使用 PyTorch 创建的多步时间序列预测的 Encoder-Decoder 模型
Encoder-decoder 模型在序列到序列的自然语言处理任务(如语言翻译等)中提供了最先进的结果。多步时间序列预测也可以被视为一个 seq2seq 任务,可以使用 encoder-decoder 模型来处理。本文提供了一个用于解决 Kaggle 时间序列预测任务的 encoder-decoder 模型,并介绍了获得前 10% 结果所涉及的步骤。
数据集
所使用的数据集来自过去的 Kaggle 竞赛 —— Store Item demand forecasting challenge,给定过去 5 年的销售数据(从 2013 年到 2017 年)的 50 个商品来自 10 家不同的商店,预测接下来 3 个月(2018 年 1 月 1 日至 2018 年 3 月 31 日)每个商品的销售情况。这是一个多步多元的时间序列预测问题。

特征也非常的少
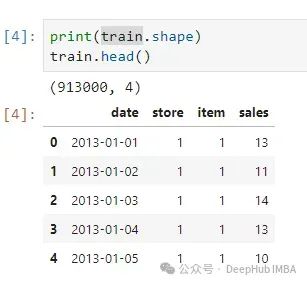
有500个商店组合,这意味着要预测500个时间序列。
数据预处理
深度学习模型擅长自行发现特征,因此可以将特征工程简化到最少。
从图表中可以看出,我们的数据具有每周和每月的季节性以及每年的趋势,为了捕捉这些特性,可以向模型提供DateTime 特征。为了更好地捕捉每个商品销售的年度趋势,还提供了年度自相关性。
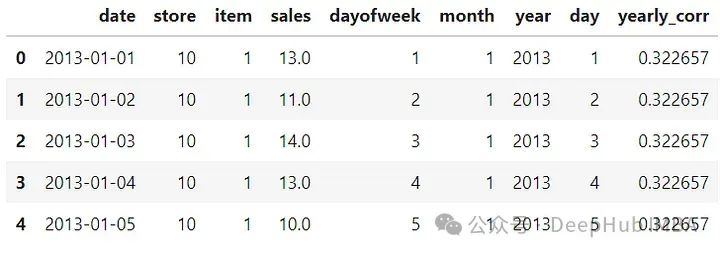
时间的特征是有周期性的,为了将这些信息提供给模型,对 DateTime 特征应用了正弦和余弦变换。
最终的特征如下所示。
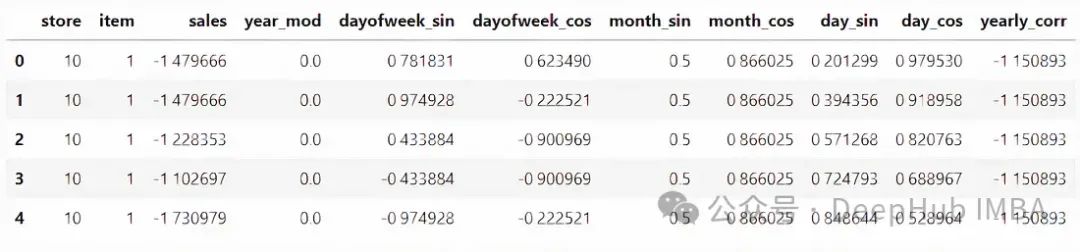
神经网络期望所有特征的值都在相同的尺度上,因此数据缩放变得必不可少。每个时间序列的值都是独立归一化的。年度自相关和年份也进行了归一化。
Encoder-decoder 模型接受一个序列作为输入并返回一个序列作为输出,所以需要将数据转为序列
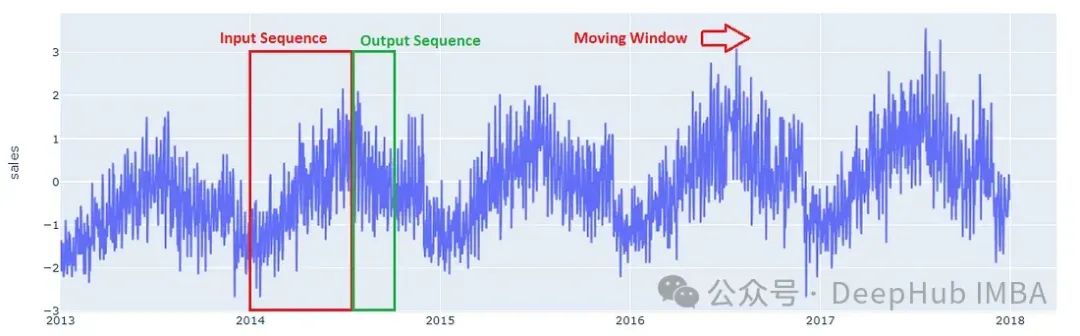
输出序列的长度固定为 90 天,而输入序列的长度必须根据问题的复杂性和可用的计算资源来选择。对于这个问题,可以选择 180 天(6 个月)的输入序列长度。通过在数据集中的每个时间序列上应用滑动窗口来构建序列数据。
数据集和数据加载器
Pytorch 提供了方便的抽象 —— Dataset 和 Dataloader —— 用于将数据输入模型。Dataset 接受序列数据作为输入,并负责构建每个数据点以输入到模型中。Dataloader 则可以读取Dataset 生成批量的数据
class StoreItemDataset(Dataset):def __init__(self, cat_columns=[], num_columns=[], embed_vector_size=None, decoder_input=True, ohe_cat_columns=False):super().__init__()self.sequence_data = Noneself.cat_columns = cat_columnsself.num_columns = num_columnsself.cat_classes = {}self.cat_embed_shape = []self.cat_embed_vector_size = embed_vector_size if embed_vector_size is not None else {}self.pass_decoder_input=decoder_inputself.ohe_cat_columns = ohe_cat_columnsself.cat_columns_to_decoder = Falsedef get_embedding_shape(self):return self.cat_embed_shapedef load_sequence_data(self, processed_data):self.sequence_data = processed_datadef process_cat_columns(self, column_map=None):column_map = column_map if column_map is not None else {}for col in self.cat_columns:self.sequence_data[col] = self.sequence_data[col].astype('category')if col in column_map:self.sequence_data[col] = self.sequence_data[col].cat.set_categories(column_map[col]).fillna('#NA#')else:self.sequence_data[col].cat.add_categories('#NA#', inplace=True)self.cat_embed_shape.append((len(self.sequence_data[col].cat.categories), self.cat_embed_vector_size.get(col, 