顺序表与链表学习笔记
顺序表及其结构定义
(1)结构定义
- 顺序存储:
- 顺序表的元素按顺序存储在一块连续的内存区域中,每个元素占用相同大小的存储空间。
- 通过数组实现,每个元素可以通过下标快速访问。
- 存储密度高:
- 因为顺序表使用连续的内存空间,所以其存储密度很高,没有额外的指针存储开销。
- 随机访问:
- 顺序表支持O(1)时间复杂度的随机访问,可以通过下标直接访问任意位置的元素。
- 访问时间复杂度:O(1)。
- 动态性:
- 顺序表通常预留一定的存储空间来处理动态增长,但在容量不足时需要扩展数组。
- 扩展数组时需要重新分配一块更大的连续内存,并将现有元素复制到新内存区域中。
- 插入和删除操作:
- 在顺序表的末尾进行插入和删除操作的时间复杂度为O(1)。
- 在顺序表的中间或开头进行插入和删除操作的时间复杂度为O(n),因为需要移动大量元素以保持连续存储。
- 空间浪费问题:
- 如果顺序表预留了过多的空间而未使用,会导致空间浪费。
- 如果预留的空间不足,需要频繁扩展数组,会导致性能下降。
顺序表代码实现
#include<stdio.h>
#include <stdlib.h>
#include <time.h>typedef struct vector {int size, count;int *data;
}vector;vector* getNewVector(int n) {vector *p = (vector *)malloc(sizeof(vector));p->size = n;p->count = 0;p->data = (int *)malloc(sizeof(int) * n);return p;
}int expand(vector *v) {if (v == NULL) return 0;printf("expand v from %d to %d\n", v->size, v->size * 2);int *p = (int *)realloc(v->data , sizeof(int) * v->size * 2);if (p == NULL) return 0;v->data = p;v->size *= 2;return 1;
}int insert(vector *v, int pos, int val) {if (pos < 0 || pos > v->count) return 0;if (v->size == v->count && !expand(v)) return 0;for (int i = v->count - 1; i >= pos; i--) {v->data[i + 1] = v->data[i];}v->data[pos] = val;v->count += 1;return 1;
}int erase(vector *v, int pos) {if (pos < 0 || pos >= v->count) return 0;for (int i = pos + 1; i < v->count; i++) {v->data[i - 1] = v->data[i];}v->count -= 1;return 1;
}void clear(vector *v) {if (v == NULL) return ;free(v->data);free(v);return ;
}void output_vector(vector *v) {int len = 0;for (int i = 0; i < v->size; i++) {len += printf("%3d", i);}printf("\n");for (int i = 0; i < len; i++) printf("-");printf("\n");for (int i = 0; i < v->count; i++) {printf("%3d", v->data[i]);}printf("\n\n\n");return ;
}int main() {srand(time(0));#define MAX_OP 20 vector *v = getNewVector(2);for (int i = 0; i < MAX_OP; i++) {int op = rand() % 4, pos, val, ret;switch (op) {case 0:case 1: case 2: {pos = rand() % (v->count + 2);val = rand() % 100;ret = insert(v, pos, val);printf("insert %d at %d to vector = %d\n", val, pos, ret);} break;case 3: {pos = rand() % (v->count + 2);ret = erase(v, pos);printf("erase item at %d in vector = %d\n", pos, ret);} break;}output_vector(v);}clear(v);return 0;
}链表及其结构定义
链表是一种灵活的线性数据结构,与数组(顺序表)相比具有许多不同的性质。以下是链表的主要结构性质:
-
动态内存分配
- 动态性:链表节点在需要时动态分配内存,不需要事先分配固定大小的内存空间。链表的大小可以在运行时根据需要动态增长或收缩。
- 内存利用率高:链表避免了数组可能出现的空间浪费问题,因为它只使用需要的内存。
-
节点结构
-
节点组成:链表由一系列节点组成,每个节点包含数据部分和指针部分。数据部分存储实际的数据,指针部分用于指向下一个节点(或前后节点)。
typedef struct Node {int data;struct Node *next; } Node;
-
-
顺序访问
- 线性访问:链表不支持随机访问,只能从头节点开始顺序访问每个节点。访问第n个节点的时间复杂度为O(n)。
