机器学习 - 文本特征处理之 TF 和 IDF
TF(Term Frequency,词频)和IDF(Inverse Document Frequency,逆文档频率)是文本处理和信息检索中的两个重要概念,常用于计算一个词在文档中的重要性。下面是详细解释:
TF(词频)
词频表示某个词在一个文档中出现的频率。其计算公式如下:
TF ( t , d ) = 出现次数 ( t , d ) 文档中词语总数 ( d ) \text{TF}(t, d) = \frac{\text{出现次数}(t, d)}{\text{文档中词语总数}(d)} TF(t,d)=文档中词语总数(d)出现次数(t,d)
其中:
- ( t ) 表示词语
- ( d ) 表示文档
示例:
假设有一个文档内容如下:
这 是 一个 示例 示例 文本
- “示例”出现了2次,文档总共有6个词语。
- 词频(TF)计算:
TF ( 示例 , d ) = 2 6 = 0.333 \text{TF}(\text{示例}, d) = \frac{2}{6} = 0.333 TF(示例,d)=62=0.333
IDF(逆文档频率)
逆文档频率用于衡量一个词在所有文档中的普遍重要性。词语越常见,其IDF值越低;词语越不常见,其IDF值越高。其计算公式如下:
IDF ( t ) = log ( N 1 + 包含词语的文档数 ( t ) ) \text{IDF}(t) = \log \left( \frac{N}{1 + \text{包含词语的文档数}(t)} \right) IDF(t)=log(1+包含词语的文档数(t)N)
其中:
- ( N ) 表示文档的总数
- 包含词语的文档数 ( t ) \text{包含词语的文档数}(t) 包含词语的文档数(t) 表示包含词语 ( t ) 的文档数
示例:
假设有以下三个文档:
文档1:这 是 一个 示例 文本
文档2:这是 另一个 示例
文档3:这是 一段 示例 文字
- “示例”在所有3个文档中都出现了。
- 逆文档频率(IDF)计算:
IDF ( 示例 ) = log ( 3 1 + 3 ) = log ( 3 4 ) = − 0.124 \text{IDF}(\text{示例}) = \log \left( \frac{3}{1 + 3} \right) = \log \left( \frac{3}{4} \right) = -0.124 IDF(示例)=log(1+33)=log(43)=−0.124
TF-IDF(词频-逆文档频率)
TF-IDF结合了TF和IDF两个指标,衡量一个词在文档中的重要性。其计算公式如下:
TF-IDF ( t , d ) = TF ( t , d ) × IDF ( t ) \text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t) TF-IDF(t,d)=TF(t,d)×IDF(t)
示例:
结合上述TF和IDF的计算,假设“示例”在某文档中的词频TF为0.333,IDF为-0.124:
TF-IDF ( 示例 , d ) = 0.333 × − 0.124 = − 0.0413 \text{TF-IDF}(\text{示例}, d) = 0.333 \times -0.124 = -0.0413 TF-IDF(示例,d)=0.333×−0.124=−0.0413
这种计算方式表明,尽管“示例”词在单个文档中较为频繁,但在所有文档中都很常见,因此其重要性并不高。
实际应用TF-IDF的示例
假设我们有以下三个文档:
文档1:我 喜欢 学习 机器学习
文档2:机器学习 是 很 有趣 的
文档3:我 喜欢 编程 和 机器学习
第一步:计算每个词的词频(TF)
计算每个文档中每个词的词频:
文档1:我 喜欢 学习 机器学习
我:1/4 = 0.25
喜欢:1/4 = 0.25
学习:1/4 = 0.25
机器学习:1/4 = 0.25
文档2:机器学习 是 很 有趣 的
机器学习:1/5 = 0.20
是:1/5 = 0.20
很:1/5 = 0.20
有趣:1/5 = 0.20
的:1/5 = 0.20
文档3:我 喜欢 编程 和 机器学习
我:1/5 = 0.20
喜欢:1/5 = 0.20
编程:1/5 = 0.20
和:1/5 = 0.20
机器学习:1/5 = 0.20
第二步:计算逆文档频率(IDF)
文档1:我 喜欢 学习 机器学习
文档2:机器学习 是 很 有趣 的
文档3:我 喜欢 编程 和 机器学习
计算IDF:
机器学习:log(3 / (1 + 3)) = log(3 / 4) = -0.124
我:log(3 / (1 + 2)) = log(3 / 3) = 0
喜欢:log(3 / (1 + 2)) = log(3 / 3) = 0
学习:log(3 / (1 + 1)) = log(3 / 2) = 0.176
是:log(3 / (1 + 1)) = log(3 / 2) = 0.176
很:log(3 / (1 + 1)) = log(3 / 2) = 0.176
有趣:log(3 / (1 + 1)) = log(3 / 2) = 0.176
的:log(3 / (1 + 1)) = log(3 / 2) = 0.176
编程:log(3 / (1 + 1)) = log(3 / 2) = 0.176
和:log(3 / (1 + 1)) = log(3 / 2) = 0.176
第三步:计算每个词的TF-IDF
将每个词的词频乘以其逆文档频率:
文档1:我 喜欢 学习 机器学习
我:0.25 * 0 = 0
喜欢:0.25 * 0 = 0
学习:0.25 * 0.176 = 0.044
机器学习:0.25 * -0.124 = -0.031
文档2:机器学习 是 很 有趣 的
机器学习:0.20 * -0.124 = -0.0248
是:0.20 * 0.176 = 0.0352
很:0.20 * 0.176 = 0.0352
有趣:0.20 * 0.176 = 0.0352
的:0.20 * 0.176 = 0.0352
文档3:我 喜欢 编程 和 机器学习
我:0.20 * 0 = 0
喜欢:0.20 * 0 = 0
编程:0.20 * 0.176 = 0.0352
和:0.20 * 0.176 = 0.0352
机器学习:0.20 * -0.124 = -0.0248
详细分析
通过正确的TF-IDF计算,我们可以更准确地确定每个文档中最重要的词语。
文档1分析:
- “学习”的TF-IDF值最高(0.044),表明在文档1中,“学习”是最重要的词语。
- “我”和“喜欢”的TF-IDF值为0,因为它们在多个文档中都很常见。
- “机器学习”的TF-IDF值为-0.031,表明它虽然在文档中出现,但在所有文档中都很常见,因此在区分这个文档时并不重要。
文档2分析:
- “是”、“很”、“有趣”、“的”这四个词的TF-IDF值相同(0.0352),表明它们在文档2中同等重要。
- “机器学习”的TF-IDF值为-0.0248,同样因为它在所有文档中都很常见。
文档3分析:
- “编程”和“和”的TF-IDF值最高(0.0352),表明它们在文档3中最重要。
- “我”和“喜欢”的TF-IDF值为0,因为它们在多个文档中都很常见。
- “机器学习”的TF-IDF值为-0.0248,同样因为它在所有文档中都很常见。
应用TF-IDF结果
这些TF-IDF值帮助我们更准确地理解每个文档的关键内容和主题。例如:
- 在文档1中,“学习”是关键词,可以推测文档的主题是学习相关内容。
- 在文档2中,“是”、“很”、“有趣”、“的”这几个词同等重要,可能表示文档在描述机器学习的有趣性。
- 在文档3中,“编程”和“和”是关键词,可以推测文档的主题涉及编程和机器学习的关系。
通过这些TF-IDF值,我们可以更有效地进行文本分类、主题提取和信息检索,提高处理文本数据的准确性和效率。
相关文章:

