在Ubuntu 14.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。
Elasticsearch 支持 RESTful 操作。这意味着您可以使用 HTTP 方法(GET、POST、PUT、DELETE 等)结合 HTTP URI(/collection/entry)来操作您的数据。直观的 RESTful 方法既方便开发人员又用户友好,这也是 Elasticsearch 受欢迎的原因之一。
Elasticsearch 是一款免费且开源的软件,由 Elastic 公司提供支持。这种组合使其适用于从个人测试到企业集成的各种场景。
本文将介绍 Elasticsearch,并向您展示如何安装、配置和开始使用它。
先决条件
在按照本教程操作之前,请确保您完成以下先决条件:
- 一个 Ubuntu 14.04 Droplet
- 一个非 root sudo 用户。详情请参阅《使用 Ubuntu 14.04 进行初始服务器设置》。
除非另有说明,本教程中需要 root 权限的所有命令都应该以具有 sudo 权限的非 root 用户身份运行。
假设
本教程假设您的服务器正在使用类似于此处描述的 VPN:《如何使用 Ansible 和 Tinc VPN 保护您的服务器基础设施》。这将为服务器提供私有网络功能,无论其物理网络如何。
如果您正在使用共享私有网络,比如 DigitalOcean 私有网络,则此安全功能将已经对同一团队或同一区域帐户中的服务器启用。这在使用 Elasticsearch 时尤为重要,因为它的 HTTP 接口中没有内置安全性。
步骤 1 — 安装 Java
首先,您需要在 Droplet 上安装 Java 运行环境(JRE),因为 Elasticsearch 是用 Java 编写的。Elasticsearch 需要 Java 7 或更高版本。Elasticsearch 推荐使用 Oracle JDK 版本 1.8.0_73,但本地 Ubuntu OpenJDK JRE 包也可以正常工作。
本步骤将向您展示如何安装这两个版本,以便您可以决定哪个更适合您。
安装 OpenJDK
本地 Ubuntu OpenJDK JRE 包是免费的,得到良好支持,并通过 Ubuntu APT 安装管理器自动管理。
在使用 APT 安装 OpenJDK 之前,请运行以下命令更新您的 Ubuntu Droplet 上可用的安装包列表:
sudo apt-get update
之后,您可以使用以下命令安装 OpenJDK:
sudo apt-get install openjdk-7-jre
要验证您的 JRE 是否已安装并可用,请运行以下命令:
java -version
结果应如下所示:
[secondary_label Output of java -version]
java version "1.7.0_79"
OpenJDK Runtime Environment (IcedTea 2.5.6) (7u79-2.5.6-0ubuntu1.14.04.1)
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
安装 Java 8
当您在使用 Elasticsearch 时,开始寻找更好的 Java 性能和兼容性时,您可能选择安装 Oracle 的专有 Java(Oracle JDK 8)。
将 Oracle Java PPA 添加到 apt:
sudo add-apt-repository -y ppa:webupd8team/java
更新您的 apt 包数据库:
sudo apt-get update
使用以下命令安装 Oracle Java 8 的最新稳定版本(并接受弹出的许可协议):
sudo apt-get -y install oracle-java8-installer
最后,验证它是否已安装:
java -version
步骤 2 — 下载并安装 Elasticsearch
Elasticsearch 可以直接从 elastic.co 以 zip、tar.gz、deb 或 rpm 包的形式下载。对于 Ubuntu,最好使用 deb(Debian)包,它将安装运行 Elasticsearch 所需的一切。
在撰写本文时,最新的 Elasticsearch 版本是 1.7.2。使用以下命令在您选择的目录中下载它:
wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.deb
然后,以通常的 Ubuntu 方式使用 dpkg 命令安装它,如下所示:
sudo dpkg -i elasticsearch-1.7.2.deb
这将导致 Elasticsearch 安装在 /usr/share/elasticsearch/,其配置文件放置在 /etc/elasticsearch,并将其 init 脚本添加到 /etc/init.d/elasticsearch。
为确保 Elasticsearch 随 Droplet 自动启动和停止,使用以下命令将其 init 脚本添加到默认运行级别:
sudo update-rc.d elasticsearch defaults
步骤 3 — 配置 Elastic
现在 Elasticsearch 及其 Java 依赖已经安装完成,是时候配置 Elasticsearch 了。
