aws dynamodb 使用awsapi和PartiQL掌握dynamodb的CRUD操作
总结一下
- dynamodb通常和java等后端sdk结合使用
- 使用的形式可以是api或partiql语法调用
- dynamodb的用法不难,更重要的是维护成本,所需的服务集成,技术选型等
- 和大数据结合场景下有独特优势
之后可能再看看java sdk中DynamoDBMapper的写法,以及对标产品documentdb的比较
创建dynamodb表
创建表
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/create-table.html
- 主键可包含一个属性(分区键)或两个属性(分区键和排序键)。需要提供每个属性的属性名称、数据类型和角色:
HASH(针对分区键) 和RANGE(针对排序键) - 使用预置模式,则必须指定表的初始读取和写入吞吐量设置
/// 预配置表
aws dynamodb create-table \--table-name Music \--attribute-definitions \AttributeName=Artist,AttributeType=S \AttributeName=SongTitle,AttributeType=S \--key-schema \AttributeName=Artist,KeyType=HASH \AttributeName=SongTitle,KeyType=RANGE \--provisioned-throughput \ReadCapacityUnits=5,WriteCapacityUnits=5 \--table-class STANDARD# --table-class STANDARD_INFREQUENT_ACCESS// 按需表
aws dynamodb create-table \--table-name Music \--attribute-definitions \AttributeName=Artist,AttributeType=S \AttributeName=SongTitle,AttributeType=S \--key-schema \AttributeName=Artist,KeyType=HASH \AttributeName=SongTitle,KeyType=RANGE \--billing-mode=PAY_PER_REQUEST
控制台创建默认表的配置如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hGso1Yks-1678515745623)(assets/image-20230311111037435.png)]](https://img-blog.csdnimg.cn/6f6499e69bad4b50b0979a0f93865dc1.png)
查看表
- 对按需表调用
DescribeTable时,读取容量单位和写入容量单位设置为 0
aws dynamodb describe-table --table-name Music
此时的最佳实践是开启Point-in-time recovery(dynamodb的自动备份),避免意外的写入和删除
-
可以按需恢复到最近35天(无法修改,禁用在开启需要从0开始计算天数)中的任意时间点。
-
备份方式为增量备份
-
开启时间点恢复不影响api的性能
-
支持跨region还原表
-
删除开启时间点还原的表,会自动创建一个备份快照(保留 35 天)
aws dynamodb update-continuous-backups \ --table-name Music \ --point-in-time-recovery-specification \ PointInTimeRecoveryEnabled=true
写入item
插入item有两种视图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iiqkYI07-1678515745625)(assets/image-20230311112037750.png)]](https://img-blog.csdnimg.cn/405e217a2c77469a8d6c3e29374f63b3.png)
dynamodb api插入item
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/put-item.html#examples
cat > item.json << EOF
{"Artist": {"S": "No One You Know"},"SongTitle": {"S": "Howdy"},"AlbumTitle": {"S": "Somewhat Famous"},"Awards": {"N": "0"}
}
EOF
aws dynamodb put-item \--table-name MusicCollection \--item file://item.json \--return-consumed-capacity TOTAL \--return-item-collection-metrics SIZE
// output
{"ConsumedCapacity": {"TableName": "Music","CapacityUnits": 1.0}
}
PartiQL插入item
aws dynamodb execute-statement --statement "INSERT INTO Music \VALUE {'Artist':'Oh My Hony','SongTitle':'Call Me Today', 'AlbumTitle':'Somewhat Famous', 'Awards':'1'}"
读取item
dynamodb api读取item
https://docs.aws.amazon.com/cli/latest/reference/dynamodb/get-item.html
--consistent-read|--no-consistent-read(boolean)Determines the read consistency model: If set to
true, then the operation uses strongly consistent reads; otherwise, the operation uses eventually consistent reads.
aws dynamodb get-item \--consistent-read \--table-name Music \--key '{ "Artist": {"S": "Acme Band"}, "SongTitle": {"S": "Happy Day"}}'
PartiQL读取item
aws dynamodb execute-statement --statement "SELECT * FROM Music \WHERE Artist='Acme Band' AND SongTitle='Happy Day'"
更新item
dynamodb api更新item,逻辑上先查询再修改
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/dynamodb/update-item.html
aws dynamodb update-item \--table-name Music \--key '{ "Artist": {"S": "Acme Band"}, "SongTitle": {"S": "Happy Day"}}' \--update-expression "SET AlbumTitle = :newval" \--expression-attribute-values '{":newval":{"S":"Updated Album Title1"}}' \--return-values ALL_NEW
PartiQL更新item
aws dynamodb execute-statement --statement "UPDATE Music \SET AlbumTitle='Updated Album Title' \WHERE Artist='Acme Band' AND SongTitle='Happy Day' \RETURNING ALL NEW *"
查询item
dynamodb api查询item
