据科学、软件工程等多个领域的知识。
相关文章:

2024-06-27 问AI: 介绍一下 LLM building process
文心一言 LLM(Large Language Model,大语言模型)的构建过程是一个复杂且资源密集的任务,涉及多个关键步骤。以下是LLM构建过程的主要阶段,以及每个阶段的一些关键考虑因素: 数据收集与预处理:…...

猫也有自动厕所上了吗?自费分享好用的智能猫砂盆,看完不亏。
还有人在用普通猫砂盘吗?之前我也是用的普通猫砂盘,但我发现只要我在上班时间,我就无法顾忌到小猫的便便,但又不想回家就闻到一股臭味,更何况现在夏天也快到了,便便残留一会就会发酵发臭,导致生…...
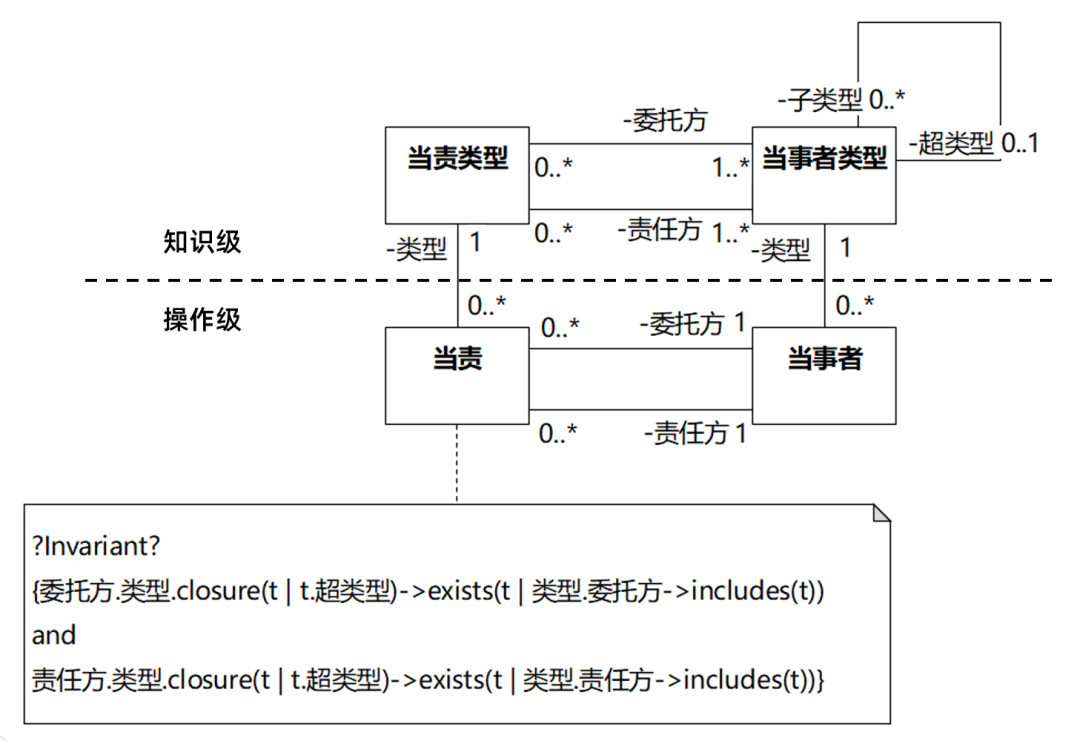
《分析模式》漫谈07-怎样把一张图从不严谨改到严谨
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 下图是《分析模式》原书第2章的图2.10,里面有一些错误和考虑不周的地方: 2004中译本和2020中译本的翻译如下: 基本上都是照搬,没有改过…...

