ElasticSearch中的BM25算法实现原理及应用分析
文章目录
- 一、引言
- 二、BM25算法实现原理
- BM25算法的实现原理
- 1. 词频(TF):
- 2. 逆文档频率(IDF):
- 3. 长度归一化:
- 4. BM25评分公式:
- BM25算法示例
- 三、BM25算法在ElasticSearch中的应用分析
- 3.1 文档搜索
- 3.2 参数调整
- 3.3 混合搜索
- 四、结论

一、引言
ElasticSearch是一个基于Lucene构建的开源搜索引擎,广泛应用于各种搜索场景中。为了提供高质量的搜索结果,ElasticSearch内部集成了多种信息检索算法,其中BM25算法是ElasticSearch
5.0及以后版本默认的相似度算法。BM25算法是一种基于词频(TF)和逆文档频率(IDF)的评分模型,用于评估查询与文档之间的相关性。本文将详细分析BM25算法的实现原理及其在ElasticSearch中的应用。
二、BM25算法实现原理
BM25算法的实现原理
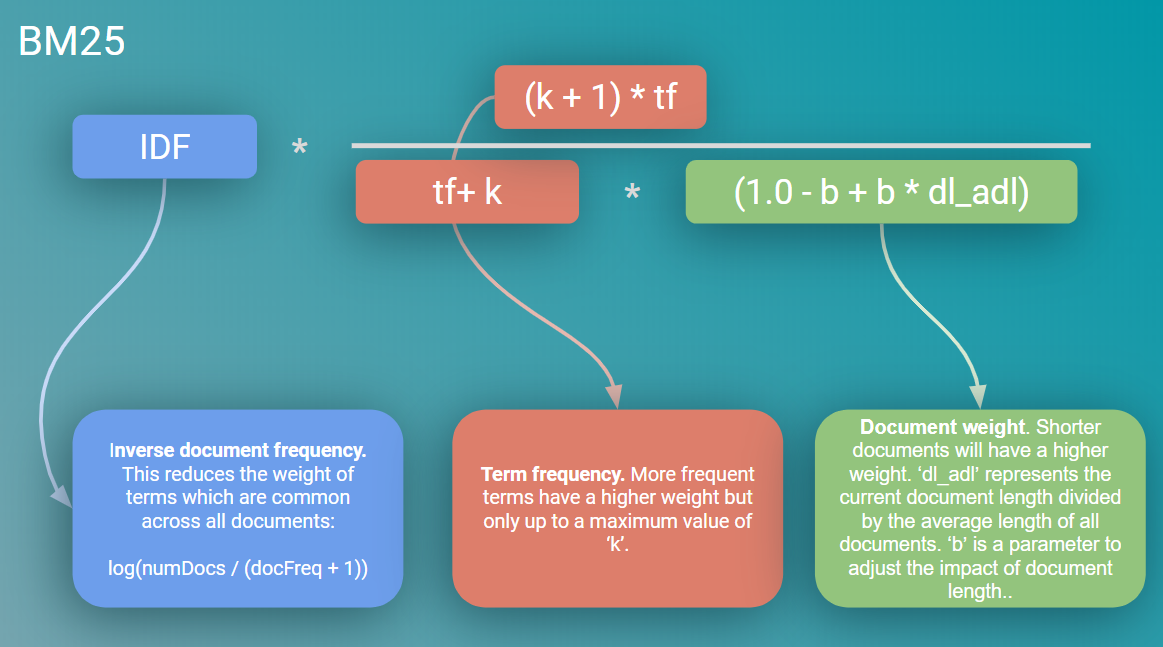
BM25算法是一种在信息检索中广泛使用的排名函数,用于评估文档与用户查询之间的相关性。该算法是TF-IDF(词频-逆文档频率)的改进版本,旨在解决TF-IDF在处理某些问题时的不足。BM25算法的实现原理主要包括以下几个方面:
1. 词频(TF):
- 基本定义:
- 词频(TF)指的是在给定的文档
d中,词项t出现的次数。 - BM25调整:BM25对传统的TF计算方法进行了调整,引入了饱和度和长度归一化,以防止长文档由于包含更多词项而获得不公平的高评分。
- 词频(TF)指的是在给定的文档
- 饱和处理:
- 为了避免词项频率过高时产生过大的影响,BM25对TF进行了饱和处理。这通常通过一个非线性函数实现,使得词频的增长在达到一定阈值后变得平缓。
- 计算公式(在BM25公式中):
- 词频
f(qi, D)直接作为计算的一部分,但它会被一个饱和函数调整。具体来说,TF部分在BM25公式中通常表示为:
f r a c f ( q i , D ) c d o t ( k _ 1 + 1 ) f ( q i , D ) + k _ 1 c d o t ( 1 − b + b c d o t f r a c ∣ D ∣ t e x t a v g d l ) \\frac{f(qi, D) \\cdot (k\_1 + 1)}{f(qi, D) + k\_1 \\cdot (1 - b + b \\cdot \\frac{|D|}{\\text{avgdl}})} fracf(qi,D)cdot(k_1+1)f(qi,D)+k_1cdot(1−b+bcdotfrac∣D∣textavgdl) -
- 其中, ( f ( q i , D ) ) (f(qi, D)) (f(qi,D))是词项(qi)在文档(D)中的出现次数。