aws dynamodb query \--table-name Music \--key-condition-expression "Artist = :name" \--expression-attribute-values '{":name":{"S":"Acme Band"}}'
这里必须指定key表达式,否则会报错
An error occurred (ValidationException) when calling the Query operation: ExpressionAttributeValues can only be specified when using expressions: FilterExpression and KeyConditionExpression are null
PartiQL查询item
aws dynamodb execute-statement --statement "SELECT * FROM Music \WHERE Artist='Acme Band'"
更新dynamodb表
支持的操作有
- 修改表的预置吞吐量设置
- 更改表的读/写容量模式。
- 在表上操作全局二级索引
- 在表上启用或禁用 DynamoDB Streams
修改读写模式
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/switching.capacitymode.html
| 类型 | 位置 | 模式转换 |
|---|---|---|
| 按需模式 => 预置模式 | ||
| 读写模式 | 控制台 | 根据表和全局二级索引在过去 30 分钟内占用的读写容量估计初始预配置容量值 |
| 读写模式 | CLI 或 SDK | 用户通过cw查看历史使用情况(ConsumedWriteCapacityUnits 和 ConsumedReadCapacityUnits 指标)以确定新的吞吐量设置 |
| 按需模式 <= 预置模式 | ||
| 读写模式 | 任意 | 无需指定预期应用程序执行的读取和写入吞吐量 |
| 预置模式 => 按需模式 | ||
| 自动扩缩 | CLI 或 SDK | 可能会保留自动扩缩设置 |
| 自动扩缩 | 控制台 | 会删除自动扩缩设置 |
| 按需模式 <= 预置模式 | ||
| 自动扩缩 | CLI 或 SDK | 保留先前的 Auto Scaling 设置 |
| 自动扩缩 | 控制台 | 建议设置,目标利用率:70%,最小预置容量:5 个单位,最大预置容量:区域最大值 |
-
从按需模式更新为预置模式
- 控制台修改,根据表和全局二级索引在过去 30 分钟内占用的读写容量估计初始预配置容量值
- CLI 或 SDK,用户通过cw查看历史使用情况(
ConsumedWriteCapacityUnits和ConsumedReadCapacityUnits指标)以确定新的吞吐量设置
-
从预置模式更新为按需模式
- 无需指定预期应用程序执行的读取和写入吞吐量
关于自动扩缩
-
从预置模式更新为按需模式
-
控制台会删除自动扩缩设置
-
cli则可能会保留自动扩缩设置
-
-
从按需模式更新为预置模式
- 控制台建议设置,目标利用率:70%,最小预置容量:5 个单位,最大预置容量:区域最大值
- cli保留先前的 Auto Scaling 设置
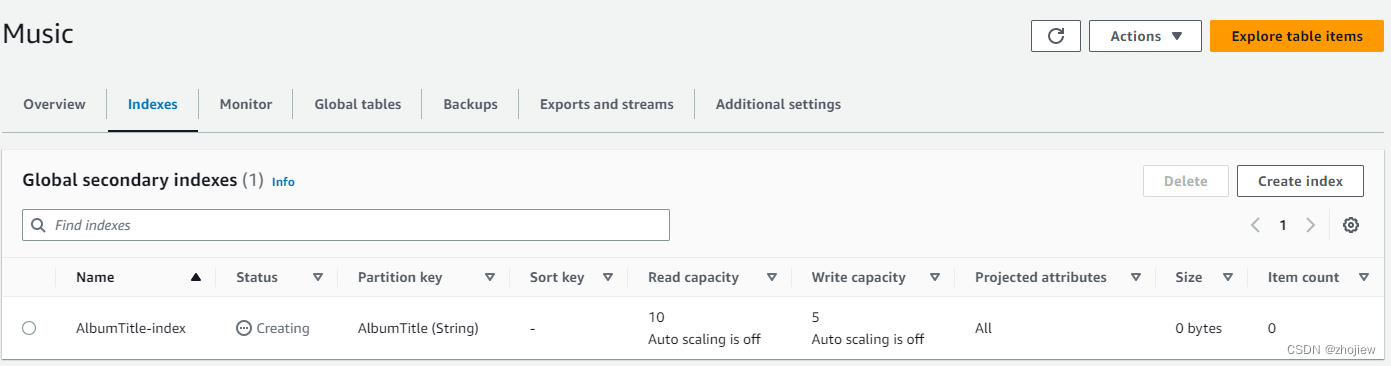
创建全局二级索引
创建全局二级索引是更新表操作的一种
dynamodb api创建索引
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/dynamodb/update-table.html#examples
If you are adding a new global secondary index to the table,
AttributeDefinitionsmust include the key element(s) of the new index.
cat > gsi-updates.json << EOF
[{"Create": {"IndexName": "AlbumTitle-index","KeySchema": [{"AttributeName": "AlbumTitle","KeyType": "HASH"}],"ProvisionedThroughput": {"ReadCapacityUnits": 10,"WriteCapacityUnits": 5},"Projection": {"ProjectionType": "ALL"}}}
]
EOF
aws dynamodb update-table \--table-name Music \--attribute-definitions AttributeName=AlbumTitle,AttributeType=S \--global-secondary-index-updates file://gsi-updates.json
控制台查看
aws dynamodb describe-table --table-name Music | grep IndexStatus
查询全局二级索引
dynamodb api查询GSI
aws dynamodb query \--table-name Music \--index-name AlbumTitle-index \--key-condition-expression "AlbumTitle = :name" \--expression-attribute-values '{":name":{"S":"Somewhat Famous"}}'
PartiQL查询GSI
aws dynamodb execute-statement --statement "SELECT * FROM ‘Music’.‘AlbumTitle-index’ \WHERE AlbumTitle='Somewhat Famous'"
删除表
aws dynamodb delete-table --table-name Music
查看吞吐量配额
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/ServiceQuotas.html#default-limits-throughput
- 预置吞吐量配额是表容量加上其所有全局二级索引容量的总和
$ aws dynamodb describe-limits
{"AccountMaxReadCapacityUnits": 80000,"AccountMaxWriteCapacityUnits": 80000,"TableMaxReadCapacityUnits": 40000,"TableMaxWriteCapacityUnits": 40000
}
相关问题
节流问题
https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/ProvisionedThroughput.html#ProvisionedThroughput.Troubleshooting
-
DynamoDB 仅向 CloudWatch 报告分钟级指标,然后将这些指标计算为一分钟的总和并取平均值。但是 DynamoDB 本身会应用每秒的速率限制。可能由于微突增产生限流
-
当 2 个数据点在 1 分钟内超过所配置的目标利用率值时,可以触发自动扩缩,如果峰值间隔超过 1 分钟,则可能无法触发自动扩缩。在触发自动扩缩之后,都会调用
UpdateTable API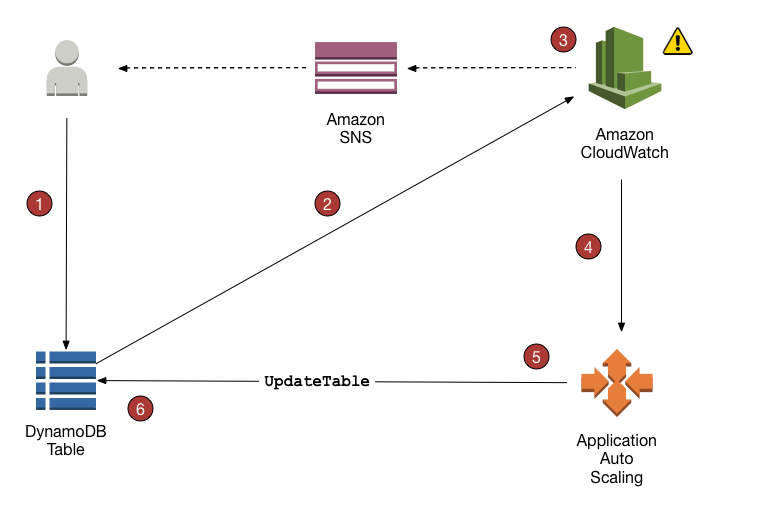
-
对于按需表,如果吞吐量在 30 分钟内超出先前峰值的两倍,则可能发生节流
-
生成的“热分区”超过了每分区每秒 3000 RCU 或 1000 WCU 的限制,这可能会导致节流
相关文章:
aws dynamodb 使用awsapi和PartiQL掌握dynamodb的CRUD操作
总结一下 dynamodb通常和java等后端sdk结合使用使用的形式可以是api或partiql语法调用dynamodb的用法不难,更重要的是维护成本,所需的服务集成,技术选型等和大数据结合场景下有独特优势 之后可能再看看java sdk中DynamoDBMapper的写法&…...
【C++学习】类和对象(上)
前言: 由于之前电脑“嗝屁”了,导致这之前一直没有更新博客,今天才拿到电脑,在这里说声抱歉。接下来就进入今天的学习,在之前我们已经对【C】进行了初步的认识,有了之前的知识铺垫,今天我们将来…...

