经典的卷积神经网络模型 - ResNet
经典的卷积神经网络模型 - ResNet
flyfish
2015年,何恺明(Kaiming He)等人在论文《Deep Residual Learning for Image Recognition》中提出了ResNet(Residual Network,残差网络)。在当时,随着深度神经网络层数的增加,训练变得越来越困难,主要问题是梯度消失和梯度爆炸现象。即使使用各种优化技术和正则化方法,深层网络的表现仍然不如浅层网络。ResNet通过引入残差块(Residual Block)有效解决了这个问题,使得网络层数可以大幅度增加,同时还能显著提升模型的表现。
经典的卷积神经网络模型 - AlexNet
经典的卷积神经网络模型 - VGGNet
卷积层的输出
1x1卷积的作用
2. 残差(Residual)
在ResNet中,残差指的是输入值与输出值之间的差值。具体来说,假设输入为 x x x,经过一系列变换后的输出为 F ( x ) F(x) F(x),ResNet引入了一条“快捷连接”(shortcut connection),直接将输入 x x x加入到输出 F ( x ) F(x) F(x),最终的输出为 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。这种结构称为残差块(Residual Block)。
3. ResNet的不同版本
ResNet有多个不同版本,后面的数字表示网络层的数量。具体来说:
- ResNet18: 18层
- ResNet34: 34层
- ResNet50: 50层
- ResNet101: 101层
- ResNet152: 152层
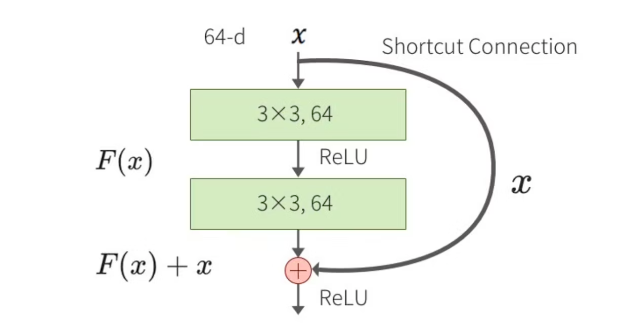
4. 常规残差模块
常规残差模块(Residual Block)包含两个3x3卷积层,每个卷积层后面跟着批归一化(Batch Normalization)和ReLU激活函数。假设输入为 x x x,经过第一层卷积、批归一化和ReLU后的输出为 F 1 ( x ) F_1(x) F1(x),再经过第二层卷积、批归一化后的输出为 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2(F1(x))。最终的输出是输入 x x x和 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2(F1(x))的和,即 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。
ResNet-18和ResNet-34使用的是BasicBlock。
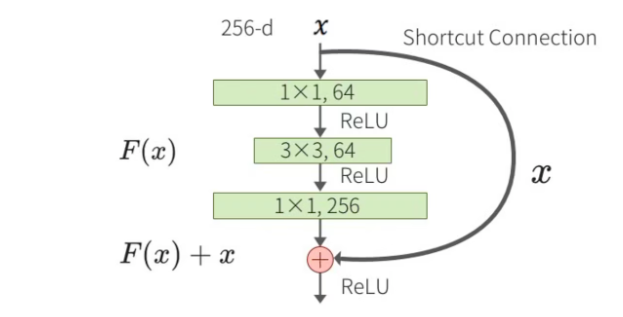
5. 瓶颈残差模块(Bottleneck Residual Block)
瓶颈残差模块用于更深的ResNet版本(如ResNet50及以上),目的是减少计算量和参数量。瓶颈残差模块包含三个卷积层:一个1x1卷积层用于降维,一个3x3卷积层用于特征提取,最后一个1x1卷积层用于升维。假设输入为 x x x,经过1x1卷积降维后的输出为 F 1 ( x ) F_1(x) F1(x),再经过3x3卷积后的输出为 F 2 ( F 1 ( x ) ) F_2(F_1(x)) F2(F1(x)),最后经过1x1卷积升维后的输出为 F 3 ( F 2 ( F 1 ( x ) ) ) F_3(F_2(F_1(x))) F3(F2(F1(x)))。最终的输出是输入 x x x和 F 3 ( F 2 ( F 1 ( x ) ) ) F_3(F_2(F_1(x))) F3(F2(F1(x)))的和,即 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x。ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck。
6. 快捷连接(shortcut connection )
快捷连接(shortcut connection),即直接将输入 x x x加到输出 F ( x ) F(x) F(x)上,从而避免了梯度消失和梯度爆炸问题。
import torchvision.models as models
resnet18 = models.resnet18()
print(resnet18)
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=512, out_features=1000, bias=True)
)
自定义实现ResNet-18
import torch
import torch.nn as nn
