Elasticsearch实战教程: 如何在海量级数据中进行快速搜索

引入
Elasticsearch(简称ES)是一个基于Apache Lucene™的开源搜索引擎,无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。几天我们就来体验一下如何在海量数据中快速进行搜索。
文章目录
- 引入
- 一、环境搭建
- 1.1、安装JDK
- 1.2、安装ElasticSearch
- 1.3、设置data的目录
- 1.4、设置log的目录
- 1.5、修改配置文件elasticsearch.yml
- 1.6、启动elasticsearch
- 二、创建数据索引
- 2.1创建 `my_index`的索引
- 三. 进行数据导入
- 四、 进行数据搜索
- 总结
一、环境搭建
首先,在使用 Elasticsearch 之前,我们需要先安装好服务,操作也很简单。
本次我们选择我们采用CentOS7来部署 ElasticSearch 服务。
登录https://www.elastic.co/cn/downloads/elasticsearch,选择相应的系统环境下载软件包,这里我用的操作系统是CentOS,所以选择Linux环境。
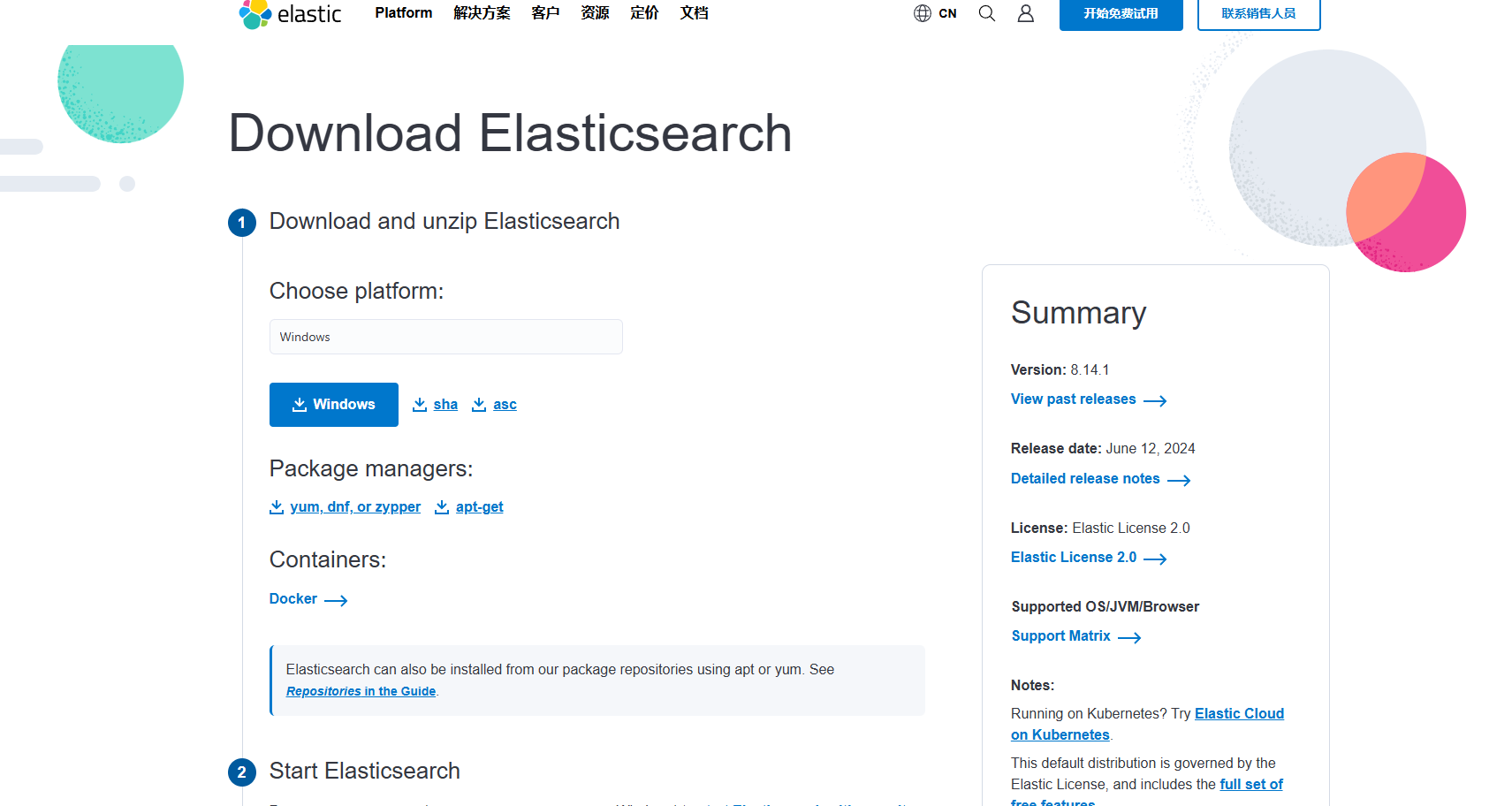
1.1、安装JDK
Elasticsearch 是用 Java 语言开发的,所以在安装之前,需要先安装一下JDK
yum -y install java-1.8.0-openjdk
查看java安装情况
java -version
1.2、安装ElasticSearch
进入到对应上传的文件夹,安装ElasticSearch
rpm -ivh elasticsearch-6.1.0.rpm
查找安装路径
rpm -ql elasticsearch
一般是装在/usr/share/elasticsearch/下。
1.3、设置data的目录
创建/data/es-data目录,用于elasticsearch数据的存放
mkdir -p /data/es-data
修改该目录的拥有者为elasticsearch
chown -R elasticsearch:elasticsearch /data/es-data
1.4、设置log的目录
mkdir -p /log/es-log
修改该目录的拥有者为elasticsearch
chown -R elasticsearch:elasticsearch /log/es-log
1.5、修改配置文件elasticsearch.yml
vim /etc/elasticsearch/elasticsearch.yml
修改如下内容:
#设置节点名称
cluster.name: my-es#设置data存放的路径为/data/es-data
path.data: /data/es-data#设置logs日志的路径为/log/es-log
path.logs: /log/es-log#设置内存不使用交换分区,配置了bootstrap.memory_lock为true时反而会引发9200不会被监听,原因不明
bootstrap.memory_lock: false#设置允许所有ip可以连接该elasticsearch
network.host: 0.0.0.0#开启监听的端口为9200
http.port: 9200#增加新的参数,为了让elasticsearch-head插件可以访问es (5.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"
1.6、启动elasticsearch
启动