- ( k _ 1 ) (k\_1) (k_1)是一个可调参数,通常设置在1.2到2.0之间,用于控制词频的饱和程度。
- ( b ) (b) (b)是另一个可调参数,通常设置在0.0到0.75之间,用于控制文档长度对得分的影响。
- ( ∣ D ∣ ) (|D|) (∣D∣)是文档 ( D ) (D) (D)的长度(即词项数量)。
- t e x t a v g d l text{avgdl} textavgdl 是文档集合中文档的平均长度。
- 词频
- 特点:
- 当词项在文档中出现次数很少时,TF的增加会显著提高该词项在文档中的权重。
- 然而,随着词项出现次数的增加,TF的增加对权重的贡献会逐渐减小,从而实现饱和效果。
- 与TF-IDF中的TF比较:
- 在传统的TF-IDF中,词频通常是直接计算并使用的,没有饱和处理。
- 而在BM25中,词频经过了一个非线性函数的调整,使得文档中的高频词项不会获得过高的权重。
2. 逆文档频率(IDF):
定义:衡量词项在整个文档集合中稀有程度的指标。
计算方法:通常是基于log函数来计算,即
I D F ( t ) = l o g ( N / d f ( t ) ) IDF(t) = log(N / df(t)) IDF(t)=log(N/df(t))
,其中 N N N是文档总数, d f ( t ) df(t) df(t)是包含词项t的文档数。
3. 长度归一化:
引入原因:考虑到文档长度对评分的影响,BM25引入了长度归一化因子。
实现方式:通过计算文档长度与平均文档长度的比值,并将其作为一个因子加入到评分公式中。
4. BM25评分公式:
公式:
S c o r e ( D , Q ) = ∑ ( I D F ( q i ) ∗ f ( q i , D ) ∗ ( k 1 + 1 ) ) / ( f ( q i , D ) + k 1 ∗ ( 1 − b + b ∗ ∣ D ∣ / a v g d l ) ) Score(D, Q) = ∑(IDF(qi) * f(qi, D) * (k1 + 1)) / (f(qi, D) + k1 * (1 - b + b * |D| / avgdl)) Score(D,Q)=∑(IDF(qi)∗f(qi,D)∗(k1+1))/(f(qi,D)+k1∗(1−b+b∗∣D∣/avgdl))
- D D D:文档
- Q Q Q:查询,由词项qi组成
- q i qi qi:查询中的词项
- f ( q i , D ) f(qi, D) f(qi,D):词项qi在文档D中的词频
- ∣ D ∣ |D| ∣D∣:文档D的长度
- a v g d l avgdl avgdl:文档集合的平均文档长度
- k 1 k1 k1和 b b b:可调节的参数,通常k1取1.2到2.0之间的值,b取0.0到1.0之间的值

