elasticsearch源码分析-03选举集群状态
选举集群状态
es中存储的数据有一下几种,state元数据、lucene索引文件、translog事务日志
元数据信息可以分为:
- 集群层面的元信息-对应着metaData数据结构,主要是clusterUUid、settings、templates等
- 索引层面的元信息-对应着indexMetaData数据结构,主要存储分片数量、mappings索引字段映射等
- 分片层面的元信息-对应着shardStateMetaData,主要是version、indexUUid、主分片等
每个节点可能会有不同的集群状态,需要选择正确的元数据作为权威源数据。状态信息的管理在gatewayService中,它实现了ClusterStateListener接口,当选择完主节点后会发布一个集群状态task,触发回调方法clusterChanged
//恢复分片分配状态
performStateRecovery(enforceRecoverAfterTime, reason);
集群层和索引层元数据恢复在gateway模块完成
public void clusterChanged(final ClusterChangedEvent event) {if (lifecycle.stoppedOrClosed()) {return;}final ClusterState state = event.state();//只有主节点才能执行if (state.nodes().isLocalNodeElectedMaster() == false) {// not our job to recoverreturn;}//已经执行过了集群状态和索引状态恢复了if (state.blocks().hasGlobalBlock(STATE_NOT_RECOVERED_BLOCK) == false) {// already recoveredreturn;}//这段省略主要是检查是否达到恢复状态条件......//恢复状态performStateRecovery(enforceRecoverAfterTime, reason);
}
首先判断只有主节点可以执行状态选举,然后判断是否已经在执行了状态恢复任务了,如果是则直接返回;如果没有则执行恢复状态任务
最终会调用recoveryRunnable.run()
final Gateway gateway = new Gateway(settings, clusterService, listGatewayMetaState);recoveryRunnable = () ->gateway.performStateRecovery(new GatewayRecoveryListener());
执行gateway的performStateRecovery方法
首先回去所有master资格的节点信息
//具有master资格的node节点final String[] nodesIds = clusterService.state().nodes().getMasterNodes().keys().toArray(String.class);
获取其他master节点的元数据
//获取集群及信息final TransportNodesListGatewayMetaState.NodesGatewayMetaState nodesState = listGatewayMetaState.list(nodesIds, null).actionGet();
这里我们看下TransportNodesListGatewayMetaState的构造函数
public TransportNodesListGatewayMetaState(ThreadPool threadPool, ClusterService clusterService, TransportService transportService,ActionFilters actionFilters, GatewayMetaState metaState) {super(ACTION_NAME, threadPool, clusterService, transportService, actionFilters,Request::new, NodeRequest::new, ThreadPool.Names.GENERIC, NodeGatewayMetaState.class);this.metaState = metaState;
}//注册action处理类
transportService.registerRequestHandler(actionName, executor, false, canTripCircuitBreaker, requestReader,new TransportHandler());
回到list方法,会调用doExecute方法
public ActionFuture<NodesGatewayMetaState> list(String[] nodesIds, @Nullable TimeValue timeout) {PlainActionFuture<NodesGatewayMetaState> future = PlainActionFuture.newFuture();execute(new Request(nodesIds).timeout(timeout), future);return future;
}protected void doExecute(Task task, NodesRequest request, ActionListener<NodesResponse> listener) {//执行new AsyncAction(task, request, listener).start();
}
发送所有节点获取元数据
void start() {final DiscoveryNode[] nodes = request.concreteNodes();if (nodes.length == 0) {//没有需要获取数据的node// nothing to notifythreadPool.generic().execute(() -> listener.onResponse(newResponse(request, responses)));return;}TransportRequestOptions.Builder builder = TransportRequestOptions.builder();if (request.timeout() != null) {builder.withTimeout(request.timeout());}//循环发送请求给所有节点for (int i = 0; i < nodes.length; i++) {final int idx = i;final DiscoveryNode node = nodes[i];final String nodeId = node.getId();try {TransportRequest nodeRequest = newNodeRequest(request);if (task != null) {nodeRequest.setParentTask(clusterService.localNode().getId(), task.getId());}//发送请求transportService.sendRequest(node, transportNodeAction, nodeRequest, builder.build(),new TransportResponseHandler<NodeResponse>() {@Overridepublic NodeResponse read(StreamInput in) throws IOException {return newNodeResponse(in);}//处理返回@Overridepublic void handleResponse(NodeResponse response) {onOperation(idx, response);}@Overridepublic void handleException(TransportException exp) {onFailure(idx, node.getId(), exp);}@Overridepublic String executor() {return ThreadPool.Names.SAME;}});} catch (Exception e) {onFailure(idx, nodeId, e);}}
}
对端接收请求后处理在上面注册的NodeTransportHandler,构造每个节点元数据返回
//node请求处理class NodeTransportHandler implements TransportRequestHandler<NodeRequest> {@Overridepublic void messageReceived(NodeRequest request, TransportChannel channel, Task task) throws Exception {channel.sendResponse(nodeOperation(request, task));}}protected NodeGatewayMetaState nodeOperation(NodeRequest request) {return new NodeGatewayMetaState(clusterService.localNode(), metaState.getMetadata());}
我们继续回到每个节点发送请求的返回处理
//处理返回