systemctl start elasticsearch
查看状态
systemctl status elasticsearch
设置开机启动
systemctl enable elasticsearch
启动成功之后,测试服务是否开启
curl -X GET http://localhost:9200
同时也可以远程测试一下,如果网络被拒绝,检查防火墙是否开启
#查询防火墙状态
firewall-cmd --state
如果状态是active表示已经开启,可以将其关闭
#关闭防火墙
systemctl stop firewalld.service
如果不想开机启动,可以输入如下命令
#禁止firewall开机启动
systemctl disable firewalld.service
二、创建数据索引
在Elasticsearch中,数据是以JSON格式存储的。首先,我们需要创建一个索引,索引相当于一个数据集合,它可以包含一个或多个类型(type)。
2.1创建 my_index的索引
PUT /my_index
{"settings": {"number_of_shards": 1,"number_of_replicas": 0},"mappings": {"properties": {"title": { "type": "text" },"content": { "type": "text" }}}
}
在上面的例子中,我们创建了一个名为my_index的索引,并设置了分片数为1,副本数为0。同时,我们定义了两个字段title和content,它们的类型都是文本。
三. 进行数据导入
接下来,我们需要将数据导入到Elasticsearch中。可以使用POST请求和bulk API来实现。
POST /my_index/_bulk
{ "index": { "_id": 1 } }
{ "title": "Elasticsearch教程", "content": "这是一篇关于Elasticsearch的教程。" }
{ "index": { "_id": 2 } }
{ "title": "Elasticsearch实战", "content": "这是一篇关于Elasticsearch实战的教程。" }
四、 进行数据搜索
现在,我们的数据已经导入到Elasticsearch中,可以使用GET请求来搜索数据。
GET /my_index/_search
{"query": {"match": {"title": "Elasticsearch"}}
}
上面的例子中,我们使用了一个简单的匹配查询来搜索标题中包含"Elasticsearch"的文档。
总结
在本教程中,我们学习了如何在Elasticsearch中创建索引、导入数据、进行数据搜索以及一些性能优化建议。希望这些内容能够帮助您在海量级数据中实现快速搜索。
相关文章:
Elasticsearch实战教程: 如何在海量级数据中进行快速搜索
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 Elasticsearch(简称ES)是一个基于Apache Lucene™的开源搜索引擎,无论在开源还是专有领…...
Python学习笔记24:进阶篇(十三)常见标准库使用之数据压缩功能模块zlib,gzip,bz2,lzma的学习使用
前言 本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。 根据模块知识,一次讲解单个或者多个模块的内容。 教程链接:https://docs.python.org/zh-cn/3/tutorial/index.html 数据压缩…...