50)))def __len__(self):return len(self.sequence_data)def __getitem__(self, idx):row = self.sequence_data.iloc[[idx]]x_inputs = [torch.tensor(row['x_sequence'].values[0], dtype=torch.float32)]y = torch.tensor(row['y_sequence'].values[0], dtype=torch.float32)if self.pass_decoder_input:decoder_input = torch.tensor(row['y_sequence'].values[0][:, 1:], dtype=torch.float32)if len(self.num_columns) > 0:for col in self.num_columns:num_tensor = torch.tensor([row[col].values[0]], dtype=torch.float32)x_inputs[0] = torch.cat((x_inputs[0], num_tensor.repeat(x_inputs[0].size(0)).unsqueeze(1)), axis=1)decoder_input = torch.cat((decoder_input, num_tensor.repeat(decoder_input.size(0)).unsqueeze(1)), axis=1)if len(self.cat_columns) > 0:if self.ohe_cat_columns:for ci, (num_classes, _) in enumerate(self.cat_embed_shape):col_tensor = torch.zeros(num_classes, dtype=torch.float32)col_tensor[row[self.cat_columns[ci]].cat.codes.values[0]] = 1.0col_tensor_x = col_tensor.repeat(x_inputs[0].size(0), 1)x_inputs[0] = torch.cat((x_inputs[0], col_tensor_x), axis=1)if self.pass_decoder_input and self.cat_columns_to_decoder:col_tensor_y = col_tensor.repeat(decoder_input.size(0), 1)decoder_input = torch.cat((decoder_input, col_tensor_y), axis=1)else:cat_tensor = torch.tensor([row[col].cat.codes.values[0] for col in self.cat_columns],dtype=torch.long)x_inputs.append(cat_tensor)if self.pass_decoder_input:x_inputs.append(decoder_input)y = torch.tensor(row['y_sequence'].values[0][:, 0], dtype=torch.float32)if len(x_inputs) > 1:return tuple(x_inputs), yreturn x_inputs[0], y
模型架构
Encoder-decoder 模型是一种用于解决序列到序列问题的循环神经网络(RNN)。
Encoder-decoder 模型由两个网络组成——编码器(Encoder)和解码器(Decoder)。编码器网络学习(编码)输入序列的表示,捕捉其特征或上下文,并输出一个向量。这个向量被称为上下文向量。解码器网络接收上下文向量,并学习读取并提取(解码)输出序列。
在编码器和解码器中,编码和解码序列的任务由一系列循环单元处理。
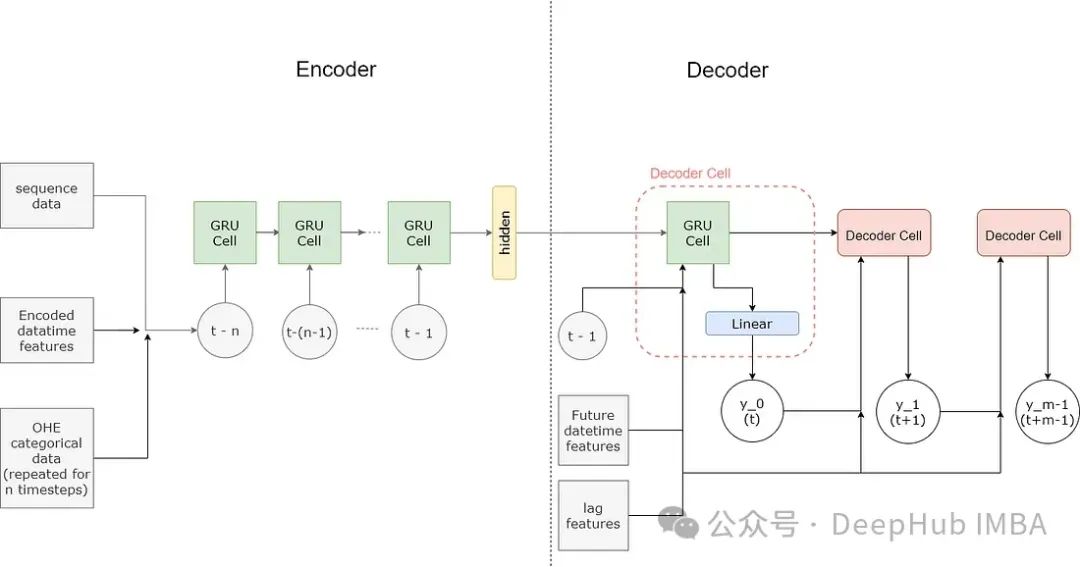
编码器
编码器网络的输入形状为(序列长度,特征维度),因此序列中的每个项目由 n 个值组成。在构建这些值时,不同类型的特征被不同对待。
时间依赖特征 — 这些是随时间变化的特征,如销售和 DateTime 特征。在编码器中,每个连续的时间依赖值被输入到一个 RNN 单元中。
数值特征 — 不随时间变化的静态特征,如序列的年度自相关。这些特征在序列的长度中重复,并被输入到 RNN 中。重复和合并值的过程在 Dataset 中处理。