@Override
public void handleResponse(NodeResponse response) {onOperation(idx, response);
}private void onOperation(int idx, NodeResponse nodeResponse) {//记录node的返回结果responses.set(idx, nodeResponse);//当所有节点都返回结果了无论是失败还是成功了if (counter.incrementAndGet() == responses.length()) {finishHim();}
}private void finishHim() {NodesResponse finalResponse;try {finalResponse = newResponse(request, responses);} catch (Exception e) {logger.debug("failed to combine responses from nodes", e);listener.onFailure(e);return;}//触发监听回调listener.onResponse(finalResponse);
}
及获取到了其他节点的元数据,继续回到performStateRecovery
需要获取的master角色节点数
//需要分配数量
final int requiredAllocation = Math.max(1, minimumMasterNodes);
开始通过版本号选择集群层元数据,比较版本号,选择版本号最大的集群状态
//集群元数据
for (final TransportNodesListGatewayMetaState.NodeGatewayMetaState nodeState : nodesState.getNodes()) {if (nodeState.metadata() == null) {continue;}found++;if (electedGlobalState == null) {electedGlobalState = nodeState.metadata();//比较版本号大的胜出} else if (nodeState.metadata().version() > electedGlobalState.version()) {electedGlobalState = nodeState.metadata();}for (final ObjectCursor<IndexMetadata> cursor : nodeState.metadata().indices().values()) {indices.addTo(cursor.value.getIndex(), 1);}
}
检查是否有足够数量节点返回了集群状态
//没有获取足够的节点返回消息
if (found < requiredAllocation) {listener.onFailure("found [" + found + "] metadata states, required [" + requiredAllocation + "]");return;
}
构造集群状态,删除索引信息,下面会选择索引级元数据
//更新全局状态,清理索引,我们在下一阶段选择它们final Metadata.Builder metadataBuilder = Metadata.builder(electedGlobalState).removeAllIndices();
遍历所有节点选择返回的索引元数据版本最高的节点作为索引级元数据,然后将索引级元数据添加到metadataBuilder中
for (int i = 0; i < keys.length; i++) {if (keys[i] != null) {final Index index = (Index) keys[i];IndexMetadata electedIndexMetadata = null;int indexMetadataCount = 0;for (final TransportNodesListGatewayMetaState.NodeGatewayMetaState nodeState : nodesState.getNodes()) {if (nodeState.metadata() == null) {continue;}final IndexMetadata indexMetadata = nodeState.metadata().index(index);if (indexMetadata == null) {continue;}if (electedIndexMetadata == null) {electedIndexMetadata = indexMetadata;//比较版本号,选择最大版本号} else if (indexMetadata.getVersion() > electedIndexMetadata.getVersion()) {electedIndexMetadata = indexMetadata;}indexMetadataCount++;}if (electedIndexMetadata != null) {if (indexMetadataCount < requiredAllocation) {logger.debug("[{}] found [{}], required [{}], not adding", index, indexMetadataCount, requiredAllocation);} // TODO if this logging statement is correct then we are missing an else here//设置索引级元数据metadataBuilder.put(electedIndexMetadata, false);}}
}
构造恢复后的集群级元数据和索引级元数据
//恢复后的集群状态
ClusterState recoveredState = Function.<ClusterState>identity().andThen(state -> ClusterStateUpdaters.upgradeAndArchiveUnknownOrInvalidSettings(state, clusterService.getClusterSettings())).apply(ClusterState.builder(clusterService.getClusterName()).metadata(metadataBuilder).build());listener.onSuccess(recoveredState);
调用GatewayRecoveryListener的onSuccess向集群提交任务
class GatewayRecoveryListener implements Gateway.GatewayStateRecoveredListener {@Overridepublic void onSuccess(final ClusterState recoveredState) {logger.trace("successful state recovery, importing cluster state...");clusterService.submitStateUpdateTask("local-gateway-elected-state",new RecoverStateUpdateTask() {@Overridepublic ClusterState execute(final ClusterState currentState) {final ClusterState updatedState = ClusterStateUpdaters.mixCurrentStateAndRecoveredState(currentState, recoveredState);return super.execute(ClusterStateUpdaters.recoverClusterBlocks(updatedState));}});}@Overridepublic void onFailure(final String msg) {logger.info("state recovery failed: {}", msg);resetRecoveredFlags();}}
调用RecoverStateUpdateTask的execute方法
@Override
public ClusterState execute(final ClusterState currentState) {if (currentState.blocks().hasGlobalBlock(STATE_NOT_RECOVERED_BLOCK) == false) {logger.debug("cluster is already recovered");return currentState;}//状态信息恢复完成final ClusterState newState = Function.<ClusterState>identity().andThen(ClusterStateUpdaters::updateRoutingTable).andThen(ClusterStateUpdaters::removeStateNotRecoveredBlock).apply(currentState);//开始分配分片return allocationService.reroute(newState, "state recovered");
}
集群元数据和索引级元数据恢复完成开始分配分片