- 指针操作:链表操作依赖于指针,需要进行频繁的指针操作(如指针的赋值和修改)。
-
插入和删除操作
- 高效操作:插入和删除操作在链表任意位置的时间复杂度为O(1),只需修改相关指针。不需要像数组那样移动大量数据,因此在处理动态数据时效率较高。
5. 指针操作
- 复杂性:链表的操作依赖于指针,需要进行频繁的指针操作(如指针的赋值和修改)。指针操作复杂度较高,容易出错。
- 额外空间:链表每个节点需要额外的指针空间,与数组相比,链表有一定的空间开销。
不同类型的链表特性
-
单向链表
-
单向链接:每个节点包含一个指向下一个节点的指针。
-
末尾节点:链表末尾的节点指针为NULL,表示链表的结束。
typedef struct Node {int data;struct Node *next; } Node;
-
-
双向链表
-
双向链接:每个节点包含一个指向下一个节点的指针和一个指向前一个节点的指针。
-
双向访问:可以从任意节点方便地访问其前驱节点和后继节点。
-
额外开销:每个节点需要额外的空间存储前驱节点的指针。
typedef struct DNode {int data;struct DNode *prev;struct DNode *next; } DNode;
-
-
循环链表
-
循环结构:循环链表的最后一个节点的指针指向头节点,形成一个环。
-
循环单向链表:最后一个节点的
next指向头节点。 -
循环双向链表:最后一个节点的
next指向头节点,头节点的prev指向最后一个节点。// 循环单向链表 typedef struct CNode {int data;struct CNode *next; } CNode;// 循环双向链表 typedef struct CDNode {int data;struct CDNode *prev;struct CDNode *next; } CDNode;
-
-
链表的应用场景
- 插入和删除频繁:链表适用于插入和删除操作频繁的场景,如实现栈、队列、符号表等。
- 内存管理:链表可以更好地管理内存,在需要频繁分配和释放内存的场景中表现优异。
-
链表的缺点
- 随机访问效率低:链表不支持高效的随机访问,只能顺序访问,访问效率较低。
- 指针开销:每个节点需要存储额外的指针信息,相对于数组,链表有一定的空间开销。
- 复杂性:链表的指针操作较为复杂,容易出错,调试困难。
单链表代码实现
#include<stdio.h>
#include<stdlib.h>
#include<time.h>typedef struct Node {int data;struct Node *next;
}Node;Node *getNewNode(int val) {Node *p = (Node *)malloc(sizeof(Node));p->data = val;p->next = NULL; return p;
}Node *insert(Node *head, int pos, int val) {Node new_head, *p = &new_head, *node = getNewNode(val);new_head.next = head;for (int i = 0; i < pos; i++) p = p->next;node->next = p->next;p->next = node;return new_head.next;
}void clear(Node *head) {if (head == NULL) return ;for (Node *p = head, *q; p; p = q) {q = p->next;free(p);}return ;
}void output_linlist(Node *head, int flag) {int n = 0; for (Node *p = head; p; p = p->next) n += 1;for (int i = 0; i < n; i++) {printf("%3d", i);printf(" ");}printf("\n");for (Node *p = head; p; p = p->next) {printf("%3d", p->data);printf("->");}printf("\n");if (flag == 0) printf("\n\n");return ;
}int find(Node *head, int val) {Node *p = head;int n = 0;while (p) {if (p->data == val) {output_linlist(head, 1);int len = 5 * n + 2;for (int i = 0; i < len; i++) printf(" ");printf("^\n");for (int i = 0; i < len; i++) printf(" ");printf("|\n");return 1;}n++;p = p->next;}return 0;
}int main() {srand(time(0));#define MAX_OP 10Node *head = NULL;for (int i = 0; i < MAX_OP; i++) {int pos = rand() % (i + 1), val = rand() % 100, ret;printf("insert %d at %d to linklist\n", val, pos);head = insert(head, pos, val);output_linlist(head, 0);}int val;while (~scanf("%d", &val)) {if (find(head, val) == 0) {printf("not found\n");}}clear(head);return 0;
}``
相关文章:

顺序表与链表学习笔记
顺序表及其结构定义 (1)结构定义 顺序存储: 顺序表的元素按顺序存储在一块连续的内存区域中,每个元素占用相同大小的存储空间。通过数组实现,每个元素可以通过下标快速访问。 存储密度高: 因为顺序表使用…...
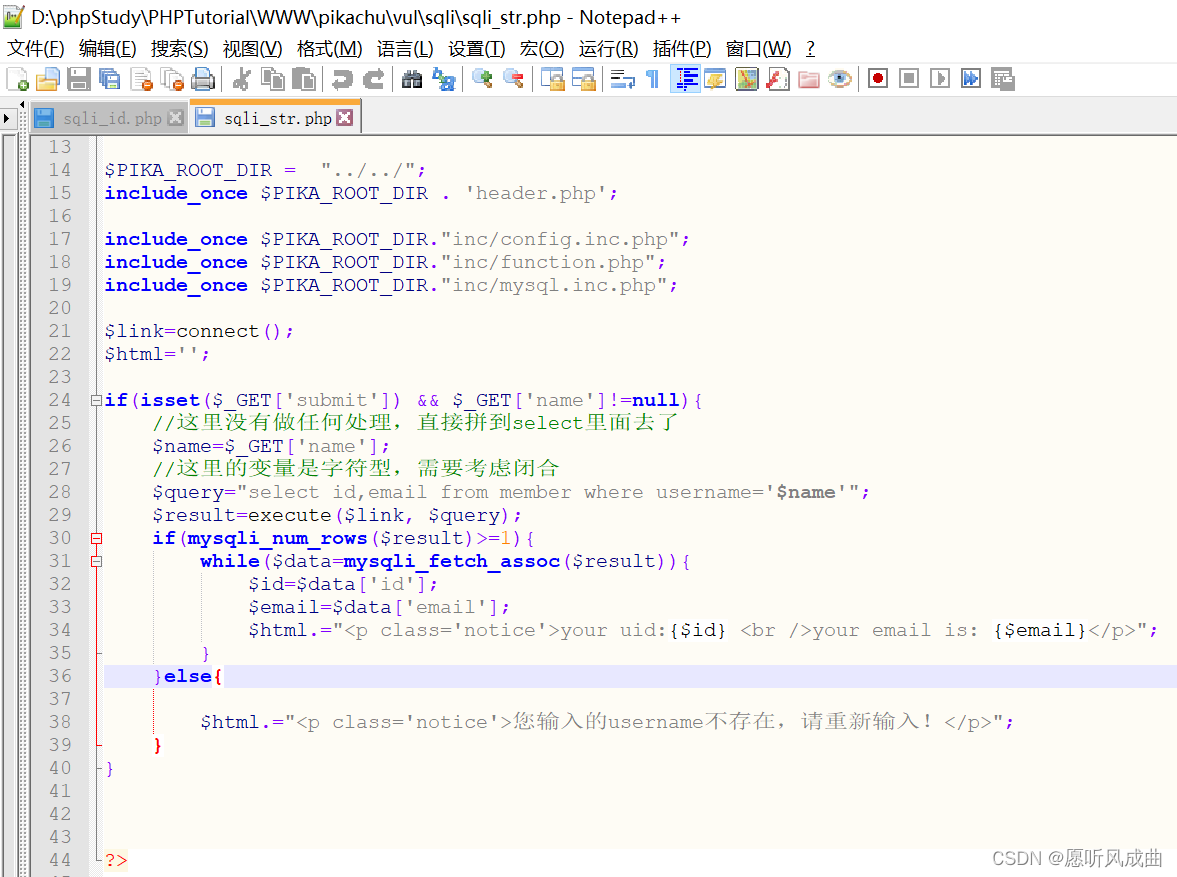
2.SQL注入-字符型
SQL注入-字符型(get) 输入kobe查询出现id和邮箱 猜测语句,字符在数据库中需要用到单引号或者双引号 select 字段1,字段2 from 表名 where usernamekobe;在数据库中查询对应的kobe,根据上图对应上。 select id,email from member where usernamekobe;编写payload语…...