一文带你深入理解【Java基础】· Java反射机制(下)
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...
JVM的几种GC
GC JVM在进行GC时,并不是对这三个区域统一回收。大部分时候,回收都是新生代~ 新生代GC(minor GC): 指发生在新生代的垃圾回收动作,因为Java对象大多都具备朝生夕灭的特点,所以minor GC发生得非…...
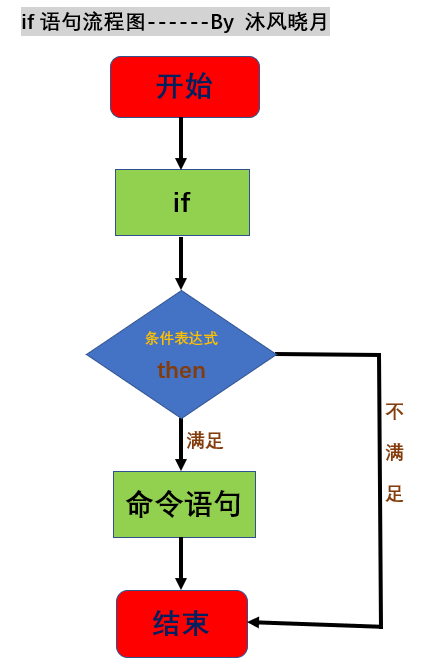
掌握Shell脚本的if语句,让你的代码更加精准和高效
前言 大家好,我是沐风晓月,本文首发于csdn, 作者: 我是沐风晓月。 文章收录于 我是沐风晓月csdn专栏 【系统架构实战】专栏中的【shell脚本入门到精通】专栏。 本专栏从零基础带你层层深入,学会shell脚本,不是梦。 &…...