- 元数据的持久化
具有master资格的节点和数据节点可以持久化集群状态,当接收到集群状态变更时会将其持久化到磁盘GatewayClusterApplier实现了ClusterStateApplier,当集群状态变更时会调用applyClusterState方法
@Override
public void applyClusterState(ClusterChangedEvent event) {if (event.state().blocks().disableStatePersistence()) {incrementalClusterStateWriter.setIncrementalWrite(false);return;}try {// Hack: This is to ensure that non-master-eligible Zen2 nodes always store a current term// that's higher than the last accepted term.// TODO: can we get rid of this hack?if (event.state().term() > incrementalClusterStateWriter.getPreviousManifest().getCurrentTerm()) {incrementalClusterStateWriter.setCurrentTerm(event.state().term());}//更新磁盘上的元数据incrementalClusterStateWriter.updateClusterState(event.state());incrementalClusterStateWriter.setIncrementalWrite(true);} catch (WriteStateException e) {logger.warn("Exception occurred when storing new meta data", e);}
}
将集群级元数据和索引级元数据落盘
void updateClusterState(ClusterState newState) throws WriteStateException {//元数据Metadata newMetadata = newState.metadata();final long startTimeMillis = relativeTimeMillisSupplier.getAsLong();final AtomicClusterStateWriter writer = new AtomicClusterStateWriter(metaStateService, previousManifest);//全局元数据long globalStateGeneration = writeGlobalState(writer, newMetadata);//索引级元数据Map<Index, Long> indexGenerations = writeIndicesMetadata(writer, newState);Manifest manifest = new Manifest(previousManifest.getCurrentTerm(), newState.version(), globalStateGeneration, indexGenerations);writeManifest(writer, manifest);previousManifest = manifest;previousClusterState = newState;final long durationMillis = relativeTimeMillisSupplier.getAsLong() - startTimeMillis;final TimeValue finalSlowWriteLoggingThreshold = this.slowWriteLoggingThreshold;if (durationMillis >= finalSlowWriteLoggingThreshold.getMillis()) {logger.warn("writing cluster state took [{}ms] which is above the warn threshold of [{}]; " +"wrote metadata for [{}] indices and skipped [{}] unchanged indices",durationMillis, finalSlowWriteLoggingThreshold, writer.getIndicesWritten(), writer.getIndicesSkipped());} else {logger.debug("writing cluster state took [{}ms]; wrote metadata for [{}] indices and skipped [{}] unchanged indices",durationMillis, writer.getIndicesWritten(), writer.getIndicesSkipped());}
}
- 加载磁盘元数据
在node实例的start方法中会调用gatewayMetaState.start方法
//集群元数据
final GatewayMetaState gatewayMetaState = injector.getInstance(GatewayMetaState.class);
gatewayMetaState.start(settings(), transportService, clusterService, injector.getInstance(MetaStateService.class),injector.getInstance(MetadataIndexUpgradeService.class), injector.getInstance(MetadataUpgrader.class),injector.getInstance(PersistedClusterStateService.class));
然后会调用loadFullState方法
//加载元数据
manifestClusterStateTuple = metaStateService.loadFullState();public Tuple<Manifest, Metadata> loadFullState() throws IOException {//加载最新的状态文件final Manifest manifest = MANIFEST_FORMAT.loadLatestState(logger, namedXContentRegistry, nodeEnv.nodeDataPaths());if (manifest == null) {return loadFullStateBWC();}//构建元数据final Metadata.Builder metadataBuilder;if (manifest.isGlobalGenerationMissing()) {metadataBuilder = Metadata.builder();} else {final Metadata globalMetadata = METADATA_FORMAT.loadGeneration(logger, namedXContentRegistry, manifest.getGlobalGeneration(),nodeEnv.nodeDataPaths());if (globalMetadata != null) {metadataBuilder = Metadata.builder(globalMetadata);} else {throw new IOException("failed to find global metadata [generation: " + manifest.getGlobalGeneration() + "]");}}//索引级元数据for (Map.Entry<Index, Long> entry : manifest.getIndexGenerations().entrySet()) {final Index index = entry.getKey();final long generation = entry.getValue();final String indexFolderName = index.getUUID();final IndexMetadata indexMetadata = INDEX_METADATA_FORMAT.loadGeneration(logger, namedXContentRegistry, generation,nodeEnv.resolveIndexFolder(indexFolderName));if (indexMetadata != null) {metadataBuilder.put(indexMetadata, false);} else {throw new IOException("failed to find metadata for existing index " + index.getName() + " [location: " + indexFolderName +", generation: " + generation + "]");}}return new Tuple<>(manifest, metadataBuilder.build());
}
从磁盘读取构建索引级元数据和集群级元数据,用于构建集群状态对象ClusterState
相关文章:

elasticsearch源码分析-03选举集群状态
选举集群状态 es中存储的数据有一下几种,state元数据、lucene索引文件、translog事务日志 元数据信息可以分为: 集群层面的元信息-对应着metaData数据结构,主要是clusterUUid、settings、templates等索引层面的元信息-对应着indexMetaData数…...

MySQL 重要参数优化
max_connections = 3000 innodb_buffer_pool_size = 8G max_allowed_packet = 32M innodb_file_io_threads = 8 innodb_thread_concurrency = 16 innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 16M 参数说明 max_connections = 3000 运行MySQL的最大连…...
软件测试之接口测试(Postman/Jmeter)
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是接口测试 通常做的接口测试指的是系统对外的接口,比如你需要从别的系统来…...
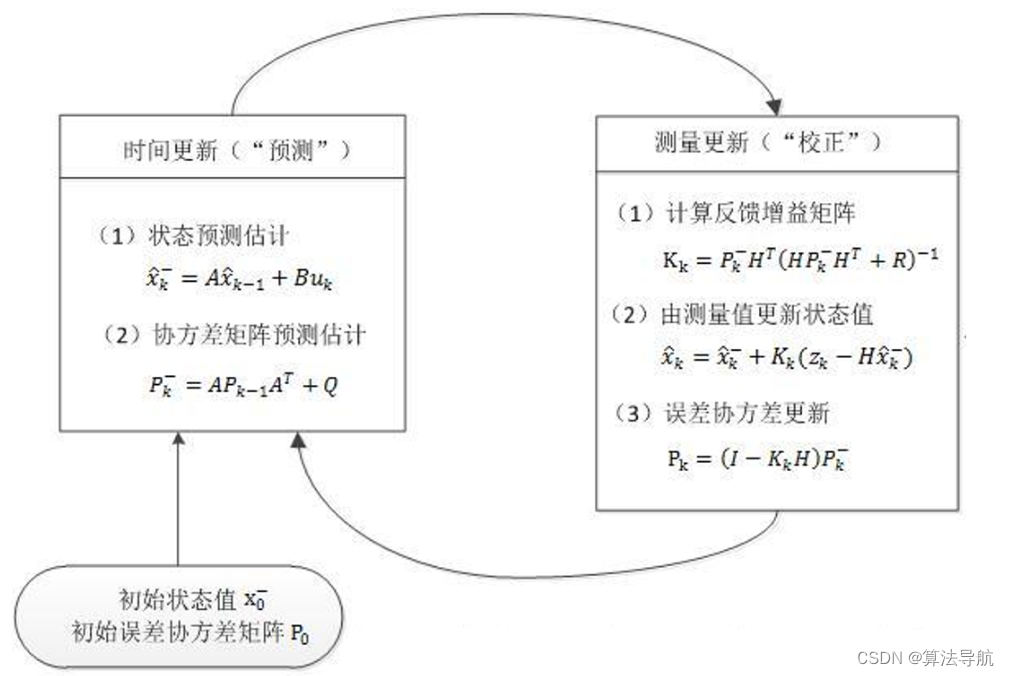
14 卡尔曼滤波及代码实现
文章目录 14 卡尔曼滤波及代码实现14.0 基本概念14.1 公式推导14.2 代码实现 14 卡尔曼滤波及代码实现 14.0 基本概念 卡尔曼滤波是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据包括系统中的噪声和…...
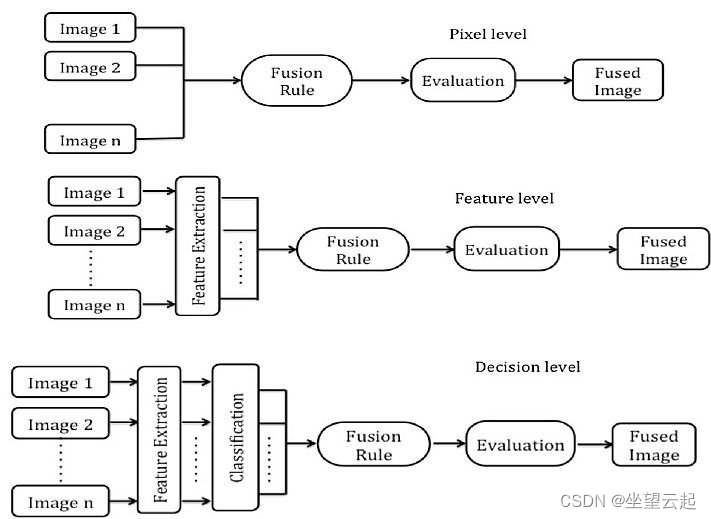
计算机视觉 图像融合技术概览
在许多计算机视觉应用中(例如机器人运动和医学成像),需要将来自多幅图像的相关信息集成到一幅图像中。这种图像融合将提供更高的可靠性、准确性和数据质量。 多视图融合可以提高图像的分辨率,同时恢复场景的 3D 表示。多模态融合结合了来自不同传感器的图像,称为多传感器融…...
计算机网络课程实训:局域网方案设计与实现(基于ensp)