在Ubuntu 14.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C++:inline关键字nullptr
inline关键字 C中inline使用关键点强调 (1)inline是一种“用于实现的关键字”,而不是一种“用于声明的关键字”,所以关键字 inline 必须与函数定义体放在一起,而不是和声明放在一起 (2)如果希望在多个c文件中使用,则inline函数应…...

数字信号处理实验三(IIR数字滤波器设计)
IIR数字滤波器设计(2学时) 要求: 产生一复合信号序列,该序列包含幅度相同的28Hz、50Hz、100Hz、150Hz的单音(单频)信号;其中,50Hz及其谐波为工频干扰(注:采样…...

Why is Kafka fast?(Kafka性能基石)
Kafka概述 Why is kafka fast? 思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast? 我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(through…...

Linux下的SSH详解及Ubuntu教程
前言 SSH(Secure Shell)是一种用于计算机之间安全通信的协议,广泛应用于远程登录、系统管理和文件传输等场景。本文将详细介绍SSH在Linux系统(特别是Ubuntu)下的使用,包括安装、配置、密钥管理和常见应用&…...
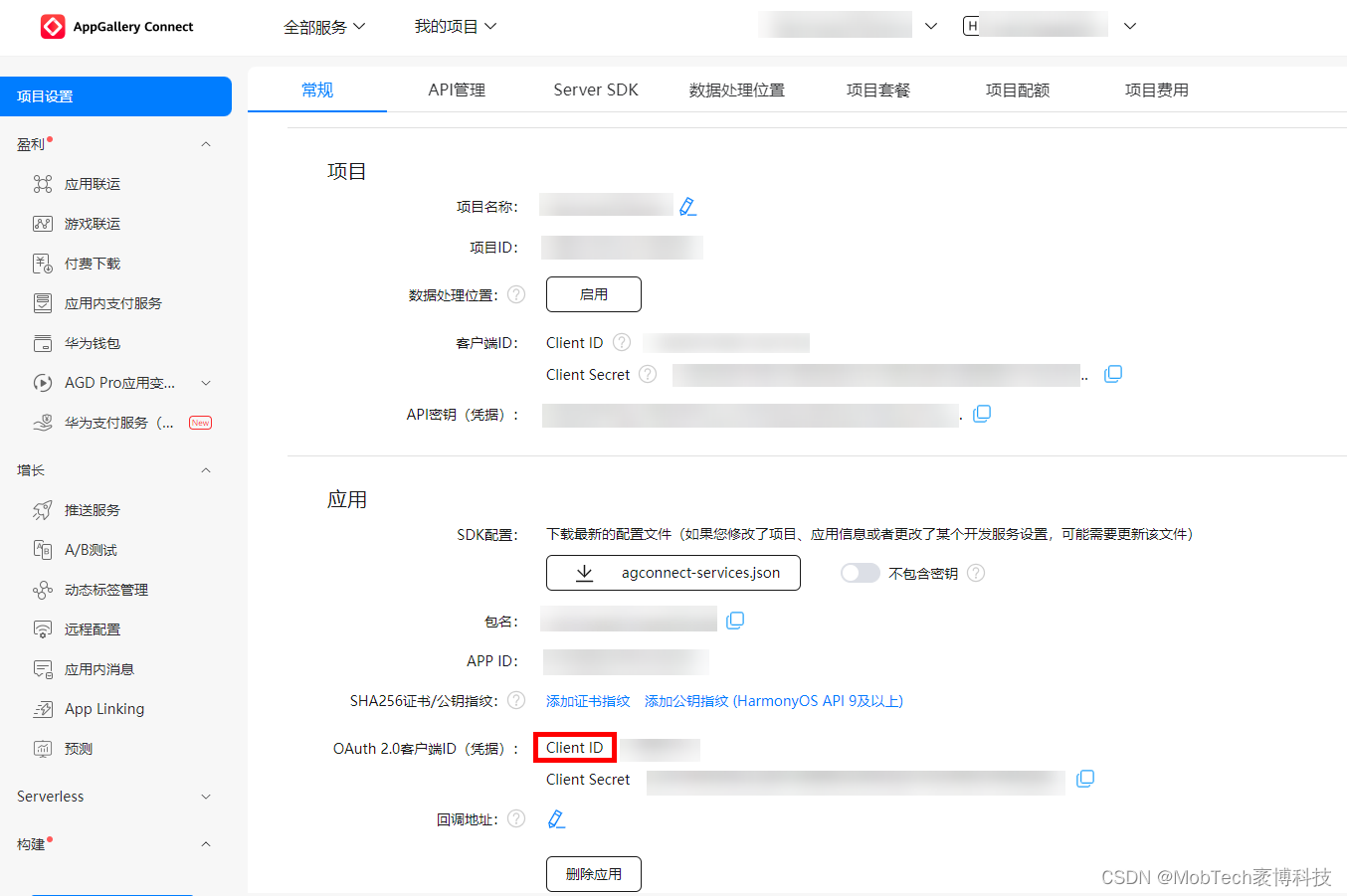
MobPush HarmonyOS NEXT 版本集成指南
开发工具:DevEco Studio 集成方式:在线集成 HarmonyOS API支持:> 11 集成前准备 注册账号 使用MobSDK之前,需要先在MobTech官网注册开发者账号,并获取MobTech提供的AppKey和AppSecret,详情可以点击查…...

