elasticsearch-6.8.23的集群搭建过程
三个节点的 ElasticSearch 集群搭建步骤
准备三台机器:28.104.87.98、28.104.87.100、28.104.87.101 和 ElasticSearch 的安装包 elasticsearch-6.8.23.tar.gz
----------------------------- 28.104.87.98,使用 root 用户操作 ---------------------------
上传 elasticsearch-6.8.23.tar.gz 到 28.104.87.98,比如上传到 /opt/es 目录下
进入到 /opt/es 目录,执行 tar -zxvf elasticsearch-6.8.23.tar.gz 命令,解压安装包到本目录
进入到 ElasticSearch 的配置目录 cd /opt/es/elasticsearch-6.8.23/config
执行 cp elasticsearch-6.8.23.yml elasticsearch-6.8.23.yml.backup 命令,对配置文件进行备份。(此步骤可选)
执行 vi elasticsearch-6.8.23.yml 命令,编辑配置文件
cluster.name: elasticsearch # 集群的名字
node.master: true # 是不是有作为 Master 节点的资格
node.name: node-1 # 节点的名字,集群内要唯一不可重复
node.data: true # 是否存储数据
path.data: /opt/es/data # 存储数据的路径,这个要自己创建
path.logs: /opt/es/logs # 存储日志的路径,这个要自己创建
network.host: 28.104.87.98 # 设置节点的 ip
http.port: 9200 #设置端口号
discovery.zen.ping.unicast.hosts:["28.104.87.98","28.104.87.100","28.104.87.101"] # 集群里所有节点的 ip
discovery.zen.minimum_master_nodes: 2 # 选举 Master 节点时需要参与的最少的候选主节点,计算方式:节点数/2+1
discovery.zen.ping_timeout: 10s # 超时时间
path.repo: ["/mnt/databackup/ElasticSearchBackupSet"] # 使用 NFS 共享的方式进行 Elasticsearch 备份的目录,这个要自己创建。(此配置项可选)
创建三个目录 /opt/es/data、/opt/es/logs、/mnt/databackup/ElasticSearchBackupSet(此目录可选)
创建启动当前节点的 ElasticSearch 用户和设置密码
useradd esUser
passwd esUser
把 /opt/es、/mnt 目录及其子目录授权给 esUser
chown -R esUser:esUser /opt/es
chown -R esUser:esUser /mnt
给 /mnt 目录及其子目录授权 750 权限
chmod -R 750 /mnt
切换用户 esUser
su - esUser
----------------------------- 28.104.87.98,使用 esUser 用户操作 ------------------------------------------------------
进入到 /opt/es/elasticsearch-6.8.23/bin 目录下
cd /opt/es/elasticsearch-6.8.23/bin
启动 ElasticSearch 服务,下面的命令二选一,./elasticesearch 命令能看到启动日志,但是会占用一个窗口。
./elasticesearch
./elasticesearch -d
----------------------------- 28.104.87.100,使用 root 用户操作 ------------------------------------------------------
上传 elasticsearch-6.8.23.tar.gz 到 28.104.87.100,比如上传到 /opt/es 目录下
进入到 /opt/es 目录,执行 tar -zxvf elasticsearch-6.8.23.tar.gz 命令,解压安装包到本目录
进入到 ElasticSearch 的配置目录 cd /opt/es/elasticsearch-6.8.23/config
执行 cp elasticsearch-6.8.23.yml elasticsearch-6.8.23.yml.backup 命令,对配置文件进行备份(此步骤可选)
执行 vi elasticsearch-6.8.23.yml 命令,编辑配置文件
cluster.name: elasticsearch # 集群的名字
node.master: true # 是不是有作为 Master 节点的资格
node.name: node-2 # 节点的名字,集群内要唯一不可重复
node.data: true # 是否存储数据
path.data: /opt/es/data # 存储数据的路径,这个要自己创建
path.logs: /opt/es/logs # 存储日志的路径,这个要自己创建
network.host: 28.104.87.100 # 设置节点的 ip
http.port: 9200 #设置端口号
discovery.zen.ping.unicast.hosts:["28.104.87.98","28.104.87.100","28.104.87.101"] # 集群里所有节点的 ip
discovery.zen.minimum_master_nodes: 2 # 选举 Master 节点时需要参与的最少的候选主节点,计算方式:节点数/2+1
discovery.zen.ping_timeout: 10s # 超时时间
path.repo: ["/mnt/databackup/ElasticSearchBackupSet"] # 使用 NFS 共享的方式进行 Elasticsearch 备份的目录,这个要自己创建。(此配置项可选)
创建三个目录 /opt/es/data、/opt/es/logs、/mnt/databackup/ElasticSearchBackupSet(此目录可选)
创建启动当前节点的 ElasticSearch 用户和设置密码
useradd esUser
passwd esUser
把 /opt/es、/mnt 目录及其子目录授权给 esUser
chown -R esUser:esUser /opt/es
chown -R esUser:esUser /mnt
给 /mnt 目录及其子目录授权 750 权限
chmod -R 750 /mnt
切换用户 esUser
su - esUser
----------------------------- 28.104.87.100,使用 esUser 用户操作 ------------------------------------------------------
进入到 /opt/es/elasticsearch-6.8.23/bin 目录下
cd /opt/es/elasticsearch-6.8.23/bin
启动 ElasticSearch 服务,下面的命令二选一,./elasticesearch 命令能看到启动日志,但是会占用一个窗口。
./elasticesearch
./elasticesearch -d
----------------------------- 28.104.87.101,使用 root 用户操作 ------------------------------------------------------
上传 elasticsearch-6.8.23.tar.gz 到 28.104.87.101,比如上传到 /opt/es 目录下
进入到 /opt/es 目录,执行 tar -zxvf elasticsearch-6.8.23.tar.gz 命令,解压安装包到本目录
进入到 ElasticSearch 的配置目录 cd /opt/es/elasticsearch-6.8.23/config
执行 cp elasticsearch-6.8.23.yml elasticsearch-6.8.23.yml.backup 命令,对配置文件进行备份(此步骤可选)
执行 vi elasticsearch-6.8.23.yml 命令,编辑配置文件
cluster.name: elasticsearch # 集群的名字
node.master: true # 是不是有作为 Master 节点的资格
node.name: node-3 # 节点的名字,集群内要唯一不可重复
node.data: true # 是否存储数据
path.data: /opt/es/data # 存储数据的路径,这个要自己创建
path.logs: /opt/es/logs # 存储日志的路径,这个要自己创建
network.host: 28.104.87.101 # 设置节点的 ip
http.port: 9200 #设置端口号
discovery.zen.ping.unicast.hosts:["28.104.87.98","28.104.87.100","28.104.87.101"] # 集群里所有节点的 ip
discovery.zen.minimum_master_nodes: 2 # 选举 Master 节点时需要参与的最少的候选主节点,计算方式:节点数/2+1
discovery.zen.ping_timeout: 10s # 超时时间
path.repo: ["/mnt/databackup/ElasticSearchBackupSet"] # 使用 NFS 共享的方式进行 Elasticsearch 备份的目录,这个要自己创建。(此配置项可选)
创建三个目录 /opt/es/data、/opt/es/logs、/mnt/databackup/ElasticSearchBackupSet(此目录可选)
创建启动当前节点的 ElasticSearch 用户和设置密码
useradd esUser
passwd esUser
把 /opt/es、/mnt 目录及其子目录授权给 esUser
chown -R esUser:esUser /opt/es