机器学习 - 文本特征处理之 TF 和 IDF
TF(Term Frequency,词频)和IDF(Inverse Document Frequency,逆文档频率)是文本处理和信息检索中的两个重要概念,常用于计算一个词在文档中的重要性。下面是详细解释: TF(…...
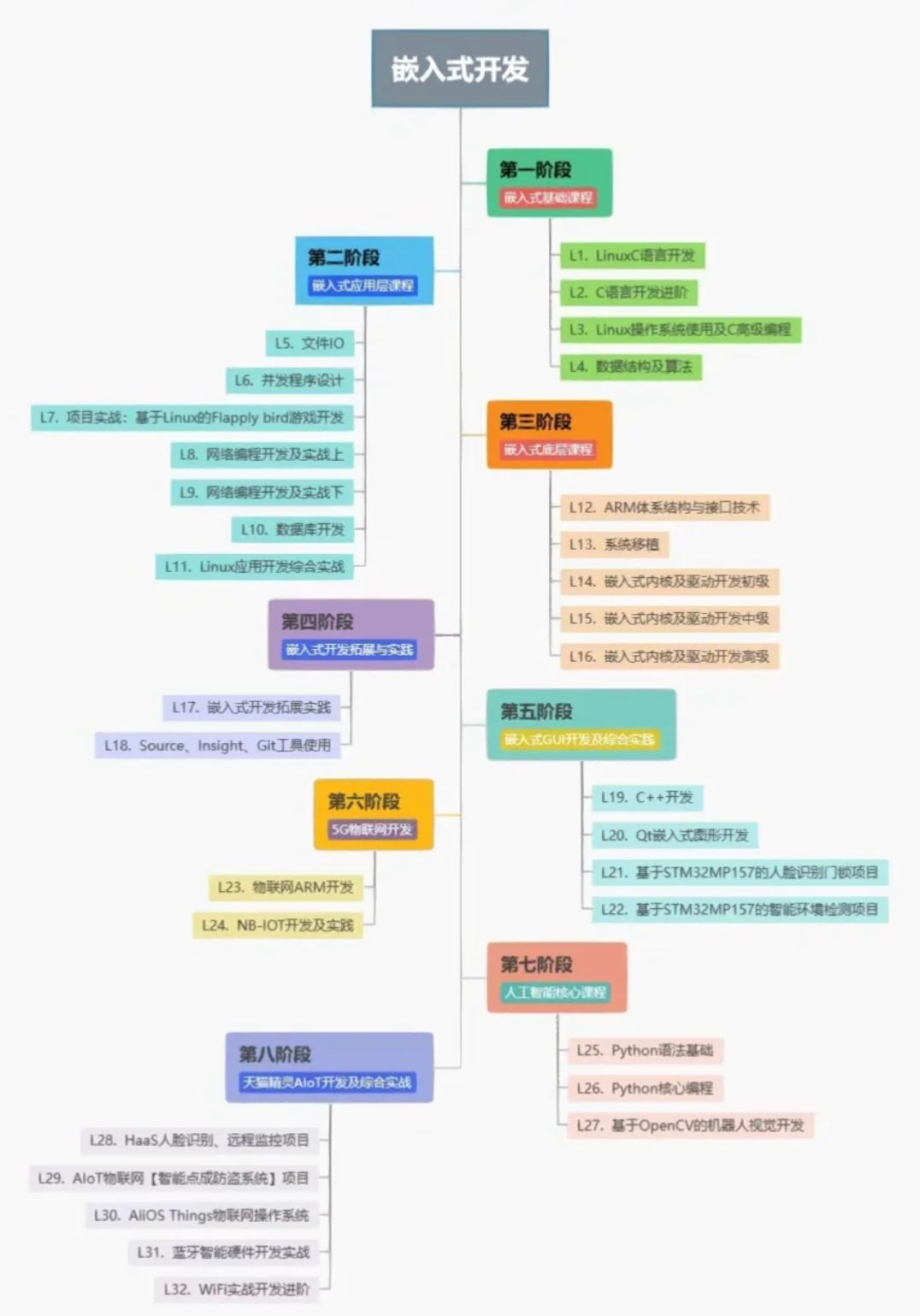
因为自己淋过雨所以想给嵌入式撑把伞
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「嵌入式的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!!新手学嵌入式,…...