【笔记】Android Settings 应用设置菜单的界面代码介绍
简介 Settings应用中,提供多类设置菜单入口,每个菜单内又有各模块功能的实现。 那么各个模块基于Settings 基础的界面Fragment去实现UI,层层按不同业务进行封装继承实现子类: DashboardFragmentSettingsPreferenceFragment 功…...

Symfony配置管理深度解析:构建可维护项目的秘诀
Symfony是一个高度灵活且功能丰富的PHP框架,它提供了一套强大的配置管理系统,使得开发者能够轻松定制和优化应用程序的行为。本文将深入探讨Symfony中的配置管理机制,包括配置的结构、来源、加载过程以及最佳实践。 一、配置管理的重要性 在…...
视频的宣传片二维码怎么做?扫码播放视频的制作教程
现在很多的宣传片会通过扫码的方式来展示,通过将视频生成二维码之后,其他人就可以扫码来查看视频内容,从而简化获取视频的过程,提升视频传播的效率及用户查看视频的便捷性。目前,日常生活和工作中就有视频二维码的应用…...

实用的网站
前端 精简CSS格式 Font Awesome 图标库 BootCDN 加速服务 LOGO U钙网 AI AI工具集 视频下载 B站视频解析下载...
Monorepo(单体仓库)与 MultiRepo(多仓库): Monorepo 单体仓库开发策略与实践指南
🔥 个人主页:空白诗 文章目录 一、引言1. Monorepo 和 MultiRepo 简介2. 为什么选择 Monorepo? 二、Monorepo 和 MultiRepo 的区别1. 定义和概述2. 各自的优点和缺点3. 适用场景 三、Monorepo 的开发策略1. 版本控制2. 依赖管理3. 构建和发布…...

使用 PyTorch 创建的多步时间序列预测的 Encoder-Decoder 模型
Encoder-decoder 模型在序列到序列的自然语言处理任务(如语言翻译等)中提供了最先进的结果。多步时间序列预测也可以被视为一个 seq2seq 任务,可以使用 encoder-decoder 模型来处理。本文提供了一个用于解决 Kaggle 时间序列预测任务的 encod…...