chown -R esUser:esUser /mnt
给 /mnt 目录及其子目录授权 750 权限
chmod -R 750 /mnt
切换用户 esUser
su - esUser
----------------------------- 28.104.87.101,使用 esUser 用户操作 ------------------------------------------------------
进入到 /opt/es/elasticsearch-6.8.23/bin 目录下
cd /opt/es/elasticsearch-6.8.23/bin
启动 ElasticSearch 服务,下面的命令二选一,./elasticesearch 命令能看到启动日志,但是会占用一个窗口。
./elasticesearch
./elasticesearch -d
三台机器上的 ElasticSearch 成功启动以后,在浏览器输入以下地址查看集群健康状态、集群里的所有节点、集群里的所有索引
http://28.104.87.101:9200/_cluster/health?pretty
http://28.104.87.101:9200/_cat/nodes?pretty
http://28.104.87.101:9200/_cat/indices?pretty
--------------------------- 使用 NFS 共享的方式进行 Elasticsearch 备份过程中可能遇到的问题 ------------------------
java -version 命令查看三台机器的 jdk 版本,如果不是 OpenJDK 需要在 java.security 文件里面取消 crypto.policy=unlimited 的注释
cat /etc/passwd | grep esUser 命令查看三台机器 esUser 的 uid 和 gid 是否一致,不一致需要修改为一致
---------------------------------------------- 设置集群的账户和密码(可选) -------------------------------------------------------
如果集群搭建成功了,就可以开始设置账户和密码。注意:设置了账户和密码以后,节点内部的通信需要各个节点配置相同的证书。
1、集群启动以后,新开启一个 Linux 登录窗口,选择 28.104.87.98、28.104.87.100、28.104.87.101 中的任何一个都可以,以 28.104.87.98 为例
2、进入到 ElasticSearch 的配置目录 cd /opt/es/elasticsearch-6.8.23/config
3、执行 vi elasticsearch-6.8.23.yml 命令,编辑配置文件,添加下面内容
http.cors.enabled: true # 是否支持跨域
http.cors.allow-origin: "*" # 当设置允许跨域,默认为 *,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type # 跨域允许设置的头信息,默认为 X-Requested-With,Content-Type,Content-Length
http.cors.allow-methods: OPTIONS,HEAD,GET,POST,PUT,DELETE # 允许跨域的请求方式,默认OPTIONS,HEAD,GET,POST,PUT,DELETE
http.cors.allow-credentials: true # 是否返回设置的跨域 Access-Control-Allow-Credentials 头,如果设置为 true,那么会返回给客户端xpack.security.enabled: true # # 设置启用了 xpack 安全特性。请注意,启用安全特性后,还需要设置用户名和密码
xpack.security.transport.ssl.enabled: true # 设置启用了节点间通信的SSL/TLS 来加密 Elasticsearch 节点之间的通信。
xpack.license.self_generated.type: basic # 设置指定了使用基本类型的自生成许可证
xpack.security.transport.ssl.verification_mode: certificate # 设置定义了 SSL/TLS 通信时的证书验证模式
xpack.security.transport.ssl.keystore.path: /opt/es/elasticsearch-6.8.23/config/elastic-certificates.p12 # 设置指定了包含 SSL 密钥和证书的 PKCS#12 文件(.p12)的路径
xpack.security.transport.ssl.truststore.path: /opt/es/elasticsearch-6.8.23/config/elastic-certificates.p12 # 设置指定了包含受信任证书集合的 PKCS#12 文件(.p12)的路径
4、配置 x-pack 生成 p12 格式证书(用来加密 Elasticsearch 节点之间的通信)
cd /opt/es/elasticsearch-6.8.23/bin 进入到 bin 目录下,执行下面的命令,把生成的证书放到 /opt/es/elasticsearch-6.8.23/config 目录下
./elasticsearch-certutil cert -out …/config/elastic-certificates.p12 -pass “”
5、修改证书的权限
cd /opt/es/elasticsearch-6.8.23/config
chmod 640 elastic-certificates.p12
6、把生成的证书复制到其他节点的 /opt/es/elasticsearch-6.8.23/config 目录下。可以通过命令完成;也可以先下载下来,再上传的方式完成
7、集群剩余的节点复制证书到 /opt/es/elasticsearch-6.8.23/config 目录下后,需要在 elasticsearch-6.8.23.yml 文件中添加配置。
http.cors.enabled: true # 是否支持跨域
http.cors.allow-origin: "*" # 当设置允许跨域,默认为 *,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type # 跨域允许设置的头信息,默认为 X-Requested-With,Content-Type,Content-Length
http.cors.allow-methods: OPTIONS,HEAD,GET,POST,PUT,DELETE # 允许跨域的请求方式,默认OPTIONS,HEAD,GET,POST,PUT,DELETE
http.cors.allow-credentials: true # 是否返回设置的跨域 Access-Control-Allow-Credentials 头,如果设置为 true,那么会返回给客户端xpack.security.enabled: true # # 设置启用了 xpack 安全特性。请注意,启用安全特性后,还需要设置用户名和密码
xpack.security.transport.ssl.enabled: true # 设置启用了节点间通信的SSL/TLS 来加密 Elasticsearch 节点之间的通信。
xpack.license.self_generated.type: basic # 设置指定了使用基本类型的自生成许可证
xpack.security.transport.ssl.verification_mode: certificate # 设置定义了 SSL/TLS 通信时的证书验证模式
xpack.security.transport.ssl.keystore.path: /opt/es/elasticsearch-6.8.23/config/elastic-certificates.p12 # 设置指定了包含 SSL 密钥和证书的 PKCS#12 文件(.p12)的路径
xpack.security.transport.ssl.truststore.path: /opt/es/elasticsearch-6.8.23/config/elastic-certificates.p12 # 设置指定了包含受信任证书集合的 PKCS#12 文件(.p12)的路径
8、停止集群的服务,重新启动集群
9、集群启动以后,新开启一个 Linux 登录窗口,选择 28.104.87.98、28.104.87.100、28.104.87.101 中的任何一个都可以,以 28.104.87.98 为例
10、进入到 ElasticSearch 的 bin 目录 cd /opt/es/elasticsearch-6.8.23/bin 目录,执行下面的命令。按照提示,设置账号 elastic、apm_system、kibana、logstash_system、beats_system、remote_monitoring_user 的账号和密码
./elasticsearch-setup-passwords interactive
11、三台机器上的 ElasticSearch 成功启动以后,在浏览器输入以下地址查看集群健康状态、集群里的所有节点、集群里的所有索引,此时会要求输入账号和密码
http://28.104.87.101:9200/_cluster/health?pretty
http://28.104.87.101:9200/_cat/nodes?pretty
http://28.104.87.101:9200/_cat/indices?pretty
---------------------------------------------- 使用 NFS 共享的方式进行 Elasticsearch 备份过程中可能遇到的问题 -------------------------------------------------------
java -version 命令查看三台机器的 jdk 版本,如果不是 OpenJDK 需要在 java.security 文件里面取消 crypto.policy=unlimited 的注释
cat /etc/passwd | grep esUser 命令查看三台机器 esUser 的 uid 和 gid 是否一致,不一致需要修改为一致
相关文章:

elasticsearch-6.8.23的集群搭建过程
三个节点的 ElasticSearch 集群搭建步骤 准备三台机器:28.104.87.98、28.104.87.100、28.104.87.101 和 ElasticSearch 的安装包 elasticsearch-6.8.23.tar.gz ----------------------------- 28.104.87.98,使用 root 用户操作 ----------------------…...

javascript输出语法
javascript输出有三种方式 一种是弹窗输出,就是网页弹出一个对话框,弹出输出内容 语法是aler(内容) 示例代码如下 <body> <script> alert(你好); </script> </body> 这段代码运行后网页会出现一个对话框,弹出你…...
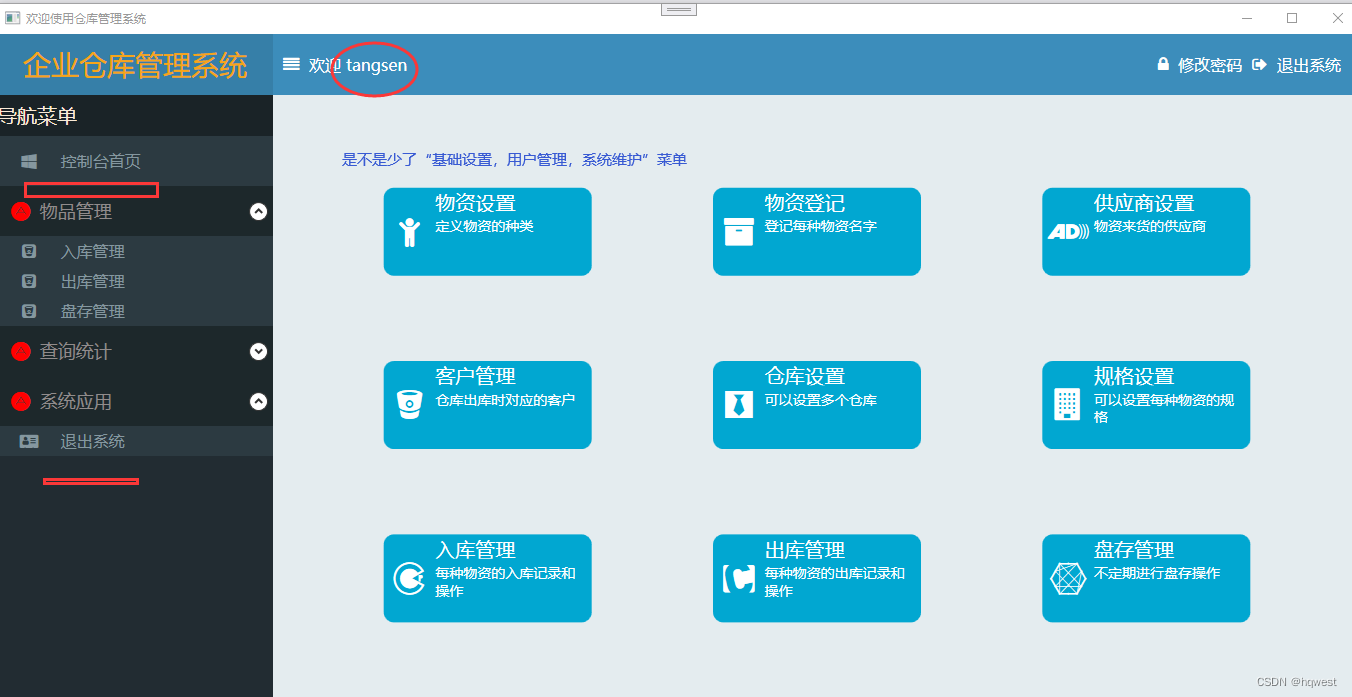
仓库管理系统26--权限设置
原创不易,打字不易,截图不易,多多点赞,送人玫瑰,留有余香,财务自由明日实现 1、权限概述 在应用软件中,通常将软件的功能分为若干个子程序,通过主程序调用。那么,通过…...

