昇思25天学习打卡营第6天|简单的深度学习模型实战 - 函数式自动微分
自动微分(Automatic Differentiation)是什么?微分是函数在某一处的导数值,自动微分就是使用计算机程序自动求解函数在某一处的导数值。自动微分可用于计算神经网络反向传播的梯度大小,是机器学习训练中不可或缺的一步。
这些公式难免让人头大,好在自动微分就是帮助我们“自动”解决微分问题的。机器学习平台如TensorFlow、PyTorch都实现了自动微分,使用非常的方便,不过有必要理解其原理。要理解“自动微分”,需要先理解常见的求解微分的方式,可分为以下四种:
- 手动求解法(Manual Differentiation)
- 数值微分法(Numerical Differentiation)
- 符号微分法(Symbolic Differentiation)
- 自动微分法(Automatic Differentiation)
所谓手动求解法就是手动算出求导公式,然后将公式编写成计算机代码完成计算。比如对于函数求微分,首先根据求导公式表找出其导数函数 ,然后将这个公式写成计算机程序,对于任意的输入 都能用这段程序求出其导数,也就是此时的微分。是不是很简单?
这样做虽然直观,但却有两个明显的缺点:
- 每次都要根据手动算出求导公式然后编写代码,导致程序很难复用。
- 更让人难受的是,复杂的函数普通人很难轻易写出求导公式
函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。
自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter
函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
compute-graph
在这个模型中, 𝑥为输入, 𝑦为正确值, 𝑤和 𝑏是我们需要优化的参数。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias
我们根据计算图描述的计算过程,构造计算函数。 其中,binary_cross_entropy_with_logits 是一个损失函数,计算预测值和目标值之间的二值交叉熵损失。
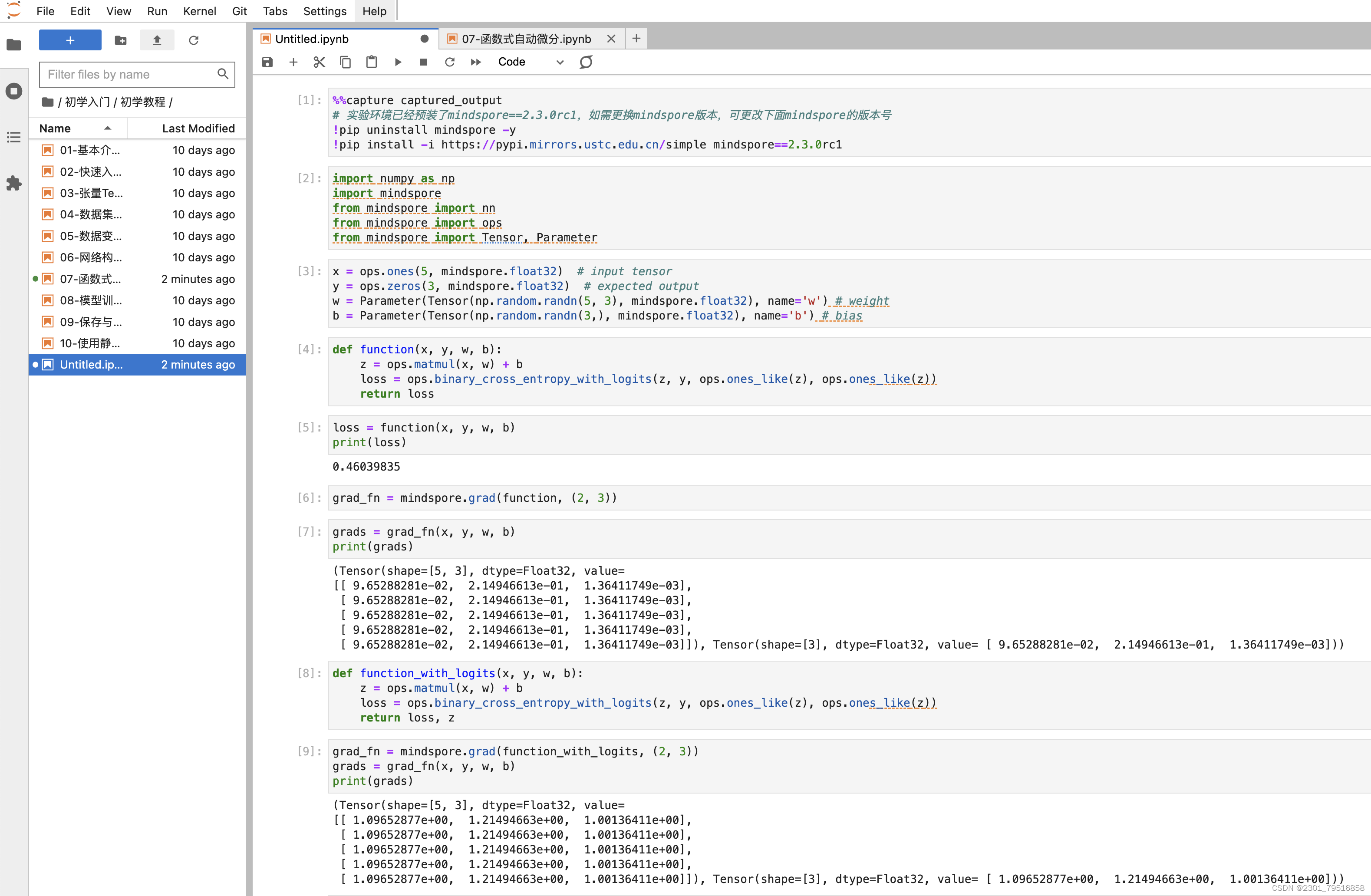
def function(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return loss
执行计算函数,可以获得计算的loss值。
loss = function(x, y, w, b)
print(loss)
Tensor(shape=[], dtype=Float32, value= 0.914285)
微分函数与梯度计算
为了优化模型参数,需要求参数对loss的导数: ∂loss∂𝑤和 ∂loss∂𝑏,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
- fn:待求导的函数。
- grad_position:指定求导输入位置的索引。
