算法:哈希表
目录
题目一:两数之和
题目二:判定是否互为字符重排
题目三:存在重复元素I
题目四:存在重复元素II
题目五:字母异位词分组
关于哈希表
哈希表就是存储数据的容器
哈希表的优势是:快速查找某个元素O(1)
所以当频繁查找某一个数时,就可以使用哈希表,这里提一点,在频繁查某个数时,也需要想到前面学过的二分算法,时间复杂度是O(logN),虽然比哈希表慢一些,但是哈希表的空间复杂度高,而logN级别的时间复杂度也是非常快的,所以能使用二分还是建议使用二分
关于哈希表的使用:
①使用容器
②使用数组模拟哈希表,此时下标是K,内容是V
例如字符串的字符的操作,数据范围很小的时候,可以使用数组模拟
之所以使用数组模拟而不直接使用容器,是因为用数组模拟速度比较快,相比较而言,如果使用容器,还得new一个容器,查找时还需要调用接口,也有消耗
题目一:两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6 输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6 输出:[0,1]
需要注意,这道题要求一个元素不能重复在答案中出现
解法一:暴力解法
在我们前面所讲的暴力枚举方式,是固定一个数,再将这个数后面的所有数与该数的组合一一枚举出来,最终完成暴力枚举
这里采用相反的方向,先固定一个数,再与前面的数依次枚举,同样可以完成暴力枚举的操作
由于第一次使用这种查找前面数的暴力方式,所以写一下代码,便于理解,两层for循环,也是比较简单的:
class Solution
{
public:vector<int> twoSum(vector<int>& nums, int target) {for(int i = 0; i < nums.size(); i++){for(int j = i - 1; j >= 0; j--)//从固定数的前面找符合要求的数{if(nums[i] + nums[j] == target) return {j, i};}}//照顾编译器return {0,0};}
};解法二:哈希表优化
之所以在上面提到了第二种暴力枚举的思路,就是为了优化暴力枚举的方式,引入哈希表,具体说明如下:
数组是: [2,7,10,15],目标是17
先固定一个数2,再找2之前的数,由于2之前没有数,所以往下遍历
接着固定7,再找7之前的数,不符合,继续向下遍历
这时遍历到10了,按照之前暴力枚举的思路,将固定的数与它之前的数依次相加,从而顺利找到目标值,但是可以引入优化的思路,此时就体现哈希的思想了:
既然此时固定的数是10,目标值是17,那么就不需要向前遍历,依次与10相加,判断是否等于目标值,直接将 目标值 - 固定的数 = 17 - 10 = 7,也就是在固定的数前面需要找一个数7,那么这时引入哈希表,在固定前面的数时都放入哈希表中,所以此时需要找7,就不需要遍历前面的数了,直接使用哈希表查找,哈希表查找的时间复杂度为O(1),效率是非常高的,是典型的用空间换时间的算法,因为哈希表的空间复杂度是O(N)
这里说明一下,为什么需要引入第二种暴力枚举,来用哈希表进行优化呢,第一种暴力枚举的策略为什么不太好优化?
第一点:需要提前将元素放入哈希表
第一种暴力枚举的方式,是固定一个数,向后寻找,此时如果想用哈希表的策略,我们就需要提前将数组中的所有数放入哈希表中,才能够知道后面有没有数等于 (target - 该数),比第二种方式差,第二种是边遍历边插入
第二点:很容易误判自己
由于刚开始将所有元素都放入了哈希表中,假设数组是[1,2,4,5],目标值是8,当遍历到 4 这个数时,哈希表中已经有全部的元素在了,此时我们需要找的数是 8 - 4 = 4,很容易误判导致自己找到自己,因为需要找的是4,自己本身也是4,所以这里还需要特殊判断一下找到的数字是否是本身,而上面说的第二种方式,是从固定的数前面找,不会找到自己的,因为都是判断过了,才会插入到哈希表中
所以在做题时,哈希表中,第一个存的是数,第二个存的是该数的下标
代码如下:
class Solution
{
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int, int> hash;//<nums[i], i>for(int i = 0; i < nums.size(); i++){int ret = target - nums[i];//需要找的值if(hash.count(ret)){return {hash[ret], i};}hash[nums[i]] = i;}//照顾编译器return {0,0};}
};题目二:判定是否互为字符重排
给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。
示例 1:
输入:s1= "abc",s2= "bca" 输出: true
示例 2:
输入:s1= "abc",s2= "bad" 输出: false
这道题可以理解为:判断两个字符串重排列之后,所包含的字母是否相同,也就是判断两个字符串中包含的字母个数是否相同
所以很明显,就可以使用哈希表来统计出现的个数,使用容器unordered_map和数组模拟哈希表都能完成, 这里肯定是优先采用数组模拟的方法,因为数组的速度回快一些,并且容器的效率也不高,消耗也会比数组大一些,下面两种解法都列举:
解法一:使用unordered_map容器
先将第一个字符串的字符插入哈希表中,然后遍历另一个字符串,此时每遍历一个字符都判断是否在这个哈希表中,如果不在就return false,如果在value--,再在下面判断value是否为0,因为可能会出现多个相同字符,如果减到0了,就说明不对,return false即可
下面还可以优化一点,如果两个字符串长度都不同,那就不需要比较了,肯定是不同的
代码如下:
class Solution
{