分类特征 — 如商店 ID 和商品 ID 等特征,可以通过多种方式处理,每种方法的实现可以在 encoders.py 中找到。对于最终模型,分类变量进行了独热编码,跨序列重复,并被输入到 RNN 中,这也在 Dataset 中处理。
带有这些特征的输入序列被输入到循环网络 — GRU 中。下面给出了使用的编码器网络的代码。
class RNNEncoder(nn.Module):def __init__(self, rnn_num_layers=1, input_feature_len=1, sequence_len=168, hidden_size=100, bidirectional=False, device='cpu', rnn_dropout=0.2):super().__init__()self.sequence_len = sequence_lenself.hidden_size = hidden_sizeself.input_feature_len = input_feature_lenself.num_layers = rnn_num_layersself.rnn_directions = 2 if bidirectional else 1self.gru = nn.GRU(num_layers=rnn_num_layers,input_size=input_feature_len,hidden_size=hidden_size,batch_first=True,bidirectional=bidirectional,dropout=rnn_dropout)self.device = devicedef forward(self, input_seq):ht = torch.zeros(self.num_layers * self.rnn_directions, input_seq.size(0), self.hidden_size, device=self.device)if input_seq.ndim < 3:input_seq.unsqueeze_(2)gru_out, hidden = self.gru(input_seq, ht)print(gru_out.shape)print(hidden.shape)if self.rnn_directions * self.num_layers > 1:num_layers = self.rnn_directions * self.num_layersif self.rnn_directions > 1:gru_out = gru_out.view(input_seq.size(0), self.sequence_len, self.rnn_directions, self.hidden_size)gru_out = torch.sum(gru_out, axis=2)hidden = hidden.view(self.num_layers, self.rnn_directions, input_seq.size(0), self.hidden_size)if self.num_layers > 0:hidden = hidden[-1]else:hidden = hidden.squeeze(0)hidden = hidden.sum(axis=0)else:hidden.squeeze_(0)return gru_out, hidden
解码器
解码器接收来自编码器的上下文向量,解码器的输入还包括未来的 DateTime 特征和滞后特征。模型中使用的滞后特征是前一年的值。使用滞后特征的原因是,鉴于输入序列仅限于 180 天,提供超出此时间的重要数据点将有助于模型。
不同于直接使用循环网络(GRU)的编码器,解码器是通过循环一个解码器单元来构建的。这是因为从每个解码器单元获得的预测作为输入传递给下一个解码器单元。每个解码器单元由一个 GRUCell 组成,其输出被输入到一个全连接层,该层提供预测。每个解码器单元的预测被组合形成输出序列。
class DecoderCell(nn.Module):def __init__(self, input_feature_len, hidden_size, dropout=0.2):super().__init__()self.decoder_rnn_cell = nn.GRUCell(input_size=input_feature_len,hidden_size=hidden_size,)self.out = nn.Linear(hidden_size, 1)self.attention = Falseself.dropout = nn.Dropout(dropout)def forward(self, prev_hidden, y):rnn_hidden = self.decoder_rnn_cell(y, prev_hidden)output = self.out(rnn_hidden)return output, self.dropout(rnn_hidden)
Encoder-Decoder模型
下面代码将上面2个模型整合完成完整的seq2seq模型