开启IT世界的第一步:高考新生的暑期学习指南
目录 前言 了解IT领域 学习编程语言 实践项目 学习资源 阅读专业书籍 培养良好的学习习惯 结语 最后 - 投票 前言 七月的钟声敲响,各省的高考分数已揭晓,意味着一段紧张而又充满奋斗的旅程画上了句号。然而,高考的结束并不意味…...
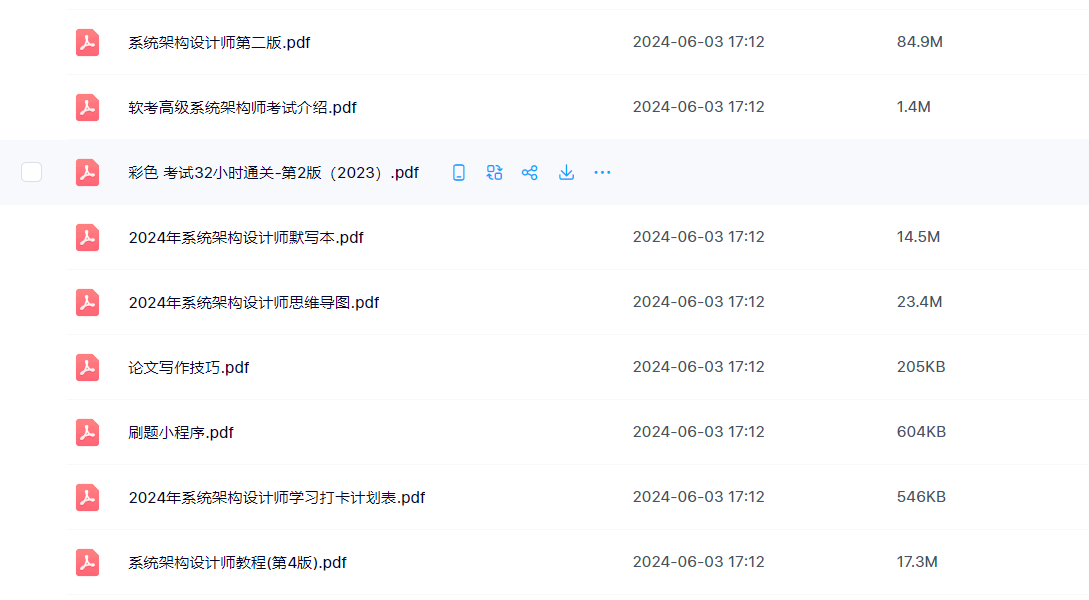
软考系统架构师高效备考方法论
软考系统架构师高效备考方法论 本章总结的备考方法论也是希望能帮助更多的小伙伴高效的备考最终通过考试,这种考试个人感觉是尽量一次性考过, 