文章目录 前言基本要求操作分公司1分公司2总部核心交换机配置实现内部服务器的搭建acl_deny部分用户与服务器出口出口防火墙配置 前言 本篇文章是小编实训部分内容,内容可能会有错误,另外ensp对电脑兼容性及其挑剔,在使用之前一定要安装好。…...
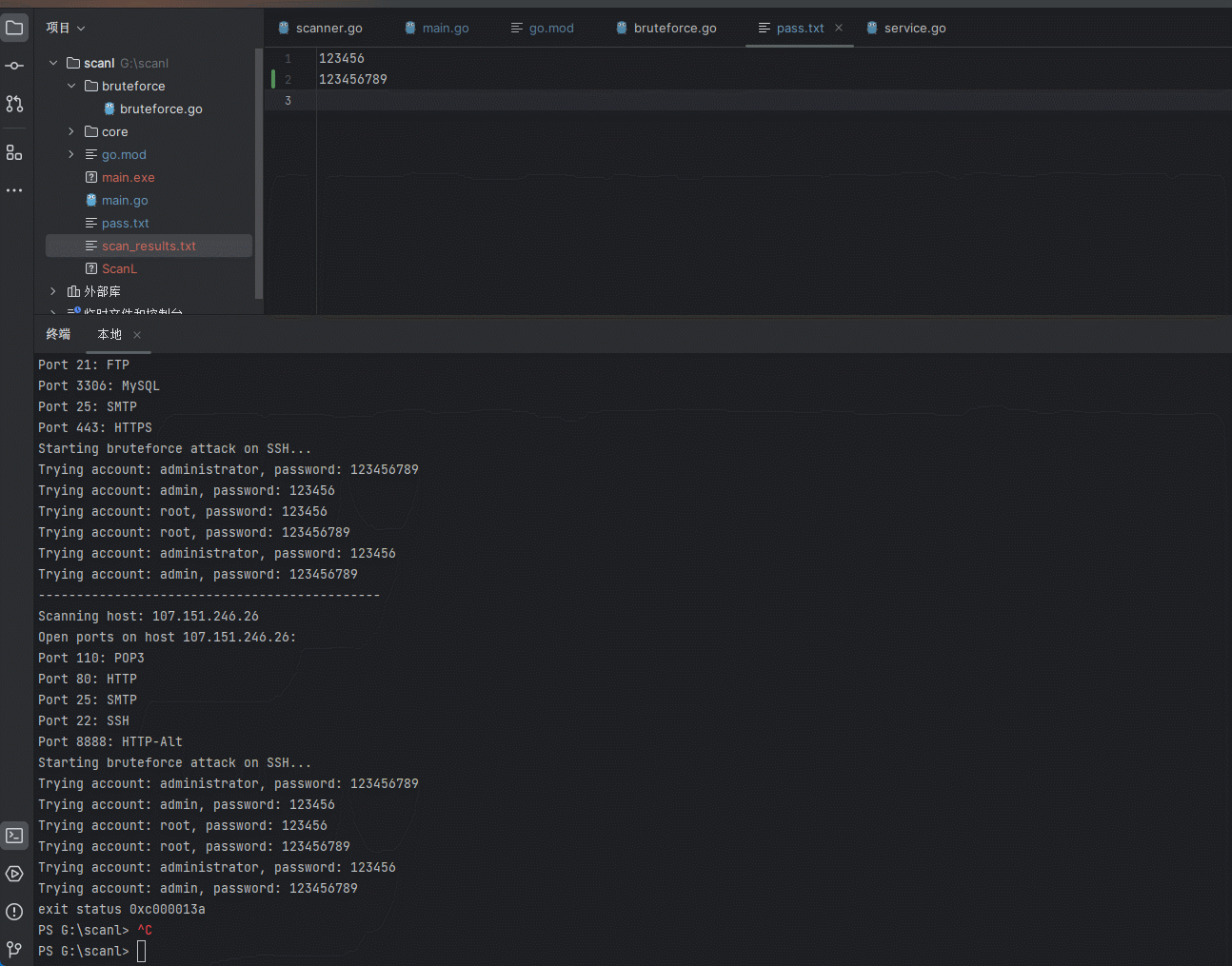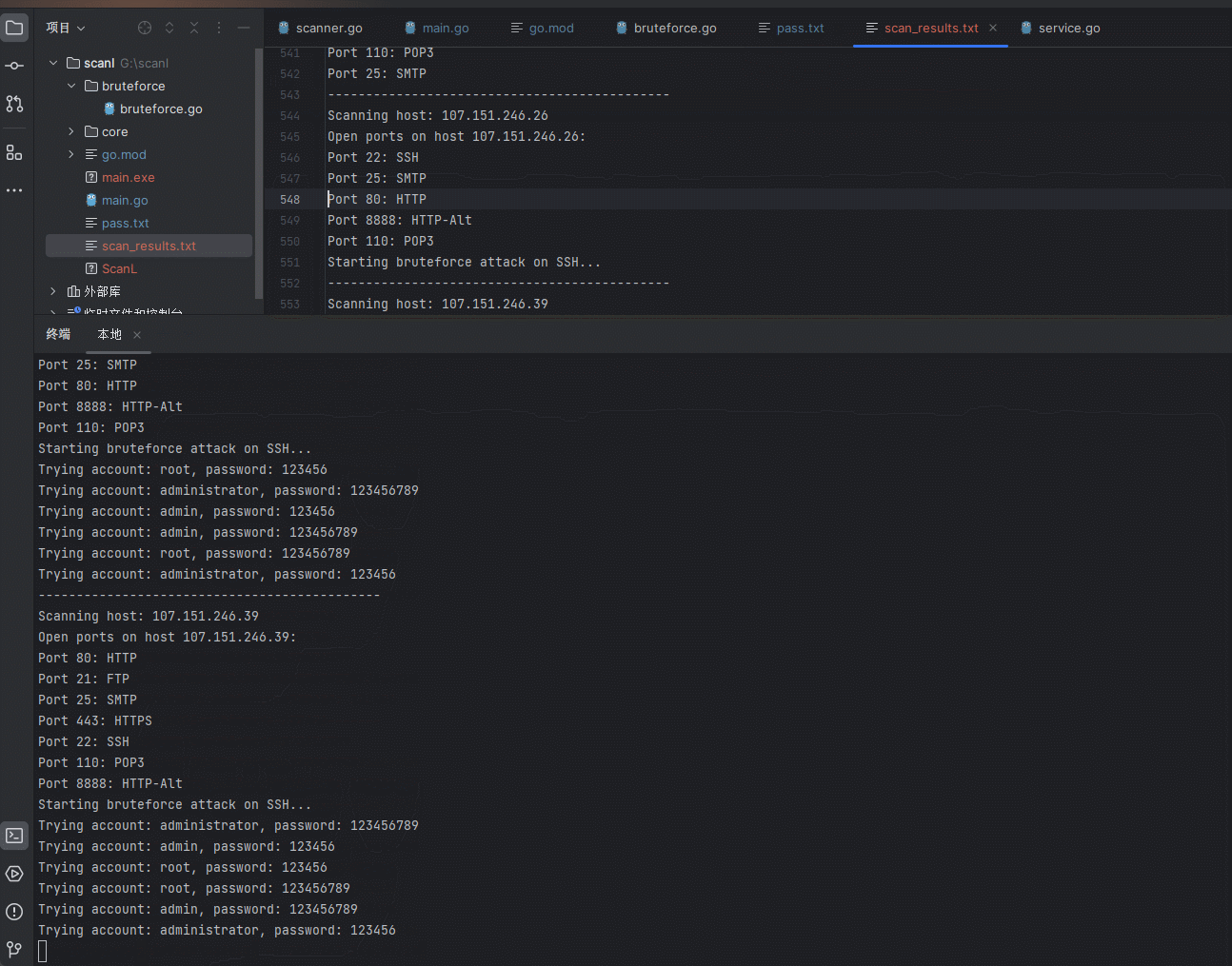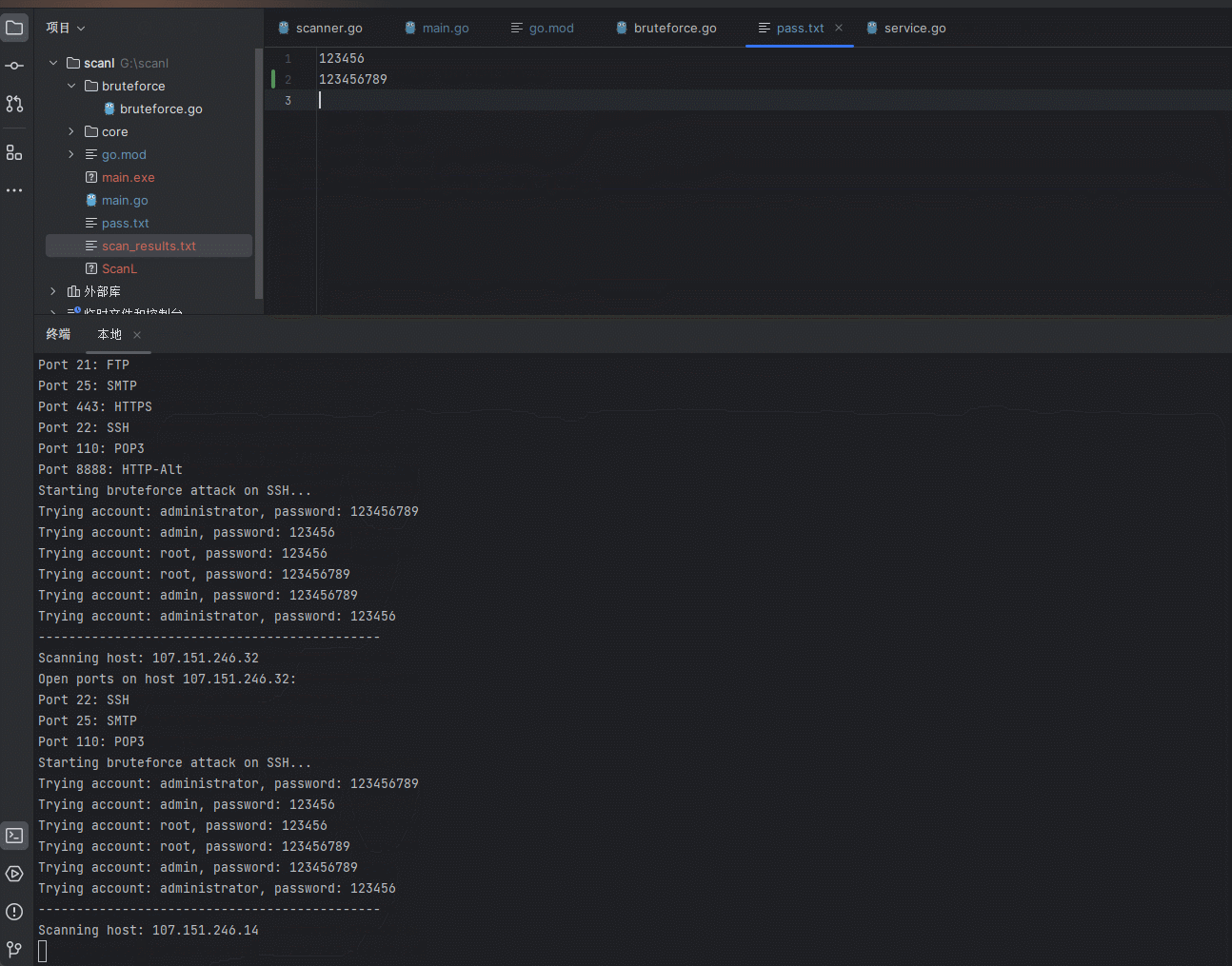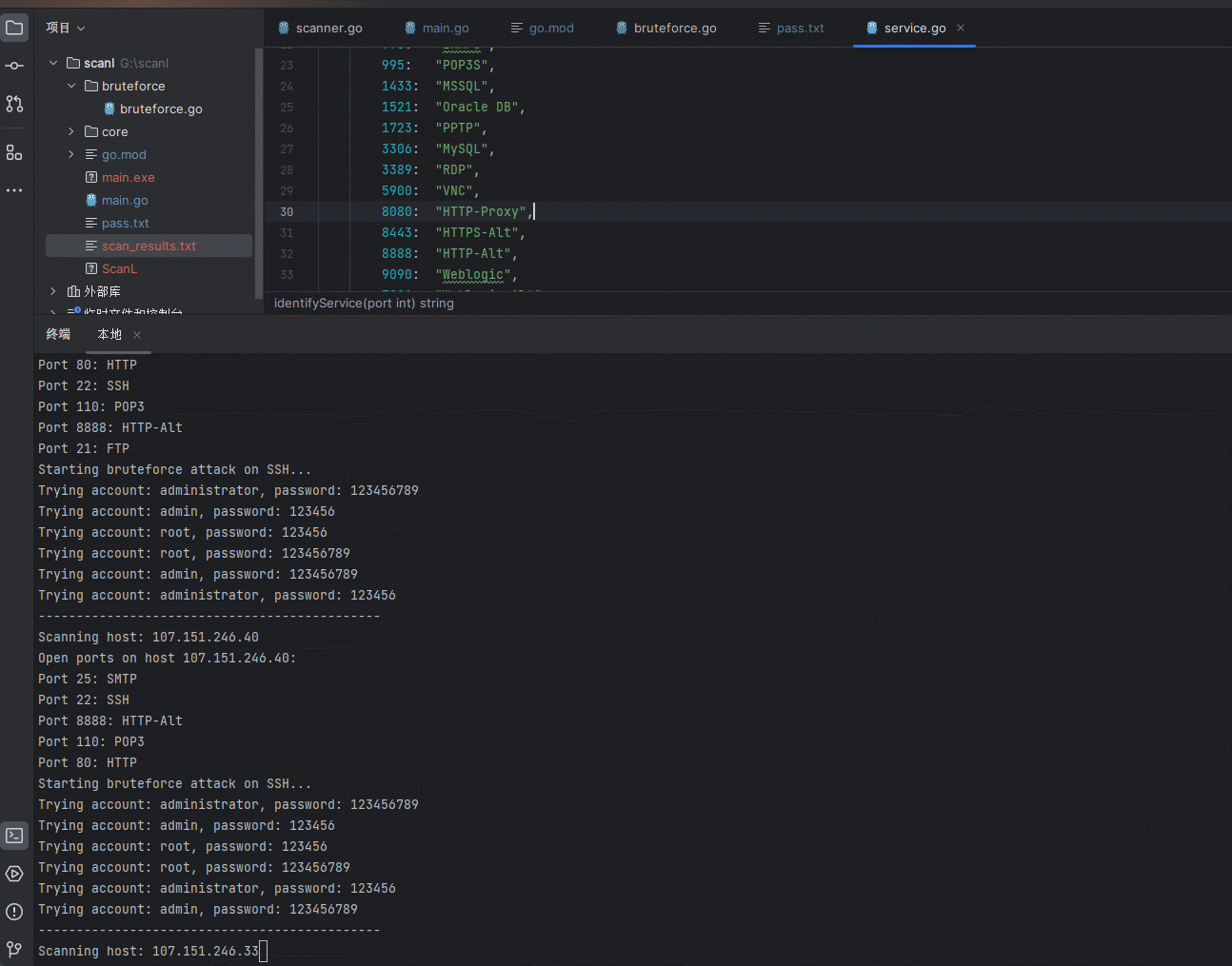
【安全开发】内网扫描器
文章目录 前言现实现的功能较少后序开发会逐步加入简单漏洞探探测和代理功能。 一、开发过程1.项目结构2.main.go3.core模块3.1 scanner.go3.2 service.go 4.bruteforc4.1 bruteforce.go 二、使用步骤 前言 为什么要写这个? fscna被杀的概率太高(哪天二…...
)
ESP32-C3模组上跑通MQTT(5)
接前一篇文章:ESP32-C3模组上跑通MQTT(4) 本文内容参考: 《ESP32-C3 物联网工程开发实战》 一分钟了解MQTT协议 ESP32 MQTT