class EncoderDecoderWrapper(nn.Module):def __init__(self, encoder, decoder_cell, output_size=3, teacher_forcing=0.3, sequence_len=336, decoder_input=True, device='cpu'):super().__init__()self.encoder = encoderself.decoder_cell = decoder_cellself.output_size = output_sizeself.teacher_forcing = teacher_forcingself.sequence_length = sequence_lenself.decoder_input = decoder_inputself.device = devicedef forward(self, xb, yb=None):if self.decoder_input:decoder_input = xb[-1]input_seq = xb[0]if len(xb) > 2:encoder_output, encoder_hidden = self.encoder(input_seq, *xb[1:-1])else:encoder_output, encoder_hidden = self.encoder(input_seq)else:if type(xb) is list and len(xb) > 1:input_seq = xb[0]encoder_output, encoder_hidden = self.encoder(*xb)else:input_seq = xbencoder_output, encoder_hidden = self.encoder(input_seq)prev_hidden = encoder_hiddenoutputs = torch.zeros(input_seq.size(0), self.output_size, device=self.device)y_prev = input_seq[:, -1, 0].unsqueeze(1)for i in range(self.output_size):step_decoder_input = torch.cat((y_prev, decoder_input[:, i]), axis=1)if (yb is not None) and (i > 0) and (torch.rand(1) < self.teacher_forcing):step_decoder_input = torch.cat((yb[:, i].unsqueeze(1), decoder_input[:, i]), axis=1)rnn_output, prev_hidden = self.decoder_cell(prev_hidden, step_decoder_input)y_prev = rnn_outputoutputs[:, i] = rnn_output.squeeze(1)return outputs
训练
模型的性能高度依赖于优化、学习率等超参数和策略
- 验证策略 —— 由于我们的数据是时间依赖的,交叉的训练-验证-测试分割不适用。时间依赖的训练-验证-测试分割存在一个问题,即模型没有在最近的验证数据上进行训练,这影响了模型在测试数据上的表现。为了解决这个问题,模型在过去 3 年的数据(2014 到 2016 年)上进行训练,并预测 2017 年的前 3 个月,这用于验证和实验。最终模型在 2014 到 2017 年的数据上进行训练,并预测 2018 年的前 3 个月。最终模型基于验证模型训练的学习成果,以盲模式(无验证)进行训练。
- 优化器 —— 使用的优化器是 AdamW,它在许多学习任务中提供了最佳结果。另一个探索的优化器是 COCOBOptimizer,它不显式设置学习率。在使用 COCOBOptimizer 训练时,我观察到它比 AdamW 尤其是在初始迭代时收敛更快。但使用 AdamW 和单周期学习得到了最佳结果。
- 学习率调度 —— 使用了 1cycle 学习率调度器。通过使用循环学习的学习率查找器确定了周期中的最大学习率。
- 损失函数 —— 使用的损失函数是均方误差损失(MSE),这与最终测试的损失 —— SMAPE 不同。MSE 损失提供了更稳定的收敛性,优于使用 SMAPE。
- 为编码器和解码器网络使用了不同的优化器和调度器,这带来了结果的改进。
- 除了权重衰减外,还在编码器和解码器中使用了 dropout 来对抗过拟合。
结果
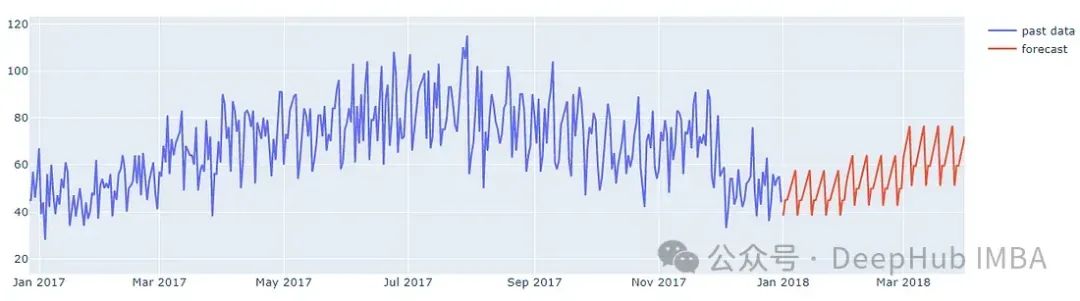
下图显示了该模型对2018年前3个月某家商店单品的预测。
通过绘制所有商品的平均销售额,以及均值预测来去除噪声,可以更好地评估模型。下图来自验证模型对特定日期的预测,可以与实际销售数据进行比较。
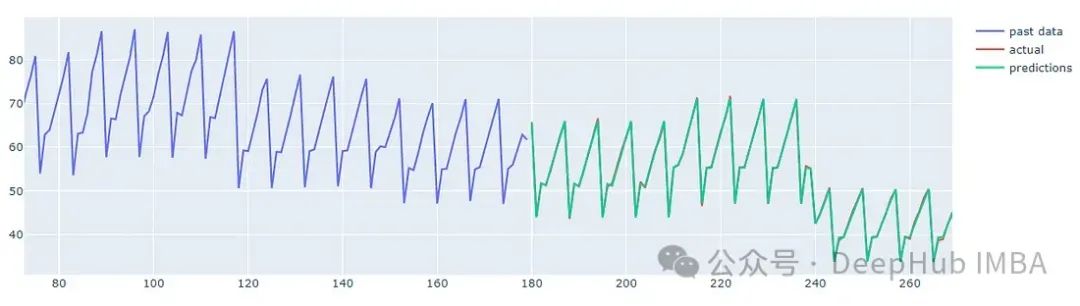
这个结果在竞赛排行榜中提供前10%的排名。