什么是封装?为什么要封装?
什么是封装? 封装是计算机科学中的一个重要概念,尤其在面向对象编程(OOP)中占据核心地位。封装主要指的是将数据(属性)和对这些数据的操作(方法)组合在一个单元中(我们称…...
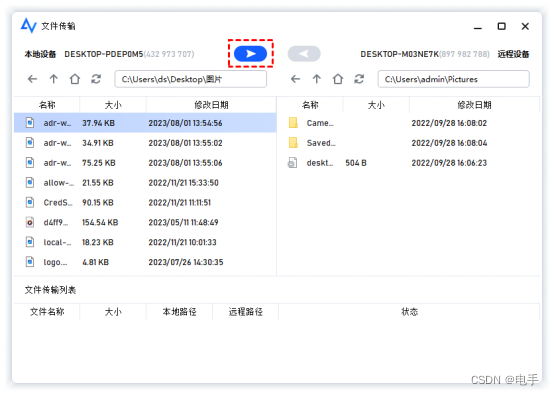
远程桌面无法复制粘贴文件到本地怎么办?
远程桌面不能复制粘贴问题 Windows远程桌面为我们提供了随时随地访问文件和数据的便捷途径,大大提升了工作和生活的效率。然而,在使用过程中,我们也可能遇到一些问题。例如,在通过远程桌面传输文件时,常常会出现无法复…...
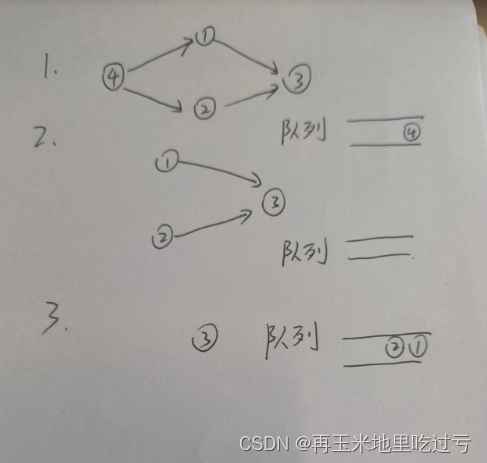
LeetCode 207. 课程表
思路:这是一道拓扑排序问题,拓扑排序听起来可能有点复杂,但实际上它是个相当直观的概念。想象一下,你有很多事情要做,但有些事情必须在另一些事情完成之后才能开始,就像你得先穿上袜子再穿鞋子 拓扑排序就…...
数据结构历年考研真题对应知识点(树的基本概念)
目录 5.1树的基本概念 5.1.2基本术语 【森林中树的数量、边数和结点数的关系(2016)】 5.1.3树的性质 【树中结点数和度数的关系的应用(2010、2016)】 【指定结点数的三叉树的最小高度分析(2022)】 5.1…...

Pytorch和Tensorflow安装【Win和Linux】
Ubuntu/win安装Pytorch和Tensorflow 说明: 这两种框架的搭建,均基于Anaconda进行搭建。先在系统中安装Anaconda软件。 一、Pytorch的搭建 windows安装 (1)搭建参考官网给的命令,pytorch官网 (2)下载地址:https://download.pytorch.org/whl/torch_stable.html 从上述…...

筑算网基石 创数智未来|锐捷网络闪耀2024 MWC上海
2024年6月26日至28日,全球科技界瞩目的GSMA世界移动大会(MWC 上海)在上海新国际博览中心(SNIEC)盛大召开。作为行业领先的网络解决方案提供商,锐捷网络以“筑算网基石 创数智未来”为主题,带来了…...