import torch.nn.functional as Fclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion * out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * out_channels))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, out_channels, num_blocks, stride):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channels * block.expansionfor _ in range(1, num_blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet18(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)# Example usage
model = resnet18()
print(model)
自定义实现ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152
ResNet-18和ResNet-34使用的是BasicBlock,而ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion * out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * out_channels))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_channels, out_channels, stride=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)self.relu = nn.ReLU(inplace=True)self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels * self.expansion:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels * self.expansion))def forward(self, x):out = self.relu(self.bn1(self.conv1(x)))out = self.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))out += self.shortcut(x)out = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, out_channels, num_blocks, stride):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channels * block.expansionfor _ in range(1, num_blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet18(num_classes=1000):return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)def resnet34(num_classes=1000):return ResNet(BasicBlock, [3, 4, 6, 3], num_classes)def resnet50(num_classes=1000):return ResNet(Bottleneck, [3, 4, 6, 3], num_classes)def resnet101(num_classes=1000):return ResNet(Bottleneck, [3, 4, 23, 3], num_classes)def resnet152(num_classes=1000):return ResNet(Bottleneck, [3, 8, 36, 3], num_classes)# Example usage
model_18 = resnet18()
model_34 = resnet34()
model_50 = resnet50()
model_101 = resnet101()
model_152 = resnet152()print(model_18)
print(model_34)
print(model_50)
print(model_101)
print(model_152)
网络结构
以ResNet18和ResNet50的结构举例
因为ResNet-18和ResNet-34使用的是BasicBlock,ResNet-50、ResNet-101和ResNet-152使用的是Bottleneck,可以区分看。
ResNet18
-
输入:224x224图像
-
卷积层:7x7卷积,64个过滤器,步长2
-
最大池化层:3x3,步长2
-
残差模块:
-
2个Basic Block,每个包含2个3x3卷积层(64个过滤器)
-
2个Basic Block,每个包含2个3x3卷积层(128个过滤器)
-
2个Basic Block,每个包含2个3x3卷积层(256个过滤器)
-
2个Basic Block,每个包含2个3x3卷积层(512个过滤器)
-
-
全局平均池化层
-
全连接层:1000个单元(对应ImageNet的1000个类别)
用参数表示就是 [2, 2, 2, 2]
ResNet50
-
输入:224x224图像