BM25算法示例
假设我们有以下简单的场景:
1. 文档集合:包含两篇文档D1和D2。
- D1: “The cat sat on the mat.”
- D2: “The dog chased the cat around the house.”
2. 查询:Q = “cat”
3. 计算步骤:
TF计算:
- D1中"cat"的TF = 1
- D2中"cat"的TF = 1
IDF计算 (假设只有两篇文档):
I D F ( " c a t " ) = l o g ( 2 / 2 ) = 0 IDF("cat") = log(2 / 2) = 0 IDF("cat")=log(2/2)=0
(因为"cat"在两篇文档中都出现了)
注意:在实际应用中,由于文档集合通常很大,IDF值通常不会是0。
长度归一化 (假设|D1| = 5, |D2| = 7, avgdl = 6):
- D1的长度归一化因子 = 1(因为|D1|与avgdl接近)
- D2的长度归一化因子会稍小一些(因为|D2|略大于avgdl)
- BM25评分(由于IDF为0,这里的评分仅作为示例):
S c o r e ( D 1 , Q ) = ( 0 ∗ 1 ∗ ( k 1 + 1 ) ) / ( 1 + k 1 ∗ ( 1 − b + b ∗ 5 / 6 ) ) Score(D1, Q) = (0 * 1 * (k1 + 1)) / (1 + k1 * (1 - b + b * 5 / 6)) Score(D1,Q)=(0∗1∗(k1+1))/(1+k1∗(1−b+b∗5/6))
S c o r e ( D 2 , Q ) = ( 0 ∗ 1 ∗ ( k 1 + 1 ) ) / ( 1 + k 1 ∗ ( 1 − b + b ∗ 7 / 6 ) ) Score(D2, Q) = (0 * 1 * (k1 + 1)) / (1 + k1 * (1 - b + b * 7 / 6)) Score(D2,Q)=(0∗1∗(k1+1))/(1+k1∗(1−b+b∗7/6))
注意:由于IDF为0,这里的评分都为0。在实际应用中,由于IDF不会是0,所以评分会有所不同。
4.结果 :由于评分相同(但实际上不会是0),我们可以根据其他因素(如文档长度、其他词项的评分等)来进一步排序文档。
请注意,这个示例是为了说明BM25算法的计算过程而简化的。在实际应用中,文档集合会更大,IDF值不会是0,并且会考虑查询中的多个词项。

三、BM25算法在ElasticSearch中的应用分析
3.1 文档搜索
ElasticSearch使用BM25算法来计算查询与文档的相关性评分,并根据评分对搜索结果进行排序。用户输入的查询会被分词,并与索引中的文档进行匹配,最终返回相关性最高的文档列表。
在文档搜索过程中,用户输入的查询首先会被Elasticsearch的分词器处理成多个查询词项,然后这些词项与索引中的文档进行匹配。BM25算法会根据每个词项在文档中出现的频率(TF)和在整个文档集合中的稀有程度(IDF)来计算每个词项对文档得分的贡献。此外,BM25算法还包括两个可调节的参数k1和b,分别用来控制词频的饱和度和文档长度对得分的影响。
3.2 参数调整
ElasticSearch允许用户根据实际需求调整BM25算法中的参数(如k1,
b),以优化搜索结果的准确性和相关性。通过调整这些参数,可以控制词频、文档长度等因素对评分的影响,从而适应不同的搜索场景和数据集。
3.3 混合搜索
除了使用BM25算法进行文本搜索外,ElasticSearch还支持与其他算法(如向量模型、基于学习的模型等)进行混合搜索。通过结合不同算法的优点,可以进一步提高搜索效率和准确性,满足更复杂的搜索需求。