《C++20设计模式》中单例模式
文章目录 一、前言二、饿汉式1、实现 三、懒汉式1、实现 四、最后 一、前言 单例模式定义: 单例模式(Singleton Pattern)是一种创建型设计模式,其主要目的是确保一个类只有一个实例,并提供全局访问点来访问这个实例。…...
前端技术(说明篇)
Introduction ##编写内容:1.前端概念梳理 2.前端技术种类 3.前端学习方式 ##编写人:贾雯爽 ##最后更新时间:2024/07/01 Overview 最近在广州粤嵌进行实习,项目名称是”基于Node实现多人聊天室“,主要内容是对前端界…...
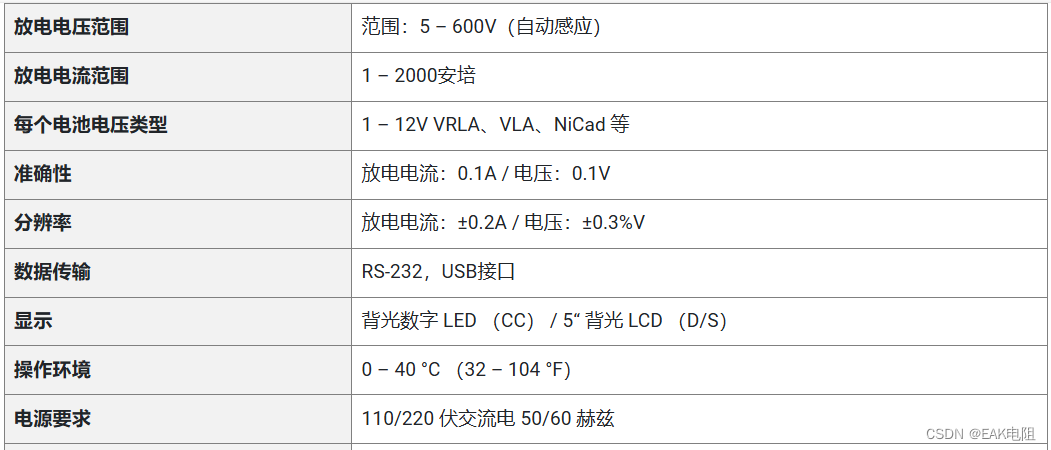
带电池监控功能的恒流直流负载组
EAK的交流和直流工业电池负载组测试仪对于测试和验证关键电力系统的能力至关重要,旨在实现最佳精度。作为一家客户至上的公司,我们继续尽我们所能应对供应链挑战,以提供出色的交货时间,大约是行业其他公司的一半。 交流负载组 我…...