音质好的蓝牙耳机有哪些?音质最好的蓝牙耳机排行
说起当代人外出必备是数码产品,蓝牙耳机肯定存在。不管是听歌还是追剧,蓝牙耳机在音质上的表现也是越来越好了。下面,我来给大家推荐几款音质好的蓝牙耳机,一起来看看吧。 一、南卡小音舱蓝牙耳机 参考价:259 蓝牙版…...

一次Android App NDK崩溃问题的分析及解决
文章目录小结NDK崩溃的问题通过logcat查看崩溃日志提取tombstone的记录通过ndk-stack来输出日志取得的日志分析并解决分析使用add2line定位具体报错的行数解决参考小结 最近碰一次Android App NDK崩溃的问题,这个NE(Native Exception)是从ND…...
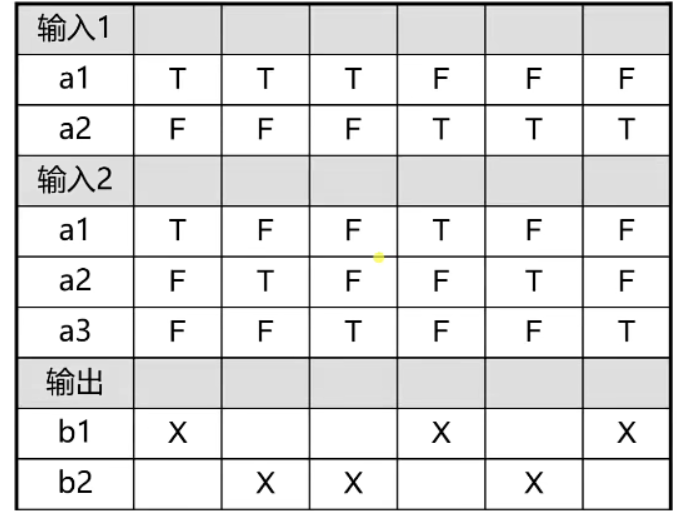
因果图判定表法
因果图&判定表法 在了解了等价类和边界值比较适宜搭档的测试用例方法之后 接下来我们来了解另外一队就是因果图和判定表 因果图会产生判定表法 因果图法 等价类划分法和边界值分析方法都是着重考虑输入条件而不考虑输入条件的各种组合、输入条件之间的相互制约关系。例…...