四、结论
ElasticSearch中的BM25算法是一种基于词频和逆文档频率的评分模型,通过计算查询与文档的相关性评分来提供高质量的搜索结果。其实现原理简单而有效,通过调整参数和与其他算法进行混合搜索,可以进一步优化搜索结果的准确性和相关性。在实际应用中,ElasticSearch的BM25算法已经得到了广泛的应用和验证,为用户提供了高效、准确的搜索体验。
相关文章:
ElasticSearch中的BM25算法实现原理及应用分析
文章目录 一、引言二、BM25算法实现原理BM25算法的实现原理1. 词频(TF):2. 逆文档频率(IDF):3. 长度归一化:4. BM25评分公式: BM25算法示例 三、BM25算法在ElasticSearch中的应用分析…...
web权限到系统权限 内网学习第一天 权限提升 使用手工还是cs???msf可以不??
现在开始学习内网的相关的知识了,我们在拿下web权限过后,我们要看自己拿下的是什么权限,可能是普通的用户权限,这个连添加用户都不可以,这个时候我们就要进行权限提升操作了。 权限提升这点与我们后门进行内网渗透是乘…...
ros1仿真导航机器人 hector_mapping gmapping
仅为学习记录和一些自己的思考,不具有参考意义。 1 hector_mapping 建图过程 (1)gazebo仿真 roslaunch why_simulation why_slam.launch <launch><!-- We resume the logic in empty_world.launch, changing only the name of t…...
嵌入式实验---实验五 串口数据接收实验
一、实验目的 1、掌握STM32F103串口数据接收程序设计流程; 2、熟悉STM32固件库的基本使用。 二、实验原理 1、STM32F103R6能通过查询中断方式接收数据,每接收到一个字节,立即向对方发送一个相同内容的字节,并把该字节的十六进…...

ubuntu 22.04下编译安装glog共享库
笔者是完美主义者,在编译opencv4.9时,有个有关glog的warn,就下载编译google的glog库并把它编译成shared libaray。重新编译opencv4.9时,该warn解除。现把编译安装glog过程记录,以备后查。 以下操作全程以root身份或sudo执行。 cd…...
Linux环境安装配置nginx服务流程
Linux环境的Centos、麒麟、统信操作系统安装配置nginx服务流程操作: 1、官网下载 下载地址 或者通过命令下载 wget http://nginx.org/download/nginx-1.20.2.tar.gz 2、上传到指定的服务器并解压 tar -zxvf nginx-1.20.1.tar.gzcd nginx-1.20.1 3、编译并安装到…...

设计模式-模板模式
简介 模板方法模式是一种行为设计模式,它在父类中定义了一个操作的算法框架,允许子类在不改变算法结构的情况下重定义算法的某些步骤。这种模式是基于继承的,通过抽象类将通用的代码抽取到超类中,同时通过具体类实现或者改写算法…...

物理删除和逻辑删除区别
物理删除和逻辑删除是数据库管理中针对记录删除操作的两种不同方式,它们的主要区别在于数据的实际处理和后续影响: 物理删除: 操作实质:物理删除会将数据记录从数据库表中彻底移除,包括记录所占的磁盘空间都会被释放。…...

C# 警告 warning MSB3884: 无法找到规则集文件“MinimumRecommendedRules.ruleset”
警告 warning MSB3884: 无法找到规则集文件“MinimumRecommendedRules.ruleset” C:\Program Files\Microsoft Visual Studio\2022\Professional\MSBuild\Current\Bin\amd64\Microsoft.CSharp.CurrentVersion.targets(129,9): warning MSB3884: 无法找到规则集文件“MinimumRe…...
Lua网站开发之文件表单上传
这个代码示例演示如何上传文件或图片,获取上传信息及保存文件到本地。 local fw require("fastweb") local request require("fastweb.request") local response require("fastweb.response") local cjson require("cjson&q…...

千益畅行,旅游卡,如何赚钱?
赚钱这件事情,只有自己努力执行才会有结果。生活中没有幸运二字,每个光鲜亮丽的背后,都是不为人知的付出! #旅游卡服务#...