要不然老拖着,虽然每年可以考两次,5月和11月,两次考试间隔5个月时间&#…...
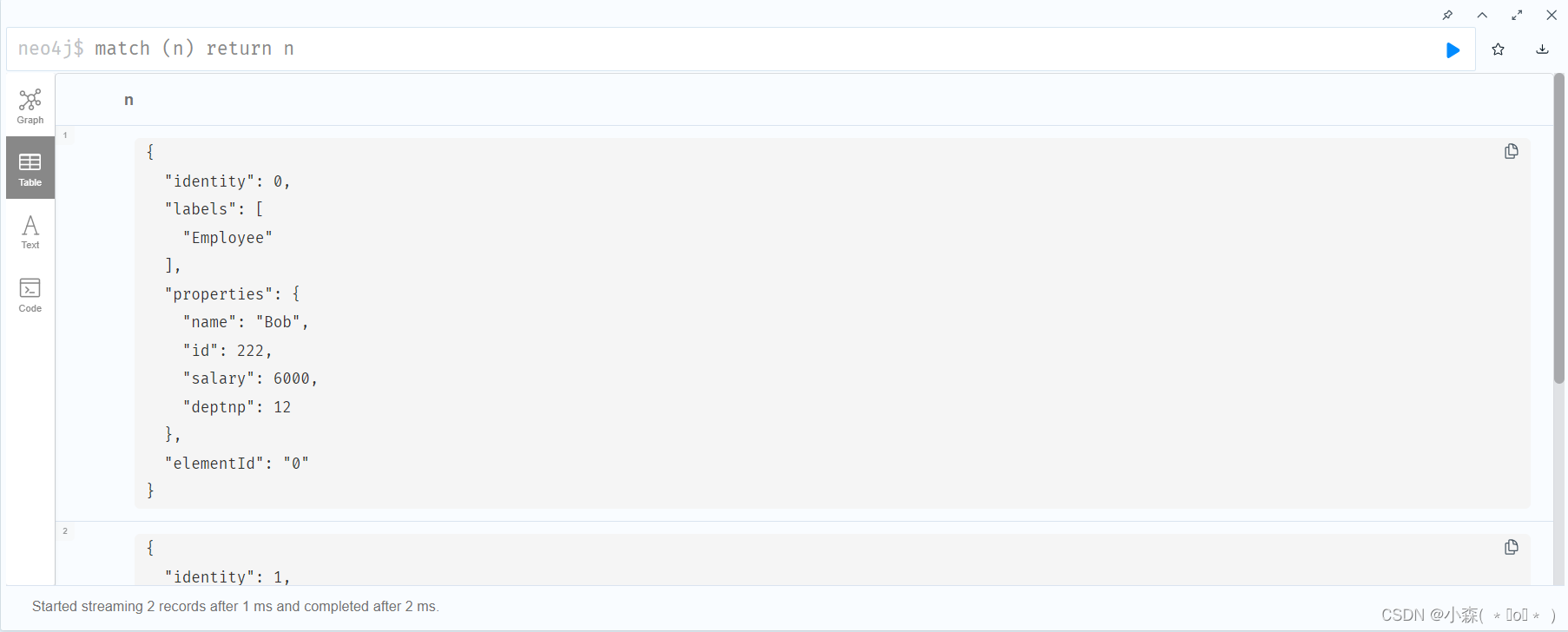
【neo4j图数据库】入门实践篇
探索数据之间的奥秘:Neo4j图数据库引领新纪元 在数字化浪潮汹涌的今天,数据已成为企业最宝贵的资产之一。然而,随着数据量的爆炸性增长和数据关系的日益复杂,传统的关系型数据库在处理诸如社交网络、推荐系统、生物信息学等高度互…...