API指南-CSDN博客 ESP-IDF MQTT 示例入门_mqtt outbox-CSDN博客 ESP32用自签CA进行MQTT的TLS双向认证通信_esp32 mqtt ssl-CSDN博客 特此致谢!…...
Arduino - LED 矩阵
Arduino - LED 矩阵 Arduino - LED Matrix LED matrix display, also known as LED display, or dot matrix display, are wide-used. In this tutorial, we are going to learn: LED矩阵显示器,也称为LED显示器,或点阵显示器,应用广泛。在…...
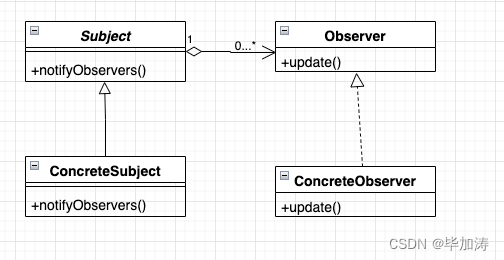
设计模式 - Observer Pattern 观察者模式
文章目录 定义观察者模式的实现构成构成UML图 观察者模式的代码实现场景代码实现 总结优点缺点应用场景 其他设计模式文章: 定义 观察者模式是行为型模式的一种,它定义对象间的一种一对多的依赖关系,使得每当一个对象改变状态,它…...