public:bool CheckPermutation(string s1, string s2) {if(s1.size() != s2.size()) return false;unordered_map<char, int> hash(s1.size());for(auto& it : s1) hash[it]++;//插入哈希表中for(auto& it : s2)//遍历字符串2,与哈希表中元素比较{if(!hash.count(it)) return false;//如果没出现,返回falseif(hash[it] == 0) return false;//如果出现多次,返回false--hash[it]; //每次出现value--}//走到这里还没有return,说明是相同的字符串return true;}
};解法二:数组模拟
只需要开大小为26的数组即可,因为题目中只会出现小写字母
同样使用上述的方法,只需要一个数组,将第一个字符串插入数组中,然后遍历第二个字符串,当出现相同字符时,该位置的数--,如果发现减到负数,就返回false
同样可以加上优化,如果两个字符串长度都不同,那就不需要比较了,肯定是不同的
代码如下:
class Solution
{
public:bool CheckPermutation(string s1, string s2) {if(s1.size() != s2.size()) return false;int hash[26] = {0};for(auto& it : s1) hash[it - 'a']++;//插入数组对应位置中for(auto& it : s2)//遍历字符串2,与数组中元素比较{//先--value,然后判断是否小于0if(--hash[it - 'a'] < 0) return false;}//走到这里还没有return,说明是相同的字符串return true;}
};题目三:存在重复元素I
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1] 输出:true
示例 2:
输入:nums = [1,2,3,4] 输出:false
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2] 输出:true
这道题就是判断是否会出现重复元素,比较简单
可以使用上面的两数之和那道题的思路,当遍历到这个数时,找找这个数前面是否有数等于这个数,又因为并不需要关注下标,只需要关注是否出现,所以使用unordered_set即可
代码如下:
class Solution
{
public:bool containsDuplicate(vector<int>& nums) {unordered_set<int> hash(nums.size());for(int i = 0; i < nums.size(); i++){if(hash.count(nums[i])) return true;hash.insert(nums[i]);}return false;}
};题目四:存在重复元素II
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [1,2,3,1], k = 3 输出:true
示例 2:
输入:nums = [1,0,1,1], k = 1 输出:true
示例 3:
输入:nums = [1,2,3,1,2,3], k = 2 输出:false
这道题与上一道题解法基本相同,在上一题是否有重复元素的基础上,增加了条件,判断重复元素的下标之差是否小于等于K,所以这里的哈希表就需要统计下标了,所以就需要使用容器unordered_map了
同样,遍历到某个数时,先判断前面是否出现相同的数,如果出现,再下标之差是否小于等于K,如果都满足就return true,否则继续往后遍历,当遍历完还没有return,就说明没有符合条件的数,最后return false
代码如下:
class Solution
{
public:bool containsNearbyDuplicate(vector<int>& nums, int k) {unordered_map<int, int> hash(nums.size());for(int i = 0; i < nums.size(); i++){//如果重复,则继续判断重复元素的下标是否满足条件if(hash.count(nums[i]) && ((i - hash[nums[i]]) <= k))return true;hash[nums[i]] = i; }//走到这说明没有符合条件的数return false;}
};题目五:字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
此题是给出了字符串数组,vector<string>,每个元素存储的是一个字符串,最终将每一个相同字母组成的字符串放在一起,最终返回
这道题就是深度考验我们对于哈希表容器中类型的使用,我们可以想到一种非常巧妙的方法,首先需要判断是否是字母异位词,可以用上面的哈希表的方式,先将第一个字符串放入哈希表,再遍历第二个字符串,是否与哈希表中出现的一样,但是这种方式不利于更好的解决下面的问题,所以这道题的策略是:
将题目的每一个字符串都按照ASCLL码排序,创建一个unordered_map<string, vector<string>>,然后遍历题目给的字符串数组,如果出现相同的就插入到unordered_map的value中,如果出现不同的就新创建一个插入
再遍历这个哈希表,将相同位置的vector<string>都插入到一起,最终返回即可
代码如下:
class Solution
{
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> hash;//把所有字母异位词分组for(auto& it : strs){//以排序后的tmp作为哈希表的Key,插入的it作为Valuestring tmp = it;sort(tmp.begin(), tmp.end());hash[tmp].push_back(it);}//结果提取出来vector<vector<string>> ret;//表示将哈希表的元素都提取出来,first存在x里,second存在y里for(auto& [x,y] : hash){ret.push_back(y);}return ret;}
};哈希表题目到此结束啦
相关文章:

算法:哈希表
目录 题目一:两数之和 题目二:判定是否互为字符重排 题目三:存在重复元素I 题目四:存在重复元素II 题目五:字母异位词分组 关于哈希表 哈希表就是存储数据的容器 哈希表的优势是:快速查找某个元素O(…...
自然语言处理基本知识(1)
一 分词基础 NLP:搭建了计算机语言和人类语言之间的转换 1 精确分词,试图将句子最精确的分开,适合文本分析 >>> import jieba >>> content "工信处女干事每月经过下属科室" >>> jieba.cut(content,cut_all …...

Java中的数据加密与安全传输
Java中的数据加密与安全传输 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨一下在Java中如何实现数据加密与安全传输。 随着互联网的普及和网络…...

UG NX二次开发(C++)-根据草图创建拉伸特征(UFun+NXOpen)
1、前言 UG NX是基于特征的三维建模软件,其中拉伸特征是一个很重要的特征,有读者问如何根据草图创建拉伸特征,我在这篇博客中讲述一下草图创建拉伸特征的UG NX二次开发方法,感兴趣的可以加入QQ群:749492565,或者在评论区留言。 2、在UG NX中创建草图,然后创建拉伸特征 …...

TS_开发一个项目
目录 一、编译一个TS文件 1.安装TypeScript 2.创建TS文件 3.编译文件 4.用Webpack打包TS ①下载依赖 ②创建文件 ③启动项目 TypeScript是微软开发的一个开源的编程语言,通过在JavaScript的基础上添加静态类型定义构建而成。TypeScript通过TypeScript编译器或…...
)
2024年华为OD机试真题-传递悄悄话 -C++-OD统一考试(C卷D卷)
2024年OD统一考试(D卷)完整题库:华为OD机试2024年最新题库(Python、JAVA、C++合集) 题目描述: 给定一个二叉树,每个节点上站着一个人,节点数字表示父节点到该节点传递悄悄话需要花费的时间。 初始时,根节点所在位置的人有一个悄悄话想要传递给其他人,求二叉树所有节…...
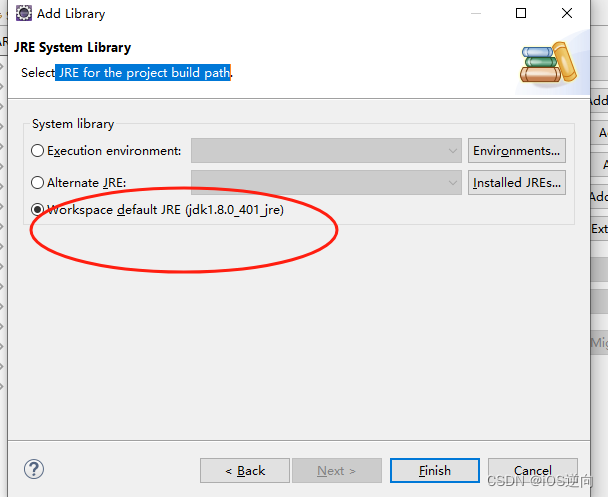
eclipse基础工程配置( tomcat配置JRE环境)
文章目录 I eclipse1.1 工程配置1.2 编译工程1.3 添加 JRE for the project build pathII tomcat配置JRE环境2.1 Eclipse编辑tomcat运行环境(Mac版本)2.2 Eclipse编辑tomcat运行环境(windows版本)2.3 通过tomcat7W.exe配置运行环境(windows系统)I eclipse 1.1 工程配置 …...