关于Disruptor监听策略
Disruptor框架提供了多种等待策略,每种策略都有其适用的场景和特点。以下是这些策略的详细介绍及其适用场景: 1. BlockingWaitStrategy 特点: 使用锁和条件变量进行线程间通信,线程在等待时会进入阻塞状态,释放CPU资…...
)
大数据面试题之HBase(3)
HBase的预分区 HBase的热点问题 HBase的memstore冲刷条件 HBase的MVCC HBase的大合并与小合并,大合并是如何做的?为什么要大合并 既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase HBase和Phoenix的区别 HBase支…...

c#中赋值、浅拷贝和深拷贝
在 C# 编程中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是用于复制对象的两种不同方式,它们在处理对象时有着重要的区别和适用场景。 浅拷贝(Shallow Copy) 浅拷贝是指创建一个新对…...

旧版st7789屏幕模块 没有CS引脚的天坑 已解决!!!
今天解决了天坑一个,大家可能有的人买的是st7789屏幕模块,240x240,1.3寸的 他标注的是老版,没有CS引脚,小崽子长这样: 这熊孩子用很多通用的驱动不吃,死活不显示,网上猛搜ÿ…...

激光粒度分析仪校准步骤详解:提升测量精度的秘诀
在材料科学、环境监测、医药研发等众多领域,激光粒度分析仪以其高精度、高效率的测量性能,成为了不可或缺的测试工具。然而,为了保持其测量结果的准确性和可靠性,定期校准是不可或缺的步骤。 接下来,佰德将为您详细介…...