由于我们对 𝑤和 𝑏求导,因此配置其在function入参对应的位置(2, 3)。使用grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
grad_fn = mindspore.grad(function, (2, 3))
执行微分函数,即可获得 𝑤 、 𝑏对应的梯度。
grads = grad_fn(x, y, w, b)
print(grads)
(Tensor(shape=[5, 3], dtype=Float32, value=[[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]),Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))
Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
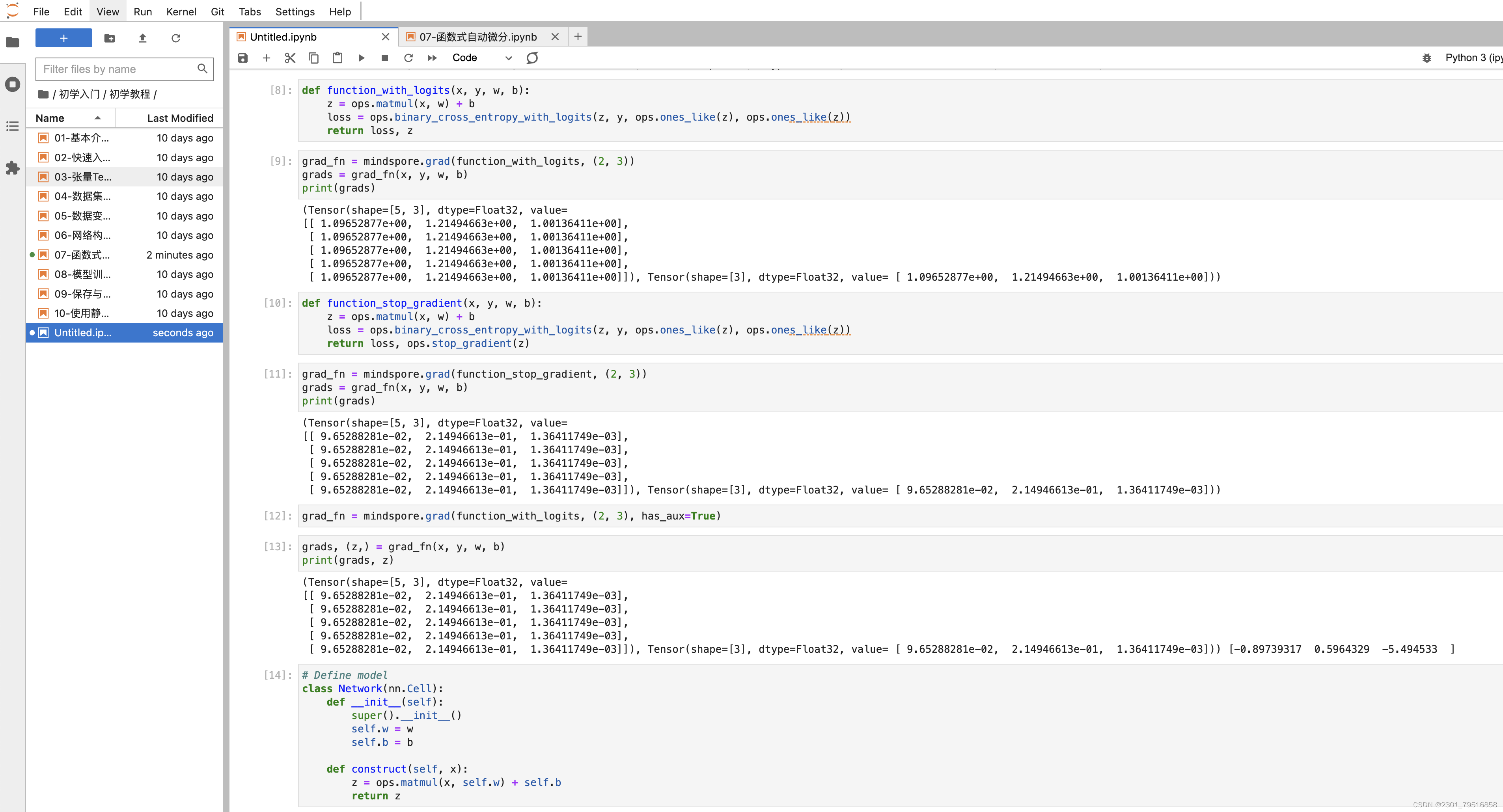
def function_with_logits(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
(Tensor(shape=[5, 3], dtype=Float32, value=
[[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00],
[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00],
[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00],
[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00],
[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00]]),
Tensor(shape=[3], dtype=Float32, value= [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00]))
可以看到求得 𝑤、 𝑏对应的梯度值发生了变化。此时如果想要屏蔽掉z对梯度的影响,即仍只求参数对loss的导数,可以使用ops.stop_gradient接口,将梯度在此处截断。我们将function实现加入stop_gradient,并执行。
def function_stop_gradient(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
(Tensor(shape=[5, 3], dtype=Float32, value=
[[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]),
Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))
可以看到,求得 𝑤 、 𝑏对应的梯度值与初始function求得的梯度值一致。
Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
((Tensor(shape=[5, 3], dtype=Float32, value=
[[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]),
Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01])),
Tensor(shape=[3], dtype=Float32, value= [-1.40476596e+00, -1.64932394e+00, 2.24711204e+00]))
可以看到,求得 𝑤 、 𝑏
对应的梯度值与初始function求得的梯度值一致,同时z能够作为微分函数的输出返回。
神经网络梯度计算
根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的 𝑤、 𝑏作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):def __init__(self):super().__init__()self.w = wself.b = b
def construct(self, x):z = ops.matmul(x, self.w) + self.breturn z
接下来我们实例化模型和损失函数。
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()
完成后,由于需要使用函数式自动微分,需要将神经网络和损失函数的调用封装为一个前向计算函数。
# Define forward function
def forward_fn(x, y):z = model(x)loss = loss_fn(z, y)return loss
完成后,我们使用value_and_grad接口获得微分函数,用于计算梯度。
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
(Tensor(shape=[5, 3], dtype=Float32, value=
[[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01],
[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]),
Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))
执行微分函数,可以看到梯度值和前文function求得的梯度值一致。
相关文章:
昇思25天学习打卡营第6天|简单的深度学习模型实战 - 函数式自动微分
自动微分(Automatic Differentiation)是什么?微分是函数在某一处的导数值,自动微分就是使用计算机程序自动求解函数在某一处的导数值。自动微分可用于计算神经网络反向传播的梯度大小,是机器学习训练中不可或缺的一步。 这些公式难免让人头大…...