-
卷积层:7x7卷积,64个过滤器,步长2
-
最大池化层:3x3,步长2
-
残差模块:
-
3个Bottleneck Block,每个包含1x1降维、3x3卷积、1x1升维(256个过滤器)
-
4个Bottleneck Block,每个包含1x1降维、3x3卷积、1x1升维(512个过滤器)
-
6个Bottleneck Block,每个包含1x1降维、3x3卷积、1x1升维(1024个过滤器)
-
3个Bottleneck Block,每个包含1x1降维、3x3卷积、1x1升维(2048个过滤器)
-
-
全局平均池化层
-
全连接层:1000个单元(对应ImageNet的1000个类别)
用参数表示就是 [3, 4, 6, 3]
列表参数表示每个阶段(layer)中包含的残差块(residual block)的数量。ResNet的网络结构通常分为多个阶段,每个阶段包含多个残差块。这些残差块可以是常规的(BasicBlock)或瓶颈的(Bottleneck)。具体来说:
[2, 2, 2, 2] 表示第1个阶段有2个残差块,第2个阶段有2个残差块,第3个阶段有2个残差块,第4个阶段有2个残差块。
[3, 4, 6, 3] 表示第1个阶段有3个残差块,第2个阶段有4个残差块,第3个阶段有6个残差块,第4个阶段有3个残差块。
BasicBlock: 实现了常规残差模块,包含两个3x3的卷积层。用于ResNet-18和ResNet-34。
Bottleneck: 实现了瓶颈残差模块,包含一个1x1卷积层、一个3x3卷积层和另一个1x1卷积层。用于ResNet-50、ResNet-101和ResNet-152。
identity shortcut和projection shortcut
import torchvision.models as models
model = models.resnet50()
print(model)
完整内容自行打印看,这里主要说明 identity shortcut和projection shortcut
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))......
在 ResNet 中,identity shortcut 和 projection shortcut 主要出现在 Bottleneck 模块中。
- Identity Shortcut : 这是直接跳过层的快捷方式,输入直接添加到输出。通常在输入和输出维度相同时使用。在模型输出中可以看到,如
layer1的第1和第2个Bottleneck:
(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)
)
可以看到这里没有 downsample 层,所以输入和输出直接相加。
- Projection Shortcut : 这是使用卷积层调整维度的快捷方式,用于当输入和输出维度不同时。在模型输出中可以看到,如
layer1的第0个Bottleneck:
(0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
)
这里有一个 downsample 层,通过卷积和批量归一化调整输入的维度以匹配输出。
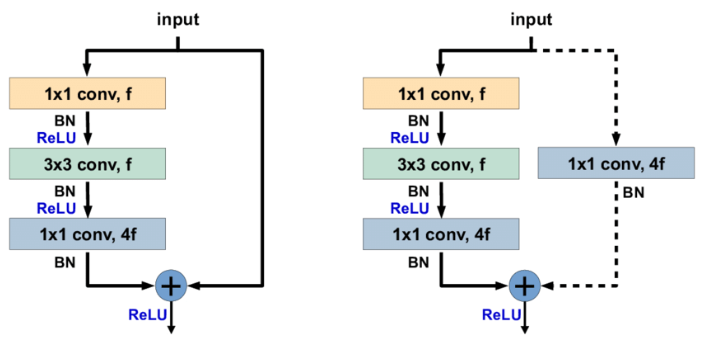
-
Identity Shortcut : 左侧图,没有
downsample层。如果要写上downsample也是(downsample): Sequential()括号里是空的 -
Projection Shortcut :右侧图 有
downsample层,用于调整维度。 比如
(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
Bottleneck 结构中,f 通常表示瓶颈层的过滤器(或通道)数。
在 Bottleneck 模块中,通常有三层卷积:
第一个 1x1 卷积,用于降低维度,通道数是 f。
第二个 3x3 卷积,用于在降低维度的情况下进行卷积操作,通道数也是 f。
第三个 1x1 卷积,用于恢复维度,通道数是 4f。
如果要保证输出的特征图大小是固定的(如 1x1),自适应平均池化或者全局平均池化是最常用的选择;如果要调整通道数并保持空间结构,则可以用 1x1 卷积和池化的组合。
无论输入的特征图大小是多少,自适应平均池化都可以将其调整到一个指定的输出大小。在 ResNet 中使用的 AdaptiveAvgPool2d(output_size=(1, 1)) 会将输入的特征图调整到大小为 1x1。通过将特征图大小固定,可以更容易地设计网络结构,尤其是全连接层的输入部分。例如,将特征图调整到 1x1 后,后面的全连接层只需要处理固定数量的特征,不用考虑输入图像的大小变化。在特征图被调整到较小的大小(例如 1x1)后,随后的全连接层所需的参数和计算量会显著减少。
相关文章:
经典的卷积神经网络模型 - ResNet
经典的卷积神经网络模型 - ResNet flyfish 2015年,何恺明(Kaiming He)等人在论文《Deep Residual Learning for Image Recognition》中提出了ResNet(Residual Network,残差网络)。在当时,随着…...