d3dx9_43.dll丢失怎么解决?d3dx9_43.dll怎么安装详细教程
在使用计算机中,如果遇到d3dx9_43.dll丢失或许找不到d3dx9_43.dll无法运行打开软件怎么办?这个是非常常见问题,下面我详细介绍一下d3dx9_43.dll是什么文件与d3dx9_43.dll的各种问题以及d3dx9_43.dll丢失的多个解决方法! 一、d3dx9…...
)
[C++] 退出清理函数解读(exit、_exit、abort、atexit)
说明:在C中,exit、_exit(或_Exit)、abort和atexit是用于控制程序退出和清理的标准库函数。下面是对这些函数的详细解读: exit 函数原型:void exit(int status);作用:exit函数用于正常退出程序…...
)
代码随想录(回溯)
组合(Leetcode77) 思路 用递归每次遍历从1-n得数,然后list来记录是不是组合到k个了,然后这个每次for循环的开始不能和上一个值的开始重复,所以设置个遍历开始索引startindex class Solution {static List<List<…...

编译原理1
NFA&DFA 在正规式的等价证明可以借助正规集,也可以通过有限自动机DFA来证明等价,以下例题是针对DFA证明正规式的等价,主要步骤是①NFA;②状态转换表; ③状态转换矩阵; ④化简DFA; 文法和语…...

【信息系统项目管理师知识点速记】组织通用管理:流程管理
23.2 流程管理 通过流程视角能够真正看清楚组织系统的本质与内在联系,理顺流程能够理顺整个组织系统。流程是组织运行体系的框架基础,流程框架的质量影响和决定了整个组织运行体系的质量。把流程作为组织运行体系的主线,配备满足流程运作需要的资源,并构建与流程框架相匹配…...

前端 JS 经典:箭头函数的意义
箭头函数是为了消除函数的二义性。 1. 二义性 函数的二义性指函数有不同的两种用法,就造成了二义性,函数的两种用法:1. 指令序列。2. 构造器 1.1 指令序列 就是调用函数,相当于将函数内部的代码再从头执行一次。 1.2 构造器 …...

