PX2平台Pytorch源码编译
写在前面:以下内容完成于2019年底,只是把笔记放到了CSDN上。
需要注释掉NCLL及分布式相关的配置
libcudart.patch
diff --git a/torch/cuda/__init__.py b/torch/cuda/__init__.py
index 4591702..07e1268 100644
--- a/torch/cuda/__init__.py
+++ b/torch/cuda/__init__.py
@@ -59,7 +59,7 @@ def _load_cudart():if platform.system() == 'Windows':lib = find_cuda_windows_lib()else:
- lib = ctypes.cdll.LoadLibrary(None)
+ lib = ctypes.cdll.LoadLibrary("libcudart.so")if hasattr(lib, 'cudaGetErrorName'):return lib
remove_nccl.patch
diff --git a/CMakeLists.txt b/CMakeLists.txt
index 159b153..6f7423d 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -95,7 +95,7 @@ option(USE_LMDB "Use LMDB" ON)option(USE_METAL "Use Metal for iOS build" ON)option(USE_MOBILE_OPENGL "Use OpenGL for mobile code" ON)option(USE_NATIVE_ARCH "Use -march=native" OFF)
-option(USE_NCCL "Use NCCL" ON)
+option(USE_NCCL "Use NCCL" OFF)option(USE_SYSTEM_NCCL "Use system-wide NCCL" OFF)option(USE_NNAPI "Use NNAPI" OFF)option(USE_NNPACK "Use NNPACK" ON)
@@ -119,7 +119,7 @@ option(USE_TENSORRT "Using Nvidia TensorRT library" OFF)option(USE_ZMQ "Use ZMQ" OFF)option(USE_ZSTD "Use ZSTD" OFF)option(USE_MKLDNN "Use MKLDNN" OFF)
-option(USE_DISTRIBUTED "Use distributed" ON)
+option(USE_DISTRIBUTED "Use distributed" OFF)cmake_dependent_option(USE_MPI "Use MPI for Caffe2. Only available if USE_DISTRIBUTED is on." ON"USE_DISTRIBUTED" OFF)
diff --git a/tools/setup_helpers/dist_check.py b/tools/setup_helpers/dist_check.py
index 8859fe1..5d2ed1c 100644
--- a/tools/setup_helpers/dist_check.py
+++ b/tools/setup_helpers/dist_check.py
@@ -6,7 +6,7 @@ from .env import IS_CONDA, IS_LINUX, IS_WINDOWS, CONDA_DIR, check_env_flag, checfrom .cuda import USE_CUDA# On ROCm, RCCL development isn't complete. https://github.com/ROCmSoftwarePlatform/rccl
-USE_DISTRIBUTED = not check_negative_env_flag("USE_DISTRIBUTED") and not IS_WINDOWS and not check_env_flag("USE_ROCM")
+USE_DISTRIBUTED = FalseUSE_GLOO_IBVERBS = FalseIB_DEVINFO_CMD = "ibv_devinfo"
diff --git a/tools/setup_helpers/nccl.py b/tools/setup_helpers/nccl.py
index c1cc886..576f74e 100644
--- a/tools/setup_helpers/nccl.py
+++ b/tools/setup_helpers/nccl.py
@@ -9,7 +9,7 @@ from .env import IS_WINDOWS, IS_DARWIN, IS_CONDA, CONDA_DIR, check_negative_env_from .cuda import USE_CUDA, CUDA_HOME-USE_NCCL = USE_CUDA and not IS_DARWIN and not IS_WINDOWS
+USE_NCCL = FalseUSE_SYSTEM_NCCL = FalseNCCL_LIB_DIR = NoneNCCL_SYSTEM_LIB = None
diff --git a/torch/CMakeLists.txt b/torch/CMakeLists.txt
index 9c4a018..6849cb1 100644
--- a/torch/CMakeLists.txt
+++ b/torch/CMakeLists.txt
@@ -690,7 +690,7 @@ if (BUILD_PYTHON)list(APPEND TORCH_PYTHON_SRCS ${TORCH_SRC_DIR}/csrc/distributed/c10d/init.cpp)list(APPEND TORCH_PYTHON_LINK_LIBRARIES c10d)list(APPEND TORCH_PYTHON_COMPILE_DEFINITIONS USE_C10D)
- if (USE_CUDA)