【Git 学习笔记】1.3 Git 的三个阶段
1.3 Git 的三个阶段 由于远程代码库后续存在新的提交,因此实操过程中的结果与书中并不完全一致。根据书中 HEAD 指向的 SHA-1:34acc370b4d6ae53f051255680feaefaf7f7850d,可通过以下命令切换到对应版本,并新建一个 newdemo 分支来…...

华为DCN之:SDN和NFV
1. SDN概述 1.1 SDN的起源 SDN(Software Defined Network)即软件定义网络。是由斯坦福大学Clean Slate研究组提出的一种新型网络创新架构。其核心理念通过将网络设备控制平面与数据平面分离,从而实现了网络控制平面的集中控制,为…...
黑马头条-数据管理平台
目录 项目准备 验证码登录 验证码登录-流程 token 的介绍 个人信息设置和 axios 请求拦截器 axios 响应拦截器和身份验证失败 优化-axios 响应结果 发布文章-富文本编辑器 项目准备 技术: • 基于 Bootstrap 搭建网站标签和样式 • 集成 wangEditor 插件…...

API Object设计模式
API测试面临的问题 API测试由于编写简单,以及较高的稳定性,许多公司都以不同工具和框架维护API自动化测试。我们基于seldom框架也积累了几千条自动化用例。 •简单的用例 import seldomclass TestRequest(seldom.TestCase):def test_post_method(self…...

Python 爬虫:多进程,多线程爬虫<提高爬取效率>
关于多进程,多线程的知识,请自行查询资料补充 ~~~~~~~~~~~ 使用多进程: 在python中,使用多进程需要先导包: from threding import Threaddef work(name):for i in range(1000):print(f"我是线程:{n…...
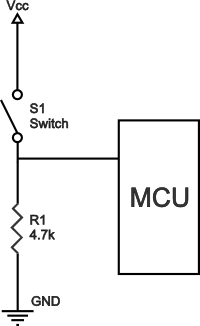
什么是上拉电阻器?上拉和下拉电阻的典型应用
什么是上拉电阻器? 上拉电阻是逻辑电路中使用的电阻,用于确保引脚在所有条件下具有明确定义的逻辑电平。提醒一下,数字逻辑电路有三种逻辑状态:高、低和浮动(或高阻抗)。当引脚未被拉至高或低逻辑电平&…...

centos7安装python3.10
文章目录 1. 安装依赖项2. 下载Python 3.10源码3. 解压源码并进入目录4. 配置安装选项5. 编译并安装Python6. 验证安装7.创建软连接8. 安装pip39. 换源 1. 安装依赖项 sudo yum groupinstall -y "Development Tools" sudo yum install -y openssl-devel bzip2-devel…...

QT事件处理及实例(鼠标事件、键盘事件、事件过滤)
这篇文章通过鼠标事件、键盘事件和事件过滤的三个实例介绍事件处理的实现。 鼠标事件及实例 鼠标事件包括鼠标的移动、按下、松开、单击和双击等。 创建一个MouseEvent项目,通过项目介绍如何获得和处理鼠标事件。程序效果如下图所示。 界面布局代码如下ÿ…...

职场新人必备待办工具 高效待办工作更省心
作为一名初入职场的菜鸟,我曾被繁琐的工作任务压得喘不过气。每天,邮件、会议、项目任务像潮水般涌来,我常常感到力不从心,生怕遗漏了什么重要事项。那种焦虑,就像站在人来人往的地铁站,却不知道自己该搭乘…...

【创作纪念日】我的CSDN1024创作纪念
机缘 注册CSDN是很长时间了,但是上学时因为专业是电气工程,与编程打交道比较少,一直都是寻求帮助,而非内容输出。直到考研后专业改变,成为了主要跟软件编程、计算机知识相关的研究后,才逐步开启自己的CSDN…...
在AvaotaA1全志T527开发板上使用 UART 连接开发板
连接开发板 AvaotaA1提供两种连接串口输出方式,因为AvaotaA1需要DC 12V/2A/5.5-2.1电源适配器才可以启动系统,请先确保电源已接通。 方式一: 使用配套的 TyepC-SUB 转接板 40Gbps雷电线标准TypeC数据线,就可以同步实现 USB 串口…...