Elasticsearch 的配置文件位于 /etc/elasticsearch 目录下。主要有两个文件:
-
elasticsearch.yml— 配置 Elasticsearch 服务器设置。除了日志设置之外,几乎所有选项都存储在这里,这也是我们主要关注的文件。 -
logging.yml— 提供日志配置。一开始,您无需编辑此文件。您可以保留所有默认的日志选项。默认情况下,您可以在/var/log/elasticsearch目录下找到生成的日志。
在任何 Elasticsearch 服务器上自定义的第一个变量是 elasticsearch.yml 中的 node.name 和 cluster.name。正如它们的名称所示,node.name 指定服务器(节点)的名称,以及后者所关联的集群。
如果您不自定义这些变量,node.name 将根据 Droplet 主机名自动分配。cluster.name 将自动设置为默认集群的名称。
cluster.name 值被 Elasticsearch 的自动发现功能用于自动发现和关联 Elasticsearch 节点到一个集群。因此,如果您不更改默认值,您可能会在集群中发现不需要的节点,这些节点在同一网络上被找到。
要开始编辑主要的 elasticsearch.yml 配置文件:
sudo nano /etc/elasticsearch/elasticsearch.yml
删除 node.name 和 cluster.name 行开头的 # 字符以取消注释,然后更改它们的值。您在 /etc/elasticsearch/elasticsearch.yml 文件中的第一个配置更改应如下所示:
...
node.name: "My First Node"
cluster.name: mycluster1
...
另一个重要的设置是服务器的角色,可以是 “master” 或 “slave”。“Masters” 负责集群的健康和稳定性。在具有大量集群节点的大型部署中,建议有多个专用 “master”。通常,专用 “master” 不会存储数据或创建索引。因此,不应该有被过载的机会,从而危及集群的健康。
“Slaves” 用作可以加载数据任务的 “工作马”。即使 “slave” 节点被过载,只要有其他节点来承担额外负载,集群健康就不应受到严重影响。
确定服务器角色的设置称为 node.master。如果您只有一个 Elasticsearch 节点,应该将此选项保持注释状态,以保持其默认值 true — 即唯一节点也应该是主节点。或者,如果您希望将节点配置为从节点,删除 node.master 行开头的 # 字符,并将值更改为 false:
...
node.master: false
...
另一个重要的配置选项是 node.data,它确定节点是否存储数据。在大多数情况下,此选项应保留其默认值(true),但有两种情况下您可能希望不在节点上存储数据。一种情况是当节点是专用 “master” 时,正如我们已经提到的。另一种情况是当节点仅用于从其他节点获取数据和聚合结果时。在后一种情况下,节点将充当 “搜索负载均衡器”。
同样,如果您只有一个 Elasticsearch 节点,应该将此设置保持注释状态,以保持默认值 true。否则,要禁用本地存储数据,请取消注释以下行并将值更改为 false:
...
node.data: false
...
另外两个重要选项是 index.number_of_shards 和 index.number_of_replicas。前者确定索引将被分成多少片段(shards)。后者定义将在集群中分布的副本数量。拥有更多的分片可以提高索引性能,而拥有更多的副本可以加快搜索速度。
假设您仍在单个节点上探索和测试 Elasticsearch,最好从只有一个分片和没有副本开始。因此,它们的值应设置为以下内容(确保删除行开头的 #):
...
index.number_of_shards: 1
index.number_of_replicas: 0
...
您可能有兴趣更改的另一个最终设置是 path.data,它确定数据存储的路径。默认路径是 /var/lib/elasticsearch。在生产环境中,建议为存储 Elasticsearch 数据使用专用分区和挂载点。在最佳情况下,这个专用分区将是一个单独的存储介质,它将提供更好的性能和数据隔离。您可以通过取消注释 path.data 行并更改其值来指定不同的 path.data 路径:
...
path.data: /media/different_media
...
完成所有更改后,请保存并退出文件。现在,您可以使用以下命令首次启动 Elasticsearch:
sudo service elasticsearch start
请至少等待 10 秒,以便 Elasticsearch 完全启动,然后才能使用它。否则,您可能会收到无法连接的错误。
第四步 —— 安全设置 Elastic
Elasticsearch 没有内置的安全机制,可以被访问 HTTP API 的任何人控制。本节不是一个全面的 Elasticsearch 安全设置指南。请采取必要的措施防止未经授权的访问以及保护其运行的服务器/虚拟机。考虑使用 iptables 进一步保护您的系统。
第一个安全调整是防止公共访问。要移除公共访问,请编辑文件 elasticsearch.yml:
sudo nano /etc/elasticsearch/elasticsearch.yml
找到包含 network.bind_host 的行,通过删除行首的 # 字符来取消注释,并将值更改为 localhost,使其如下所示:
...
network.bind_host: localhost
...
另外,为了增强安全性,您可以禁用用于评估自定义表达式的动态脚本。通过构造自定义恶意表达式,攻击者可能会危害您的环境。
要禁用自定义表达式,请在 /etc/elasticsearch/elasticsearch.yml 文件末尾添加以下行:
...script.disable_dynamic: true
...
第五步 —— 测试
到目前为止,Elasticsearch 应该在 9200 端口上运行。您可以使用 curl 这个命令行客户端 URL 传输工具进行测试,执行一个简单的 GET 请求,如下所示:
curl -X GET 'http://localhost:9200'
您应该会看到以下响应:
[secondary_label Output of curl]
{"status" : 200,"name" : "Harry Leland","cluster_name" : "elasticsearch","version" : {"number" : "1.7.2","build_hash" : "e43676b1385b8125d647f593f7202acbd816e8ec","build_timestamp" : "2015-09-14T09:49:53Z","build_snapshot" : false,"lucene_version" : "4.10.4"},"tagline" : "You Know, for Search"
}
如果您看到类似上面的响应,那么 Elasticsearch 正常工作。如果没有,请确保您已正确遵循安装说明,并且已允许 Elasticsearch 充分启动的时间。
第六步 —— 使用 Elasticsearch
要开始使用 Elasticsearch,让我们首先添加一些数据。如前所述,Elasticsearch 使用 RESTful API,响应通常包括 CRUD 命令:创建、读取、更新和删除。我们将再次使用 curl 进行操作。
您可以使用以下命令添加第一条数据:
curl -X POST 'http://localhost:9200/tutorial/helloworld/1' -d '{ "message": "Hello World!" }'
您应该会看到以下响应:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"created":true}
通过 curl,我们向 Elasticseach 服务器发送了一个 HTTP POST 请求。请求的 URI 是 /tutorial/helloworld/1。理解这里的参数很重要:
tutorial是 Elasticsearch 中数据的索引。helloworld是类型。1是上述索引和类型下我们条目的 id。
您可以使用以下 HTTP GET 请求检索此第一条数据:
curl -X GET 'http://localhost:9200/tutorial/helloworld/1'
结果应该如下所示:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"found":true,"_source":{ "message": "Hello World!" }}
要修改现有条目,您可以使用以下 HTTP PUT 请求:
curl -X PUT 'localhost:9200/tutorial/helloworld/1?pretty' -d '
{"message": "Hello People!"
}'
Elasticsearch 应该会确认成功修改,如下所示:
{"_index" : "tutorial","_type" : "helloworld","_id" : "1","_version" : 2,"created" : false
}
在上面的示例中,我们将第一条目的 message 修改为 “Hello People!”。因此,版本号已自动增加为 2。
您可能已经注意到上述请求中的额外参数 pretty。它启用了人类可读的格式,因此您可以将每个数据字段写在新的一行上。在检索数据时,您也可以使结果更美观,如下所示:
curl -X GET 'http://localhost:9200/tutorial/helloworld/1?pretty'
现在,响应将以更好的格式呈现:
{"_index" : "tutorial","_type" : "helloworld","_id" : "1","_version" : 2,"found" : true,"_source":{ "message": "Hello World!" }
}
到目前为止,我们已经向 Elasticsearch 添加了数据并进行了查询。要了解其他操作,请查看 API 文档。
结论
这就是安装、配置和开始使用Elasticsearch的简单过程。一旦你对手动查询有了足够的了解,下一个任务将是从你的应用程序开始使用它。
相关文章:

在Ubuntu 14.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C++:inline关键字nullptr
inline关键字 C中inline使用关键点强调 (1)inline是一种“用于实现的关键字”,而不是一种“用于声明的关键字”,所以关键字 inline 必须与函数定义体放在一起,而不是和声明放在一起 (2)如果希望在多个c文件中使用,则inline函数应…...

数字信号处理实验三(IIR数字滤波器设计)
IIR数字滤波器设计(2学时) 要求: 产生一复合信号序列,该序列包含幅度相同的28Hz、50Hz、100Hz、150Hz的单音(单频)信号;其中,50Hz及其谐波为工频干扰(注:采样…...

Why is Kafka fast?(Kafka性能基石)
Kafka概述 Why is kafka fast? 思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast? 我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(through…...

Linux下的SSH详解及Ubuntu教程
前言 SSH(Secure Shell)是一种用于计算机之间安全通信的协议,广泛应用于远程登录、系统管理和文件传输等场景。本文将详细介绍SSH在Linux系统(特别是Ubuntu)下的使用,包括安装、配置、密钥管理和常见应用&…...
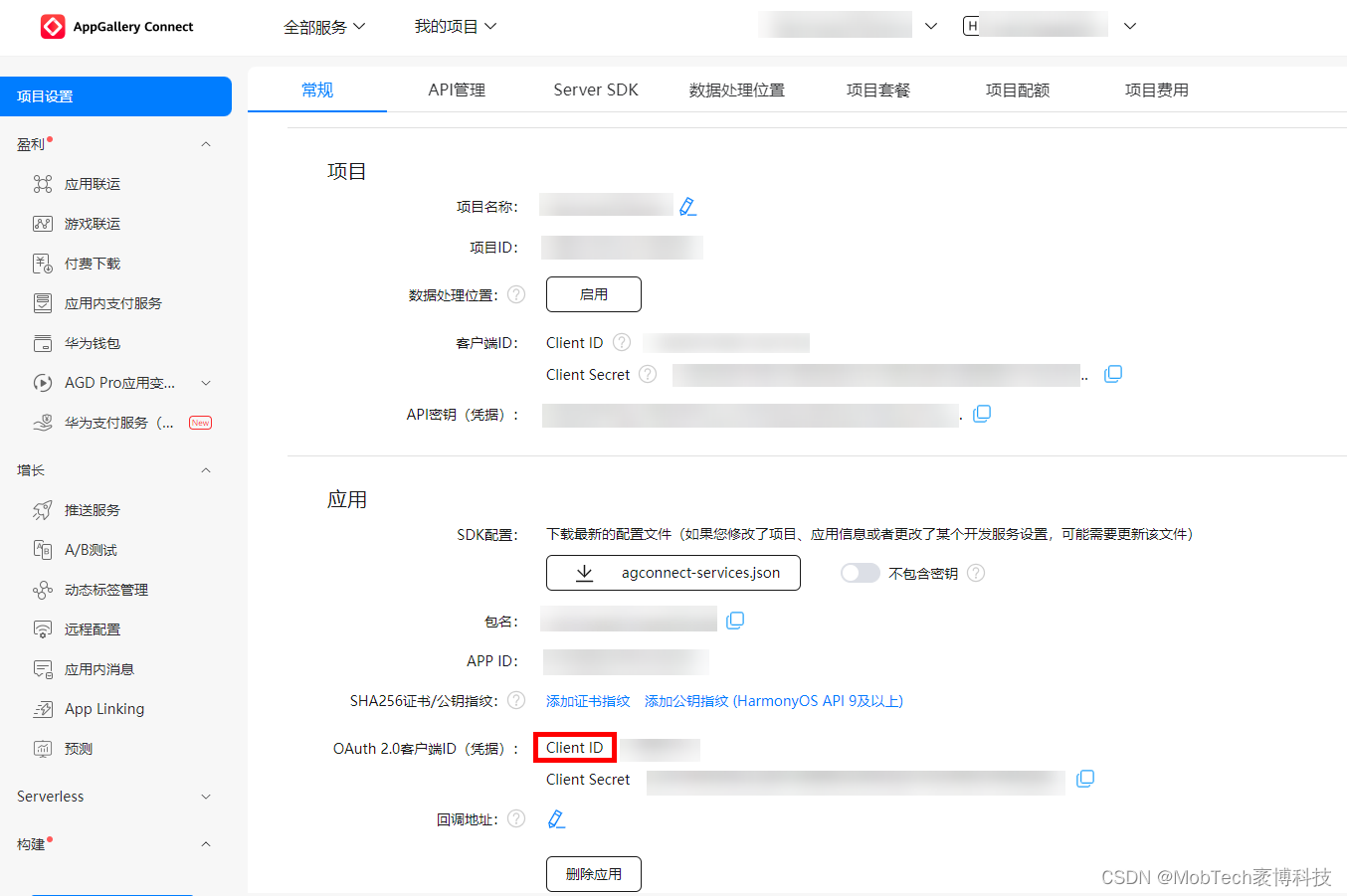
MobPush HarmonyOS NEXT 版本集成指南
开发工具:DevEco Studio 集成方式:在线集成 HarmonyOS API支持:> 11 集成前准备 注册账号 使用MobSDK之前,需要先在MobTech官网注册开发者账号,并获取MobTech提供的AppKey和AppSecret,详情可以点击查…...