【面试系列】C++ 高频面试题
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

程序猿大战Python——实现简单的图书馆系统操作
步骤1:安装和导入库 首先,确保已经安装了 pymysql 库。如果没有安装,请执行以下命令: pip install pymysql 然后,导入必要的库: import pymysql 步骤2:创建数据库和表的函数 编写一个函数来…...

液体粒子计数器的原理及常见型号选择 lighthouse代理商北京中邦兴业
液体颗粒计数用于测量液体样品中颗粒的大小和分布。通过用激光二极管照射液体样品并检测散射光来测量颗粒分布和尺寸。散射光的性质与粒子大小的大小有关。液体颗粒计数器可用于批量取样或在线(连续监测)应用,如水处理厂,或用于…...

Java知识点整理 16 — Spring Bean
在之前的文章 Java知识点整理 8 — Spring 简介 中介绍了 Spring 的两大核心概念 IoC 和 AOP,但对 Spring Bean 的介绍不全面,本文将补充 Spring 中 Bean 的概念。 一. 什么是 Spring Bean 在 Spring 官方文档中,对 bean 的定义为…...

Nvidia Jetson/RK3588+AI双目立体相机,适合各种割草机器人、扫地机器人、AGV等应用
双目立体视觉是基于视差原理,依据成像设备从不同位置获取的被测物体的图像,匹配对应点的位置偏移,得到视差数据,进而计算物体的空间三维信息。为您带来高图像质量的双目立体相机,具有高分辨率、低功耗、远距离等优点&a…...

springboot使用feign调用不依赖cloud
在使用spring boot调用第三方api中,常用的是okhttp、apache http client等,但是直接使用下来还是有点繁琐,需要手动转换实体。 在springcloud中有个openfeign调用,第一次体验到调用接口还能这么丝滑。注解写道接口上,…...
springboot中使用springboot cache
前言:SpringBoot中使用Cache缓存可以提高对缓存的开发效率 此图片是SpringBootCache常用注解 Springboot Cache中常用注解 第一步:引入依赖 <!--缓存--><dependency><groupId>org.springframework.boot</groupId><artifactId…...

Promise,async/await的运用
一,了解Promise Promise是异步编程的一种解决方案,它是一个对象,可以获取异步操作的消息,它的出现避免了地狱回调。 (1)Promise的实例有三个状态: Pending(进行中) Re…...

图论·多源最短路径Floyddijsktra
例题地址 多源最短路径 多个源点多个终点可以使用Floyd算法直接求各源点到终点的最短距离,也可以直接多次使用dijsktra算法求单源点到终点的最短距离 Floyd算法 使用条件 多源最短路径权值正负皆可 核心思想:动态规划 子问题: 设(A,B)…...
微服务 | Springboot整合GateWay+Nacos实现动态路由
1、简介 路由转发 执行过滤器链。 网关,旨在为微服务架构提供一种简单有效的统一的API路由管理方式。同时,基于Filter链的方式提供了网关的基本功能,比如:鉴权、流量控制、熔断、路径重写、黑白名单、日志监控等。 基本功能…...
)
保姆级教程:在HCL模拟器上给H3C路由器配置DHCP服务器(双网段实战)
从零构建H3C路由器双网段DHCP服务:模拟器实战与协议解析 在虚拟实验室中搭建网络环境已成为现代工程师的必备技能,而DHCP服务作为网络自动化的基石,其配置过程往往成为初学者接触企业级设备的第一个实战挑战。本文将使用H3C官方推出的HCL模拟…...

Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列创意软件
Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列创意软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud用…...

RISC-V双发射混合运算优化技术COPIFT解析
1. RISC-V双发射混合运算优化技术概述在当今处理器架构设计中,能效比已经超越单纯性能指标成为首要考量因素。RISC-V作为开源指令集架构,凭借其模块化设计和可扩展性,为能效优化提供了独特优势。双发射(Dual-Issue)技术通过每个时钟周期发射两…...

半导体光刻OPC技术:稀疏模型到网格模型的转换实践
1. 光学邻近效应校正(OPC)技术演进背景在半导体制造的光刻工艺中,光学邻近效应校正(Optical Proximity Correction, OPC)是一项至关重要的分辨率增强技术。随着制程节点不断微缩至65nm以下,传统的光学模型面…...

Laravel-admin图表组件终极指南:从零实现ECharts与Chart.js数据可视化
Laravel-admin图表组件终极指南:从零实现ECharts与Chart.js数据可视化 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin Laravel-admin作为一款高…...

避坑指南:香橙派串口开发中orangepiEnv.txt与armbianEnv.txt的配置差异详解
香橙派串口开发实战:系统配置差异与深度调试指南 当你在深夜调试香橙派串口时,突然发现修改的配置文件毫无反应——这种经历相信不少开发者都遇到过。问题的根源往往不在于代码本身,而是隐藏在系统环境中的配置差异。本文将带你深入剖析香橙派…...

2026年,你的企业为什么还不会用AI发稿?技术人深度拆解Infoseek媒体库
最近GitHub上又一个开源项目火了,能自动生成并发布技术博客。这让我想到,在我们讨论AI取代程序员的同时,另一个领域的“自动化”早已跑在了前面——企业的媒体内容发布。很多技术团队还在手动找渠道、求小编,而一些市场部同事&…...

Canvas动画实战:从零构建动态星空效果与性能优化
1. 项目概述:从静态到动态的视觉魔法“Animated_star”这个项目名,听起来就充满了趣味和想象力。它不是一个复杂的商业应用,也不是一个深奥的算法研究,而是一个纯粹关于“视觉创造”的实践。简单来说,这个项目的核心目…...

从航拍云台到机器人关节:手把手教你用STM32F103和MPU6050实现二自由度姿态稳定
从零打造二自由度姿态稳定系统:STM32F103与MPU6050实战指南 1. 项目背景与核心需求 在无人机航拍、机器人关节控制等领域,姿态稳定系统扮演着关键角色。想象一下,当你用自制无人机拍摄视频时,画面总是晃动不稳;或者机器…...

智能体开发爆发期!程序员现在转型,还能赶上红利吗?
文章目录 前言一、为什么2026年是智能体开发的爆发元年?1.1 市场数据说话:万亿级赛道正在加速形成1.2 企业需求爆发:从"要不要做"到"怎么做"1.3 薪资差距拉大:同样3年经验,薪资差一倍 二、90%程序…...