【Asterinas】Asterinas 进程启动与切换
Asterinas 进程启动与切换 进程启动 进程创建: Rust pub fn spawn_user_process( executable_path: &str, argv: Vec, envp: Vec, ) -> Result<Arc> { // spawn user process should give an absolute path debug_assert!(executable_path.starts_with…...
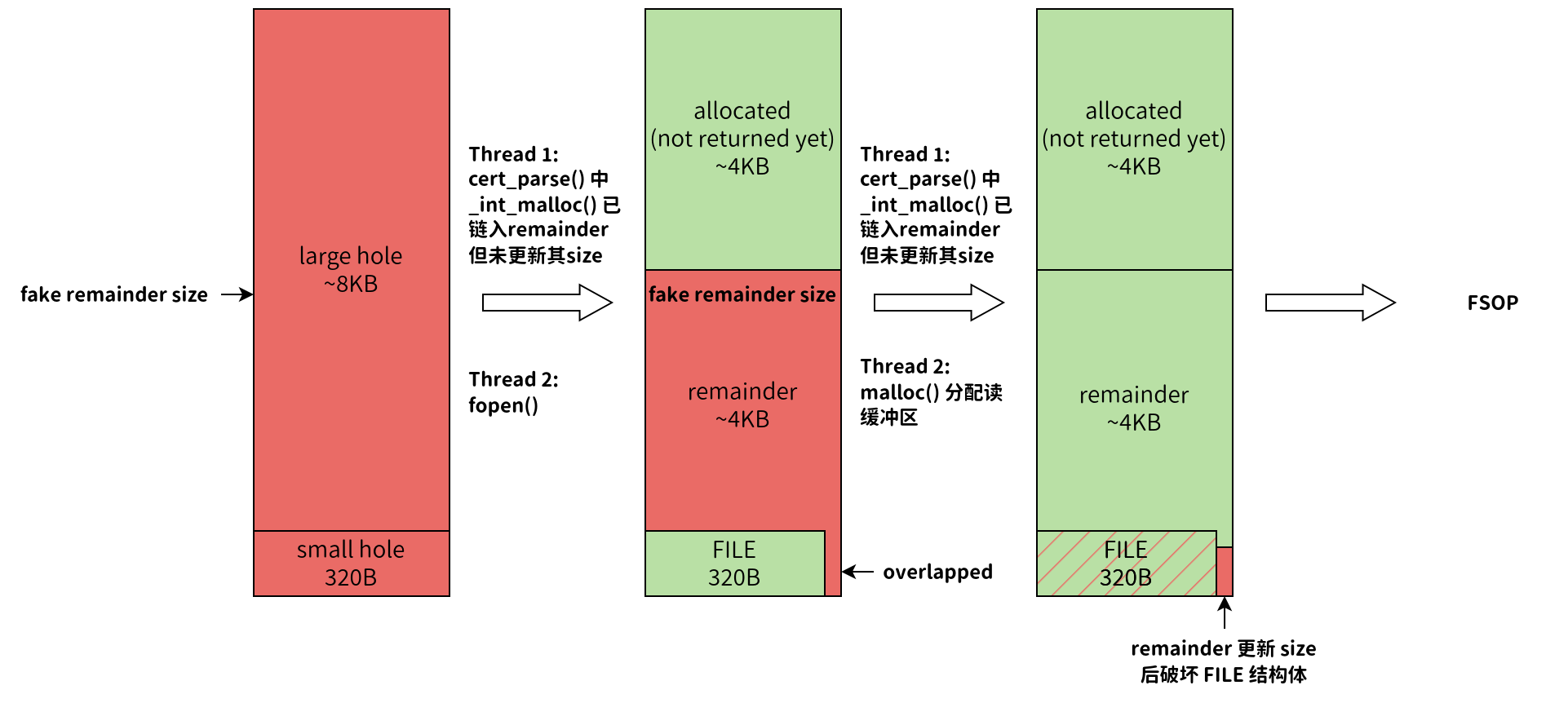
CVE-2024-6387 分析
文章目录 1. 漏洞成因2. 漏洞利用前置知识2.1 相关 SSH 协议报文格式2.2 Glibc 内存分配相关规则 3. POC3.1 堆内存布局3.2 服务端解析数据时间测量3.3 条件竞争3.4 FSOP 4. 相关挑战 原文链接:个人博客 近几天,OpenSSH爆出了一个非常严重的安全漏洞&am…...