T4打卡 学习笔记
所用环境 ● 语言环境:Python3.11 ● 编译器:jupyter notebook ● 深度学习框架:TensorFlow2.16.1 ● 显卡(GPU):NVIDIA GeForce RTX 2070 设置GPU from tensorflow import keras from tensorflow.keras…...
抖音矩阵云混剪系统源码 短视频矩阵营销系统V2(全开源版)
>>>系统简述: 抖音阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复,多…...
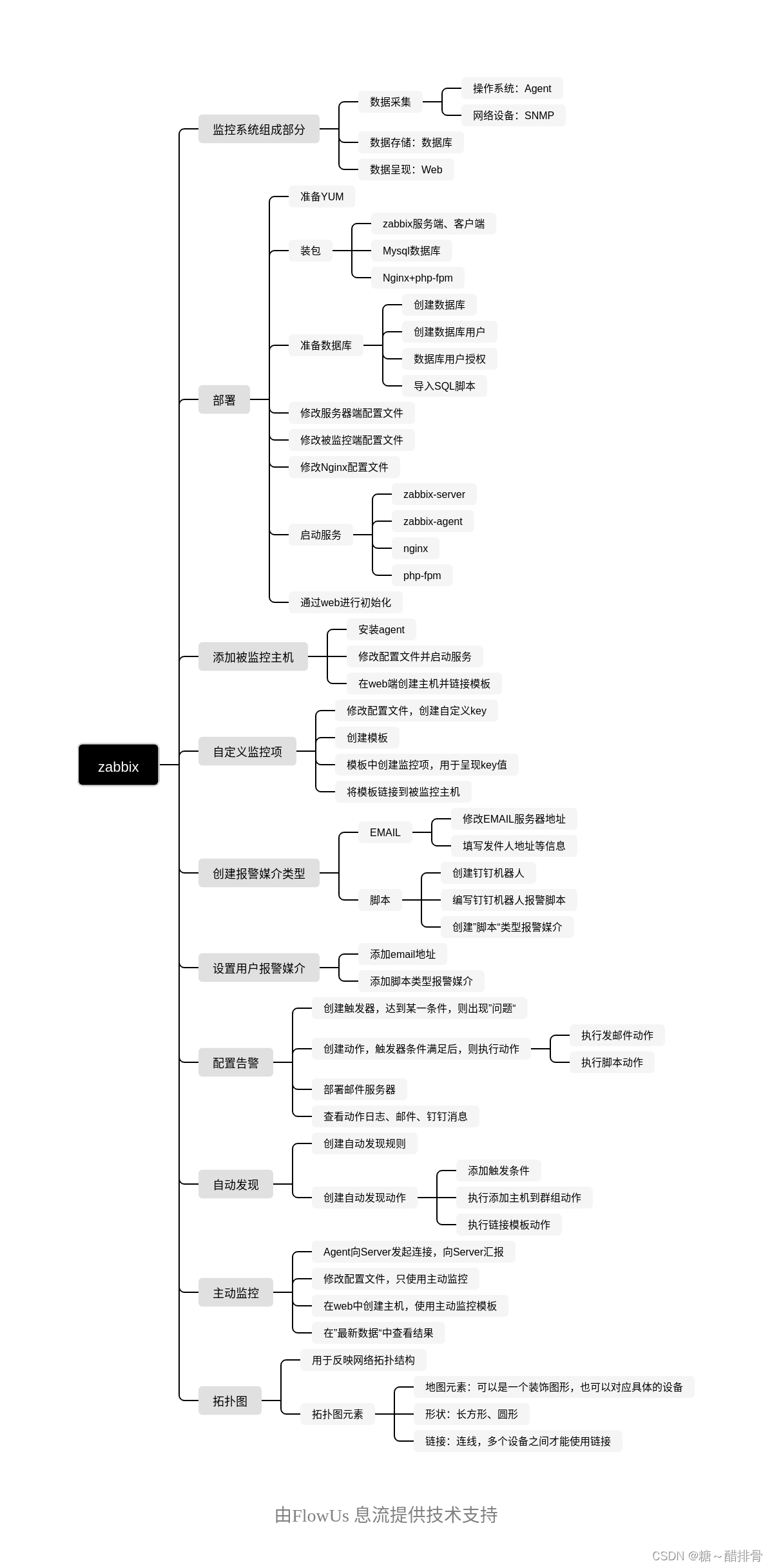
zabbix报警机制
zabbix思路流程...

【Matlab】-- 飞蛾扑火优化算法
文章目录 文章目录 01 飞蛾扑火算法介绍02 飞蛾扑火算法伪代码03 基于Matlab的部分飞蛾扑火MFO算法04 参考文献 01 飞蛾扑火算法介绍 飞蛾扑火算法(Moth-Flame Optimization,MFO)是一种基于自然界飞蛾行为的群体智能优化算法。该算法由 Sey…...