总结
本文演示了使用Encoder-Decoder 模型创建多步时间序列预测的完整步骤,但是为了达到这个结果(10%),作者还做了超参数调优。并且这个模型还没有增加注意力机制,所以还可以通过探索注意机制来进一步改进模型,进一步提高模型的记忆能力,应该能获得更好的分数。
本文代码:
https://avoid.overfit.cn/post/242a897692244172ae44adc15a569647
作者:Gautham Kumaran
相关文章:
使用 PyTorch 创建的多步时间序列预测的 Encoder-Decoder 模型
Encoder-decoder 模型在序列到序列的自然语言处理任务(如语言翻译等)中提供了最先进的结果。多步时间序列预测也可以被视为一个 seq2seq 任务,可以使用 encoder-decoder 模型来处理。本文提供了一个用于解决 Kaggle 时间序列预测任务的 encod…...

开启IT世界的第一步:高考新生的暑期学习指南
目录 前言 了解IT领域 学习编程语言 实践项目 学习资源 阅读专业书籍 培养良好的学习习惯 结语 最后 - 投票 前言 七月的钟声敲响,各省的高考分数已揭晓,意味着一段紧张而又充满奋斗的旅程画上了句号。然而,高考的结束并不意味…...
软考系统架构师高效备考方法论
软考系统架构师高效备考方法论 本章总结的备考方法论也是希望能帮助更多的小伙伴高效的备考最终通过考试,这种考试个人感觉是尽量一次性考过, 要不然老拖着,虽然每年可以考两次,5月和11月,两次考试间隔5个月时间&#…...
【neo4j图数据库】入门实践篇
探索数据之间的奥秘:Neo4j图数据库引领新纪元 在数字化浪潮汹涌的今天,数据已成为企业最宝贵的资产之一。然而,随着数据量的爆炸性增长和数据关系的日益复杂,传统的关系型数据库在处理诸如社交网络、推荐系统、生物信息学等高度互…...