Oracle 数据库相关信息清单列表
Oracle 数据库相关信息清单列表 一、设置Oracle安装目录 Oracle基目录(ORACLE_BASE):D:\databases\oracle\oracle_11g\app\Administrator 软件位置(ORACLE_HOME):D:\databases\oracle\oracle_11g\app\Administrator\product\11.2.0\dbhome_1 数据库文件位置:D:\databa…...

射频资料搜集--推荐几个网站和链接
https://picture.iczhiku.com/resource/eetop/wHKYFQlDTRRShCcc.pdfhttps://picture.iczhiku.com/resource/eetop/wHKYFQlDTRRShCcc.pdfVCO pulling的资料 模拟滤波器与电路设计手册 - 射频微波仿真 - RF技术社区 Practical RF Amplifier Design Using the Available Gain Pr…...

B1048 数字加密
decription 本题要求实现一种数字加密方法。首先固定一个加密用正整数 A,对任一正整数 B,将其每 1 位数字与 A 的对应位置上的数字进行以下运算:对奇数位,对应位的数字相加后对 13 取余——这里用 J 代表 10、Q 代表 11、K 代表 …...

Qt使用FFmpeg播放视频
一、使用场景 因为项目中需要加载MP4播放开机视频,而我们的设备所使用的架构为arm架构,其中缺乏一些多媒体库。安装这些插件库比较麻烦,所以最终决定使用FFmpeg播放视频。 二、下载编译ffmpeg库 2.1 下载源码 源码下载路径:http…...
Win32 ListBox控件
Win32 ListBox控件 创建ListBox控件 创建窗口函数 HWND CrateWindowEx(DWORD dwExStyle , // 窗口的扩展风格,基本没用LPCTSTR lpClassName, // 已经注册的窗口类名称LPCTSTR lpWindowName, // 窗口标题栏的名字DWORD dwStyle, // 窗口的基本风格int x, // 左上角水平坐标int …...
最大值池化与均值池化比较分析
1 问题在深度学习的卷积网络过程中,神经网络有卷积层,池化层,全连接层。而池化层有最大值池化和均值池化两种情况,而我们组就在思考,最大值池化和均值池化有什么区别呢?两者的模型准确率是否有所不同&#…...

统计学 多元线性回归
文章目录统计学 多元线性回归多元线性回归模型拟合优度显著性检验线性关系检验回归系数检验多重共线性及其处理多重共线性的问题多重共线性的识别与处理变量选择利用回归方程进行预测哑变量回归统计学 多元线性回归 多元线性回归模型 多元线性回归模型:设因变量为…...
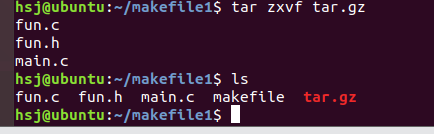
tar和gzip压缩和解压
打包和压缩的区别:打包:将多文件 封装在一起压缩:将多文件 封装在一起 通过特定的算法 将冗余的数据 进行删除tar默认是打包命令,如果想用tar进行压缩 必须加选项1、gzip格式压缩:tar zcvf 压缩包包名 文件1 文件2 文件…...

搭建Docker企业私有仓库
什么是仓库 仓库(Repository)是存储和分发 Docker 镜像的地方。镜像仓库类似于代码仓库,Docker Hub 的命名来自 GitHub,Github 是我们常用的代码存储和分发的地方。同样 Docker Hub 是用来提供 Docker 镜像存储和分发的地方。 谈…...