纯干货丨知乎广告投放流程和避坑攻略
精准有效的广告投放企业获客的关键,知乎作为中国最大的知识分享平台,拥有着高质量的用户群体和高度的用户粘性,为广告主提供了独一无二的品牌传播与产品推广平台。然而,如何在知乎上高效、精准地进行广告投放,避免不必…...
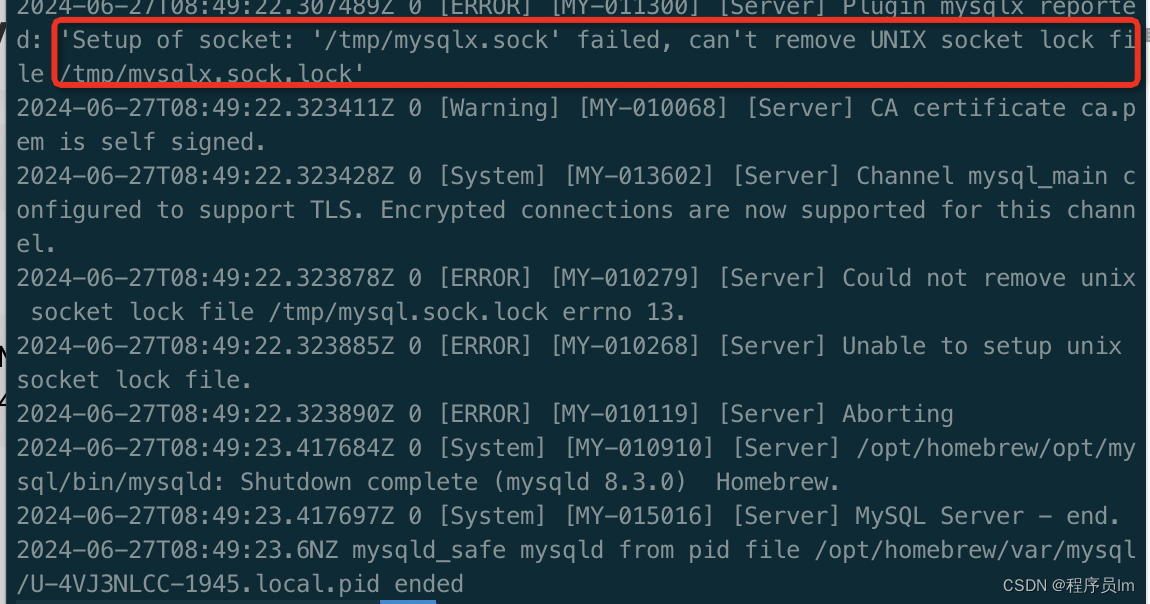
mac 安装mysql启动报错 ERROR!The server quit without update PID file
发现问题: mac安装mysql初次启动报错: 一般出现这种问题,大多是文件夹权限,或者以前安装mysql卸载不干净导致。首先需要先确定问题出在哪?根据提示我们可以打开mysql的启动目录,查看启动日志。 问题解决&a…...

TypeScrip环境安装与基础
TS环境安装与基础 文章目录 一、什么是TypeScript(微软开发的)二、TypeScript的特性三、环境安装node安装配置详解(常用:outDir,strict ) 四、注释方式五、数据类型 一、什么是TypeScript(微软开…...

6.27学习总结
一、高数 1、斯托克斯公式(曲线<->曲面):看清顺时针(负)/逆时针(正) 2、曲面方程变二重积分: 前、上、右:正; 后、下、左:负; 3…...

选择第三方软件测试机构做验收测试的好处简析
企事业单位在自行开发完软件系统或委托软件开发公司生产软件之后,有一个必经流程就是验收测试,以验证该产品是否符合用户需求、是否可以上线。为了客观评估所委托生产的软件质量,第三方软件测试机构往往成为企事业单位做验收测试的首选&#…...