+ if (USE_CUDA AND USE_NCCL)list(APPEND TORCH_PYTHON_SRCS ${TORCH_SRC_DIR}/csrc/distributed/c10d/ddp.cpp)endif()endif()
diff --git a/torch/csrc/distributed/c10d/init.cpp b/torch/csrc/distributed/c10d/init.cpp
index 2b42e1e..11a866d 100644
--- a/torch/csrc/distributed/c10d/init.cpp
+++ b/torch/csrc/distributed/c10d/init.cpp
@@ -435,7 +435,7 @@ They are used in specifying strategies for reduction collectives, e.g.,&::c10d::ProcessGroup::Work::wait,py::call_guard<py::gil_scoped_release>());-#ifdef USE_CUDA
+#if defined(USE_CUDA) && defined(USE_TORCH)module.def("_dist_bucket_tensors",&::c10d::bucketTensors,
iGPU上显示资源不足:iGPU的寄存器数据只有dGPU的一半,需要将降低CUDA的线程数
RuntimeError: cuda runtime error (7) : too many resources requested for launch at /opt/zhangmm/docker/pytorch_1.1.0/aten/src/THCUNN/generic/SpatialUpSamplingBilinear.cu:67
cankao: https://github.com/pytorch/pytorch/issues/8103#issuecomment-424343705
Pytorch on PX2
diff --git a/aten/src/ATen/cuda/CUDAContext.cpp b/aten/src/ATen/cuda/CUDAContext.cpp
index 70a7d05b6..48bf1173e 100644
--- a/aten/src/ATen/cuda/CUDAContext.cpp
+++ b/aten/src/ATen/cuda/CUDAContext.cpp
@@ -24,6 +24,8 @@ void initCUDAContextVectors() {void initDeviceProperty(DeviceIndex device_index) {cudaDeviceProp device_prop;AT_CUDA_CHECK(cudaGetDeviceProperties(&device_prop, device_index));
+ // patch for "too many resources requested for launch"
+ device_prop.maxThreadsPerBlock = device_prop.maxThreadsPerBlock / 2;device_properties[device_index] = device_prop;}diff --git a/aten/src/ATen/cuda/detail/KernelUtils.h b/aten/src/ATen/cuda/detail/KernelUtils.h
index e535f4d83..ac057c504 100644
--- a/aten/src/ATen/cuda/detail/KernelUtils.h
+++ b/aten/src/ATen/cuda/detail/KernelUtils.h
@@ -12,7 +12,10 @@ namespace at { namespace cuda { namespace detail {for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < (n); i += blockDim.x * gridDim.x)// Use 1024 threads per block, which requires cuda sm_2x or above
-constexpr int CUDA_NUM_THREADS = 1024;
+//constexpr int CUDA_NUM_THREADS = 1024;
+
+// patch for "too many resources requested for launch"
+constexpr int CUDA_NUM_THREADS = 512;// CUDA: number of blocks for threads.inline int GET_BLOCKS(const int N)
diff --git a/aten/src/THCUNN/common.h b/aten/src/THCUNN/common.h
index 9e3ed7d85..08fcb4532 100644
--- a/aten/src/THCUNN/common.h
+++ b/aten/src/THCUNN/common.h
@@ -9,7 +9,10 @@"Some of weight/gradient/input tensors are located on different GPUs. Please move them to a single one.")// Use 1024 threads per block, which requires cuda sm_2x or above
-const int CUDA_NUM_THREADS = 1024;
+//const int CUDA_NUM_THREADS = 1024;
+
+// patch for "too many resources requested for launch"
+const int CUDA_NUM_THREADS = 512;// CUDA: number of blocks for threads.inline int GET_BLOCKS(const int N)
相关文章:

PX2平台Pytorch源码编译
写在前面:以下内容完成于2019年底,只是把笔记放到了CSDN上。 需要注释掉NCLL及分布式相关的配置 libcudart.patch diff --git a/torch/cuda/__init__.py b/torch/cuda/__init__.py index 4591702..07e1268 100644 --- a/torch/cuda/__init__.pyb/torc…...
昇思25天学习打卡营第6天|简单的深度学习模型实战 - 函数式自动微分
自动微分(Automatic Differentiation)是什么?微分是函数在某一处的导数值,自动微分就是使用计算机程序自动求解函数在某一处的导数值。自动微分可用于计算神经网络反向传播的梯度大小,是机器学习训练中不可或缺的一步。 这些公式难免让人头大…...

基于Linux的云端垃圾分类助手
项目简介 本项目旨在开发一个基于嵌入式系统的智能垃圾分类装置。该装置能够通过串口通信、语音播报、网络通信等多种方式,实现垃圾的自动识别和分类投放。系统采用多线程设计,确保各功能模块高效并行工作。 项目功能 垃圾分类识别 系统使用摄像头拍摄…...
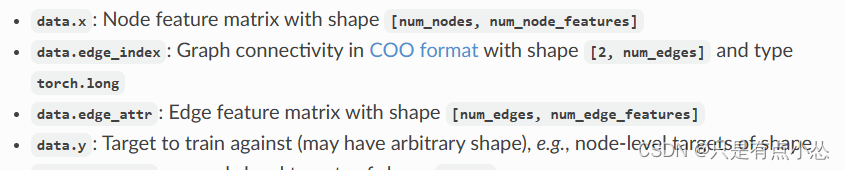
【PYG】Planetoid中边存储的格式,为什么打印前十条边用edge_index[:, :10]
edge_index 是 PyTorch Geometric 中常用的表示图边的张量。它通常是一个形状为 [2, num_edges] 的二维张量,其中 num_edges 表示图中边的数量。每一列表示一条边,包含两个节点的索引。 实际上这是COO存储格式,官方文档里也有写,…...
【知识图谱系列】(实例)python操作neo4j构建企业间的业务往来的知识图谱
本章节通过聚焦于"金额"这一核心属性,构建了一幅知识图谱,旨在揭示"销售方"与"购买方"间的商业互动网。在这张图谱中,绿色节点象征着购买方,而红色节点则代表了销售方。这两类节点间的紧密连线&…...

解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题
解决MySQL删除/var/lib/mysql下的所有文件后无法启动的问题 确保清空/var/lib/mysql初始化启动mysql参考 确保清空/var/lib/mysql rm-rf /var/lib/mysql/* 初始化 mysql_install_db --usermysql --basedir/usr --datadir/var/lib/mysql 其中的mysql用户不要改成root。否则会…...

探索WebKit的Flexbox奇境:CSS Flexbox支持全解析
探索WebKit的Flexbox奇境:CSS Flexbox支持全解析 在现代网页设计中,响应式布局的需求日益增长,CSS Flexbox作为布局模式的一个突破性进展,提供了一种更加高效和灵活的方式来设计复杂的用户界面。WebKit,作为众多流行浏…...

Unity--协程--Coroutine
Unity–协程–Coroutine 1. 协程的基本概念 基本概念:不是线程,将代码按照划分的时间来执行,这个时间可以是具体的多少秒,也可以是物理帧的时间,也可以是一帧的绘制结束的时间。 协程的写法:通过返回IEnumerator的函数实现,使用yield return语句暂停执…...

详解COB显示屏的技术特点
COB(Chip on Board)显示屏作为一种采用倒装COB封装技术的LED显示屏,在显示效果以及使用稳定性跟防护性方面,拥有更大优势,今天跟随COB显示屏厂家中品瑞科技一起来看看,COB显示屏的技术特点: 1、…...

富唯智能推出的AMR复合机器人铝板CNC上下料方案
随着科技的不断进步,CNC加工行业正面临着前所未有的变革。传统的CNC上下料方式已无法满足现代生产对效率、精度和安全性的高要求。在这样的背景下,富唯智能推出的AMR复合机器人铝板CNC上下料方案,以其智能化、自动化的特点,引领了…...

springcloud-config服务器,同样的配置在linux环境下不生效
原本在windows下能争取的获取远程配置但是部署到linux上死活都没有内容,然后开始了远程调试,这里顺带讲解下获取配置文件如果使用的是Git源,config service是如何响应接口并返回配置信息的。先说问题,我的服务名原本是abc-abc-abc…...