独一无二的设计模式——单例模式(python实现)
1. 引言 大家好,今天我们来聊聊设计模式中的“独一无二”——单例模式。想象一下,我们在开发一个复杂的软件系统,需要一个全局唯一的配置管理器,或者一个统一的日志记录器;如果每次使用这些功能都要创建新的实例&…...
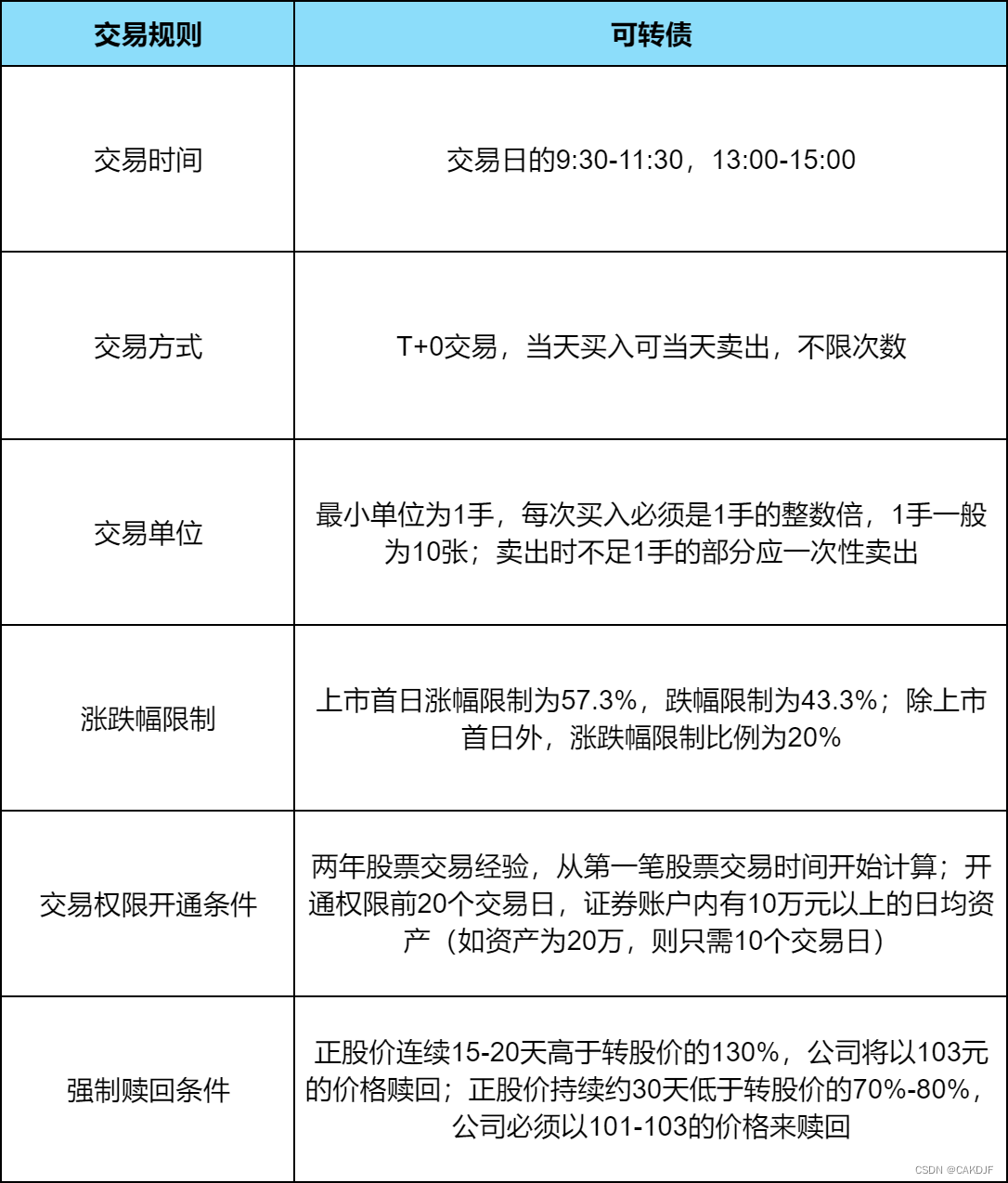
第二证券:可转债基础知识?想玩可转债一定要搞懂的交易规则!
可转债,全称是“可转化公司债券”,是上市公司为了融资,向社会公众所发行的一种债券,具有股票和债券的双重特点,投资者可以选择按照发行时约定的价格将债券转化成公司一般股票,也可作为债券持有到期后收取本…...