Java List操作详解及常用方法
Java List操作详解及常用方法 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 什么是Java List? Java中的List是一种动态数组,它允许存…...
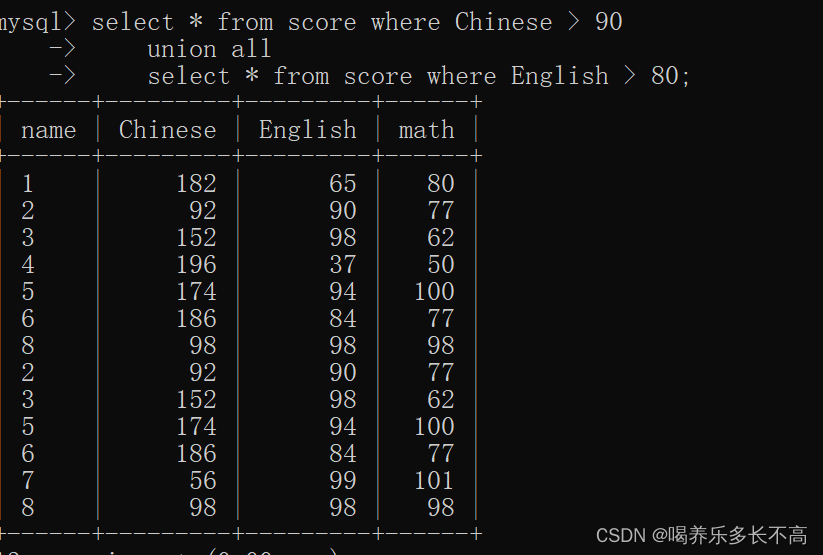
《mysql篇》--查询(进阶)
目录 将查询结果作为插入数据 聚合查询 聚合函数 count sum group by子句 having 联合查询 笛卡尔积 多表查询 join..on实现多表查询 内连接 外连接 自连接 子查询 合并查询 将查询结果作为插入数据 Insert into 表2 select * from 表1//将表1的查询数据插入…...

