【Rust】——所有的模式语法
💻博主现有专栏:
C51单片机(STC89C516),c语言,c++,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux,基于HTML5的网页设计及应用,Rust(官方文档重点总结),jQuery,前端vue.js,Javaweb开发,Python机器学习等
🥏主页链接:Y小夜-CSDN博客
目录
🎯匹配字面值
🎯匹配命名变量
🎯多个模式
🎯通过..-=匹配值的范围
🎯解构并分解值
🎃解构结构体
🎃解构枚举
🎃解构嵌套的结构体和枚举
🎃解构结构体和元组
🎯忽略模式中的值
🎃使用_使用忽略整个值
🎃使用嵌套的_忽略部分值
🎃通过在名字前以一个_开头来忽略未使用的变量
🎃用..忽略剩余值
🎯匹配守卫提供的额外条件
🎯@绑定
🎯匹配字面值
可以直接匹配字面值模式。
let x = 1;match x {1 => println!("one"),2 => println!("two"),3 => println!("three"),_ => println!("anything"),}这段代码会打印
one因为x的值是 1。如果希望代码获得特定的具体值,则该语法很有用。
🎯匹配命名变量
命名变量是匹配任何值的不可反驳模式,这在之前已经使用过数次。然而当其用于
match表达式时情况会有些复杂。因为match会开始一个新作用域,match表达式中作为模式的一部分声明的变量会覆盖match结构之外的同名变量,与所有变量一样。let x = Some(5);let y = 10;match x {Some(50) => println!("Got 50"),Some(y) => println!("Matched, y = {y}"),_ => println!("Default case, x = {:?}", x),}println!("at the end: x = {:?}, y = {y}", x);让我们看看当
match语句运行的时候发生了什么。第一个匹配分支的模式并不匹配x中定义的值,所以代码继续执行。第二个匹配分支中的模式引入了一个新变量
y,它会匹配任何Some中的值。因为我们在match表达式的新作用域中,这是一个新变量,而不是开头声明为值 10 的那个y。这个新的y绑定会匹配任何Some中的值,在这里是x中的值。因此这个y绑定了x中Some内部的值。这个值是 5,所以这个分支的表达式将会执行并打印出Matched, y = 5。如果
x的值是None而不是Some(5),头两个分支的模式不会匹配,所以会匹配下划线。这个分支的模式中没有引入变量x,所以此时表达式中的x会是外部没有被覆盖的x。在这个假想的例子中,match将会打印Default case, x = None。一旦
match表达式执行完毕,其作用域也就结束了,同理内部y的作用域也结束了。最后的println!会打印at the end: x = Some(5), y = 10。
🎯多个模式
在
match表达式中,可以使用|语法匹配多个模式,它代表 或(or)运算符模式。例如,如下代码将x的值与匹配分支相比较,第一个分支有 或 选项,意味着如果x的值匹配此分支的任一个值,它就会运行:let x = 1;match x {1 | 2 => println!("one or two"),3 => println!("three"),_ => println!("anything"),}上面的代码会打印
one or two。
🎯通过..-=匹配值的范围
..=语法允许你匹配一个闭区间范围内的值。在如下代码中,当模式匹配任何在给定范围内的值时,该分支会执行:let x = 5;match x {1..=5 => println!("one through five"),_ => println!("something else"),}如果
x是 1、2、3、4 或 5,第一个分支就会匹配。这个语法在匹配多个值时相比使用|运算符来表达相同的意思更为方便;如果使用|则不得不指定1 | 2 | 3 | 4 | 5。相反指定范围就简短的多,特别是在希望匹配比如从 1 到 1000 的数字的时候!编译器会在编译时检查范围不为空,而
char和数字值是 Rust 仅有的可以判断范围是否为空的类型,所以范围只允许用于数字或char值。let x = 'c';match x {'a'..='j' => println!("early ASCII letter"),'k'..='z' => println!("late ASCII letter"),_ => println!("something else"),}
🎯解构并分解值
🎃解构结构体
有两个字段
x和y的结构体Point,可以通过带有模式的let语句将其分解:struct Point {x: i32,y: i32, }fn main() {let p = Point { x: 0, y: 7 };let Point { x: a, y: b } = p;assert_eq!(0, a);assert_eq!(7, b); }这段代码创建了变量
a和b来匹配结构体p中的x和y字段。这个例子展示了模式中的变量名不必与结构体中的字段名一致。不过通常希望变量名与字段名一致以便于理解变量来自于哪些字段。因为变量名匹配字段名是常见的,同时因为let Point { x: x, y: y } = p;包含了很多重复,所以对于匹配结构体字段的模式存在简写:只需列出结构体字段的名称,则模式创建的变量会有相同的名称。struct Point {x: i32,y: i32, }fn main() {let p = Point { x: 0, y: 7 };let Point { x, y } = p;assert_eq!(0, x);assert_eq!(7, y); }这段代码创建了变量
x和y,与变量p中的x和y相匹配。其结果是变量x和y包含结构体p中的值。也可以使用字面值作为结构体模式的一部分进行解构,而不是为所有的字段创建变量。这允许我们测试一些字段为特定值的同时创建其他字段的变量。
展示了一个
match语句将Point值分成了三种情况:直接位于x轴上(此时y = 0为真)、位于y轴上(x = 0)或不在任何轴上的点。fn main() {let p = Point { x: 0, y: 7 };match p {Point { x, y: 0 } => println!("On the x axis at {x}"),Point { x: 0, y } => println!("On the y axis at {y}"),Point { x, y } => {println!("On neither axis: ({x}, {y})");}} }第一个分支通过指定字段
y匹配字面值0来匹配任何位于x轴上的点。此模式仍然创建了变量x以便在分支的代码中使用。类似的,第二个分支通过指定字段
x匹配字面值0来匹配任何位于y轴上的点,并为字段y创建了变量y。第三个分支没有指定任何字面值,所以其会匹配任何其他的Point并为x和y两个字段创建变量。在这个例子中,值
p因为其x包含 0 而匹配第二个分支,因此会打印出On the y axis at 7。记住
match表达式一旦找到一个匹配的模式就会停止检查其它分支,所以即使Point { x: 0, y: 0}在x轴上也在y轴上,这些代码也只会打印On the x axis at 0。