【TS】TypeScript 原始数据类型深度解析
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 TypeScript 原始数据类型深度解析一、引言二、基础原始数据类型2.1 boolean2.2 …...

怎么样调整分类的阈值
调整分类模型的阈值是改变模型对正负类的预测标准的一种方法,常用于提高精确率、召回率或者其他性能指标。以下是如何调整分类阈值的步骤和方法: PS:阈值是针对预测概率(表示样本属于某个特定类别的可能性)来说的 调…...
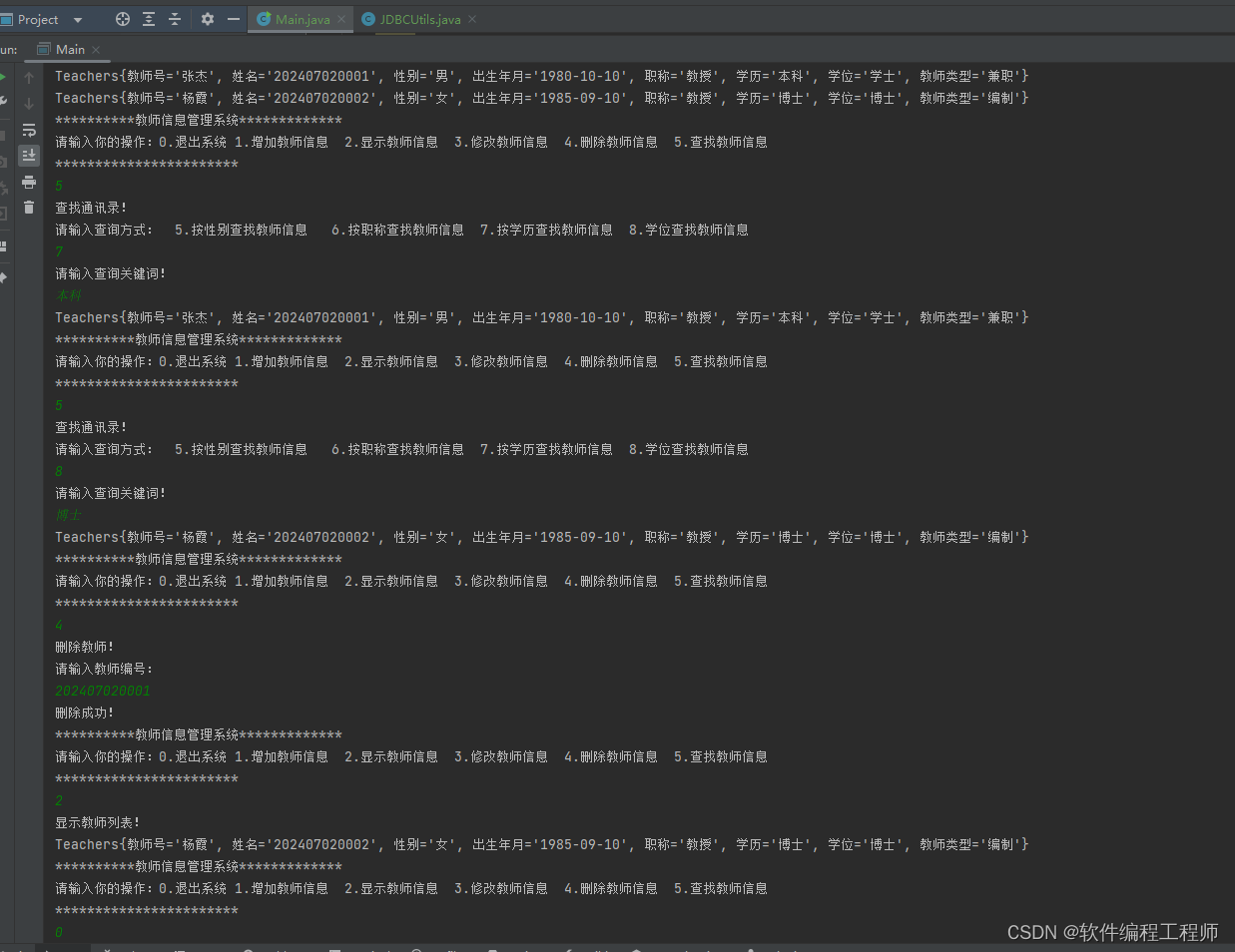
java+mysql教师管理系统
完整源码地址 教师信息管理系统使用命令行交互的方式及数据库连接实现教师信息管理系统,该系统旨在实现教师信息的管理,并根据需要进行教师信息展示。该软件的功能有如下功能 (1)基本信息管理(教师号、姓名、性别、出生年月、职称、学历、学位、教师类型…...

PDF文档如何统计字数,统计PDF文档字数的方法有哪些?
在平时使用pdf阅读或者是处理文档的时候,常常需要统计文档的字数。pdf在查看文字时其实很简单。 PDF文档是一种常见的电子文档格式,如果需要对PDF文档中的字数进行统计,可以使用以下方法: Adobe Acrobat DC:Adobe Ac…...