数据库-MySQL 实战项目——书店图书进销存管理系统数据库设计与实现(附源码)
一、前言 该项目非常适合MySQL入门学习的小伙伴,博主提供了源码、数据和一些查询语句,供大家学习和参考,代码和表设计有什么不恰当还请各位大佬多多指点。 所需环境 MySQL可视化工具:navicat; 数据库:MySq…...
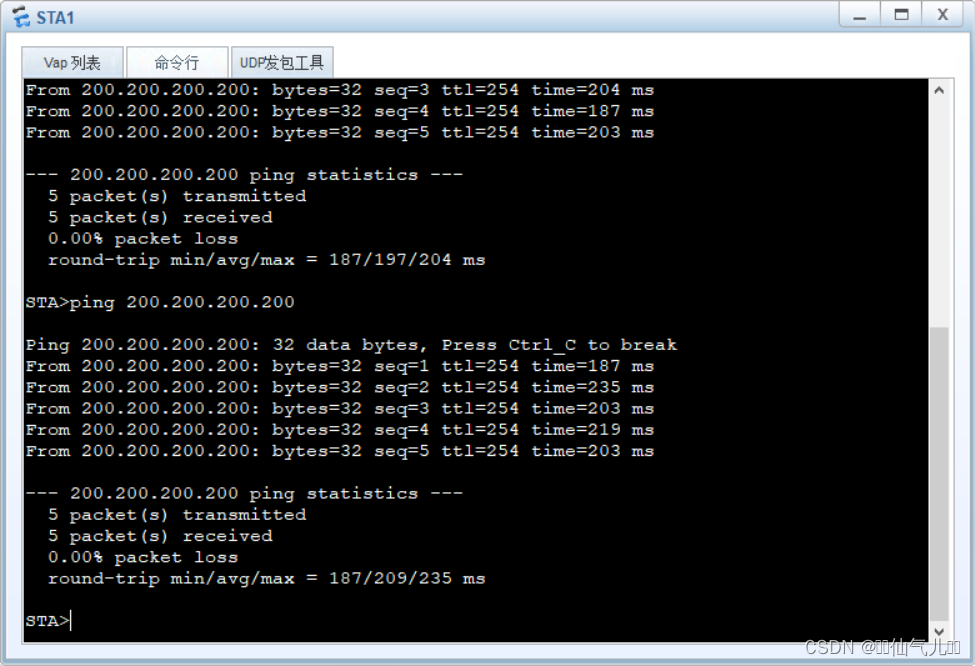
eNSP中WLAN的配置和使用
一、基础配置 1.拓扑图 2.VLAN和IP配置 a.R1 <Huawei>system-view [Huawei]sysname R1 GigabitEthernet 0/0/0 [R1-GigabitEthernet0/0/0]ip address 200.200.200.200 24 b.S1 <Huawei>system-view [Huawei]sysname S1 [S1]vlan 100 [S1-vlan100]vlan 1…...
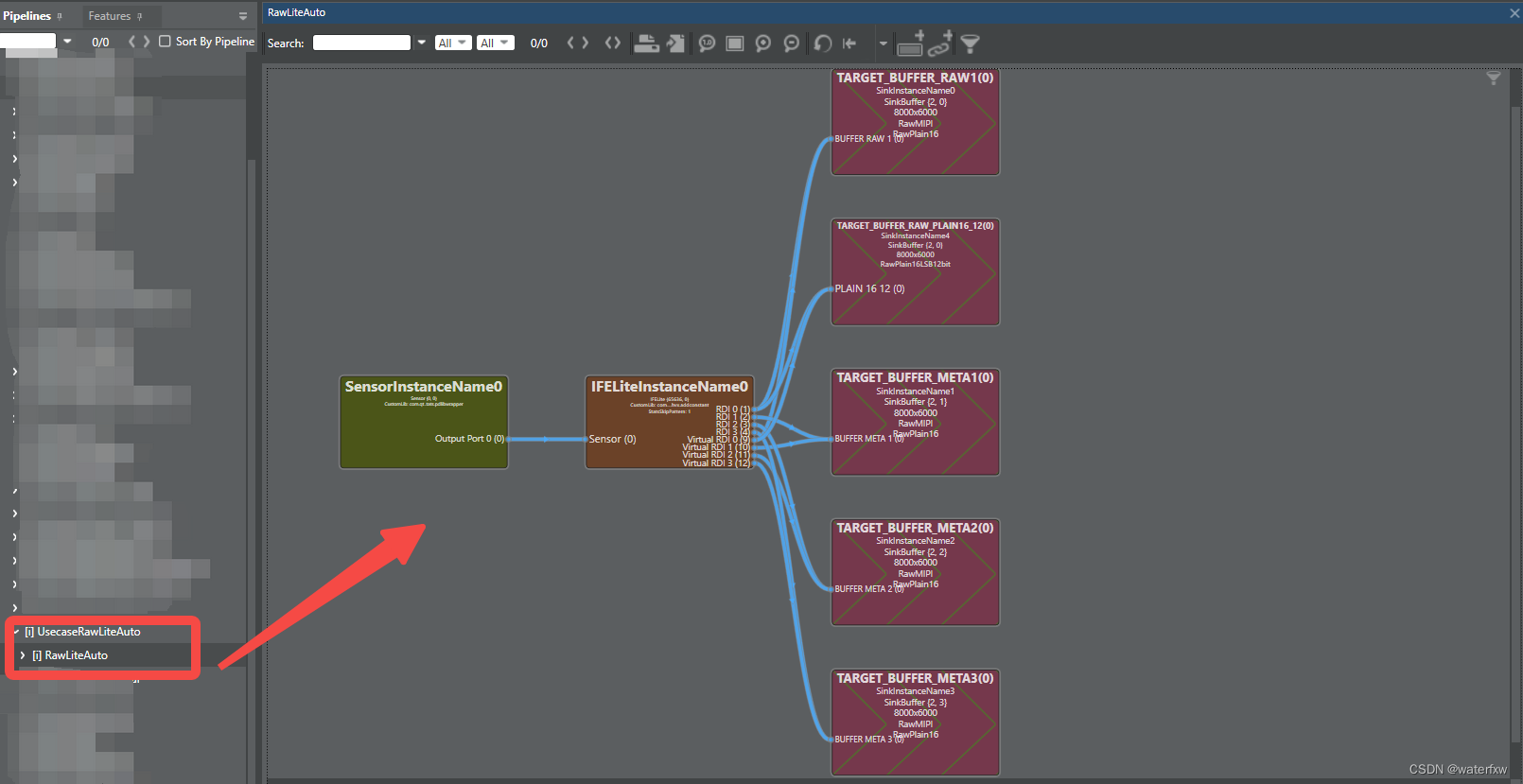
<sa8650>QCX ID16_UsecaseRawLiteAuto 使用详解
<sa8650>QCX ID16_UsecaseRawLiteAuto 使用详解 一、前言二、ID16_UsecaseRawLiteAuto拓扑图三、UsecaseRawLiteAuto拓扑图 解析3.1 camxUsecaseRawLiteAuto.xml3.2 camxRawLiteAuto.xml四、测试一、前言 我们在使用QCX时,如果由于使用的摄像头自带了ISP,那么可能不需要使…...

为什么3d重制变换模型会变形?---模大狮模型网
在当今数字技术飞速发展的时代,3D建模和动画制作已经成为影视、游戏和虚拟现实中不可或缺的一部分。然而,即使在高级的3D软件中,重制(rigging)和变换(transformation)过程中仍然会面临一个普遍的问题——模型变形。这种变形可能导致动画效果不…...