🎃解构枚举
不过当时没有明确提到解构枚举的模式需要对应枚举所定义的储存数据的方式。
enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(i32, i32, i32), }fn main() {let msg = Message::ChangeColor(0, 160, 255);match msg {Message::Quit => {println!("The Quit variant has no data to destructure.");}Message::Move { x, y } => {println!("Move in the x direction {x} and in the y direction {y}");}Message::Write(text) => {println!("Text message: {text}");}Message::ChangeColor(r, g, b) => {println!("Change the color to red {r}, green {g}, and blue {b}",)}} }这段代码会打印出
Change the color to red 0, green 160, and blue 255。尝试改变msg的值来观察其他分支代码的运行。对于像
Message::Quit这样没有任何数据的枚举成员,不能进一步解构其值。只能匹配其字面值Message::Quit,因此模式中没有任何变量。对于像
Message::Move这样的类结构体枚举成员,可以采用类似于匹配结构体的模式。在成员名称后,使用大括号并列出字段变量以便将其分解以供此分支的代码使用。
🎃解构嵌套的结构体和枚举
目前为止,所有的例子都只匹配了深度为一级的结构体或枚举,不过当然也可以匹配嵌套的项!
enum Color {Rgb(i32, i32, i32),Hsv(i32, i32, i32), }enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(Color), }fn main() {let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));match msg {Message::ChangeColor(Color::Rgb(r, g, b)) => {println!("Change color to red {r}, green {g}, and blue {b}");}Message::ChangeColor(Color::Hsv(h, s, v)) => {println!("Change color to hue {h}, saturation {s}, value {v}")}_ => (),} }
match表达式第一个分支的模式匹配一个包含Color::Rgb枚举成员的Message::ChangeColor枚举成员,然后模式绑定了 3 个内部的i32值。第二个分支的模式也匹配一个Message::ChangeColor枚举成员,但是其内部的枚举会匹配Color::Hsv枚举成员。我们可以在一个match表达式中指定这些复杂条件,即使会涉及到两个枚举。
🎃解构结构体和元组
甚至可以用复杂的方式来混合、匹配和嵌套解构模式。如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来:
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });这将复杂的类型分解成部分组件以便可以单独使用我们感兴趣的值。
通过模式解构是一个方便利用部分值片段的手段,比如结构体中每个单独字段的值。
🎯忽略模式中的值
有时忽略模式中的一些值是有用的,比如
match中最后捕获全部情况的分支实际上没有做任何事,但是它确实对所有剩余情况负责。有一些简单的方法可以忽略模式中全部或部分值:使用_模式(我们已经见过了),在另一个模式中使用_模式,使用一个以下划线开始的名称,或者使用..忽略所剩部分的值。让我们来分别探索如何以及为什么要这么做。
🎃使用_使用忽略整个值
我们已经使用过下划线作为匹配但不绑定任何值的通配符模式了。虽然这作为
match表达式最后的分支特别有用,也可以将其用于任意模式,包括函数参数中fn foo(_: i32, y: i32) {println!("This code only uses the y parameter: {}", y); }fn main() {foo(3, 4); }这段代码会完全忽略作为第一个参数传递的值
3,并会打印出This code only uses the y parameter: 4。大部分情况当你不再需要特定函数参数时,最好修改签名不再包含无用的参数。在一些情况下忽略函数参数会变得特别有用,比如实现 trait 时,当你需要特定类型签名但是函数实现并不需要某个参数时。这样可以避免一个存在未使用的函数参数的编译警告,就跟使用命名参数一样。
🎃使用嵌套的_忽略部分值
也可以在一个模式内部使用
_忽略部分值,例如,当只需要测试部分值但在期望运行的代码中没有用到其他部分时。示例 18-18 展示了负责管理设置值的代码。业务需求是用户不允许覆盖现有的自定义设置,但是可以取消设置,也可以在当前未设置时为其提供设置。let mut setting_value = Some(5);let new_setting_value = Some(10);match (setting_value, new_setting_value) {(Some(_), Some(_)) => {println!("Can't overwrite an existing customized value");}_ => {setting_value = new_setting_value;}}println!("setting is {:?}", setting_value);这段代码会打印出
Can't overwrite an existing customized value接着是setting is Some(5)。在第一个匹配分支,我们不需要匹配或使用任一个Some成员中的值;重要的部分是需要测试setting_value和new_setting_value都为Some成员的情况。在这种情况,我们打印出为何不改变setting_value,并且不会改变它。对于所有其他情况(
setting_value或new_setting_value任一为None),这由第二个分支的_模式体现,这时确实希望允许new_setting_value变为setting_value。let numbers = (2, 4, 8, 16, 32);match numbers {(first, _, third, _, fifth) => {println!("Some numbers: {first}, {third}, {fifth}")}}这会打印出
Some numbers: 2, 8, 32,值 4 和 16 会被忽略。