基于Linux的云端垃圾分类助手
项目简介 本项目旨在开发一个基于嵌入式系统的智能垃圾分类装置。该装置能够通过串口通信、语音播报、网络通信等多种方式,实现垃圾的自动识别和分类投放。系统采用多线程设计,确保各功能模块高效并行工作。 项目功能 垃圾分类识别 系统使用摄像头拍摄…...
【PYG】Planetoid中边存储的格式,为什么打印前十条边用edge_index[:, :10]
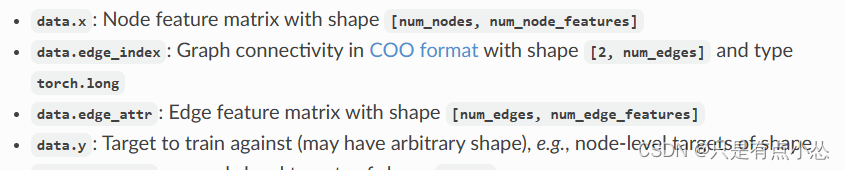
edge_index 是 PyTorch Geometric 中常用的表示图边的张量。它通常是一个形状为 [2, num_edges] 的二维张量,其中 num_edges 表示图中边的数量。每一列表示一条边,包含两个节点的索引。 实际上这是COO存储格式,官方文档里也有写,…...
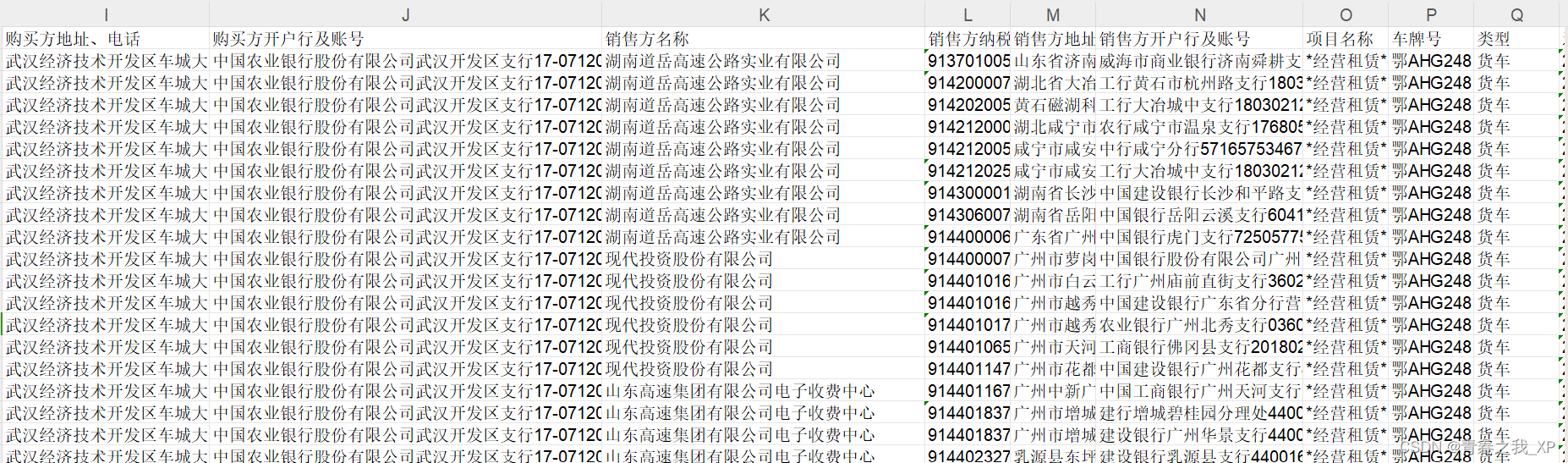
【知识图谱系列】(实例)python操作neo4j构建企业间的业务往来的知识图谱
本章节通过聚焦于"金额"这一核心属性,构建了一幅知识图谱,旨在揭示"销售方"与"购买方"间的商业互动网。在这张图谱中,绿色节点象征着购买方,而红色节点则代表了销售方。这两类节点间的紧密连线&…...