ElasticSearch中的BM25算法实现原理及应用分析
文章目录 一、引言二、BM25算法实现原理BM25算法的实现原理1. 词频(TF):2. 逆文档频率(IDF):3. 长度归一化:4. BM25评分公式: BM25算法示例 三、BM25算法在ElasticSearch中的应用分析…...
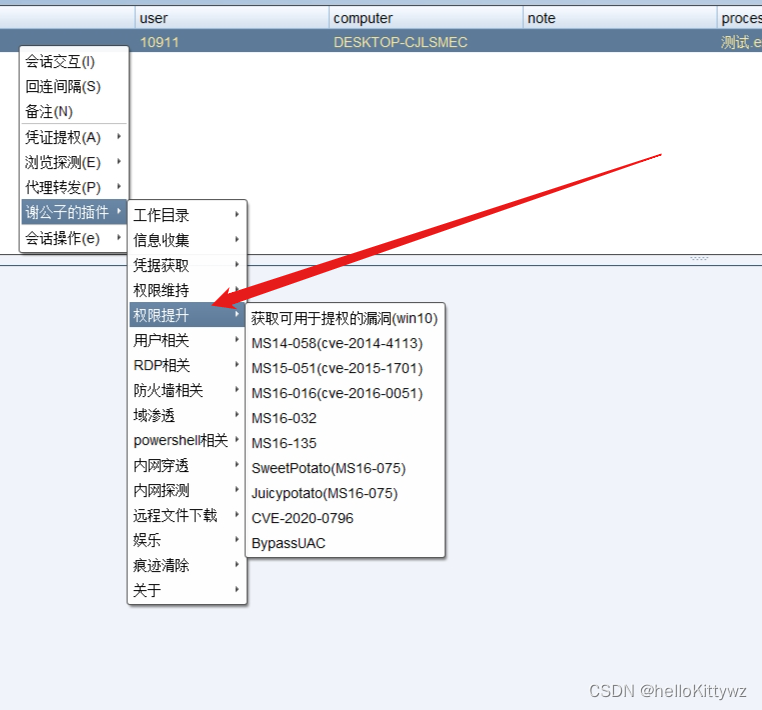
web权限到系统权限 内网学习第一天 权限提升 使用手工还是cs???msf可以不??
现在开始学习内网的相关的知识了,我们在拿下web权限过后,我们要看自己拿下的是什么权限,可能是普通的用户权限,这个连添加用户都不可以,这个时候我们就要进行权限提升操作了。 权限提升这点与我们后门进行内网渗透是乘…...
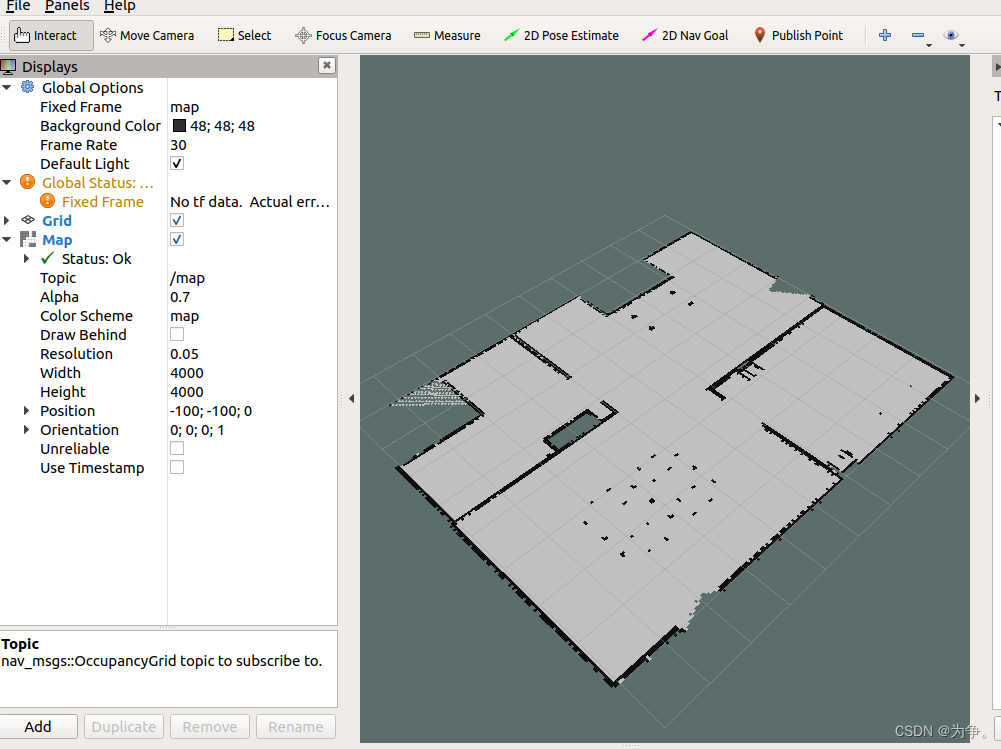
ros1仿真导航机器人 hector_mapping gmapping
仅为学习记录和一些自己的思考,不具有参考意义。 1 hector_mapping 建图过程 (1)gazebo仿真 roslaunch why_simulation why_slam.launch <launch><!-- We resume the logic in empty_world.launch, changing only the name of t…...
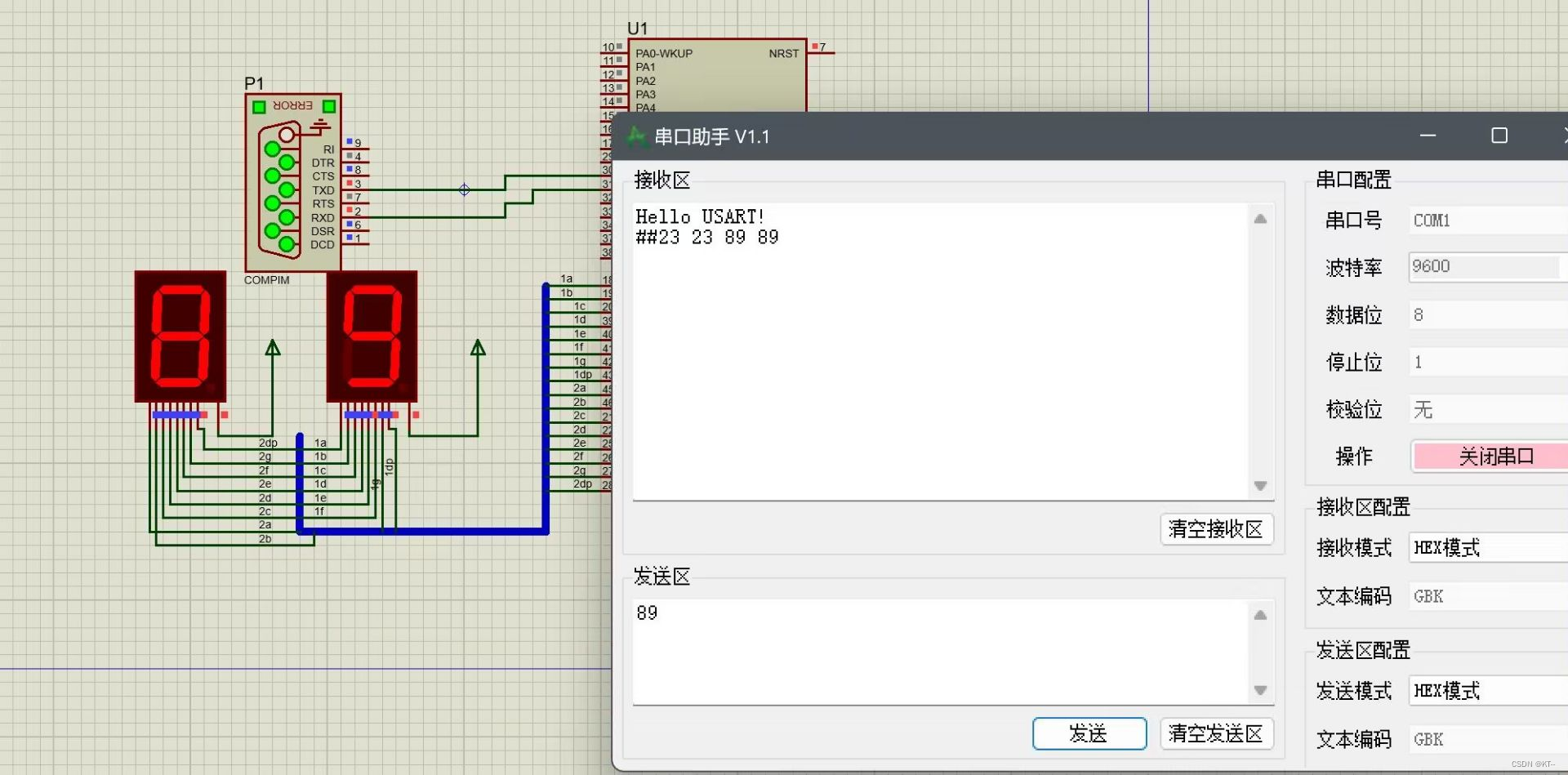
嵌入式实验---实验五 串口数据接收实验
一、实验目的 1、掌握STM32F103串口数据接收程序设计流程; 2、熟悉STM32固件库的基本使用。 二、实验原理 1、STM32F103R6能通过查询中断方式接收数据,每接收到一个字节,立即向对方发送一个相同内容的字节,并把该字节的十六进…...