🎃通过在名字前以一个_开头来忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告,因为未使用的变量可能会是个 bug。但是有时创建一个还未使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头。示例 18-20 中创建了两个未使用变量,不过当编译代码时只会得到其中一个的警告:
fn main() {let _x = 5;let y = 10; }这里得到了警告说未使用变量
y,不过没有警告说使用_x。注意,只使用
_和使用以下划线开头的名称有些微妙的不同:比如_x仍会将值绑定到变量,而_则完全不会绑定。为了展示这个区别的意义:let s = Some(String::from("Hello!"));if let Some(_s) = s {println!("found a string");}println!("{:?}", s);我们会得到一个错误,因为
s的值仍然会移动进_s,并阻止我们再次使用s。然而只使用下划线本身,并不会绑定值。let s = Some(String::from("Hello!"));if let Some(_) = s {println!("found a string");}println!("{:?}", s);上面的代码能很好的运行;因为没有把
s绑定到任何变量;它没有被移动。
🎃用..忽略剩余值
对于有多个部分的值,可以使用
..语法来只使用特定部分并忽略其它值,同时避免不得不每一个忽略值列出下划线。..模式会忽略模式中剩余的任何没有显式匹配的值部分。struct Point {x: i32,y: i32,z: i32,}let origin = Point { x: 0, y: 0, z: 0 };match origin {Point { x, .. } => println!("x is {}", x),}这里列出了
x值,接着仅仅包含了..模式。这比不得不列出y: _和z: _要来得简单,特别是在处理有很多字段的结构体,但只涉及一到两个字段时的情形。fn main() {let numbers = (2, 4, 8, 16, 32);match numbers {(first, .., last) => {println!("Some numbers: {first}, {last}");}} }这里用
first和last来匹配第一个和最后一个值。..将匹配并忽略中间的所有值。然而使用
..必须是无歧义的。如果期望匹配和忽略的值是不明确的,Rust 会报错。、fn main() {let numbers = (2, 4, 8, 16, 32);match numbers {(.., second, ..) => {println!("Some numbers: {}", second)},} }如果编译上面的例子,会得到下面的错误:
$ cargo runCompiling patterns v0.1.0 (file:///projects/patterns) error: `..` can only be used once per tuple pattern--> src/main.rs:5:22| 5 | (.., second, ..) => {| -- ^^ can only be used once per tuple pattern| || previously used hereerror: could not compile `patterns` due to previous errorRust 不可能决定在元组中匹配
second值之前应该忽略多少个值,以及在之后忽略多少个值。这段代码可能表明我们意在忽略2,绑定second为4,接着忽略8、16和32;抑或是意在忽略2和4,绑定second为8,接着忽略16和32,以此类推。变量名second对于 Rust 来说并没有任何特殊意义,所以会得到编译错误,因为在这两个地方使用..是有歧义的。
🎯匹配守卫提供的额外条件
匹配守卫(match guard)是一个指定于
match分支模式之后的额外if条件,它也必须被满足才能选择此分支。匹配守卫用于表达比单独的模式所能允许的更为复杂的情况。这个条件可以使用模式中创建的变量。示例 18-26 展示了一个
match,其中第一个分支有模式Some(x)还有匹配守卫if x % 2 == 0(当x是偶数的时候为真):let num = Some(4);match num {Some(x) if x % 2 == 0 => println!("The number {} is even", x),Some(x) => println!("The number {} is odd", x),None => (),}上例会打印出
The number 4 is even。当num与模式中第一个分支比较时,因为Some(4)匹配Some(x)所以可以匹配。接着匹配守卫检查x除以2的余数是否等于0,因为它等于0,所以第一个分支被选择。相反如果
num为Some(5),因为5除以2的余数是1不等于0所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,这次匹配因为它没有匹配守卫所以会匹配任何Some成员。无法在模式中表达类似
if x % 2 == 0的条件,所以通过匹配守卫提供了表达类似逻辑的能力。这种替代表达方式的缺点是,编译器不会尝试为包含匹配守卫的模式检查穷尽性。
🎯@绑定
at 运算符(
@)允许我们在创建一个存放值的变量的同时测试其值是否匹配模式。示例 18-29 展示了一个例子,这里我们希望测试Message::Hello的id字段是否位于3..=7范围内,同时也希望能将其值绑定到id_variable变量中以便此分支相关联的代码可以使用它。可以将id_variable命名为id,与字段同名,不过出于示例的目的这里选择了不同的名称。enum Message {Hello { id: i32 },}let msg = Message::Hello { id: 5 };match msg {Message::Hello {id: id_variable @ 3..=7,} => println!("Found an id in range: {}", id_variable),Message::Hello { id: 10..=12 } => {println!("Found an id in another range")}Message::Hello { id } => println!("Found some other id: {}", id),}上例会打印出
Found an id in range: 5。通过在3..=7之前指定id_variable @,我们捕获了任何匹配此范围的值并同时测试其值匹配这个范围模式。第二个分支只在模式中指定了一个范围,分支相关代码没有一个包含
id字段实际值的变量。id字段的值可以是 10、11 或 12,不过这个模式的代码并不知情也不能使用id字段中的值,因为没有将id值保存进一个变量。最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量
id,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对id字段的值进行测试:任何值都会匹配此分支。
相关文章:

【Rust】——所有的模式语法
💻博主现有专栏: C51单片机(STC89C516),c语言,c,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux…...

基于Python的求职招聘管理系统【附源码】
摘 要 随着互联网技术的不断发展,人类的生活已经逐渐离不开网络了,在未来的社会中,人类的生活与工作都离不开数字化、网络化、电子化与虚拟化的数字技术。从互联网的发展历史、当前的应用现状和发展趋势来看,我们完全可以肯定&…...
Python23 使用Tensorflow实现线性回归
TensorFlow 是一个开源的软件库,用于数值计算,特别适用于大规模的机器学习。它由 Google 的研究人员和工程师在 Google Brain 团队内部开发,并在 2015 年首次发布。TensorFlow 的核心是使用数据流图来组织计算,使得它可以轻松地利…...

C++:枚举类的使用案例及场景
一、使用案例 在C中,枚举类(也称为枚举类型或enum class)是C11及以后版本中引入的一种更加强大的枚举类型。与传统的枚举(enum)相比,枚举类提供了更好的类型安全性和作用域控制。下面是一个使用枚举类的案…...
)
中英双语介绍美国的州:明尼苏达州(Minnesota)
中文版 明尼苏达州简介 明尼苏达州位于美国中北部,以其万湖之州的美誉、丰富的自然资源和多样化的经济结构而著称。以下是对明尼苏达州的详细介绍,包括其地理位置、人口、经济、教育、文化和主要城市。 地理位置 明尼苏达州东接威斯康星州࿰…...