全面体验ONLYOFFICE 8.1版本桌面编辑器
ONLYOFFICE官网 在当今的数字化办公环境中,选择合适的文档处理工具对于提升工作效率和团队协作至关重要。ONLYOFFICE 8.1版本桌面编辑器,作为一款集成了多项先进功能的办公软件,为用户提供了全新的办公体验。今天,我们将深入探索…...

建议csdn赶紧将未经作者同意擅自锁住收费的文章全部解锁,别逼我用极端手段让你们就范
前两天我偶然发现csdn竟然将我以前发表的很多文章锁住向读者收费才让看。 csdn这种无耻行径往小了说是侵犯了作者的版权著作权,往大了说这是在打击我国IT领域未来的发展,因为每一个做过编程工作的人都知道,任何一个程序员的学习成长过程都少不…...

紧急预警:2024Q3起PlayAI将下线v2.1旧版翻译协议!迁移倒计时47天,5类遗留系统升级避坑手册
更多请点击: https://intelliparadigm.com 第一章:PlayAI多语种同步翻译功能详解 PlayAI 的多语种同步翻译功能基于端到端神经机器翻译(NMT)架构与实时语音流处理引擎深度融合,支持中、英、日、韩、法、西、德、俄等…...

3步轻松解锁Cursor Pro完整功能:免费使用AI编程助手的终极指南
3步轻松解锁Cursor Pro完整功能:免费使用AI编程助手的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

【omc】Claude Code 必备神器:Oh-My-ClaudeCode 让你的 AI 编程效率翻倍
用过 Claude Code 的人都知道,它很强。 但强归强,用起来有不少痛点:Token 烧得快、任务动不动崩溃、复杂项目搞不定。 Oh-My-ClaudeCode(OMC)就是来治这些病的。一、为什么需要 OMC? 原生 Claude Code 的三…...

基于OpenClaw构建AI智能体:从RAG到自动化工作流的实战指南
1. 项目概述:一个开源AI应用案例的“藏宝图”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫awesome-openclaw-usecases-zh。光看名字,就能拆解出几个关键信息:“awesome”系列(意味着是精选合集…...

如何用Mermaid CLI彻底改变技术文档工作流
如何用Mermaid CLI彻底改变技术文档工作流 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli 在技术文档编写过程中,图表创建往往是效率瓶颈。传统绘图工具需要手动拖拽、反…...

openclaw-route-check:多协议路由诊断工具的原理、安装与实战应用
1. 项目概述与核心价值最近在折腾一些需要跨地域、跨网络环境访问的服务时,路由问题总是最让人头疼的环节。你可能也遇到过类似情况:明明服务部署在A地,从B地访问时延迟高得离谱,或者干脆时通时不通,排查起来像大海捞针…...
)
中标麒麟OS访问Win10共享文件夹,手把手教你搞定SMB连接(附终端挂载命令)
中标麒麟OS与Win10共享文件夹互通实战指南 在国产化办公环境逐步普及的今天,中标麒麟OS作为主流国产操作系统之一,与Windows系统之间的文件共享成为日常办公刚需。本文将针对零基础用户,提供两种高效稳定的SMB共享连接方案:图形化…...

深度解析微信小程序逆向工程:wxappUnpacker技术揭秘与实战指南
深度解析微信小程序逆向工程:wxappUnpacker技术揭秘与实战指南 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序作为现代移动应用开发…...

基于ClamAV的容器化文件安全扫描服务:clambot架构与实战
1. 项目概述:一个守护文件安全的“哨兵” 如果你在服务器运维、文件共享系统或者邮件网关的岗位上工作过,那么对恶意文件、病毒、木马的防范一定是你日常工作的重中之重。手动检查?效率太低且容易遗漏。依赖单一杀毒软件?误报和性…...

从零上手Ranorex:录制、验证与参数化测试实战解析
1. Ranorex自动化测试入门指南 第一次接触Ranorex时,我和大多数测试工程师一样,被它强大的功能所震撼。作为一款专业的自动化测试工具,Ranorex能够显著提升测试效率,特别适合需要频繁回归测试的项目场景。记得我第一次用它完成计算…...