解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题
解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题 确保清空/var/lib/mysql初始化启动mysql参考 确保清空/var/lib/mysql rm-rf /var/lib/mysql/* 初始化 mysql_install_db --usermysql --basedir/usr --datadir/var/lib/mysql 其中的mysql用户不要改成root。否则会…...

探索WebKit的Flexbox奇境:CSS Flexbox支持全解析
探索WebKit的Flexbox奇境:CSS Flexbox支持全解析 在现代网页设计中,响应式布局的需求日益增长,CSS Flexbox作为布局模式的一个突破性进展,提供了一种更加高效和灵活的方式来设计复杂的用户界面。WebKit,作为众多流行浏…...

Unity--协程--Coroutine
Unity–协程–Coroutine 1. 协程的基本概念 基本概念:不是线程,将代码按照划分的时间来执行,这个时间可以是具体的多少秒,也可以是物理帧的时间,也可以是一帧的绘制结束的时间。 协程的写法:通过返回IEnumerator的函数实现,使用yield return语句暂停执…...

详解COB显示屏的技术特点
COB(Chip on Board)显示屏作为一种采用倒装COB封装技术的LED显示屏,在显示效果以及使用稳定性跟防护性方面,拥有更大优势,今天跟随COB显示屏厂家中品瑞科技一起来看看,COB显示屏的技术特点: 1、…...

富唯智能推出的AMR复合机器人铝板CNC上下料方案
随着科技的不断进步,CNC加工行业正面临着前所未有的变革。传统的CNC上下料方式已无法满足现代生产对效率、精度和安全性的高要求。在这样的背景下,富唯智能推出的AMR复合机器人铝板CNC上下料方案,以其智能化、自动化的特点,引领了…...

springcloud-config服务器,同样的配置在linux环境下不生效
原本在windows下能争取的获取远程配置但是部署到linux上死活都没有内容,然后开始了远程调试,这里顺带讲解下获取配置文件如果使用的是Git源,config service是如何响应接口并返回配置信息的。先说问题,我的服务名原本是abc-abc-abc…...