Python实现万花筒效果:创造炫目的动态图案
文章目录 引言准备工作前置条件 代码实现与解析导入必要的库初始化Pygame定义绘制万花筒图案的函数主循环 完整代码 引言 万花筒效果通过反射和旋转图案创造出美丽的对称图案。在这篇博客中,我们将使用Python来实现一个动态的万花筒效果。通过利用Pygame库…...

JavaScript之深入对象,详细讲讲构造函数与常见内置构造函数
前言:哈喽,大家好,我是前端菜鸟的自我修养!今天给大家详细讲讲构造函数与常见内置构造函数,并提供具体代码帮助大家深入理解,彻底掌握!原创不易,如果能帮助到带大家,欢迎…...

PyQt5水平布局--只需5分钟带你搞懂
PyQt5水平布局(QHBoxLayout)是一种在GUI应用程序中用于组织和排列控件的布局方式。它允许开发者将控件在水平方向上从左到右依次排列,非常适合于需要并排显示控件的场景,如工具栏、水平菜单等。 import sys from PyQt5.QtWidgets…...

telegram mini app和game实现登录功能
接上一篇文章,我们在创建好telegram机器人后,开始开发小游戏或者mini App,那就避免不了登录功能。 公开链接 bot设置教程:https://lengmo714.top/6e79860b.html 参考教程参考教程,telegram已经给我们提供非常多的api,我们在获取用…...

【Python】字典练习
python期考练习 目录 1. 首都名编辑 2. 摩斯电码 3. 登录 4. 学生的姓名和年龄编辑 5. 电商 6. 学生基本信息 7. 字母数 1. 首都名 初始字典 (可复制) : d{"China":"Beijing","America":"Washington","Norway":…...
Apache POI、EasyPoi、EasyExcel
目录 编辑 (一)Apache PoI 使用 (二)EasyPoi使用 (三)EasyExcel使用 写 读 最简单的读 最简单的读的excel示例 最简单的读的对象 (一)Apache PoI 使用 (二&…...

gcop:简化 Git 提交流程的高效助手 | 一键生成 commit message
💖 大家好,我是Zeeland。Tags: 大模型创业、LangChain Top Contributor、算法工程师、Promptulate founder、Python开发者。📣 个人说明书:Zeeland📣 个人网站:https://me.zeeland.cn/📚 Github…...