【图书推荐】CPython设计与实现“适合所有Python工程师阅读的书籍”
目录 一、图书推荐 |【CPython设计与实现】 1.1、书籍介绍 1.2、内容简介 1.3、适合哪些人阅读 1.4、作者译者简介 1.5、购买链接 一、图书推荐 |【CPython设计与实现】 "深入Python核心,揭秘CPython的设计智慧!📖 对于每一位热衷…...
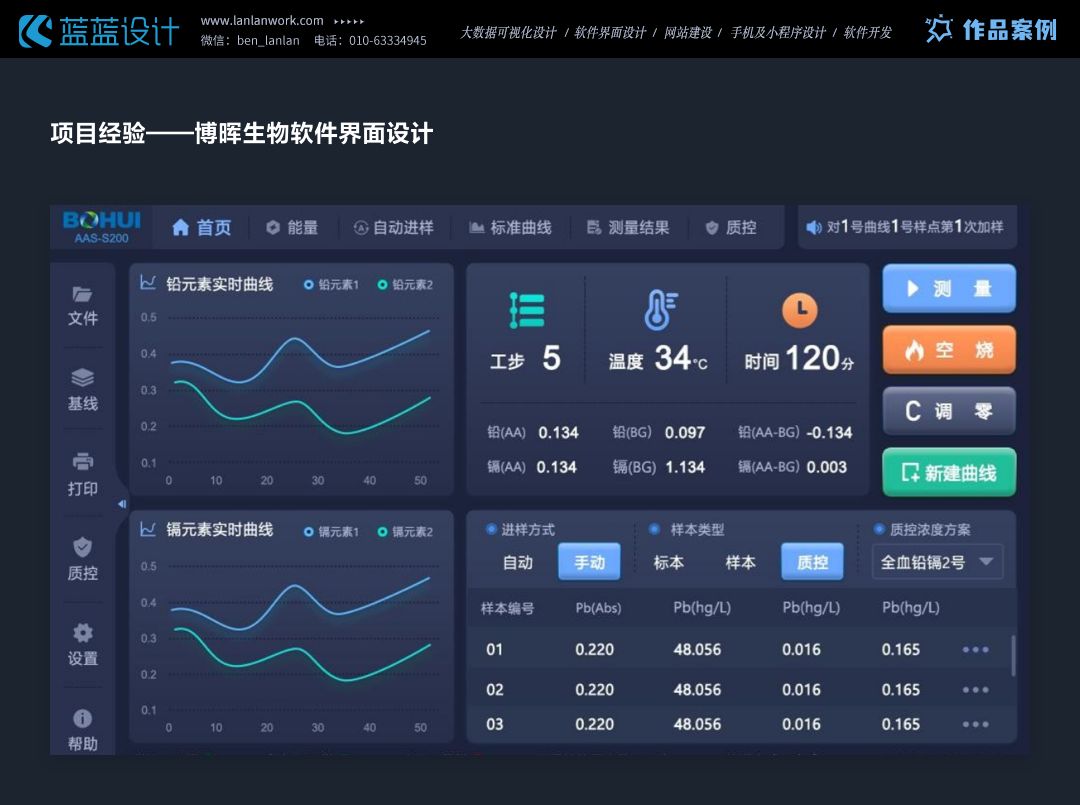
原创作品—医疗行业软件界面UI、交互设计
在医疗行业大屏UI设计中,首要的是以用户为中心,深入理解医生、护士、管理层等用户群体的具体需求和工作流程。大屏设计应直观展示关键医疗数据、患者信息、设备状态等,确保用户能够迅速、准确地获取所需信息。同时,功能布局应合理…...

[C++深入] --- vector容器浅析
vector是一个封装了动态大小数组的顺序容器,它能够存放各种类型的对象。 可以删除元素、可以插入元素、可以查找元素,做这些工作我们无需管理容器内存。容器内存管理,这种脏活累活全部交由vector管理。了解一下vector的内存管理策略,能够更加充分的利用内存。 1 vector内存…...

用MySQL和navicatpremium做一个项目—(财务管理系统)。
1 ER图缩小的话怕你们看不清,所以截了两张图 2 vsdx绘图结果 3DDL和DML,都有点长分了好多次上传,慢慢看 DDL -- 用户表 CREATE TABLE users (user_id INT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,username VARCHAR(50) NOT NULL UNIQUE COMMENT 用…...

Jenkins教程-5-gitee自动化测试任务构建
上一小节我们学习了Jenkins构建gitlab自动化测试任务的方法,本小节我们讲解一下gitee自动化测试任务的构建方法。 接下来我们以windows系统为例,讲解一下构建实际自动化测试任务的具体步骤。 安装git和gitee插件 点击进入Jenkins插件管理页面 安装完插…...
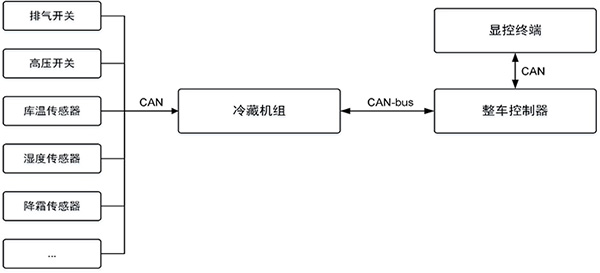
CAN-bus总线在冷链运输中的应用
CAN-bus总线在冷链运输中的应用 如图1所示,疫苗冷链是指为保证疫苗从疫苗生产企业到接种单位运转过程中的质量而装备的存储、运输冷藏设施、设备。由于疫苗对温度敏感,从疫苗制造的部门到疫苗使用的现场之间的每一个环节,都可能因温度过高而失效。在储运过程中,一旦温度超…...

Vue 与 React 区别
Vue.js和React是现代Web开发中两种非常流行的前端框架,两者在**核心概念、组件以及生态系统扩展性**等方面存在区别。具体分析如下: 1. **核心概念** - **Vue**:Vue是一个渐进式JavaScript框架,它致力于视图层,易于上手…...

docker+[nginx] 部署nacos2.x 集群
docker+[nginx] 部署nacos2.x 集群 由于机器有限,本文搭建伪集群 准备: nacos1 :192.168.50.9:8848 nacos2:192.168.50.9:8858 nacos3:192.168.50.9:8868 mysql nginx 【可选,见文末】 创建容器共享网络 便于直接使用容器名连接mysql,如果不创建,连接mysql直接使用i…...