ubuntu 22.04下编译安装glog共享库
笔者是完美主义者,在编译opencv4.9时,有个有关glog的warn,就下载编译google的glog库并把它编译成shared libaray。重新编译opencv4.9时,该warn解除。现把编译安装glog过程记录,以备后查。 以下操作全程以root身份或sudo执行。 cd…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制
OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中的卡顿和帧率限制?Open…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

怎么找到一个行业的源头工厂、绕开中间商?一套五步识别流程
你下了单,货到了,质量也还行。但心里一直有个疙瘩:这家供应商到底是自己在生产,还是从别处转手赚了你一道差价? 这个问题对采购方和跨境卖家不是洁癖,是真金白银。同一款产品,源头工厂和中间商的…...

如何3分钟快速上手企业级后台管理系统:终极配置秘籍
如何3分钟快速上手企业级后台管理系统:终极配置秘籍 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均可使用 项目地址: https://…...

如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解
如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

Deep Lake:AI数据湖与向量数据库一体化管理实践
1. 项目概述:当数据湖遇上深度学习如果你正在构建一个AI应用,无论是图像识别、自然语言处理还是多模态模型,数据管理绝对是你绕不开的“硬骨头”。数据分散在各个文件夹、云存储、数据库里,格式五花八门,加载速度慢&am…...