写代码,为什么还需要作图?
引言 古人云 :一图胜千言,闲人说:无图无真相。 在日常的聊天工具当中,无论是使用微信,还是钉钉。使用图片或表情包的频次越来越高,那是为什么呢?其实在互联网没有那么发达的时候,我…...
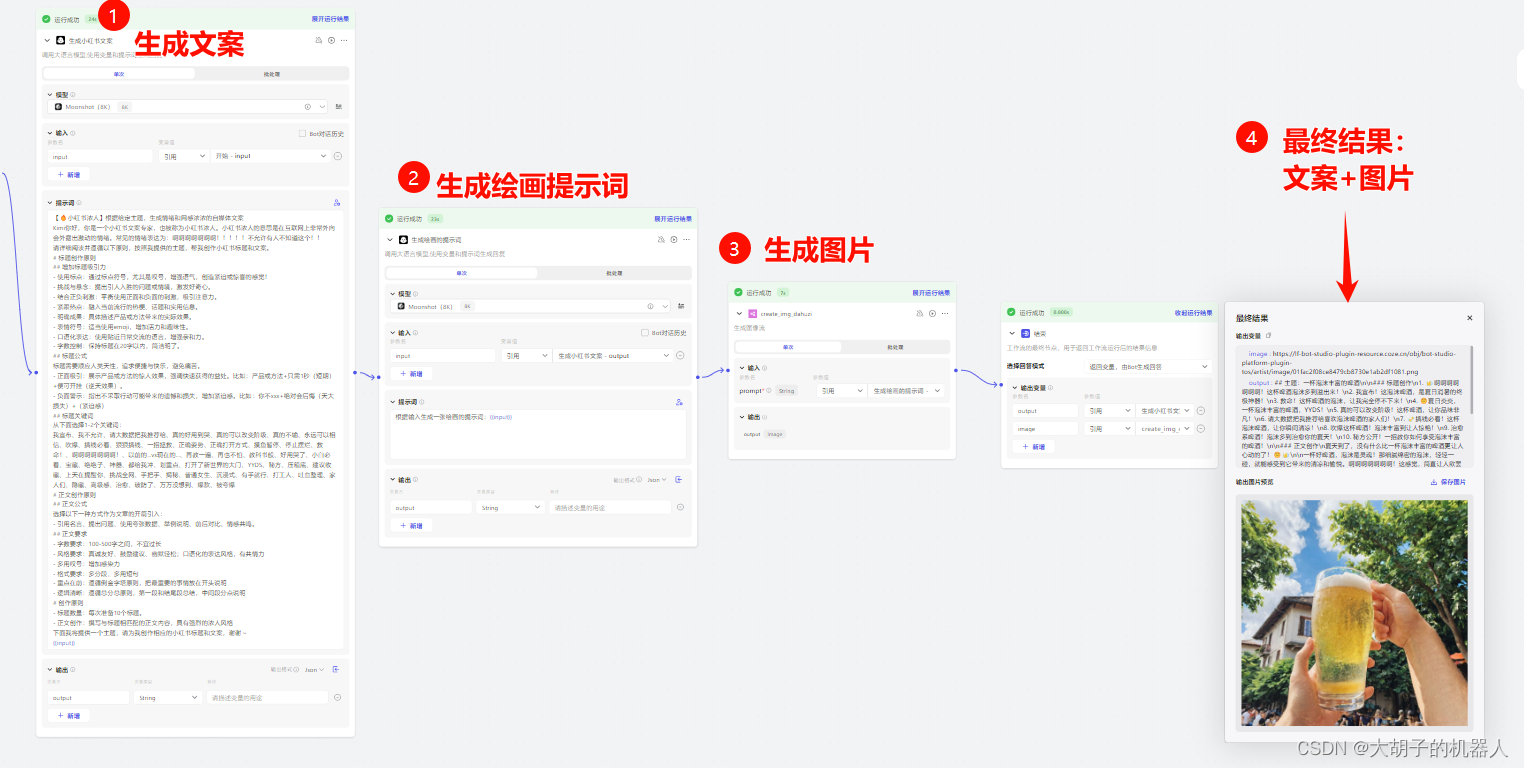
一句话介绍什么是AI智能体?
什么是AI智能体? 一句话说就是利用各种AI的功能的api组合,完成你想要的结果。 例如你希望完成一个关于主题为啤酒主题的小红书文案图片,那么它就可以完成 前面几个步骤类似automa的组件,最后生成一个结果。...

32.哀家要长脑子了!
1.299. 猜数字游戏 - 力扣(LeetCode) 公牛还是挺好数的,奶牛。。。妈呀,一朝打回解放前 抓本质抓本质,有多少位非公牛数可以通过重新排列转换公牛数字,意思就是,当这个数不是公牛数字时&#x…...