什么是封装?为什么要封装?
什么是封装? 封装是计算机科学中的一个重要概念,尤其在面向对象编程(OOP)中占据核心地位。封装主要指的是将数据(属性)和对这些数据的操作(方法)组合在一个单元中(我们称…...
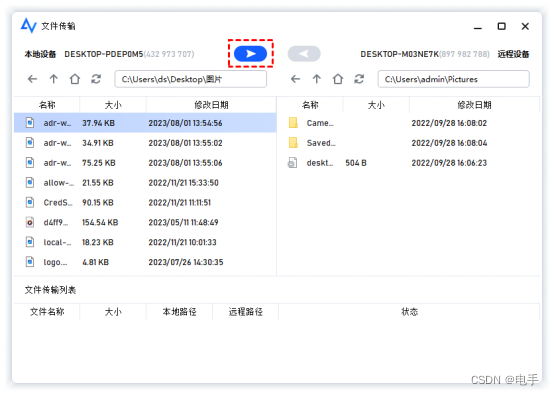
远程桌面无法复制粘贴文件到本地怎么办?
远程桌面不能复制粘贴问题 Windows远程桌面为我们提供了随时随地访问文件和数据的便捷途径,大大提升了工作和生活的效率。然而,在使用过程中,我们也可能遇到一些问题。例如,在通过远程桌面传输文件时,常常会出现无法复…...
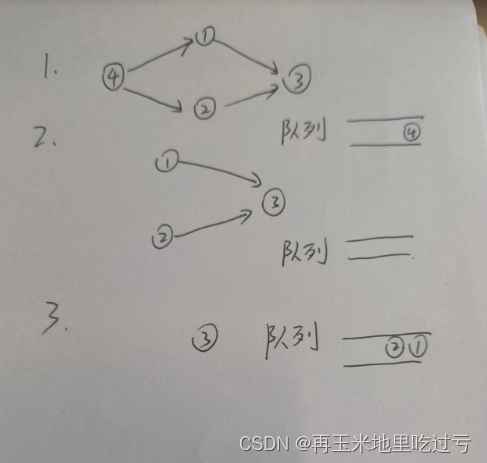
LeetCode 207. 课程表
思路:这是一道拓扑排序问题,拓扑排序听起来可能有点复杂,但实际上它是个相当直观的概念。想象一下,你有很多事情要做,但有些事情必须在另一些事情完成之后才能开始,就像你得先穿上袜子再穿鞋子 拓扑排序就…...
数据结构历年考研真题对应知识点(树的基本概念)
目录 5.1树的基本概念 5.1.2基本术语 【森林中树的数量、边数和结点数的关系(2016)】 5.1.3树的性质 【树中结点数和度数的关系的应用(2010、2016)】 【指定结点数的三叉树的最小高度分析(2022)】 5.1…...

Pytorch和Tensorflow安装【Win和Linux】
Ubuntu/win安装Pytorch和Tensorflow 说明: 这两种框架的搭建,均基于Anaconda进行搭建。先在系统中安装Anaconda软件。 一、Pytorch的搭建 windows安装 (1)搭建参考官网给的命令,pytorch官网 (2)下载地址:https://download.pytorch.org/whl/torch_stable.html 从上述…...

筑算网基石 创数智未来|锐捷网络闪耀2024 MWC上海
2024年6月26日至28日,全球科技界瞩目的GSMA世界移动大会(MWC 上海)在上海新国际博览中心(SNIEC)盛大召开。作为行业领先的网络解决方案提供商,锐捷网络以“筑算网基石 创数智未来”为主题,带来了…...