Linux学习第54天:Linux WIFI 驱动:蓝星互联
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 数字化、现代化的今天,随处的WIFI给与了大众极大的方便,也感受到了科技的力量。万物互联、无线互联越来越成为一个不可逆转的趋势。现在比较火…...

芯片后端之 PT 使用 report_timing 产生报告如何阅读
今天,就PT常用的命令,做一个介绍,希望对大家以后的工作,起到帮助作用。 在PrimeTime中,使用report_timing -delay max命令生成此报告。switch -delay max表示定时报告用于设置(这是默认值)。 首先,我们整…...

基于elastic stack搭建的ELK系统资源占用预估
1、ES 1.1 内存:ES非常消耗内存,不是JVM用到的内存,而是机器的物理内存,ES在运行期间对JVM Heap(堆内存)的需求较小 实践建议: 数据量过百万,建议单台服务器的内存至少要有16GB;数据量过亿,建议单台服务器的内存至少要有64GB 1.2 CPU:ES集…...

LiteDB - 一个单数据文件 .NET NoSQL 文档存储
LiteDB 一个小巧、快速、轻量级的 NoSQL 嵌入式数据库。 Serverless NoSQL 文档存储类似于 MongoDB 的简单 API100% C# 代码,支持 .NET 3.5 / .NET 4.0 / NETStandard 1.3 / NETStandard 2.0,单 DLL (小于 300 kb)支持线程和进程安全支持文档/操作级别的 ACID支持写失败后的数…...

PS4游戏存档管理终极指南:如何使用Apollo工具轻松备份和修改游戏进度
PS4游戏存档管理终极指南:如何使用Apollo工具轻松备份和修改游戏进度 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 在PlayStation 4游戏体验中,游戏存档管理一直是个让玩家头疼的…...

Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章
Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 Flutter for OpenHarmony 学习资料搜索与 PDF 阅读器开发实战 大家好!今天带大家从零开始打造一款专…...

Windows系统mfc140.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

MarkFlowy:基于智能感知的Markdown写作流工具设计与实现
1. 项目概述:一个为Markdown而生的高效写作流工具 如果你和我一样,每天的工作都离不开Markdown——写技术文档、整理项目笔记、构思博客文章,那你一定体会过那种在“专注写作”和“格式调整”之间反复横跳的痛苦。刚进入心流状态,…...

别再手动调阈值了!OpenCV实战:用Otsu和自适应阈值搞定光照不均的图片分割
智能图像分割实战:Otsu与自适应阈值技术解决光照不均难题 在工业质检、医疗影像分析、自动驾驶等场景中,图像分割的准确性直接影响最终结果。但现实世界的光照条件往往复杂多变——同一张图片可能同时存在过曝和欠曝区域,传统全局阈值方法在…...

如何让经典DirectX游戏在现代Windows上完美运行:DDrawCompat终极兼容解决方案
如何让经典DirectX游戏在现代Windows上完美运行:DDrawCompat终极兼容解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.co…...

CSP-J/S 2020 真题精讲:从“优秀的拆分”看二进制位运算的实战应用
1. 从“优秀的拆分”理解二进制位运算的妙用 第一次看到这道题时,我完全被"优秀的拆分"这个说法吸引了。题目要求我们把一个正整数拆分成不同的2的正整数次幂之和,听起来有点抽象对吧?让我用一个生活中的例子来解释:假设…...

AUTOSAR Wdg模块的两种“狗”:片内看门狗与SPI外挂看门狗配置异同点解析
AUTOSAR Wdg模块深度解析:片内与SPI外挂看门狗的工程实践指南 在汽车电子控制单元(ECU)开发中,看门狗(Watchdog)模块是确保系统可靠性的关键组件。AUTOSAR标准下的Wdg模块支持两种典型硬件架构——片内集成…...
)
Midjourney V6 acrylic paint提示词工程:从模糊描述到精准输出的12个专业级Prompt模板(含色彩层厚/笔触硬度/画布纹理三重控制)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6丙烯画风格的核心演进与底层渲染机制 Midjourney V6 对丙烯画(Acrylic Painting)风格的建模已脱离早期依赖纹理叠加与后处理滤镜的粗粒度模拟,转向基于…...

AI时代数据中心架构变革:从计算中心到加速基础设施
1. 从“计算中心”到“加速基础设施”:数据中心架构的范式转移最近和几个在头部云厂商做架构设计的老朋友聊天,话题总绕不开一个词:加速基础设施。这词儿听起来挺高大上,但说白了,就是咱们传统数据中心那套“通用计算存…...