TS_类型
目录 1.类型注解 2.类型检查 3.类型推断 4.类型断言 ①尖括号(<>)语法 ②as语法 5.数据类型 ①boolean ②number ③string ④undefined 和 null ⑤数组和元组 ⑥枚举 ⑦any 和void ⑧symbol ⑨Function ⑩Object 和 object 6.高…...
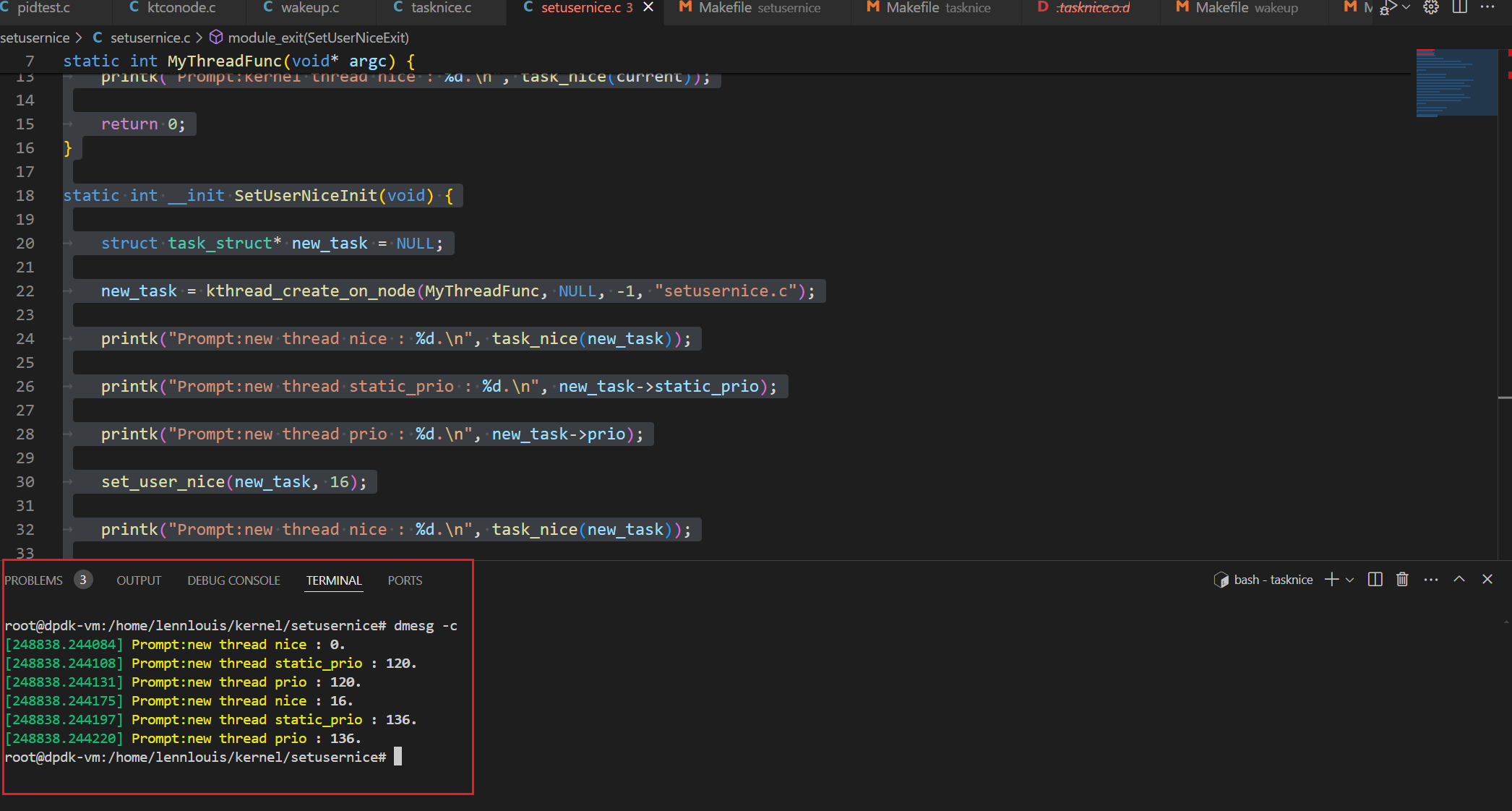
Linux源码阅读笔记10-进程NICE案例分析2
set_user_nice set_user_nice函数功能:设置某一进程的NICE值,其NICE值的计算是根据进程的静态优先级(task_struct->static_prio),直接通过set_user_nice函数更改进程的静态优先级。 内核源码 void set_user_nice…...