T4打卡 学习笔记
所用环境 ● 语言环境:Python3.11 ● 编译器:jupyter notebook ● 深度学习框架:TensorFlow2.16.1 ● 显卡(GPU):NVIDIA GeForce RTX 2070 设置GPU from tensorflow import keras from tensorflow.keras…...
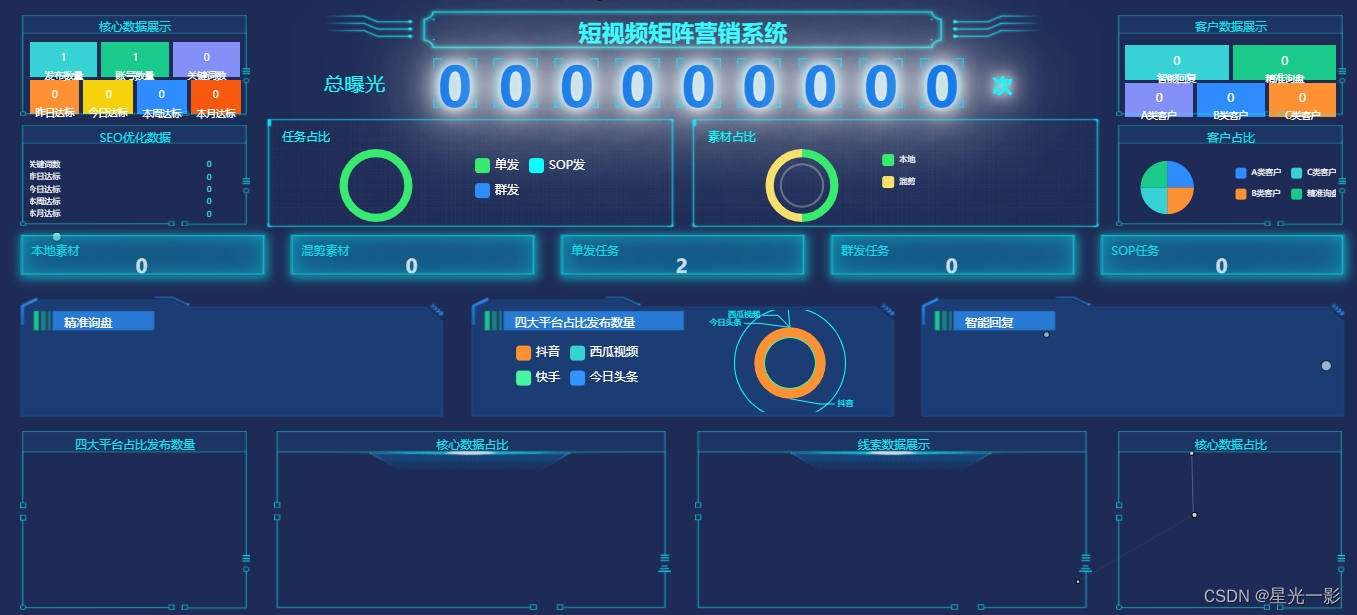
抖音矩阵云混剪系统源码 短视频矩阵营销系统V2(全开源版)
>>>系统简述: 抖音阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复,多…...
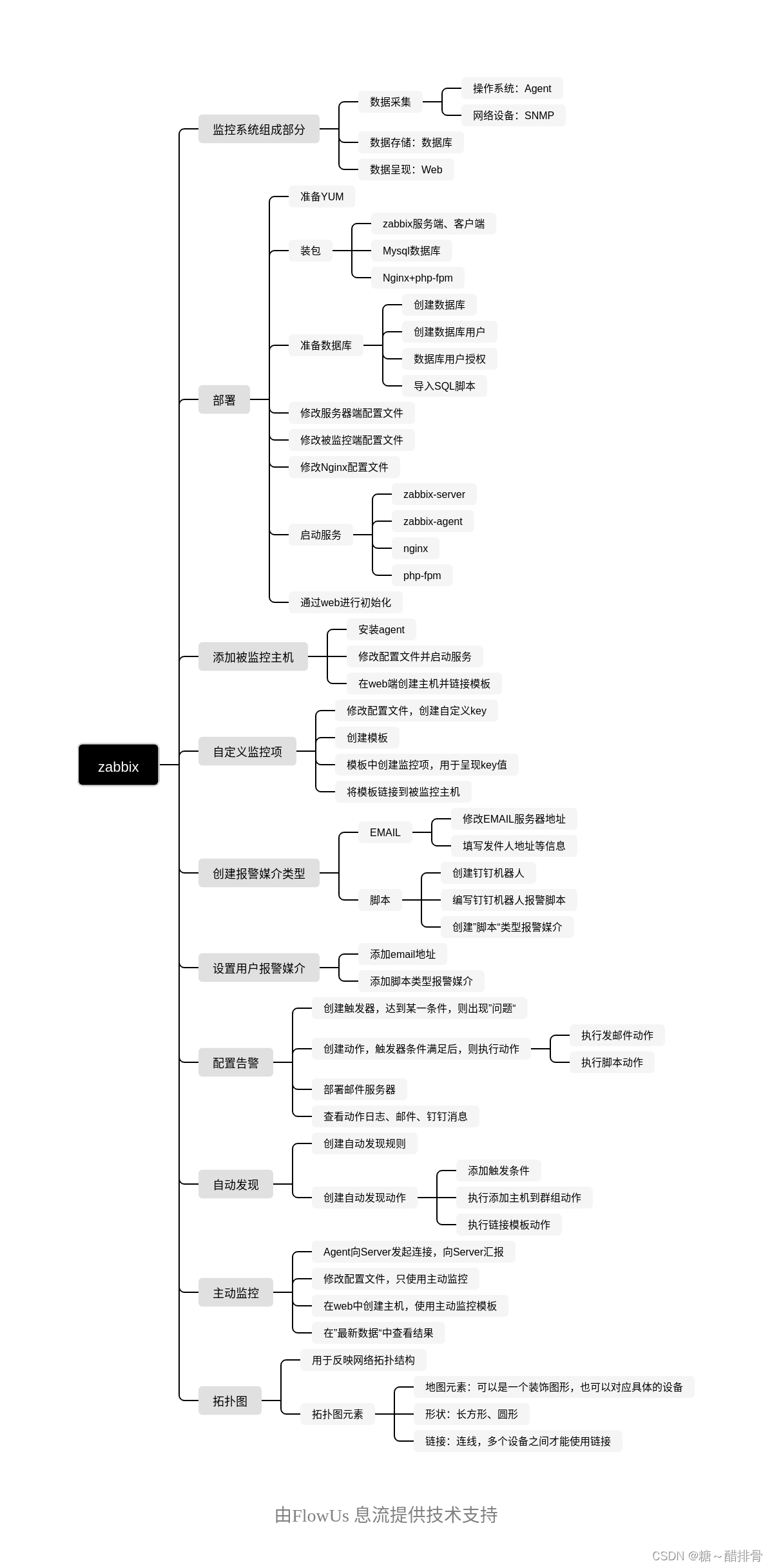
zabbix报警机制
zabbix思路流程...