原型模式的实现
1. 引言 1.1 背景 在实际编程中,有时需要频繁创建多个相似但稍有不同的对象。如果采用传统的对象创建方式,容易造成代码冗余,对象重复初始化操作也可能带来大量的的资源消耗(如时间、内存等)。这样不仅降低了灵活性,导致难以适应状态的变化,还降低了代码的可扩展性。 …...

【第二套】华为 2024 年校招-硬件电源岗
1.为了避免 50Hz 的电⽹电压⼲扰放⼤器,应该⽤那种滤波器: A.带阻滤波器 B.带通滤波器 C.低通滤波器 D.⾼通滤波器 2.PID 中的 I 和 D 的作⽤分别是? A、消除静态误差和提⾼动态性能 B、消除静态误差和减⼩调节时间 C、提⾼动态性能和减⼩超调…...
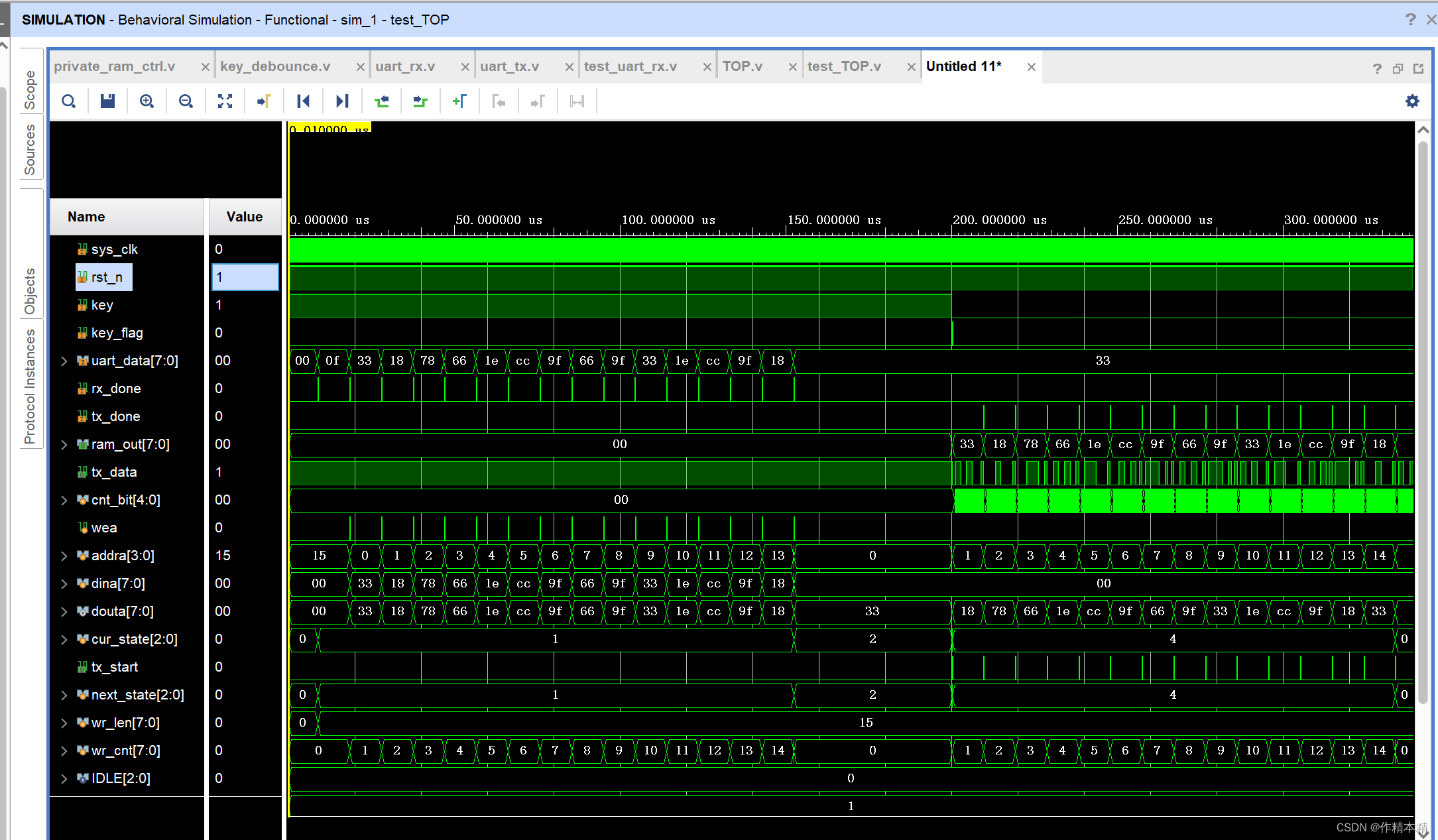
Xilinx FPGA:vivado利用单端RAM/串口传输数据实现自定义私有协议
一、项目要求 实现自定义私有协议,如:pc端产生数据:02 56 38 ,“02”代表要发送数据的个数,“56”“38”需要写进RAM中。当按键信号到来时,将“56”“38”读出返回给PC端。 二、信号流向图 三、状态…...