[NOIP2009 提高组] 最优贸易(C++,tarjan,topo,DP)
题目描述 $C 国有国有国有 n 个大城市和个大城市和个大城市和 m$ 条道路,每条道路连接这 nnn个城市中的某两个城市。任意两个城市之间最多只有一条道路直接相连。这 mmm 条道路中有一部分为单向通行的道路,一部分为双向通行的道路,双向通行的…...

计算机网络:移动IP
移动IP相关概念 移动IP技术是移动结点(计算机/服务器)以固体的网络IP地址,实现跨越不同网段的漫游功能,并保证了基于网络IP的网络权限在漫游中不发生任何改变。移动结点:具有永久IP地址的设备。归属代理(本…...

binutils工具集——GNU binutils工具集简介
以下内容源于网络资源的学习与整理,如有侵权请告知删除。 GNU binutils是一个二进制工具集,主要包括: ld,GNU链接器。as,GNU汇编器。addr2line,把地址转化为文件名和行号。nm,列出目标文件的符…...

SubLens:AI订阅管理浏览器插件,一站式聚合账单与扣款提醒
1. 项目概述:一个帮你管好AI订阅账单的浏览器插件 如果你和我一样,订阅了不止一个AI服务——比如ChatGPT Plus用来日常对话和写作,Claude Pro用来处理长文档,GitHub Copilot写代码,Cursor辅助开发,再加上G…...

GPU内核优化技术:R3框架原理与实践
1. GPU内核优化基础与挑战在HPC和科学计算领域,GPU内核优化是提升计算效率的核心技术。内核(Kernel)作为GPU上执行的基本计算单元,其性能直接影响整个应用的运行时间。典型的优化手段包括循环展开、内存访问优化、指令级并行等&am…...

城市级智慧停车平台建设思路:如何整合多个停车项目的数据
引言随着城市化进程的加速和机动车保有量的持续攀升,"停车难、停车乱"已经成为困扰各大城市的普遍性问题。根据公安部统计数据,截至2025年底,全国机动车保有量已突破4.5亿辆,而城市停车位缺口预计超过8000万个。与此同时…...

基于Ansible Playbook的Kubernetes集群自动化部署实践
1. 项目概述:一个为Kubernetes集群部署而生的自动化剧本如果你和我一样,长期在运维和DevOps一线摸爬滚打,那么对Kubernetes集群的初始化部署一定又爱又恨。爱的是它带来的强大编排能力,恨的是那套繁琐、易错、文档分散的kubeadm i…...
)
Midjourney未来三年风格演进路径图(2024–2026关键拐点全标注)
更多请点击: https://intelliparadigm.com 第一章:Midjourney 2026年审美趋势总览 2026年,Midjourney 的视觉语言正经历一场由技术理性与人文温度共同驱动的范式迁移。V7引擎全面启用动态语义权重调节(DSWR)ÿ…...

智能设备语音交互进阶:从‘慢交互’到‘快交互’,详解ONESHOT模式下的音频残留音过滤实战
智能设备语音交互进阶:ONESHOT模式下的音频残留音过滤实战 在智能语音交互领域,ONESHOT模式已经成为提升用户体验的关键技术。这种允许用户在唤醒设备后无需二次唤醒即可直接下达指令的交互方式,正在重塑人机对话的自然流畅度。然而ÿ…...

5分钟免费解锁iPhone激活锁:applera1n实用指南
5分钟免费解锁iPhone激活锁:applera1n实用指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 面对二手iPhone的激活锁界面,你是否感到束手无策?applera1n是一款专为…...

VLSI时代下74系列离散逻辑芯片的现代应用与设计实践
1. 从“胶水逻辑”到“系统粘合剂”:离散逻辑芯片的现代生存法则 在今天的数字电路设计领域,提起“7400系列”或者“74HC04”,很多年轻工程师的第一反应可能是博物馆里的古董,或者教科书上的历史章节。主流叙事已经被SoC、FPGA和高…...
)
告别砖头:GD32 BootLoader设计中的Flash分区与地址规划实战指南(含IAR/Keil工程配置)
GD32 BootLoader架构设计与Flash分区策略实战 1. 理解GD32 Flash存储特性与IAP基础架构 GD32系列MCU的Flash存储结构呈现出典型的非均匀扇区分布特征——前4个扇区为16KB,后续扇区则扩展为64KB。这种物理特性直接影响了BootLoader设计的核心逻辑。不同于传统均匀分…...

如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南
如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch 还在为DS918…...