在Python asyncio中如何识别协程是否被block了
现在asyncio在Python中的使用越来越广泛了,但是很多人对于协程(corotine)的一些使用方式还不太熟悉。在这篇文章中,我将会介绍如何识别协程是否被block了,并以常用的HTTP网络库requests/httpx为例来说明如何避免协程被block的问题。 为什么协程会被block 在Python中,可…...
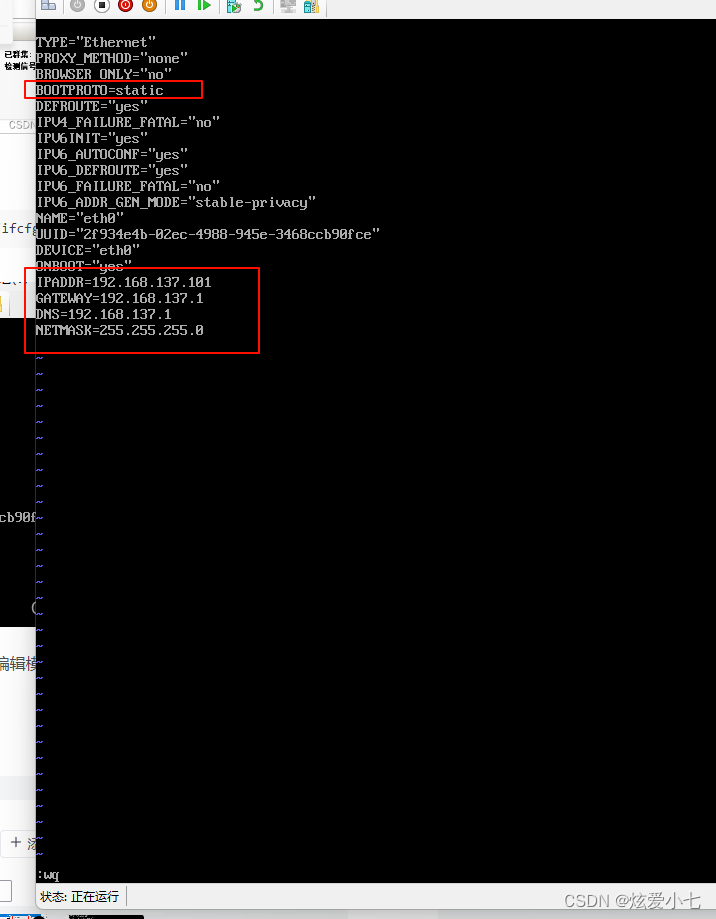
Hyper-V虚拟机固定IP地址(手把手教设置)
链接虚拟机修改网络配置文件 输入指令 sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0 然后 输入 按 i 键 再按回车 (enter) 进入编辑模式 修改配置(这几项)其中 IPADDR 就是你想给虚拟机固定的 IP 地址 多台的话只需要修改这个IP 就行其他不变 BOOTPROTO=static…...

以 Vue 3 项目为例,多个请求下如何全局封装 Loading 的展示与关闭?其中大有学问!
大家好,我是CodeQi! 项目开发中,Loading 的展示与关闭是非常关键的用户体验设计。 当我们的应用需要发起多个异步请求时,如何有效地管理全局 Loading 状态,保证用户在等待数据加载时能有明确的反馈,这是一个值得深入探讨的问题。 本文将以 Vue 3 项目为例,详细讲解如…...
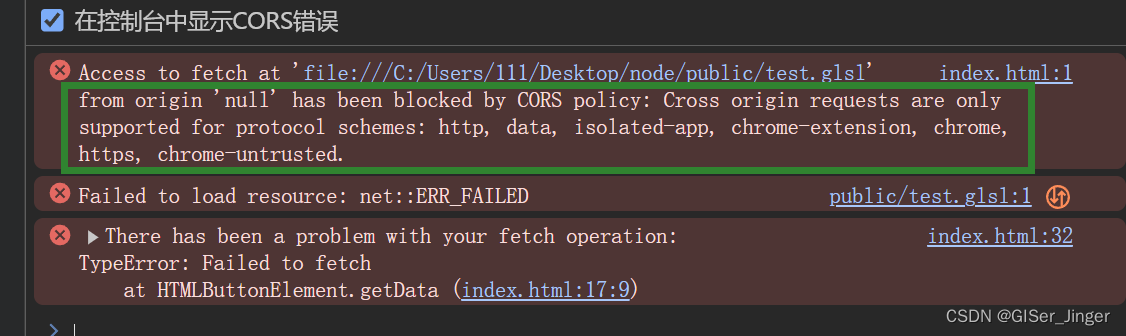
Node.js学习(一)
Node.js安装与入门案例: 需求:点击按钮,请求本地目录指定文件的内容,并显示在页面上 刚入门肯定想着直接写相对路径请求指定路径数据就行了,可是会发现不行。 网页运行在浏览器端,通常后续要发布…...