Spark on k8s 源码解析执行流程
Spark on k8s 源码解析执行流程 1.通过spark-submit脚本提交spark程序 在spark-submit脚本里面执行了SparkSubmit类的main方法 2.运行SparkSubmit类的main方法,解析spark参数,调用submit方法 3.在submit方法里调用doRunMain方法,最终调用r…...

粤港联动,北斗高质量国际化发展的重要机遇
今年是香港回归27周年,也是《粤港澳大湾区发展规划纲要》公布5周年,5年来各项政策、平台不断为粤港联动增添新动能。“十四五”时期的粤港澳大湾区,被国家赋予了更重大的使命,国家“十四五”《规划纲要》提出,以京津冀…...

Chrome导出cookie的实战教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

视频文字转语音经验笔记
自媒体视频制作的一些小经验,分享给大家。 一、音频部分: 1、文字转语音阐述: 微软语音识别 云希-青年男, 0.5-0.8变速 。注:云泽-中年男(不支持长音频录制), 适合郑重场合&#…...

视频融合共享平台LntonCVS统一视频接入平台智慧安防应用方案
安防视频监控平台LntonCVS是一款拥有强大拓展性和灵活部署能力的综合管理平台。它支持多种主流标准协议,包括国标GB28181、RTSP/Onvif、RTMP等,同时兼容各厂家的私有协议和SDK,如海康Ehome、海大宇等。LntonCVS不仅具备传统安防视频监控功能&…...

Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生
Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...
CircuitPython与NeoPixel实战:从硬件连接到动态灯光效果
1. 项目概述:用Python点亮你的硬件创意如果你玩过Arduino,可能会觉得C/C的语法和库管理有点门槛;如果你熟悉Python,又觉得它和硬件之间隔着一层纱。那么,当Raspberry Pi Pico这块性价比极高的微控制器,遇上…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

KMS智能激活终极指南:如何一键永久激活Windows和Office
KMS智能激活终极指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次重装系统后都要重新激活Office&…...

【c++面向对象编程】第24篇:类型转换运算符:自定义隐式转换与explicit
目录 一、一个自然的想法 二、类型转换运算符的基本语法 写法 使用 三、隐式转换的风险 问题1:意外的不希望发生的转换 问题2:多个转换路径的歧义 问题3:与构造函数隐式转换叠加导致混乱 四、explicit:禁止隐式转换 语法…...

Linux磁盘挂载与开机自启配置
Linux磁盘挂载与开机自启配置磁盘挂载是 Linux 存储管理中的基础操作。很多线上问题都与挂载配置有关,例如重启后数据盘没挂上、路径指向错误分区、应用因挂载点缺失而启动失败。中级阶段不仅要会临时挂载,更要理解永久挂载的配置方式和风险控制。一、先…...

LC-SLM高精度波面生成:从原理、标定到闭环校正的完整指南
1. 项目概述与核心价值最近在实验室里折腾一个光学精密测量项目,核心需求是生成一个特定形状、高精度的光波面。这玩意儿在光学检测、自适应光学、全息成像甚至一些前沿的微纳加工领域都是刚需。比如,你想检测一个非球面镜的面形误差,最直接的…...

如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南
如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...