Spring Boot 学习第八天:AOP代理机制对性能的影响
1 概述 在讨论动态代理机制时,一个不可避免的话题是性能。无论采用JDK动态代理还是CGLIB动态代理,本质上都是在原有目标对象上进行了封装和转换,这个过程需要消耗资源和性能。而JDK和CGLIB动态代理的内部实现过程本身也存在很大差异。下面将讨…...

Linux[高级管理]——Squid代理服务器的部署和应用(传统模式详解)
🏡作者主页:点击! 👨💻Linux高级管理专栏:点击! ⏰️创作时间:2024年6月24日11点11分 🀄️文章质量:95分 目录 ————前言———— Squid功能 Squ…...

使用Vue 2 + Element UI搭建后台管理系统框架实战教程
后台管理系统作为企业内部的核心业务平台,其界面的易用性和功能性至关重要。Vue 2作为一个成熟的前端框架,以其轻量级和高效著称,而Element UI则是一套专为桌面端设计的Vue 2组件库,它提供了丰富的UI元素和组件,大大简…...

Carla安装教程
1.前言 对于从事自动驾驶的小伙伴而言,或多或少应该都接触过一些的仿真软件,今天要给大家介绍的这款仿真软件应该算的上是业界非常有名的一款仿真软件——carla。 目前carla的学习教程也还是蛮多的,但是写的都不是很全,在配置的…...

【PYG】处理Cora数据集分类任务使用的几个函数log_softmax,nll_loss和argmax
文章目录 log_softmax解释作用示例解释输出 nll_loss解释具体操作示例代码解释 nll_losslog_softmaxcross_entropy解释代码示例解释 argmax()解释作用示例代码解释示例输出 log_softmax F.log_softmax(x, dim1) 是 PyTorch 中的一个函数,用于对输入张量 x 应用 log…...

Labview绘制柱状图
废话不多说,直接上图 我喜欢用NXG风格,这里我个人选的是xy图。 点击箭头指的地方 选择直方图 插值选择第一个 直方图类型我选的是第二个效果如图。 程序部分如图。 最后吐槽一句,现在看CSDN好多文章都要收费了,哪怕一些简单的入…...

使用Python实现一个简单的密码管理器
文章目录 一、项目概述二、实现步骤2.1 安装必要的库2.2 设计密码数据结构2.3 实现密码加密和解密2.4 实现主要功能2.4.1 添加新密码2.4.2 显示所有密码2.4.3 查找特定密码2.4.4 更新密码2.4.5 删除密码 2.5 实现用户界面 三、代码示例3.1 加密和解密示例3.2 用户界面示例 在现…...

【云原生】服务网格(Istio)如何简化微服务通信
🐇明明跟你说过:个人主页 🏅个人专栏:《未来已来:云原生之旅》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、微服务架构的兴起 2、Istio:服务网格的佼…...

spring boot 整合 sentinel
注意版本问题 我这是jdk11 、spring boot 2.7.15 、 alibaba-sentinel 2.1.2.RELEASE <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.15</version><…...
蜜雪冰城小程序逆向
app和小程序算法一样 小程序是wasm...

pbootcms提交留言成功后跳转到指定的网址
pbootcms在线留言表单提交成功后,如何跳转到指定的网址,默认提交留言后留在原来的页面,如果提交后需要跳转到指定网址,我们需要对文件进行修改。首先我们打开/core-/function/helper.php文件找到第162行左右代码: ech…...