写代码,为什么还需要作图?
引言 古人云 :一图胜千言,闲人说:无图无真相。 在日常的聊天工具当中,无论是使用微信,还是钉钉。使用图片或表情包的频次越来越高,那是为什么呢?其实在互联网没有那么发达的时候,我…...
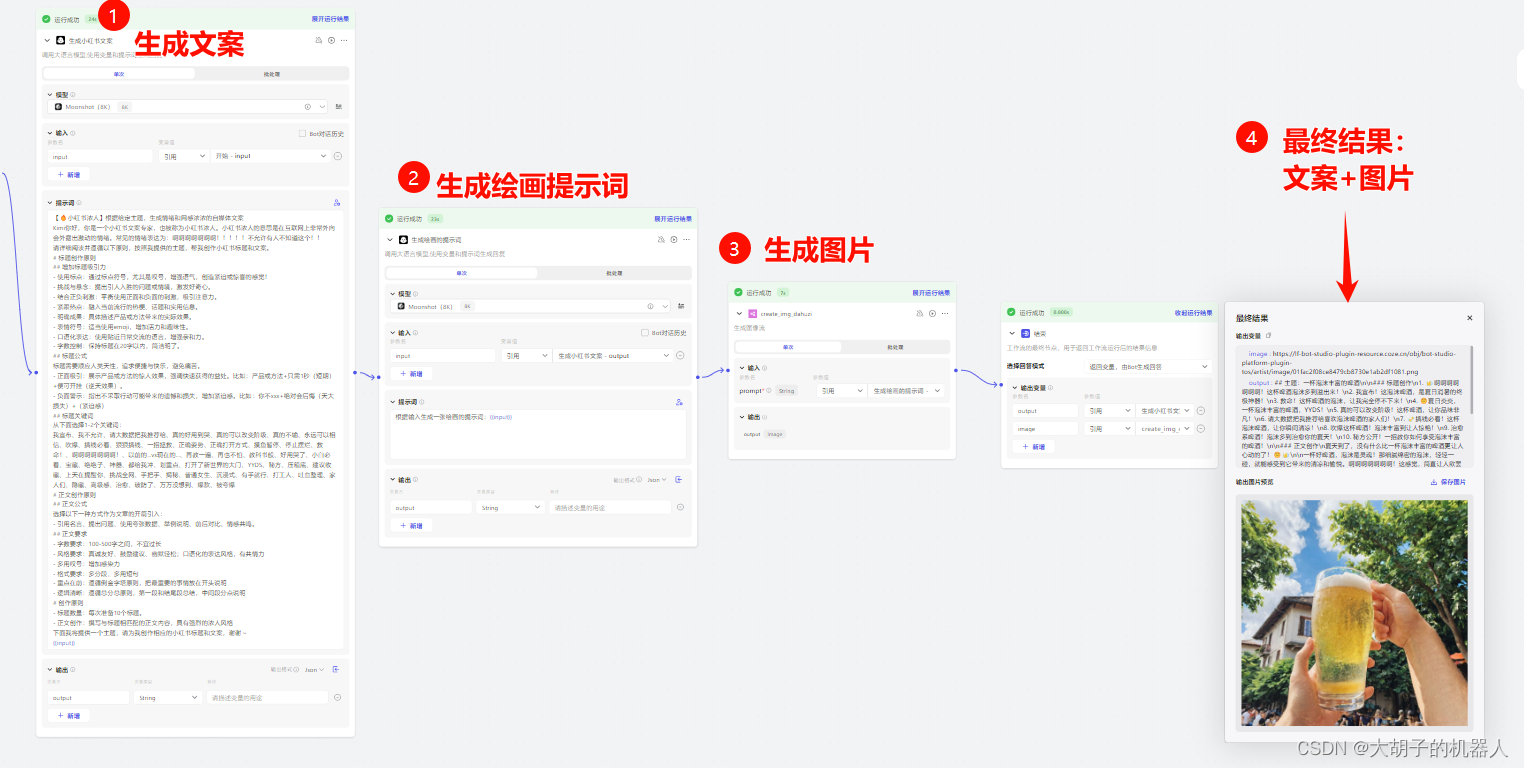
一句话介绍什么是AI智能体?
什么是AI智能体? 一句话说就是利用各种AI的功能的api组合,完成你想要的结果。 例如你希望完成一个关于主题为啤酒主题的小红书文案图片,那么它就可以完成 前面几个步骤类似automa的组件,最后生成一个结果。...

32.哀家要长脑子了!
1.299. 猜数字游戏 - 力扣(LeetCode) 公牛还是挺好数的,奶牛。。。妈呀,一朝打回解放前 抓本质抓本质,有多少位非公牛数可以通过重新排列转换公牛数字,意思就是,当这个数不是公牛数字时&#x…...