【TS】TypeScript 原始数据类型深度解析
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 TypeScript 原始数据类型深度解析一、引言二、基础原始数据类型2.1 boolean2.2 …...

怎么样调整分类的阈值
调整分类模型的阈值是改变模型对正负类的预测标准的一种方法,常用于提高精确率、召回率或者其他性能指标。以下是如何调整分类阈值的步骤和方法: PS:阈值是针对预测概率(表示样本属于某个特定类别的可能性)来说的 调…...
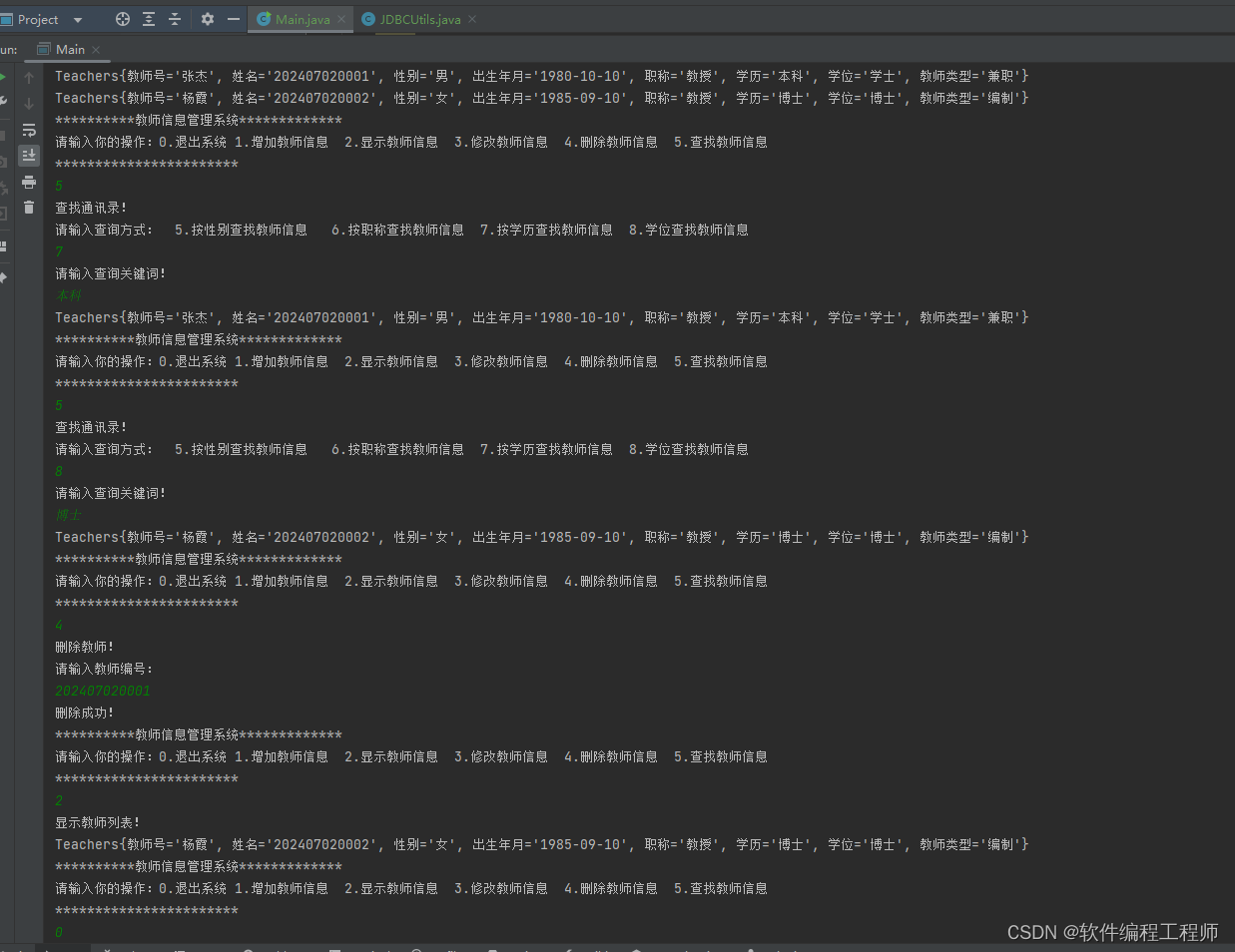
java+mysql教师管理系统
完整源码地址 教师信息管理系统使用命令行交互的方式及数据库连接实现教师信息管理系统,该系统旨在实现教师信息的管理,并根据需要进行教师信息展示。该软件的功能有如下功能 (1)基本信息管理(教师号、姓名、性别、出生年月、职称、学历、学位、教师类型…...

PDF文档如何统计字数,统计PDF文档字数的方法有哪些?
在平时使用pdf阅读或者是处理文档的时候,常常需要统计文档的字数。pdf在查看文字时其实很简单。 PDF文档是一种常见的电子文档格式,如果需要对PDF文档中的字数进行统计,可以使用以下方法: Adobe Acrobat DC:Adobe Ac…...