Spring Data JPA使用及实现原理总结
Spring Data JPA系列 1、SpringBoot集成JPA及基本使用 2、Spring Data JPA Criteria查询、部分字段查询 3、Spring Data JPA数据批量插入、批量更新真的用对了吗 4、Spring Data JPA的一对一、LazyInitializationException异常、一对多、多对多操作 5、Spring Data JPA自定…...

告别卡顿!用这款神器轻松下载M3U8格式视频流
告别卡顿!用这款神器轻松下载M3U8格式视频流 【免费下载链接】m3u8-downloader 一个M3U8 视频下载(M3U8 downloader)工具。跨平台: 提供windows、linux、mac三大平台可执行文件,方便直接使用。 项目地址: https://gitcode.com/gh_mirrors/m3u8d/m3u8-downloader …...

知识竞赛的“锦囊”设计:场外求助、免答权、双倍分
🧧 知识竞赛的“锦囊”设计:场外求助、免答权、双倍分救命稻草 策略博弈 让竞赛悬念迭起💎 一、锦囊设计的核心价值在知识竞赛中,锦囊不仅是选手的“救命稻草”,更是增加节目悬念、提升观众参与感的关键元素。合理设…...
的模板化部署)
统信UOS系统管理员必看:一招搞定用户配置文件(.config/autostart)的模板化部署
统信UOS系统配置模板化实战:从屏保设置到全局用户环境部署 在大型企业或教育机构的桌面环境管理中,统信UOS作为国产操作系统的代表,其标准化部署能力直接影响运维效率。当我们在模板用户中精心配置了各项参数——从屏幕保护时间到电源管理策略…...

FPGA新手避坑指南:用Vivado IP核搞定AXI总线,从看懂波形开始
FPGA新手避坑指南:用Vivado IP核搞定AXI总线,从看懂波形开始 第一次在Vivado中看到AXI总线波形时,我盯着屏幕上跳动的信号线完全摸不着头脑。VALID和READY信号像在玩捉迷藏,突发传输的时序如同天书——这大概是每个FPGA初学者都会…...

个人开发者如何借助 Taotoken 低成本体验顶级大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何借助 Taotoken 低成本体验顶级大模型 对于个人开发者或学生而言,直接接入和使用各家顶尖大模型 API 往往…...

SAP S/4HANA Cloud Public Edition 3-System Landscape 里的系统与 Tenant 设计
做 SAP S/4HANA Cloud Public Edition 项目时,最容易被低估的一件事,不是功能点本身,而是系统与 tenant 的边界。很多实施风险,并不是来自某个配置字段填错,也不是来自某段 ABAP 扩展代码写得不够优雅,而是项目一开始就没有把 Development、Test、Production、Customizin…...

如何用KLOGG在5分钟内成为日志分析高手
如何用KLOGG在5分钟内成为日志分析高手 【免费下载链接】klogg Really fast log explorer based on glogg project 项目地址: https://gitcode.com/gh_mirrors/kl/klogg 你是否曾在海量日志文件中迷失方向?面对数十GB的日志数据,传统的grep命令显…...

巧用邮件合并批量生成带条形码的证件标签
1. 为什么需要批量生成带条形码的证件标签? 在日常办公中,我们经常会遇到需要批量制作证件标签的情况。比如学校图书馆要给新生办理借书证,公司要给新员工制作工牌,或者社区要给居民发放会员卡。传统的手工制作方式不仅效率低下&…...

如何用LinkSwift解锁九大网盘下载新姿势?完整攻略揭秘
如何用LinkSwift解锁九大网盘下载新姿势?完整攻略揭秘 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

怎样高效搭建AI多智能体交易系统:3步快速部署完整方案
怎样高效搭建AI多智能体交易系统:3步快速部署完整方案 【免费下载链接】TradingAgents-AI.github.io TradingAgents: Multi-Agents LLM Financial Trading Framework 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-AI.github.io 想要让AI…...