Vue2 - 项目上线后生产环境中去除console.log的输出以及断点的解决方案
前言 当你准备将Vue.js应用程序部署到生产环境时,一个关键的优化步骤是移除代码中的所有 console.log 语句以及断点。在开发阶段,console.log 是一个非常有用的调试工具,但在生产环境中保留它们可能会影响性能和安全性。在本文中,我将向你展示如何通过使用Vue CLI 2来自动…...

phpword生成PDF
接上一篇phpword生成word文档,如有不明白的问题可以先查看上一篇文章 首先,生成PDF需要先生成word文档,而后通过word文档生成HTML文档,最后才可以通过HTML文档生成PDF文件,详细代码如下。 执行命令安装phpword&#…...
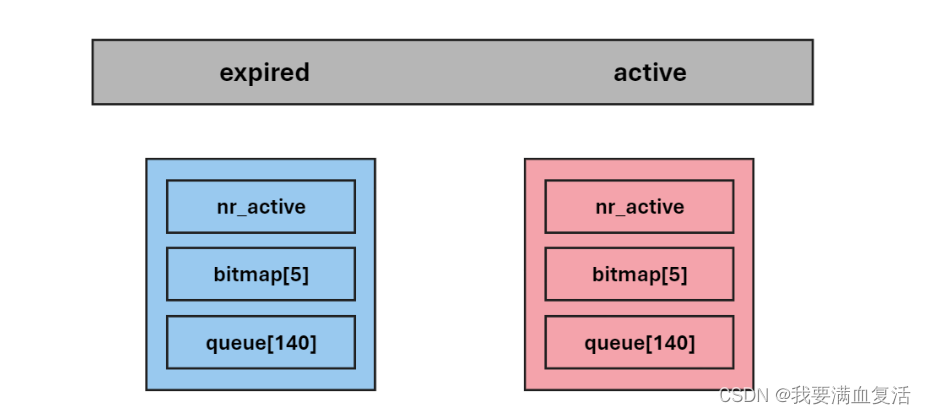
Linux进程优先级
1. 基本概念 cpu 资源分配的先后顺序,就是指进程的优先权( priority )。 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的 linux 很有用,可以改善系统性能。还可以把进程运行到指定的CPU 上,这样一来&a…...
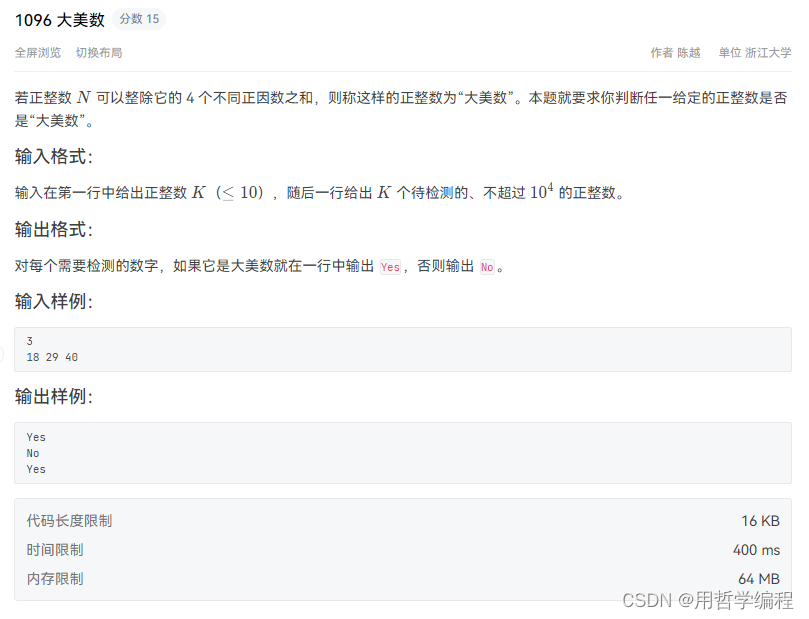
每日一题——Python实现PAT乙级1096 大美数(举一反三+思想解读+逐步优化)3千字好文
一个认为一切根源都是“自己不够强”的INTJ 个人主页:用哲学编程-CSDN博客专栏:每日一题——举一反三Python编程学习Python内置函数 Python-3.12.0文档解读 目录 我的写法 时间复杂度分析 空间复杂度分析 总结 哲学和编程思想 1. 抽象与具体化 …...