16、matlab求导、求偏导、求定积分、不定积分、数值积分和数值二重积分
0)前言 在MATLAB中,对函数进行不同形式的求导、求积分操作是非常常见的需求,在工程、科学等领域中经常会用到。以下是关于求导、求积分以及数值积分的简介: 求导:在MATLAB中可以使用diff函数对函数进行求导操作。diff…...
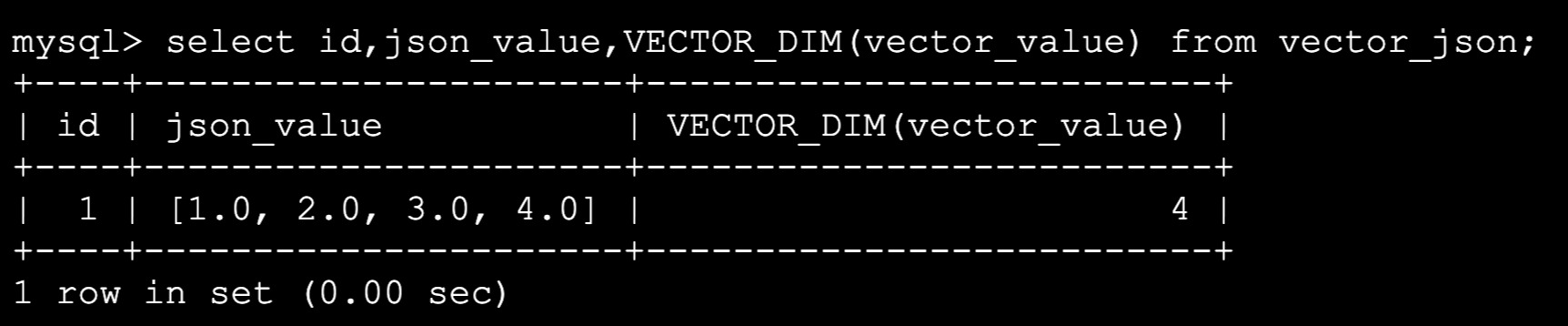
MySQL 9.0创新版发布!功能又进化了!
作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验, Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复, 安装迁移,性能优化、故障…...

AI编程助手Code-Buddy:本地优先、插件化架构与工程实践全解析
1. 项目概述:一个为开发者量身打造的智能代码伙伴 最近在逛GitHub的时候,发现了一个挺有意思的项目,叫 runkids/code-buddy 。光看名字,“代码伙伴”,就让人感觉这应该是个能帮我们写代码、解决开发问题的工具。点进…...

量子互联网节点混合程序执行挑战与Qoala架构解析
1. 量子互联网节点的混合程序执行挑战量子互联网作为量子计算与量子通信技术的融合产物,正在从理论构想走向工程实践。与传统互联网不同,量子互联网的核心功能依赖于量子比特(qubit)的特殊性质——特别是量子纠缠和量子叠加态。这…...

如何永久免费使用AI编程助手:Cursor Free VIP完整指南
如何永久免费使用AI编程助手:Cursor Free VIP完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放
Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的开源…...

1.8.1 掌握Scala类与对象 - Scala类
本次实战通过两组对比鲜明的案例,带你快速入门Scala面向对象编程的核心。首先,通过创建User类,我们掌握了Scala普通类的定义方式,了解了如何使用private修饰符封装成员变量,以及如何通过new关键字实例化对象并调用其公…...

开源免费Web搜索工具openclaw-free-web-search:原理、部署与实战调优
1. 项目概述:一个开源、免费的Web搜索工具最近在折腾一些需要实时信息查询的小项目,比如新闻聚合、舆情监控或者简单的市场调研,发现直接调用商业搜索引擎的API要么有调用限制,要么费用不菲。就在这个当口,我注意到了G…...

如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南
如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的开源Flash逆向工程工具…...

软考高级信息系统项目管理师备考笔记-第14章项目沟通管理
第14章项目沟通管理备考知识点及历年真题 一、历年真题分布 2023年5月 选择题3分 案例6分 2023年11月 选择题3分 案例5分第一批、案例10分第二批 2024年5月 选择题3分 案例16分第一批 2025年5月 选择题2分 案例4分第一批、案例9分第二批 二、备考学习笔记 14.1 …...
)
Docker容器化高可用架构部署方案(二)
01-环境准备 本文档详细介绍部署前的环境准备工作,包括操作系统要求、Docker安装、内核参数配置和网络确认。 系统要求 硬件要求 CPU:至少2核心 内存:至少4GB 磁盘:至少40GB可用空间 操作系统 OpenEuler 24.03 SP3 或其他L…...

如何快速掌握Avogadro 2:开源分子可视化工具的终极指南
如何快速掌握Avogadro 2:开源分子可视化工具的终极指南 【免费下载链接】avogadrolibs Avogadro libraries provide 3D rendering, visualization, analysis and data processing useful in computational chemistry, molecular modeling, bioinformatics, material…...