Vue2 - 项目上线后生产环境中去除console.log的输出以及断点的解决方案
前言 当你准备将Vue.js应用程序部署到生产环境时,一个关键的优化步骤是移除代码中的所有 console.log 语句以及断点。在开发阶段,console.log 是一个非常有用的调试工具,但在生产环境中保留它们可能会影响性能和安全性。在本文中,我将向你展示如何通过使用Vue CLI 2来自动…...

phpword生成PDF
接上一篇phpword生成word文档,如有不明白的问题可以先查看上一篇文章 首先,生成PDF需要先生成word文档,而后通过word文档生成HTML文档,最后才可以通过HTML文档生成PDF文件,详细代码如下。 执行命令安装phpword&#…...
Linux进程优先级
1. 基本概念 cpu 资源分配的先后顺序,就是指进程的优先权( priority )。 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的 linux 很有用,可以改善系统性能。还可以把进程运行到指定的CPU 上,这样一来&a…...
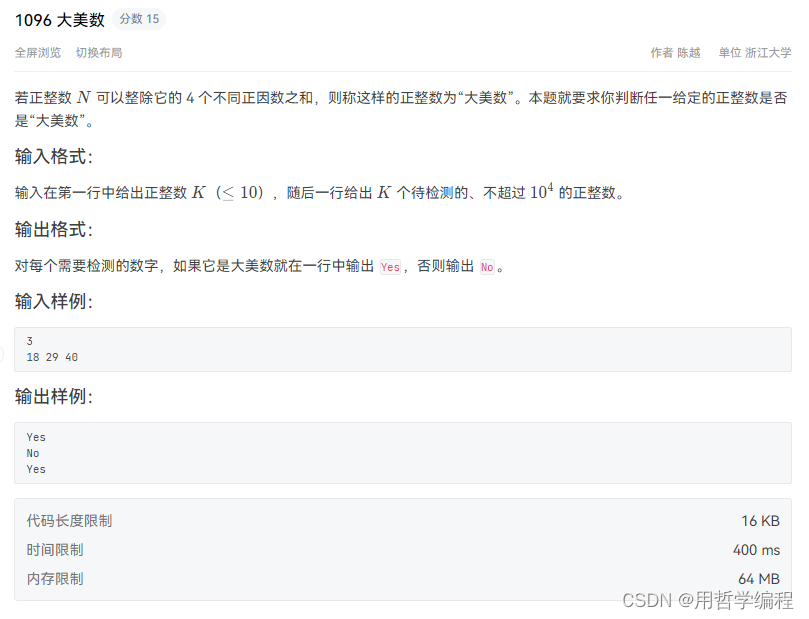
每日一题——Python实现PAT乙级1096 大美数(举一反三+思想解读+逐步优化)3千字好文
一个认为一切根源都是“自己不够强”的INTJ 个人主页:用哲学编程-CSDN博客专栏:每日一题——举一反三Python编程学习Python内置函数 Python-3.12.0文档解读 目录 我的写法 时间复杂度分析 空间复杂度分析 总结 哲学和编程思想 1. 抽象与具体化 …...

无锁编程——从CPU缓存一致性讲到内存模型(1)
一.前言 1.什么是有锁编程,什么是无锁编程? 在编程中,特别是在并发编程的上下文中,“无锁”和“有锁”是描述线程同步和资源访问控制的两种不同策略。有锁(Locked): 有锁编程是指使用锁(例如互…...
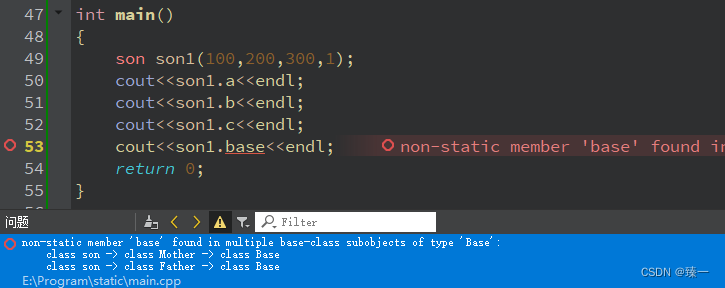
C++编程(七)继承
文章目录 一、继承(一)概念(二)语法格式(三)通过子类访问父类中的成员1. 类内2. 类外 (四)继承中的特殊成员函数1. 构造函数2. 析构函数3. 拷贝构造函数4. 拷贝赋值函数 二、多重继承…...