无锁编程——从CPU缓存一致性讲到内存模型(1)
一.前言 1.什么是有锁编程,什么是无锁编程? 在编程中,特别是在并发编程的上下文中,“无锁”和“有锁”是描述线程同步和资源访问控制的两种不同策略。有锁(Locked): 有锁编程是指使用锁(例如互…...
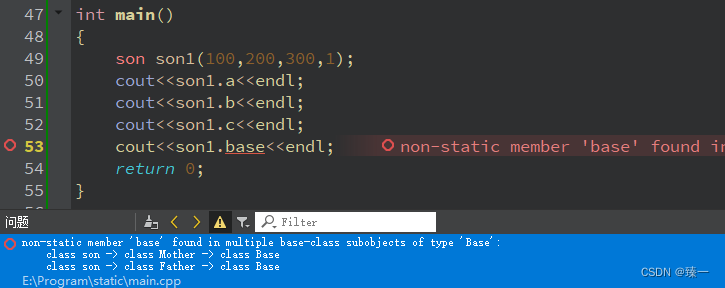
C++编程(七)继承
文章目录 一、继承(一)概念(二)语法格式(三)通过子类访问父类中的成员1. 类内2. 类外 (四)继承中的特殊成员函数1. 构造函数2. 析构函数3. 拷贝构造函数4. 拷贝赋值函数 二、多重继承…...
)
大厂4年经验Java面试题深入解析(10道)
大厂 4 年经验 Java 面试题深入解析(10 道) 这篇文章不是面向校招,也不是面向只会背八股的初级候选人,而是针对已经有 4 年左右实际项目经验、准备冲击大厂的 Java 工程师。 大厂面试更看重你是否能把基础原理、线上问题、设计取舍…...

aztfexport扩展开发:如何自定义资源映射和导入逻辑
aztfexport扩展开发:如何自定义资源映射和导入逻辑 【免费下载链接】aztfexport A tool to bring existing Azure resources under Terraforms management 项目地址: https://gitcode.com/gh_mirrors/az/aztfexport Azure Export for Terraform(a…...

基于API网关与Go的物联网设备管理平台架构设计与实践
1. 项目概述:一个为冲浪模拟器设计的API网关最近在折腾一个很有意思的项目,叫WindsurfPoolAPI。乍一看这个名字,你可能会联想到风帆冲浪或者游泳池,但实际上,它是一个为“冲浪模拟器”这类设备或应用场景设计的后端API…...

从开源模型到API服务:OpenClaw部署实战与Docker+FastAPI方案解析
1. 项目概述:从开源模型到可部署服务的跨越最近在折腾大语言模型本地部署的朋友,可能都绕不开一个名字:OpenClaw。这个由智源研究院开源的模型,以其在代码生成和数学推理上的出色表现,吸引了不少开发者和研究者的目光。…...

STM32H743 FDCAN实战:手把手教你调试CAN节点错误计数器与Bus_Off状态
STM32H743 FDCAN实战:从寄存器到代码的Bus_Off恢复指南 当你的STM32H743项目突然出现CAN通信中断,调试器里FDCAN_PSR寄存器的BOFF位亮起红灯时,真正的挑战才刚刚开始。这不是普通的通信故障,而是触发了CAN协议中最严厉的惩罚机制—…...

React Native Navigation终极指南:构建原生移动应用导航的完整解决方案 [特殊字符]
React Native Navigation终极指南:构建原生移动应用导航的完整解决方案 🚀 【免费下载链接】react-native-navigation A complete native navigation solution for React Native 项目地址: https://gitcode.com/gh_mirrors/re/react-native-navigation…...

PCIe 6.0 Flit Mode 实战解析:从TLP到Flit,你的数据包到底经历了什么?
PCIe 6.0 Flit Mode 深度解析:数据包的奇幻漂流之旅 当一颗来自CPU的事务请求被封装成TLP(Transaction Layer Packet)时,它即将开始一段穿越PCIe 6.0协议栈的奇妙旅程。这段旅程不再是传统PCIe版本中的"自由行"…...

ARM CoreSight ROM Tables解析与调试实践
1. ARM CoreSight ROM Tables基础解析在嵌入式调试领域,ARM CoreSight架构提供了一套完整的调试与追踪解决方案。作为该架构的关键组成部分,ROM Tables扮演着系统调试资源的"目录"角色。想象一下走进一个巨大的图书馆,ROM Tables就…...

告别硬件依赖:用Proteus玩转STM32F1,从CubeMX生成代码到仿真调试的避坑实践
零硬件玩转STM32F103:Proteus仿真全流程与LL库高效开发指南 从真实硬件到虚拟仿真的思维转换 嵌入式开发者的传统认知里,调试灯闪烁必须连接实物开发板——直到他们遇到Proteus。这款电路仿真软件让STM32F103系列芯片在虚拟环境中完美运行,配…...

5分钟快速上手GSE:魔兽世界智能技能循环终极指南
5分钟快速上手GSE:魔兽世界智能技能循环终极指南 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compiler …...