【Matlab】-- 飞蛾扑火优化算法
文章目录 文章目录 01 飞蛾扑火算法介绍02 飞蛾扑火算法伪代码03 基于Matlab的部分飞蛾扑火MFO算法04 参考文献 01 飞蛾扑火算法介绍 飞蛾扑火算法(Moth-Flame Optimization,MFO)是一种基于自然界飞蛾行为的群体智能优化算法。该算法由 Sey…...

全面体验ONLYOFFICE 8.1版本桌面编辑器
ONLYOFFICE官网 在当今的数字化办公环境中,选择合适的文档处理工具对于提升工作效率和团队协作至关重要。ONLYOFFICE 8.1版本桌面编辑器,作为一款集成了多项先进功能的办公软件,为用户提供了全新的办公体验。今天,我们将深入探索…...

建议csdn赶紧将未经作者同意擅自锁住收费的文章全部解锁,别逼我用极端手段让你们就范
前两天我偶然发现csdn竟然将我以前发表的很多文章锁住向读者收费才让看。 csdn这种无耻行径往小了说是侵犯了作者的版权著作权,往大了说这是在打击我国IT领域未来的发展,因为每一个做过编程工作的人都知道,任何一个程序员的学习成长过程都少不…...

Pycharm一些问题解决办法
研究生期间遇到关于Pycharm一些问题报错以及解决办法的汇总 ModuleNotFoundError: No module named sklearn’ 安装机器学习库,需要注意报错的sklearn是scikit-learn缩写。 pip install scikit-learnPyCharm 导包提示 unresolved reference 描述:模块…...
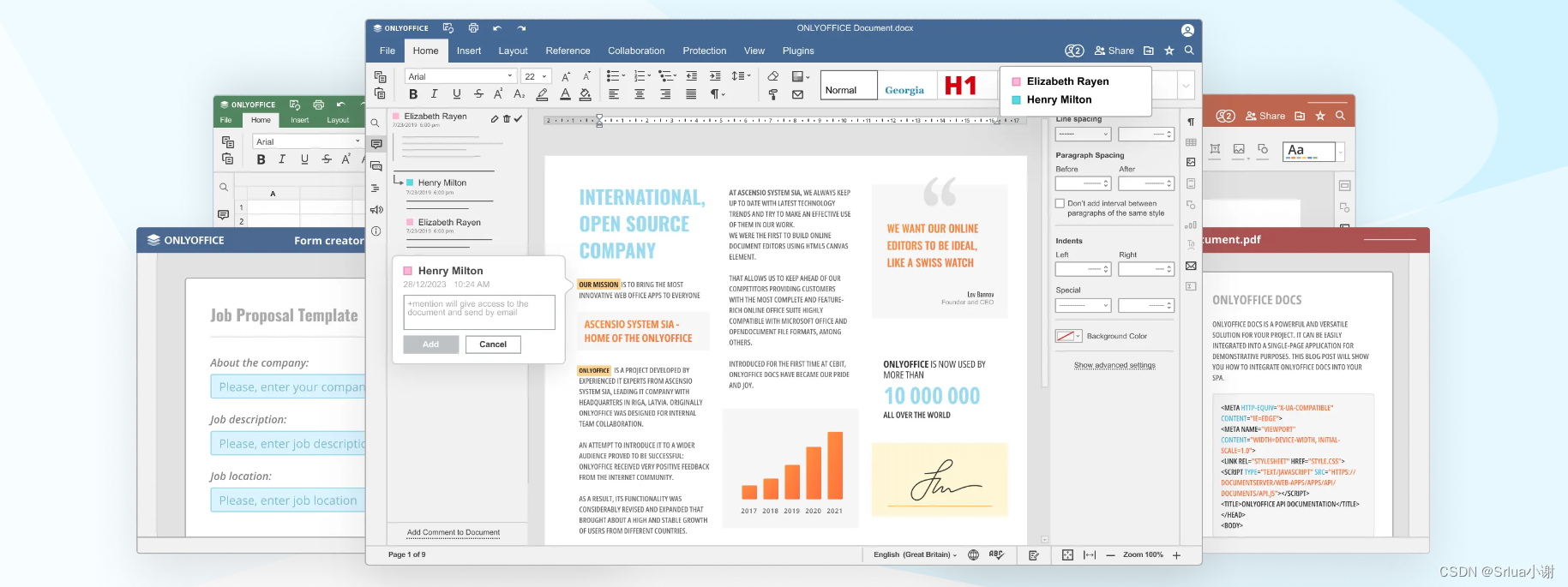
ONLYOFFICE 桌面编辑器 8.1 发布:全新 PDF 编辑器、幻灯片版式、增强 RTL 支持及更多本地化选项
目录 什么是ONLYOFFICE? ONLYOFFICE 主要特点包括: 官网信息: 1. 功能齐全的 PDF 编辑器 1.1 编辑 PDF 文本 1.2 插入和修改对象 1.3 创建和填写表单 2. 幻灯片版式功能 2.1 快速应用幻灯片版式 2.2 动画窗格的改进 3. 文档编辑、…...
)
Jetson AGX Orin到手后,第一件事不是装CUDA,而是先搞定这个源(附nvidia-l4t-apt-source.list配置)
Jetson AGX Orin开发板开箱必做:正确配置软件源的深度指南 当你第一次拿到Jetson AGX Orin这款强大的边缘计算设备时,兴奋之余可能会迫不及待地想要安装CUDA、cuDNN等AI开发环境。但很多开发者都会在这里踩到一个"坑"——直接运行sudo apt ins…...