在Python asyncio中如何识别协程是否被block了
现在asyncio在Python中的使用越来越广泛了,但是很多人对于协程(corotine)的一些使用方式还不太熟悉。在这篇文章中,我将会介绍如何识别协程是否被block了,并以常用的HTTP网络库requests/httpx为例来说明如何避免协程被block的问题。 为什么协程会被block 在Python中,可…...
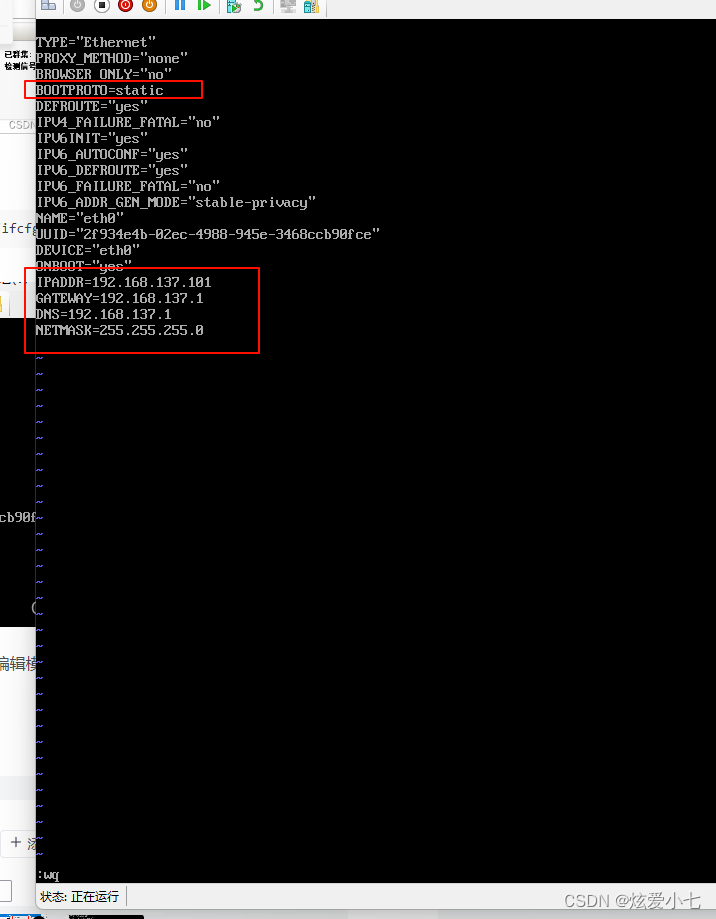
Hyper-V虚拟机固定IP地址(手把手教设置)
链接虚拟机修改网络配置文件 输入指令 sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0 然后 输入 按 i 键 再按回车 (enter) 进入编辑模式 修改配置(这几项)其中 IPADDR 就是你想给虚拟机固定的 IP 地址 多台的话只需要修改这个IP 就行其他不变 BOOTPROTO=static…...

以 Vue 3 项目为例,多个请求下如何全局封装 Loading 的展示与关闭?其中大有学问!
大家好,我是CodeQi! 项目开发中,Loading 的展示与关闭是非常关键的用户体验设计。 当我们的应用需要发起多个异步请求时,如何有效地管理全局 Loading 状态,保证用户在等待数据加载时能有明确的反馈,这是一个值得深入探讨的问题。 本文将以 Vue 3 项目为例,详细讲解如…...
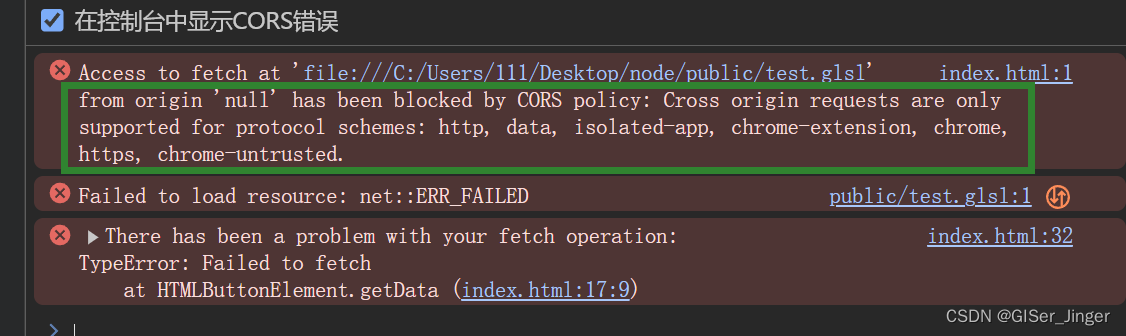
Node.js学习(一)
Node.js安装与入门案例: 需求:点击按钮,请求本地目录指定文件的内容,并显示在页面上 刚入门肯定想着直接写相对路径请求指定路径数据就行了,可是会发现不行。 网页运行在浏览器端,通常后续要发布…...

Spring Data JPA使用及实现原理总结
Spring Data JPA系列 1、SpringBoot集成JPA及基本使用 2、Spring Data JPA Criteria查询、部分字段查询 3、Spring Data JPA数据批量插入、批量更新真的用对了吗 4、Spring Data JPA的一对一、LazyInitializationException异常、一对多、多对多操作 5、Spring Data JPA自定…...

【C语言】extern 关键字
在C语言中,extern关键字用于声明一个变量或函数是定义在另一个文件中的。它使得在多个文件之间共享变量或函数成为可能。extern关键字常见于大型项目中,通常用于声明全局变量或函数,这些变量或函数的定义位于其他文件中。 基本用法 变量声明…...
改变亮度)
Linux--V4L2应用程序开发(二)改变亮度
一、思路流程 创建一个新线程用来控制亮度,线程通过读取用户输入来增加或减少亮度值,并使用 ioctl 函数将新亮度值设置到视频设备。 二、代码 /*创建线程来控制亮度*/ pthread_t thread; pthread_create(&thread, NULL, thread_brightness_contrl…...