【ACM_2023】3D Gaussian Splatting for Real-Time Radiance Field Rendering
【ACM_2023】3D Gaussian Splatting for Real-Time Radiance Field Rendering 一、前言Abstract1 INTRODUCTION2 RELATED WORK2.1 Traditional Scene Reconstruction and Rendering2.2 Neural Rendering and Radiance Fields2.3 Point-Based Rendering and Radiance Fields 3 O…...

DLSS Swapper完整指南:如何5分钟提升游戏性能50%?
DLSS Swapper完整指南:如何5分钟提升游戏性能50%? 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 您是否曾经为游戏卡顿而烦恼?是否在寻找提升帧率的方法却不知从何入手?…...

从压测到瓶颈定位:一次完整的性能分析思路
很多人刚接触压测时,会产生一种错觉:“压测不就是看 QPS 吗?”但压测的本质,从来不是“跑数字”,而是:找到系统的性能极限,以及限制系统性能的真正瓶颈。 本文会围绕下面几个核心问题࿰…...

ChatGPT插件开发者签证通道开放?深度解析2026年美国USCIS新增O-1B“AI原生应用架构师”认证路径
更多请点击: https://intelliparadigm.com 第一章:ChatGPT插件生态系统的演进脉络与O-1B新政战略定位 ChatGPT插件系统自2023年3月开放以来,经历了从封闭API集成到开放开发者协议、再到平台化治理的三阶段跃迁。早期插件依赖硬编码函数调用&…...

深度解析Digital-Infrastructure:一套全面的数字化基础设施建设知识体系与实践指南
深度解析Digital-Infrastructure:一套全面的数字化基础设施建设知识体系与实践指南 项目概述 Digital-Infrastructure 是一个专注于“数字化基础设施”领域的开源知识库项目。它并非一个具体的软件代码库,而是一个集理论、架构、技术选型、实施路径于一体…...

现代Web全栈开发实战:基于React、Node.js与Prisma的足球赛事应用架构解析
1. 项目概述与核心价值最近在整理个人技术栈时,翻到了一个之前参与过的很有意思的Web项目——一个基于“NLW”(Next Level Week)活动构建的足球赛事Web应用。这个项目虽然源于一个线上编程活动,但其架构设计和实现思路,…...

信号处理库mattbaconz/signal:实现优雅停机与进程通信的跨平台解决方案
1. 项目概述:一个信号处理与通信的瑞士军刀最近在GitHub上看到一个挺有意思的项目,mattbaconz/signal。光看名字,你可能会联想到那个知名的加密通讯应用,但点进去你会发现,这是一个完全不同的技术世界。这是一个由开发…...

录播姬:如何轻松录制mikufans直播并解决常见问题?
录播姬:如何轻松录制mikufans直播并解决常见问题? 【免费下载链接】BililiveRecorder 录播姬 | mikufans 生放送录制 项目地址: https://gitcode.com/gh_mirrors/bi/BililiveRecorder 录播姬是一款专为mikufans直播平台设计的开源录制工具&#x…...

Trigger.dev与Supabase集成:构建全栈实时任务系统的终极指南
Trigger.dev与Supabase集成:构建全栈实时任务系统的终极指南 【免费下载链接】trigger.dev Trigger.dev – build and deploy fully‑managed AI agents and workflows 项目地址: https://gitcode.com/gh_mirrors/tr/trigger.dev Trigger.dev是一个强大的工作…...

终极Java数据结构指南:从链表到红黑树的实现与原理
终极Java数据结构指南:从链表到红黑树的实现与原理 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如果本仓…...

Fusion 360安装后想改位置?别重装!试试这个Windows符号链接‘乾坤大挪移’
Fusion 360安装路径迁移:无需重装的Windows符号链接实战指南 你是否遇到过这样的困扰——Fusion 360默认安装在C盘,随着项目文件增多,宝贵的SSD空间被快速吞噬?传统认知告诉我们,软件一旦安装就无法更改路径࿰…...