基于MCP协议构建AI记忆管理服务:原理、实现与应用实践
1. 项目概述:一个为AI应用量身定制的记忆管理工具最近在折腾AI应用开发,特别是那些需要长期对话或上下文关联的场景时,一个绕不开的痛点就是“记忆”问题。模型本身是健忘的,每次对话都是全新的开始。为了让AI能记住用户偏好、历史…...

小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量 对于小型开发或产品团队而言,在项目开发中集成多个大语言…...

终极免费风扇控制软件:如何让你的电脑既安静又凉爽
终极免费风扇控制软件:如何让你的电脑既安静又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

如何快速解锁NCM加密音乐:NcmppGui完整使用指南
如何快速解锁NCM加密音乐:NcmppGui完整使用指南 【免费下载链接】ncmppGui 一个使用C编写的极速ncm转换GUI工具 项目地址: https://gitcode.com/gh_mirrors/nc/ncmppGui 你是否曾经下载了喜欢的音乐,却因为NCM格式的限制而无法在其他设备上播放&a…...

书匠策AI官网www.shujiangce.com|别再硬扛了!这个AI把写期刊论文变成了“填空题“
微信公众号搜一搜「书匠策AI」,三分钟治好你的论文拖延症! 各位还在深夜对着Word文档发呆的同学们,今天我不讲道理,只讲工具。 你们有没有想过一个问题:为什么写期刊论文这件事,让90%的人觉得痛苦…...

别再手动整理PDF了!用Zotero+坚果云打造你的免费文献同步工作流
Zotero与坚果云联动:构建无缝文献管理生态系统的终极指南 科研工作者和学生群体常面临一个普遍困境:如何在多台设备间高效同步和管理海量文献资料?传统的手动复制粘贴或依赖收费云服务不仅效率低下,还存在版本混乱的风险。本文将深…...

AISuperDomain:构建AI API智能网关,解决网络延迟与高可用难题
1. 项目概述与核心价值最近在折腾一些自动化脚本和本地化AI应用时,我遇到了一个挺普遍但又有点烦人的问题:如何让我的程序能稳定、高效地访问那些部署在境外的AI服务API,比如OpenAI、Claude或者一些开源的模型托管平台。直接调用?…...

FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程
FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程 当激光雷达在复杂环境中高速移动时,如何实现精准的实时定位与建图?FAST-LIO2通过创新的迭代误差状态卡尔曼滤波(IEKF)框架,将IMU预积分与激…...

当代酷刑:如厕等信号
如厕等信号,属于当代十大酷刑之一。作为社会观察理性分析的结合体,今天,我想写一些这物理世界的墙,也是这消费世界的墙。你有没有过这样的感受?不管你家里换了多么厉害的宽带,多么高端前沿的路由器…...