Elasticsearch实战教程: 如何在海量级数据中进行快速搜索
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 Elasticsearch(简称ES)是一个基于Apache Lucene™的开源搜索引擎,无论在开源还是专有领…...
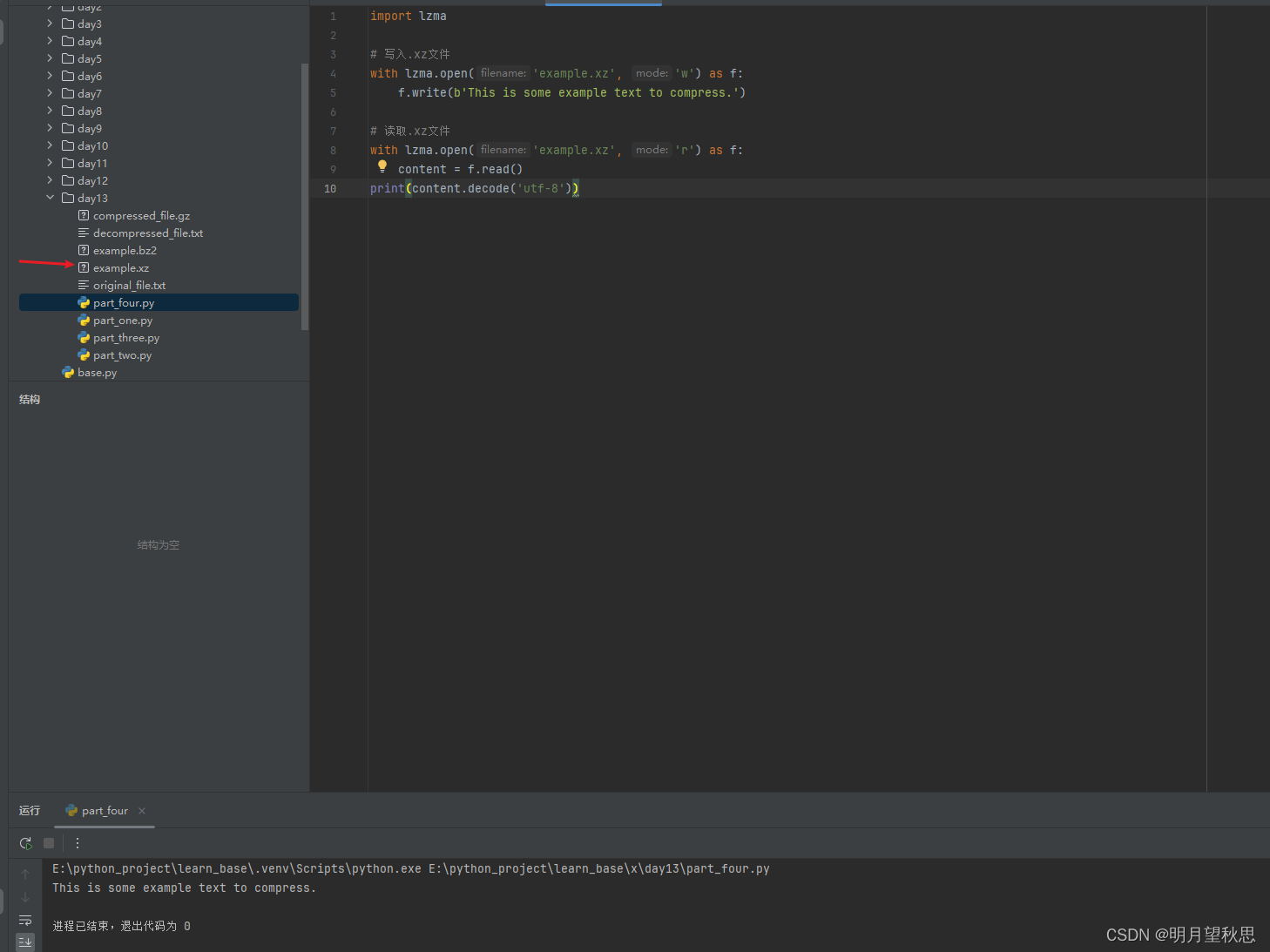
Python学习笔记24:进阶篇(十三)常见标准库使用之数据压缩功能模块zlib,gzip,bz2,lzma的学习使用
前言 本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。 根据模块知识,一次讲解单个或者多个模块的内容。 教程链接:https://docs.python.org/zh-cn/3/tutorial/index.html 数据压缩…...