Element-plus点击当前行之后获取数据显示跟随行数据
要实现点击当前行后,在当前行的下方显示数据,可以通过以下步骤来实现: 在表格的行点击事件中获取当前点击行的位置信息。根据位置信息动态计算并设置需要显示数据区域的位置。 下面是一个更新后的示例代码,演示如何在 Element-P…...

Docker与微服务实战2022 尚
Docker与微服务实战2022 尚硅谷讲师:周阳 1. 基础篇(零基小白) 1 1.1. Docker简介 2 1.2. Docker安装 15 1.3. Docker常用命令 29 1.4. Docker镜像 43 1.5. 本地镜像发布到阿里云 50 1.6. 本地镜像发布到私有库 57 1.7. Docker容器数据卷 64 1.8. Docker常规安装简介 …...

Spring @Cacheable缓存注解用法说明
注解Cacheable 是 Spring 框架中用于缓存数据的方法或类的注解。通过使用这个注解,你可以避免重复计算和重复获取数据,从而提高应用程序的性能。 基本用法 引入依赖 确保在你的项目中引入了 Spring Cache 相关的依赖。如果你使用的是 Spring Boot&…...

Redis如何实现主从复制
Redis主从复制包括全量复制和增量复制。主是主服务器,从是从服务器,主服务器(master )的数据如果更新了也会同步到从服务器(slave),一个主服务器可以搭配很多个从服务器,主服务器负责写入,从服务器只能读取…...
正则表达式以及文本三剑客grep、sed、awk
正则表达式匹配的是文本内容,文本三剑客都是针对文本内容。 grep:过滤文本内容 sed:针对文本内容进行增删改查 awk:按行取列 一、grep grep的作用使用正则表达式来匹配文本内容 1、grep选项 -m:匹配几次之后停止…...
HSRP热备份路由协议(VRRP虚拟路由冗余协议)配置以及实现负载均衡
1、相关原理 在网络中,如果一台作为默认网关的三层交换机或者路由器损坏,所有使用该网关为下一跳的主机通信必然中断,即使配置多个默认网关,在不重启终端的情况下,也不能彻底换到新网关。Cisco提出了HSRP热备份路由协…...

不同集成学习算法的比较:随机森林、AdaBoost、XGBoost、LightGBM
好的,我来为您比较一些常见的集成学习算法,并生成表格形式以便于对比: 算法主要思想和特点应用场景并行处理支持稳定性和鲁棒性主要优化策略和技术AdaBoost使用加权投票组合多个弱分类器,逐步提升分类器性能二分类和多分类问题&a…...

【聊聊原子性,中断,以及nodejs中的具体示例】
什么是原子性 从一个例子说起, x ,读和写 , 如图假设多线程,线程1和线程2同时操作变量x,进行x的操作,那么由于写的过程中,都会先读一份x数据到cpu的寄存器中,所以这个时候cpu1 和 c…...

常见网络端口号
在网络工程领域,了解和掌握默认端口号是至关重要的。端口号是计算机网络中最基本的概念之 一,用于标识特定的网络服务或应用程序。 1、什么是端口号? 端口号是计算机网络中的一种标识,用于区分不同的网络服务和应用程序。每个端…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

Biomni:生物医学图像分析从入门到精通,AI与传统CV融合实战
1. 项目概述:当AI学会“看”懂生物医学图像如果你在生物医学研究、药物发现或者临床诊断领域工作,大概率会和我一样,对海量的生物医学图像数据感到既兴奋又头疼。兴奋的是,这些图像——无论是显微镜下的细胞切片、组织病理学玻片&…...

VS Code光标主题定制指南:提升开发效率与视觉舒适度
1. 项目概述:一个为开发者量身定制的光标主题集合如果你和我一样,每天有超过8个小时的时间是在代码编辑器里度过的,那么你一定对那个在屏幕上闪烁的光标再熟悉不过了。它不仅仅是文本插入点,更是我们思维在数字世界中的延伸。然而…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...