STM32 ADC精度提升方法
STM32 ADC精度提升方法 Fang XS.1452512966qq.com如果有错误,希望被指出,学习技术的路难免会磕磕绊绊量的积累引起质的变化 硬件方法 优化布局布线,尽量减小其他干扰增加电源、Vref去耦电容使用低通滤波器,或加磁珠使用DCDC时尽…...
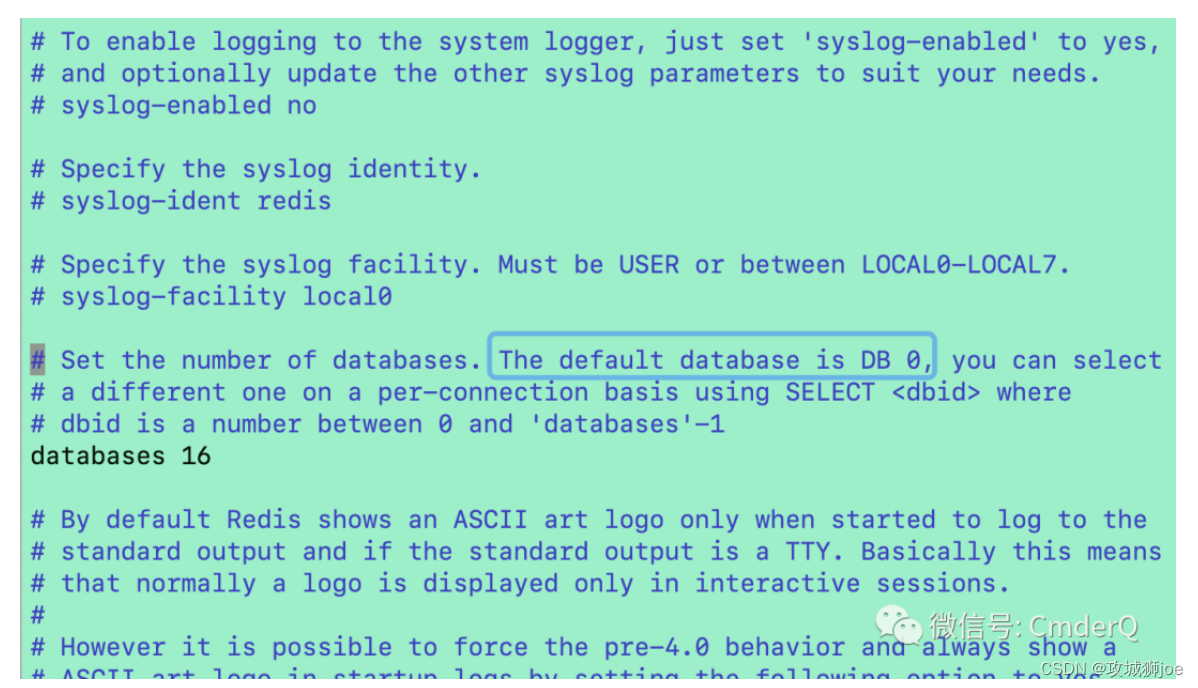
Redis为什么设计多个数据库
关于Redis的知识前面已经介绍过很多了,但有个点没有讲,那就是一个Redis的实例并不是只有一个数据库,一般情况下,默认是Databases 0。 一 内部结构 设计如下: Redis 的源码中定义了 redisDb 结构体来表示单个数据库。这个结构有若干重要字段,比如: dict:该字段存储了…...
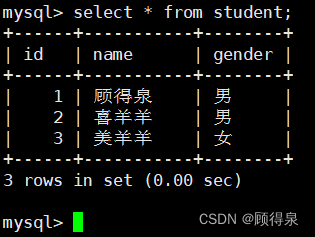
零基础学习MySQL---MySQL入门
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C从入门到精通》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、什么是数据库 问:存储数据用文件就可以了,为什么还要弄个数据库呢? 这就不得不提…...
HUAWEI MPLS 静态配置和动态LDP配置
MPLS(Multi-Protocol Label Switching,多协议标签交换技术)技术的出现,极大地推动了互联网的发展和应用。例如:利用MPLS技术,可以有效而灵活地部署VPN(Virtual Private Network,虚拟专用网),TE(Traffic Eng…...

【Rust】——所有的模式语法
💻博主现有专栏: C51单片机(STC89C516),c语言,c,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux…...

基于Python的求职招聘管理系统【附源码】
摘 要 随着互联网技术的不断发展,人类的生活已经逐渐离不开网络了,在未来的社会中,人类的生活与工作都离不开数字化、网络化、电子化与虚拟化的数字技术。从互联网的发展历史、当前的应用现状和发展趋势来看,我们完全可以肯定&…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...