[Gstreamer] 消息处理handler的设置
前言: Gstreamer 提供以 GstMessage 和 GstBus 为基础的消息传递机制,所有GstMessage 发送的时候都需要指定 GstBus 用来明确当前 message 将在哪条 Bus 上流转。所有的 GstMessage 最终都会进入一个handler,这个handler函数可以通过两种方式…...

线性代数笔记
行列式 求高阶行列式 可以划上三角 上三角 余子式 范德蒙行列式 拉普拉斯公式 行列式行列对换值不变 矩阵 矩阵的运算 同型矩阵加减 对应位置相加减 矩阵的乘法 左边第 i 行 一次 相乘求和 右边 第 j 列 eg 中间相等 两边规模 矩阵的幂运算 解题思路 找规律 数学归纳…...

未公开 GeoServer开源服务器wfs远程命令执行漏洞 已复现(CVE-2024-36401)
0x01 阅读须知 技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成…...
【WebGIS干货分享】Webgis 面试题-浙江中海达
1、Cesium 中有几种拾取坐标的方式,分别介绍 Cesium 是一个用于创建 3D 地球和地理空间应用的 JavaScript 库。在 Cesium 中,你可以使用不同的方式来拾取坐标,以便与地球或地图上的对象进行交 互。以下是 Cesium 中几种常见的拾取坐标的方式…...

ES 修改索引字段类型
大体的原理: 1:按照老索引按需修改,新建新索引 2:转移数据(数据量大,时间会很长) 3:删除老索引 4:给新索引 创建别名 第一步:创建新索引 可以先获取老索引ma…...

嵌入式Linux系统固化:从启动卡制作到eMMC克隆的工程实践
1. 项目概述:从“启动卡”到“系统固化”的工程实践在嵌入式开发、工业控制、边缘计算乃至一些特定的服务器运维场景里,我们经常会遇到一个看似基础却至关重要的需求:如何将一个完整的Linux操作系统,从一张临时的启动介质…...

动力电池技术迭代:从能量密度到系统集成的多维竞争
1. 动力电池行业的“肌肉”意味着什么最近,行业里关于宁德时代又推出新产品的消息传得沸沸扬扬。作为在这个行业里摸爬滚打了十几年的老兵,每次看到这样的新闻,我的第一反应不是“又来了”,而是“这次他们想解决什么问题ÿ…...

美颜SDK如何选择?直播APP开发最容易忽略的几个问题
这几年,直播行业的竞争已经从“有没有功能”,逐渐演变成了“用户体验够不够好”。很多团队在做直播APP时,往往会把重点放在推流、连麦、礼物、私域运营这些显性功能上,却忽略了一个对用户留存影响极大的核心模块——美颜SDK。尤其…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型指南 对于习惯使用 OpenAI 官方 Python SDK 的开发者来说,…...

3步掌握OmenSuperHub:惠普游戏本性能控制终极指南
3步掌握OmenSuperHub:惠普游戏本性能控制终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿界面…...

ARM TLBIP指令解析与应用实践
1. ARM TLBIP指令深度解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当页表发生变更时,必须及时使TLB中对应的缓存条目失效,以确保内存访问的正…...

【M1 Mac实战】MATLAB R2021b 安装与优化全攻略
1. M1 Mac安装MATLAB R2021b前的准备工作 第一次在M1芯片的Mac上安装MATLAB R2021b时,我遇到了不少坑。这里分享下必须做好的几项准备工作,能帮你节省至少2小时的折腾时间。 首先确认你的系统版本。实测在macOS Monterey(12.0)到V…...

分享一些常见的SQL计算面试题
代码都是基于mysql实现,如果小伙伴们有其他的思路欢迎留言~ 1.行列转换2.分组求top-n3.连续登录问题(包括日期可间断和不可间断)4.找连续出现3次及以上的数字5.直播间同时在线人数统计1.行列转换 表tb1: 表tb2: 行转…...

米尔MYS-8MMX开发板实战:从交叉编译到网络视频监控系统搭建
1. 开箱与初体验:米尔MYS-8MMX开发板印象作为一名在嵌入式领域摸爬滚打多年的开发者,拿到一块新的开发板,那种感觉就像老木匠看到一块上好的木料,总想立刻上手试试它的“成色”。米尔电子这次推出的MYS-8MMX开发板,基于…...

如何高效配置阅读APP书源:完整指南助你轻松获取全网小说资源
如何高效配置阅读APP书源:完整指南助你轻松获取全网小说资源 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 还在为找不到心仪的小说而烦恼吗?想要打造属于自己的个性化阅读环境吗…...