【笔记】Android Settings 应用设置菜单的界面代码介绍
简介 Settings应用中,提供多类设置菜单入口,每个菜单内又有各模块功能的实现。 那么各个模块基于Settings 基础的界面Fragment去实现UI,层层按不同业务进行封装继承实现子类: DashboardFragmentSettingsPreferenceFragment 功…...

Symfony配置管理深度解析:构建可维护项目的秘诀
Symfony是一个高度灵活且功能丰富的PHP框架,它提供了一套强大的配置管理系统,使得开发者能够轻松定制和优化应用程序的行为。本文将深入探讨Symfony中的配置管理机制,包括配置的结构、来源、加载过程以及最佳实践。 一、配置管理的重要性 在…...
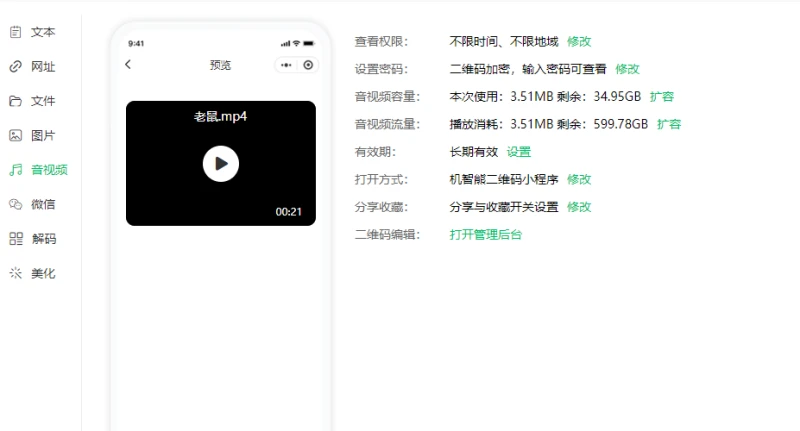
视频的宣传片二维码怎么做?扫码播放视频的制作教程
现在很多的宣传片会通过扫码的方式来展示,通过将视频生成二维码之后,其他人就可以扫码来查看视频内容,从而简化获取视频的过程,提升视频传播的效率及用户查看视频的便捷性。目前,日常生活和工作中就有视频二维码的应用…...

实用的网站
前端 精简CSS格式 Font Awesome 图标库 BootCDN 加速服务 LOGO U钙网 AI AI工具集 视频下载 B站视频解析下载...

3分钟告别Armoury Crate:华硕笔记本轻量化控制终极指南
3分钟告别Armoury Crate:华硕笔记本轻量化控制终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, E…...

基于CircuitPython与MCP23017的环境音效混合器:嵌入式音频与GPIO扩展实战
1. 项目概述与环境音效混合器的核心价值如果你和我一样,对嵌入式音频项目充满热情,同时又常常被微控制器有限的GPIO引脚数量所困扰,那么这个基于CircuitPython与MCP23017的环境音效混合器项目,绝对值得你花上一个周末的时间来亲手…...

米尔RK3576开发板评测:工业AI与边缘计算的性能甜点方案
1. 项目概述:当RK3576遇上米尔开发板,工业AI的新选择最近在嵌入式圈子里,瑞芯微的RK3576这颗SoC讨论热度挺高。作为一枚常年混迹在工控、边缘计算和AIoT项目里的老工程师,我对这类新平台的发布总是格外敏感。米尔电子作为国内老牌…...

C语言实现热水器温度控制PID算法详解与嵌入式实战
1. 项目概述与核心价值最近在整理一些嵌入式开发的老项目,翻出来一个用C语言写的热水器温度控制PID算法示例。这玩意儿虽然代码量不大,但麻雀虽小五脏俱全,把PID控制的核心思想、参数整定、抗积分饱和这些关键点都体现出来了。对于刚接触自动…...

NGA论坛优化摸鱼体验:终极指南让你的浏览效率提升300%[特殊字符]
NGA论坛优化摸鱼体验:终极指南让你的浏览效率提升300%🔥 【免费下载链接】NGA-BBS-Script NGA论坛增强脚本,给你完全不一样的浏览体验 项目地址: https://gitcode.com/gh_mirrors/ng/NGA-BBS-Script 你是否厌倦了在NGA论坛浏览时被杂乱…...

Spring Cloud整合XXL-Job避坑指南:调度过期策略选错,你的定时任务可能就白跑了
Spring Cloud微服务中XXL-Job调度策略深度解析与实战避坑 在微服务架构盛行的今天,定时任务作为业务系统中不可或缺的一环,其稳定性和可靠性直接影响着核心业务流程。XXL-Job作为一款轻量级分布式任务调度平台,凭借其简单易用、功能强大的特性…...

Obsidian个性化主页:如何用3款模板解决知识管理效率难题?
Obsidian个性化主页:如何用3款模板解决知识管理效率难题? 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage …...

三自由度机械臂运动学建模与求解:从DH参数到算法验证
1. 三自由度机械臂运动学基础 刚接触机械臂控制时,我最头疼的就是运动学建模这部分。三自由度机械臂虽然结构简单,但要把它的运动规律用数学语言描述清楚,需要建立完整的理论框架。运动学主要研究机械臂末端执行器的位置、速度和加速度与各关…...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...

2026年腾讯云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这篇
2026年腾讯云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这篇。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Toke…...